
Traffic Anomaly Prediction System Using Predictive Network
 , ,
, ,
Abstract
:1. Introduction
- We combine unsupervised video prediction i.e., PredNet and supervised action classification. Our novel idea is to predict future frames based on features extracted using CNN with their labels.
- The model just uses video frames as input and does not require pre-processed optical flows. This approach predicts and propagates error at the feature level, rather than at the pixel level.
2. Related Work
2.1. Video Prediction Learning
2.1.1. Predictive Coding in Anomaly and Accident Prediction
2.2. Related Datasets
2.3. Motivation
- Extract important features from the video sequence.
- Decode features map and calculate the final prediction score by IOU function for anomaly and accident prediction.
3. Materials and Methods
3.1. PredNet Architecture
3.2. Prosposed Method

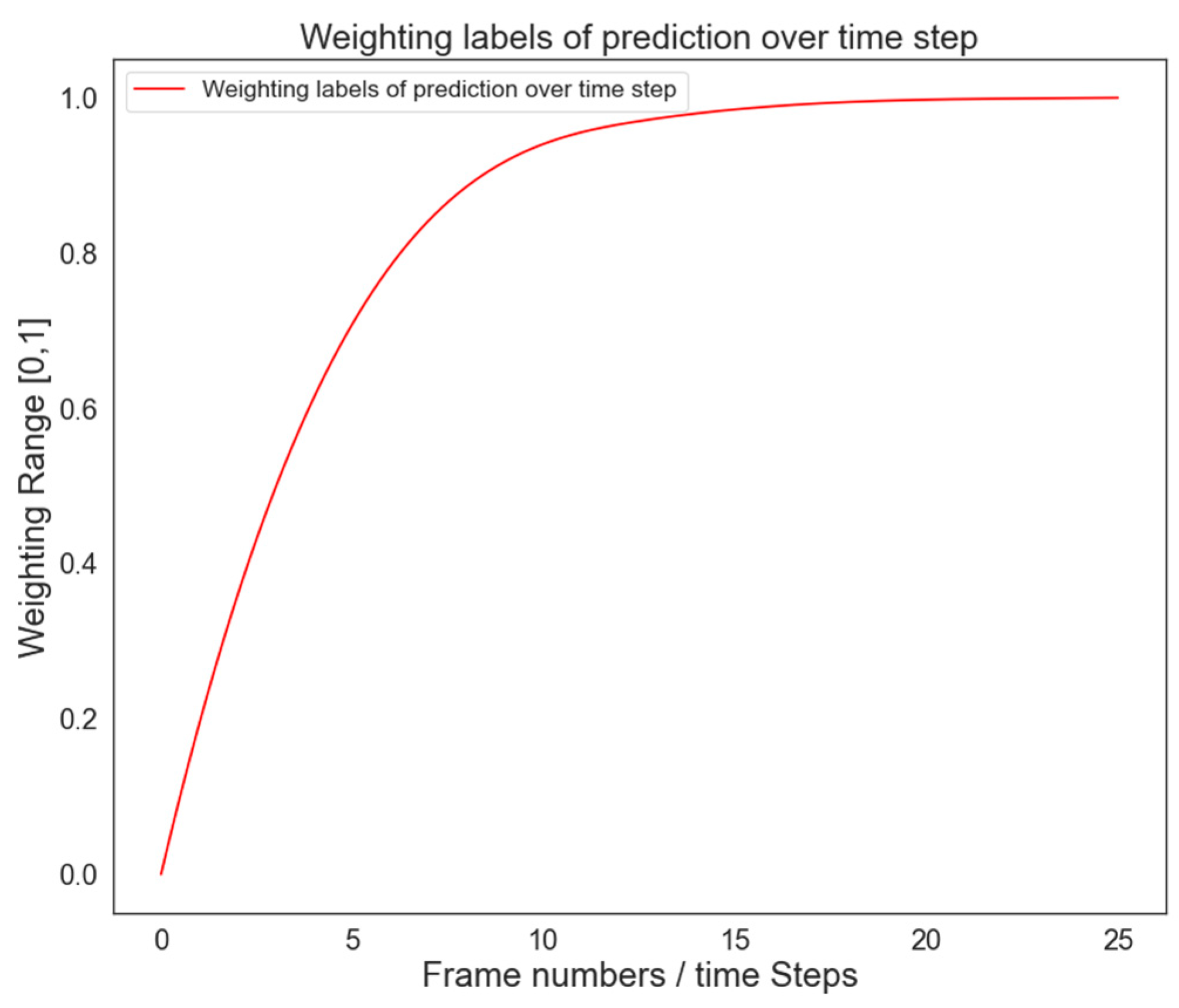
3.2.1. Semantic Feature Extraction
3.2.2. FW-PredNet Architecture
3.2.3. Network Training Parameters
3.3. Datasets
3.3.1. HTA
3.3.2. KITTI
3.3.3. D2city
4. Experiments and Results
4.1. Baseline
4.1.1. CGAN
4.1.2. FlowNet
4.2. Model Analysis
- The last layer of CNN pre-trained on ImageNet is fine-tuned on HTA.
- The last layer of CNN pre-trained on KITTI is fine-tuned on HTA.
- Fix the weights of CNN pre-trained on ImageNet dataset and train the PredNet on HTA.
- Fix the weights of CNN pre-trained on KITTI dataset and train the PredNet on HTA.
4.2.1. Evaluation on HTA
4.2.2. Evaluation on KITTI
4.2.3. Evaluation on D2city
5. Discussion
6. Conclusions and Future Work
- In this paper, we have introduced the FWPredNet framework for accident and anomaly anticipation, and outperformed the previous state-of-the-art by a better margin on the downstream tasks of classification accuracy on KITTI, D2city and HTA datasets.
- It can be deduced that our proposed variation in FWPredNet is able to capture additional information from generated video sequences while we train the PredNet from scratch on the given dataset.
- We evaluated vanilla PredNet [7] then compared it to our FWPredNet model. Compared with traditional models (CGAN, Flownet, PredNet), FWPredNet performs better in both Accident and Close Merge classes. One limitation of the test performance is that it struggles with speeding vehicles because the learning ability of the model is sensitive to the continuity of motion but still achieves better results compared with the rest of the three methods.
- Finally, on the engineering front, the current implementation of the FWPredNet takes very long time to train, and work can be done towards more efficient usage of GPUs. The computational cost of FWPredNet is 3.9M more than the vanilla PredNet but we accepted it as trade-off for “accuracy over computational cost”. A successor to FWPredNet can be designed, which does not have the aforementioned limitations and is faster in implementation of the proposed model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shirazi, M.S.; Morris, B.T. Looking at Intersections: A Survey of Intersection Monitoring, Behavior and Safety Analysis of Recent Studies. IEEE Trans. Intell. Transp. Syst. 2017, 18, 4–24. [Google Scholar] [CrossRef]
