
Fine Resolution Imagery and LIDAR-Derived Canopy Heights Accurately Classify Land Cover with a Focus on Shrub/Sapling Cover in a Mountainous Landscape


Abstract
:1. Introduction
2. Materials and Methods
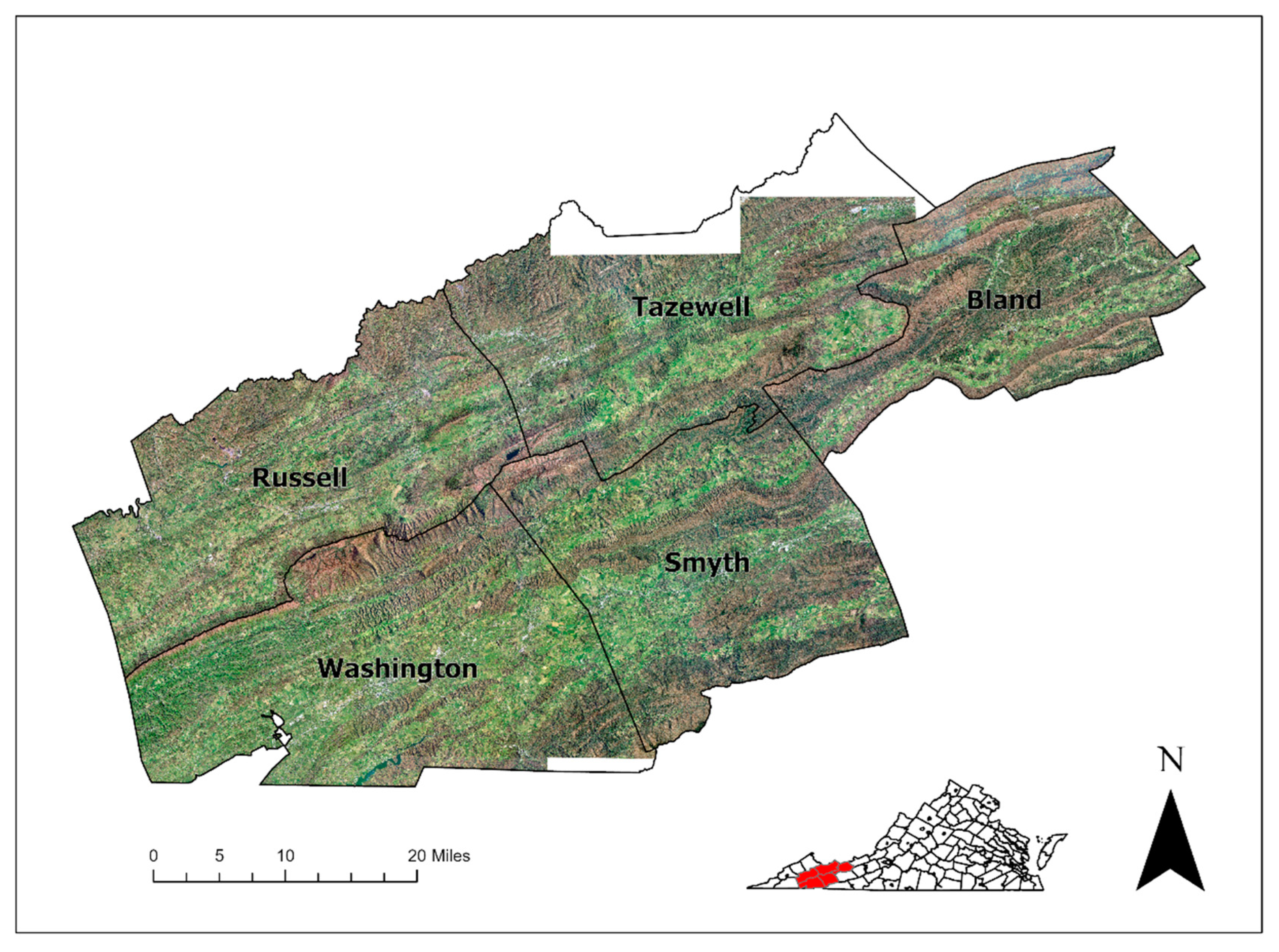
2.1. Study Area
2.2. Predictor Raster Acquisition and Processing
2.3. Training Data
2.4. Random Forest Classification
2.5. Accuracy Assessment
2.6. Comparison with Publicly Available Land Cover Data
3. Results
3.1. Classification Accuracy
3.2. Predictor Importance
3.3. Comparison with Publicly Available Land Cover Data
4. Discussion
4.1. Comparison with Publicly Available Land Cover Data
4.2. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- With, K. Essentials of Landscape Ecology; Oxford University Press: Oxford, UK, 2019; ISBN 978-0198838395. [Google Scholar]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 national land cover database for the conterminous United States—Representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar] [CrossRef]
- Grêt-Regamey, A.; Weibel, B.; Bagstad, K.J.; Ferrari, M.; Geneletti, D.; Klug, H.; Schirpke, U.; Tappeiner, U. On the effects of scale for ecosystem services mapping. PLoS ONE 2014, 9, e112601. [Google Scholar] [CrossRef] [PubMed]
- Rioux, J.F.; Cimon-Morin, J.; Pellerin, S.; Alard, D.; Poulin, M. How land cover spatial resolution affects mapping of urban ecosystem service flows. Front. Environ. Sci. 2019, 7, 93. [Google Scholar] [CrossRef]
- Xie, Y.; Sha, Z.; Yu, M. Remote sensing imagery in vegetation mapping: A review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- Moskal, L.M.; Styers, D.M.; Halabisky, M. Monitoring urban tree cover using object-based image analysis and public domain remotely sensed data. Remote Sens. 2011, 3, 2243–2262. [Google Scholar] [CrossRef] [Green Version]
- Hayes, M.M.; Miller, S.N.; Murphy, M.A. High-resolution landcover classification using random forest. Remote Sens. Lett. 2014, 5, 112–121. [Google Scholar] [CrossRef]
- Gonçalves, J.; Henriques, R.; Alves, P.; Sousa-Silva, R.; Monteiro, A.T.; Lomba, Â.; Marcos, B.; Honrado, J. Evaluating an unmanned aerial vehicle-based approach for assessing habitat extent and condition in fine-scale early successional mountain mosaics. Appl. Veg. Sci. 2016, 19, 132–146. [Google Scholar] [CrossRef] [Green Version]
