
Meta-Pixel-Driven Embeddable Discriminative Target and Background Dictionary Pair Learning for Hyperspectral Target Detection


Abstract
:1. Introduction
- (1)
- The meta-pixel set for HSI is defined by inheriting the merits of the homogeneous superpixel spectral property and the local manifold affinity structure, which can significantly reduce the influence of the spectral variability and find the most informative and prototype spectral signatures of HSI.
- (2)
- A Meta-pixel-driven Embeddable Discriminative background and target Dictionary Pair (MEDDP) learning model is established to efficiently learn a discriminative and compact background dictionary from the constructed meta-pixel set by introducing the discriminative structural incoherence. In addition, an adaptive low-dimensional embeddable subspace is jointly derived to reduce spectral redundancy and extract meaningful features, which can lead to more accurate characterizations of the target and background.
- (3)
- An efficient optimization algorithm is designed to solve the MEDDP model. The key variables, i.e., the background dictionary and orthogonal embeddable projection matrix are optimized iteratively to find the satisfied solutions. Furthermore, a novel meta-pixel-level target detection is performed based on the MEDDP model and some representation learning strategies. Experiments on several benchmark HSI datasets verify the effectiveness of the proposed method in comparison with several state-of-the-art HSI target detectors.
2. Related Works
2.1. Low-Rank Modeling
2.2. Sparse Representation Theory-Based HSI Target Detection
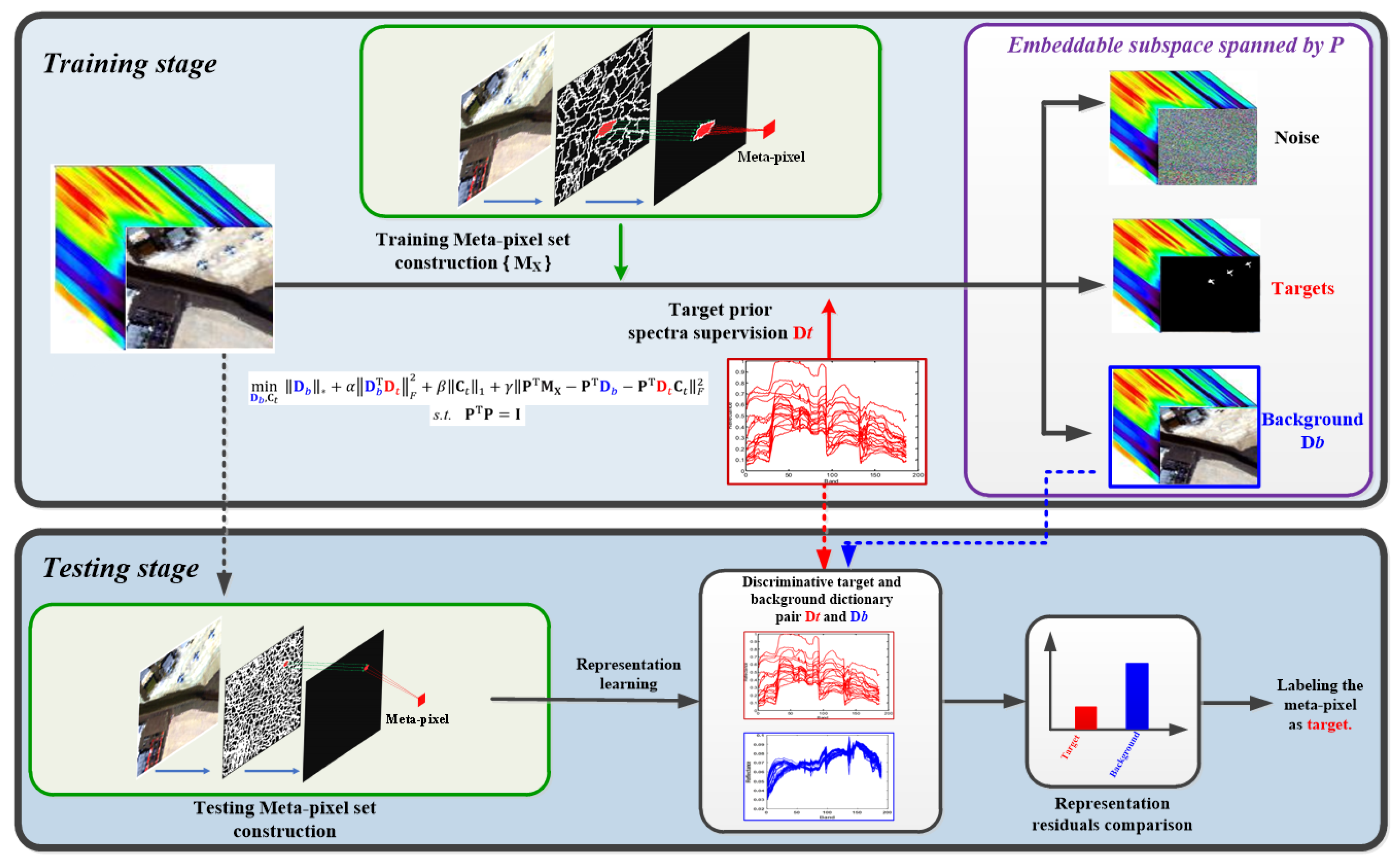
3. Metal-Pixel-Driven Embeddable Discriminative Target and Background Dictionary Pair Learning for HSI Target Detection
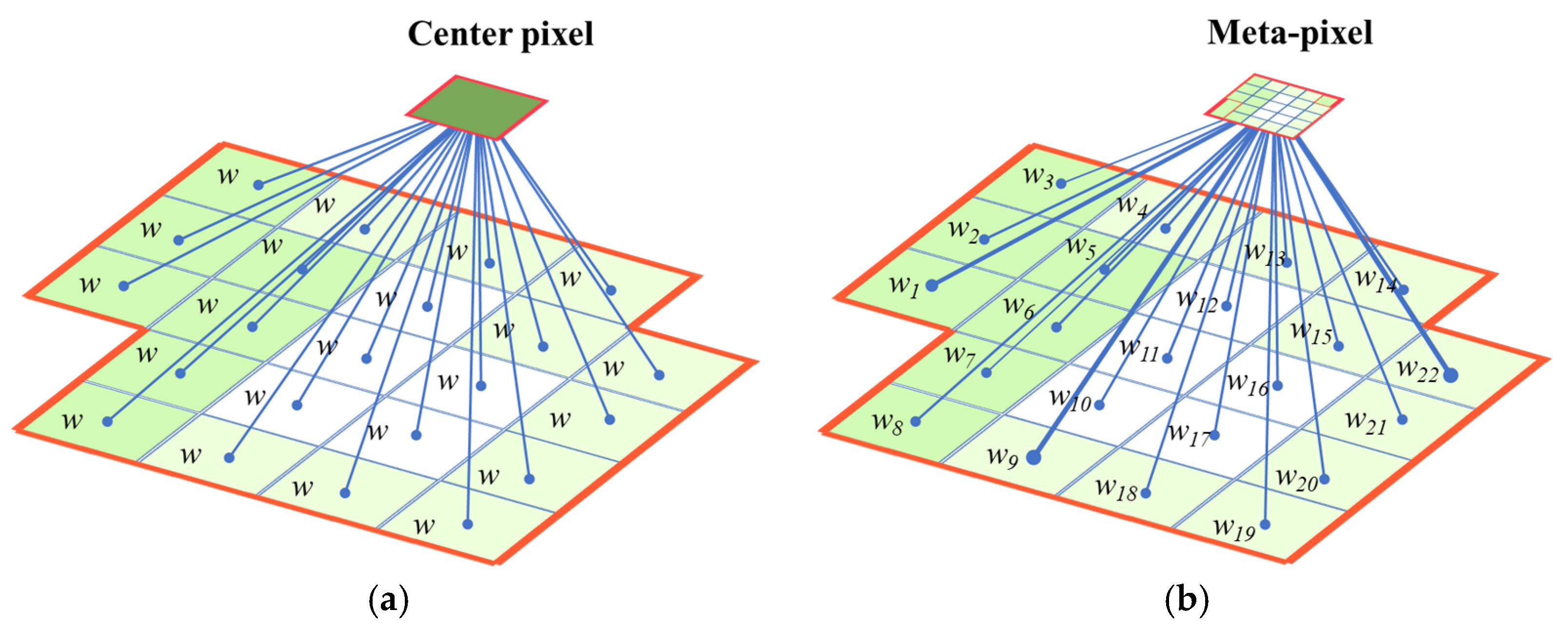
3.1. Meta-Pixel Set Construction
3.2. MEDDP Model Formulation