- Yuan, Y.; Fang, J.; Wang, Q. Online Anomaly Detection in Crowd Scenes via Structure Analysis. IEEE Trans. Cybern. 2015, 45, 548–561. [Google Scholar] [CrossRef] [PubMed]
- Cheng, K.-W.; Chen, Y.-T.; Fang, W.-H. Gaussian Process Regression-Based Video Anomaly Detection and Localization with Hierarchical Feature Representation. IEEE Trans. Image Process. 2015, 24, 5288–5301. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Chen, J. A Review of Methods for Detecting Point Anomalies on Numerical Dataset. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 559–565. [Google Scholar]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer vision for autonomous vehicles: Problems, datasets and state of the art. In Foundations and Trends® in Computer Graphics and Vision; Now Publishers: Boston, MA, USA, 2021; Volume 12, pp. 1–308. [Google Scholar]
- Muhammad, K.; Ullah, A.; Lloret, J.; Del Ser, J.; de Albuquerque, V.H.C. Deep Learning for Safe Autonomous Driving: Current Challenges and Future Directions. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4316–4336. [Google Scholar] [CrossRef]
- Lotter, W.; Kreiman, G.; Cox, D. Deep predictive coding networks for video prediction and unsupervised learning. arXiv 2016, arXiv:1605.0810. [Google Scholar]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Che, Z.; Li, G.; Li, T.; Jiang, B.; Shi, X.; Zhang, X.; Ye, J. D2City: A Large-Scale Dashcam Video Dataset of Diverse Traffic Scenarios. arXiv 2019, arXiv:1904.01975. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Yu, P.S. Predrnn++: Towards A resolution of the deep-in-time dilemma in spatiotemporal predictive learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Finn, C.; Goodfellow, I.; Levine, S. Unsupervised learning for physical interaction through video prediction. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 64–72. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Anticipating the Future by Watching Unlabeled Video. 2015. Available online: http://www.cs.columbia.edu/~vondrick/prediction/paper.pdf (accessed on 15 December 2021).
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3104–3112. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Riaz, W.; Azeem, A.; Chenqiang, G.; Yuxi, Z.; Saifullah; Khalid, W. YOLO Based Recognition Method for Automatic License Plate Recognition. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 87–90. [Google Scholar]
