
An Empirical Bayesian Approach to Quantify Multi-Scale Spatial Structural Diversity in Remote Sensing Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Background
2. Methods
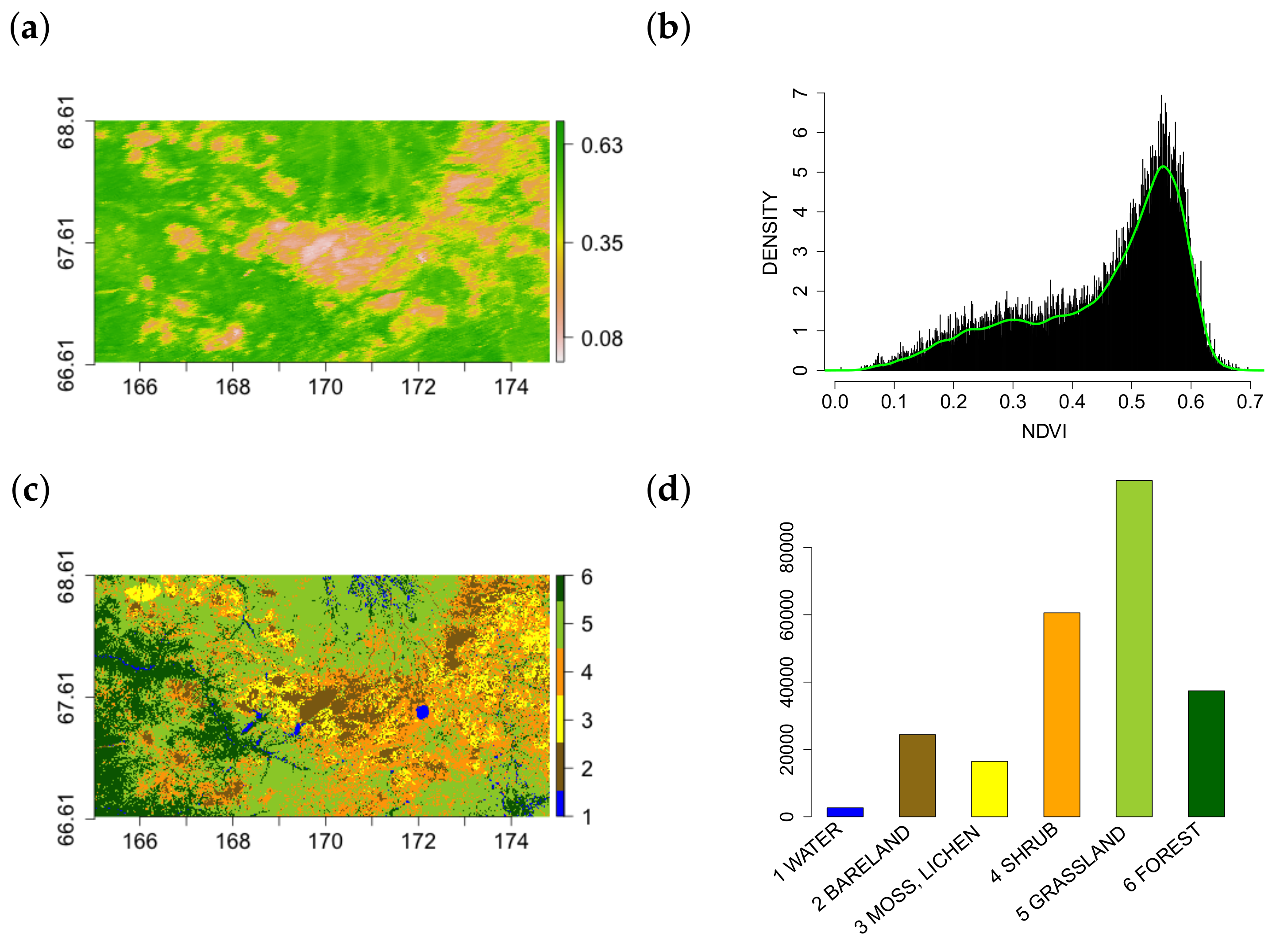
2.1. Study Region, Data and Software
2.2. Structural Diversity
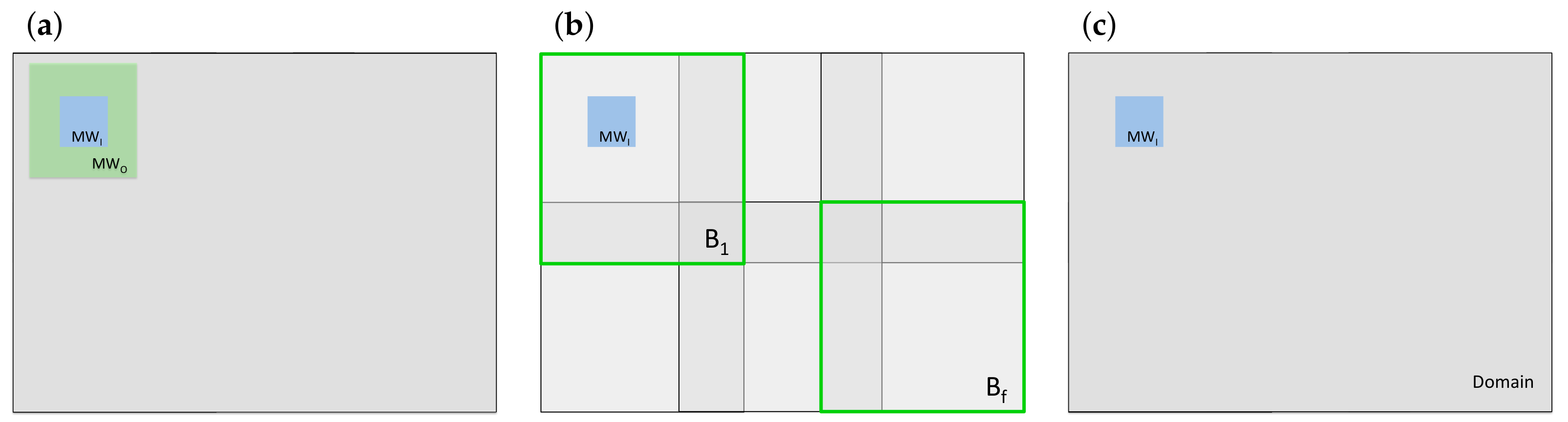
2.3. Spatial Scale
2.4. Beta-Binomial Model in an Empirical Bayesian Setting
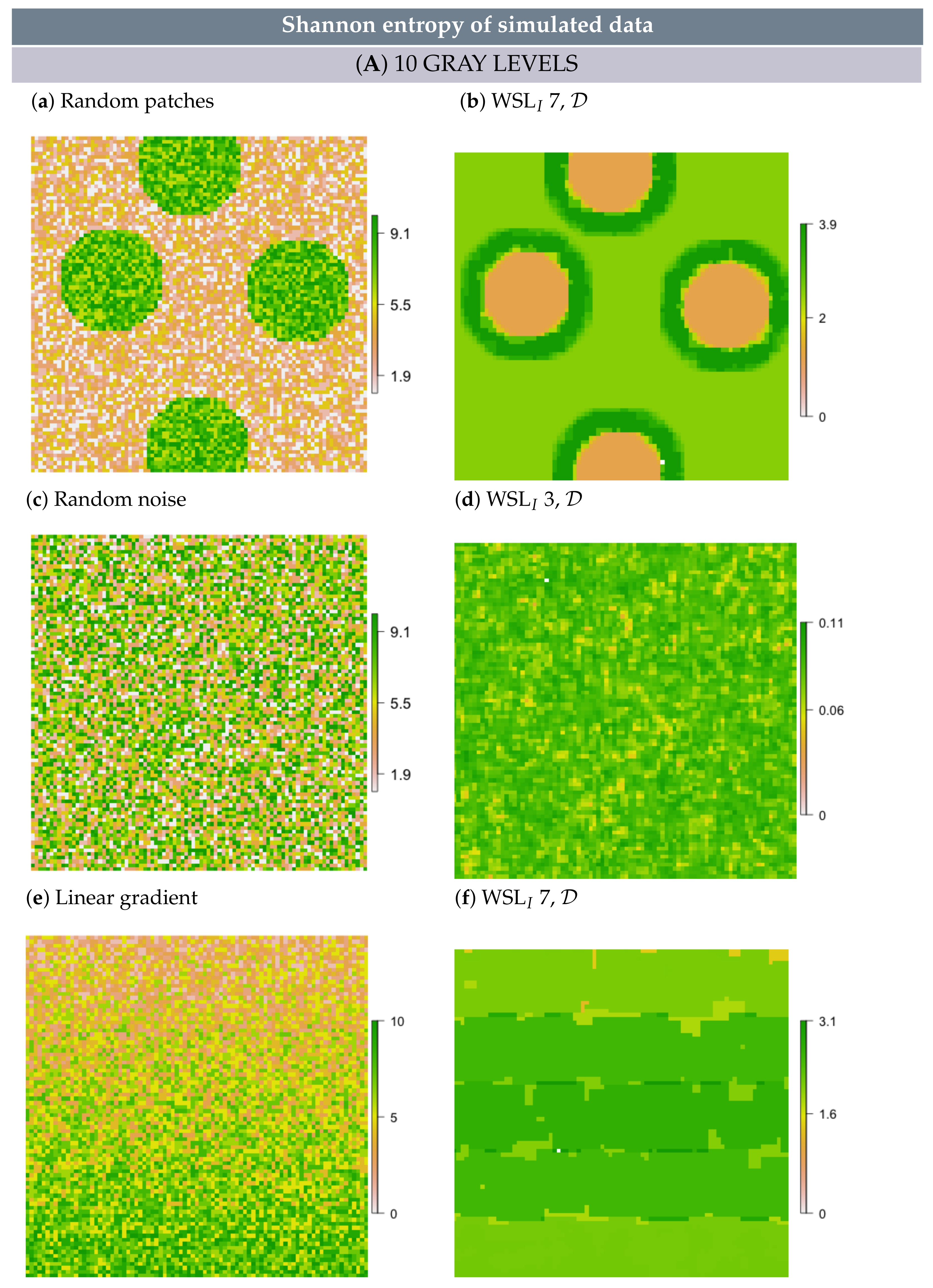
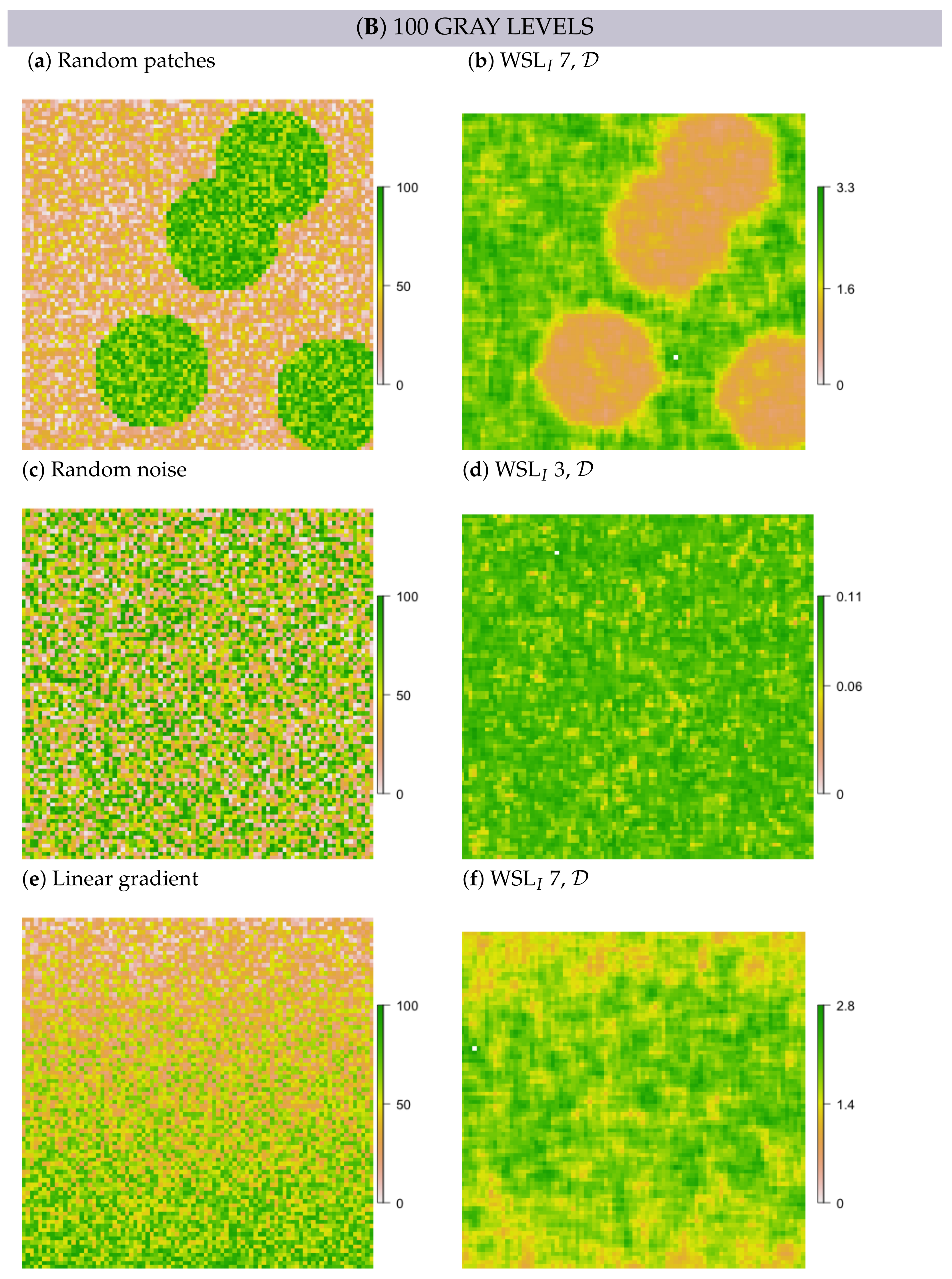
2.5. Simulation
2.6. Structural Diversity in Northern Eurasia and in Different Resolution Data
2.7. Detailed Hypotheses
- As outlined in Section 1, we expected to detect multi-scale features in the same places as scale-specific features, because all scale-specific features were found to originate from transition zones. However, the type of scale-specific features depends on the scale, which permits a hypothesis for the type of multi-scale features expected.
