
Hyperspectral Image Classification Promotion Using Clustering Inspired Active Learning
 , , , and
, , , and
Abstract
:1. Introduction
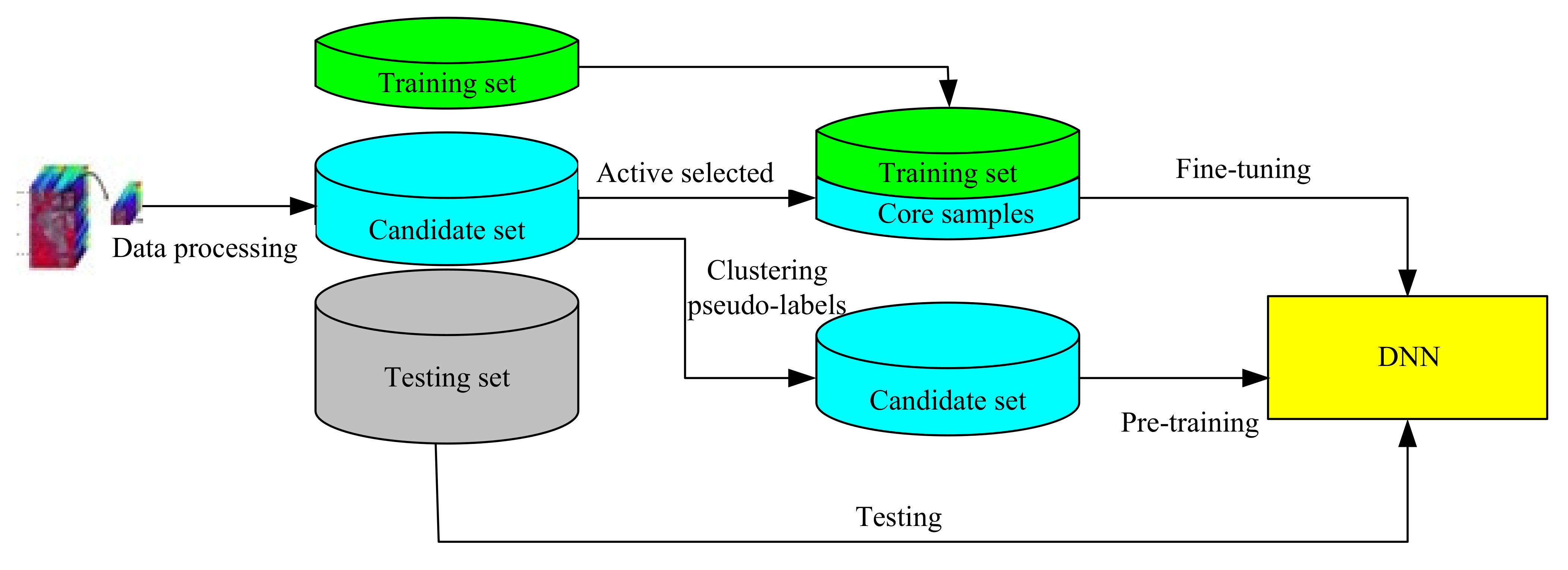
2. The Proposed Method
2.1. Data Pre-Processing
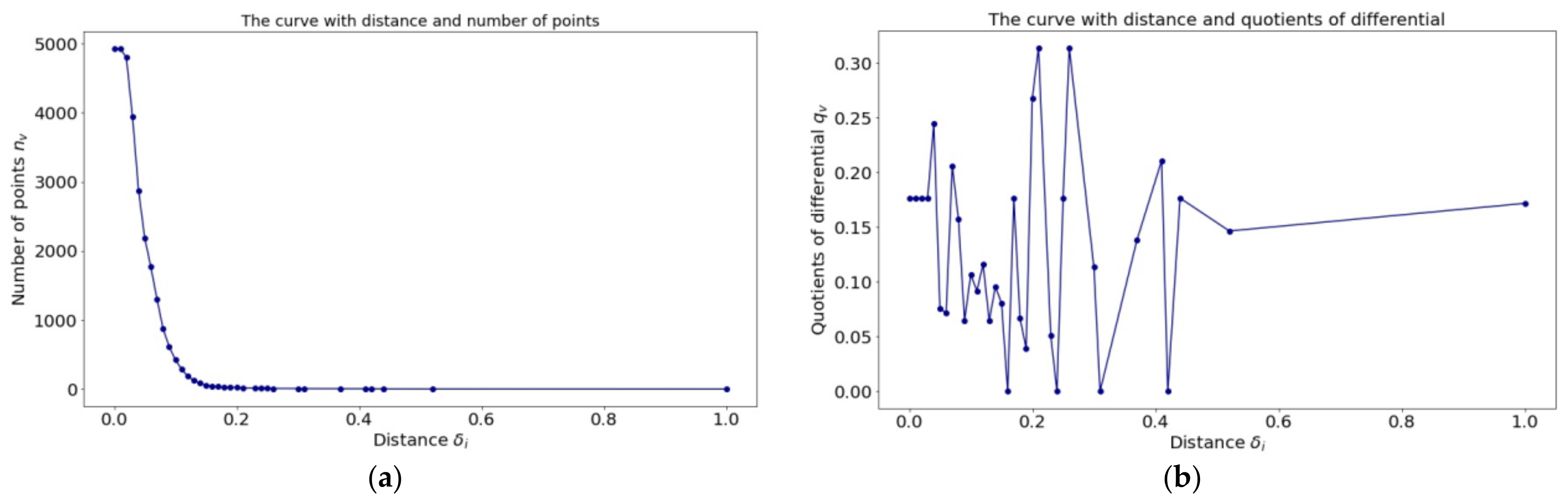
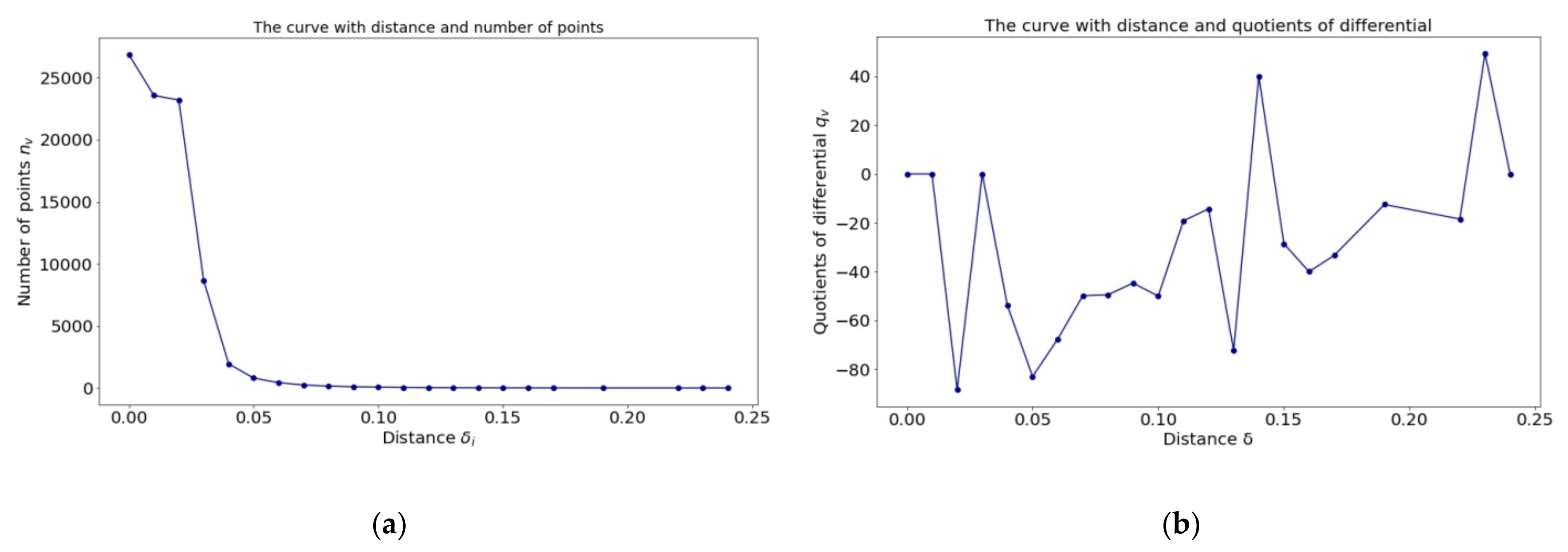
2.2. Actively Selecting Core Samples via MCFSFDP
2.3. K-Means Clustering-Based Pseudo-Labeling Scheme
2.4. Fine-Tuning and Testing
3. Experiments and Analysis
3.1. Datasets
3.2. Experimental Parameter Settings
3.3. Experimental Results
3.3.1. Effectiveness of the Core Samples Actively Selected via MCFSFDP
3.3.2. Effectiveness of the Proposed Method-Based on Actively Selected Core Samples
3.3.3. Effectiveness of Pre-Training by Testing Samples with Pseudo-Labels
3.3.4. The Proposed Method Compared with the Other Methods
4. Discussion
4.1. Influence of the Network Training Iterations
4.2. Influence of the Number of Clusters and Iterations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Landgrebe, D. Hyperspectral image data analysis. IEEE Signal Process. Mag. 2002, 19, 17–28. [Google Scholar] [CrossRef]
- Shaw, G.; Manolakis, D. Signal processing for hyperspectral image exploitation. IEEE Signal Process. Mag. 2002, 19, 12–16. [Google Scholar] [CrossRef]
- Myasnikov, E.V. Hyperspectral image segmentation using dimensionality reduction and classical segmentation approaches. Samara Natl. Res. 2017, 41, 564–572. [Google Scholar] [CrossRef]
- Andriyanov, N.; Dementiev, V.; Gladkikh, A. Analysis of the Pattern Recognition Efficiency on Non-Optical Images. In Proceedings of the 2021 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 13–14 May 2021; pp. 0319–0323. [Google Scholar]
- Lazcano, R.; Madronal, D.; Florimbi, G.; Sancho, J.; Sanchez, S.; Leon, R.; Fabelo, H.; Ortega, S.; Torti, E.; Salvador, R.; et al. Parallel Implementations Assessment of a Spatial-Spectral Classifier for Hyperspectral Clinical Applications. IEEE Access 2019, 7, 152316–152333. [Google Scholar] [CrossRef]