3.3. MEDDP Model Optimization
- (1)
- Updateby solving the following problem with the other variables fixed.
- (2)
- Updatewith the other variables fixed and solve the following problem.
- (3)
- Updatewith the other variables fixed by solving the following problem.
- (4)
- Updatewith the other variables fixed by solving the following problem.
- (5)
- Updatewith the other variables fixed by solving the following problem.
- (6)
- Update the Lagrange multipliers and penalty parameter:
| Algorithm 1. Solving problem (18) using Inexact ALM. |
| Input: Meta-pixel set , target prior spectra . Reduced dimension d. |
| Initialization: Initialize by PCA, . |
| Whilenot convergencedo |
| 1. Update by successively solving the sub-problems in (23), (25), (27), (30) and (33). |
| 2. Update the Lagrange multipliers and penalty parameter as in (19). |
| 3. Examine the convergence conditions: |
| End while |
| Output:. |
3.4. Meta-Pixel-Level Target Detection Based on MEDDP Model
| Algorithm 2. MEDDP and meta-pixel-based target detection. |
| Input: HSI dataset , target prior spectra , tradeoff parameters . Reduced dimension d. |
| 1. Construct a training meta-pixel set of based on ERS and local manifold preservation. |
| 2. Obtain the optimal target and background dictionary pair by solving Algorithm 1. |
| 3. Construct testing meta-pixel set, and use the obtained dictionary pair for me-ta-pixel-level target detection via different representation-based target detection strat-egies, such as the SRBBH presented in (35)–(37). |
| Output: Detection map |
4. Experimental Verifications
4.1. Benchmark HSI Datasets
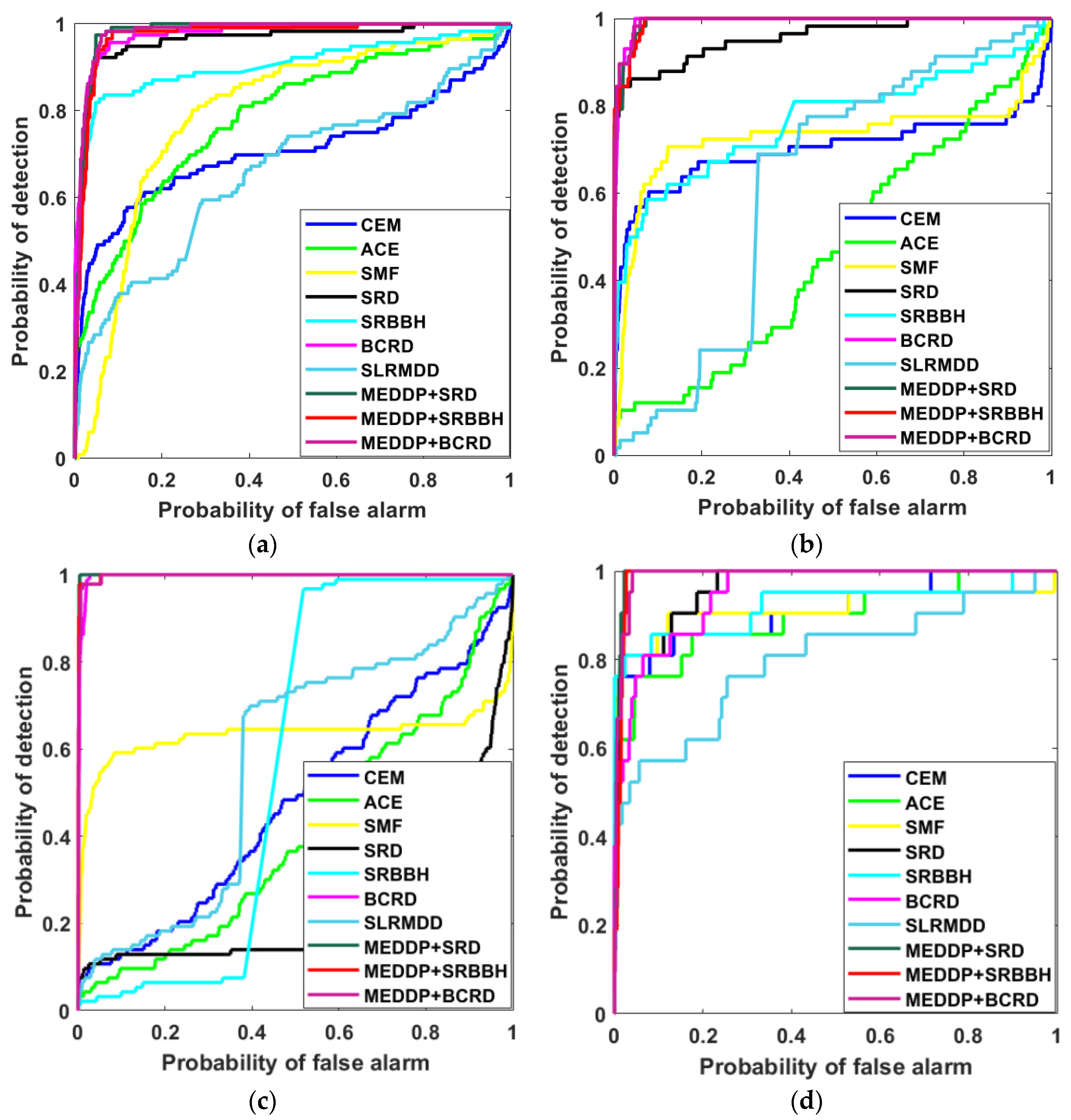
4.2. Comparison Methods and Performance Evaluation Metrics
- (1)
- ACE: ACE is a background unstructured detector by assuming that the background has the same covariance structure but different variances under the two hypotheses [9].
- (2)
