Figure 1.
GPR data formats and images. The top image represents the data format of the GPR reflections, where the x-axis represents the vehicle travel direction (along-track), the y-axis represents the radar channel dimension direction (cross-track), and the t-axis represents the time (depth) dimension of the radar’s downward data acquisition. The image at the bottom is the waveform or image representation of the data collected by GPR in each dimension. From left to right are the A-scan, B-scan, C-scan, D-scan, and 3D data.
Figure 1.
GPR data formats and images. The top image represents the data format of the GPR reflections, where the x-axis represents the vehicle travel direction (along-track), the y-axis represents the radar channel dimension direction (cross-track), and the t-axis represents the time (depth) dimension of the radar’s downward data acquisition. The image at the bottom is the waveform or image representation of the data collected by GPR in each dimension. From left to right are the A-scan, B-scan, C-scan, D-scan, and 3D data.
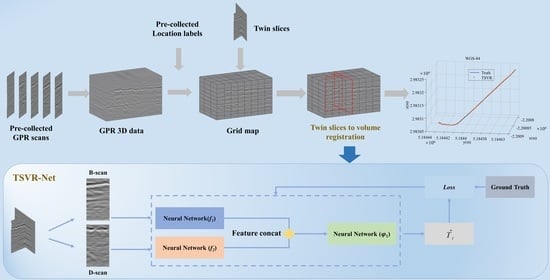
Figure 2.
LGPR localization process. The process is mainly divided into map creation in the solid box and real-time localization in the dashed box. Firstly, the pre-collected data and location labels are interpolated to the grid to obtain the map data with GPR data and location labels. Then, the current scanned image is registered to the grid map, and the corresponding localization label of the image marked by the red box is obtained through registration.
Figure 2.
LGPR localization process. The process is mainly divided into map creation in the solid box and real-time localization in the dashed box. Firstly, the pre-collected data and location labels are interpolated to the grid to obtain the map data with GPR data and location labels. Then, the current scanned image is registered to the grid map, and the corresponding localization label of the image marked by the red box is obtained through registration.
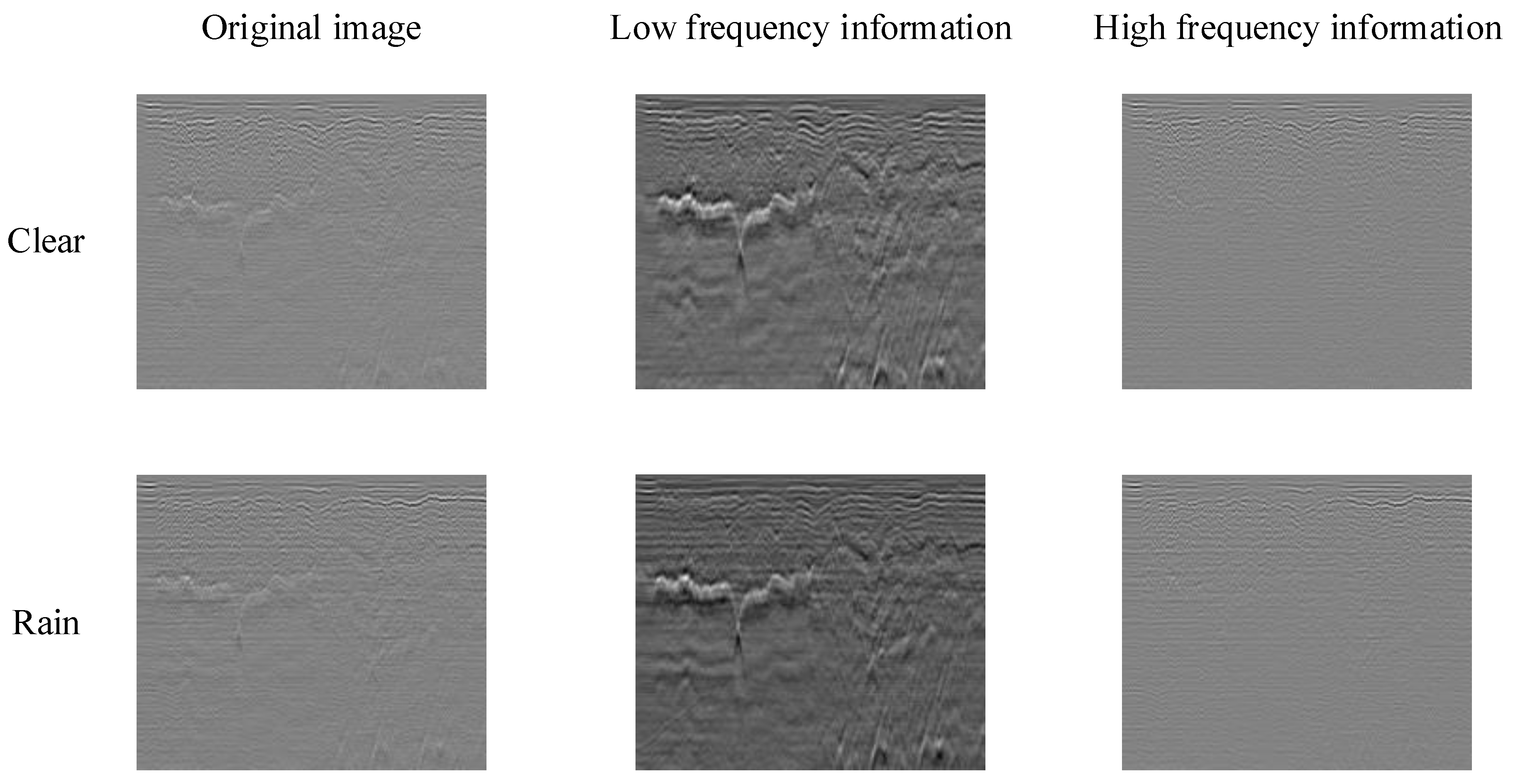
Figure 3.
GPR image correlation in clear and rainy weather. The first and second rows show the analysis of the GPR images obtained from scanning the same road section on clear and rainy days, respectively. The left side is the raw image scanned, the middle is the low-frequency image, and the right is the high-frequency image.
Figure 3.
GPR image correlation in clear and rainy weather. The first and second rows show the analysis of the GPR images obtained from scanning the same road section on clear and rainy days, respectively. The left side is the raw image scanned, the middle is the low-frequency image, and the right is the high-frequency image.
