1. Introduction
The sea and the land are the geomorphological units on the surface of the earth, and the boundary line between seawater and land becomes the coastal zone [
1]. The location of the coastline is an important part of determining the remote sensing survey of an island’s coastal zone. Coastline information is the basis for measuring and calibrating terrestrial and water resources and is the foundation for the excavation and management of coastal zone resources. The location and orientation of the coastline provides the most basic information for automated ship navigation, coastline erosion monitoring, and modelling, etc. The analysis of coastline lengths and changing coast sections is a prerequisite for carrying out the evolution of the natural environment [
2]. Therefore, rapid and accurate coastline extraction, and thus dynamic monitoring is a pressing issue in many coastal zone studies, which is of great practical importance for the effective development, sustainable use, and scientific management of coastal zones.
Traditional coastline mapping methods are mainly field surveys and photogrammetry. Due to the complexity of coastline surveys and the wide range, rapid changes and fragmentation of ground objects, these traditional methods of detection have long working cycles and are labor-intensive and inefficient, making it difficult to achieve dynamic monitoring of the coastline [
3]. At the same time, limited by the geographical environment and other conditions, some survey areas are not easily accessible, making mapping difficult. Remote sensing technology is a comprehensive application technology of earth observation based on physical means, geological analysis, and mathematical methods. It is powerful in data acquisition, has the advantages of large range, high temporal resolution, high spatial resolution, multi-spectral and multi-temporal sequence, and is not constrained by weather, geographical environment, and other conditions, which has outstanding advantages in coastal zone resource exploration and comprehensive management. Remote sensing has therefore become an effective means of extracting coastlines and monitoring their dynamic changes.
Remote sensing images are photographs based on electromagnetic wave imaging. Remote sensing images can not only be used to analyze the natural attributes of ground objects and the environment, but also provide a basis for urban development and search and rescue [
4]. Currently, the commonly used remote sensing images mainly include hyperspectral images and multispectral images. Multispectral images are reflected by the brightness values of different spectral dimensions of the same scene obtained according to the sensitivity of sensors. Based on the response difference of different ground objects in the specific spectral segment, the study was carried out [
5]. The spectral resolution of hyperspectral images reaches the order of 10
−2λ, and the target region is simultaneously imaged in tens to hundreds of continuous and subdivided spectral bands [
6]. Meanwhile, surface image information and spectral information are obtained. Compared with multi-spectral remote sensing images, the hyperspectral image has been greatly improved in information richness. Scholars have carried out a significant amount of work based on hyperspectral and multi-spectral remote sensing data, mainly focusing on image quality enhancement, semantic segmentation, and feature fusion.
In terms of quality enhancement, at the present stage, multi-spectral remote sensing images have higher quality than hyperspectral remote sensing images, but they still face twill, ghost images, and noise images, which need to be further improved. Based on the traditional feature method, the models are constructed according to the ground object morphology and spectral line law. Representative algorithms include texture [
7,
8], brightness analysis model [
9,
10], wavelet transform [
11], color [
12,
13], light transmission model [
14], filtering [
15,
16], weak signal enhancement [
17,
18], local and global model [
19]. Based on the statistical method, the models are constructed according to the features of pixel distribution. Representative ones are cuckoo search model [
20], fuzzy [
21,
22], statistical histogram [
23,
24], noise statistics [
25,
26], and comparative statistical analysis [
27]. Based on the deep network method, the neural conduction process is simulated, and the mapping model is constructed, including CNN [
28,
29], dual autoencoder network [
30], edged-enhanced GAN [
31,
32], conditional generative adversarial networks [
33], and end-to-end network [
34]. In general, for quality improvement, traditional methods still dominate, because they extract the inherent properties of substances and have high generalization performance. However, deep learning methods require a high correlation between test data and training data, with poor generalization performance.
In semantic segmentation, effective features are the premise of efficient analysis, and it is of great significance to select representative features from numerous features to carry out research. Methods based on traditional features include MRF (Markov random field) [
35,
36], mean-shift [
37,
38], spectral [
39,
40], texture [
41,
42], dynamic statistical [
43,
44], graph theory [
45,
46], and the threshold method [
47,
48]. Based on a deep network, the network is constructed in a supervised manner [
49]. CNN is used to extract the correlation between pixels, and a series of improved algorithms [
50,
51] are proposed. Then, the 3D model is constructed to mine the relationship between image channels [
52,
53,
54], and the Unet structure is introduced to realize image segmentation [
55,
56]. Moreover, the DNN network is constructed to mine depth features [
57], and ResNet connects shallow and deep features [
58]. In general, in the face of good image quality, the deep network method simulates the neural conduction process with a relatively obvious segmentation effect but the traditional method cannot be essentially improved.