- Davies, K.W.; Petersen, S.L.; Johnson, D.D.; Davis, D.B.; Madsen, M.D.; Zvirzdin, D.L.; Bates, J.D. Estimating juniper cover from national agriculture imagery program (NAIP) imagery and evaluating relationships between potential cover and environmental variables. Rangel. Ecol. Manag. 2010, 63, 630–637. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Zégre, N.P.; Yuill, C.B. Comparison of NAIP orthophotography and rapideye satellite imagery for mapping of mining and mine reclamation. GIScience Remote Sens. 2014, 51, 301–320. [Google Scholar] [CrossRef]
- Hurskainen, P.; Adhikari, H.; Siljander, M.; Pellikka, P.K.E.; Hemp, A. Auxiliary datasets improve accuracy of object-based land use/land cover classification in heterogeneous savanna landscapes. Remote Sens. Environ. 2019, 233, 111354. [Google Scholar] [CrossRef]
- Laliberte, A.S.; Rango, A. Texture and scale in object-based analysis of subdecimeter resolution unmanned aerial vehicle (UAV) imagery. IEEE Trans. Geosci. Remote Sens. 2009, 47, 761–770. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Aguirre-Gutiérrez, J.; Seijmonsbergen, A.C.; Duivenvoorden, J.F. Optimizing land cover classification accuracy for change detection, a combined pixel-based and object-based approach in a mountainous area in Mexico. Appl. Geogr. 2012, 34, 29–37. [Google Scholar] [CrossRef] [Green Version]
- Salehi, B.; Zhang, Y.; Zhong, M. A combined object- and pixel-based Image Analysis Framework for Urban Land Cover classifiation of VHR Imagery. Photogramm. Eng. Remote Sens. 2013, 79, 999–1014. [Google Scholar] [CrossRef]
- Martinuzzi, S.; Vierling, L.A.; Gould, W.A.; Falkowski, M.J.; Evans, J.S.; Hudak, A.T.; Vierling, K.T. Mapping snags and understory shrubs for a LiDAR-based assessment of wildlife habitat suitability. Remote Sens. Environ. 2009, 113, 2533–2546. [Google Scholar] [CrossRef] [Green Version]
- Estornell, J.; Ruiz, L.A.; Velázquez-Martí, B.; Hermosilla, T. Estimation of biomass and volume of shrub vegetation using LiDAR and spectral data in a Mediterranean environment. Biomass Bioenergy 2012, 46, 710–721. [Google Scholar] [CrossRef] [Green Version]
- Potapov, P.; Li, X.; Hernandez-Serna, A.; Tyukavina, A.; Hansen, M.C.; Kommareddy, A.; Pickens, A.; Turubanova, S.; Tang, H.; Silva, C.E.; et al. Mapping global forest canopy height through integration of GEDI and Landsat data. Remote Sens. Environ. 2021, 253, 112165. [Google Scholar] [CrossRef]
- U.S. Geological Survey. The National Map—New Data Delivery Homepage, Advanced Viewer, Lidar Visualization: US. Geological Survey Fact Sheet 2019–3032; U.S. Geological Survey: Reston, VA, USA, 2019; Volume 2.