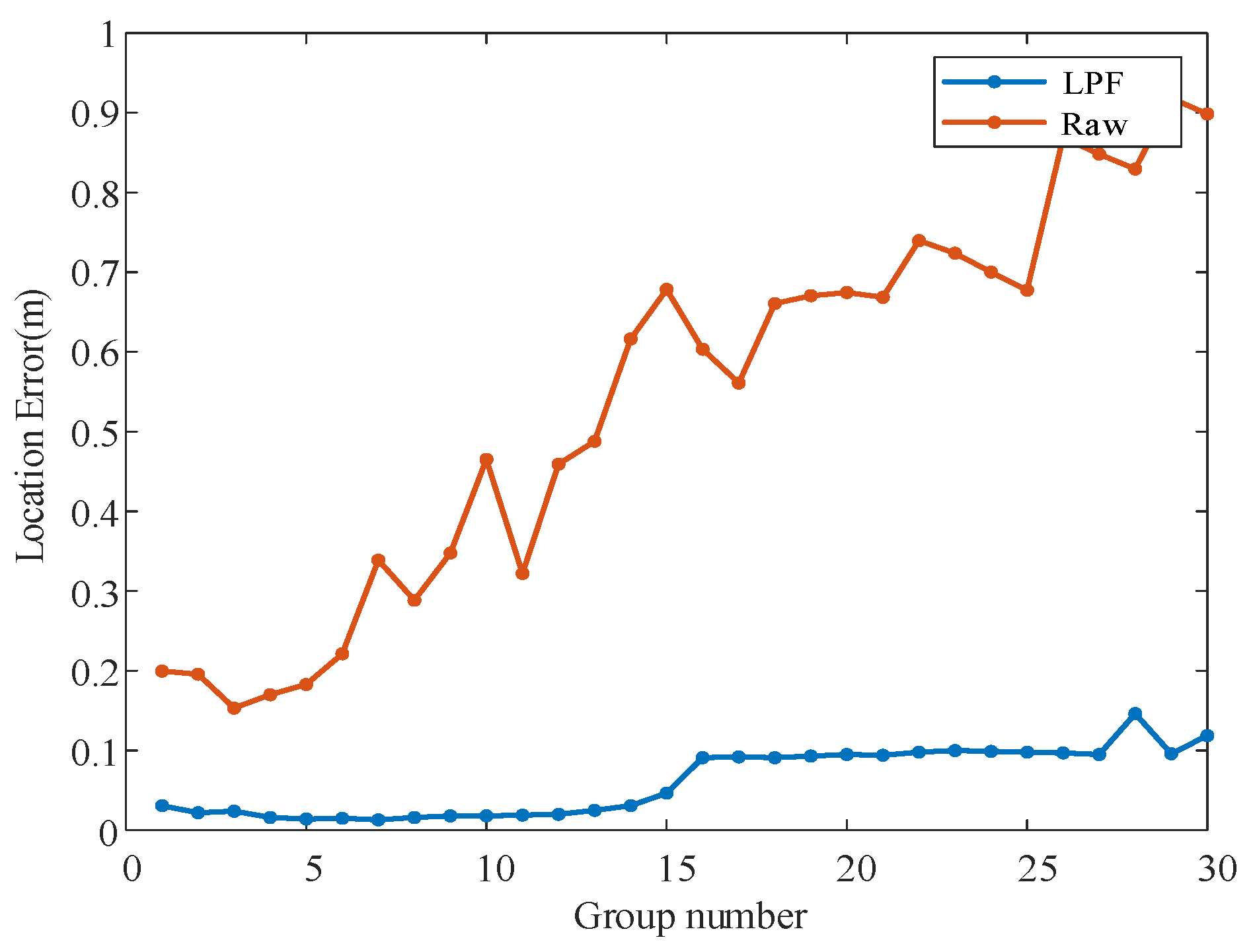
Figure 4.
Comparison of baseline localization errors between low-frequency and raw images. The line graph plots the error obtained by comparing the registration localization with the actual localization for 30 sets of data using the baseline. The blue line in the figure indicates the localization error of the low-frequency image registration, and the red line indicates the localization error of the raw image registration.
Figure 4.
Comparison of baseline localization errors between low-frequency and raw images. The line graph plots the error obtained by comparing the registration localization with the actual localization for 30 sets of data using the baseline. The blue line in the figure indicates the localization error of the low-frequency image registration, and the red line indicates the localization error of the raw image registration.
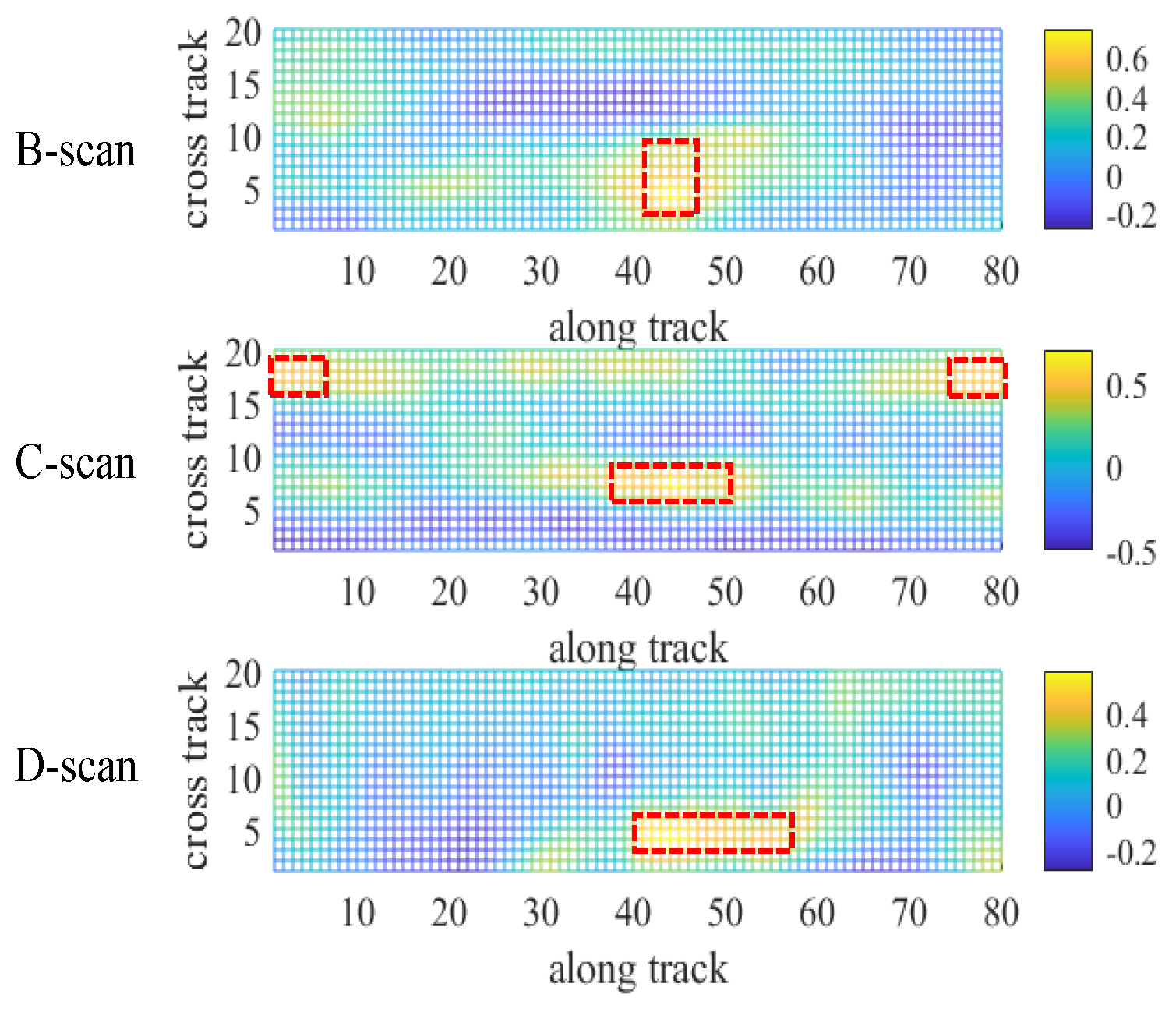
Figure 5.
Correlation surface analysis of the sliced data in different dimensions. From top to bottom are the correlation surface results for the B-scan, C-scan, and D-scan on the volume at the location (45, 4, 0) of the volume data, respectively. The bright yellow colour in the image indicates a correlation of 1, and the dark blue colour indicates a correlation of −1, where the red box area is the correlation peak area.
Figure 5.
Correlation surface analysis of the sliced data in different dimensions. From top to bottom are the correlation surface results for the B-scan, C-scan, and D-scan on the volume at the location (45, 4, 0) of the volume data, respectively. The bright yellow colour in the image indicates a correlation of 1, and the dark blue colour indicates a correlation of −1, where the red box area is the correlation peak area.