In the terms of feature fusion, it is necessary to carry out research on feature fusion to make up for the insufficient representation of a single algorithm or single data source. Based on pixel fusion, the performance of different sensors is analyzed and fused according to pixel points [
59,
60]. Later, the features are extracted according to different algorithms and a fusion model is constructed [
61,
62]. Based on the fusion of decision sets, the fusion model is constructed according to the operating results of the algorithm, thus achieving the fusion [
63,
64]. In general, fusion algorithms with different levels show different advantages, and they need to be analyzed in a specific context.
According to the above analysis, a coastline recognition algorithm was proposed based on multi-feature network fusion: (1) a remote sensing image enhancement algorithm based on PCA was proposed; (2) the network framework of spatial attention and spectral attention models was proposed to extract possible coastline regions; (3) the extraction of the suspected coastline areas based on the HRnet network was proposed; and (4) the fusion mode of decision sets was constructed to realize coastline extraction and display directly in the way of coastline straightening.
The structure of this study is as follows: In
Section 2, the main framework of the algorithm in this paper is introduced, and the coastline recognition and display algorithm of multi-feature network fusion is proposed. n
Section 3, the effectiveness of the algorithm is proved through a lot of experiments. In
Section 4, the innovation points and future work are summarized.
2. Methods
In this paper, a complete coastline recognition algorithm was constructed based on the requirements of remote sensing image coastline recognition, and the specific process is shown in
Figure 1. First, PCA was used to extract the principal components of the image and remove the noise. Secondly, the dual attention network and HRnet network were constructed to extract suspected coastline regions from different angles, and the decision set fusion method was constructed to realize coastline extraction. To intuitively display the effect of coastline extraction, a coastline straightening model was established.
2.1. Introduction to Basic Networks
Google developed the DeepLab semantic segmentation framework [
65]. DeepLab-v1 uses atrous convolution operation to expand the network receptive field under the condition of reducing the sampling, and the dense feature map is obtained, thus realizing target segmentation. Due to the single-scale structure of Deeplab-V1, the processing capability of multi-scale segmentation objects is poor [
66]. Atrous Spatial Pyramid Pooling (ASPP) structure was proposed in Deeplab-V2 to capture multi-scale image context information of feature images, and full-link CRF operation was adopted to obtain more accurate segmentation images. However, the expansion rate of the 3 × 3 convolution kernel in the ASPP structure keeps increasing, and the 3 × 3 convolution will degenerate into the 1 × 1 convolution [
67]. To compensate for this defect and integrate global context information, Deeplab-v3 changes the ASPP structure to three 3 × 3 convolution operations with expansion rates of {6, 12, 18} and one global average pooling operation, respectively. As the ASPP incorporates image-level features and contains target location information, the fully connected CRF is removed from the V3 edition [
68]. DeepLab V3+ network adds an encoding-decoding structure based on V3. The encoder is divided into a deep dilated convolutional neural network and an ASPP layer. The decoder integrates low-level features for feature graph recovery, as shown in
Figure 2.
The convolutional layer is used to extract feature images, and the pooling layer is used to reduce the dimension of feature images to decrease the computation of the deep network. As the downsampling operation causes the loss of target boundary information, it will affect the effect of semantic segmentation. Furthermore, DeepLabv3+ adds Atrous Convolution to the deep feature extraction network, increasing network receptive fields without adding network parameters and minimizing the loss of target boundary feature information in the feature graph. In the face of different targets in the image with different scales, the unified use of the same layer feature segmentation can not ensure the requirements of accuracy. Therefore, the DeepLabv3+ network uses the Spatial Pyramid Pooling (SSP) operation in SSP-NET as a reference to improve the network to ASPP, aiming to realize the segmentation of multi-scale objects. After 1 × 1 convolution, 3 × 3 convolution with an expansion rate of {6,12,18} and global average pooling of the input feature images, ASPP merges the feature images and compresses the number of channels to 256. Finally, ASPP can complete the extraction and differentiation of target feature information of different scales. To fully extract the high-level feature information of the target object in the image, the DeepLabv3+ network carries out a down-sampling operation on the input image. Then it adopts a coding-decoding structure to fuse low-level features in the process of feature graph recovery, in order to compensate for the lost boundary information in the down-sampling operation. Finally, it adopts a linear interpolation method to recover boundary information, thus improving the precision of network segmentation.