- Eismann, M.T.; Hardie, R.C. Application of the stochastic mixing model to hyperspectral resolution enhancement. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1924–1933. [Google Scholar] [CrossRef]
- Chang, C.-I. An information-theoretic approach to spectral variability, similarity, and discrimination for hyperspectral image analysis. IEEE Trans. Inf. Theory 2000, 46, 1927–1932. [Google Scholar] [CrossRef] [Green Version]
- Jia, X.; Richards, J.A. Efficient maximum likelihood classification for imaging spectrometer data sets. IEEE Trans. Geosci. Remote Sens. 1994, 32, 274–281. [Google Scholar]
- Chen, S.; Gunn, S.R.; Harris, C.J. The relevance vector machine technique for channel equalization application. IEEE Trans. Neural Netw. 2001, 12, 1529–1532. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised Hyperspectral Image Segmentation Using Multinomial Logistic Regression with Active Learning. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4085–4098. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral Image Classification via Kernel Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 217–231. [Google Scholar] [CrossRef] [Green Version]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral–Spatial Hyperspectral Image Classification via Multiscale Adaptive Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7738–7749. [Google Scholar] [CrossRef]
- Baassou, B.; He, M.; Mei, S.; Zhang, Y. Unsupervised hyperspectral image classification algorithm by integrating spatial-spectral information. In Proceedings of the 2012 International Conference on Audio, Language and Image Processing, Shanghai, China, 16–18 July 2012; pp. 610–615. [Google Scholar]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Wei, Z.; Xu, Y. A Lightweight Spectral–Spatial Feature Extraction and Fusion Network for Hyperspectral Image Classification. Remote Sens. 2020, 12, 1395. [Google Scholar] [CrossRef]
