Author Contributions
Conceptualization, X.B., X.F. and Y.Y.; methodology, X.Y.; software, X.B., X.F. and Y.Y.; validation, X.B., X.F. and Y.Y.; formal analysis, X.B., X.F. and Y.Y.; investigation, X.B. and X.F.; data curation, X.B., X.F., Y.Y., M.Y. and X.W.; writing—original draft preparation, X.B., X.F. and Y.Y.; writing—review and editing, X.Y.; visualization, X.B. and X.F.; supervision, X.Y. and M.Y.; project administration, X.Y.; funding acquisition, X.Y. All authors have read and agreed to the published version of the manuscript.
Figure 1.
(a) is a sparse trajectory point in a non-road area; (b) is the trajectory point that falls on the vegetation next to the road; (c) is a dense trajectory noise in a small area; (d) is a road without track points; (e) is a road with extremely sparse trajectories.
Figure 1.
(a) is a sparse trajectory point in a non-road area; (b) is the trajectory point that falls on the vegetation next to the road; (c) is a dense trajectory noise in a small area; (d) is a road without track points; (e) is a road with extremely sparse trajectories.
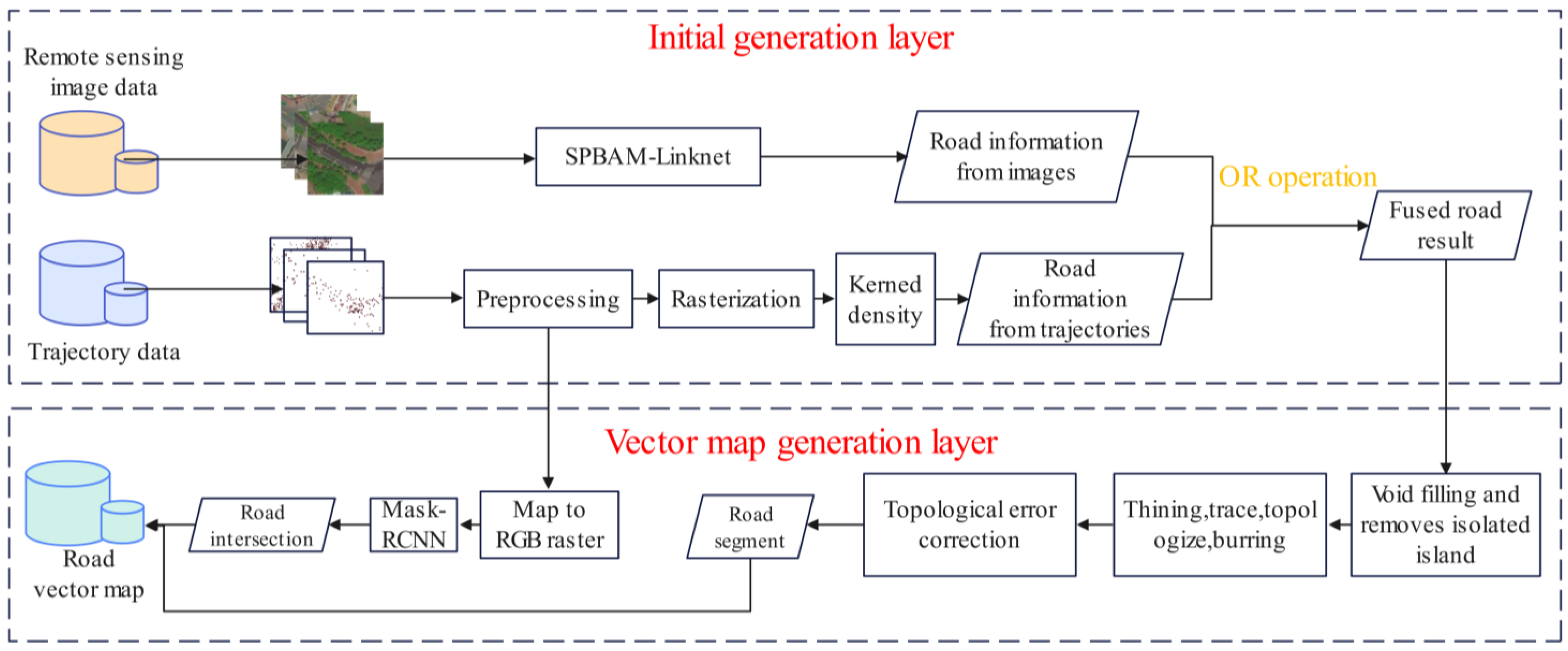
Figure 2.