2.2. Image Enhancement Based on PCA
Principal component analysis (PCA), as a multi-dimensional orthogonal linear transformation based on statistical features, is an algorithm for feature extraction of remote sensing images [
69]. Its principle is as follows: linear transformation is performed on the image, and the space X composed by the image is multiplied by the linear change matrix R to form a new space and constitute a new image.
where X is the pixel vector before the transformation; Y is the pixel vector after the transformation; and T is the transformation matrix.
The original image matrix X is normalized:
where
m and
n are the number of variables and pixels, respectively.
The covariance matrix is calculated:
The eigenvalue
λ and eigenvector
U of matrix
S are calculated:
The eigenvalues are arranged from large to small, {
λ1,
λ2,
λm}, and the corresponding eigenvectors form the following matrix:
where Y is the row vector of the matrix, and
Yj = [
yj1,
yj2, …, yjn] is the jth principal component. After principal component transformation, m new variables are obtained, namely, the first principal component, the second principal component, … the
m-th principal component. Matrix
y is the data after feature extraction.
Part of the data information in an image is redundant, and the data between each band are often highly correlated. Principal component transformation aims to extract the useful data features of the original bands into a small number of new principal component images so that the different principal component images are independent of each other, and then the minimum information loss of the original data can be guaranteed. Principal component analysis (PCA) is of great significance to compress the highly correlated data among the transformed bands by simplifying the original multiple indexes into a few independent comprehensive indexes. The 16-bit data is linearly mapped to [0,1]. Meanwhile, random flipping and mirroring are adopted to increase the diversity of the data.
2.3. Network Framework Based on Dual Attention
DeepLabv3+ network has shown excellent segmentation performance, but there are still some shortcomings: (1) to increase the segmentation of multi-scale targets, the network connects the ASPP structure after the cavity convolution feature extraction network. The large expansion rate cannot accurately extract the features of the image edge target, nor can it completely simulate the relationship between the local features of the large-scale target, which leads to the cavity phenomenon in the large-scale target segmentation. Therefore, the DeepLabv3+ network reduces the segmentation accuracy of edge targets and large-scale targets in remote sensing images; and (2) in the process that the network model from the feature extraction network to recovering the feature map by upsampling, the number of model parameters is huge, and there will be a phenomenon of parameter instability in the network backpropagation process, which leads to the difficulty of training and the slow convergence of the network.
In recent years, the attention mechanism has been successfully applied to the field of deep learning, which can simulate long-term dependence in image processing and establish the relationship between two pixels in an image with a certain distance. After introducing the self-attention mechanism into the image generation and evaluation of the GAN network, it is found that using the attention mechanism in the middle or high-level features makes the GAN network image generation effect significant. Based on the self-attention mechanism, the non-local operation in the spatio-temporal dimension is proposed, and good results have been achieved in images and videos. The self-attention mechanism is introduced into the semantic segmentation task, and the network model DANet is designed, which proves that the self-attention mechanism is also applicable to the semantic segmentation task. The self-attention mechanism in the DANet network is described as follows.
Spatial attention module: Information is obtained through context information. The semantic segmentation feature extraction based on FCNs is mainly local, which is easy to cause intra-class segmentation errors. The purpose of the spatial attention module is to fit the context relationship between global features, so that similar features in different locations can enhance each other and improve semantic segmentation ability. The module structure is shown in
Figure 3. The local feature A is obtained through the backbone network, and the depth feature matrix {
B,
C,
D} is obtained by convolution. The spatial attention is calculated by using the Softmax layer:
where (
B′)
T is the transpose of the inverse matrix of matrix B, N is the number of elements in the channel;
Sji represents the influence factor of the
i-th position on the
j-th position, indicating that similar features at two different positions have greater correlation and influence on each other. On this basis, the spatial attention module is constructed:
where
α is the learning parameter, and
E is the weighted sum of all location features and original features. Therefore, the location attention mechanism has a global context view and tries to selectively aggregate context according to location attention, so that similar semantic features can promote each other and maintain semantic consistency.
