1. Introduction
Event cameras, as a kind of bio-inspired sensor, trigger events on each pixel independently and asynchronously according to the changes of scene brightness. Compared with standard cameras, they output event flow, which is formed by coordinates on the image plane and the time when an event happens, namely x,y and t (µs or ns level). Another characteristic of event flow is polarity, which indicates the increase or decrease in brightness. The presence or absence of polarity information depends on manufacturers. For example, DAVIS 240C from Inivation provides polarity information, while IMX636 from Sony/Prophesee does not have polarity information.
Event cameras have the characteristics of low latency, high dynamic range, and low power consumption. Due to their different characteristics compared to traditional cameras, event cameras open up a new paradigm for a series of tasks such as VO (Visual Odometry), SLAM (Simultaneous Localization and Mapping), and SfM (Structure from Motion). Feature tracking on event cameras is one fundamental step toward the maturity of these practical applications, which have aroused the interest of a wide range of researchers [
1,
2].
Although many asynchronous feature-tracking methods have been proposed, template matching on event frames or event patches is still a major way to process event information, especially for high-level tasks [
3]. By accumulating a certain number of events or calculating the significance of the incoming event, the contours of objects in the scene are formed in an image-like frame, which is closely related to the movement of the carrier.
Practical feature tracking on event frames still faces challenges from efficiency and accuracy problems. Efficiency is related to high event rates, which depends on carrier motions, scene (e.g., dynamic objects), texture, etc. Event rates may vary significantly, and thus, the frequency of event frames may be very high, increasing the computational difficulty of keeping tracking on a sufficient number of features.
Event flow is sparse, asynchronous, noisy, and only represents brightness changes; thus, event-to-frame transformation has the problem of low signal-to-noise ratio and “texture” loss. Therefore, feature tracking purely relying on event flow may have drift problems, deteriorating the accuracy and robustness of high-level tasks.
Purely relying on event flow information will lead to one problem: when the carrier is moving slowly, the time interval between event frames may be larger than that between images. The frequency of positioning or mapping solutions would not meet the requirements of users. For example, when a drone is performing autonomous exploration slowly in an unknown environment, timely positioning results are still needed for motion and path planning. Therefore, intensity images and inertial information can still provide timely updates as the basic support for high-level tasks.
From the view of bionics, the research on animal processing mechanisms for external information shows that different parts of the brain handle different senses with different attention, which jointly supports the decision of action and judgment. Visual information is not an exception, which is highly related to events, as events only happen when brightness changes. Both global views of the scenes and inertial information are still sensed and processed by the brain latently. Therefore, the fusion of event, intensity, and inertial information has support from bionic research [
4,
5].
Now, several event cameras, such as DAVIS 346 and CeleX-4, provide normal intensity images, angular velocity, and acceleration from embedded IMU (Inertial Measurement Unit), supporting the feasibility of using complementary information for feature tracking.
The advantages of multiple sensor fusion bring potentials to overcome accuracy and efficiency problems from purely event-information-based methods. Therefore, a new feature-tracking method on event frames is proposed in this paper. Its novelty can be summarized as follows:
An event-frame-based feature tracker by using multiple hypothesis testing with batch processing (MHT-BP) is proposed to provide initial tracking solution. In MHT-BP, four-parameter affine transformation is proposed to improve motion coverage of template matching, and batch processing is proposed to improve tracking efficiency.
Together with inertial information prediction, a time-related stochastic model and a constant-velocity model are proposed to loosely integrate the solutions of tracking solution from intensity image and initial tracking solutions, which improves tracking accuracy.
A comparison with other state-of-the-art methods is conducted on publicly available event-camera datasets in terms of tracking efficiency, accuracy, and length. The results show that the proposed method achieved significantly higher accuracy and efficiency and comparable feature-tracking lengths.
The rest of paper is constructed as follows:
Section 2 reviews feature-detection and -tracking methods on event camera.
