1. Introduction
Synthetic aperture radar (SAR) is a high-resolution imaging radar with long-range, all-day, all-weather operation [
1,
2,
3]. It plays an essential role in ship detection, environmental inspection, geological mapping and other applications [
4,
5,
6]. As a fundamental maritime task [
7,
8,
9], SAR ship detection has received significant attention in areas such as marine traffic control, maritime distress rescue and maritime defence warning [
7,
8,
9]. The traditional and deep learning methods are the main methods of SAR ship detection [
10].
Traditional methods generally complete SAR ship detection tasks by manually extracting the geometric structure features, the electromagnetic scattering features, the transformation features and the local invariant features. The constant false alarm rate (CFAR) is the most widely and deeply applied traditional SAR ship detection method. Novak et al. [
11] proposed a two-parameter CFAR approach for modelling sea clutter using a Gaussian model. Gao et al. [
12] proposed a method based on Parzen-window-kernel density estimation as an SAR image ship detection method based on non-parametric modelling. Sugimoto et al. [
13] combined Yamaguchi decomposition theory with the CFAR method to accomplish SAR ship detection. Lang et al. [
14] proposed a hierarchical SAR ship recognition scheme by extracting texture descriptors to construct a robust ship classification and recognition representation. Leng et al. [
15] combined the SAR ship’s intensity and location information and proposed a bilateral CFAR method. Dai et al. [
16] proposed a CFAR SAR ship detection method based on the supervised learning approach based on object candidate regions. However, the traditional methods rely excessively on manual feature extraction, so this one has a tedious computational process and poor generalisation, which cannot meet the needs of SAR ship detection. With the rise of deep learning technology, SAR ship detection algorithms based on deep learning have been widely studied in recent years [
17,
18,
19,
20].
Deep learning SAR ship detection methods have shown excellent performance. Kang et al. [
17] used the object proposals generated by Faster R-CNN for the guard window of the CFAR algorithm to enhance the detection performance for small targets. Kang et al. [
4] also proposed a multi-layer fused convolutional neural network based on contextual regions, fusing deep semantic features and shallow high-resolution features to improve detection performance for small ships. Chang et al. [
18] developed a reduced YOLOv2 algorithm that has fewer layers than regular YOLOv2, and they achieved speed and accuracy improvements. Tang et al. [
21] developed a noise level classifier (NLC), an SAR target potential area extraction module (STPAE) and a YOLOv5-based detection module, N-YOLO, and achieved competitive performance. Cui et al. [
22] proposed a method based on CenterNet, which is based on spatial shuffle-group enhancement (SSE) attention, for large-scale SAR image ship detection. Zhu et al. [
20] proposed an R-FCOS method that can detect dim and small ships in large-scale SAR images with higher accuracy than other that of methods.
Current SAR ship detection research is mainly based on computationally intensive neural networks. Although achieving high detection accuracy, the computational complexity of such models is unsatisfactory. However, computational complexity and detection accuracy are equally essential for SAR ship detection tasks. Yu et al. [
23] designed the ASIR-Block, Focus-Block, SPP-Block and CAPE-Block modules based on the attention mechanism and feature pyramid network and constructed FASC-Net. Zhou et al. [
24] proposed the CSPMRes2 module for improving feature representation and the FC-FPN module for adapting feature maps, and constructed MSSDNet based on YOLOv5s. Liu et al. [
25] used YOLOV4-LITE and MobileNetv2 as the baseline network, proposed an improved receptive field block (RFB) structure to enhance the network’s feature extraction ability and proposed a sliding-window-block method to detect the whole SAR image, which can solve the problem of image input. Lightweight SAR ship detectors have excellent applications, especially in seaside defence warnings and sea distress rescue, which should not be neglected.
