
Spectral Swin Transformer Network for Hyperspectral Image Classification

Abstract
:1. Introduction
2. Proposed Approach
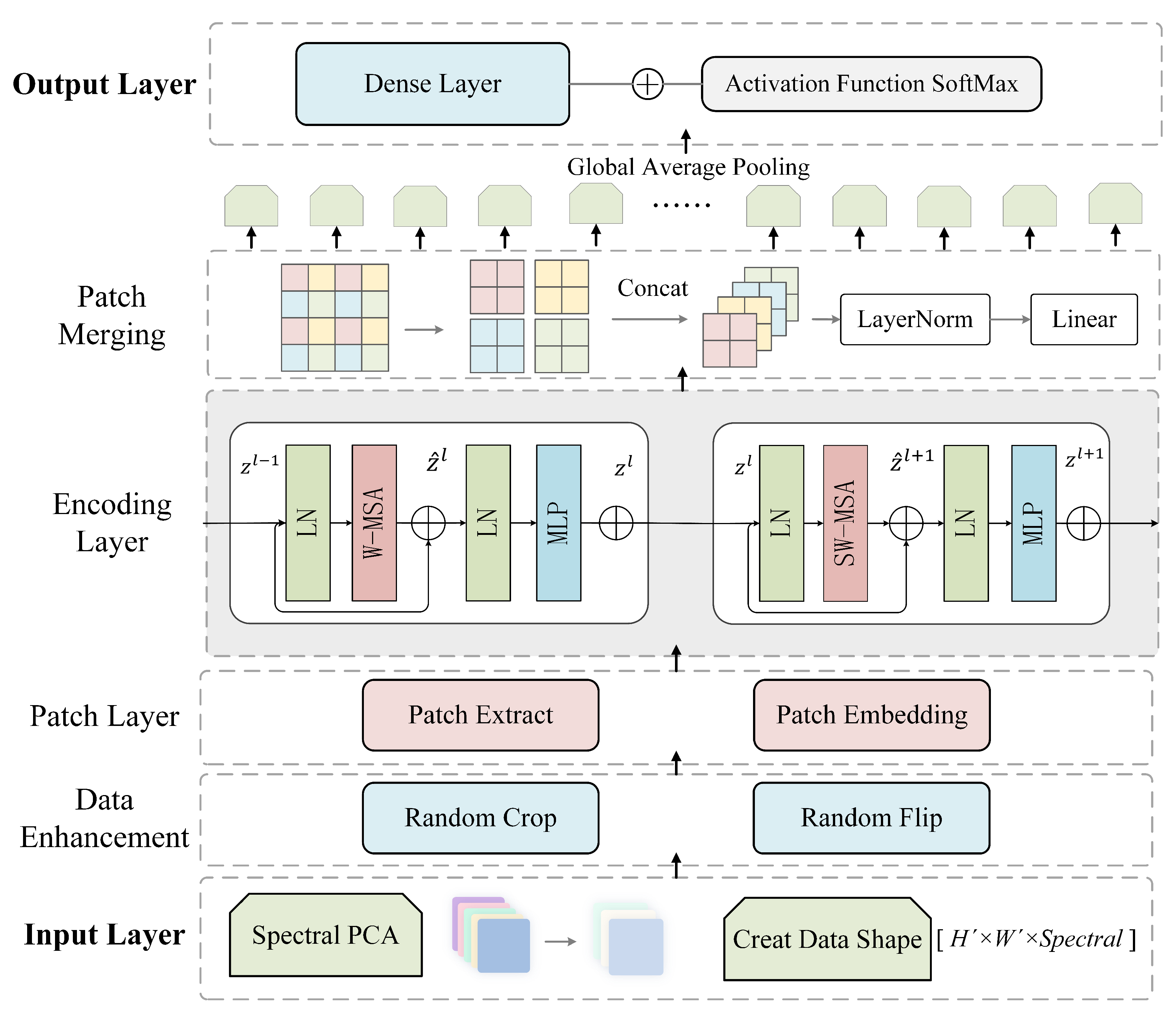
2.1. Spectral Swin Transformer Network for HSI Classification
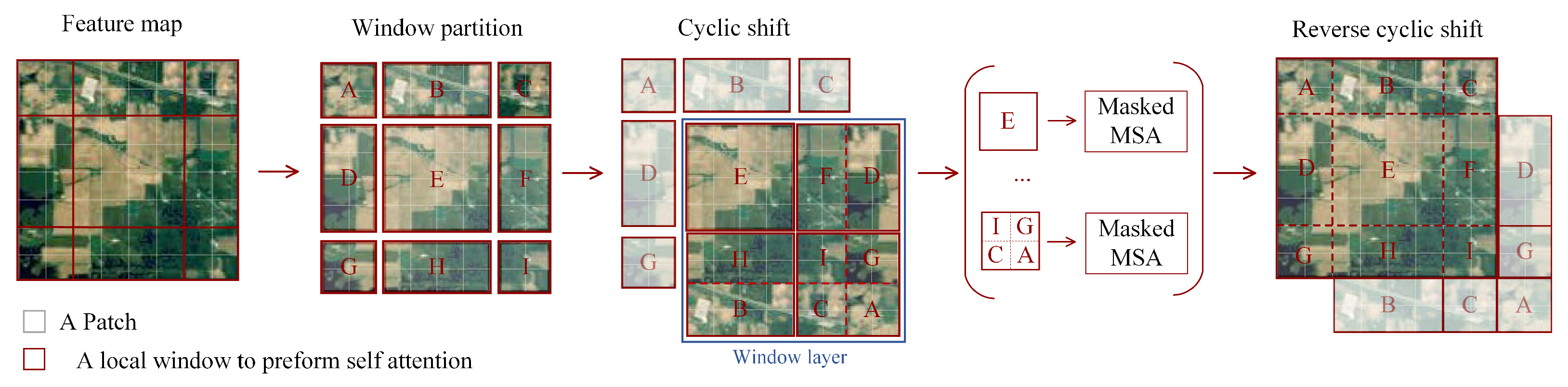
2.2. Swin Transformer Encoder and SW-MSA
2.3. Parametric Analysis
3. Experimental Results
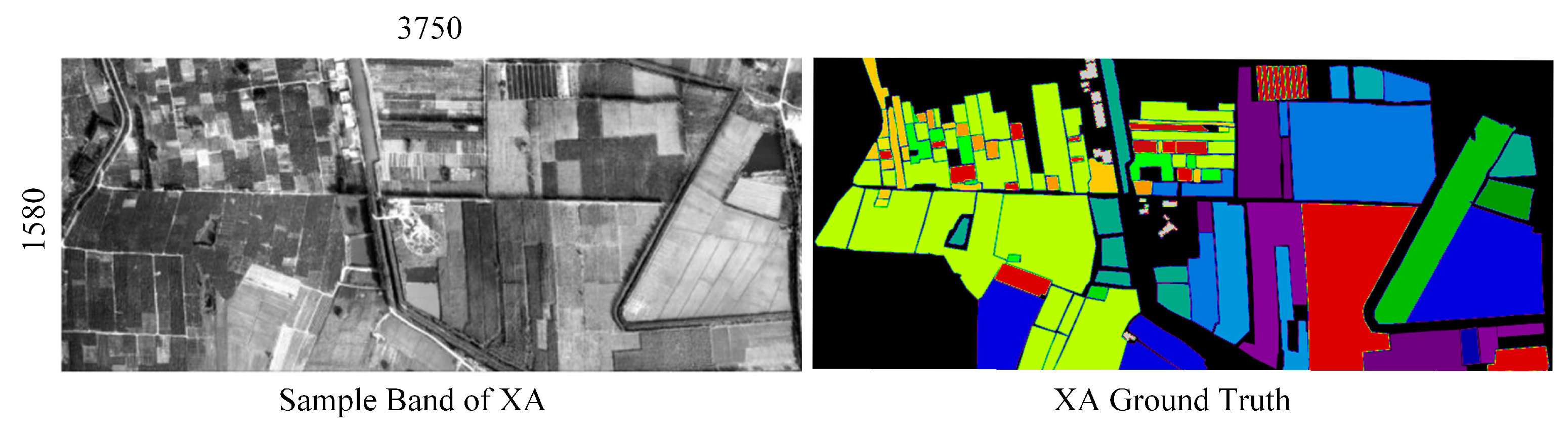
3.1. Dataset Description
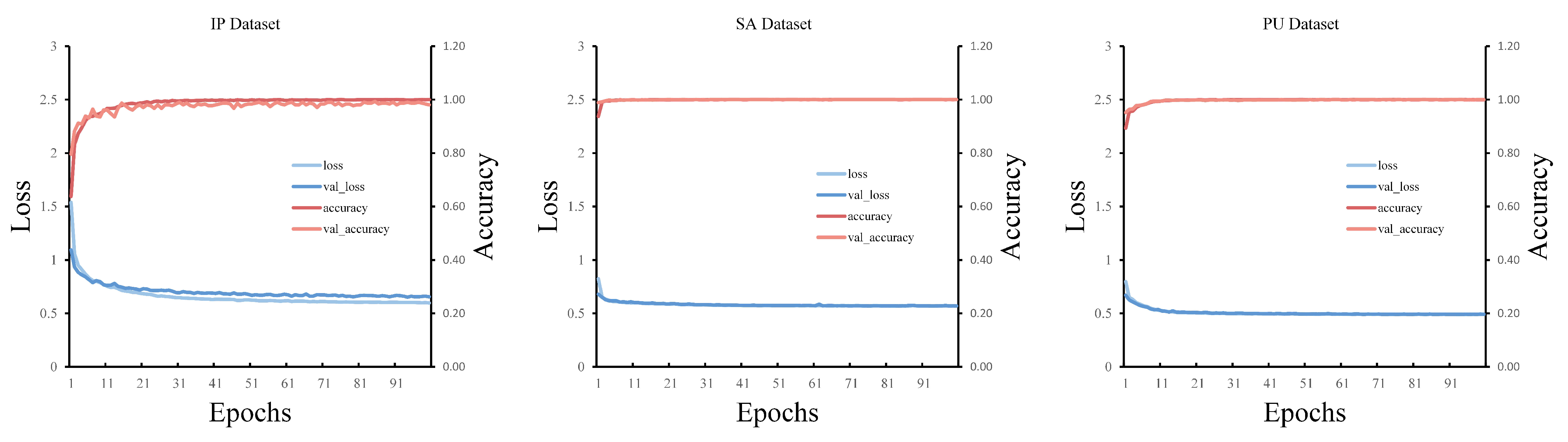
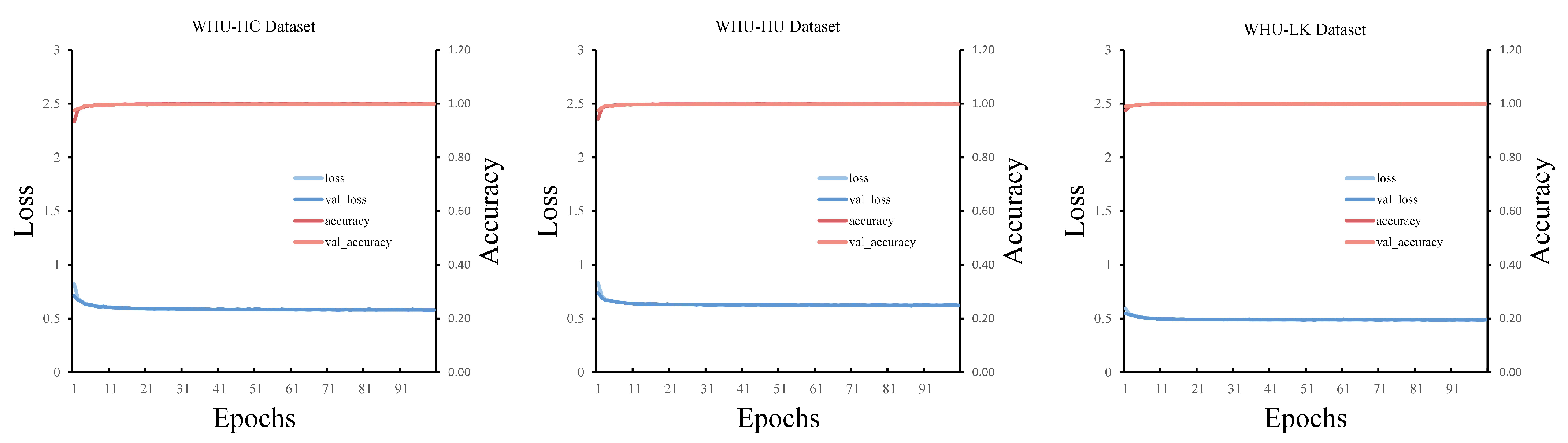
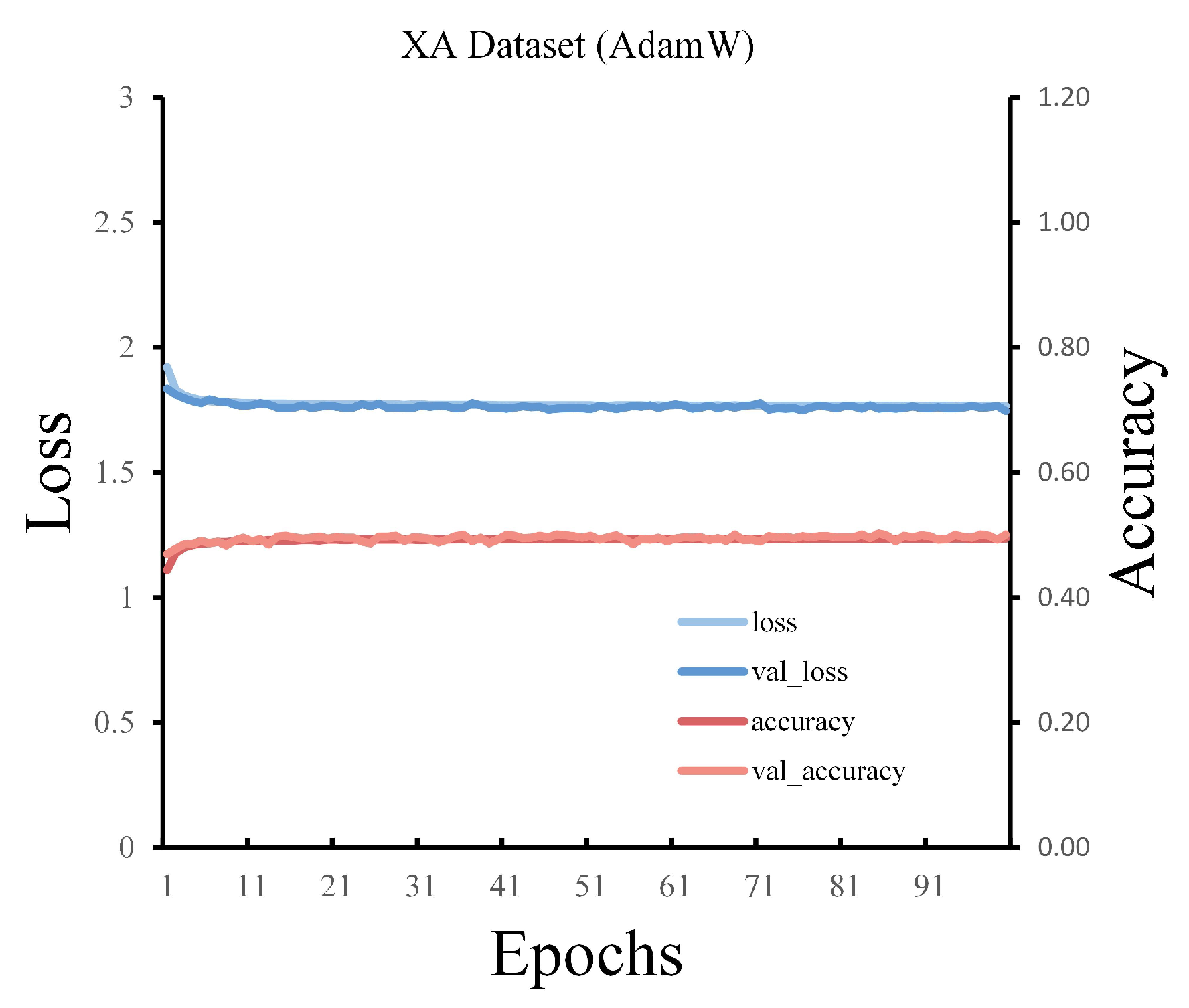
3.2. Training Details and Evaluation Indicators
3.3. Classification Results of Public Hyperspectral Image Datasets
3.4. Classification Results for Each Object Class in All HSI Datasets
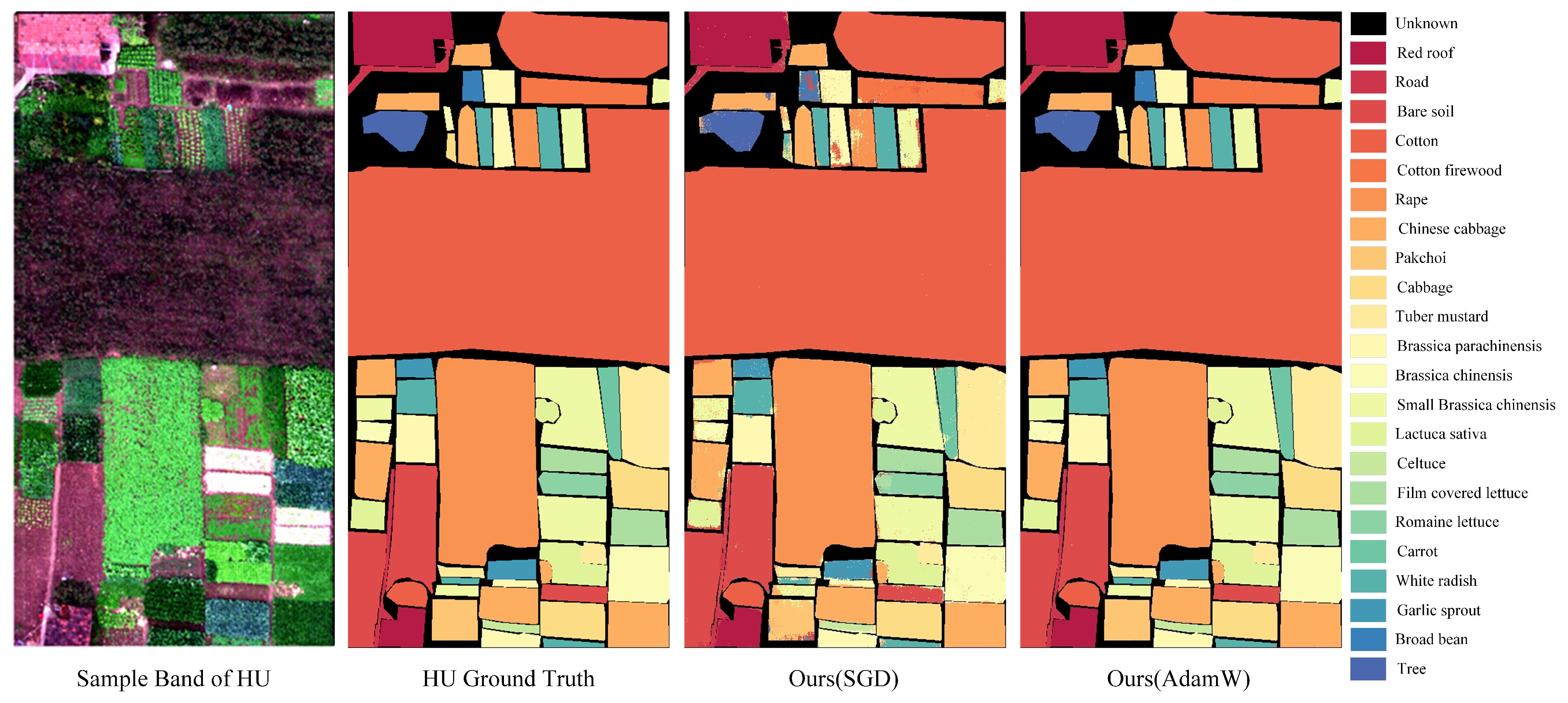
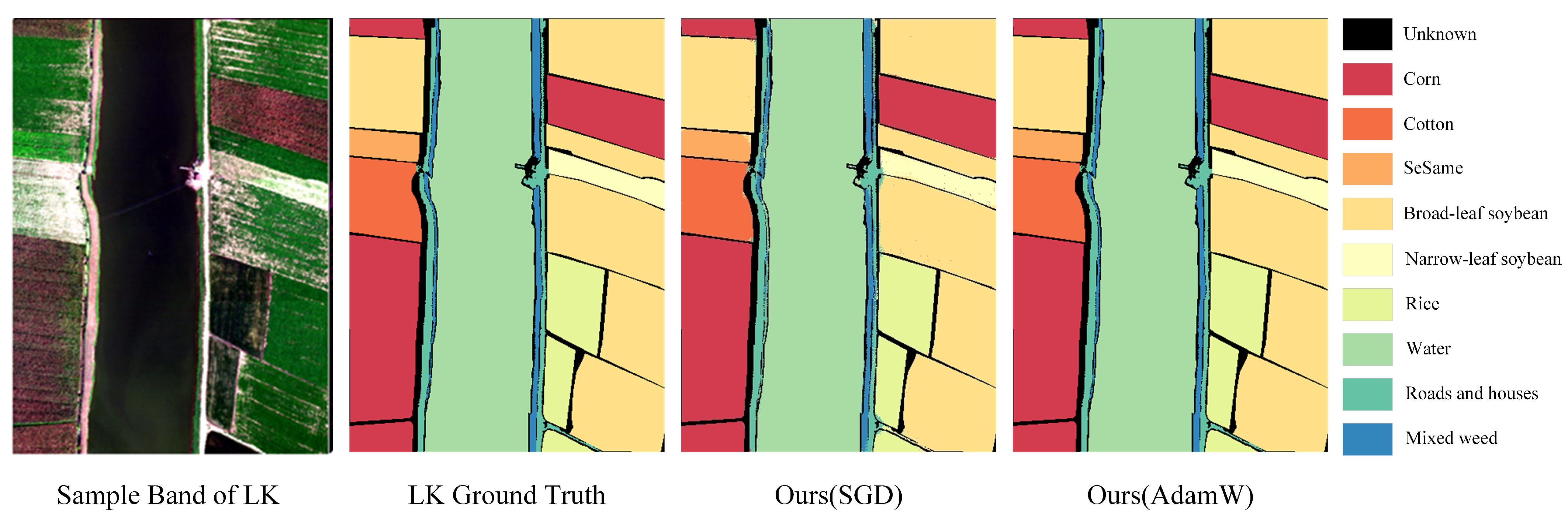
3.5. Classification Maps and Comparisons
3.5.1. Classification Maps of Chinese Dataset: (WHU-HI and XA Datasets)
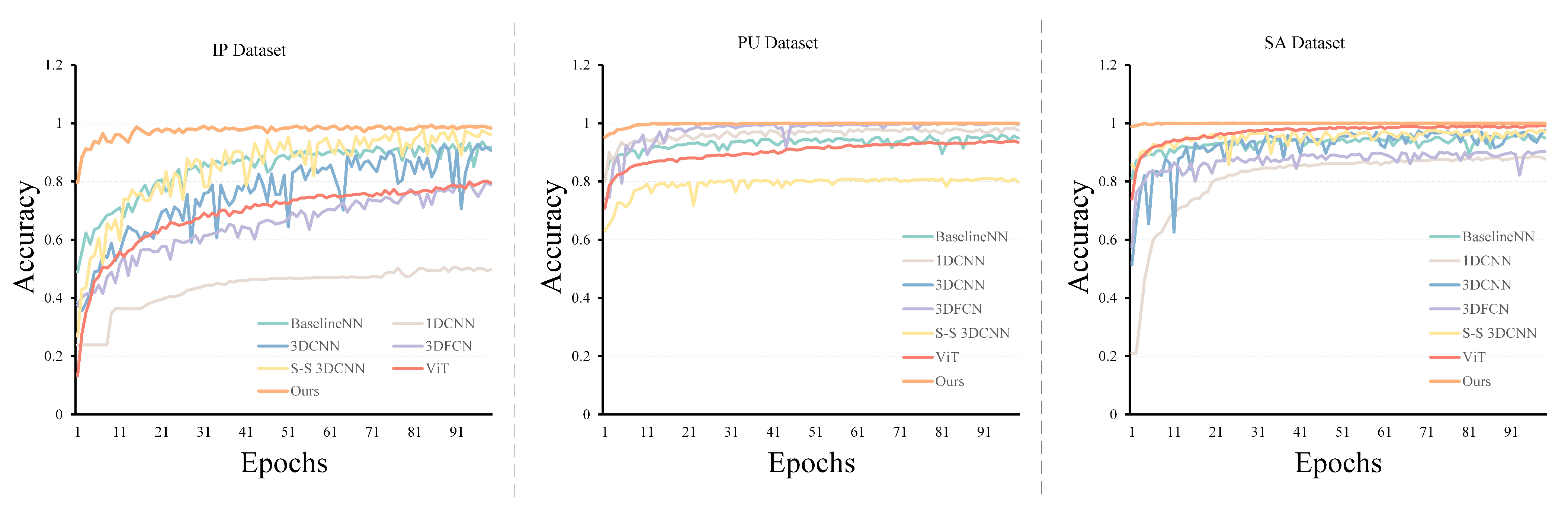
3.5.2. Comparison of Our Proposed Model with Other Models on IP, SA, and PU Hyperspectral Datasets
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HSI | hyperspectral image |
| PCA | principal component analysis |
| ICA | independent component analysis |
| CNN | convolutional neural network |
| FCN | fully convolutional network |
| GCN | graph convolution network |
| MS-CNN | multiscale convolutional neural network |
| Swin | shifted window |
| LN | layer normalization |
| W-MSA | multi-head self-attention |
| MLP | multilayer perceptron |
| IP | Indian pine |
| SA | Salinas |
| PU | University of Pavia |
| UAV | unmanned aerial vehicle |
| WHU-Hi | Wuhan University of Technology (China) - hyperspectral image |
| LK | WHU-Hi-Longkou |
| HC | WHU-Hi-HanChuan |
| HU | WHU-Hi-HongHu |
| XA | XA |