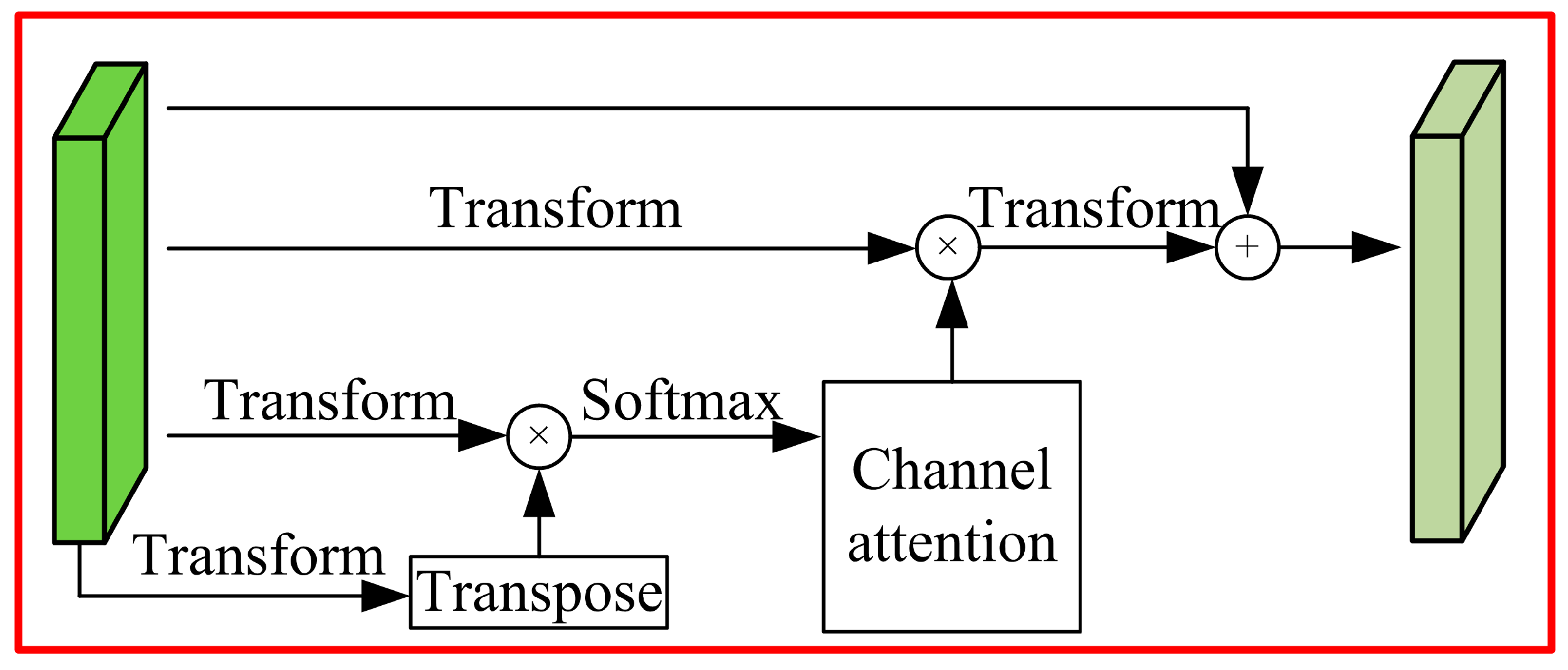
Channel attention mechanism module: high-level semantic features of different channels are extracted to achieve category forecast, and there is a certain relationship between the different categories of semantic. By using the contact between different channel feature images, the feature images that are interconnected can be highlighted, and specific semantic features can be promoted, so it is necessary to explore the features of the different channels. The channel attention module is shown in
Figure 4.