- Greaves, H.E.; Vierling, L.A.; Eitel, J.U.H.; Boelman, N.T.; Magney, T.S.; Prager, C.M.; Griffin, K.L. High-resolution mapping of aboveground shrub biomass in Arctic tundra using airborne lidar and imagery. Remote Sens. Environ. 2016, 184, 361–373. [Google Scholar] [CrossRef]
- Cleve, C.; Kelly, M.; Kearns, F.R.; Moritz, M. Classification of the wildland-urban interface: A comparison of pixel- and object-based classifications using high-resolution aerial photography. Comput. Environ. Urban Syst. 2008, 32, 317–326. [Google Scholar] [CrossRef]
- Askins, R.A. Sustaining biological diversity in early successional communities: The challange of managing unpopular habitats. Wildl. Soc. Bull. 2001, 29, 407–412. [Google Scholar] [CrossRef]
- King, D.I.; Schlossberg, S. Synthesis of the conservation value of the early-successional stage in forests of eastern North America. For. Ecol. Manage. 2014, 324, 186–195. [Google Scholar] [CrossRef]
- Besnard, S.; Carvalhais, N.; Arain, M.A.; Black, A.; De Bruin, S.; Buchmann, N.; Cescatti, A.; Chen, J.; Clevers, J.G.P.W.; Desai, A.R.; et al. Quantifying the effect of forest age in annual net forest carbon balance. Environ. Res. Lett. 2018, 13, 124018. [Google Scholar] [CrossRef] [Green Version]
- Ciais, P.; Dolman, A.J.; Bombelli, A.; Duren, R.; Peregon, A.; Rayner, P.J.; Miller, C.; Gobron, N.; Kinderman, G.; Marland, G.; et al. Current systematic carbon-cycle observations and the need for implementing a policy-relevant carbon observing system. Biogeosciences 2014, 11, 3547–3602. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.K.; Vogler, J.B.; Shoemaker, D.A.; Meentemeyer, R.K. LiDAR-Landsat data fusion for large-area assessment of urban land cover: Balancing spatial resolution, data volume and mapping accuracy. ISPRS J. Photogramm. Remote Sens. 2012, 74, 110–121. [Google Scholar] [CrossRef]
- Hartfield, K.A.; Landau, K.I.; van Leeuwen, W.J.D. Fusion of high resolution aerial multispectral and lidar data: Land cover in the context of urban mosquito habitat. Remote Sens. 2011, 3, 2364–2383. [Google Scholar] [CrossRef] [Green Version]
- Ucar, Z.; Bettinger, P.; Merry, K.; Akbulut, R.; Siry, J. Estimation of urban woody vegetation cover using multispectral imagery and LiDAR. Urban For. Urban Green. 2018, 29, 248–260. [Google Scholar] [CrossRef]
- Buehler, D.A.; Roth, A.M.; Vallender, R.; Will, T.C.; Confer, J.L.; Canterbury, R.A.; Swarthout, S.B.; Rosenberg, K.V.; Bulluck, L.P. Status and conservation priorities of Golden-winged Warbler (Vermivora chrysoptera) in North America. Auk 2007, 124, 1439–1445. [Google Scholar] [CrossRef]
- Albrecht-Mallinger, D.J.; Bulluck, L.P. Limited evidence for conspecific attraction in a low-density population of a declining songbird, the Golden-winged Warbler (Vermivora chrysoptera). Condor 2016, 118, 451–462. [Google Scholar] [CrossRef]
- WorldView Solutions, Inc. Technical Plan of Operations: Virginia Statewide Land Cover Data Development; WorldView Solutions: Richmond, VA, USA, 2016. [Google Scholar]