- CEM: CEM detects target by designing a finite impulse response filter (FIRF) using the known target spectrum and minimizing the energy of the interference signal. However, CEM fails to consider the assumption of data distribution, which will restrict its performance [37].
- (3)
- SMF: Different from CEM, the SMF detector estimates the background covariance matrix and then employs the generalized likelihood ratio test for detection with only a single target spectrum, which cannot fully model the diversity of target spectra [10].
- (4)
- SRD: SRD represents a test pixel using the target and background combined dictionary, and then determines the label of test pixel (background or target) by examining which sub-dictionary yields a smaller representation residual for the test pixel [18].
- (5)
- SRBBH: SRBBH combines the idea of binary hypothesis and sparse representation, in which the test pixel is respectively represented by the background dictionary, and the background and target combined dictionary under the two hypotheses that the target is present or absent. The derived representation errors under the two hypotheses are used for the final detection decision [19].
- (6)
- BCRD: In BCRD, both pixels in the background and pixels in the target can be collaboratively represented by some pixels of the image. The detection result is achieved by estimating the residual difference of two collaborative representations [20].
- (7)
- SLRMDD: SLRMDD is based on sparse and low-rank matrix decomposition and regards the given HSI as a composition of the sum of low-rank background HSI and a sparse target HSI containing targets via a target dictionary constructed from some online spectral libraries. Strategy one is used for target detection by combining the separated background dictionary with the SRBBH detector. The ratio between the two key parameters is set as 5/2 [4].