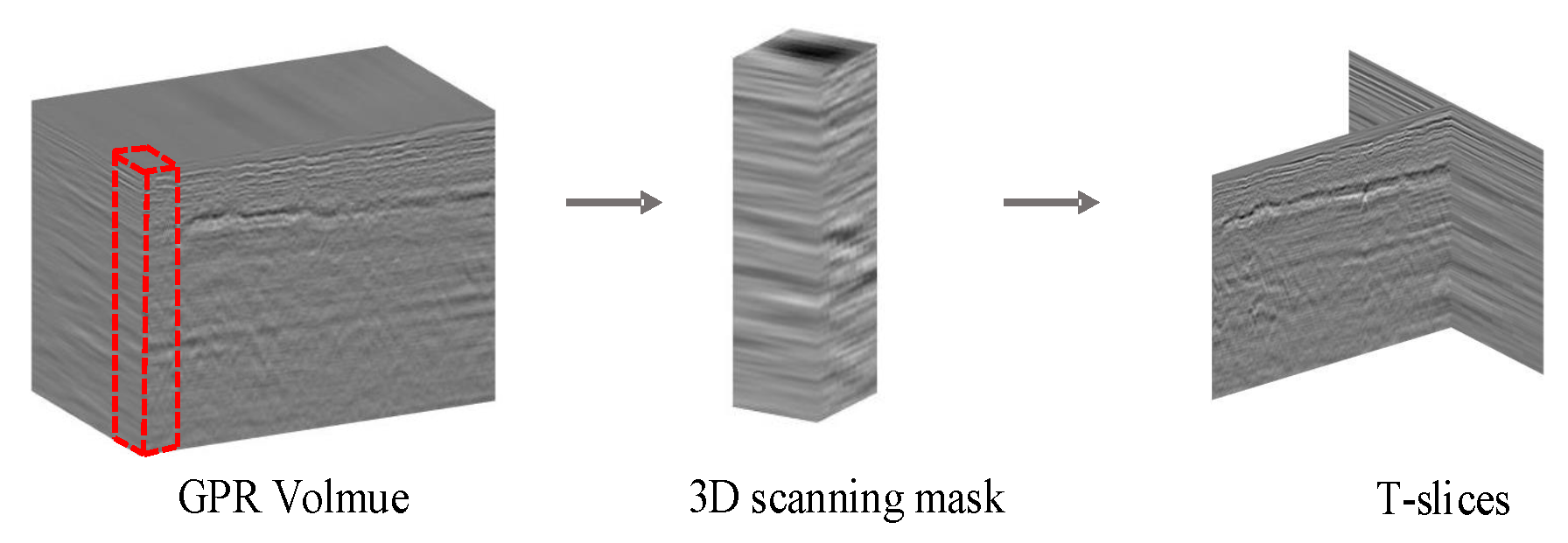
Figure 6.
T-slices production process.
Figure 6.
T-slices production process.
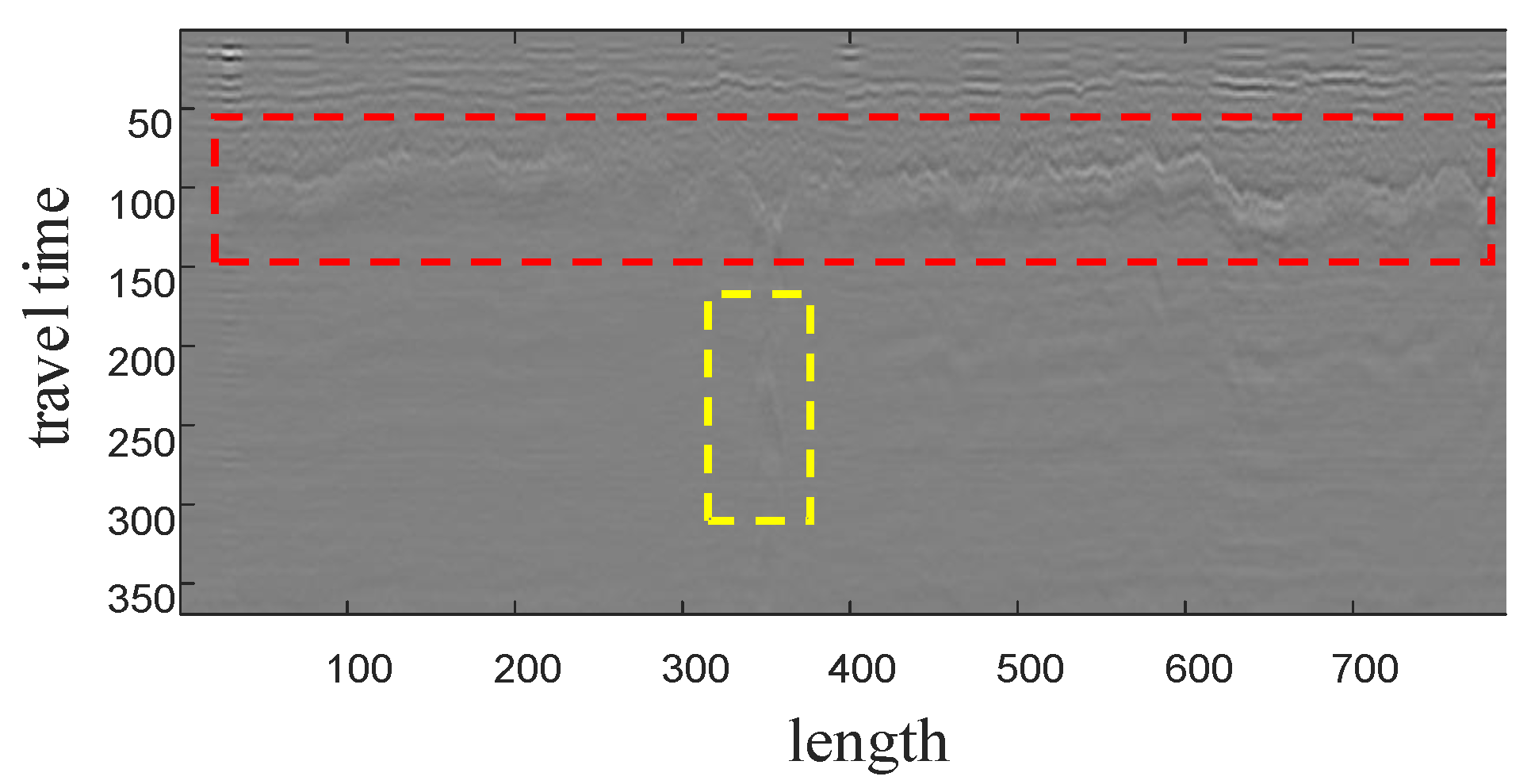
Figure 7.
Typical GPR image. The red box region in the image has a clear black-white layering, demonstrating the layered characteristics of the GPR image, caused by the different dielectric constants of different geological layers. The yellow box region in the image demonstrates the hyperbolic feature of the subsurface target reacting to the image.
Figure 7.
Typical GPR image. The red box region in the image has a clear black-white layering, demonstrating the layered characteristics of the GPR image, caused by the different dielectric constants of different geological layers. The yellow box region in the image demonstrates the hyperbolic feature of the subsurface target reacting to the image.