- In simulated random patch data, we expected the edges between patches and the surrounding area to persevere as rings; hence, these rings would resemble multi-scale features.
- In white noise and linear gradient data, we expected to detect no multi-scale features and also no scale-specific features, independent of metric formulation, scale and GL. However, some random structure may emerge, simply because values are not all the same.
- In the uni-scale approach, structural diversity is quantified based on all the information available on the considered scale. In the nested scales approach, prior information is only included about the value pairs that are present on the likelihood scale. This affects the structural diversity value assigned to the center pixel directly, because it is the sum of the individual metrics and hence is influenced by the number of elements that are summed up. We expected this to affect the smoothing of the structural diversity map. We further expected features to be contained to the inner scale and the size of features to be determined entirely by MW.
- When the inner and the outer scale are relatively similar in size, then approximates and approximates . This happens when double moving windows of similar size are employed. In this case, the depicted diverse structures are ‘produced’ by approximately equal amounts of information from the prior and from the likelihood. On the other hand, prior and likelihood will not differ that much, because inner and outer scale are of similar size and also because they are centered on the same pixel. Therefore, we expected to see similar features compared to the uni-scale approach and we expected the smoothing of scale-specific and of multi-scale features to be similar.
- When the outer scale is much larger than the inner scale, then and dominate over and and will eventually be much larger because the number of pixel pairs increases rapidly with the WSL (Figure S3). An exception are cases where value pairs are very rare on the outer scale, but frequent on the inner scale. Yet, such rare cases may not be visible, because only one particular might be affected. However when the prior dominates, then the spatial structure in the resulting map is mostly based on prior information. The larger the outer scale in relation to the inner scale, the stronger this relation will be. In such situations, the differences between features detected with and without prior information can be directly attributed to differences between the inner and the outer scale.
- When the outer scale is the domain or a block, spatial structure is driven by , because , and are constant. Therefore, as the outer scale increases and the prior dominates the posterior, we expected diversity maps to eventually not differ anymore in terms of the types and sizes of features they depict.
- (a)
- When the outer scale is a block, we expected features to appear before a relatively homogeneous background inside each block, because in each block, the denominator is the same for every MW and so is . Yet, we expected the different blocks to have slightly different background values, because is expected to be different in each block.
- (b)
- When the outer scale is , we expected features to appear before a relatively homogeneous background in the whole structural diversity map, because the denominator and are the same for every MW in the whole domain.
3. Results
3.1. Multi-Scale Structural Diversity Features in NDVI Data
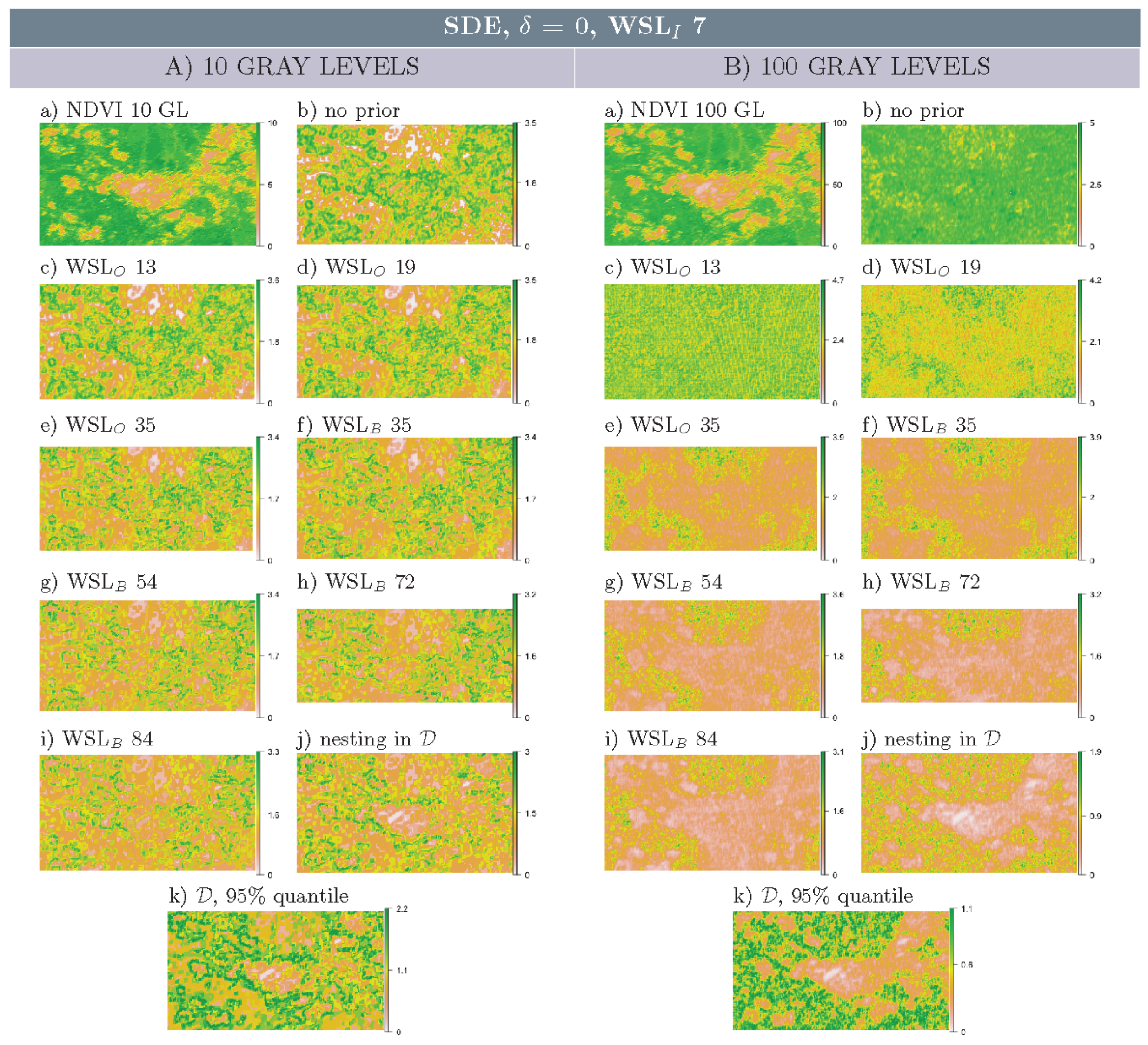
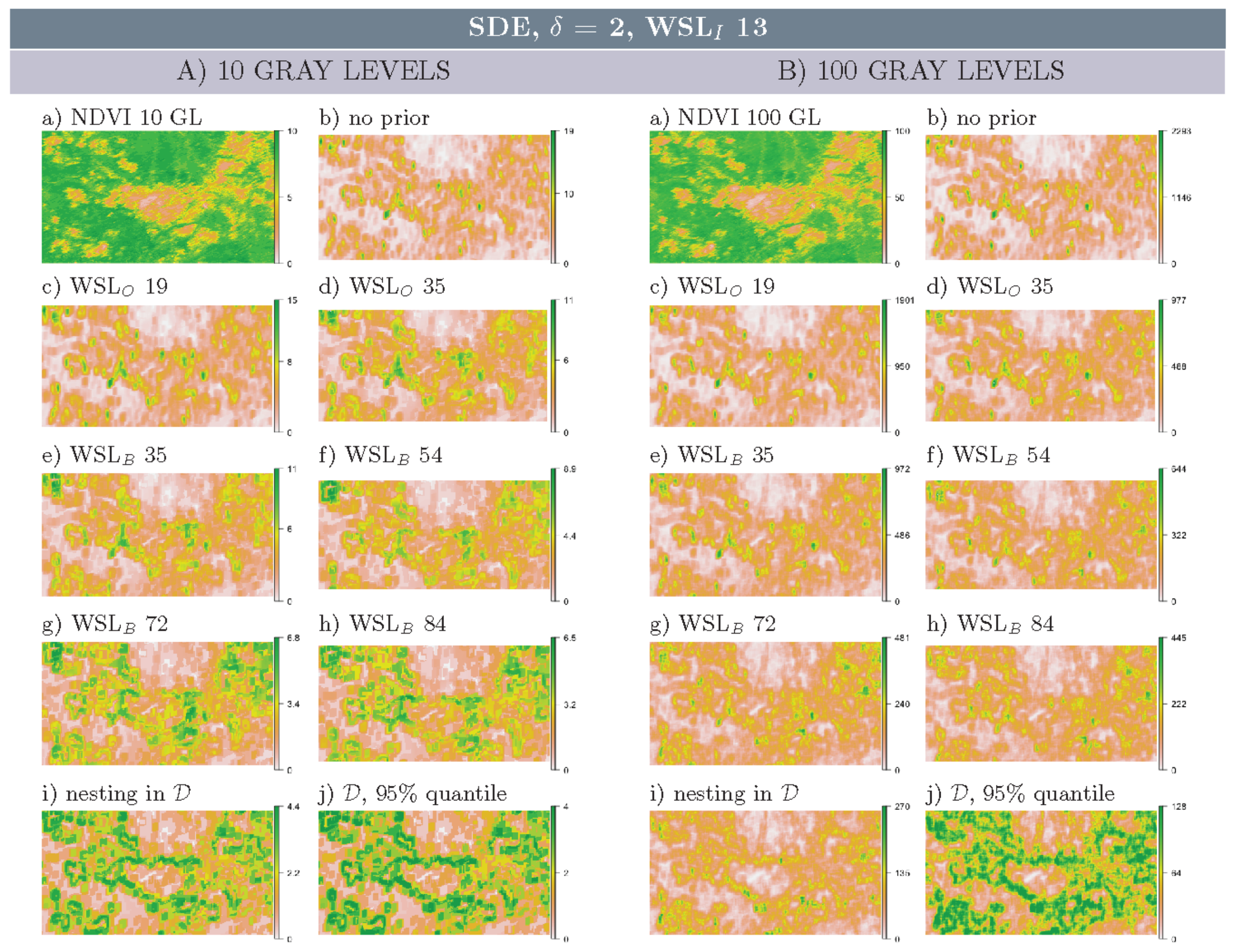
3.2. Multi-Scale Structural Diversity in Simulated Data
3.3. Regime-Separation and GL-Dependency
3.4. Spatial Scale
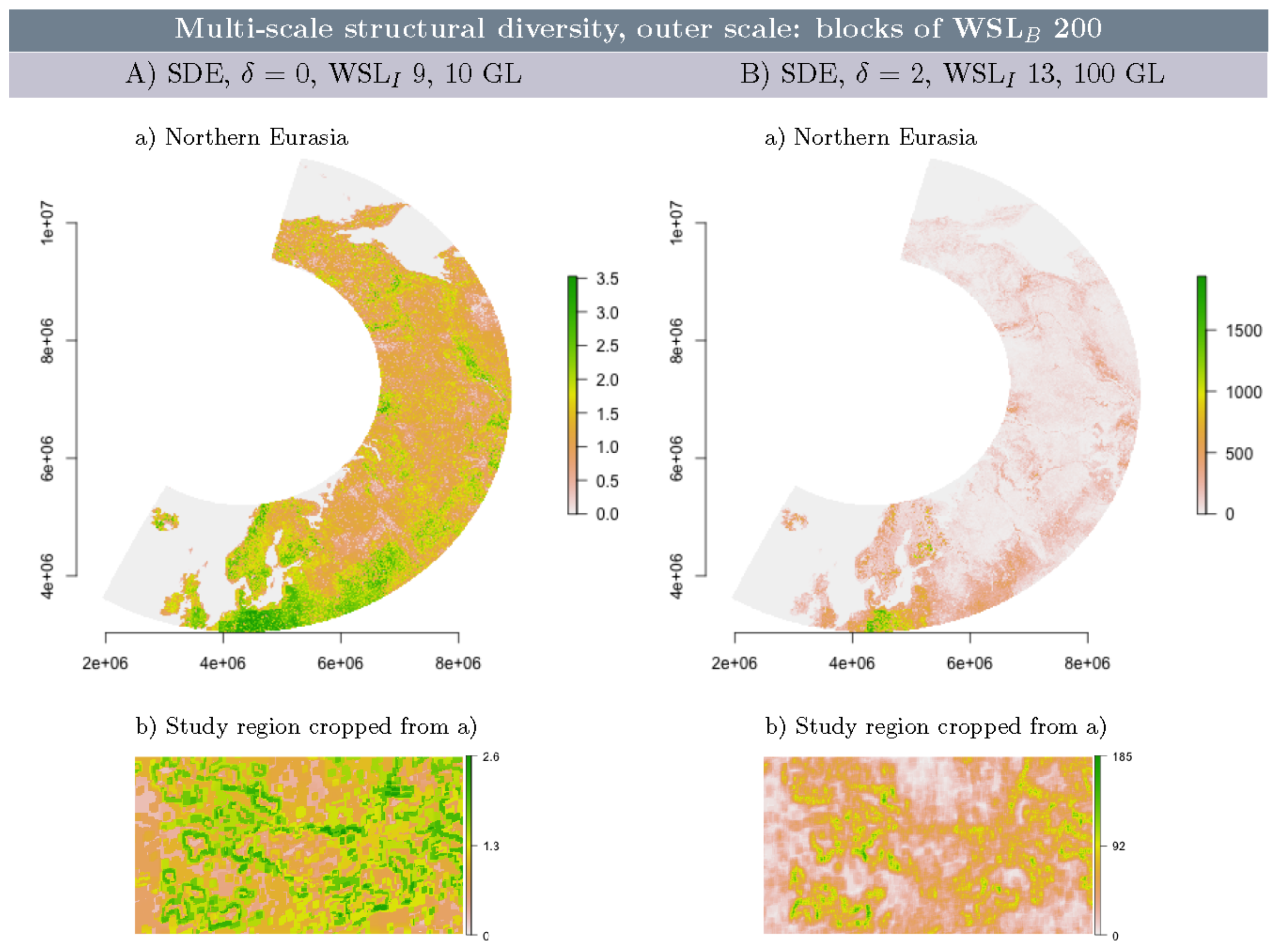
3.5. Multi-Scale Structural Diversity in Northern Eurasia