The overall process of road extraction.
Figure 2.
The overall process of road extraction.
Figure 3.
The structure of SPBAM-Linknet.
Figure 3.
The structure of SPBAM-Linknet.
Figure 4.
The left is the stop point, and the right is the drift point.
Figure 4.
The left is the stop point, and the right is the drift point.
Figure 5.
Generating binary road images based on trajectories. (1) shows the trajectory data; (2) shows the method of selecting thresholds for sparse and dense regions of the trajectory, where (a) is the trajectory density map and (b) is the grayscale curve of the trajectory density map; (c) illu-trates the principle of linear interpolation between trajectory points, where the orange points repr-sent the actual tracking points and the green points represent the interpolated points; (3) is the pa-tition mapping result; (4) presents the results of kernel density estimation.
Figure 5.
Generating binary road images based on trajectories. (1) shows the trajectory data; (2) shows the method of selecting thresholds for sparse and dense regions of the trajectory, where (a) is the trajectory density map and (b) is the grayscale curve of the trajectory density map; (c) illu-trates the principle of linear interpolation between trajectory points, where the orange points repr-sent the actual tracking points and the green points represent the interpolated points; (3) is the pa-tition mapping result; (4) presents the results of kernel density estimation.
Figure 6.
The selection of the threshold value for removing isolated objects.
Figure 6.
The selection of the threshold value for removing isolated objects.
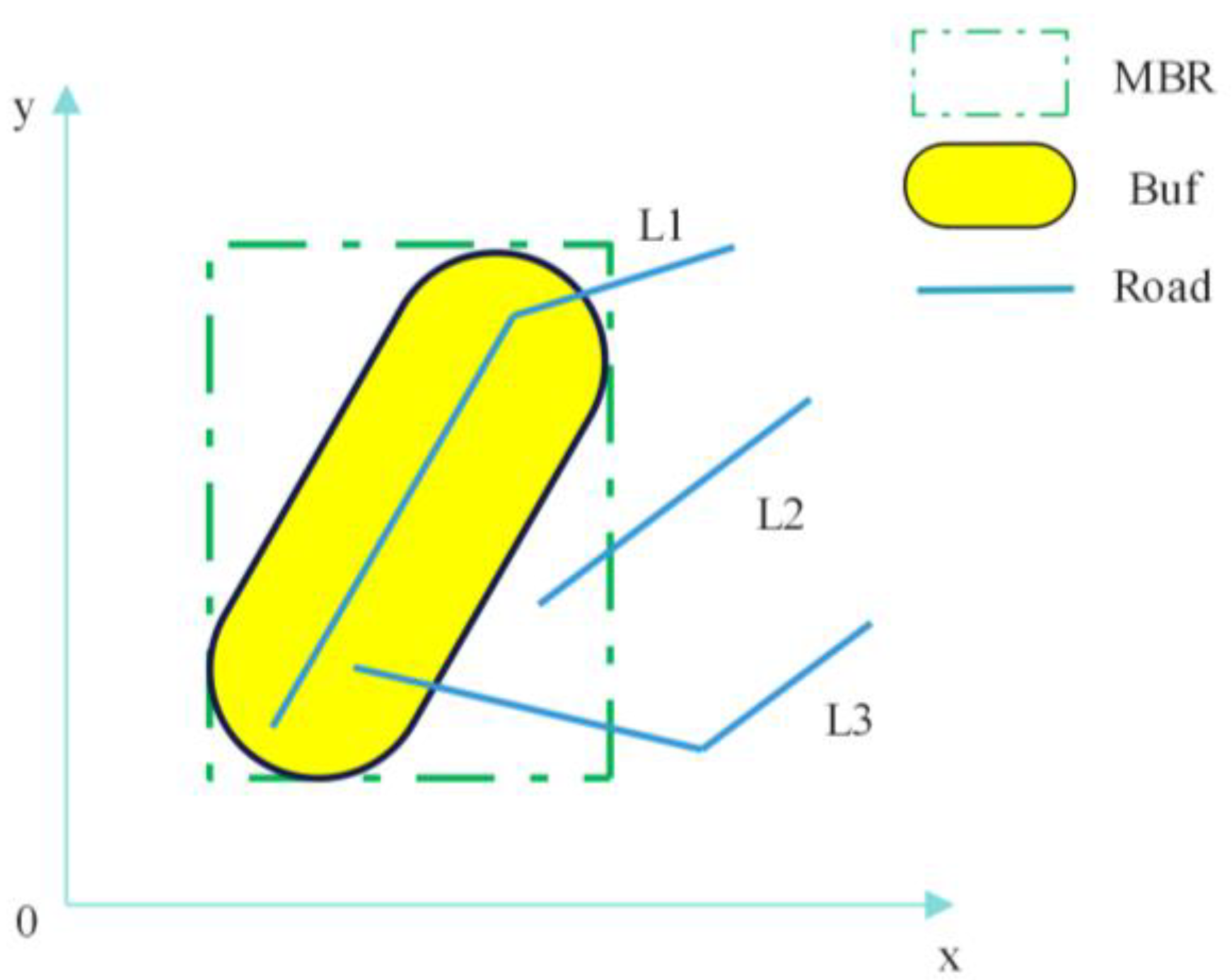
Figure 7.