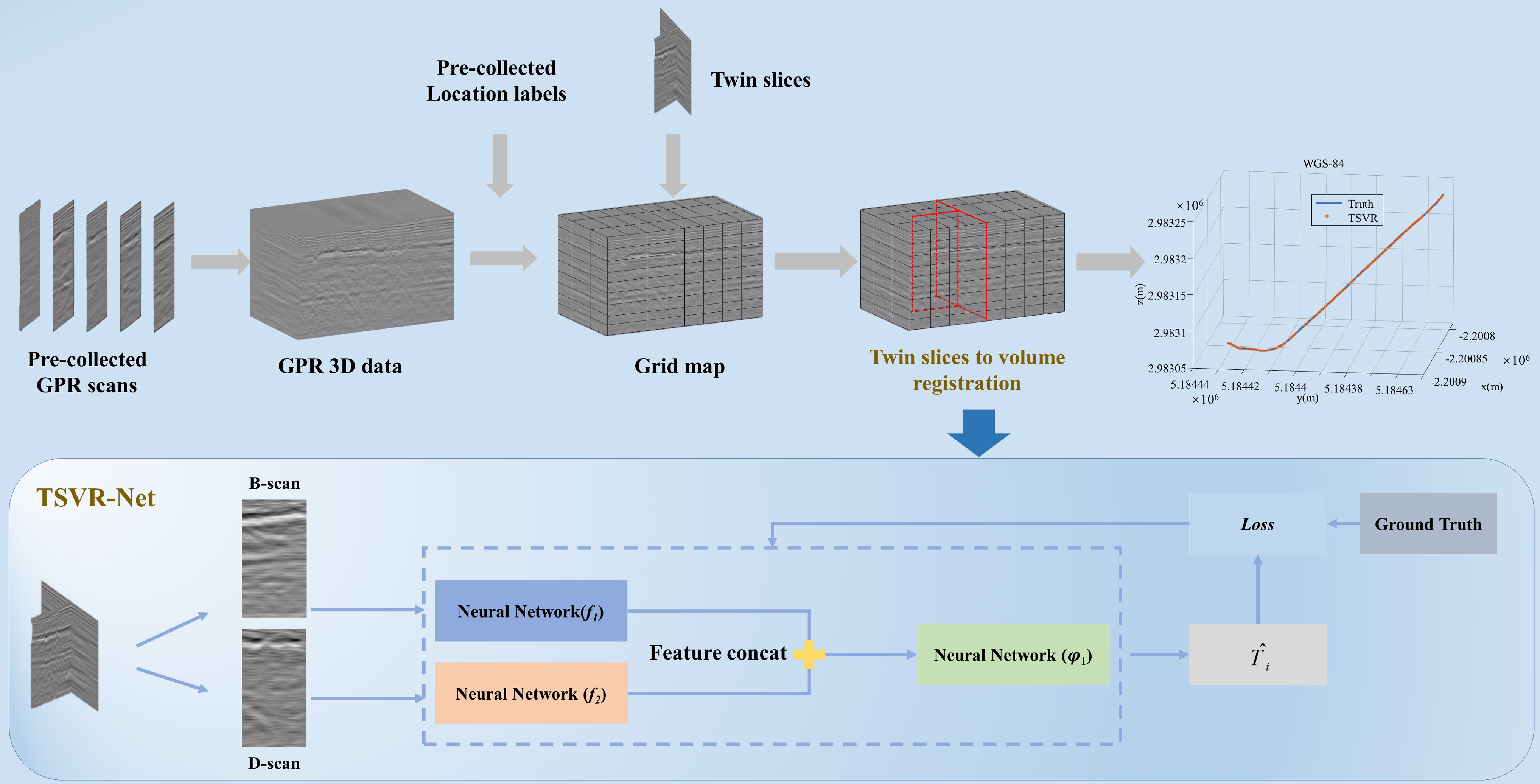
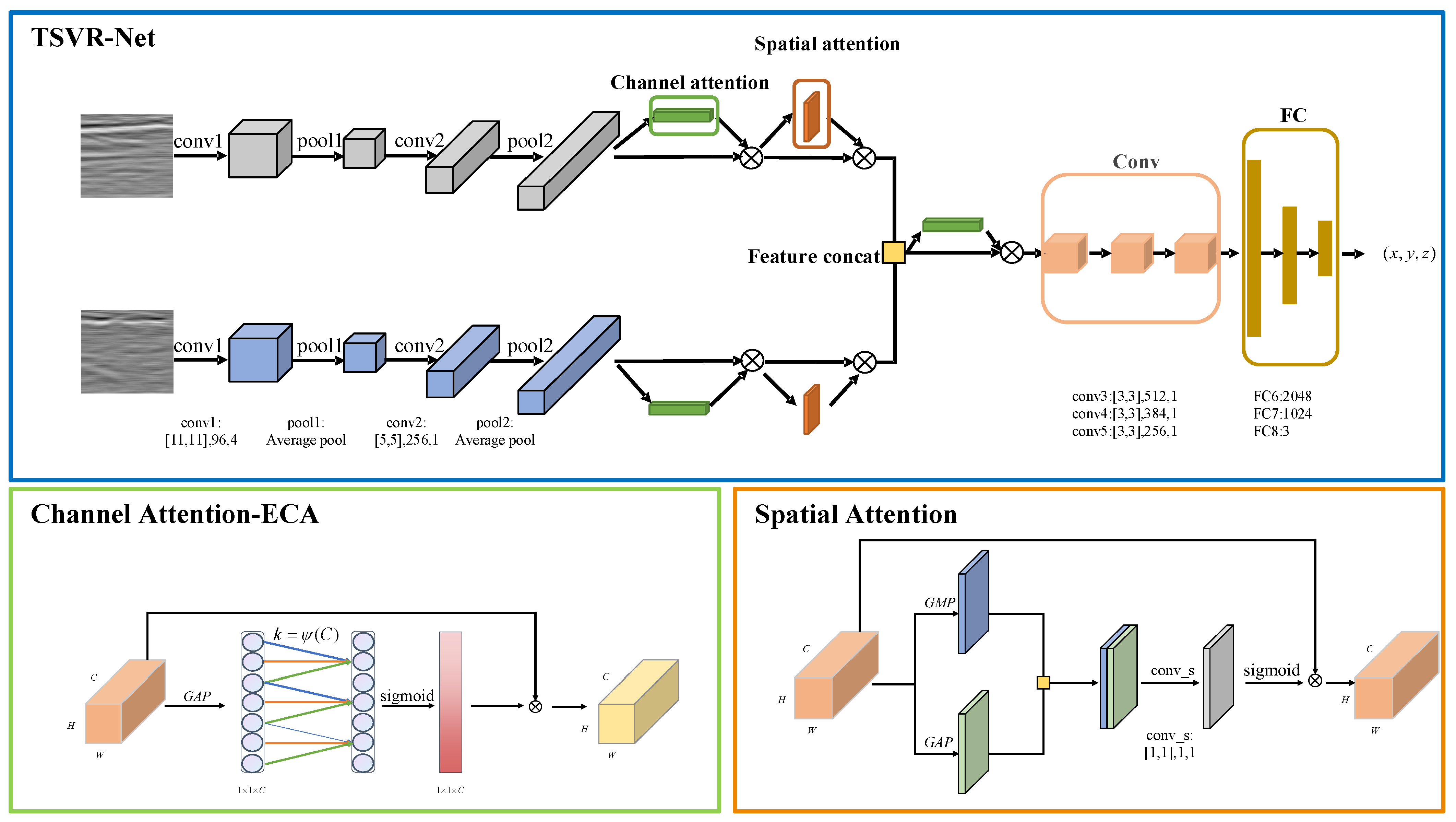
Figure 8.