| SGD | stochastic gradient descent |
Appendix A
References
- Teke, M.; Deveci, H.S.; Haliloğlu, O.; Gürbüz, S.Z.; Sakarya, U. A short survey of hyperspectral remote sensing applications in agriculture. In Proceedings of the 2013 6th International Conference on Recent Advances in Space Technologies (RAST), Istanbul, Turkey, 12–14 June 2013; pp. 171–176. [Google Scholar]
- Shafri, H.Z.; Taherzadeh, E.; Mansor, S.; Ashurov, R. Hyperspectral remote sensing of urban areas: An overview of techniques and applications. Res. J. Appl. Sci. Eng. Technol. 2012, 4, 1557–1565. [Google Scholar]
- Bedini, E. The use of hyperspectral remote sensing for mineral exploration: A review. J. Hyperspectral Remote Sens. 2017, 7, 189–211. [Google Scholar] [CrossRef]
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Rodarmel, C.; Shan, J. Principal component analysis for hyperspectral image classification. Surv. Land Inf. Sci. 2002, 62, 115–122. [Google Scholar]
- Du, H.; Qi, H.; Wang, X.; Ramanath, R.; Snyder, W.E. Band selection using independent component analysis for hyperspectral image processing. In Proceedings of the 32nd Applied Imagery Pattern Recognition Workshop, Washington, DC, USA, 15–17 October 2003; pp. 93–98. [Google Scholar]
- Gogineni, R.; Chaturvedi, A. Hyperspectral image classification. Process. Anal. Hyperspectral Data 2019. [Google Scholar] [CrossRef] [Green Version]
- Kuo, B.C.; Yang, J.M.; Sheu, T.W.; Yang, S.W. Kernel-based KNN and Gaussian classifiers for hyperspectral image classification. In Proceedings of the IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; pp. II-1006–II-1008. [Google Scholar] [CrossRef]