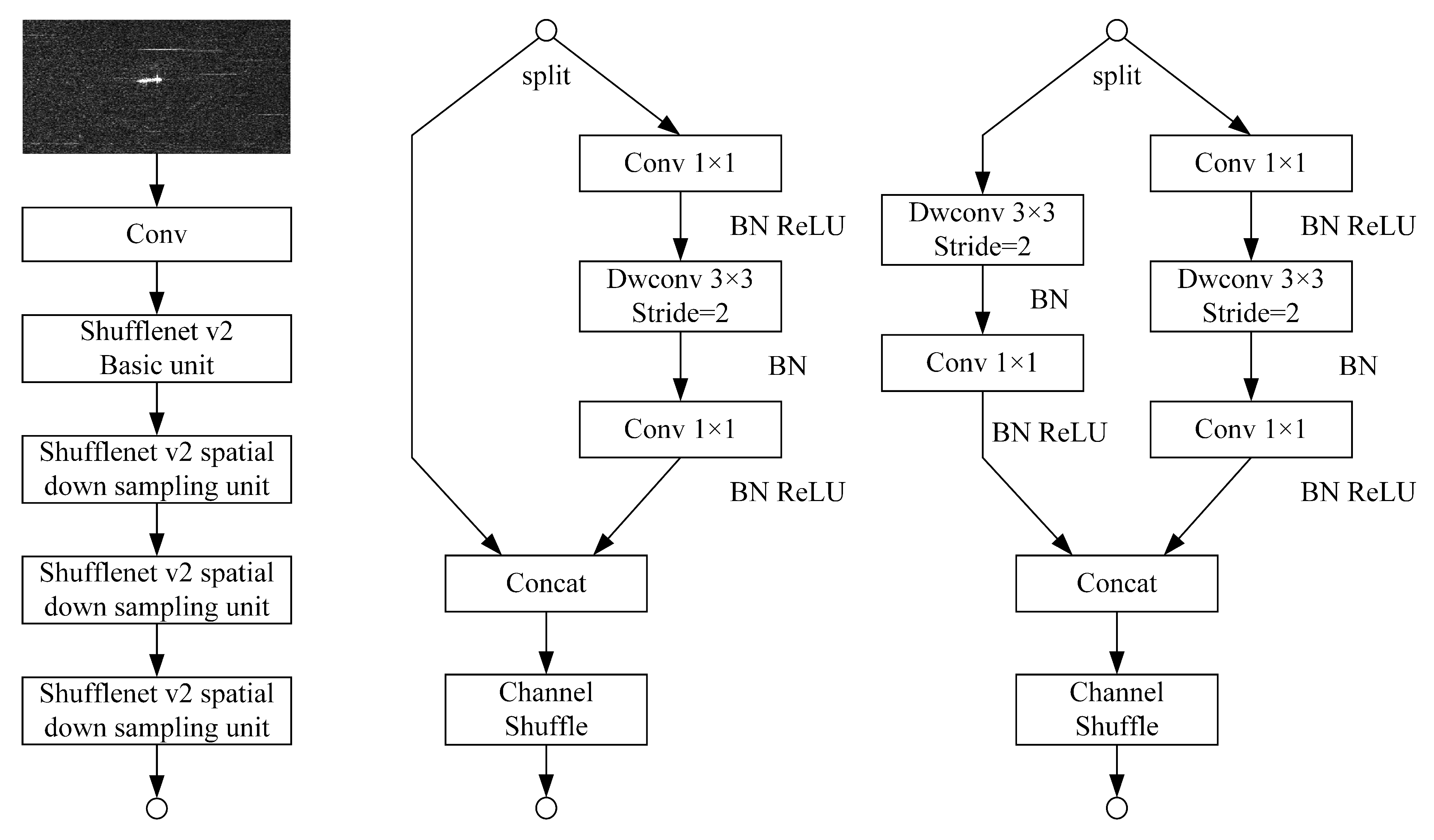
For this reason, we propose LssDet, an SAR ship detection method based on a lightweight convolutional neural network. LssDet implements a lightweight, anchor-free, one-stage SAR ship detection method which has sufficient robustness for multi-scale targets, complex backgrounds and large-scene SAR images; and it has a low computational cost and low parametric counts.