The channel attention module can directly obtain the attention diagram through matrix
A:
The corresponding channel attention is:
where
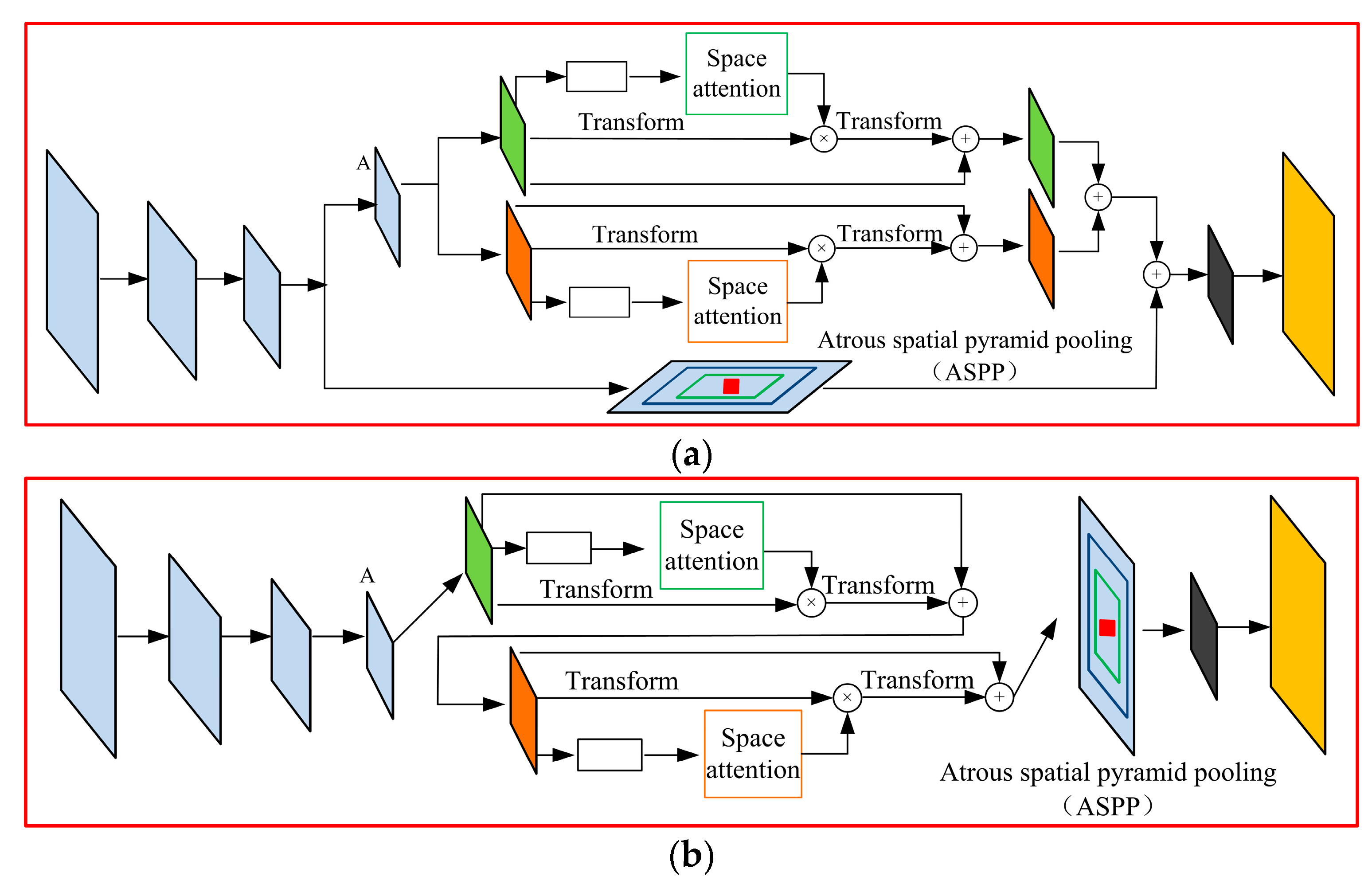
β is the learning parameter, and each channel feature is the weighted sum of all channel features and the original channel features, so the channel attention module can simulate the long-term semantic dependence between different feature maps to enhance feature representation. Based on the above analysis, the Deeplabv3+ model of double attention mechanism is proposed, and the network structure is shown in
Figure 5.
Figure 5a shows the parallel network of DAMM and ASPP. The trunk network is used to extract image features, two branch networks are adopted to process the feature images extracted from the backbone network, and then the two branch feature images are fused. The upper branch in the figure is a dual attention mechanism module (channel attention and spatial attention). The two modules operate in parallel in the dual attention module. The feature images extracted from the backbone network are convolved with a dilation rate of 2 and a convolution kernel of 3 × 3, and then sent to the channel attention module and the location attention module for processing, respectively, and the feature images are summed. The channel attention module uses the correlation between the relevant category features of different channels to strengthen different category features and improve the classification accuracy, while the spatial attention module promotes the classification accuracy of different local features by simulating the connection between different local features. The lower branch fuses the feature image processed by ASPP with the feature image processed by the dual attention module, and finally reduces the dimension of the fusion feature image. The network decoding module adopts the DeepLabv3+ decoding module to operate, and finally, the image segmentation map is obtained.