- Ma, W.; Ma, H.; Zhu, H.; Li, Y.; Li, L.; Jiao, L.; Hou, B. Hyperspectral Image Classification Based on Spatial and Spectral Kernels Generation Network. Inf. Sci. 2021, 578, 435–456. [Google Scholar] [CrossRef]
- Hang, R.; Li, Z.; Liu, Q.; Ghamisi, P.; Bhattacharyya, S.S. Hyperspectral image classification with attention aided CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2281–2293. [Google Scholar] [CrossRef]
- Abdulsamad, T.; Chen, F.; Xue, Y.; Wang, Y.; Zeng, D. Hyperspectral image classification based on spectral and spatial information using resnet with channel attention. Opt. Quantum Electron. 2021, 53, 1–20. [Google Scholar] [CrossRef]
- Pande, S.; Banerjee, B. Adaptive hybrid attention network for hyperspectral image classification. Pattern Recognit. Lett. 2021, 144, 6–12. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual spectral-spatial attention network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–Spatial Classification of Hyperspectral Data Based on Deep Belief Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Zhao, Y.; Chan, J.C.-W.; Yi, C. Hyperspectral image classification using two-channel deep convolutional neural network. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5079–5082. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Chan, T.-H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, C.; Li, Y.; Xia, Y.; Wei, W.; Zhang, L.; Zhang, Y. Convolutional Neural Networks Based Hyperspectral Image Classification Method with Adaptive Kernels. Remote Sens. 2017, 9, 618. [Google Scholar] [CrossRef] [Green Version]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A Survey of Clustering Algorithms for Big Data: Taxonomy and Empirical Analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Zhang, G.; Zhao, S.; Li, W.; Du, Q.; Ran, Q.; Tao, R. HTD-Net: A Deep Convolutional Neural Network for Target Detection in Hyperspectral Imagery. Remote Sens. 2020, 12, 1489. [Google Scholar] [CrossRef]