- Rose, A.K. Virginia’s forests, 2001. In Resource Bulletin SRS-120; US Department of Agriculture Forest Service, Southern Research Station: Asheville, NC, USA, 2007; 140p. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Ramezan, C.A.; Morgan, A.N.; Pauley, C.E. Large-area, high spatial resolution land cover mapping using random forests, GEOBIA, and NAIP orthophotography: Findings and recommendations. Remote Sens. 2019, 11, 1409. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Shao, G. Object-based land-cover mapping with high resolution aerial photography at a county scale in midwestern USA. Remote Sens. 2014, 6, 11372–11390. [Google Scholar] [CrossRef] [Green Version]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E. Evaluation of sampling and cross-validation tuning strategies for regional-scale machine learning classification. Remote Sens. 2019, 11, 185. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Lu, D.; Wu, M.; Zhang, Y.; Lu, L. Coastal wetland classification with multiseasonal high-spatial resolution satellite imagery. Int. J. Remote Sens. 2018, 39, 8963–8983. [Google Scholar] [CrossRef]
- Xie, Z.; Chen, Y.; Lu, D.; Li, G.; Chen, E. Classification of land cover, forest, and tree species classes with Ziyuan-3 multispectral and stereo data. Remote Sens. 2019, 11, 164. [Google Scholar] [CrossRef] [Green Version]
- Defries, R.S.; Townshend, J.R. Ndvi-Derived Land Cover Classifications At a Global Scale. Int. J. Remote Sens. 1994, 15, 3567–3586. [Google Scholar] [CrossRef]
- Schold, E.K. Using a Custom Landscape Classification to Understand the Factors Driving Site Occupancy by a Rapidly Declining Migratory Songbird. Master’s Thesis, Virginia Commonwealth University, Richmond, VA, USA, 2018. [Google Scholar]
- Timm, B.C.; McGarigal, K. Fine-scale remotely-sensed cover mapping of coastal dune and salt marsh ecosystems at Cape Cod National Seashore using Random Forests. Remote Sens. Environ. 2012, 127, 106–117. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 6 January 2022).
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Random For. 2019, 45, 5–32. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Hijmans, R.J.; van Etten, J. Raster: Geographic Analysis and Modeling with Raster Data. R Packag. Version 2.7-15. 2018. Available online: http://CRAN.R-project.org/package=raster (accessed on 6 January 2022).
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Hesselbarth, M.H.K.; Sciaini, M.; With, K.A.; Wiegand, K.; Nowosad, J. landscapemetrics: An open-source R tool to calculate landscape metrics. Ecography 2019, 42, 1648–1657. [Google Scholar] [CrossRef] [Green Version]
- Koetz, B.; Morsdorf, F.; van der Linden, S.; Curt, T.; Allgöwer, B. Multi-source land cover classification for forest fire management based on imaging spectrometry and LiDAR data. For. Ecol. Manag. 2008, 256, 263–271. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C. Tree, shrub, and grass classification using only RGB images. Remote Sens. 2020, 12, 1333. [Google Scholar] [CrossRef] [Green Version]
- Dewitz, J. National Land Cover Database (NLCD) 2016 Products (version 2.0, July 2020); Data Release; U.S. Geological Survey: Seattle, WA, USA, 2019. [CrossRef]
- Thatcher, C.A.; Lukas, V.; Stoker, J.M. The 3D Elevation Program and Energy for the Nation; Fact Sheet; United States Geological Survey: Seattle, WA, USA, 2020. [CrossRef]