4.3. Qualitative and Quantitative Results
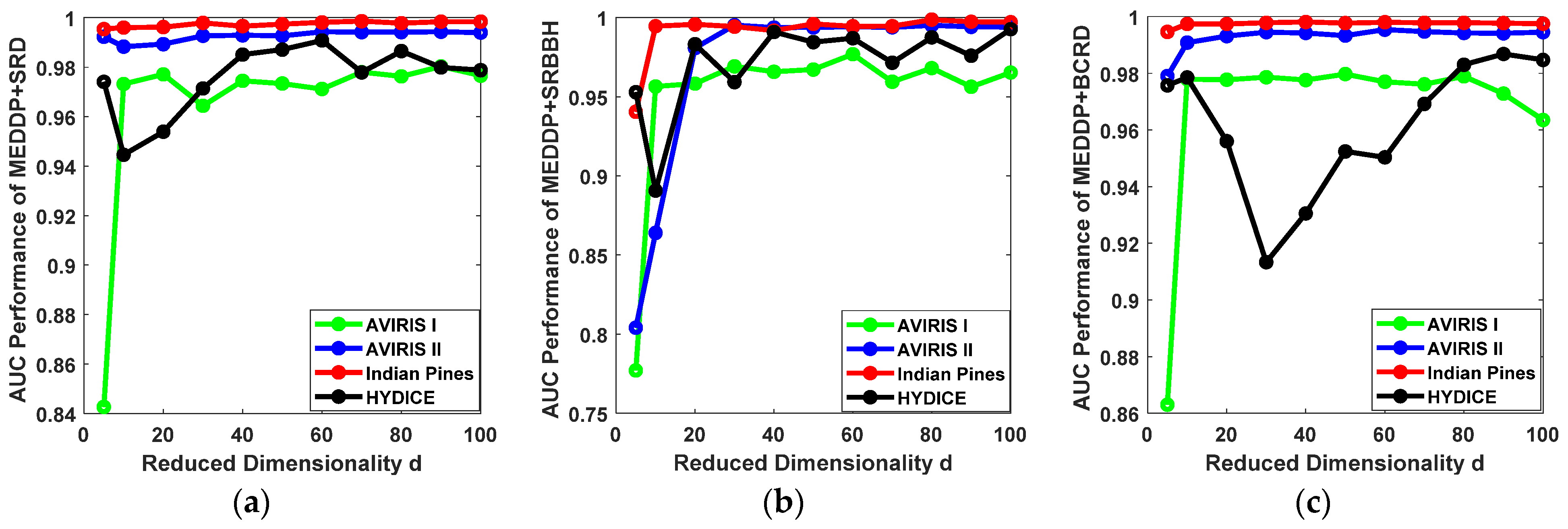
4.4. Parameters Analysis and Convergence Analysis
- (1)
- Influence of the Reduced Dimensionality d.
- (2)
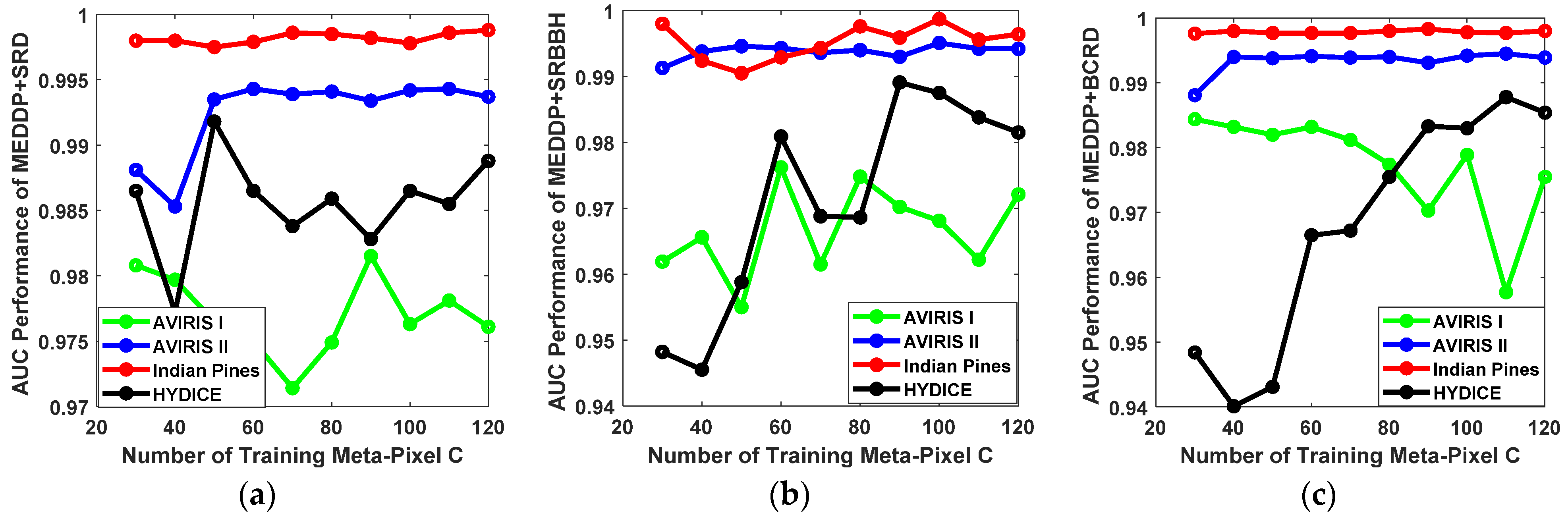
- Influence of Number of Training Meta-Pixel C.
