1. Introduction
Change detection technology is used to identify and extract information from two or multiple temporal images in the same area at different times [
1]. Due to the increasing frequency of changes in human activities, timely analysis of changes in surface ecology is of great significance to the rational development of environmental resources [
2]. Change detection technology has become an important task in the field of remote sensing [
3]. Relying on the advancement of spectral imaging technology, we can obtain multi-temporal spectral images more conveniently, which further promotes the development and practical engineering application of change detection in related research fields [
4]. The multispectral image-based change detection technology has been widely used in different disciplines such as the military, agriculture, environment, and urban planning [
5].
In early multispectral change detection research, the information of independent pixels or adjacent pixels was mainly used to discriminate the change area [
6]. For example, Bovolo et al. proposed a change vector analysis method (CVA), which calculates the degree of change through the size and direction of the pixel vector between different phases, and obtains the change intensity map, and finally according to the threshold segmentation to determine the changing areas [
7]. Multivariate change detection (MAD) and its improved iterative weighting method (IR-MAD) detect change pixels by maximizing the difference of change vectors through canonical correlation analysis [
8,
9]. Wu et al. proposed a new slow feature analysis theory, which attempts to find pixels with a small degree of change in multi-temporal images [
10]. L. Bruzzone et al. treated the image data as a Markov random field (MRF) model [
11]. Each pixel can be seen as a random variable, and its state is related to the gray value of the field pixel. Thus, the spatial domain information is used, and an iterative algorithm is used to calculate the final converged change detection result. For MRF, in the global probability framework, the neighborhood system is used to model the interaction of adjacent pixels. However, MRF is modeled under the assumption of independence, which leads to over-smoothing problems [
12]. In order to overcome this problem, Hoberg et al. [
13] introduced conditional random field (CRF) into classification and change detection. Zhao et al. [
14] proposed a classification algorithm based on conditional random field. By modeling the probability potential, the spectral clues can provide basic information for distinguishing various types of land cover. The pair-wise potential considers the spatial context information by establishing the adjacent interaction between pixels, which is beneficial to spatial smoothing. Although MRF can solve some problems of salt-and-pepper noise, because it does not have the limitation of remote dependence, it will lead to inaccurate edge location. Fully connected conditional random field (FC-CRF) overcomes this problem, fix fine mis-segmented areas, and obtain a more detailed segmentation boundary by establishing the connection relationship between all pixels in the image [
15,
16]. On the other hand, the above method based on conditional random field only considers a single piece of difference information to construct the pair-wise potential function, which easily causes the lack of information.
These classical methods only use the original shallow features and have poor detection performance in the face of complex scenes [
17]. The high spatial resolution of multispectral images results in complex ground object details, and a complex environment brings more challenges to change detection [
18,
19,
20].
Deep neural networks were recently shown to be suitable for handling detection tasks in such complex scenes [
21,
22]. Since the input of the change detection task is multi-temporal data, one of the most common network structures is to use the Siamese neural network to input images of different phases into multiple sub-networks with the same structure, and then integrate the sub-network extraction through subsequent networks to obtain the final change detection result. For example, Zhang et al. [
23] used two sub-networks with shared weights to extract high-dimensional features of image patches in different phases, respectively, and then used a multilayer perceptron to discriminate the changes of the features extracted from different image patches. This Siamese network is a late fusion method, which extracts features from multi-temporal images, respectively, and then inputs the extracted features into another network in a certain combination to identify changing features. Another common method is early fusion [
24,
25], which is to superimpose data of different phases first, and then input it into a deep network for end-to-end change detection. The network structure used is generally a fully convolutional network (FCN) [
26]. The FCN uses multiple upsampling and downsampling layers to directly output the changing binary image, and this structure allows its input size to be arbitrary. Rodrigo [
27] designed three change detection networks to study the effect of early fusion and late fusion on change detection results, and summarized the change detection scenarios and tasks that different network structures are suitable for. Chen et al. [
28] proposed a novel fully convolutional network that uses a long short-term memory network (LSTM) to extract time-varying information, which enhances the use of features and achieves good results on urban datasets. Kusetogullari et al. [
29] proposed a parallel binary particle swarm optimization (PBPSO) algorithm. First, the difference image is calculated by multi-temporal multispectral image fusion, and the difference image is manipulated by PBPSO algorithm through iterative minimization of cost function to produce the final result. Hou et al. [
30] directly used the pre-trained VGG-16 network as a feature extraction extractor for multi-temporal images. Liu et al. [
31] proposed a new change detection method using convolution neural network to extract change features under the framework of object-based image analysis (OBIA). This method combines deep learning technology and OBIA technology, and effectively improves the detection effect and accuracy. The above methods based on deep learning only use a single size convolution kernel to extract features. However, multispectral images often contain many different land covers, such as buildings, vehicles and pedestrians, and these objects are often displayed at different sizes in the image. Therefore, more robust multispectral image change detection methods often require the ability to detect objects at multiple scales.