- Loveland, T.R.; Merchant, J.W.; Ohlen, D.O.; Brown, J.F. Development of a land-cover characteristics database for the conterminous US. Photogramm. Eng. Remote Sens. 1991, 57, 1453–1463. [Google Scholar]
- Hunt, E.R. Relationship between woody biomass and PAR conversion efficiency for estimating net primary production from NDVI. Int. J. Remote Sens. 1994, 15, 1725–1730. [Google Scholar]
- Coops, N.C.; Johnson, M.; Wulder, M.A.; White, J.C. Assessment of QuickBird high spatial resolution imagery to detect red attack damage due to mountain pine beetle infestation. Remote Sens. Environ. 2006, 103, 67–80. [Google Scholar] [CrossRef]
- Verbesselt, J.; Hyndman, R.; Newnham, G.; Culvenor, D. Detecting trend and seasonal changes in satellite image time series. Remote Sens. Environ. 2010, 114, 106–115. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Soubry, I.; Doan, T.; Chu, T.; Guo, X. A systematic review on the integration of remote sensing and gis to forest and grassland ecosystem health attributes, indicators, and measures. Remote Sens. 2021, 13, 3262. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Vanderbilt, B.C.; Ramezan, C.A. Land cover classification and feature extraction from National Agriculture Imagery Program (NAIP) Orthoimagery: A review. Photogramm. Eng. Remote Sens. 2017, 83, 737–747. [Google Scholar] [CrossRef]
- Van Iersel, W.; Straatsma, M.; Middelkoop, H.; Addink, E. Multitemporal classification of river floodplain vegetation using time series of UAV images. Remote Sens. 2018, 10, 1144. [Google Scholar] [CrossRef] [Green Version]
- Morgan, B.E.; Chipman, J.W.; Bolger, D.T.; Dietrich, J.T. Spatiotemporal analysis of vegetation cover change in a large ephemeral river: Multi-sensor fusion of unmanned aerial vehicle (uav) and landsat imagery. Remote Sens. 2021, 13, 51. [Google Scholar] [CrossRef]
- Newman, E.A. Disturbance Ecology in the Anthropocene. Front. Ecol. Evol. 2019, 7, 147. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, R.E.; Andréfouët, S.; Cohen, W.B.; Gómez, C.; Griffiths, P.; Hais, M.; Healey, S.P.; Helmer, E.H.; Hostert, P.; Lyons, M.B.; et al. Bringing an ecological view of change to landsat-based remote sensing. Front. Ecol. Environ. 2014, 12, 339–346. [Google Scholar] [CrossRef]
- Pazúr, R.; Price, B.; Atkinson, P.M. Fine temporal resolution satellite sensors with global coverage: An opportunity for landscape ecologists. Landsc. Ecol. 2021, 36, 2199–2213. [Google Scholar] [CrossRef]
- Anderson, K.; Gaston, K.J. Lightweight unmanned aerial vehicles will revolutionize spatial ecology. Front. Ecol. Environ. 2013, 11, 138–146. [Google Scholar] [CrossRef] [Green Version]
- Almeida, D.R.A.; Broadbent, E.N.; Zambrano, A.M.A.; Wilkinson, B.E.; Ferreira, M.E.; Chazdon, R.; Meli, P.; Gorgens, E.B.; Silva, C.A.; Stark, S.C.; et al. Monitoring the structure of forest restoration plantations with a drone-lidar system. Int. J. Appl. Earth Obs. Geoinf. 2019, 79, 192–198. [Google Scholar] [CrossRef]
- Leipe, S.C.; Carey, S.K. Rapid shrub expansion in a subarctic mountain basin revealed by repeat airborne lidar. Environ. Res. Commun. 2021, 3, 071001. [Google Scholar] [CrossRef]