- Wei, Y.; Zhou, Y. Spatial-Aware Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3232. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral image classification using deep pixel-pair features. IEEE Trans. Geosci. Remote Sens. 2016, 55, 844–853. [Google Scholar] [CrossRef]
- Kemker, R.; Kanan, C. Self-Taught Feature Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2693–2705. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-spatial residual network for hyperspectral image classification: A 3-d deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Fang, B.; Li, Y.; Zhang, H.; Chan, J.C.-W. Hyperspectral Images Classification Based on Dense Convolutional Networks with Spectral-Wise Attention Mechanism. Remote Sens. 2019, 11, 159. [Google Scholar] [CrossRef] [Green Version]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J.; Pla, F. Capsule networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2145–2160. [Google Scholar] [CrossRef]
- Li, W.; Wei, W.; Zhang, L.; Wang, C.; Zhang, Y. Unsupervised deep domain adaptation for hyperspectral image classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, W.; Chen, Y.; He, X.; Li, Z. Soft Augmentation-Based Siamese CNN for Hyperspectral Image Classification with Limited Training Samples. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Cui, Y.; Yu, Z.; Han, J.; Gao, S.; Wang, L. Dual-Triple Attention Network for Hyperspectral Image Classification Using Limited Training Samples. IEEE Geosci. Remote Sens. Lett. 2021. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the ICLR 2016: International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [Green Version]
- Hyperspectral Remote Sensing Scenes. Available online: http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes (accessed on 10 December 2021).