Due to the development of convolutional neural networks, multi-scale feature extraction is possible. For example, Chen et al. [
32] added a multi-scale convolution module to the Siamese network in order to extract multi-scale features in complex ground objects. Compared with traditional single-scale features, this module can extract multi-scale features. The spatial spectral features of the neural network are refined by the conditional random field (CRF) to obtain more accurate change results. Song et al. [
33] used transfer learning and recurrent fully convolutional networks with multiscale three-dimensional (3D) filters, which can extract meaningful features better and improve the detection accuracy. Zhang et al. [
34] proposed a Siamese change detection method called SMD-Net, which used multiscale difference maps for stepwise enhancement of information in change regions. The results show that the method has excellent performance in detecting object integrity, small object detection and object edge detection. Several of the above methods showed that the multi-scale feature extraction capability can be very helpful for change detection. However, for a multispectral image, different scales have different percentages. Therefore, it is necessary to consider assigning adaptive weights to different scales when extracting features, so as to obtain finer multi-scale features.
Since Volodymyr [
35] applied the attention mechanism to the field of computer vision, scholars from various countries have been interested in it. For example, Zhang et al. [
36] first used a fully convolutional dual-stream structure to extract highly representative deep features in parallel, and used the attention mechanism in the feature difference recognition module to enhance the feature expression, and the whole method of deep supervision training was used to enhance the network performance. Peng et al. [
37] proposed a dense attention method consisting of multiple upsampling attention units in order to model the internal correlation between high-level features and low-level features. The method employed both upsampling spatial attention and upsampling channel attention, and could use high-level elements with rich category information to guide the selection of low-level elements, as well as spatial contextual information to capture the changing elements of ground objects. Fang et al. [
38] proposed a densely connected Siamese network (SNUNet) and an ensemble channel attention module (ECAM) for in-depth monitoring. Through ECAM, the most representative features at different semantic levels can be extracted and used in the final classification. Chen et al. [
39] proposed a spatial-temporal attention neural network and designed a self-attention mechanism to simulate the spatial-temporal relationship. The experimental results show that the self-attention module can well suppress the false detection caused by registration errors in bitemporal images, and is more robust to the changes of color and scale. These examples show the effectiveness and reliability of the attention mechanism. Spatial attention can focus on the areas related to the detection task in the image, while channel attention enhances or suppresses different channels for different tasks by calculating the importance of each feature channel. Therefore, the spatial channel joint attention gives the feature map a better expression of change information in both the channel dimension and the spatial dimension [
40].
Multispectral images with high spatial resolution have rich detail of ground objects, and changing objects may show different scales. Compared with the feature extraction module using a single-scale convolution kernel, extracting more representative multi-scale change features in multispectral images can better maintain the structural integrity of the change region. For different change scenarios, the detection network assigns different weights to convolution kernels of different scales to extract features without human participation, which is very meaningful. Another limitation is that the deep neural network will lose part of the original image information during the information transfer process, which leads to inaccurate positioning of the detected boundary of the changed region, and requires subsequent processing techniques to solve the problem of small-scale misclassification and refine the classification boundary. The method based on FC-CRF can solve this kind of problem, but only consider the single difference information when constructing pair-wise potential function will cause the lack of information. Therefore, it is necessary to consider the use of multimodal differential information to construct the pair-wise potential function.