Intersection and Connection Demonstration. The red square represents the 8-neighborhood of the triangle.
Figure 7.
Intersection and Connection Demonstration. The red square represents the 8-neighborhood of the triangle.
Figure 8.
Before (a) and after (b) the removal of “islands”.
Figure 8.
Before (a) and after (b) the removal of “islands”.
Figure 9.
Topological Inconsistency Detection Methods.
Figure 9.
Topological Inconsistency Detection Methods.
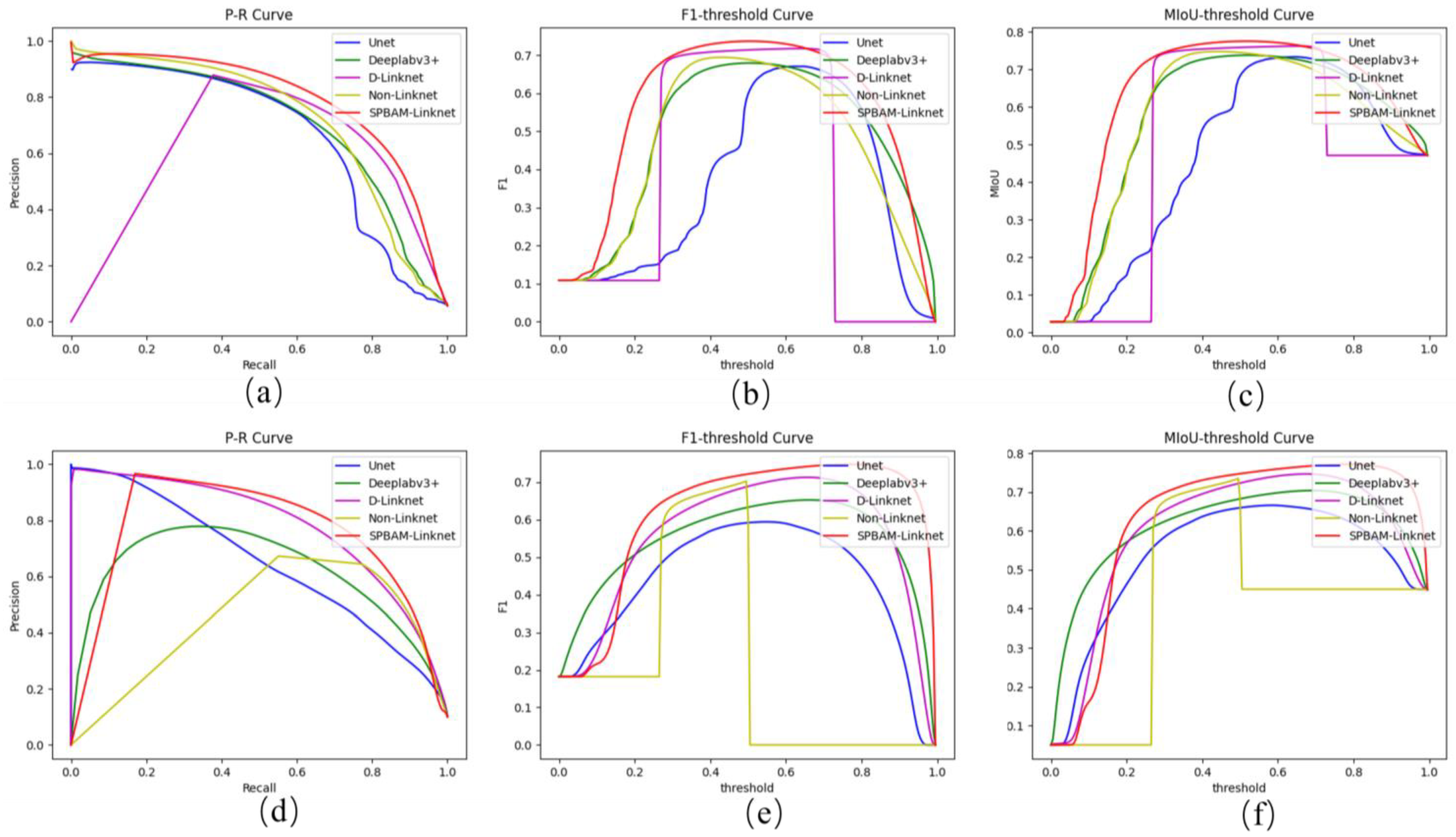
Figure 10.