Section 3 firstly illustrates the data stream that the proposed method deals with and gives a brief description of WF-MHT-BP and then presents inertial based rotation prediction, which acts as the priors for the next feature-tracking steps in
Section 3.1. The method to generate event frame is introduced in
Section 3.2. After that, MHT-BP, which is the tracking method purely relying on event frames, is introduced in
Section 3.3.
Section 3.4 presents the weighted integration of feature-tracking solutions from event frame and intensity frame. In
Section 4, WF-MHT-BP is compared with two methods implemented in MATLAB and EKLT (Event-based Lucas–Kanade Tracker), implemented in C++ in terms of accuracy and efficiency, and EKLT in terms of feature-tracking length.
Section 5 concludes the paper and gives the direction for future work.
2. Related Work
Feature tracking is an active research field, where a number of algorithms have been proposed. Traditional feature tracking on intensity images can be divided into feature-matching-based methods and template-based tracking methods [
6]. Two representative methods are SIFT (Scale-Invariant Feature Transform) [
7] and KLT [
8,
9] respectively. Recently, many deep-learning-based algorithms have been proposed to improve the available number and robustness of feature matching, such as SuperPoint [
10] and D2Net [
11]. However, the efficiency problem of deep-learning-based methods is an obstacle for practical applications, especially for mobile devices.
Due to the different characteristics of event cameras, feature tracking on event flow follows different paradigms. A practical way is to convert event flow to event frames. Usually, events are collected in a temporal window to form event frames, and then, traditional feature tracking paradigms can be applied [
12,
13]. To improve efficiency and accuracy, different event-to-frame transformations and feature-tracking methods are proposed [
14].
Event-to-frame transformation is the first step for event-frame-based feature tracking. Time-surface (TS) is a kind of global 2D surface using exponential decay kernel [
15] to emphasize events happening recently. Another global method is Event Map, proposed by Zhu et al. [
12], to project the events in a selected spatio-temporal window on frames directly. Surface of active events (SAE) is a local form of processing 3D spatio-temporal domain that pays attention to the most recent event at each pixel [
16]. Normally, feature detection on TS or SAE is more accurate than direct methods, as the response of events happening recently is larger. However, computational complexities of direct methods are much lower than that of TS or SAE. Besides, TS or SAE needs more memory, as at least floats are needed in event frames.
A number of event-camera-based feature-detection and tracking algorithms focusing on improving accuracy and efficiency have been proposed. Li et al. [
17] proposed SAE-based FA-Harris corner detection algorithm directly on asynchronous events instead of event frames. Alzugaray et al. [
18] proposed Arc* detector based on modified SAE filtering and subsequently proposed HASTE (multi-Hypothesis Asynchronous Speeded-up Tracking of Events), which purely tracked feature on an asynchronous patch using multi-hypothesis [
19]. Tedaldi et al. [
13] detected Harris features in intensity images and then used ICP (Iterative Closest Point) method to establish correspondences. Zhu et al. [
12] proposed an affine transformation based Expectation-Maximization (EM) algorithm to align two patches in the consequent event frames.
The fusion of event frames and intensity images provides benefits for feature tracking. Gehrig et al. [
20] proposed an event-camera-based tracker, which optimized brightness increment differences from intensity images and event flows. Dong et al. [
21] proposed a template-based feature-tracking method to improve the robustness. They predicted feature-tracking solutions with events and used intensity to correct them. The calculation burdens of these methods cannot be ignored due to their high algorithm complexities. It is observed that only a few features are set to be tracked in these algorithms to ensure real-time performances, affecting the applications of high-level tasks.
Some high-level applications potentially achieve feature tracking by reconstructing 3D geometry. Usually, 3D coordinates of features act as prior information for feature tracking, as they can be projected to the image plane with predicted poses. Zhou et al. [
3,
22] tracked the pose of a stereo event camera and reconstructed 3D environments by minimizing spatio-temporal energy. Liu et al. [
23] proposed spatial-temporal registration algorithm as a part of event-camera-based pose-estimation method. However, the performance of feature tracking and quality of high-level tasks (e.g., pose estimation, scene reconstruction) are closely related. Multiple factors affect feature-tracking accuracy. Moreover, computational burdens will increase with higher algorithm complexity.