- Mercier, G.; Lennon, M. Support vector machines for hyperspectral image classification with spectral-based kernels. In Proceedings of the IGARSS 2003. 2003 IEEE International Geoscience and Remote Sensing Symposium. Proceedings (IEEE Cat. No. 03CH37477), Toulouse, France, 21–25 July 2003; Volume 1, pp. 288–290. [Google Scholar]
- Kuo, B.C.; Ho, H.H.; Li, C.H.; Hung, C.C.; Taur, J.S. A kernel-based feature selection method for SVM with RBF kernel for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 317–326. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Fauvel, M.; Chanussot, J.; Benediktsson, J.A. SVM-and MRF-based method for accurate classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 736–740. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Kwon, H. Going deeper with contextual CNN for hyperspectral image classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2016, 219, 88–98. [Google Scholar] [CrossRef]
- Mei, X.; Pan, E.; Ma, Y.; Dai, X.; Huang, J.; Fan, F.; Du, Q.; Zheng, H.; Ma, J. Spectral-Spatial Attention Networks for Hyperspectral Image Classification. Remote Sens. 2019, 11, 963. [Google Scholar] [CrossRef] [Green Version]
- Mengmeng, Z.; Wei, L.; Qian, D. Diverse region-based CNN for hyperspectral image classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar]
- Wan, S.; Gong, C.; Zhong, P.; Du, B.; Zhang, L.; Yang, J. Multiscale dynamic graph convolutional network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3162–3177. [Google Scholar] [CrossRef] [Green Version]
- Jiao, L.; Liang, M.; Chen, H.; Yang, S.; Liu, H.; Cao, X. Deep fully convolutional network-based spatial distribution prediction for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5585–5599. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W.; Li, S. A CNN with multiscale convolution and diversified metric for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3599–3618. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Bei, Z.; Yanfei, Z.; Liangpei, Z.; Bo, H. The Fisher Kernel Coding Framework for High Spatial Resolution Scene Classification. Remote Sens. 2016, 8, 157. [Google Scholar]