According to the above analyses, a multispectral image change detection method based on multi-scale adaptive kernel network and multimodal conditional random field (MSAK-Net-MCRF) is proposed. Facing the complex environment of multispectral images, a selective kernel convolution block is used to extract spatial features of different scales, which has convolution branches with different sizes of convolution kernels and can enhance the feature extraction capabilities of the network. At the same time, the neural network assigns an automatically learned convolution kernel weight to each convolution branch to measure the importance of features at different scales. Then the attention model is used to selectively enhance and filter the fusion of shallow features and deep features in the network. Finally, use the multimodal conditional random field to subdivide the detection results of the neural network, refine the boundary information of the change object, and obtain more accurate change detection results. The contributions of this paper are summarized as follows:
- (1)
A multispectral image change detection framework based on multi-scale adaptive kernel network (MSAK-Net) is designed, which is an encoder-decoder architecture. The framework extends the U-Net bilaterally and retains the jump connection. The encoding path effectively mines the multi-scale deep features in the original image. An attention mechanism is introduced into the decoding path to enhance the use of useful information. After that, the multimodal conditional random field is used to post-process the network results to refine the classification boundary.
- (2)
A selective convolution kernel block (SCKB) is designed to fully exploit the complex spatial features in multispectral images. SCKB assigns an adaptive weight to the convolution branches of different scales to obtain better multi-scale features. In addition, the designed upsampling module is embedded in the decoding path, which uses the attention mechanism to integrate the change information and improve the use of the useful information of the task.
The rest of this paper is organized as follows. In
Section 2, the proposed method is represented in detail. In
Section 3, we describe the datasets and the environmental conditions of the experiments. In