- (3)
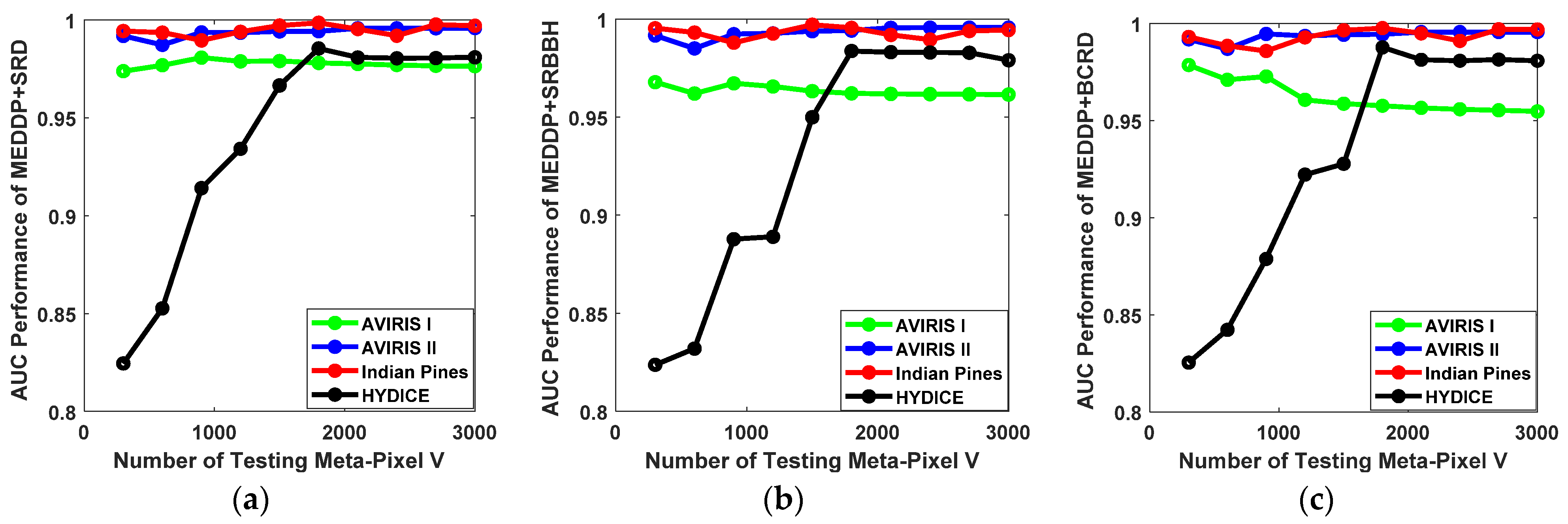
- Impact of the Number of Testing Meta-Pixel V.
- (4)
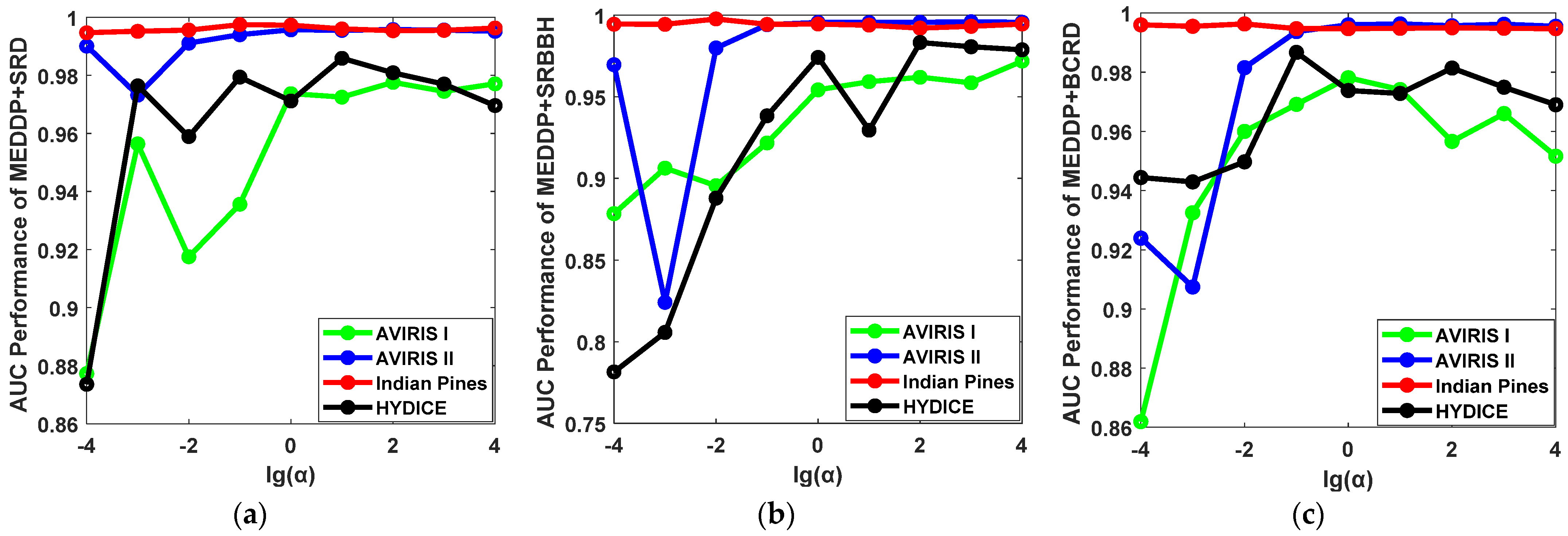