- Zhao, B.; Zhong, Y.; Xia, G.S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2108–2123. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Cen, Y.; Zhang, L.; Zhang, X.; Wang, Y.; Qi, W.; Tang, S.; Zhang, P. Aerial hyperspectral remote sensing classification dataset of Xiongan New Area (Matiwan Village). J. Remote. Sens. 2020, 24, 1299–1306. Available online: https://www.ygxb.ac.cn/en/article/doi/10.11834/jrs.20209065/ (accessed on 1 May 2023).
- Audebert, N.; Le Saux, B.; Lefèvre, S. Deep learning for classification of hyperspectral data: A comparative review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Yu, A.; Xue, Z. A semi-supervised convolutional neural network for hyperspectral image classification. Remote Sens. Lett. 2017, 8, 839–848. [Google Scholar] [CrossRef]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Kwon, H. Contextual deep CNN based hyperspectral classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3322–3325. [Google Scholar]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Ayas, S.; Tunc-Gormus, E. SpectralSWIN: A spectral-Swin Transformer network for hyperspectral image classification. Int. J. Remote Sens. 2022, 43, 4025–4044. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Numbers | Attention Heads | Attention Window | Shifting Window | S-T Block |
|---|---|---|---|---|
| 0 | 88.61% | |||
| 1 | 97.13% | 98.21% | 97.46% | 96.19% |
| 2 | 97.48% | 97.46% | 97.37% | 97.46% |
| 4 | 97.63% | 98.46% | 97.54% | |
| 8 | 97.46% |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Alfalfa | 0.79 | 0.97 | 0.87 | 32 |