The architecture of our network and attention modules. The blue box shows the architecture of our network. The green box is the channel attention module (using ECA). The orange box is the spatial attention module. The convolutional layer configuration is denoted as: kernel size, number of channels, and stride. GAP denotes global average pooling. GMP denotes global max pooling. The symbol indicates matrix multiplication. Feature concatenation is fusion of all the channel dimensions.
Figure 8.
The architecture of our network and attention modules. The blue box shows the architecture of our network. The green box is the channel attention module (using ECA). The orange box is the spatial attention module. The convolutional layer configuration is denoted as: kernel size, number of channels, and stride. GAP denotes global average pooling. GMP denotes global max pooling. The symbol indicates matrix multiplication. Feature concatenation is fusion of all the channel dimensions.
Figure 9.
GPR data acquisition equipment.
Figure 9.
GPR data acquisition equipment.
Figure 10.
Actual measurement data recording section schematic. Among them, the red, yellow, and blue boxes represent asphalt, masonry, and cement road sections, respectively.
Figure 10.
Actual measurement data recording section schematic. Among them, the red, yellow, and blue boxes represent asphalt, masonry, and cement road sections, respectively.
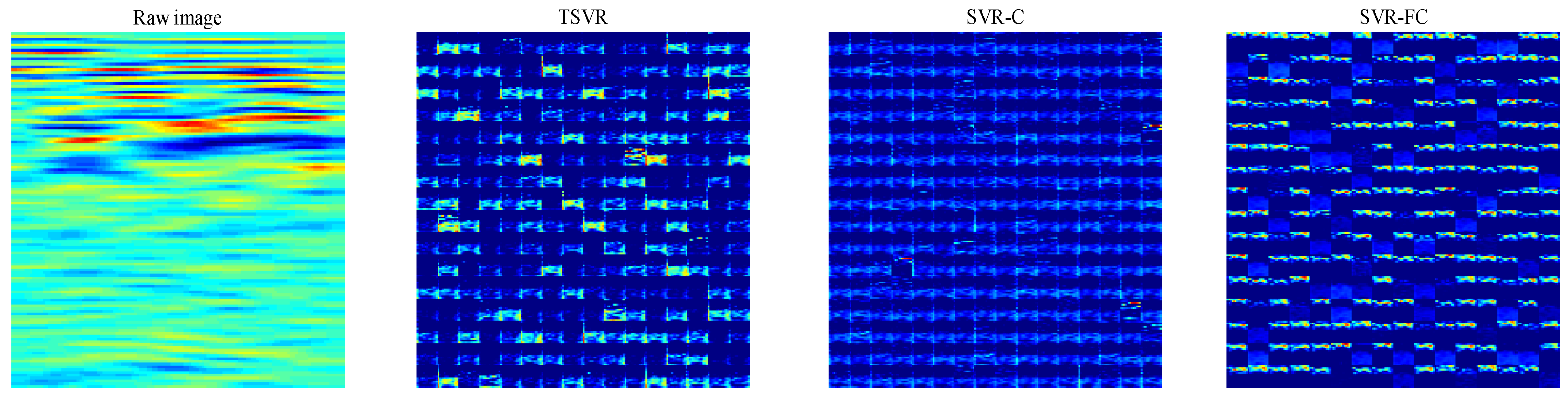
Figure 11.
Feature map visualization of the input conv3 layer. The left-most image is the input D-scan image. The following three images are the feature map collections of TSVR, SVR-C, and SVR-FC networks, respectively. Each feature map collection is obtained by arranging 256 feature maps in a 16 × 16 format.
Figure 11.
Feature map visualization of the input conv3 layer. The left-most image is the input D-scan image. The following three images are the feature map collections of TSVR, SVR-C, and SVR-FC networks, respectively. Each feature map collection is obtained by arranging 256 feature maps in a 16 × 16 format.
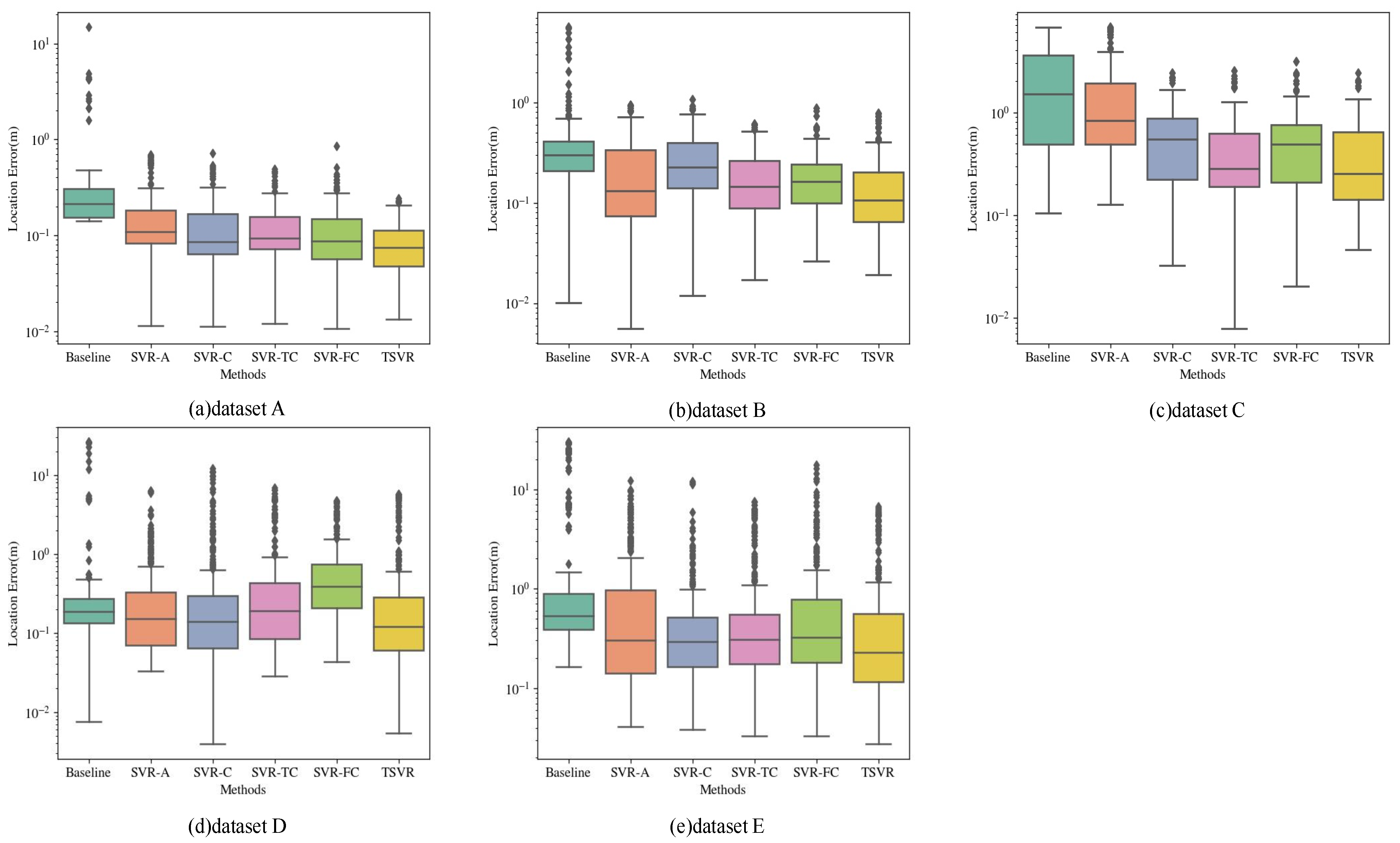
Figure 12.