In summary, feature tracking on event frames has efficiency and accuracy problems: (1) Tracking efficiency is low due to characteristics of event cameras and designed algorithms. The number of trackable feature points is small, which affects the stability of high-level tasks. (2) Purely tracking features on events easily cause accuracy problems. Although multiple sensor-fusion-based feature tracking has been proposed, the efficiency and accuracy problems still need to be further explored with all available information.
3. Methodology
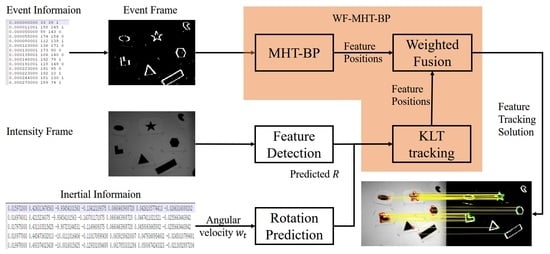
The incoming data stream for an event-camera-based localization or mapping system is illustrated in
Figure 1 as the basic input assumption of the proposed method. Event flow, intensity images, and inertial information will be received asynchronously. Note that polarity information of event flow is not a must for the proposed method. Normally, intensity images and inertial information have equal time intervals. If no dynamic objects are in the scene, event flow potentially represents carrier motion, and the “frequency” of event frames is not even if a constant number of events are collected. Therefore, the proposed method cannot predict the resource of the next input.
Another characteristic of the data stream is that features are only detected on intensity images. Since each intensity frame will be attached with an event frame (see
Section 3.2), the features to be tracked are directly projected to event frames with the same position.
The implementation of the proposed method can be illustrated in
Figure 2. Firstly, IMU provides angular velocity
for feature rotation prediction, which acts as priors for KLT tracking and MHT-BP. Secondly, event flow is accumulated to generate event frame
for practical applications. Feature-detection module provides the positions of features for initialization, and features will be also re-detected if the number or the distribution score [
24] of features are less than the threshold. Thirdly, with the assistance of rotation prediction from IMU, the method assigns MHT-BP for event frame
and KLT tracking for intensity image
. The weighted fusion mechanism will fuse their solutions. The tracking solution is outputted by MHT-BP or weighted fusion module depending on the applications. After the feature-tracking process is over, the method will automatically add detected features if the number or the distribution score [
24] of features are not large enough. Shi-Tomasi corner feature point [
25] was chosen as the feature to be tracked. Note that the proposed method is not limited to feature types and can be extended by other features, such as FAST [
26].
3.1. Inertial-Aided Rotation Prediction
According to the work of [
27,
28], the relationship between tracked features in two consecutive images can be approximated by Equation (1) considering the small translation relative to depth.
where
is the intrinsic matrix, and
and
are 2D positions of the tracked feature and the predicted feature, respectively. The rotation matrix R can be integrated from angular velocity information
[
27] as shown in
Figure 2.
will acts as the predicted feature position for the tracking.
3.2. Event-to-Frame Transformation
In this method, the generation of event frames follows that of Event Map instead of TS or SAE. Since TS- or SAE-based event-frame-generation method involves exponential computing, it is thus not used to reduce computing complexity.
Event-to-frame transformation follows two modes as shown in Equation (2): One is collecting a constant number events. The events are projected on the image plane to form a binary image. Absence and presence of events within the temporal window are expressed by 0 and 1, respectively.
Another way is by the timestamps of intensity images. If one intensity image has been received, the events between the timestamp of last frame (intensity frame or event frame) and current timestamp, which is represented by
, will be collected. That is, each intensity image has an attached event frame. This will cause one potential problem: If the number of events is too small, the generated event frame will be too sparse for reliable feature tracking. However, this situation will be alleviated by the following integration from intensity image:
3.3. Affine Transformation-Based Multiple Hypothesis Testing for Batch Processing (MHT-BP)
The work of [
19] proposed five hypotheses purely based on event flow, which are Null, East, North, West, and South hypotheses. Firstly, a template and a model are generated from a time window on event flow. Then the alignment score that quantifies their differences is calculated to guide the selection of the above-mentioned five hypotheses.