- Olden, J.D.; Jackson, D.A. Illuminating the “black box”: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002, 154, 135–150. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Samples | ||||
|---|---|---|---|---|---|
| Number | Classes | Total | Training | Candidate | Testing |
| 1 | Alfalfa | 46 | 6 | 17 | 23 |
| 2 | Corn-notill | 1428 | 26 | 688 | 714 |
| 3 | Corn-mintill | 830 | 12 | 403 | 415 |
| 4 | Corn | 237 | 7 | 112 | 118 |
| 5 | Grass-pasture | 483 | 8 | 234 | 241 |
| 6 | Grass-trees | 730 | 16 | 349 | 365 |
| 7 | Grass-pasture-mowed | 28 | 5 | 9 | 14 |
| 8 | Hay-windrowed | 478 | 13 | 226 | 239 |
| 9 | Oats | 20 | 5 | 5 | 10 |
| 10 | Soybean-notill | 972 | 12 | 474 | 486 |
| 11 | Soybean-mintill | 2455 | 38 | 1190 | 1227 |
| 12 | Soybean-clean | 593 | 11 | 286 | 296 |
| 13 | Wheat | 205 | 7 | 96 | 102 |
| 14 | Woods | 1265 | 15 | 618 | 632 |
| 15 | Building-Grass-Trees | 386 | 12 | 181 | 193 |
| 16 | Stone-Steel-Towers | 93 | 7 | 40 | 46 |
| Total | 10,249 | 200 | 4928 | 5121 | |
| Class | Samples | ||||
|---|---|---|---|---|---|
| Number | Classes | Total | Training | Candidate | Testing |
| 1 | Broccoli_green_weeds_1 | 2009 | 11 | 994 | 1004 |
| 2 | Broccoli_green_weeds_2 | 3726 | 16 | 1847 | 1863 |
| 3 | Fallow | 1976 | 12 | 976 | 988 |
| 4 | Fallow_rough_plow | 1394 | 10 | 687 | 697 |
| 5 | Fallow_smooth | 2678 | 11 | 1328 | 1339 |
| 6 | Stubble | 3959 | 19 | 1961 | 1979 |
| 7 | Celery | 3579 | 13 | 1777 | 1789 |
| 8 | Grapes_untrained | 11,271 | 14 | 5622 | 5635 |
| 9 | Soil_vinyard_develop | 6203 | 15 | 3087 | 3101 |
| 10 | Corn_senesced_green_weeds | 3278 | 10 | 1629 | 1639 |
| 11 | Lettuce_romaine_4wk | 1068 | 12 | 522 | 534 |
| 12 | Lettuce_romaine_5wk | 1927 | 13 | 951 | 963 |
| 13 | Lettuce_romaine_6wk | 916 | 10 | 448 | 458 |
| 14 | Lettuce_romaine_7wk | 1070 | 11 | 524 | 535 |
| 15 | Vinyard_untrained | 7268 | 15 | 3621 | 3634 |
| 16 | Vinyard_vertical_trellis | 1807 | 10 | 894 | 903 |
| Total | 54,129 | 200 | 26,868 | 27,061 | |
| Class | The Adaptive Distance Threshold | The Number of Selected Core Samples | Testing Accuracy (%) | |
|---|---|---|---|---|
| Randomly Selected Samples | Core Samples | |||
| 1 | 0.15 | 55 | 39.1 | 65.2 |
| 2 | 51.8 | 57.1 | ||
| 3 | 47.0 | 56.1 | ||
| 4 | 41.5 | 47.5 | ||
| 5 | 78.4 | 66.0 | ||
| 6 | 94.8 | 93.2 | ||
| 7 | 71.4 | 85.7 | ||
| 8 | 95.0 | 90.0 | ||
| 9 | 20.0 | 20.0 | ||
| 10 | 59.5 | 52.3 | ||
| 11 | 73.1 | 77.0 | ||
| 12 | 32.8 | 40.2 | ||
| 13 | 100.0 | 99.0 | ||
| 14 | 75.5 | 80.1 | ||