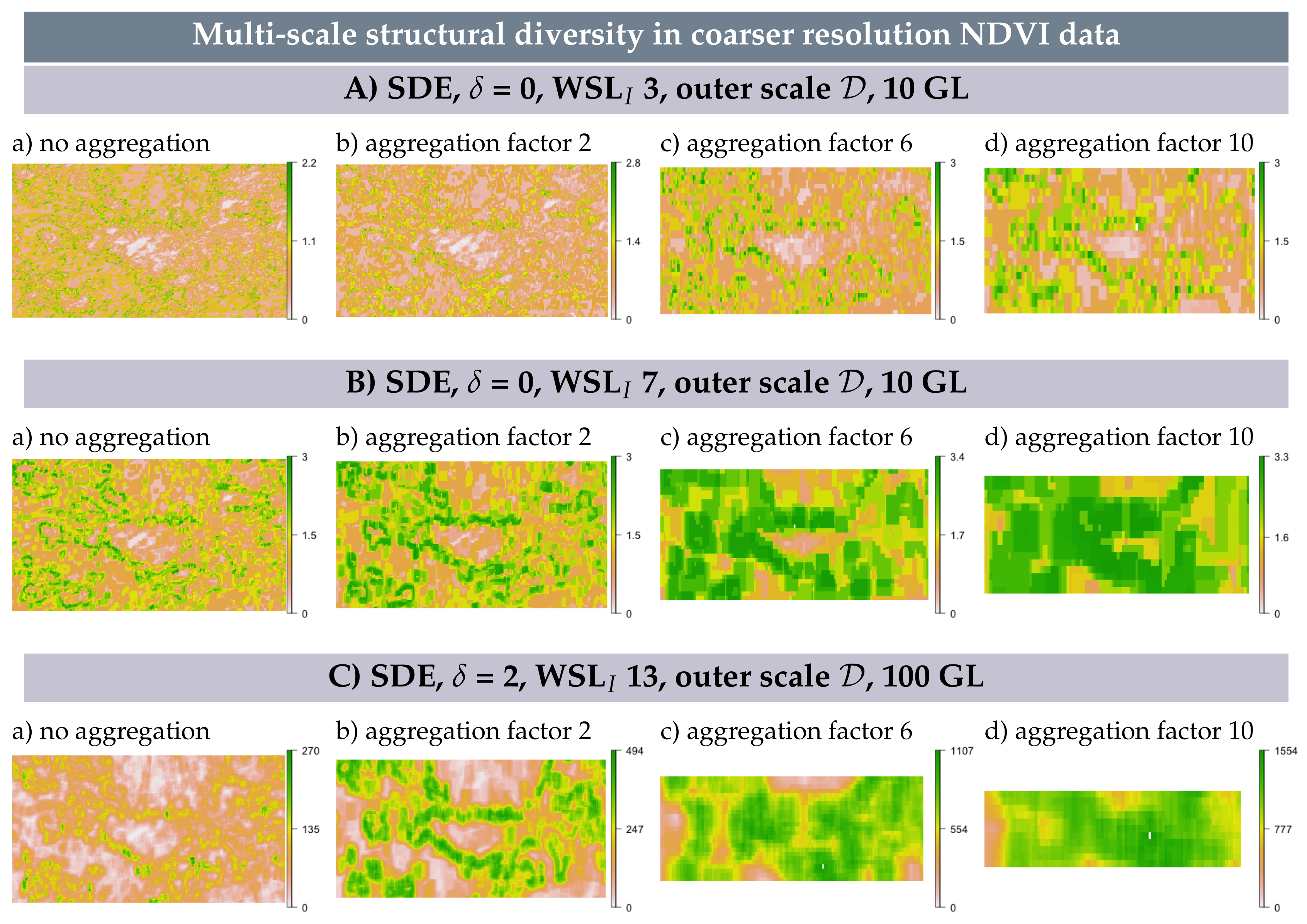
3.6. Multi-Scale Structural Diversity in Coarser Resolution NDVI Data
4. Discussion
- It can reveal the multi-scale character of landscape heterogeneity and detect multi-scale structural diversify features and spatial regimes. In particular, it can reveal near scale-invariant structures that are detected across almost all scales (such as line features in NDVI data).
- The approach can be implemented without knowledge about typical length-scales of structural diversity features.
- The smoothing effect inevitable in uni-scale moving window applications is removed.
- Block and double moving window schemes can be used interchangeably, which allows the optimal choice from a computational perspective. The block nesting scheme is particularly suitable for processing very large datasets (such as NDVI in northern Eurasia).
4.1. Multi-Scale Structural Diversity Features
4.2. Spatial Scale
4.3. Regime Separation
4.4. Linear Gradient Stratification and Rectification
4.5. Ecological Context and Possible Applications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pielke, R.A.; Avissar, R. Influence of landscape structure on local and regional climate. Landsc. Ecol. 1990, 4, 133–155. [Google Scholar] [CrossRef]
- Lyford, M.E.; Jackson, S.T.; Betancourt, J.L.; Gray, S.T. Influence of landscape structure and climate variability on a late Holocene plant migration. Ecol. Monogr. 2003, 73, 567–583. [Google Scholar] [CrossRef]
- Torras, O.; Gil-Tena, A.; Saura, S. How does forest landscape structure explain tree species richness in a Mediterranean context? Biodivers. Conserv. 2008, 17, 1227–1240. [Google Scholar] [CrossRef]
- Walz, U.; Syrbe, R.U. Linking landscape structure and biodiversity. Ecol. Indic. 2013, 31, 1–5. [Google Scholar] [CrossRef]
- Stein, A.; Gerstner, K.; Kreft, H. Environmental heterogeneity as a universal driver of species richness across taxa, biomes and spatial scales. Ecol. Lett. 2014, 17, 866–880. [Google Scholar] [CrossRef] [PubMed]
- Noss, R.F. Indicators for Monitoring Biodiversity: A Hierarchical Approach. Conserv. Biol. 1990, 4, 355–364. [Google Scholar] [CrossRef]
- Estes, L.; Elsen, P.; Treuer, T.; Ahmed, L.; Caylor, K.; Chang, J.; Choi, J.; Ellis, E. The spatial and temporal domains of modern ecology. Nat. Ecol. Evol. 2018, 2, 819–826. [Google Scholar] [CrossRef] [Green Version]
- De Jong, R.; Verbesselt, J.; Zeileis, A.; Schaepman, M.E. Shifts in global vegetation activity trends. Remote Sens. 2013, 5, 1117–1133. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.; Rees, W. Altitudinal forest-tundra ecotone categorization using texture-based classification. Remote Sens. Environ. 2019, 232, 111312. [Google Scholar] [CrossRef]
- ACIA. Impacts of a warming Arctic. In Arctic Climate Impact Assessment; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- IPCC. Climate Change 2007—The Physical Science Basis: Working Group I Contribution to the Fourth Assessment Report of the IPCC; Cambridge University Press: Cambridge, UK, 2007; Volume 4. [Google Scholar]
- Myers-Smith, I.; Elmendorf, S.; Beck, P.; Wilmking, M.; Hallinger, M.; Blok, D.; Tape, K.; Rayback, S.; Macias-Fauria, M.; Forbes, B.; et al. Climate sensitivity of shrub growth across the tundra biome. Nat. Clim. Chang. 2015, 5, 887–891. [Google Scholar] [CrossRef]
- Iturrate-Garcia, M.; O’Brien, M.J.; Khitun, O.; Abiven, S.; Niklaus, P.A.; Schaepman-Strub, G. Interactive effects between plant functional types and soil factors on tundra species diversity and community composition. Ecol. Evol. 2016, 6, 8126–8137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davidson, S.J.; Santos, M.J.; Sloan, V.L.; Reuss-Schmidt, K.; Phoenix, G.K.; Oechel, W.C.; Zona, D. Upscaling CH4 Fluxes Using High-Resolution Imagery in Arctic Tundra Ecosystems. Remote Sens. 2017, 9, 1227. [Google Scholar] [CrossRef] [Green Version]