Inspired by the work of [
19], a batch processing-based multiple hypothesis testing using four-parameter affine transformation model (MHT-BP) is proposed to improve feature-tracking efficiency. Compared with the five hypotheses in [
19], the four-parameter affine transformation model explores more hypotheses to improve matching accuracy. Moreover, batch processing is conducted to improve efficiency.
Since with the above-mentioned data stream, the possible minimal “frequency: of event frames is equal to that of intensity frame, the difference between consecutive frames is small enough for patch comparison. The small feature motions bring three benefits to improve efficiency and accuracy: (1) neighboring areas near features can provide supporting regions to make multiple hypotheses; (2) a set of features are able to share the same affine transformation, and therefore, batch processing can be conducted to improve efficiency; and (3) the search range of four parameters in the affine transformation model can be small.
The four-parameter affine transformation model is applied to generate multiple hypotheses.
represent the variation on scale, rotation, and translation on
and
respectively. The four parameters between affine transformation are shown in Equation (3).
The illustrative example of MHT-BP is illustrated in
Figure 3 given two event frames
and
. A patch on
containing a set of features are selected with the four-parameter affine transformation model. The patch is transferred to generate multiple hypotheses; that is, each hypothesis corresponds to an affine transformation. After Gaussian blur, their differences are indicated by sum of absolute differences (SAD). The affine transformation model with minimum distance is chosen to establish correspondences between the two patches. This process will go on until all the features are involved.
3.4. Weighted Fusion Using Event/Intensity Information
MHT-BP is essentially a template-matching method purely using event information, which suffers from drift problems. Due to the high “frequency” of event frames, the mature KLT tracking results between intensity frames can guide the correspondence establishment between event frames. A constant-velocity model is used to re-predict the tracking solutions. A weighted fusion method is proposed to correct the drift and thus improve the accuracy. This provides two options for real-time processing and post processing. For real-time processing, features can be obtained from MHT-BP. For the post-processing tasks, such as bundle adjustment (BA) and SfM, poses and structure calculated from tracked features of event frames can still be obtained in a delayed manner.
As illustrated in
Figure 4, the first row is one event frame sequence, and the second one is one intensity image sequence. The black dots and blue dots are detected features that share the same position. MHT-BP provides tracking solutions on each event frame. Due to the blurring effects of event frames, tracking solutions from MHT-BP suffer from drift problems. Drifts represented by uncertainties (shown in
Figure 4) increase with time. However, since KLT tracking on the intensity sequence uses texture information, the increasing rate of drift is lower than that of MHT-BP through our tests. Therefore, the weighted fusion mechanism can reduce the drift error.
Firstly, the stochastic model of MHT-BP and KLT is expressed by
and
respectively, as Equations (4) and (5). The uncertainty is related to time and tracking quality.
where
is time period from the timestamp of first intensity image.
and
are drift in the unit of pixel per second, which can adjust the weights for fusing the solutions. The parameters need to be reasonably and empirically defined.
Secondly, the velocity of optical flow from KLT tracking is assumed to be constant due to the small-motion assumption. If event frames exist between two intensity images, feature-tracking solution can be linearly estimated on virtual intensity frame, such as
and
(see the dotted border of the second row in
Figure 4) using Equations (6) and (7).
where
and
represent feature displacements between
and
on the
and
axis, respectively.
represents the time period between
and
.
represents consumed time period from
.
Thirdly, with above-mentioned stochastic model and constant-velocity model, the weighted fusion can be conducted by using Equations (8) and (9). As shown in
Figure 4, the red dots on last row show the result of weighted fusion.
The weighted fusion of MHT-BP and KLT solutions is named as WF-MHT-BP. Like the normal feature-tracking algorithm, it also detects new features after processing one event frame when the number of tracked feature or the distribution score is less than the threshold.