Comparison of the localization errors under different localization methods. The results of comparing the localization errors of different methods on five datasets are shown in the figure. Each boxplot shows the six methods, baseline, SVR-A, SVR-C, SVR-TC, SVR-FC, and TSVR, from left to right. The statistical results for each method contain a median value line, a coloured box, upper and lower boundary horizontal lines, and several diamond-shaped discrete points. The horizontal line in the coloured box indicates the median value of the localization error. The upper and lower boundaries of the box indicate the 25th and 75th percentile, respectively, and the upper and lower black boundary transversals indicate the maximum and minimum errors after removing the discrete values, respectively. A cross-sectional comparison of each boxplot demonstrates the localization performance of different methods.
Figure 12.
Comparison of the localization errors under different localization methods. The results of comparing the localization errors of different methods on five datasets are shown in the figure. Each boxplot shows the six methods, baseline, SVR-A, SVR-C, SVR-TC, SVR-FC, and TSVR, from left to right. The statistical results for each method contain a median value line, a coloured box, upper and lower boundary horizontal lines, and several diamond-shaped discrete points. The horizontal line in the coloured box indicates the median value of the localization error. The upper and lower boundaries of the box indicate the 25th and 75th percentile, respectively, and the upper and lower black boundary transversals indicate the maximum and minimum errors after removing the discrete values, respectively. A cross-sectional comparison of each boxplot demonstrates the localization performance of different methods.
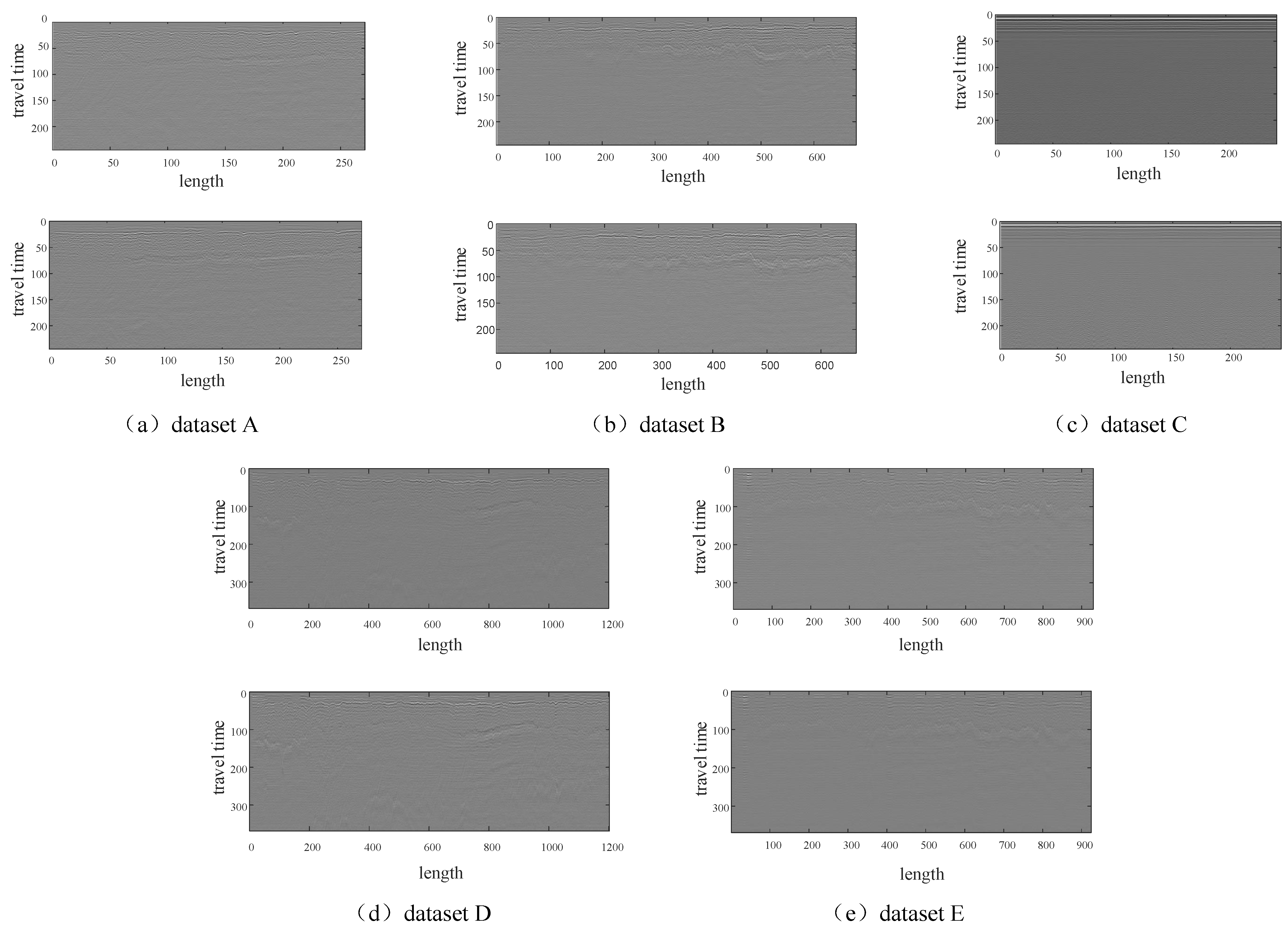
Figure 13.
B-scan images of the dataset. The two images of each dataset are the B-scan images of one channel extracted from the GPR data acquired at two different times. Among them, the volume data corresponding to the left image is used as the pre-collected map data, and the right image is used as the sliced data collected in real-time.
Figure 13.
B-scan images of the dataset. The two images of each dataset are the B-scan images of one channel extracted from the GPR data acquired at two different times. Among them, the volume data corresponding to the left image is used as the pre-collected map data, and the right image is used as the sliced data collected in real-time.
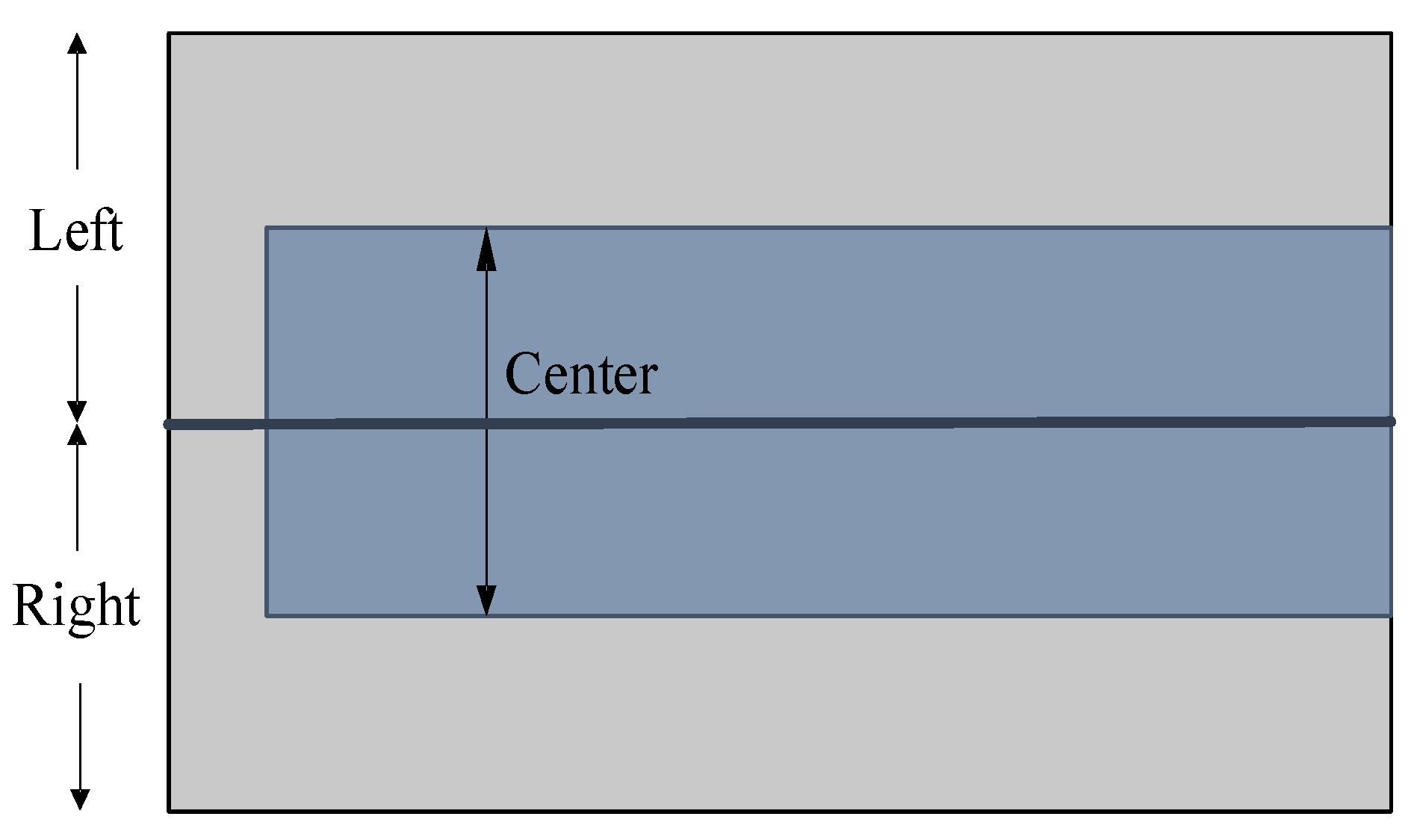
Figure 14.