Section 4, we carry out experiments and analyze the experimental results in detail. Then, in
Section 5, we explain in detail the impact of various parts of the network on the results. Finally, conclusions are drawn in
Section 6.
2. Methodology
In this section, the overall architecture of the proposed change detection method is elaborated first. Subsequently, we introduce the structure of the MSAK-Net in detail. Finally, we provide a detailed account of the proposed multimodal conditional random field.
2.1. The Framework of the Change Detection Algorithm
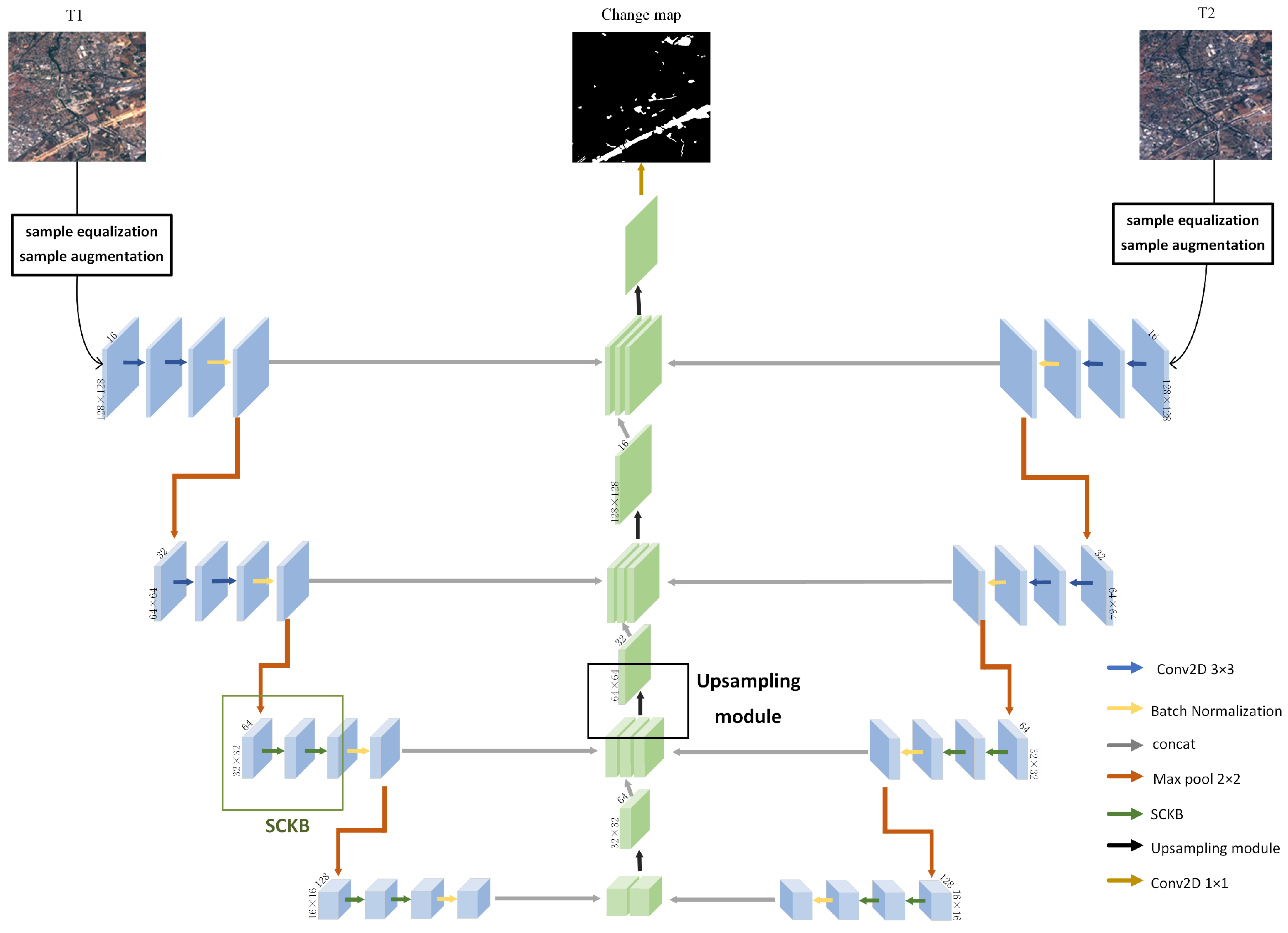
To effectively extract adaptive multi-scale features, resolve small range misclassification, and refine classification boundaries, a multispectral image change detection algorithm is proposed, whose framework is shown in
Figure 1. The first step is to use sample equalization and sample augmentation to reduce the impact of sample imbalance on MSAK-Net. The second step trains MSAK-Net in an end-to-end manner and outputs a change probability map. The third step is to construct the unary potential function and the pair-wise potential function of fully connected conditional random fields (FC-CRF) with change probability map and multimodal difference map. The multimodal conditional random field is used to fully consider the correlation information between pixels, and change detection result is obtained.
The loss function of MSAK-Net using weighted cross-entropy loss is:
where
represents the label of the
ith pixel. When the
ith pixel belongs to the changing pixel,
is 1, otherwise
is 0.
represents the prediction result of MSAK-Net for the
ith pixel, because the activation function of the last layer of the network is Sigmoid, so the value of
is a probability between zero and one. The larger the
, the greater the probability that MSAK-Net considers the pixel to belong to the changing area. On the contrary,
represents the probability that MSAK-Net predicts a non-changing pixel. It can be seen from the above formula that the optimization process of cross entropy is to increase the predicted probability
of the change pixel corresponding to
, and increase the predicted probability
of the non-change pixel corresponding to
.