The proposed WF-MHT-BP can be summarized as Algorithm 1. Facing the structure of data stream shown in
Figure 1, firstly, the inertial information is used to predict feature-tracking rotation. Then, if an event frame arrives, MHT-BP will purely use event information to generate tracking solutions. If an intensity image arrives, the proposed algorithm (WF-MHT-BP) can provide tracking solutions by fusing tracking solutions of KLT and MHT-BP. It should be noted that both MHT-BP and the proposed algorithm are able to output tracking solutions depending on when tracking solutions are needed.
| Algorithm 1: Feature-tracking method based on integration of event, intensity and inertial information (WF-MHT-BP) |
Input: Event {x,y,t}, , , search range of , . Intensity image angular velocity and threshold for feature detection and
Output: Tracking solutions on the current intensity or event frame |
| 1 | Predict feature rotation using Equation (1) with angular velocity |
| 2 | Generate event frame by using Equation (2) with and |
| 3 | If an event frame is received, then |
| 4 | Track features using MHT-BP with search range |
| 5 | If tracking solutions are needed, then |
| 6 | Ouput tracking solutions on event frame |
| 7 | If an intensity frame is received, then |
| 8 | Perform KLT tracking between and |
| 9 | Perform weighted fusion of tracking solution from KLT and MHT-BP |
| 10 | If NumOfTrackedFeature or DistributionScore then |
| 11 | Perform Shi-Tomasi detection on |
| 12 | If tracking solution is needed, then |
| 13 | Output tracking solutions on intensity frame |
4. Experiments
The experiments chose 16 datasets from an event camera dataset publicly provided by University of Zurich [
29], which uses a DAVIS 240C from Inivation, Zurich, Switzerland. It provides events flow, intensity images, and IMU measurements. The resolution of intensity images is 240 × 180. WF-MHT-BP runs on MATLAB platform in a computer with I5-10400F and 16 GB memory.
The input parameters are summarized in
Table 1.
is set as 3000, which means when 3000 events arrive, an event frame will be generated. That is, an event frame will be formed once the number of events reaches 3000.
define the search range of affine transformation as illustrated in Equation (3).
and
are drift in the unit of pixel per second used in Equations (4) and (5).
and
are set as 40 and 0.15, respectively, which means if the number or distribution score of tracked features is less than 40 or 0.15, Shi-Tomasi detection will be conducted to improve the number of newly detected features.
The state-of-the-art methods are chosen from open-source event-frame-based feature tracking methods. One is probabilistic data association-based tracking (PDAT) method proposed by Zhu et al. [
12]. The publicly available implementation is used. Another is ICP-based feature-tracking algorithm (High Temporal Resolution Tracking algorithm, HTRT) based on the work of Tedaldi et al. [
13]. Since there are no original implementation provided by the authors, an implementation by a third-party is used (
https://github.com/thomasjlew/davis_tracker, accessed on 29 February 2022). The modifications are made to provide better performances for the comparison. ICP maximum iterations is changed to 3. The feature is changed to Shi-Tomasi feature, which is the same with WF-MHT-BP.
Compared with purely using event information in the above-mentioned methods, EKLT in C++ version, which integrates event and intensity information, is also compared in accuracy, efficiency, and feature-tracking length. Since the proposed algorithm is implemented in MATLAB version, which is normally slower than C++, the performance of EKLT is listed as a reference.
Firstly, MHT-BP, which is the internal parts of WF-MHT-BP, is compared with an open-source template-matching method to show its improved efficiency and comparable accuracy. Then WF-MHT-BP is compared with PDAT, HTRT, and EKLT in tracking accuracy and efficiency. Finally, the feature-tracking length is compared between EKLT and WF-MHT-BP.