Figure 5b shows the series network of DAMM and ASPP. It uses the trunk network to extract feature images, and the feature images are convolved with an expansion rate of 2 and a convolution kernel of 3 × 3. The results are sent into DAMM for spatial and inter-channel pixel feature enhancement of feature images and then input into the ASPP module for multi-scale target segmentation. Finally, the decoding and restoration of the feature map are carried out according to the original network method.
2.4. Segmentation Model Based on HRNet
To improve the accuracy of coastline extraction, an enhanced network segmentation model based on depth discrimination is proposed. It mainly includes data preprocessing, depth feature extraction, similarity calculation, and loss minimization function calculation. The output of the lth layer of the convolutional neural network is zl, and {Hl, Wl, Cl} is the feature resolution.
HRNet is adopted to achieve feature extraction, and the structure is shown in
Figure 6. HRNet consists of four network branches that are used to extract features of different scales. In the last layer, multi-scale features are superimposed and fused, and the basic structure of HRNet consists of a convolution layer and an upsampling layer.
For the
l-th convolutional network, its input data is
zl−1, and then the corresponding convolution expression is:
where
f(.) is a nonlinear corresponding function, and if the moving step of the convolution kernel reduces the spatial dimension of the data in the process of feature extraction, upsampling is used to expand the spatial dimension of the feature map to make the feature map and the original input image have the same spatial scale. HRNet uses bilinear differences to restore the spatial dimensions of feature maps. The convolutional neural network obtains the depth feature vector corresponding to each pixel layer by layer and through superposing convolutional layer, up-sampling layer, and other networks. Softmax is used to classify the extracted features. It is assumed that the convolutional neural network adopted has a total of
L layers, and then the
l-th layer network is classifier Softmax:
where
z0,i is the
i-th pixel of the input image, and
p(
k|
z0,i) represents the probability that sample pixel
z0,i belongs to the k class. The essence of Softmax process can be regarded as similarity calculation, which calculates the inner product of feature vector
zL−1,i of pixel
z0,i as the similarity to judge the membership degree of pixel
z0,i. Therefore, the parameter vector
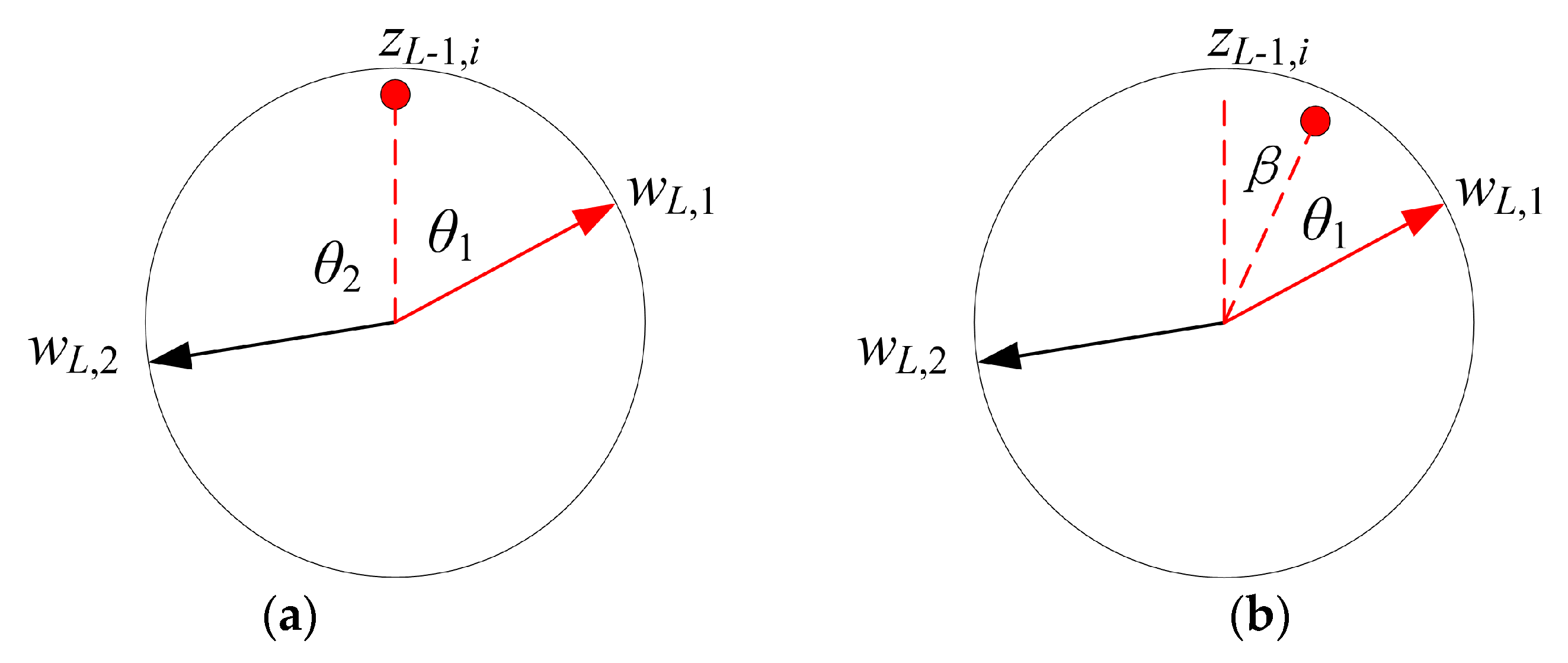
wL,c of each class can be regarded as the corresponding category center of this class. When the modules of the parameter vectors of each category are equal, the inner product similarity between the depth features of the pixel to be classified and the category center is transformed into the included angle between the high-dimensional depth features of the comparison pixel and the category center of each category, that is, the category of the pixel to be classified is judged by calculating the included angle between the depth features of the pixel to be classified and the category center. Because the angle