| 15 | 35.2 | 32.6 | ||
| 16 | 95.7 | 89.1 | ||
| OA (%) | 65.9 | 67.8 | ||
| AA (%) | 63.2 | 65.7 | ||
| Kappa | 61.1 | 64.2 | ||
| Class | The Adaptive Distance Threshold | The Number of Selected Core Samples | Testing Accuracy (%) | |
|---|---|---|---|---|
| Randomly Selected Samples | Core Samples | |||
| 1 | 0.12 | 40 | 99.0 | 95.0 |
| 2 | 97.0 | 99.4 | ||
| 3 | 45.1 | 66.5 | ||
| 4 | 99.7 | 99.6 | ||
| 5 | 78.3 | 94.2 | ||
| 6 | 99.6 | 99.1 | ||
| 7 | 99.2 | 98.3 | ||
| 8 | 88.2 | 82.3 | ||
| 9 | 94.5 | 96.8 | ||
| 10 | 67.5 | 74.6 | ||
| 11 | 91.6 | 99.1 | ||
| 12 | 97.0 | 97.0 | ||
| 13 | 99.0 | 99.0 | ||
| 14 | 90.8 | 90.5 | ||
| 15 | 45.8 | 55.8 | ||
| 16 | 88.0 | 84.6 | ||
| OA (%) | 83.1 | 85.6 | ||
| AA (%) | 86.3 | 89.5 | ||
| Kappa | 81.3 | 84.0 | ||
| Class | Testing Accuracy (%) | |
|---|---|---|
| Original Training Samples Set | Training Samples Set with Core Samples | |
| 1 | 47.8 | 65.2 |
| 2 | 47.3 | 57.1 |
| 3 | 49.6 | 56.1 |
| 4 | 44.1 | 47.5 |
| 5 | 29.9 | 66.0 |
| 6 | 92.6 | 93.2 |
| 7 | 85.7 | 85.7 |
| 8 | 93.3 | 90.0 |
| 9 | 20.0 | 20.0 |
| 10 | 30.2 | 52.3 |
| 11 | 69.4 | 77.0 |
| 12 | 29.4 | 40.2 |
| 13 | 100.0 | 99.0 |
| 14 | 74.5 | 80.1 |
| 15 | 31.1 | 32.6 |
| 16 | 93.5 | 89.1 |
| OA (%) | 58.9 | 67.8 |
| AA (%) | 58.5 | 65.7 |
| Kappa | 52.8 | 64.2 |
| Class | Testing Accuracy (%) | |
|---|---|---|
| Original Training Samples Set | Training Samples Set with Core Samples | |
| 1 | 99.1 | 95.0 |
| 2 | 97.5 | 99.4 |
| 3 | 55.9 | 66.5 |
| 4 | 99.7 | 99.6 |
| 5 | 73.0 | 94.2 |
| 6 | 99.6 | 99.1 |
| 7 | 99.2 | 98.3 |
| 8 | 90.1 | 82.3 |
| 9 | 96.0 | 96.8 |
| 10 | 64.2 | 74.6 |
| 11 | 94.2 | 99.1 |
| 12 | 98.4 | 97.0 |
| 13 | 98.7 | 99.0 |
| 14 | 90.5 | 90.5 |
| 15 | 30.0 | 55.8 |
| 16 | 83.5 | 84.6 |
| OA (%) | 81.7 | 85.6 |
| AA (%) | 56.6 | 89.5 |
| Kappa | 80.0 | 84.0 |
| The Number of Clusters | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
| Testing Accuracy OA (%) | 63.7 | 64.6 | 65.3 | 66.2 | 68.9 | 66.1 | 65.8 | 65.7 | 66.5 | 66.6 |
| The Number of Clusters | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
| Testing Accuracy OA (%) | 85.5 | 85.9 | 86.0 | 85.9 | 85.9 | 85.8 | 85.9 | 86.8 | 86.1 | 85.4 |
| Dataset 1 | Testing Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Random Selected Samples | K-Means Selected Samples | Minimum Probability Selected Samples | CFSFDP Selected Samples | MCFSFDP Selected Samples | Proposed Method | |
| OA (%) | 65.9 | 59.6 | 63.9 | 64.4 | 67.8 | 68.9 |