4.1. Feature Tracking Accuracy and Comparison between MHT-BP and FasT-Match
The goal of feature matching on event frames is to find the affine transformation in small ranges between consecutive frames. FasT-Match [
30] was chosen as the baseline to compare the efficiency and patch matching error, as it achieves the same goal with MHT-BP. Moreover, it is a template-patch-matching-based method with similar control flow as MHT-BP. The difference of MHT-BP and FasT-Match are: (1) MHT-BP uses a simplified affine transformation model, but Fast-Match uses more complex transformation model with six parameters. (2) Batch processing is used in MHT-BP, but FasT-Match does not have the mechanism. (3) FasT-Match has a branch-and-bound search strategy to find the parameters in the transformation model, but MHT-BP does not use strict termination conditions to improve efficiency. FasT-Match are implemented in MATLAB, which is the same with MHT-BP. “shapes_rotation” was chosen for efficiency and template-matching error comparison.
Small, average normalized patch errors (NPE) mean higher similarities between two patches.
Figure 5 shows the cumulative distribution function(CDF) of NPE and consumed time. The curve of MHT-BP and FasT-Match is very similar. Average NPEof FasT-Match and MHT-BP are 0.049 and 0.041, respectively, which means both of their matching errors are very small, and their differences can be ignored compared with the error ranges (0, 1). The mean consumed time of MHT-BP and FasT-Match is 3.53 ms and 80.40 ms, respectively. The consumed time of MHT-BP is much lower than FasT-Match. The reason for the acceptable error and reduced computational complexity is MHT-BP has the mechanism of batch processing and four-parameter affine transformation to improve accuracy and efficiency. It can be concluded that the majority of normalized patch errors by FasT-Match are slightly lower than that of MHT-BP method. However, the consumed time for MHT-BP is much lower than that of FasT-Match, which shows around a 10
–20
increase in speed. Although matching error of MHT-BP increased by around 19% compared with FasT-Match (0.049 vs. 0.041), the matching error is corrected in a timely manner by KLT tracking in WF-MHT-BP in the next step. Therefore, MHT-BP is chosen as the internal part of WF-MHT-BP.
4.2. Feature-Tracking Accuracy Comparison
Figure 6 shows feature-tracking solutions from the proposed method. The traces of tracked features are projected on the first intensity image to show the matching results. The 16 datasets with different scenarios of lighting, objects, and motion are compared in feature-tracking accuracy.
Both MHT-BP and WF-MHT-BP will generate tracking solutions. The solutions between frames are filtered by fundamental matrix based RANSAC (RANdom SAmple Consensus). For the parameters for RANSAC-based fundamental matrix, Sampson distance threshold is set as 0.1. The inlier ratio is used as the indicator for tracking accuracy. PDAT and HTRT follow in the same way. However, EKLT corrects tracking solutions from event information when an intensity frame arrives, and the inlier ratio between intensity frame is used.
For each dataset, the average inlier ratio is calculated as shown in
Table 2. Note that the inliers from RANSAC are not used for the next feature-tracking process. For each method, different scenes with different light, object, and motion settings have different average inlier ratios. It is interesting to find that inlier ratio of HTRT for all the datasets is around 50%. The inlier ratio of PDAT ranges from 38.19% in “hdr_poster” scenario to 80.80% in “shapes_transaltion” scenario. In the scenario of “boxes”-, “hdr”-, and “poster”-related scenarios, inlier ratio of PDAT decreases rapidly, showing the difficulty from environmental factors.
The inlier ratio of EKLT is much better than PDAT and HTRT, which reaches 88.26% on average. WF-MHT-BP achieves the highest inlier ratio for all datasets. The main differences between EKLT and WF-MHT-BP are: (1) EKLT uses gradients to track features on event frame without batch processing, but MHT-BP in the proposed method uses four-parameter affine transformation for feature tracking in the way of batch processing. (2) WF-MHT-BP uses inertial information to predict the positions of features, while EKLT does not use inertial information. (3) KLT only correct drifts on arrived intensity images. WF-MHT-BP uses a simple and efficient fusion mechanism to correct tracking solutions from MHT-BP and current positions of tracked features. Therefore, the main reason is that WF-MHT-BP integrated all available factors for feature tracking, making tracking solution more accurate.