- Montesano, P.M.; Neigh, C.S.R.; Macander, M.; Feng, M.; Noojipady, P. The bioclimatic extent and pattern of the cold edge of the boreal forest: The circumpolar taiga-tundra ecotone. Environ. Res. Lett. 2020, 15, 105019. [Google Scholar] [CrossRef]
- Kharuk, V.I.; Im, S.T.; Dvinskaya, M.L. Forest–tundra ecotone response to climate change in the Western Sayan Mountains, Siberia. Scand. J. For. Res. 2010, 25, 224–233. [Google Scholar] [CrossRef]
- Wilson, R.J.; Gutiérrez, D.; Gutiérrez, J.; Martínez, D.; Agudo, R.; Monserrat, V.J. Changes to the elevational limits and extent of species ranges associated with climate change. Ecol. Lett. 2005, 8, 1138–1146. [Google Scholar] [CrossRef]
- Ustin, S.L.; Middleton, E.M. Current and near-term advances in Earth observation for ecological applications. Ecol. Process. 2021, 10, 1–57. [Google Scholar] [CrossRef]
- McGarigal, K.; Tagil, S.; Cushman, S.A. Surface metrics: An alternative to patch metrics for the quantification of landscape structure. Landsc. Ecol. 2009, 24, 433–450. [Google Scholar] [CrossRef]
- Lausch, A.; Blaschke, T.; Haase, D.; Herzog, F.; Syrbe, R.U.; Tischendorf, L.; Walz, U. Understanding and quantifying landscape structure–A review on relevant process characteristics, data models and landscape metrics. Ecol. Model. 2015, 295, 31–41. [Google Scholar] [CrossRef]
- Lang, M.; Alleaume, S.; Luque, S.; Baghdadi, N.; Féret, J.B. Monitoring and Characterizing Heterogeneous Mediterranean Landscapes with Continuous Textural Indices Based on VHSR Imagery. Remote Sens. 2018, 10, 868. [Google Scholar] [CrossRef] [Green Version]
- Flury, R.; Gerber, F.; Schmid, B.; Furrer, R. Identification of dominant features in spatial data. Spat. Stat. 2021, 41, 100483. [Google Scholar] [CrossRef]
- Batty, M. Spatial entropy. Geogr. Anal. 1974, 6, 1–31. [Google Scholar] [CrossRef]
- Leibovici, D.G.; Claramunt, C.; Le Guyader, D.; Brosset, D. Local and global spatio-temporal entropy indices based on distance-ratios and co-occurrences distributions. Int. J. Geogr. Inf. Sci. 2014, 28, 1061–1084. [Google Scholar] [CrossRef] [Green Version]
- Altieri, L.; Cocchi, D.; Roli, G. A new approach to spatial entropy measures. Environ. Ecol. Stat. 2018, 25, 95–110. [Google Scholar] [CrossRef]
- Tukiainen, H.; Kiuttu, M.; Kalliola, R.; Alahuhta, J.; Hjort, J. Landforms contribute to plant biodiversity at alpha, beta and gamma levels. J. Biogeogr. 2019, 46, 1699–1710. [Google Scholar] [CrossRef] [Green Version]
- Izsák, J.; Papp, L. A link between ecological diversity indices and measures of biodiversity. Ecol. Model. 2000, 130, 151–156. [Google Scholar] [CrossRef]
- Schuh, L.; Santos, M.J.; Schaepman, M.; Furrer, R. Structural diversity entropy: A unified diversity measure to detect latent landscape features. Remote Sens. 2022. under review. [Google Scholar]
- Allen, C.R.; Holling, C.S. Cross-scale structure and scale breaks in ecosystems and other complex systems. Ecosystems 2002, 5, 315–318. [Google Scholar] [CrossRef]
- Wu, J.; Jelinski, D.E.; Luck, M.; Tueller, P.T. Multiscale analysis of landscape heterogeneity: Scale variance and pattern metrics. Geogr. Inf. Sci. 2000, 6, 6–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hay, G.J.; Blaschke, T.; Marceau, D.J.; Bouchard, A. A comparison of three image-object methods for the multiscale analysis of landscape structure. ISPRS J. Photogramm. Remote Sens. 2003, 57, 327–345. [Google Scholar] [CrossRef]
- Fuhlendorf, S.D.; Woodward, A.J.; Leslie, D.M.; Shackford, J.S. Multi-scale effects of habitat loss and fragmentation on lesser prairie-chicken populations of the US Southern Great Plains. Landsc. Ecol. 2002, 17, 617–628. [Google Scholar] [CrossRef]