| Corn—no-till | 0.97 | 0.95 | 0.96 | 1000 |
| Corn—min-till | 0.97 | 0.98 | 0.98 | 581 |
| Corn | 0.96 | 0.98 | 0.97 | 166 |
| Grass–pasture | 0.95 | 0.96 | 0.95 | 338 |
| Grass–trees | 0.96 | 0.98 | 0.97 | 511 |
| Grass—pasture-mowed | 0.75 | 0.45 | 0.56 | 20 |
| Hay—windrowed | 1.00 | 1.00 | 1.00 | 335 |
| Oats | 1.00 | 0.29 | 0.44 | 14 |
| Soybean—no-till | 0.96 | 0.95 | 0.96 | 680 |
| Soybean—min-till | 0.98 | 0.99 | 0.99 | 1719 |
| Soybean—clean | 0.94 | 0.96 | 0.95 | 415 |
| Wheat | 0.97 | 0.99 | 0.98 | 143 |
| Woods | 1.00 | 1.00 | 1.00 | 886 |
| Buildings–Grass–Trees–Drives | 1.00 | 1.00 | 1.00 | 270 |
| Stone–Steel–Towers | 0.87 | 0.63 | 0.73 | 65 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Broccoli_green_weeds_1 | 1.00 | 1.00 | 1.00 | 1406 |
| Broccoli_green_weeds_2 | 1.00 | 1.00 | 1.00 | 2608 |
| Fallow | 1.00 | 1.00 | 1.00 | 1383 |
| Fallow_rough_plow | 1.00 | 1.00 | 1.00 | 976 |
| Fallow_smooth | 1.00 | 1.00 | 1.00 | 1875 |
| Stubble | 1.00 | 1.00 | 1.00 | 2771 |
| Celery | 1.00 | 1.00 | 1.00 | 2505 |
| Grapes_untrained | 1.00 | 1.00 | 1.00 | 7890 |
| Soil_vineyard_develop | 1.00 | 1.00 | 1.00 | 4342 |
| Corn_senesced_green_weeds | 1.00 | 1.00 | 1.00 | 2295 |
| Lettuce_romaine_4wk | 1.00 | 1.00 | 1.00 | 748 |
| Lettuce_romaine_5wk | 1.00 | 1.00 | 1.00 | 1349 |
| Lettuce_romaine_6wk | 1.00 | 1.00 | 1.00 | 641 |
| Lettuce_romaine_7wk | 1.00 | 1.00 | 1.00 | 749 |
| Vineyard_untrained | 1.00 | 1.00 | 1.00 | 5088 |
| Vineyard_vertical_trellis | 1.00 | 1.00 | 1.00 | 1265 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Asphalt | 1.00 | 1.00 | 1.00 | 4642 |
| Meadows | 1.00 | 1.00 | 1.00 | 13,055 |
| Gravel | 1.00 | 1.00 | 1.00 | 1469 |
| Trees | 1.00 | 1.00 | 1.00 | 2145 |