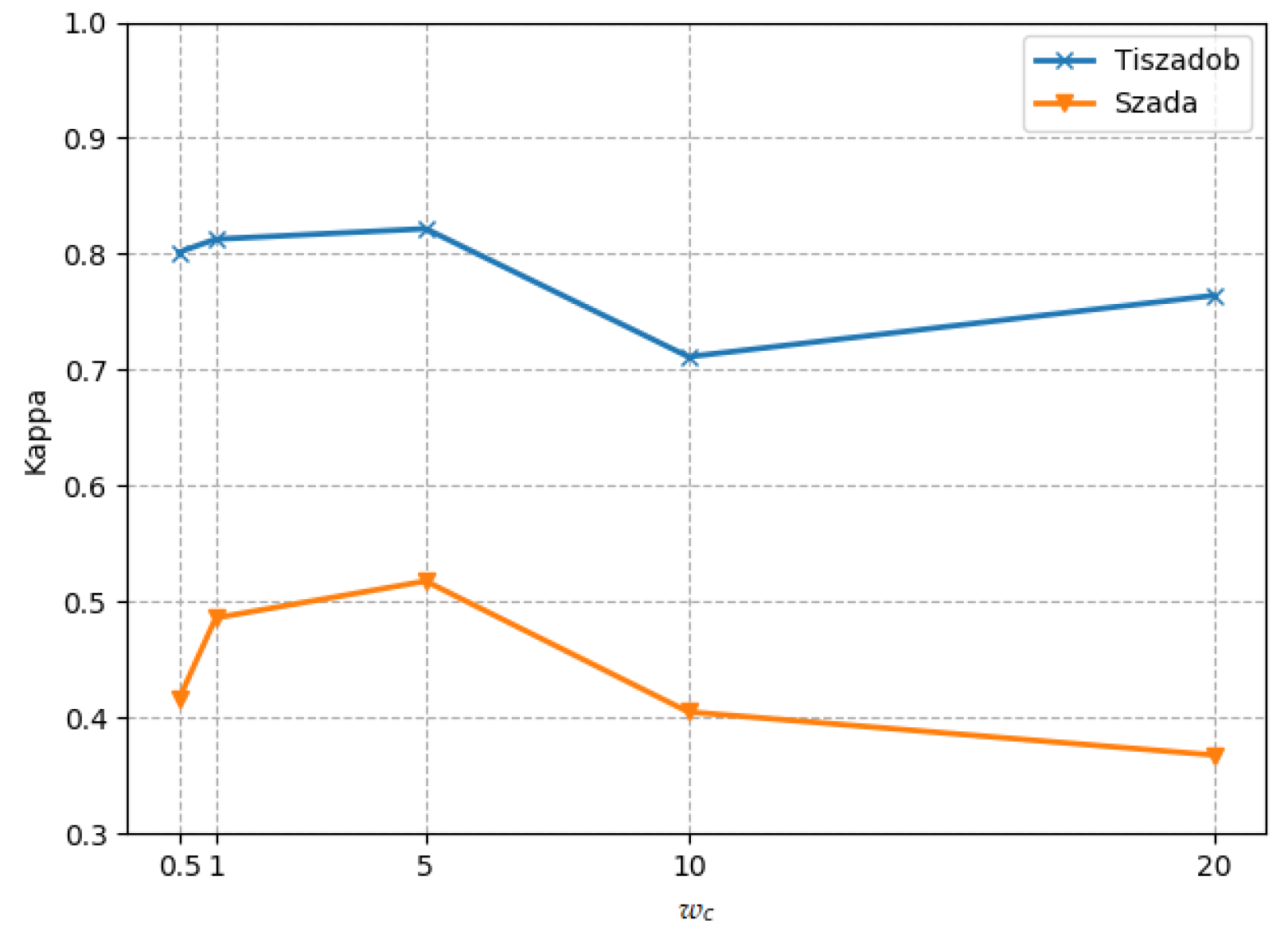
is the class weight, which is generally the ratio of the number of non-changing samples to the number of changing samples, usually a value greater than 1. We first set it empirically to 5. In
Section 5.3, we detail the effect of this weight parameter on the experimental results The weighted cross-entropy is to give a class weight when calculating the cross-entropy of the change class samples with a small number of samples. In this way, the cross entropy calculated by the change samples is larger, which makes the network pay more attention to the change samples, and can improve the recall rate of detection.