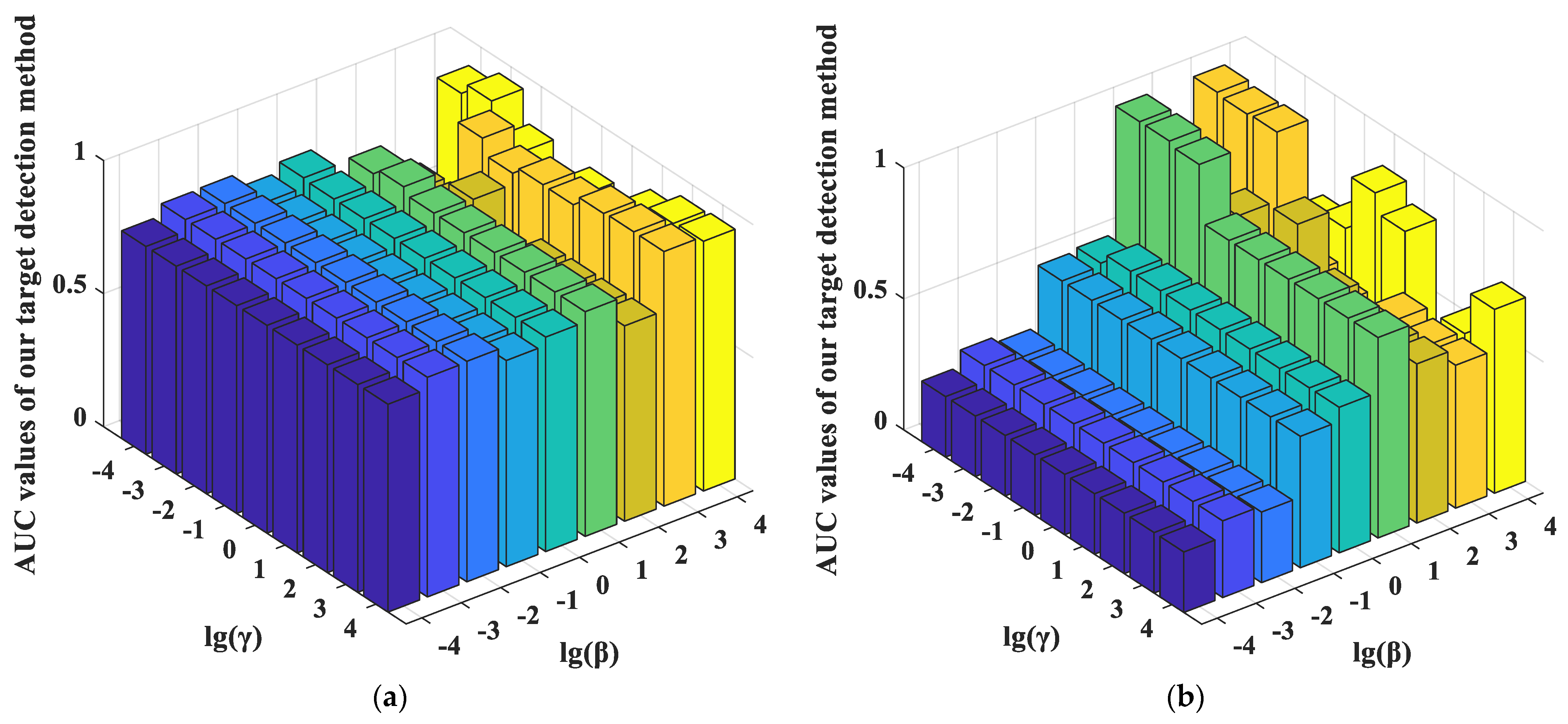
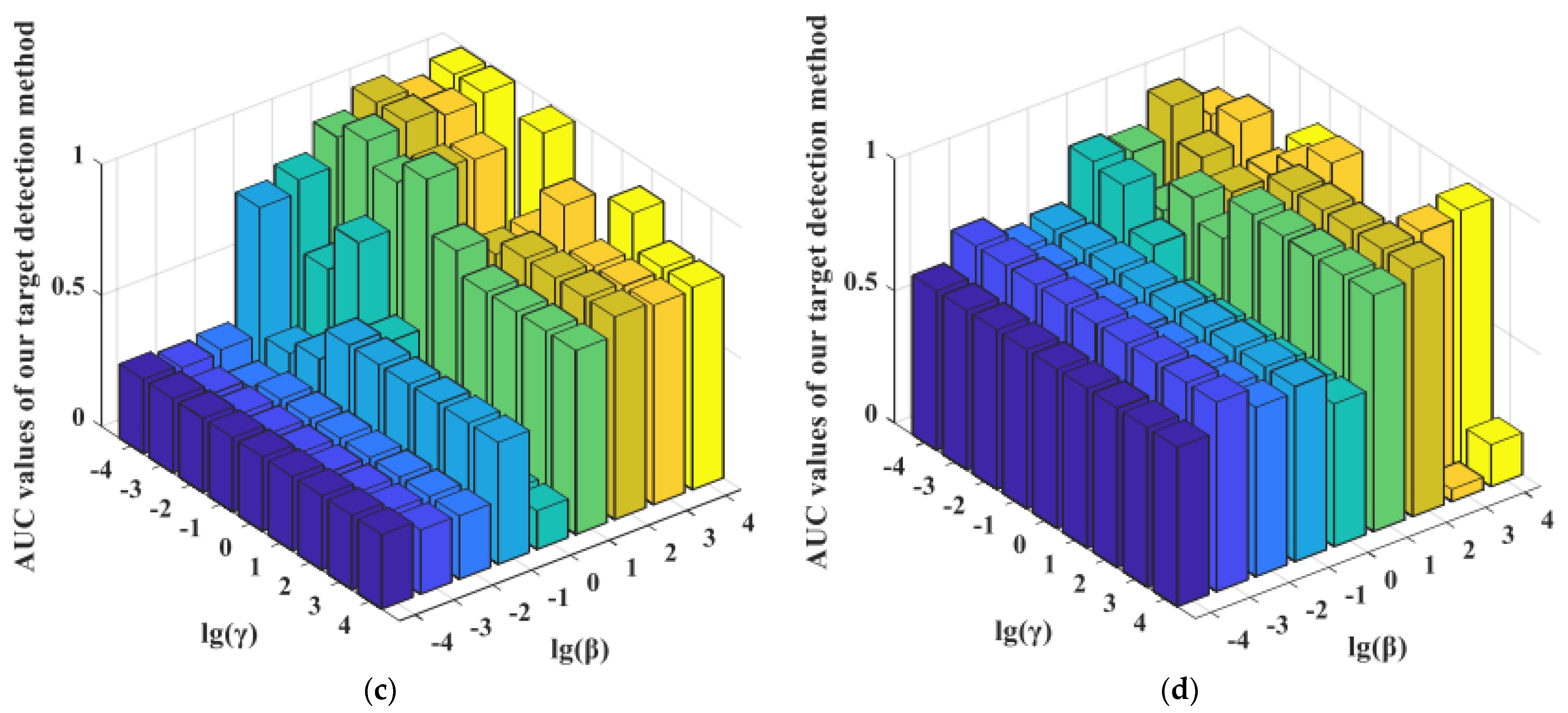
- Influence of the Balancing Parameters α, β, and γ.