θi,1 between feature point
zL−1,i and category center
wL,1 is the smallest, pixel
z0,i is divided into class 1. At this point, Softmax is transformed into:
Therefore, to increase the distinctiveness of depth features and make the depth features of similar pixels get to its corresponding category center, the included angle between category center
wL,c in the Softmax and depth features of pixels is taken as a similarity for measurement, and then the punishment factor
β is added to make the training sample and its corresponding category center have a smaller angle in the training stage. The corresponding included angle is:
For any pixel
z0,i, assuming its category is
t, then its probability of belonging to class t is:
In the loss calculation stage, the classification probability is maximized according to the maximum likelihood rule, and the classification loss function is obtained:
where m is the number of trained pixel samples;
yi is the category of pixel i. When
J takes the minimum value, it forces the sample to move to the center of its category, making the included angle smaller to compensate for the angle increase caused by the penalty factor
β. By comparing
Figure 7a,b, it can be seen that traditional Softmax and improved Softmax are used to calculate the probability that
z0,i belongs to class l. When the two get the same probability, the included angle between pixel
z0,i and class center
wL,1 in
Figure 7b is smaller than that in
Figure 7a. Therefore, in the training stage, the feature of the pixel sample is made to get close to its corresponding category center.
In the training stage, network parameters are updated by alternatively carrying out forward and backward operations. In the backward stage, the gradient descent algorithm is adopted to update network parameters:
where
w represents the parameters of each layer in the convolutional neural network;
λ is the learning rate, which is used to control the step length of network parameter update.
2.5. Coastline Recognition Algorithm Based on Image Straightening
Based on the above introduction, we have obtained the segmentation algorithms of the two models, which need to be fused. Currently, the main fusion methods are: pixel-level image fusion, feature set fusion, and decision set fusion [
70].
Pixel-level image fusion directly fuses the pixel points of the image. The scale of original image data results in time-consuming algorithm implementation. Without data processing, the advantages and disadvantages of the original sensor information will overlay and affect the fusion effect. The requirements of hardware facilities are quite high. When carrying out image fusion, the accuracy requires to be each pixel of the sensor data; As it is based on pixel calculation, pixel information is susceptible to pollution, noise, and other interference, so the effect is not stable.