- Wu, J.; Shen, W.; Sun, W.; Tueller, P.T. Empirical patterns of the effects of changing scale on landscape metrics. Landsc. Ecol. 2002, 17, 761–782. [Google Scholar] [CrossRef]
- Wu, J. Effects of changing scale on landscape pattern analysis: Scaling relations. Landsc. Ecol. 2004, 19, 125–138. [Google Scholar] [CrossRef]
- Wagner, H.H.; Fortin, M.J. Spatial analysis of landscapes: Concepts and statistics. Ecology 2005, 86, 1975–1987. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.; Homer, C.; Yang, L.; Danielson, P.; Dewitz, J.; Li, C.; Zhu, Z.; Xian, G.; Howard, D. Overall methodology design for the United States national land cover database 2016 products. Remote Sens. 2019, 11, 2971. [Google Scholar] [CrossRef] [Green Version]
- Lesak, A.A.; Radeloff, V.C.; Hawbaker, T.J.; Pidgeon, A.M.; Gobakken, T.; Contrucci, K. Modeling forest songbird species richness using LiDAR-derived measures of forest structure. Remote Sens. Environ. 2011, 115, 2823–2835. [Google Scholar] [CrossRef]
- Stickley, S.F.; Fraterrigo, J.M. Understory vegetation contributes to microclimatic buffering of near-surface temperatures in temperate deciduous forests. Landsc. Ecol. 2021, 36, 1197–1213. [Google Scholar] [CrossRef]
- Johnson, K.D.; Domke, G.M.; Russell, M.B.; Walters, B.; Hom, J.; Peduzzi, A.; Birdsey, R.; Dolan, K.; Huang, W. Estimating aboveground live understory vegetation carbon in the United States. Environ. Res. Lett. 2017, 12, 125010. [Google Scholar] [CrossRef] [Green Version]
- Venier, L.A.; Swystun, T.; Mazerolle, M.J.; Kreutzweiser, D.P.; Wainio-Keizer, K.L.; McIlwrick, K.A.; Woods, M.E.; Wang, X. Modelling vegetation understory cover using LiDAR metrics. PLoS ONE 2019, 14, e0220096. [Google Scholar] [CrossRef] [Green Version]
- Gonçalves, J.; Pôças, I.; Marcos, B.; Mücher, C.A.; Honrado, J.P. SegOptim—A new R package for optimizing object-based image analyses of high-spatial resolution remotely-sensed data. Int. J. Appl. Earth Obs. Geoinf. 2019, 76, 218–230. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Water | Developed | Barren | Dec Forest | EG Forest | Shrub/Sapling | Pasture | N | Users% | ||
| Prediction | water | 161 | 14 | 3 | 3 | 0 | 1 | 2 | 184 | 0.88 |
| developed | 2 | 367 | 16 | 3 | 0 | 9 | 12 | 409 | 0.90 | |
| barren | 0 | 33 | 339 | 3 | 0 | 7 | 32 | 414 | 0.82 | |
| Dec forest | 0 | 0 | 2 | 433 | 19 | 3 | 2 | 459 | 0.94 | |
| EG forest | 0 | 0 | 0 | 77 | 366 | 5 | 1 | 449 | 0.82 | |
| Shrub/sapling | 0 | 2 | 2 | 9 | 2 | 326 | 11 | 352 | 0.93 | |
| pasture | 0 | 2 | 6 | 4 | 0 | 11 | 440 | 463 | 0.95 | |
| N | 163 | 418 | 368 | 532 | 387 | 362 | 500 | 2730 | ||
| prod% | 0.99 | 0.88 | 0.92 | 0.81 | 0.95 | 0.90 | 0.88 | 0.8908 | ||
| Predictor Variable | Water | Developed | Barren | Deciduous Forest | Evergreen Forest | Shrub/Sapling | Pasture/Grassland | Average |
|---|---|---|---|---|---|---|---|---|
| Canopy height model | 29.5 | 23.2 | 26.0 | 68.9 | 41.5 | 51.5 | 41.6 | 40.3 |
| NDVI | 33.5 | 30.5 | 19.8 | 19.9 | 30.0 | 30.8 | 31.6 | 28.0 |
| NAIP_NIR | 22.2 | 20.0 | 15.8 | 18.9 | 19.5 | 17.9 | 31.3 | 20.8 |