- (5)
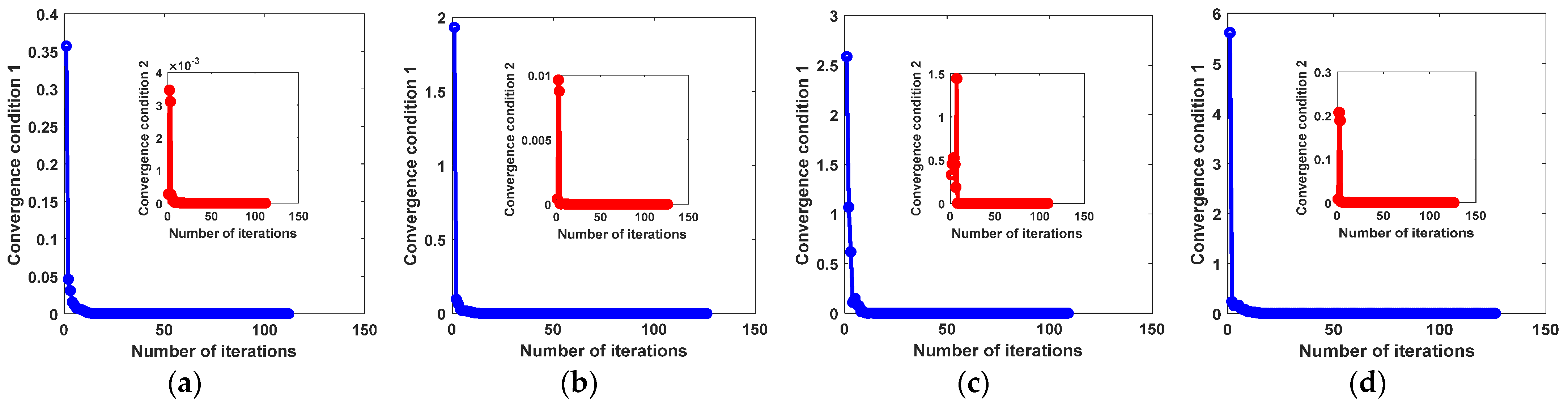
- Convergence Analysis of the Optimization Algorithm
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Wang, L.; Yu, C.; Zhao, E.; Song, M.; Wen, C.-H.; Chang, C.-I. Constrained-target band selection for multiple-target detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6079–6103. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, X.; Li, Y.; Wang, K.; Du, Q. Background learning based on target suppression constraint for hyperspectral target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5887–5897. [Google Scholar] [CrossRef]
- Wang, Y.; Lee, L.; Xue, B.; Wang, L.; Song, M.; Yu, C.; Li, S.; Chang, C.-I. A posteriori hyperspectral anomaly detection for unlabeled classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3091–3106. [Google Scholar] [CrossRef]
- Bitar, A.W.; Cheong, L.; Ovarlez, J. Sparse and low-rank matrix decomposition for automatic target detection in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5239–5251. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Li, J.; Li, Y.; Du, Q. Sensor-independent hyperspectral target detection with semisupervised domain adaptive few-shot learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6894–6906. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. Sparse transfer manifold embedding for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1030–1043. [Google Scholar] [CrossRef]
- Du, B.; Zhang, Y.; Zhang, L.; Tao, D. Beyond the sparsity-based target detector: A hybrid sparsity and statistics-based detector for hyperspectral images. IEEE Trans. Image Process. 2016, 25, 5345–5357. [Google Scholar] [CrossRef]
- Guo, T.; Luo, F.; Zhang, L.; Zhang, B.; Tan, X.; Zhou, X. Learning structurally incoherent background and target dictionaries for hyperspectral target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3521–3533. [Google Scholar] [CrossRef]
- Manolakis, D.; Marden, D.; Shaw, G.A. Hyperspectral image processing for automatic target detection applications. Linc. Lab. J. 2003, 14, 79–116. [Google Scholar]
- Nasrabadi, N.M. Regularized spectral matched filter for target recognition in hyperspectral imagery. IEEE Signal Process. Lett. 2008, 15, 317–320. [Google Scholar] [CrossRef]
- Luo, F.; Zhang, L.; Zhou, X.; Guo, T.; Cheng, Y.; Yin, T. Sparse-adaptive hypergraph discriminant analysis for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1082–1086. [Google Scholar] [CrossRef]
- Luo, F.; Zhang, L.; Du, B.; Zhang, L. Dimensionality reduction with enhanced hybrid-graph discriminant learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5336–5353. [Google Scholar] [CrossRef]
- Guo, T.; Lu, X.-P.; Zhang, Y.-X.; Yu, K. Neighboring discriminant component analysis for asteroid spectrum classification. Remote Sens. 2021, 13, 3306. [Google Scholar] [CrossRef]
- Luo, F.; Huang, H.; Ma, Z.; Liu, J. Semisupervised sparse manifold discriminative analysis for feature extraction of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6197–6211. [Google Scholar] [CrossRef]
- Xue, Z.; Du, P.; Li, J.; Su, H. Simultaneous sparse graph embedding for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6114–6133. [Google Scholar] [CrossRef]
- Huang, J.; Huang, T.; Deng, L.; Zhao, X. Joint-sparse-blocks and low-rank representation for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2419–2438. [Google Scholar] [CrossRef]
- Han, H.; Wang, G.; Wang, M.; Miao, J.; Guo, S.; Chen, L.; Zhang, M.; Guo, K. Hyperspectral unmixing via nonconvex sparse and low-rank constraint. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5704–5718. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Sparse representation for target detection in hyperspectral imagery. IEEE J. Sel. Top. Signal Process. 2011, 5, 629–640. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L. A sparse representation-based binary hypothesis model for target detection in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1346–1354. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Binary-class collaborative representation for target detection in hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1100–1104. [Google Scholar] [CrossRef]
- Li, W.; Du, Q.; Zhang, B. Combined sparse and collaborative representation for hyperspectral target detection. Pattern Recognit. 2015, 48, 3904–3914. [Google Scholar] [CrossRef]