Displays the precision–recall (P-R) curves, mean intersection-over-union (MIoU) threshold curves, and F1-score threshold curves for various neural networks on the CHN6-CUG and HB roads datasets. Panels (a–c) exhibit the P-R curves, MIoU-threshold curves, and F1-threshold curves on the CHN6-CUG dataset, while panels (d–f) depict the corresponding curves on the HB road dataset.
Figure 10.
Displays the precision–recall (P-R) curves, mean intersection-over-union (MIoU) threshold curves, and F1-score threshold curves for various neural networks on the CHN6-CUG and HB roads datasets. Panels (a–c) exhibit the P-R curves, MIoU-threshold curves, and F1-threshold curves on the CHN6-CUG dataset, while panels (d–f) depict the corresponding curves on the HB road dataset.
Figure 11.
Visualization of the road extraction results of different models on the CHN6-CUG roads dataset.
Figure 11.
Visualization of the road extraction results of different models on the CHN6-CUG roads dataset.
Figure 12.
Visualization of road extraction results of different neural networks on the HB roads dataset.
Figure 12.
Visualization of road extraction results of different neural networks on the HB roads dataset.
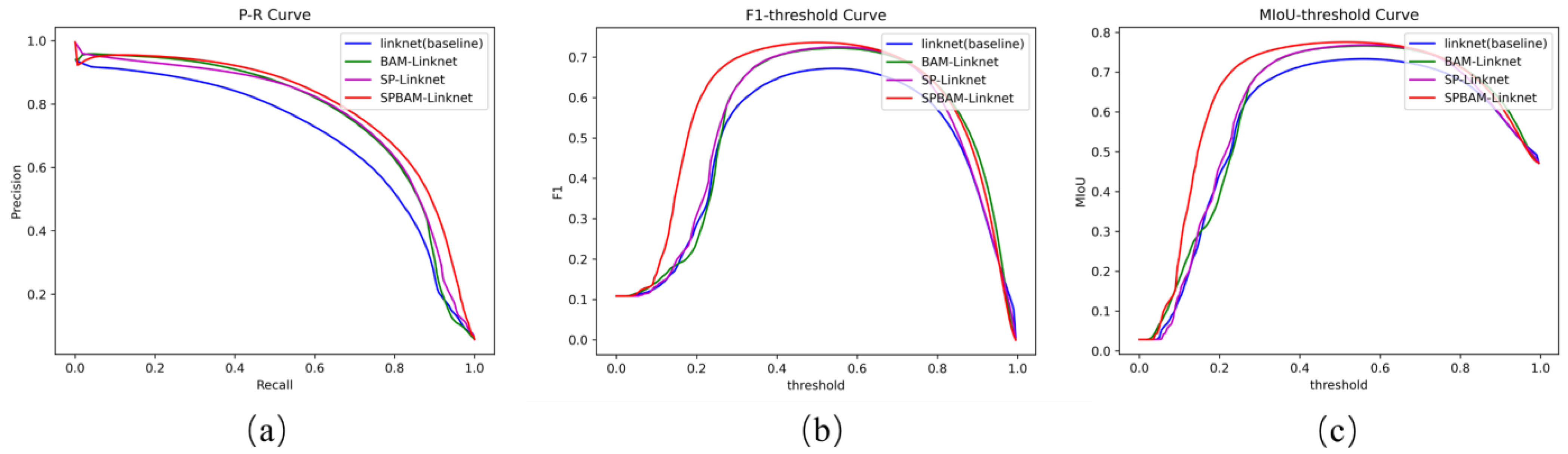
Figure 13.