2.2. The Architecture of the MSAK-Net
Since change detection can be treated as a binary image segmentation, MSAK-Net adopts U-net as the backbone, which is an advanced image segmentation network. U-Net is divided into encoding path and decoding path, but the single encoding path limits the full use of original information from dual-temporal multispectral images. Some scholars extract the difference information, merge the dual-temporal multispectral images into a single difference features map, and then perform deep feature extraction through the encoding path. Another method is to superimpose the dual-temporal multispectral images along the channel dimension, and then input the encoding path. In order to preserve the original features of the dual-temporal multispectral images, we extend the encoding path of the U-Net. A weight-sharing bilateral encoding path is designed to extract independent features of two images without introducing additional parameters. The encoding path consists of four layers of convolutional modules, and the architecture of MSAK-Net is shown in
Figure 2. The first two convolutional modules map the original image space into a high-dimensional feature space and consist of two convolutional layers with
convolution kernels and a batch normalization layer. The next two layers of convolutional networks use two consecutive SCKBs to extract rich multiscale features, and then a batch normalization layer is used to prevent overfitting. A max pooling layer is set between every two layers convolutional module to filter out robust high-dimensional features. Each convolutional modules reduces the resolution of the output feature map to half of the input feature map, but doubles the number of channels.
The decoding path consists of four upsampling modules (UM) introduced in
Section 2.4. Our proposed change detection framework preserves skip connections in U-Net networks. The shallow features and deep features are superimposed along the channel dimension and handed over to the subsequent channel attention for channel reorganization. The input of the first upsampling module is the superposition of the results of the two encoding paths. The input features of the latter three upsampling modules are directly superimposed by the output of the previous upsampling module and the output features of the two encoding paths of the same level. In contrast to the change of feature maps in the encoding path, each upsampling module in the decoding path doubles the feature map resolution. The output features of the last upsampling module go through a convolutional layer with a
convolution kernel to adjust the number of channels of the final change detection map.
In the MSAK-Net, all convolutional layers use the ReLU activation function to alleviate the gradient disappearance, except that the last convolutional layer in the decoding path uses the Sigmoid activation function to calculate the probability intensity of the change map.
2.3. Selective Convolution Kernel Block
In response to the above situation, some scholars proposed using the Inception network to extract spatial features of different sizes [
41]. The main idea of the Inception network is to improve the network performance by increasing the width of the network. The network uses
,
, and
convolution kernels to extract features of different scales, and finally fuses multi-scale features through concat operation. Because the weights of each branch in the Inception network are the same, the network pays the same attention to features of different sizes. However, an appropriate weight allocation strategy should depend on the application scenario. Focusing on the above issues, we adopted a selective convolution kernel block (SCKB) to extract multi-scale features with adaptive weights from multispectral images. The structure of SCKB is shown in
Figure 3.
The SCKB is divided into three convolution branches, each of which includes a convolution layer, a batch normalization layer, and an activation layer. The size of the convolution kernel in each convolutional layer is
,
and
, respectively, corresponding to different receptive fields, which are used to extract features of three sizes. Suppose the input feature map is
F, and the three sizes of feature maps are
,
, and
. Before calculating the weight of the convolution kernel, it is necessary to integrate the feature information of the three branches. The calculation formula of the multi-scale feature map
U is:
Assuming that the size of the input feature map
F is
, the size of the deep features obtained by the three convolution branches remains unchanged. These three deep features are superimposed on the channel dimension through the concat operation to obtain a multi-scale feature
U with a size of
. The global information is encoded by global average pooling, and then a one-dimensional feature vector
S is generated. The
cth element of the feature vector
S is calculated as follows:
Then two convolutions are introduced to fuse all the statistical information to merge the interdependence between the channels in the feature vector S, thereby enhancing the information expression of the feature map of a certain scale. There is dimension scaling in the above process, and the output of the second convolution is reshaped into a score matrix of size . The score matrix is mapped into a weight coefficient matrix through Softmax calculation, and the sum of the three values in each column is one, which corresponds to the weight of the output results of the three convolution kernels at the channel. The weight coefficient matrix is obtained by the network through learning, and automatically assigns the most appropriate weights to the multi-scale features of three different convolution kernels. Finally, the weighted value of each feature map and the corresponding weight is calculated to obtain multi-scale fusion features.