- Lyra-Jorge, M.C.; Ribeiro, M.C.; Ciocheti, G.; Tambosi, L.R.; Pivello, V.R. Influence of multi-scale landscape structure on the occurrence of carnivorous mammals in a human-modified savanna, Brazil. Eur. J. Wildl. Res. 2010, 56, 359–368. [Google Scholar] [CrossRef]
- Wiens, J.A. Spatial scaling in ecology. Funct. Ecol. 1989, 3, 385–397. [Google Scholar] [CrossRef]
- Levin, S.A. The Problem of Pattern and Scale in Ecology: The Robert H. MacArthur Award Lecture. Ecology 1992, 73, 1943–1967. [Google Scholar] [CrossRef]
- Sandel, B.; Smith, A.B. Scale as a lurking factor: Incorporating scale-dependence in experimental ecology. Oikos 2009, 118, 1284–1291. [Google Scholar] [CrossRef]
- O’Neill, R.V.; Gardner, R.H.; Milne, B.T.; Turner, M.G.; Jackson, B. Heterogeneity and spatial hierarchies. In Ecological Heterogeneity; Springer: Berlin, Germany, 1991; pp. 85–96. [Google Scholar] [CrossRef]
- Wheatley, M. Domains of scale in forest-landscape metrics: Implications for species-habitat modeling. Acta Oecol. 2010, 36, 259–267. [Google Scholar] [CrossRef]
- Geldenhuys, C.J. Bergwind Fires and the Location Pattern of Forest Patches in the Southern Cape Landscape, South Africa. J. Biogeogr. 1994, 21, 49–62. [Google Scholar] [CrossRef]
- Raffa, K.F.; Aukema, B.H.; Bentz, B.J.; Carroll, A.L.; Hicke, J.A.; Turner, M.G.; Romme, W.H. Cross-scale drivers of natural disturbances prone to anthropogenic amplification: The dynamics of bark beetle eruptions. Bioscience 2008, 58, 501–517. [Google Scholar] [CrossRef] [Green Version]
- Isbell, F.; Gonzalez, A.; Loreau, M.; Cowles, J.; Díaz, S.; Hector, A.; Mace, G.M.; Wardle, D.A.; O’Connor, M.I.; Duffy, J.E.; et al. Linking the influence and dependence of people on biodiversity across scales. Nature 2017, 546, 65–72. [Google Scholar] [CrossRef] [Green Version]
- Chust, G.; Pretus, J.; Ducrot, D.; Bedos, A.; Deharveng, L. Response of soil fauna to landscape heterogeneity: Determining optimal scales for biodiversity modeling. Conserv. Biol. 2003, 17, 1712–1723. [Google Scholar] [CrossRef]
- Geng, X.; Sun, K.; Ji, L.; Zhao, Y. A high-order statistical tensor based algorithm for anomaly detection in hyperspectral imagery. Sci. Rep. 2014, 4, 6869. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, Y.; Qi, B.; Wang, J. Global and Local Real-Time Anomaly Detectors for Hyperspectral Remote Sensing Imagery. Remote Sens. 2015, 7, 3966–3985. [Google Scholar] [CrossRef] [Green Version]
- Moradi, S.; Moallem, P.; Sabahi, M.F. Fast and robust small infrared target detection using absolute directional mean difference algorithm. Signal Process. 2020, 177, 107727. [Google Scholar] [CrossRef]
- Hafiane, A.; Palaniappan, K.; Seetharaman, G. Joint adaptive median binary patterns for texture classification. Pattern Recognit. 2015, 48, 2609–2620. [Google Scholar] [CrossRef]
- Holmström, L.; Pasanen, L.; Furrer, R.; Sain, S.R. Scale space multiresolution analysis of random signals. Comput. Stat. Data Anal. 2011, 55, 2840–2855. [Google Scholar] [CrossRef]
- Krummel, J.; Gardner, R.; Sugihara, G.; O’neill, R.; Coleman, P. Landscape patterns in a disturbed environment. Oikos 1987, 48, 321–324. [Google Scholar] [CrossRef] [Green Version]
- Baatz, M. Multi resolution segmentation. In Beitraege zum AGIT-Symposium; Salzburg: Heidelberg, Germany, 2000; pp. 12–23. [Google Scholar]
- Stuber, E.F.; Gruber, L.F.; Fontaine, J.J. A Bayesian method for assessing multi-scale species-habitat relationships. Landsc. Ecol. 2017, 32, 2365–2381. [Google Scholar] [CrossRef]
- Wikle, C.K.; Berliner, L.M. Combining Information Across Spatial Scales. Technometrics 2005, 47, 80–91. [Google Scholar] [CrossRef]
- Robbins, H. An empirical Bayes approach to statistics. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, San Diego, CA, USA, 26–31 December 1954; Volume 1, pp. 157–163. [Google Scholar]