Multi-lane mapping. (1) Left, (2) right and (3) centre. The left and right can be used to create a consistent map.
Figure 14.
Multi-lane mapping. (1) Left, (2) right and (3) centre. The left and right can be used to create a consistent map.
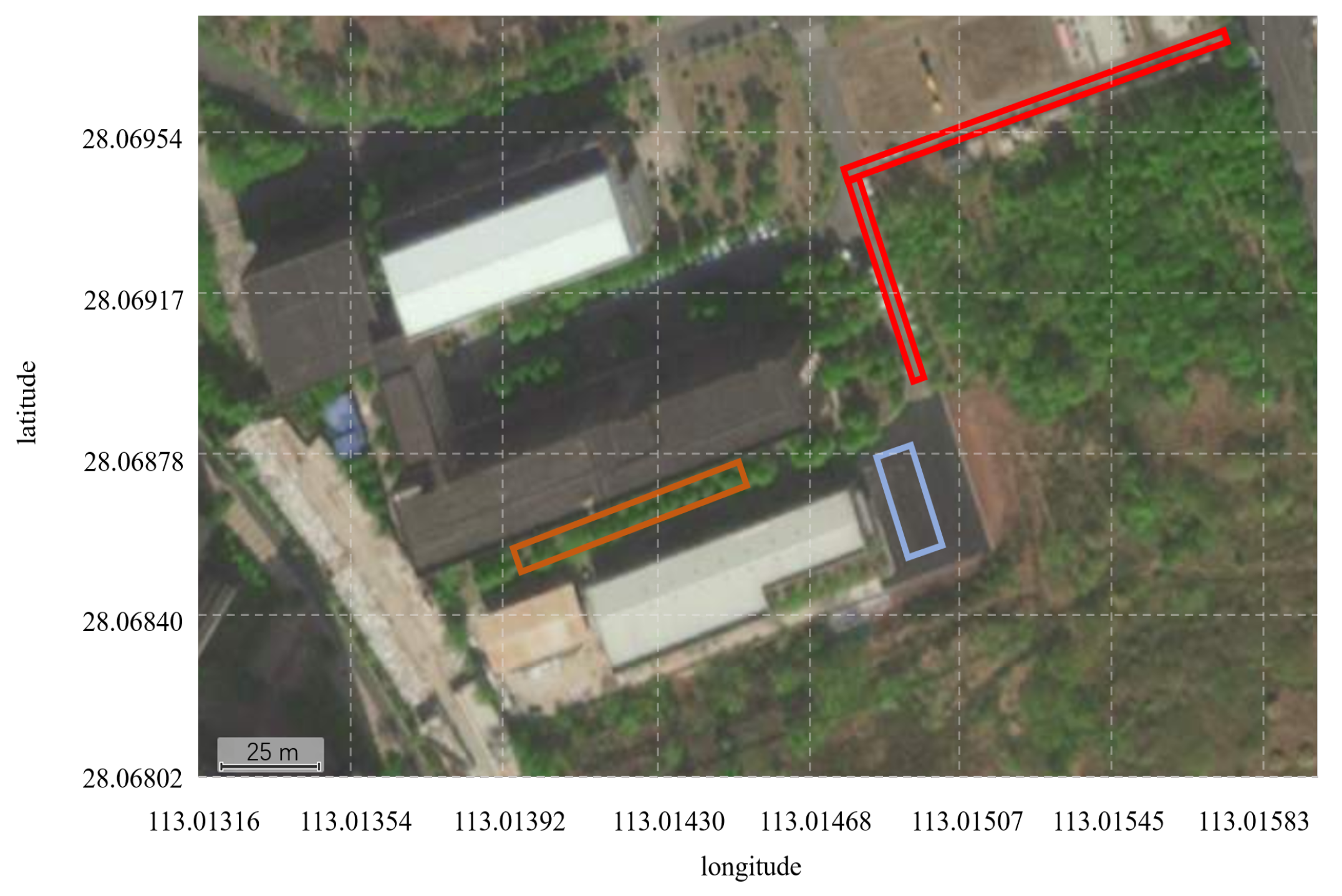
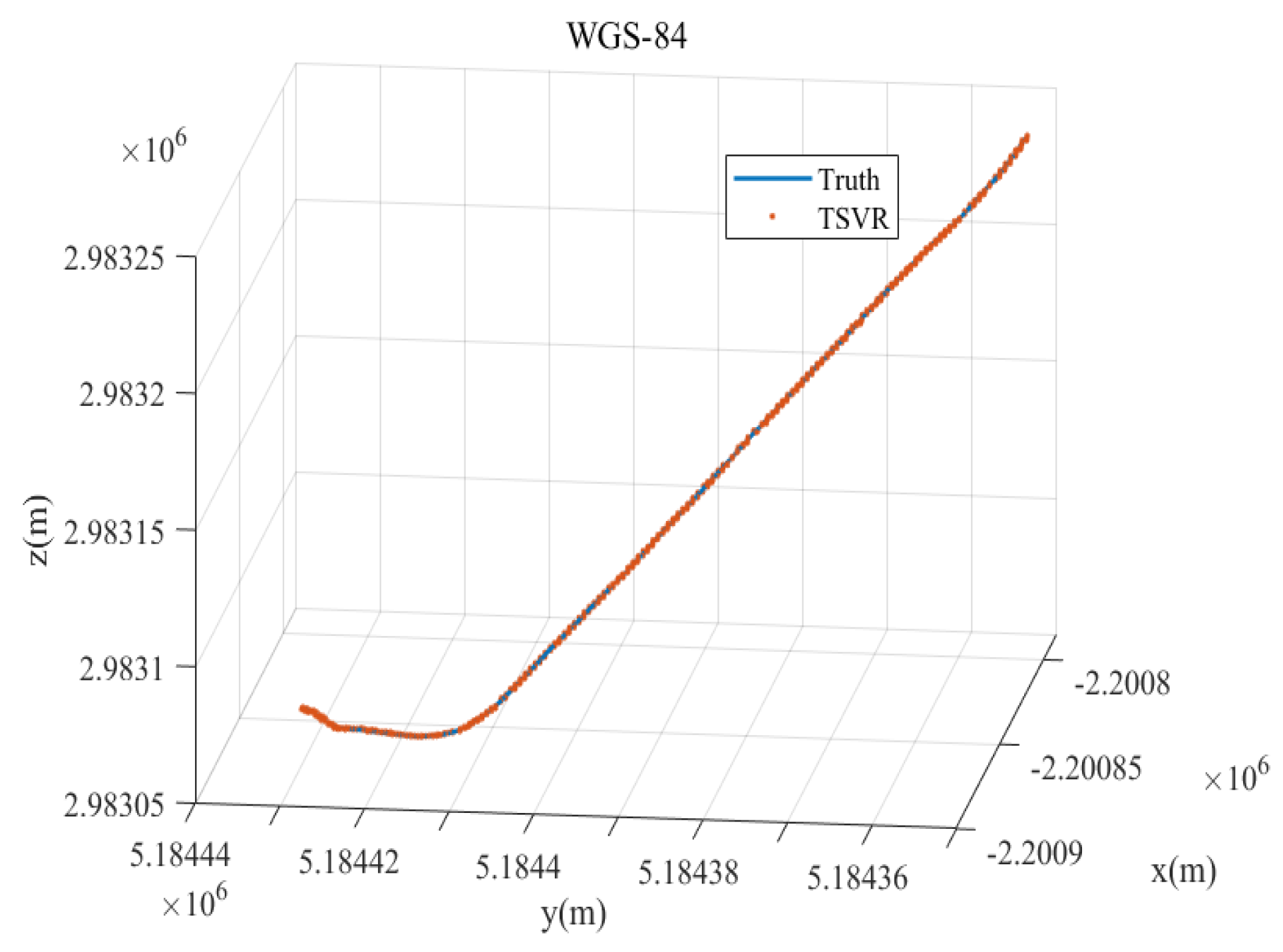
Figure 15.