4.3. Feature-Tracking Efficiency Comparison
The efficiency of WF-MHT-BP is compared with PDAT, HTRT, and EKLT since they have different numbers of initialized features, which is meaningful for real applications, as lower time complexity will lead to more abundant time for frame processing. Since different methods have a different number of tracked features, the efficiency is quantified by the consumed time per tracked feature
, which is calculated as:
where
is the consumed time on each frame, and
is the number of tracked features on each frame. Note that all the visualization parts of all algorithms are closed to ensure accurate consumed-time statistics.
As shown in
Table 3, HTRT has the highest computational complexity, which reaches 1062 ms for tracking one feature in “dynamic_rotation” scenario, which is not practical for real-time high-level tasks. EKLT still needs tens of milliseconds to track one feature between two intensity images. PDAT consumes less time to track one feature point than EKLT, but in the scenario of “dynamic_translation” and “outdoors_walking”, it reaches 56 ms and 52 ms, respectively. WF-MHT-BP achieves the best efficiency among the four feature-tracking methods, which generally improves the efficiency by approximately three orders of magnitude compared with PDAT and EKLT and four orders compared with HTRT.
The main reason for high computational complexities of PDAT and HTRT is that the registration between two patches is done one by one. Besides, EM (Expectation Maximization) and ICP algorithms used in these methods are not suitable for real-time processing. Another reason for the high time consumption of HTRT is that the related event information to be processed needs to be searched from external memory for every event frame. The time consumption is at approximately the same level with EKLT at the beginning. As feature tracking continues processing, the time consumption becomes larger, resulting in the larger overall time consumption.
For EKLT algorithm, it involves the complex optimization of object function for tracking error and also does not have a batch-processing mechanism. Therefore, their consumed time is much larger than WF-MHT-BP. The efficiency problem is optimized in WF-MHT-BP by the batch-processing mechanism and simple loose integration with KLT tracking solution, which enables the lowest computational complexity of WF-MHT-BP.
4.4. Feature-Tracking Length Comparison
Feature-tracking length is another important indicator for feature tracking especially in VO or SLAM since the improved continuity of features can give more constraints for estimating poses or constructing maps. Without re-detecting features, feature-tracking length is quantified by the time period between the timestamp of first frame and the time when the number of tracked features decreases to 10% of the initial one. Due to the high computational complexity, HTRT is not further compared in its feature-tracking length.
The result is shown in
Table 4: PDAT shows limited feature-tracking ability on tracking length, which means 90% of initialized feature can only last for 0.35 s. Its main difference with the other two methods is it purely uses event information for feature tracking, which can easily lose tracked features.
WF-MHT-BP and EKLT show similar feature-tracking length statistics, showing the superiority in integrating the measurement from two sensors. The commonality between the two methods is that intensity information is used to correct the feature-tracking drifts from event information, which is helpful to continue tracking features.
5. Concluding Remarks
This paper proposes a loosely integrated feature tracking method on event frames using event, intensity, and inertial information to improve the accuracy and efficiency problem. MHT-BP, which involves four-parameter affine transformation and batch processing, is proposed to achieve fast and short-term feature matching. Then, a weighted fusion algorithm involving the constant velocity model and the stochastic model for drifts is proposed to reduce drifts. Next, it corrects the drift by weighted fusion in the way of post-processing, which is still meaningful for event-camera-based applications, such as SfM and SLAM.
MHT-BP is compared with FasT-Match, showing better efficiency at the expense of slight accuracy decline. In comparison with three state-of-the-art methods, including both event-information-based methods (PDAT and HTRT) and one multiple-sensor fusion-based method (EKLT), WF-MHT-BP shows the significant superiority on accuracy and efficiency and comparable feature-tracking lengths with EKLT.
In the future, the work can be refined and extended in the following aspects: First, feature detection is still conducted on intensity frames in the initialization and re-detection stage. If more features are needed, but intensity images have not arrived, the accuracy of high-level tasks, such as VO and SLAM, may be affected. Therefore, feature detection on event frames still needs to be further explored. Second, the final goal of event-frame-based feature tracking is to improve the robustness in challenging environments or motions. Thus, future work will focus on the application of WF-MHT-BP on high-level tasks, such as event-camera-based localization and mapping applications.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}