- Guo, T.; Luo, F.; Zhang, L.; Tan, X.; Liu, J.; Zhou, X. Target detection in hyperspectral imagery via sparse and dense hybrid representation. IEEE Geosci. Remote Sens. Lett. 2020, 17, 716–720. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Target dictionary construction-based sparse representation hyperspectral target detection methods. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 1254–1264. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Simultaneous joint sparsity model for target detection in hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2011, 8, 676–680. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 1–37. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Liu, Q.; Li, P. Blessing of dimensionality: Recovering mixture data via dictionary pursuit. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 47–60. [Google Scholar] [CrossRef]
- Tropp, J.A.; Wright, S.J. Computational methods for sparse solution of linear inverse problems. Proc. IEEE 2010, 98, 948–958. [Google Scholar] [CrossRef] [Green Version]
- Guo, T.; Yu, K.; Aloqaily, M.; Wan, S. Constructing a prior-dependent graph for data clustering and dimension reduction in the edge of AIoT. Future Gener. Comput. Syst. 2022, 128, 381–394. [Google Scholar] [CrossRef]
- Guo, T.; Zhang, L.; Tan, X.; Yang, L.; Liang, Z. Data induced masking representation learning for face data analysis. Knowl.-Based Syst. 2019, 177, 82–93. [Google Scholar] [CrossRef]
- Lu, X.; Wang, Y.; Yuan, Y. Sparse coding from a Bayesian perspective. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 929–939. [Google Scholar]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; Volume 1, pp. 40–44. [Google Scholar]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.S.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]
- Lin, Z.; Chen, M.; Wu, L.; Ma, Y. The Augmented Lagrange Multiplier Method for Exact Recovery of Corrupted Low-Rank Matrices; Tech. Rep. UILU-ENG-09-2215; Coordinated Sci. Lab., University Illinois Urbana-Champaign: Champaign, IL, USA, 2009. [Google Scholar]
- Wang, T.; Du, B.; Zhang, L. A kernel-based target-constrained interference-minimized filter for hyperspectral sub-pixel target detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2013, 6, 626–637. [Google Scholar] [CrossRef]
- Du, Q.; Ren, H.; Chang, C.-I. A comparative study for orthogonal subspace projection and constrained energy minimization. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1525–1529. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 1983, 148, 839–843. [Google Scholar] [CrossRef] [PubMed] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning | Notation | Meaning |
|---|---|---|---|
| X | Observed HSI dataset | Dt, Db | Target and background samples (dictionaries) |
| L | Low-rank component of X | , c = 1,2,…C | Superpixel set of X |
| E | Sparse noise component of X | , c = 1,2,…C | Meta-pixel set of X |
| P | Embeddable projection matrix | Center pixel of the cth superpixel | |
| α, β, γ,λ | Tradeoff parameters | Sparse target representation matrix |
| Detectors | Datasets | |||
|---|---|---|---|---|
| AVIRIS I | AVIRIS II | Indian Pines | HYDICE | |
| ACE | 0.7843 | 0.4716 | 0.4067 | 0.8903 |
| CEM | 0.7069 | 0.7011 | 0.4794 | 0.9121 |
| SMF | 0.7933 | 0.7299 | 0.6328 | 0.9147 |
| SRD | 0.9629 | 0.9564 | 0.2155 | 0.9654 |
| BCRD | 0.9774 | 0.9934 | 0.9969 | 0.9495 |
| SRBBH | 0.9055 | 0.7675 | 0.5669 | 0.9214 |
| SLRMDD | 0.6603 | 0.6211 | 0.5719 | 0.7982 |
| MEDDP + SRD | 0.9826 | 0.9927 | 0.9988 | 0.9927 |
| MEDDP + SRBBH | 0.9735 | 0.9921 | 0.9979 | 0.9879 |
| MEDDP + BCRD | 0.9825 | 0.9943 | 0.9969 | 0.9895 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, T.; Luo, F.; Fang, L.; Zhang, B. Meta-Pixel-Driven Embeddable Discriminative Target and Background Dictionary Pair Learning for Hyperspectral Target Detection. Remote Sens. 2022, 14, 481. https://doi.org/10.3390/rs14030481
Guo T, Luo F, Fang L, Zhang B. Meta-Pixel-Driven Embeddable Discriminative Target and Background Dictionary Pair Learning for Hyperspectral Target Detection. Remote Sensing. 2022; 14(3):481. https://doi.org/10.3390/rs14030481
Chicago/Turabian StyleGuo, Tan, Fulin Luo, Leyuan Fang, and Bob Zhang. 2022. "Meta-Pixel-Driven Embeddable Discriminative Target and Background Dictionary Pair Learning for Hyperspectral Target Detection" Remote Sensing 14, no. 3: 481. https://doi.org/10.3390/rs14030481