- Gotelli, N.J.; Ulrich, W. The empirical Bayes approach as a tool to identify non-random species associations. Oecologia 2010, 162, 463–477. [Google Scholar] [CrossRef]
- Krivoruchko, K.; Gribov, A. Evaluation of empirical Bayesian kriging. Spat. Stat. 2019, 32, 100368. [Google Scholar] [CrossRef]
- McCarthy, M.A. Bayesian Methods for Ecology; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Casella, G. An introduction to empirical Bayes data analysis. Am. Stat. 1985, 39, 83–87. [Google Scholar]
- Carlin, B.P.; Louis, T.A. Empirical Bayes: Past, Present and Future. J. Am. Stat. Assoc. 2000, 95, 1286–1289. [Google Scholar] [CrossRef]
- Cowles, M.K.; Carlin, B.P. Markov chain Monte Carlo convergence diagnostics: A comparative review. J. Am. Stat. Assoc. 1996, 91, 883–904. [Google Scholar] [CrossRef]
- Hay, G.; Marceau, D.; Bouchard, A. Modeling multi-scale landscape structure within a hierarchical scale-space framework. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2002, 34, 532–535. [Google Scholar]
- Baker, W.L. Spatially heterogeneous multi-scale response of landscapes to fire suppression. Oikos 1993, 66, 66–71. [Google Scholar] [CrossRef]
- Lindeberg, T.; Haar Romeny, B.M.t. Linear scale-space I: Basic theory. In Geometry-Driven Diffusion in Computer Vision; Springer: Berlin, Germany, 1994; pp. 1–38. [Google Scholar]
- De Jong, R.; Schaepman, M.E.; Furrer, R.; De Bruin, S.; Verburg, P.H. Spatial relationship between climatologies and changes in global vegetation activity. Glob. Chang. Biol. 2013, 19, 1953–1964. [Google Scholar] [CrossRef] [PubMed]
- Guay, K.C.; Beck, P.S.; Berner, L.T.; Goetz, S.J.; Baccini, A.; Buermann, W. Vegetation productivity patterns at high northern latitudes: A multi-sensor satellite data assessment. Glob. Chang. Biol. 2014, 20, 3147–3158. [Google Scholar] [CrossRef] [Green Version]
- Schuh, L.; Schaepman, M.; Santos, M.J.; de Jong, R.; Furrer, R. Advancing Texture Metrics to Model Landscape Heterogeneity. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2735–2738. [Google Scholar] [CrossRef]
- Rahbek, C. The role of spatial scale and the perception of large-scale species-richness patterns. Ecol. Lett. 2005, 8, 224–239. [Google Scholar] [CrossRef]
- Whittaker, R.H. Communities and Ecosystems; Macmillan: New York, NY, USA, 1970. [Google Scholar]
- Sundstrom, S.M.; Eason, T.; Nelson, R.J.; Angeler, D.G.; Barichievy, C.; Garmestani, A.S.; Graham, N.A.; Granholm, D.; Gunderson, L.; Knutson, M.; et al. Detecting spatial regimes in ecosystems. Ecol. Lett. 2017, 20, 19–32. [Google Scholar] [CrossRef] [Green Version]
- Didan, K. MOD13Q1 Dataset. MODIS Terra Vegetation Indices 16-Day L3 Global 250m SIN Grid V006. NASA EOSDIS Land Processes DAAC. 2015. Available online: https://lpdaac.usgs.gov/products/mod13q1v006/ (accessed on 12 December 2022).
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. 2022. Available online: https://intro2r.com/citing-r.html (accessed on 12 December 2022).
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling. R Package Version 2.9-5. 2019. Available online: https://cran.r-project.org/web/packages/raster/raster.pdf (accessed on 12 December 2022).
- Furrer, R.; Sain, S.R. spam: A Sparse Matrix R Package with Emphasis on MCMC Methods for Gaussian Markov Random Fields. J. Stat. Softw. 2010, 36, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Nychka, D.; Furrer, R.; Paige, J.; Sain, S. Fields: Tools for Spatial Data. R Package Version 13.3. 2021. Available online: https://dnychka.github.io/portfolio/fields/ (accessed on 12 December 2022).
- Schuh, L.; Furrer, R. StrucDiv: Spatial Structural Diversity Quantification in Raster Data. 2022. Available online: https://cran.r-project.org/web/packages/StrucDiv/StrucDiv.pdf (accessed on 12 December 2022).