| Painted metal sheets | 1.00 | 1.00 | 1.00 | 942 |
| Bare Soil | 1.00 | 1.00 | 1.00 | 3520 |
| Bitumen | 1.00 | 1.00 | 1.00 | 931 |
| Self-Blocking Bricks | 1.00 | 1.00 | 1.00 | 2577 |
| Shadows | 1.00 | 1.00 | 1.00 | 663 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Strawberry | 1.00 | 1.00 | 1.00 | 31,315 |
| Cowpea | 1.00 | 1.00 | 1.00 | 15,927 |
| Soybean | 1.00 | 1.00 | 1.00 | 7201 |
| Sorghum | 1.00 | 1.00 | 1.00 | 3747 |
| Water spinach | 1.00 | 1.00 | 1.00 | 840 |
| Watermelon | 1.00 | 0.97 | 0.98 | 3173 |
| Greens | 1.00 | 1.00 | 1.00 | 4132 |
| Trees | 1.00 | 1.00 | 1.00 | 12,585 |
| Grass | 1.00 | 1.00 | 1.00 | 6628 |
| Red roof | 1.00 | 1.00 | 1.00 | 7361 |
| Gray roof | 1.00 | 1.00 | 1.00 | 11,838 |
| Plastic | 1.00 | 1.00 | 1.00 | 2575 |
| Bare soil | 0.99 | 0.99 | 0.99 | 6381 |
| Road | 1.00 | 1.00 | 1.00 | 12,992 |
| Bright object | 1.00 | 1.00 | 1.00 | 795 |
| Water | 1.00 | 1.00 | 1.00 | 52,781 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Red roof | 1.00 | 1.00 | 1.00 | 9829 |
| Road | 1.00 | 0.98 | 0.99 | 2458 |
| Bare soil | 1.00 | 1.00 | 1.00 | 15,275 |
| Cotton | 1.00 | 1.00 | 1.00 | 114,300 |
| Cotton firewood | 1.00 | 1.00 | 1.00 | 4353 |
| Rape | 1.00 | 1.00 | 1.00 | 31,190 |
| Chinese cabbage | 1.00 | 1.00 | 1.00 | 16,872 |
| Pak choi | 1.00 | 1.00 | 1.00 | 2838 |
| Cabbage | 1.00 | 1.00 | 1.00 | 7573 |
| Tuber mustard | 1.00 | 1.00 | 1.00 | 8676 |
| Brassica parachinensis | 1.00 | 1.00 | 1.00 | 7711 |
| Brassica chinensis | 1.00 | 1.00 | 1.00 | 6268 |
| Small Brassica chinensis | 1.00 | 1.00 | 1.00 | 15,755 |
| Lactuca sativa | 0.99 | 1.00 | 1.00 | 5149 |
| Celtuce | 1.00 | 0.99 | 0.99 | 701 |
| Film covered lettuce | 1.00 | 1.00 | 1.00 | 5083 |
| Romaine lettuce | 1.00 | 1.00 | 1.00 | 2107 |