| Dataset 2 | Testing Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Random Selected Samples | K-Means Selected Samples | Minimum Probability Selected Samples | CFSFDP Selected Samples | MCFSFDP Selected Samples | Proposed Method | |
| OA (%) | 83.1 | 82.9 | 83.8 | 85.1 | 85.6 | 86.8 |
| Dataset | Epochs | Testing Accuracy OA (%) | |
|---|---|---|---|
| Original Training Set | Training Set with Core Samples | ||
| Indian Pines | 1000 | 56.1 | 61.7 |
| 2000 | 59.2 | 64.6 | |
| 3000 | 58.7 | 66.1 | |
| 4000 | 59.5 | 66.2 | |
| 5000 | 59.7 | 66.4 | |
| 6000 | 56.9 | 64.8 | |
| 7000 | 59.5 | 66.2 | |
| 8000 | 58.8 | 66.2 | |
| 9000 | 59.1 | 66.6 | |
| 10,000 | 58.8 | 67.6 | |
| 11,000 | 60.1 | 64.9 | |
| 12,000 | 59.3 | 67.6 | |
| 13,000 | 58.9 | 67.8 | |
| 14,000 | 59.4 | 67.7 | |
| 15,000 | 58.7 | 66.9 | |
| Dataset | Epochs | Testing Accuracy OA (%) | |
|---|---|---|---|
| Original Training Set | Training Set with Core Samples | ||
| Salinas | 1000 | 71.1 | 71.8 |
| 2000 | 79.2 | 78.1 | |
| 3000 | 80.6 | 81.5 | |
| 4000 | 81.3 | 82.8 | |
| 5000 | 82.2 | 84.0 | |
| 6000 | 82.9 | 84.1 | |
| 7000 | 82.2 | 84.7 | |
| 8000 | 82.2 | 84.6 | |
| 9000 | 82.4 | 85.4 | |
| 10,000 | 81.4 | 85.5 | |
| 11,000 | 81.7 | 85.6 | |
| 12,000 | 80.9 | 85.5 | |
| 13,000 | 79.6 | 85.4 | |
| 14,000 | 79.1 | 85.1 | |
| 15,000 | 78.5 | 85.2 | |
| Dataset | The Number of Clusters | Testing Accuracy OA (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Epochs | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 | ||
| Indian Pines | 1000 | 60.8 | 61.8 | 63.3 | 64.3 | 66.6 | 63.8 | 62.2 | 62.6 | 62.6 | 63.7 | |
| 2000 | 62.8 | 62.7 | 63.3 | 62.9 | 67.0 | 65.4 | 64.6 | 64.4 | 64.3 | 65.7 | ||
| 3000 | 62.4 | 63.3 | 62.8 | 63.6 | 68.1 | 63.7 | 64.7 | 65.1 | 66.1 | 65.7 | ||
| 4000 | 61.1 | 64.7 | 64.2 | 65.6 | 67.9 | 63.7 | 64.1 | 65.1 | 66.2 | 66.6 | ||
| 5000 | 62.2 | 64.6 | 64.1 | 64.9 | 67.7 | 64.8 | 62.9 | 65.4 | 66.2 | 66.6 | ||
| 6000 | 62.5 | 62.9 | 64.2 | 63.2 | 67.6 | 65.3 | 65.1 | 65.3 | 66.7 | 66.3 | ||
| 7000 | 63.7 | 64.3 | 64.4 | 64.8 | 67.3 | 64.8 | 65.4 | 65.9 | 66.8 | 67.5 | ||
| 8000 | 65.5 | 63.4 | 64.5 | 65.4 | 67.8 | 66.5 | 65.8 | 64.9 | 65.5 | 66.0 | ||
| 9000 | 63.2 | 62.9 | 57.4 | 65.6 | 67.9 | 64.8 | 64.9 | 64.9 | 65.7 | 67.9 | ||
| 10,000 | 64.1 | 63.4 | 65.0 | 66.9 | 68.1 | 64.6 | 64.8 | 65.7 | 64.9 | 66.8 | ||
| 11,000 | 63.0 | 65.2 | 61.9 | 63.8 | 68.4 | 65.9 | 65.7 | 66.3 | 65.9 | 67.2 | ||
| 12,000 | 63.4 | 64.2 | 65.8 | 65.8 | 68.4 | 65.3 | 65.1 | 65.5 | 65.7 | 67.3 | ||