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- O’Neill, R.V.; Krummel, J.; Gardner, R.e.a.; Sugihara, G.; Jackson, B.; DeAngelis, D.; Milne, B.; Turner, M.G.; Zygmunt, B.; Christensen, S.; et al. Indices of landscape pattern. Landsc. Ecol. 1988, 1, 153–162. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Prentice Hall: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Clausi, D.A. An analysis of co-occurrence texture statistics as a function of grey level quantization. Can. J. Remote Sens. 2002, 28, 45–62. [Google Scholar] [CrossRef]
- Cressie, N.A. Statistics for Spatial Data; John Wiley and Sons Inc.: New York, NY, USA, 1993. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Navarro, D.; Perfors, A. An Introduction to the Beta-Binomial Model; University of Adelaide: Adelaide, Australia, 2005. [Google Scholar]
- Jeffreys, H.; Jeffreys, B.; Swirles, B. Methods of Mathematical Physics; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Weisstein, E.W. Beta Function. 2002. Available online: https://mathworld.wolfram.com/ (accessed on 12 December 2022).
- Ehbrecht, M.; Seidel, D.; Annighöfer, P.; Kreft, H.; Köhler, M.; Zemp, D.C.; Puettmann, K.; Nilus, R.; Babweteera, F.; Willim, K.; et al. Global patterns and climatic controls of forest structural complexity. Nat. Commun. 2021, 12, 519. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Rees, G.; Hofgaard, A. Delineation of the forest-tundra ecotone using texture-based classification of satellite imagery. Int. J. Remote Sens. 2020, 41, 6384–6408. [Google Scholar] [CrossRef]
- Loke, L.H.; Chisholm, R.A. Measuring habitat complexity and spatial heterogeneity in ecology. Ecol. Lett. 2022, 25, 2269–2288. [Google Scholar] [CrossRef]
- Turner, M.G.; O’Neill, R.V.; Gardner, R.H.; Milne, B.T. Effects of changing spatial scale on the analysis of landscape pattern. Landsc. Ecol. 1989, 3, 153–162. [Google Scholar] [CrossRef]
- Schneider, D.C. The rise of the concept of scale in ecology: The concept of scale is evolving from verbal expression to quantitative expression. BioScience 2001, 51, 545–553. [Google Scholar] [CrossRef] [Green Version]
- Wu, J. Effects of changing scale on landscape pattern analysis: Scaling relations. Landsc. Ecol. 2004, 19, 125–138. [Google Scholar] [CrossRef]
- Marceau, D.; Hay, G. Remote Sensing Contributions to the Scale Issue. Can. J. Remote Sens. 1999, 25, 357–366. [Google Scholar] [CrossRef]
- Lenton, T.; Rockström, J.; Gaffney, O.; Rahmstorf, S.; Richardson, K.; Steffen, W.; Schellnhuber, H. Climate tipping points—Too risky to bet against. Nature 2019, 575, 592–595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gauthier, S.; Bernier, P.; Kuuluvainen, T.; Shvidenko, A.Z.; Schepaschenko, D.G. Boreal forest health and global change. Science 2015, 349, 819–822. [Google Scholar] [CrossRef] [PubMed]
- Davidson, S.J.; Santos, M.J.; Sloan, V.L.; Watts, J.D.; Phoenix, G.K.; Oechel, W.C.; Zona, D. Mapping Arctic Tundra Vegetation Communities Using Field Spectroscopy and Multispectral Satellite Data in North Alaska, USA. Remote Sens. 2016, 8, 978. [Google Scholar] [CrossRef] [Green Version]
- Jetz, W.; Cavender-Bares, J.; Pavlick, R.; Schimel, D.; Davis, F.W.; Asner, G.P.; Guralnick, R.; Kattge, J.; Latimer, A.M.; Moorcroft, P.; et al. Monitoring plant functional diversity from space. Nat. Plants 2016, 2, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Schneider, F.D.; Morsdorf, F.; Schmid, B.; Petchey, O.L.; Hueni, A.; Schimel, D.S.; Schaepman, M.E. Mapping functional diversity from remotely sensed morphological and physiological forest traits. Nat. Commun. 2017, 8, 1441. [Google Scholar] [CrossRef] [Green Version]
- Abdel Moniem, H.E.M.; Holland, J.D. Habitat connectivity for pollinator beetles using surface metrics. Landsc. Ecol. 2013, 28, 1251–1267. [Google Scholar] [CrossRef]
- Holland, J.D.; Yang, S. Multi-scale studies and the ecological neighborhood. Curr. Landsc. Ecol. Rep. 2016, 1, 135–145. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Gómez, G.B.; Villaseñor, N.R.; Orellana, J.I.; Pozo, R.A.; Fontúrbel, F.E. A multi-scale assessment of habitat disturbance on forest animal abundance in South American temperate rainforests. For. Ecol. Manag. 2022, 520, 120360. [Google Scholar] [CrossRef]
- Liu, J.; Wilson, M.; Hu, G.; Liu, J.; Wu, J.; Yu, M. How does habitat fragmentation affect the biodiversity and ecosystem functioning relationship? Landsc. Ecol. 2018, 33, 341–352. [Google Scholar] [CrossRef]
- Rocchini, D.; Bacaro, G.; Chirici, G.; Da Re, D.; Feilhauer, H.; Foody, G.M.; Galluzzi, M.; Garzon-Lopez, C.X.; Gillespie, T.W.; He, K.S.; et al. Remotely sensed spatial heterogeneity as an exploratory tool for taxonomic and functional diversity study. Ecol. Indic. 2018, 85, 983–990. [Google Scholar] [CrossRef]
- Meiners, S.J. Multiple Effects of the Forest Edge on the Structure of an Old Field Plant Community; Rutgers, The State University of New Jersey: New Brunswick, NJ, USA, 1999. [Google Scholar]
- Wirth, R.; Meyer, S.T.; Leal, I.R.; Tabarelli, M. Plant herbivore interactions at the forest edge. In Progress in Botany; Springer: Berlin, Germany, 2008; pp. 423–448. [Google Scholar]
- Brearley, G.; McAlpine, C.; Bell, S.; Bradley, A. Influence of urban edges on stress in an arboreal mammal: A case study of squirrel gliders in southeast Queensland, Australia. Landsc. Ecol. 2012, 27, 1407–1419. [Google Scholar] [CrossRef]
- Cohard, J.M.; Rosant, J.M.; Rodriguez, F.; Andrieu, H.; Mestayer, P.G.; Guillevic, P. Energy and water budgets of asphalt concrete pavement under simulated rain events. Urban Clim. 2018, 24, 675–691. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schuh, L.A.; Santos, M.J.; Schaepman, M.E.; Furrer, R. An Empirical Bayesian Approach to Quantify Multi-Scale Spatial Structural Diversity in Remote Sensing Data. Remote Sens. 2023, 15, 14. https://doi.org/10.3390/rs15010014
Schuh LA, Santos MJ, Schaepman ME, Furrer R. An Empirical Bayesian Approach to Quantify Multi-Scale Spatial Structural Diversity in Remote Sensing Data. Remote Sensing. 2023; 15(1):14. https://doi.org/10.3390/rs15010014
Chicago/Turabian StyleSchuh, Leila A., Maria J. Santos, Michael E. Schaepman, and Reinhard Furrer. 2023. "An Empirical Bayesian Approach to Quantify Multi-Scale Spatial Structural Diversity in Remote Sensing Data" Remote Sensing 15, no. 1: 14. https://doi.org/10.3390/rs15010014