| NAIP_Blue | 12.9 | 33.4 | 16.8 | 17.4 | 15.7 | 16.9 | 16.1 | 18.5 |
| NAIP_Green | 6.1 | 18.9 | 20.3 | 17.2 | 17.0 | 17.2 | 24.8 | 17.4 |
| NAIP_Red | 7.2 | 18.8 | 20.3 | 18.2 | 19.8 | 16.4 | 17.4 | 16.9 |
| VBMP_Red | 13.0 | 15.9 | 17.7 | 19.4 | 20.6 | 20.1 | 14.5 | 17.3 |
| VBMP_Green | 7.6 | 14.8 | 13.7 | 15.1 | 10.8 | 15.6 | 18.3 | 13.7 |
| Elevation | 15.0 | 15.9 | 9.5 | 16.7 | 14.2 | 14.9 | 10.3 | 13.8 |
| VBMP_Blue | 11.4 | 20.5 | 8.3 | 16.3 | 13.2 | 14.6 | 11.5 | 13.7 |
| Slope | 19.2 | 17.6 | 6.9 | 8.1 | 8.2 | 8.8 | 9.9 | 11.2 |
| Texture | 19.5 | 10.0 | 8.0 | 10.0 | 9.2 | 9.7 | 9.7 | 10.9 |
| Aspect | 6.9 | 9.9 | 9.0 | 8.0 | 8.6 | 4.1 | 8.2 | 7.8 |
| Land Cover Class | Tazewell | Smyth | Bland | Russell | Washington | Average | |
|---|---|---|---|---|---|---|---|
| Custom Classification | Water | 0.53 | 0.34 | 0.32 | 0.76 | 0.86 | 0.56 |
| Developed | 2.75 | 2.02 | 2.18 | 2.34 | 1.60 | 2.18 | |
| Barren | 2.04 | 0.95 | 2.53 | 2.16 | 3.97 | 2.33 | |
| Decid + mixed forest | 56.91 | 57.27 | 65.85 | 46.95 | 45.01 | 54.40 | |
| Evergreen forest | 2.85 | 4.66 | 6.45 | 9.59 | 10.06 | 6.72 | |
| All forest | 59.76 | 61.93 | 72.30 | 56.54 | 55.07 | 61.12 | |
| Shrub/sapling | 6.10 | 5.58 | 3.91 | 7.46 | 3.75 | 5.36 | |
| Pasture/grassland | 28.82 | 29.18 | 18.76 | 30.74 | 34.75 | 28.45 | |
| NLCD | Water | 0.06 | 0.07 | 0.03 | 0.34 | 0.56 | 0.21 |
| Developed | 7.42 | 5.79 | 3.20 | 5.78 | 7.56 | 5.95 | |
| Barren | 0.37 | 0.60 | 0.30 | 0.37 | 0.50 | 0.43 | |
| Decid + mixed forest | 65.42 | 66.89 | 73.33 | 58.62 | 58.01 | 64.45 | |
| Evergreen forest | 4.26 | 1.55 | 2.93 | 2.71 | 1.12 | 2.52 | |
| All forest | 69.68 | 68.44 | 76.26 | 61.33 | 59.13 | 66.97 | |
| Shrub | 0.58 | 0.55 | 0.53 | 1.13 | 0.62 | 0.68 | |
| Pasture/grassland | 21.74 | 24.38 | 19.50 | 31.01 | 31.48 | 25.62 | |
| Wetlands | 0.16 | 0.17 | 0.17 | 0.04 | 0.15 | 0.14 | |
| VLCD | Water | 0.23 | 0.21 | 0.21 | 0.56 | 0.73 | 0.30 |
| Developed | 2.45 | 1.95 | 1.21 | 2.17 | 2.89 | 1.95 | |
| Barren | 0.42 | 0.02 | 0.05 | 0.34 | 0.09 | 0.21 | |
| Decid + EG forest | 68.51 | 67.71 | 77.51 | 59.34 | 56.25 | 68.27 | |
| Tree a | 5.09 | 4.73 | 2.71 | 5.08 | 5.81 | 4.40 | |
| Harvested | 0.65 | 0.26 | 0.32 | 0.82 | 0.31 | 0.51 | |
| Shrub | 1.03 | 0.74 | 0.60 | 1.36 | 0.85 | 0.93 | |
| Pasture/grassland | 21.34 | 24.17 | 17.3 | 30.25 | 32.86 | 23.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bulluck, L.; Lin, B.; Schold, E. Fine Resolution Imagery and LIDAR-Derived Canopy Heights Accurately Classify Land Cover with a Focus on Shrub/Sapling Cover in a Mountainous Landscape. Remote Sens. 2022, 14, 1364. https://doi.org/10.3390/rs14061364
Bulluck L, Lin B, Schold E. Fine Resolution Imagery and LIDAR-Derived Canopy Heights Accurately Classify Land Cover with a Focus on Shrub/Sapling Cover in a Mountainous Landscape. Remote Sensing. 2022; 14(6):1364. https://doi.org/10.3390/rs14061364
Chicago/Turabian StyleBulluck, Lesley, Baron Lin, and Elizabeth Schold. 2022. "Fine Resolution Imagery and LIDAR-Derived Canopy Heights Accurately Classify Land Cover with a Focus on Shrub/Sapling Cover in a Mountainous Landscape" Remote Sensing 14, no. 6: 1364. https://doi.org/10.3390/rs14061364