| Carrot | 0.99 | 1.00 | 0.99 | 2252 |
| White radish | 1.00 | 1.00 | 1.00 | 6098 |
| Garlic sprouts | 1.00 | 1.00 | 1.00 | 2440 |
| Broad bean | 1.00 | 0.99 | 1.00 | 930 |
| Tree | 1.00 | 1.00 | 1.00 | 2828 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Corn | 1.00 | 1.00 | 1.00 | 24,158 |
| Cotton | 1.00 | 1.00 | 1.00 | 5862 |
| Sesame | 1.00 | 1.00 | 1.00 | 2122 |
| Broadleaf soybean | 1.00 | 1.00 | 1.00 | 44,248 |
| Narrow-leaf soybean | 1.00 | 1.00 | 1.00 | 2906 |
| Rice | 1.00 | 1.00 | 1.00 | 8298 |
| Water | 1.00 | 1.00 | 1.00 | 46,939 |
| Roads and houses | 0.99 | 0.99 | 0.99 | 4987 |
| Mixed weed | 1.00 | 0.98 | 0.99 | 3660 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| Acer negundo Linn | 0.34 | 0.10 | 0.15 | 157,953 |
| Willow | 0.34 | 0.41 | 0.37 | 126,536 |
| Elm | 0.00 | 0.00 | 0.00 | 10,747 |
| Paddy | 0.47 | 0.52 | 0.49 | 316,501 |
| Chinese Pagoda Tree | 0.39 | 0.47 | 0.43 | 332,914 |
| Fraxinus chinensis | 0.37 | 0.45 | 0.40 | 118,539 |
| Koelreuteria paniculata | 0.00 | 0.00 | 0.00 | 16,313 |
| Water | 0.33 | 0.00 | 0.00 | 115,953 |
| Bare land | 0.00 | 0.00 | 0.00 | 26,886 |
| Paddy stubble | 0.35 | 0.15 | 0.21 | 135,681 |
| Robinia pseudoacacia | 0.00 | 0.00 | 0.00 | 3928 |
| Corn | 0.67 | 0.00 | 0.00 | 41,416 |
| Pear | 0.62 | 0.93 | 0.74 | 718,559 |
| Soya | 0.00 | 0.00 | 0.00 | 5006 |
| Alamo | 0.39 | 0.05 | 0.10 | 63,750 |
| Vegetable field | 0.00 | 0.00 | 0.00 | 20,404 |
| Sparsewood | 0.00 | 0.00 | 0.00 | 1047 |
| Meadow | 0.47 | 0.54 | 0.50 | 295,253 |
| Peach | 0.00 | 0.00 | 0.00 | 45,860 |
| Building | 0.15 | 0.00 | 0.00 | 20,731 |
| Methods | Average Accuracy | Overall Accuracy | Kappa | |
|---|---|---|---|---|
| ML Models | SVM | 0.317 | 0.528 | 0.427 |
| Baseline NN | 0.654 | 0.753 | 0.713 | |
| DL Models | 1D CNN | 0.203 | 0.449 | 0.324 |