P-R curve, F1-threshold curve, and MIoU-threshold curve of Linknet (baseline), BAM-Linknet, SP-Linknet, SPBAM-Linknet. (a–c) represent the precision-recall (P-R) curve, F1-threshold curve, and mean intersection over union (MIoU) curve for LinkNet, BAM-LinkNet, SP-LinkNet, and SPBAM-LinkNet.
Figure 13.
P-R curve, F1-threshold curve, and MIoU-threshold curve of Linknet (baseline), BAM-Linknet, SP-Linknet, SPBAM-Linknet. (a–c) represent the precision-recall (P-R) curve, F1-threshold curve, and mean intersection over union (MIoU) curve for LinkNet, BAM-LinkNet, SP-LinkNet, and SPBAM-LinkNet.
Figure 14.
Visualization of road extraction results on CHN6-CUG roads dataset with different modules adding.
Figure 14.
Visualization of road extraction results on CHN6-CUG roads dataset with different modules adding.
Figure 15.
(a) is the prediction result of SPBAM-Linknet trained on CHN6-CUG roads dataset; (b) is the prediction result trained on HB roads dataset; (c) is the prediction result of CHN6-CUG roads dataset and HB roads dataset.
Figure 15.
(a) is the prediction result of SPBAM-Linknet trained on CHN6-CUG roads dataset; (b) is the prediction result trained on HB roads dataset; (c) is the prediction result of CHN6-CUG roads dataset and HB roads dataset.
Figure 16.
Binary road images generated by trajectories with different parameters. (a) , . (b) , . (c) , .
Figure 16.
Binary road images generated by trajectories with different parameters. (a) , . (b) , . (c) , .
Figure 17.
The results and treatment of road topology error detection.
Figure 17.
The results and treatment of road topology error detection.
Figure 18.
The comparison of vector results. Panel (a) illustrates the ground truth generated by OpenStreetMap (OSM) processing, while panels (b–d) display the superimposed results of road segments R1, R2, and R3, respectively, with the ground truth. Areas (1,2) represent the regions where the extraction of road information using only image data failed, while areas (3,4) indicate the road information in (1,2) supplemented by trajectory data. Likewise, areas (5,6) show the regions where the extraction of road information using only trajectory data failed, and areas (7,8) depict the road information in (5,6) supplemented by image data.
Figure 18.
The comparison of vector results. Panel (a) illustrates the ground truth generated by OpenStreetMap (OSM) processing, while panels (b–d) display the superimposed results of road segments R1, R2, and R3, respectively, with the ground truth. Areas (1,2) represent the regions where the extraction of road information using only image data failed, while areas (3,4) indicate the road information in (1,2) supplemented by trajectory data. Likewise, areas (5,6) show the regions where the extraction of road information using only trajectory data failed, and areas (7,8) depict the road information in (5,6) supplemented by image data.
Figure 19.
(
a–
c) respectively represent the ground truth (GT) of vector roads, vector roads generated by RNITP, and vector roads generated by Y. Li in literature [
41]. A and B are two examples where the RNITP method successfully extracted road network information, while the method reported in reference [
41] failed to extract the same information.
Figure 19.
(
a–
c) respectively represent the ground truth (GT) of vector roads, vector roads generated by RNITP, and vector roads generated by Y. Li in literature [
41]. A and B are two examples where the RNITP method successfully extracted road network information, while the method reported in reference [
41] failed to extract the same information.
Figure 20.
Failure cases of RNITP. Cases (a–c) are several examples where the RNITP method failed due to reasons such as obstruction by buildings and trees, and lack of trajectory coverage.
Figure 20.
Failure cases of RNITP. Cases (a–c) are several examples where the RNITP method failed due to reasons such as obstruction by buildings and trees, and lack of trajectory coverage.
Table 1.
Description of inconsistent topological relationships in vector centerlines.
Table 1.