- Bao, W.; Yu, Q.; Kong, Y. Uncertainty-based traffic accident anticipation with spatio-temporal relational learning. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 16–18 October 2020; pp. 2682–2690. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Zhu, J.; Zhu, Z.; Zou, W. End-to-end video-level representation learning for action recognition. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 645–650. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Sevilla-Lara, L.; Liao, Y.; Güney, F.; Jampani, V.; Geiger, A.; Black, M.J. On the integration of optical flow and action recognition. In Proceedings of the German Conference on Pattern Recognition, Stuttgart, German, 9–12 October 2018; Springer: Cham, Switzerland, 2018; pp. 281–297. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A self-gated activation function. arXiv 2017, arXiv:1710.059417. [Google Scholar]
- Kamijo, S.; Matsushita, Y.; Ikeuchi, K.; Sakauchi, M. Traffic monitoring and accident detection at intersections. IEEE Trans. Intell. Transp. Syst. 2000, 1, 108–118. [Google Scholar] [CrossRef]
- Rojas, J.C.; Crisman, J.D. Vehicle detection in color images. In Proceedings of the Conference on Intelligent Transportation Systems, Boston, MA, USA, 12 November 1997. [Google Scholar]
- Leibe, B.; Schindler, K.; Cornelis, N.; Van Gool, L. Coupled object detection and tracking from static cameras and moving vehicles. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1683–1698. [Google Scholar] [CrossRef] [PubMed]
- Lai, A.H.S.; Yung, N.H.C. A video-based system methodology for detecting red light runners. In Proceedings of the IAPR Workshop on Machine Vision Applications, Chiba, Japan, 17–19 November 1998; pp. 23–26. [Google Scholar]
- Fatima, M.; Khan, M.U.K.; Kyung, C.M. Global feature aggregation for accident anticipation. arXiv 2020, arXiv:2006.08942. [Google Scholar]
- Thajchayapong, S.; Garcia-Trevino, E.S.; Barria, J.A. Distributed Classification of Traffic Anomalies Using Microscopic Traffic Variables. IEEE Trans. Intell. Transp. Syst. 2012, 14, 448–458. [Google Scholar] [CrossRef]
- Ikeda, H.; Kaneko, Y.; Matsuo, T.; Tsuji, K. Abnormal incident detection system employing image processing technology. In Proceedings of the 1999 IEEE/IEEJ/JSAI International Conference on Intelligent Transportation Systems (Cat. No. 99TH8383), Tokyo, Japan, 5–8 October 1999; pp. 748–752. [Google Scholar]
- Michalopoulos, P.; Jacobson, R. Field Implementation and Testing of Machine Vision Based Incident Detection System. In Proceedings of the Pacific Rim TransTech Conference: Volume I: Advanced Technologies, Washington, DC, USA, 25–28 July 1993; pp. 1–7. [Google Scholar]
- Ki, Y.K.; Kim, J.W.; Baik, D.K. A traffic accident detection model using metadata registry. In Proceedings of the Fourth International Conference on Software Engineering Research, Management and Applications, IEEE (SERA'06), Seattle, WA, USA, 9–11 August 2006; pp. 255–259. [Google Scholar]
- Wei, J.; Zhao, J.; Zhao, Y.; Zhao, Z. Unsupervised anomaly detection for traffic surveillance based on background modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 129–136. [Google Scholar]
- Liu, X.; Zhang, S.; Huang, Q.; Gao, W. Ram: A region-aware deep model for vehicle reidentification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; pp. 146–157. [Google Scholar]