Feature-level fusion is a process in which edge, shape, contour, local feature, and other information are synthetically processed after feature extraction. Feature-level fusion includes target state information fusion and target characteristic fusion. Feature level fusion includes several modules: source image acquisition, image preprocessing, image segmentation, feature extraction, feature data fusion, and target recognition. The feature fusion of an image is a kind of cost processing, which reduces the amount of data, retains most of the information, and still loses part of the details. The combination of original features form features, increases the dimension of features, and improves the accuracy of the target. Feature vectors can be directly fused or recombined according to the attributes of features themselves, and edge, shape, and clearance light are all important parameters to describe features. Target state feature fusion is a kind of target statistical feature based on multi-scale and multi-resolution, and it extracts and describes the original data state of the image and requires strict registration, and an image containing more image information can be obtained ultimately. It conducts statistics of state information of an image and then performs pattern matching. Its core idea is to achieve accurate state estimation of multi-sensor targets, and it is effectively associated with prior knowledge, so it is widely used in target tracking. The target feature fusion is the internal description of the feature extracted from the image features according to the specific semantics, or the recombination of feature attributes. These feature vectors represent abstract image information, and the features are directly recognized by machine learning theory fusion, which increases the dimension of features and improves the accuracy of target recognition. Target feature fusion is feature vector fusion recognition, which generally deals with high-dimensional problems. In essence, the fusion application is mostly pattern recognition. Compared with a single sensor, the information provided by a multi-sensor increases the dimension of feature space and enlarges the space of fine information feature scattering.
Decision-level fusion: on the basis of each sensor independently completing the decision or classification, the recognition results of multiple sensors are fused to make the global optimal decision. According to certain rules, the decision-level fusion can synthesize the source image after feature extraction and recognition and then obtain the fusion image. The input of the decision is the cognitive framework of the target. The recognition framework is formed after the basic processing of preprocessing, feature extraction and recognition by observing the target in the same scene through homogeneous and heterogeneous sensors. The fusion result is obtained by optimization decision. The decision-level fusion tends to be intelligent logic, and the recognition result of the integrated multi-sensor is more accurate and effective than single recognition. The advantages of the decision-level fusion are as follows: it has good real-time performance and self-adaptability, low data requirements and strong anti-interference ability; it is able to efficiently be compatible with multi-sensor environmental characteristic information; it has good error correction ability; it can eliminate the error caused by a single sensor through proper fusion; and the system can also obtain correct results.
As there are certain rules for the environment around the coastline, we firstly fuse the decision sets of the dual-attention network and HRnet network mentioned above, and then set thresholds to constrain pixel attributes. Let the probability that the pixel point (
x,
y) extracted by the dual attention network is a coastline be
P1(
x,
y) and the probability that the pixel point (
x,
y) extracted by the HRnet network is a coastline be
P2(
x,
y).
P = (
P1(
x,
y) +
P2(
x,
y))/2 and set a threshold
T to constrain the pixel properties, which is chosen to be 0.6 in this paper. Secondly, with the coastline as the center and
D as the width, the image data around the center line are obtained, and these data are straightened out to visually display and analyze image data as show
Figure 8. The areas belonging to the coastline are retained and others are removed.
4. Conclusions
In the face of the actual demand for coastline extraction and the problem of difficult coastline recognition, we established models from the perspective of image enhancement, dual attention network recognition, and HRENT network construction, and realized coastline extraction through the fusion idea of decision sets. Experiments show that the proposed algorithm accurately focused on the difference between sea and land to build a coastline straightening model, aiming to realize the intuitive display of the coastline. The specific innovations can be summarized as follows: (1) a PCA image enhancement algorithm was proposed based on remote sensing image features; (2) the spatial attention and channel attention models were proposed, and suspected regions were extracted from parallel and series perspectives; and (3) the improved Softmax function improved HRENT network performance. The idea of decision set fusion was adopted to realize coastline extraction, and a coastline straightening algorithm was proposed to intuitively display the effect.
However, in the research process, there are still the following problems: (1) remote sensing images have high resolution, and still take a lot of time during training and testing, which cannot meet the requirements of real-time detection; (2) the decision set fusion method currently adopted relies on the same group of data to carry out the training of dual attention network and HRENT network, and further studies are needed to determine if the algorithm is extensible; and (3) in the process of image straightening, due to the vertical angle problem, there is the problem of insufficient spatial resolution in the sampling process, resulting in poor visual effects or blurred images, so we will carry out further studies based on the above issues.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}