The SCKB automatically adjusts the weights assigned to the three multi-scale features , , and according to different application scenarios, thus enabling the network to choose the most appropriate convolution kernel size.
2.4. Attention Module-Based Upsampling Unit
Although CNN can extract rich high-dimensional features from multispectral images, not all high-dimensional features contain useful change information, and irrelevant high-dimensional features can also bring challenges to change detection. In addition, in order to improve the use of information and prevent the loss of detailed information, U-Net use skip connections to reorganize the shallow features in the encoding path and their corresponding deep features in the decoding path [
42]. However, a large number of features unrelated to change detection are also present in the shallow features with local information. Therefore, Attention Module (AM) is introduced to enhance the use of useful information. The AM is inspired by the perceptual process of the human visual system. The essence of AM is to make the network learn an attention weight. The weight corresponding to the important feature is larger, and the subsequent network will give it more attention. We added the Channel Attention Mechanism (CAM) and the Spatial Attention Mechanism (SAM) to the upsampling module of the U-Net, and designed an attention module-based Upsampling Module (UM).
An illustration of the UM is shown in
Figure 4. The channel attention mechanism can filter the relevant feature channels containing changing information in shallow features and deep features, and suppress the feature expression of channels containing redundant information. Since the input features of the UM are obtained by simple channel stacking of shallow features and deep features, it is first necessary to use CAM to optimize the channel dimension of the input features. The importance of each channel is encoded in a one-dimensional channel weight vector, and the weight coefficient of each channel is automatically learned by the network. The specific calculation process is as follows:
Here,
F represents the input feature, and
represents the weight vector of channel attention mechanism. First, perform max pooling and average pooling on the spatial dimension of
F, and obtain two feature vectors with the same length as the number of channels in
F. The feature vectors extracted by the two pooling operations are different. The max pooling is to obtain the most distinguishing features on each channel, and the average pooling is to calculate the global information of each channel. The two feature vectors are fed into a multilayer perceptron (MLP), respectively, and then the two output results are added at the pixel level. The addition result is mapped to a weight vector between zero and one by the Sigmoid activation function, and the value on each weight vector represents the importance of the corresponding feature channel.
is used as the output feature after CAM optimization, the optimization method of the final reorganization feature of channel attention mechanism is as follows:
Here, ⊗ is an element-wise multiply operation. Before the deep features are transferred to the next upsampling module, in order to enable the transposed convolutional layer to learn more significantly changing features from the feature map, a spatial attention mechanism is used to optimize and reorganize the feature map in pixel dimension.
Similar to CAM, SAM encodes the information at each pixel position in the input feature, and the network adaptively learns the spatial attention map. The structure of the spatial attention mechanism is shown in the SAM dotted box in
Figure 4. The calculation method of the spatial attention map is as follows:
where
F represents the input feature and
represents the spatial attention map. Similar to CAM, the input features are first encoded, average pooling obtains global information, and max pooling extracts robust information. Both pooling operations are one-dimensional pooling in the channel dimension, and finally two feature maps of size
are obtained. The
in Formula (
6) represents the concat operation. We superimpose feature maps encoded by two pooling layers into a
feature map. Then, the information is fused through a
convolution with a convolution kernel size of
, and finally the Sigmoid activation function is used to obtain the spatial attention map. After obtaining the spatial attention map, the calculation method of the spatial reorganization feature is as follows:
Channel attention mechanism enables the selective fusion of shallow features and deep features in U-Net results, while spatial attention mechanism suppresses the feature information of non-changing pixels and enhances the difference features of changing pixels. After the optimization of channel attention mechanism and spatial attention mechanism, the feature map has better expression of change information in both channel dimension and spatial dimension. The optimization process of the entire module requires the introduction of additional computation and parameters with just two MLPs and one convolutional layer. However, it can greatly improve the significant expression of changing features, which improves the accuracy and generality of the model. Our proposed upsampling module restores the lost pixels of the image by transposed convolution after the feature map is optimized by attention mechanism.