- Bochinski, E.; Senst, T.; Sikora, T. Extending IOU based multiobject tracking by visual information. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS) IEEE, Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Dogru, N.; Subasi, A. Traffic accident detection by using machine learning methods. In Proceedings of the Third International Symposium on Sustainable Development (ISSD’12), Sarajevo, Bosia and Herzegovina, 31 May–1 June 2012; p. 467. [Google Scholar]
- Yun, K.; Jeong, H.; Yi, K.M.; Kim, S.W.; Choi, J.Y. Motion Interaction Field for Accident Detection in Traffic Surveillance Video. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3062–3067. [Google Scholar] [CrossRef]
- Srivastava, N.; Mansimov, E.; Salakhutdinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Villegas, R.; Yang, J.; Zou, Y.; Sohn, S.; Lin, X.; Lee, H. Learning to generate long-term future via hierarchical prediction. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Morris, B.; Doshi, A.; Trivedi, M. Lane change intent prediction for driver assistance: On-road design and evaluation. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 895–901. [Google Scholar] [CrossRef]
- Jain, A.; Koppula, H.S.; Raghavan, B.; Soh, S.; Saxena, A. Car that Knows Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3182–3190. [Google Scholar] [CrossRef]
- Santhosh, K.K.; Dogra, D.P.; Roy, P.P. Anomaly detection in road traffic using visual surveillance: A survey. ACM Comput. Surv. (CSUR) 2020, 53, 1–26. [Google Scholar] [CrossRef]
- Pathak, D.; Sharang, A.; Mukerjee, A. Anomaly Localization in Topic-Based Analysis of Surveillance Videos. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 389–395. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar]
- Lee, S.; Kim, H.G.; Ro, Y.M. STAN: Spatio-Temporal Adversarial Networks for Abnormal Event Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1323–1327. [Google Scholar] [CrossRef]
- Scharwächter, T.; Enzweiler, M.; Franke, U.; Roth, S. Efficient Multi-cue Scene Segmentation. In Proceedings of the DAGM German Conference on Pattern Recognition, Saarbrücken, Germany, 3–6 September 2013; Volume 8142, pp. 435–445. [Google Scholar] [CrossRef]
- Zhong, J.; Cangelosi, A.; Zhang, X.; Ogata, T. AFA-PredNet: The Action Modulation Within Predictive Coding. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Zhong, J.; Ogata, T.; Cangelosi, A. Encoding longer-term contextual multi-modal information in a predictive coding model. arXiv 2018, arXiv:1804.06774. [Google Scholar]
- Wen, H.; Han, K.; Shi, J.; Zhang, Y.; Culurciello, E.; Liu, Z. Deep predictive coding network for object recognition. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Scharwächter, T.; Enzweiler, M.; Franke, U.; Roth, S. Stixmantics: A medium-level model for real-time semantic scene understanding. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Leibe, B.; Cornelis, N.; Cornelis, K.; Van Gool, L. Dynamic 3D Scene Analysis from a Moving Vehicle. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Volume 5302, pp. 44–57. [Google Scholar]
- Cordts, M.; Omran, M.; Scharwächter, T.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 6 April 2016; pp. 3213–3223. [Google Scholar]