Localization track of the TSVR method in the WGS-84 coordinate system.
Figure 15.
Localization track of the TSVR method in the WGS-84 coordinate system.
Table 1.
GPR image frequency band correlation calculation.
Table 1.
GPR image frequency band correlation calculation.
| | Raw Images | Low-Frequency Images | High-Frequency Image |
|---|
| Correlation | 0.4460 | 0.6897 | 0.4211 |
Table 2.
GPR system parameters.
Table 2.
GPR system parameters.
| Parameters | Parameter Values |
|---|
| Radar type | Stepped frequency continuous wave |
| Frequency bandwidth | 2.8 GHz (200–3000 MHz) |
| Array dimensions | 1845 mm × 795 mm × 150 mm |
| Number of channels (number of pairs of elements) | 20 |
| Elements spacing | 75 mm |
| Polarization mode | Linear (scanning direction) |
| Sampling interval | 0.07 m |
| Detection depth | 2–3 m |
| Vehicle platform travel speed | 10 km/h |
Table 3.
Method descriptions.
Table 3.
Method descriptions.
| Methods | Similarity Measures | Optimizer |
|---|
| Baseline | NCC | PSO |
|---|
| | Average Pooling | Input Image | Input Format | Feature Concatenation | Attention |
| SVR-A | ✔ | B-scan | [227, 227, 1] | | |
| SVR-C | ✔ | D-scan | [227, 227, 1] | | |
| SVR-TC | ✔ | B-scan, D-scan | [227, 227, 2] | | |
| SVR-FC | ✔ | B-scan, D-scan | [227, 227, 1] [227, 227, 1] | ✔ | |
| TSVR | ✔ | B-scan, D-scan | [227, 227, 1] [227, 227, 1] | ✔ | ✔ |
Table 4.
Data description.
Table 4.
Data description.
| Road Type | Weather | Lane | Route_id | Length |
|---|
| Asphalt | Clear | Left, centre, right | 1 | 180 m |
| Asphalt | Rain | Center | 1 | 180 m |
| Masonry | Clear | Left, centre, right | 2 | 60 m |
| Masonry | Rain | Center | 2 | 60 m |
| Cement | Clear | Left, centre, right | 3 | 20 m |
Table 5.
Information entropy.
Table 5.
Information entropy.
| | Asphalt (Clear) | Asphalt (Rain) | Masonry (Clear) | Masonry (Rain) | Cement (Clear) |
|---|
| entropy | 6.0909 | 6.0816 | 5.7603 | 4.8716 | 4.2013 |
Table 6.
Metrics of the different methods under dataset A.
Table 6.
Metrics of the different methods under dataset A.
| Methods | Error Median (m) | Error Var () |
|---|
| Baseline | 0.2134 | 1.4429 |
| SVR-A | 0.1089 | 0.1699 |
| SVR-C | 0.0855 | 0.1246 |
| SVR-TC | 0.0938 | 0.0921 |
| SVR-FC | 0.0871 | 0.1134 |
| TSVR | 0.0745 | 0.0506 |
Table 7.
Metrics of the different methods under dataset B.
Table 7.
Metrics of the different methods under dataset B.
| Methods | Error Median (m) | Error Var () |
|---|
| Baseline | 0.3009 | 0.9654 |
| SVR-A | 0.1326 | 0.2345 |
| SVR-C | 0.2248 | 0.2190 |
| SVR-TC | 0.1456 | 0.1410 |
| SVR-FC | 0.1617 | 0.1415 |
| TSVR | 0.1059 | 0.1686 |
Table 8.
Metrics of the different methods under dataset C.
Table 8.
Metrics of the different methods under dataset C.
| Methods | Error Median (m) | Error Var () |
|---|
| Baseline | 1.5166 | 2.0620 |
| SVR-A | 0.8275 | 1.7316 |
| SVR-C | 0.5448 | 0.5439 |
| SVR-TC | 0.2848 | 0.5112 |
| SVR-FC | 0.4882 | 0.5631 |
| TSVR | 0.2528 | 0.4797 |
Table 9.
Metrics of the different methods under dataset D.
Table 9.
Metrics of the different methods under dataset D.
| Methods | Error Median (m) | Error Var () |
|---|
| Baseline | 0.1870 | 3.1185 |
| SVR-A | 0.1510 | 0.6568 |
| SVR-C | 0.1373 | 1.5713 |
| SVR-TC | 0.1884 | 1.0519 |
| SVR-FC | 0.3838 | 0.7729 |
| TSVR | 0.1207 | 1.0784 |
Table 10.
Metrics of the different methods under dataset E.
Table 10.
Metrics of the different methods under dataset E.
| Methods | Error Median (m) | Error Var () |
|---|
| Baseline | 0.5278 | 6.7629 |
| SVR-A | 0.3031 | 1.9535 |
| SVR-C | 0.2922 | 1.1548 |
| SVR-TC | 0.3073 | 1.4566 |
| SVR-FC | 0.3235 | 2.0670 |
| TSVR | 0.2268 | 1.2289 |
Table 11.
Running time comparisons in CPU.
Table 11.
Running time comparisons in CPU.
| Methods | Time (per/s) |
|---|
| Baseline | 2.0955 |
| SVR-A | 0.0230 |
| SVR-C | 0.0234 |
| SVR-TC | 0.0244 |
| SVR-FC | 0.0298 |
| TSVR | 0.0273 |



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}