The main contributions of this paper are as follows:
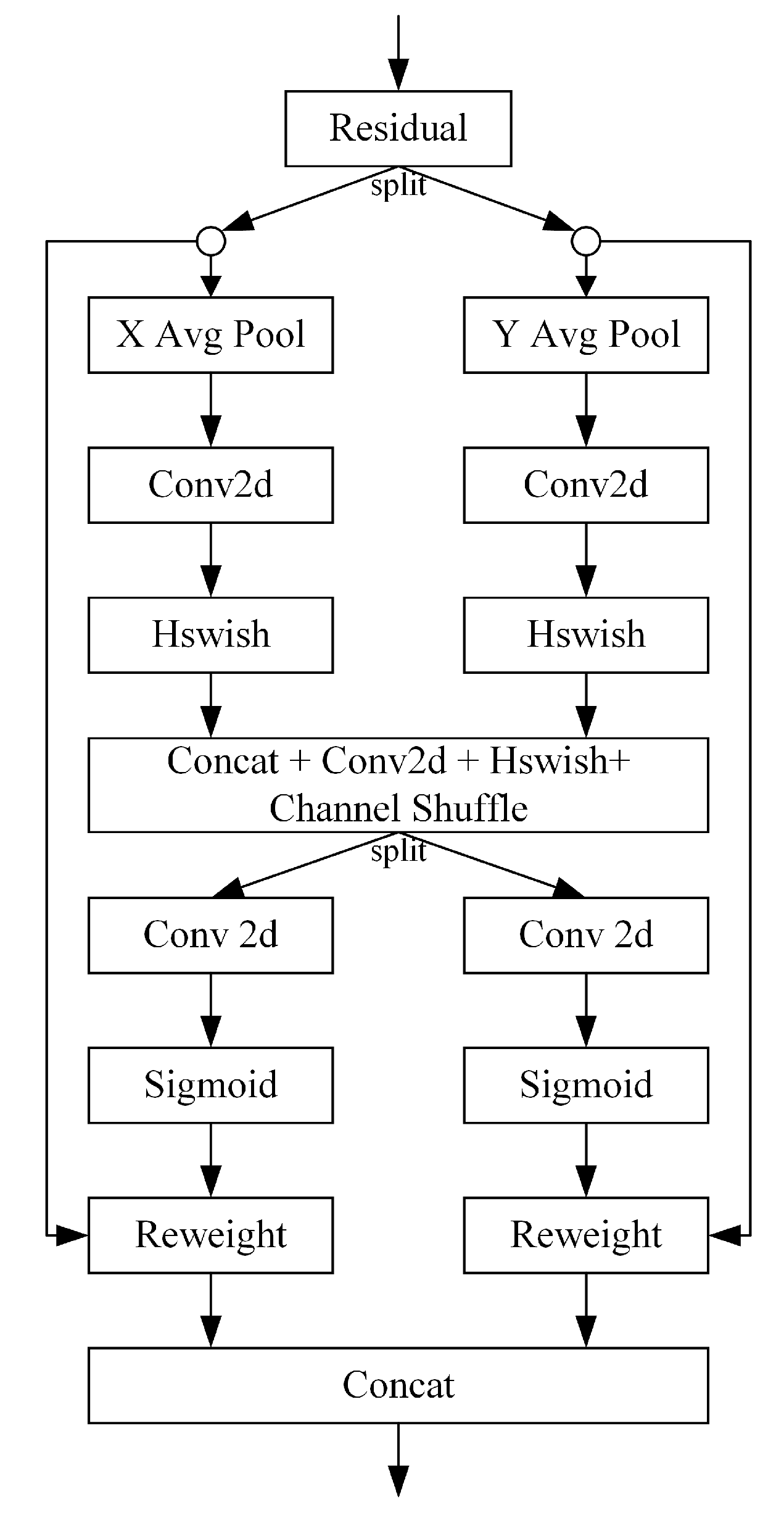
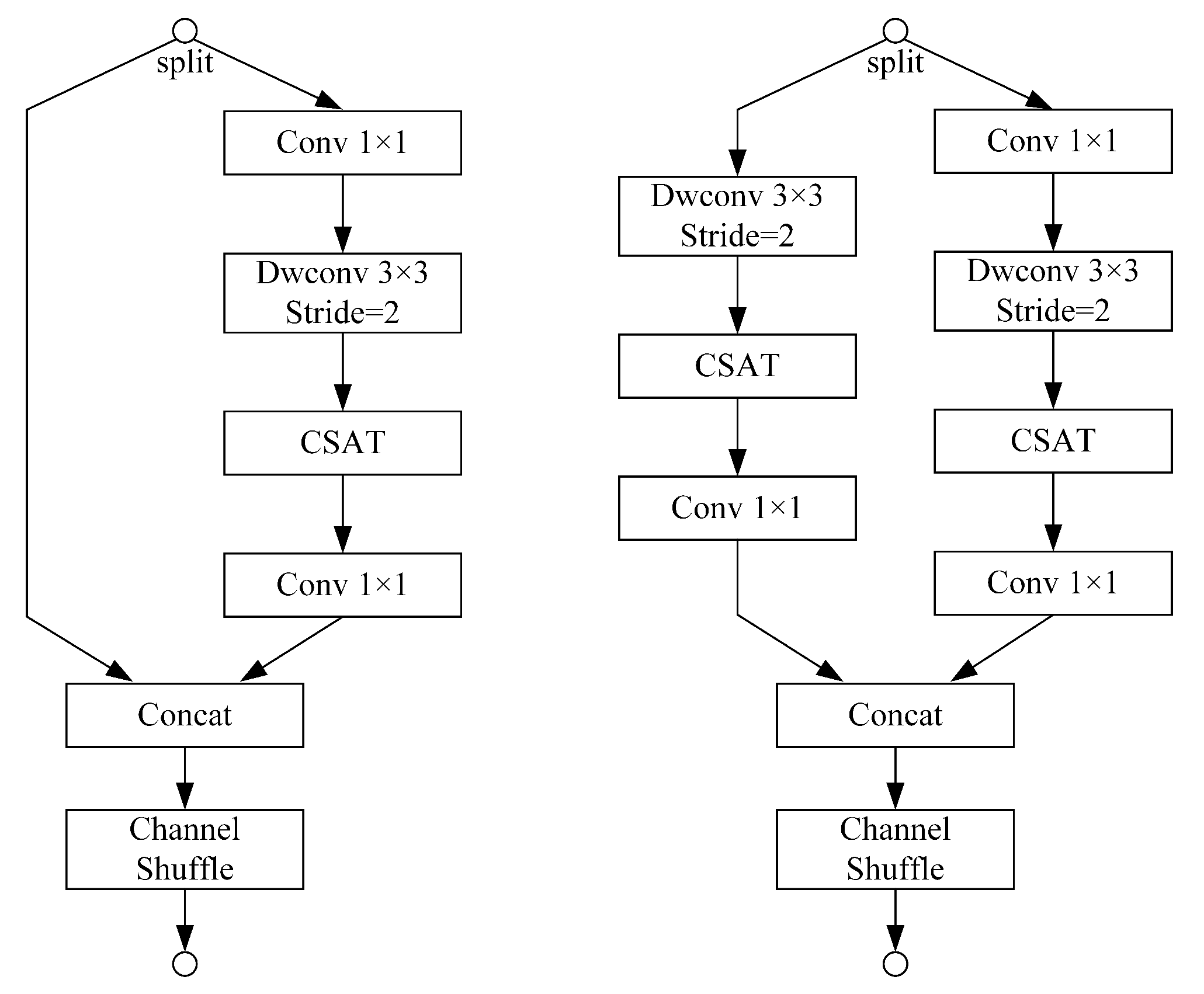
(1) A new attention module, the cross