| 3D CNN | 0.663 | 0.775 | 0.737 | |
| 3D FCN | 0.545 | 0.702 | 0.658 | |
| S-S 3D CNN | 0.744 | 0.779 | 0.749 | |
| ViT Models | ViT | 0.789 | 0.718 | 0.680 |
| S-S ViT | 0.667 | 0.887 | 0.864 | |
| Ours | 0.880 | 0.972 | 0.969 |
| Methods | Average Accuracy | Overall Accuracy | Kappa | |
|---|---|---|---|---|
| ML Models | SVM | 0.317 | 0.528 | 0.427 |
| Baseline NN | 0.908 | 0.917 | 0.908 | |
| DL Models | 1D CNN | 0.809 | 0.832 | 0.812 |
| 3D CNN | 0.879 | 0.911 | 0.901 | |
| 3D FCN | 0.904 | 0.939 | 0.932 | |
| S-S 3D CNN | 0.908 | 0.947 | 0.941 | |
| ViT Models | ViT | 0.753 | 0.781 | 0.709 |
| S-S ViT | 0.931 | 0.942 | 0.937 | |
| Ours | 0.999 | 0.999 | 0.999 |
| Methods | Average Accuracy | Overall Accuracy | Kappa | |
|---|---|---|---|---|
| ML Models | SVM | 0.635 | 0.834 | 0.771 |
| Baseline NN | 0.852 | 0.961 | 0.948 | |
| DL Models | 1D CNN | 0.585 | 0.781 | 0.696 |
| 3D CNN | 0.857 | 0.954 | 0.939 | |
| 3D FCN | 0.867 | 0.976 | 0.968 | |
| S-S 3D CNN | 0.876 | 0.969 | 0.959 | |
| ViT Models | ViT | 0.769 | 0.802 | 0.701 |
| S-S ViT | 0.836 | 0.927 | 0.908 | |
| Ours | 0.999 | 0.999 | 0.999 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Liu, Y.; Zhang, W.; Tian, Y.; Kong, W. Spectral Swin Transformer Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 3721. https://doi.org/10.3390/rs15153721
Liu B, Liu Y, Zhang W, Tian Y, Kong W. Spectral Swin Transformer Network for Hyperspectral Image Classification. Remote Sensing. 2023; 15(15):3721. https://doi.org/10.3390/rs15153721
Chicago/Turabian StyleLiu, Baisen, Yuanjia Liu, Wulin Zhang, Yiran Tian, and Weili Kong. 2023. "Spectral Swin Transformer Network for Hyperspectral Image Classification" Remote Sensing 15, no. 15: 3721. https://doi.org/10.3390/rs15153721