2.5. Secondary Classification Method Based on Multimodal Conditional Random Field
MSAK-Net has been able to achieve the classification and localization of change pixels, but there is still the problem of inaccurate localization due to information loss. In response to this problem, we use multimodal conditional random field (MCRF) to perform secondary classification on the results of MSAK-Net. The fully connected conditional random field (FC-CRF) is the optimization of the conditional random field, which overcomes the limitation of no remote dependence in the conditional random field by establishing the connection relationship between all the pixels in the image. The main idea of FC-CRF is to regard all pixels in the image as random variables in the random field model and to use an energy function to define the relationship between the pixels to describe the spatial correlation in the image, and map a set of input random variables to another set of random variables through modeling. At present, many related literatures have proved that using FC-CRF as the post-processing of the depth neural network can better recover the local information, so as to optimize the salt-and-pepper noise points in the classified image, fix fine mis-segmented areas, and obtain a more detailed segmentation boundary [
15,
16,
43,
44].
In the change detection, it is assumed that the input images
and
have
N pixels, respectively, and
is the difference map of
and
. Vector
is used to represent the classification result of the network output, and
represents the category (change, non-change) of the
ith pixel. The output result of FC-CRF is represented by
, and
represents the result of the secondary classification of the
ith pixel. The probability distribution function of a conditional random field conforms to the Gibbs distribution, and the Gibbs distribution is calculated by the product of a series of non-negative energy functions of maximal cliques in the undirected graph model, so the probability distribution of the FC-CRF output
Y is defined as follows:
where
i and
j range from 1 to
N,
represent unary potential function, and
represent pair-wise potential function.
is usually calculated from the output of MSAK-Net, and the formula is:
represents the probability intensity of MSAK-Net that the pixel
i belongs to the change pixel. The result of MSAK-Net contains more noise points and discontinuities, so it is necessary to introduce pair-wise potential function to consider the positional relationship between pixels. Most of the current pair-wise potential function are defined by the difference image
, and only considering a single difference information to construct pair-wise potential function is likely to cause information loss. Therefore, we use the multimodal information as the input information of FC-CRF and propose a new pair-wise potential function to calculate the secondary classification results. The redefined pair-wise potential function is expressed as:
where
and
are the pair-wise potential functions defined according to the grayscale difference map extracted by change vector analysis (CVA) and the spectral difference map calculated by spectral angle (SA).
and
are the weights of the two potential functions, respectively. They are usually set to 1, so as to balance the information provided by both, i.e., the proportion of the two difference information is the same weight. Taking
as an example, the detailed calculation formula is:
Here,
is a label,
if
and zero otherwise.
K represents the number of gaussian kernels.
is the weight coefficient of
.
and
are the feature vectors corresponding to pixel
i and
j. The gaussian kernels are defined as follows:
where
represents the position vector of pixel
i, and
represents the difference intensity of pixel
i in the CVA. The first gaussian kernel is used to define whether adjacent pixels with similar gray values in the difference map are of the same class.
and
are gaussian kernel parameters. The second Gaussian kernel is used to smooth the boundary and noise of the classification result, and the smoothing effect is determined by the parameter
.
and
are the weights of the above two Gaussian kernels. Calculation process of
is the same as that of
, the difference is that
uses SA spectral difference map to define the difference intensity. Finally, the class label of each pixel is derived using mean field approximation algorithm [
45].

 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}