- Chan, F.-H.; Chen, Y.-T.; Xiang, Y.; Sun, M. Anticipating Accidents in Dashcam Videos. In Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2017; pp. 136–153. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2015. [Google Scholar]
- Huang, X.; Mousavi, H.; Roig, G. Predictive Coding Networks Meet Action Recognition. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 793–797. [Google Scholar]
- Rane, R.P.; Szügyi, E.; Saxena, V.; Ofner, A.; Stober, S. Prednet and Predictive Coding: A Critical Review. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 233–241. [Google Scholar]
- Singh, H.; Hand, E.M.; Alexis, K. Anomalous Motion Detection on Highway Using Deep Learning. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1901–1905. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ravanbakhsh, M.; Sangineto, E.; Nabi, M.; Sebe, N. Training Adversarial Discriminators for Cross-Channel Abnormal Event Detection in Crowds. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1896–1904. [Google Scholar] [CrossRef]
- Fischer, P.; Dosovitsky, A. FlowNet: Learning Optical Flow with Convolutional Networks. arXiv 2015, arXiv:1504.06852v2. [Google Scholar]
- Hagenaars, J.J.; Paredes-Vallés, F. Self-Supervised Learning of Event-Based Optical Flow with Spiking Neural Networks. arXiv 2021, arXiv:2106.01862v. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Structure | Pretrained On | FineTune/Training | Accuracy | ||
|---|---|---|---|---|---|
| CNN | FWPredNet | CNN | FWPredNet | ||
| CNN | ImageNet | Classification Layer | 5.71% | ||
| CNN | KITTI | Classification Layer | 56.2% | ||
| CNN + PredNet | ImageNet | Fixed weights | From scratch | 18.44% | |
| CNN + PredNet | KITTI | Subset of KITTI | Fixed weights | From scratch | 60.3% |
| Action | CGAN | FlowNet | PredNet | FWPredNet |
|---|---|---|---|---|
| Speeding Vehicle | 0.608 | 0.623 | 0.49 | 0.629 |
| Accident | 0.607 | 0.657 | 0.55 | 0.675 |
| Close Merge | 0.422 | 0.531 | 0.19 | 0.651 |
| ACTION | CGAN | FlowNet | PredNet | FWPredNet |
|---|---|---|---|---|
| Accident | 0.439 | 0.541 | 0.38 | 0.578 |
| Close Merge | 0.526 | 0.685 | 0.45 | 0.724 |
| Action | CGAN | FlowNet | PredNet | FWPredNet |
|---|---|---|---|---|
| Accident | 0.439 | 0.541 | 0.38 | 0.718 |
| Close Merge | 0.526 | 0.685 | 0.47 | 0.704 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riaz, W.; Gao, C.; Azeem, A.; Saifullah; Bux, J.A.; Ullah, A. Traffic Anomaly Prediction System Using Predictive Network. Remote Sens. 2022, 14, 447. https://doi.org/10.3390/rs14030447
Riaz W, Gao C, Azeem A, Saifullah, Bux JA, Ullah A. Traffic Anomaly Prediction System Using Predictive Network. Remote Sensing. 2022; 14(3):447. https://doi.org/10.3390/rs14030447
Chicago/Turabian StyleRiaz, Waqar, Chenqiang Gao, Abdullah Azeem, Saifullah, Jamshaid Allah Bux, and Asif Ullah. 2022. "Traffic Anomaly Prediction System Using Predictive Network" Remote Sensing 14, no. 3: 447. https://doi.org/10.3390/rs14030447