Description of inconsistent topological relationships in vector centerlines.
| Topological Errors | Descriptions | Error Type |
|---|
![Remotesensing 15 03343 i001]() | This is a situation of endpoint overshooting. The scenario is that the circle exp, with the road endpoint as the center and the threshold radius r, intersects or passes through both lines str1 and str2, which intersect with each other. | Overshoot |
![Remotesensing 15 03343 i002]() | This is a situation of endpoint under-coverage. The scenario is that the circle exp, with the road endpoint as the center and the threshold radius r, intersects or passes through both lines str1 and str2, which are disconnected from each other. | Undershoot |
![Remotesensing 15 03343 i003]() | This is a situation of endpoint non-coincidence. The scenario is that the circle exp, with the road endpoint as the center and the threshold radius r, intersects all three lines str1, str2, and str3, and the lines are disconnected from one another. Alternatively, the circle exp intersects both lines str1 and str2, and the lines are disconnected from one another. | Non-coincidence |
Table 2.
Comparison of different road extraction methods on various road datasets.
Table 2.
Comparison of different road extraction methods on various road datasets.
| Model Name | CHN6-CUG Roads Dataset | HB Road Dataset |
|---|
| Accuracy | F1 | MIoU | Accuracy | F1 | MIoU |
|---|
| Unet | 0.9409 | 0.5908 | 0.6787 | 0.9060 | 0.5914 | 0.6595 |
| Deeplabv3+ | 0.9553 | 0.6729 | 0.7301 | 0.9093 | 0.6318 | 0.6817 |
| D-Linknet | 0.9673 | 0.7156 | 0.7615 | 0.9202 | 0.6874 | 0.7295 |
| NL-Linknet | 0.9676 | 0.6879 | 0.7453 | 0.9356 | 0.7012 | 0.7351 |
| SPBAM-Linknet | 0.9695 | 0.7369 | 0.7760 | 0.9387 | 0.7257 | 0.7514 |
Table 3.
Results of ablation experiments on the CHN6-CUG roads dataset.
Table 3.
Results of ablation experiments on the CHN6-CUG roads dataset.
| Model | Baseline | BAM | SP | Accuracy | F1 | MIoU |
|---|
| Linknet (baseline) | √ | | | 0.9596 | 0.6698 | 0.7307 |
| BAM-Linknet | √ | √ | | 0.9665 | 0.7201 | 0.7638 |
| SP-Linknet | √ | | √ | 0.9667 | 0.7220 | 0.7651 |
| SPBAM-Linknet | √ | √ | √ | 0.9695 | 0.7369 | 0.7760 |
Table 4.
Statistics of road topology error results.
Table 4.
Statistics of road topology error results.
| | Undershoot | Overshoot | Non-Coincidence |
|---|
| The number before post-processing | 2907 | 1432 | 562 |
| The number after post-processing | 98 | 122 | 72 |
| Corrected percentage | 0.9662 | 0.9148 | 0.8718 |
Table 5.
Evaluation metrics for results.
Table 5.
Evaluation metrics for results.
| Label | F1 | IoU | Precision | Recall |
|---|
| R1 | 0.8611 | 0.7560 | 0.8622 | 0.8599 |
| R2 | 0.5579 | 0.3868 | 0.9706 | 0.3914 |
| R3 | 0.8883 | 0.7991 | 0.8708 | 0.9065 |
Table 6.
Comparison between RNITP and Y. Li et al.’s method.
Table 6.
Comparison between RNITP and Y. Li et al.’s method.
| Method | F1 | IoU | Precision | Recall |
|---|
| RNITP | 0.8518 | 0.7419 | 0.8386 | 0.8655 |
| Y. Li et al. | 0.7868 | 0.6485 | 0.7027 | 0.8937 |
Table 7.
Model complexity ranking; the serial number represents the ranking position.
Table 7.
Model complexity ranking; the serial number represents the ranking position.
| Model | FLOPs of One Forward Propagation |
|---|
| UNet | 21896783462 ① |
| LinkNet | 53646196736 ② |
| SP-LinkNet | 70596986752 ③ |
| BAM-LinkNet | 82715223112 ④ |
| NL-LinkNet | 95878643712 ⑤ |
| SPBAM-LinkNet | 99761565008 ⑥ |
| D-LinkNet | 130225799168 ⑦ |
| Deeplabv3+ | 169631549440 ⑧ |























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