| 13,000 | 63.7 | 64.6 | 65.3 | 66.2 | 68.9 | 66.1 | 65.8 | 65.7 | 66.5 | 66.6 | ||
| 14,000 | 63.9 | 63.7 | 64.8 | 66.9 | 67.6 | 65.9 | 64.9 | 66.8 | 65.1 | 67.4 | ||
| 15,000 | 63.4 | 64.4 | 66.1 | 66.8 | 68.3 | 65.3 | 65.2 | 64.8 | 64.1 | 66.8 | ||
| Dataset | The Number of Clusters | Testing Accuracy OA (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Epochs | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 | ||
| Salinas | 1000 | 78.4 | 78.2 | 78.1 | 77.7 | 78.6 | 77.1 | 77.7 | 78.2 | 77.1 | 77.4 | |
| 2000 | 79.9 | 79.8 | 79.8 | 78.9 | 80.1 | 80.2 | 79.7 | 80.8 | 80.7 | 79.4 | ||
| 3000 | 80.6 | 82.2 | 81.3 | 79.7 | 82.1 | 81.7 | 80.9 | 81.9 | 83.6 | 80.2 | ||
| 4000 | 82.0 | 84.2 | 82.4 | 80.7 | 83.7 | 83.2 | 82.5 | 84.3 | 84.6 | 80.8 | ||
| 5000 | 83.4 | 85.1 | 84.1 | 81.9 | 84.4 | 84.3 | 83.7 | 85.3 | 84.8 | 83.1 | ||
| 6000 | 84.4 | 85.4 | 84.5 | 82.2 | 85.1 | 84.9 | 84.4 | 85.2 | 84.9 | 83.6 | ||
| 7000 | 84.6 | 85.6 | 85.2 | 83.9 | 85.5 | 85.3 | 84.7 | 85.8 | 85.6 | 84.4 | ||
| 8000 | 84.9 | 85.7 | 85.3 | 84.2 | 85.9 | 85.8 | 85.2 | 86.1 | 85.8 | 84.8 | ||
| 9000 | 85.3 | 86.1 | 85.7 | 84.4 | 86.1 | 85.7 | 85.3 | 86.4 | 85.9 | 85.1 | ||
| 10,000 | 85.6 | 86.2 | 85.8 | 85.1 | 86.3 | 85.8 | 85.4 | 86.7 | 85.9 | 84.8 | ||
| 11,000 | 85.5 | 85.9 | 86.0 | 85.5 | 85.9 | 85.8 | 85.9 | 86.8 | 86.1 | 85.4 | ||
| 12,000 | 85.7 | 86.2 | 85.5 | 85.2 | 86.3 | 85.6 | 86.0 | 86.1 | 86.2 | 85.0 | ||
| 13,000 | 85.3 | 85.8 | 85.7 | 85.3 | 86.0 | 85.6 | 86.3 | 86.6 | 86.3 | 84.5 | ||
| 14,000 | 85.6 | 85.5 | 85.8 | 84.7 | 85.9 | 85.2 | 86.3 | 86.4 | 85.9 | 85.8 | ||
| 15,000 | 85.9 | 85.7 | 85.7 | 84.9 | 85.6 | 85.3 | 86.2 | 86.4 | 86.5 | 86.2 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, C.; Zheng, M.; Chen, F.; Zhang, Y.; Zhuang, X.; Fan, E.; Wen, D.; Zhang, L.; Wei, W.; Zhang, Y. Hyperspectral Image Classification Promotion Using Clustering Inspired Active Learning. Remote Sens. 2022, 14, 596. https://doi.org/10.3390/rs14030596
Ding C, Zheng M, Chen F, Zhang Y, Zhuang X, Fan E, Wen D, Zhang L, Wei W, Zhang Y. Hyperspectral Image Classification Promotion Using Clustering Inspired Active Learning. Remote Sensing. 2022; 14(3):596. https://doi.org/10.3390/rs14030596
Chicago/Turabian StyleDing, Chen, Mengmeng Zheng, Feixiong Chen, Yuankun Zhang, Xusi Zhuang, Enquan Fan, Dushi Wen, Lei Zhang, Wei Wei, and Yanning Zhang. 2022. "Hyperspectral Image Classification Promotion Using Clustering Inspired Active Learning" Remote Sensing 14, no. 3: 596. https://doi.org/10.3390/rs14030596