sidelobe attention (CSAT) module, is constructed. This module enhances the model’s attention to the cross sidelobe region and models the long-range dependence of the channel and spatial information, improving the method’s effectiveness for SAR ship detection.
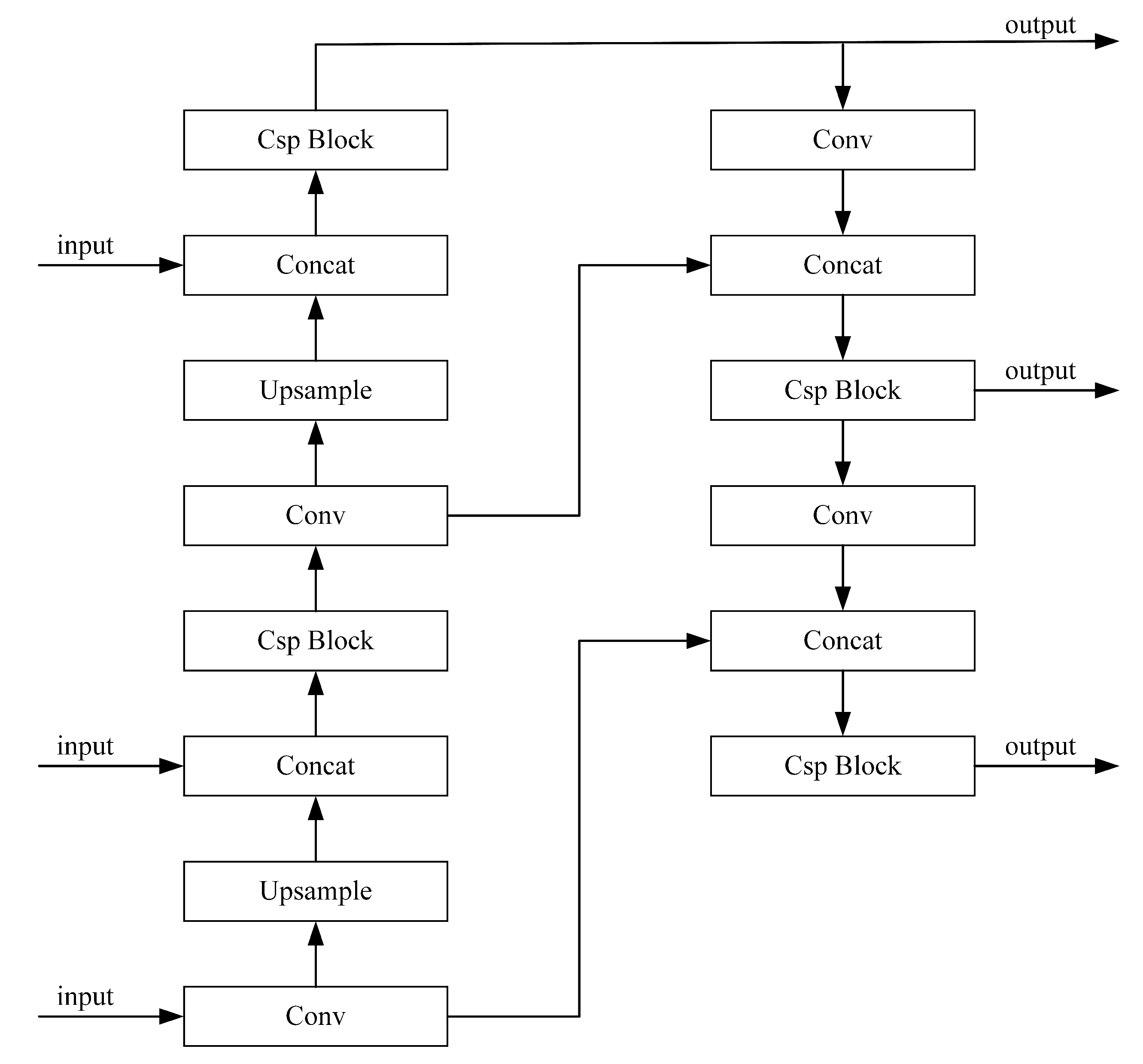
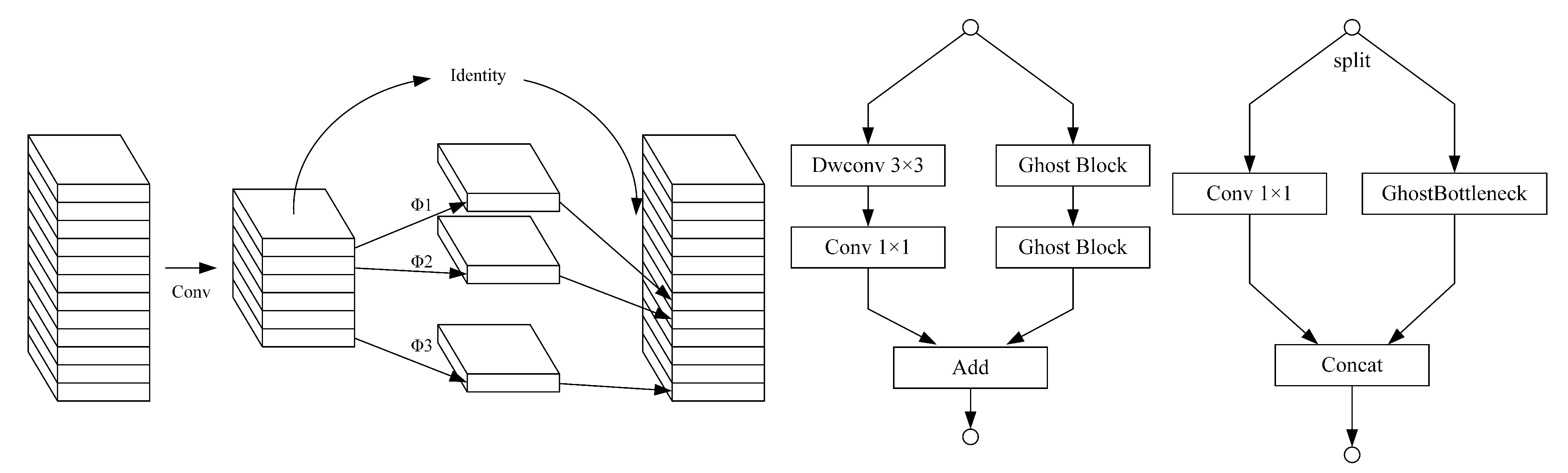
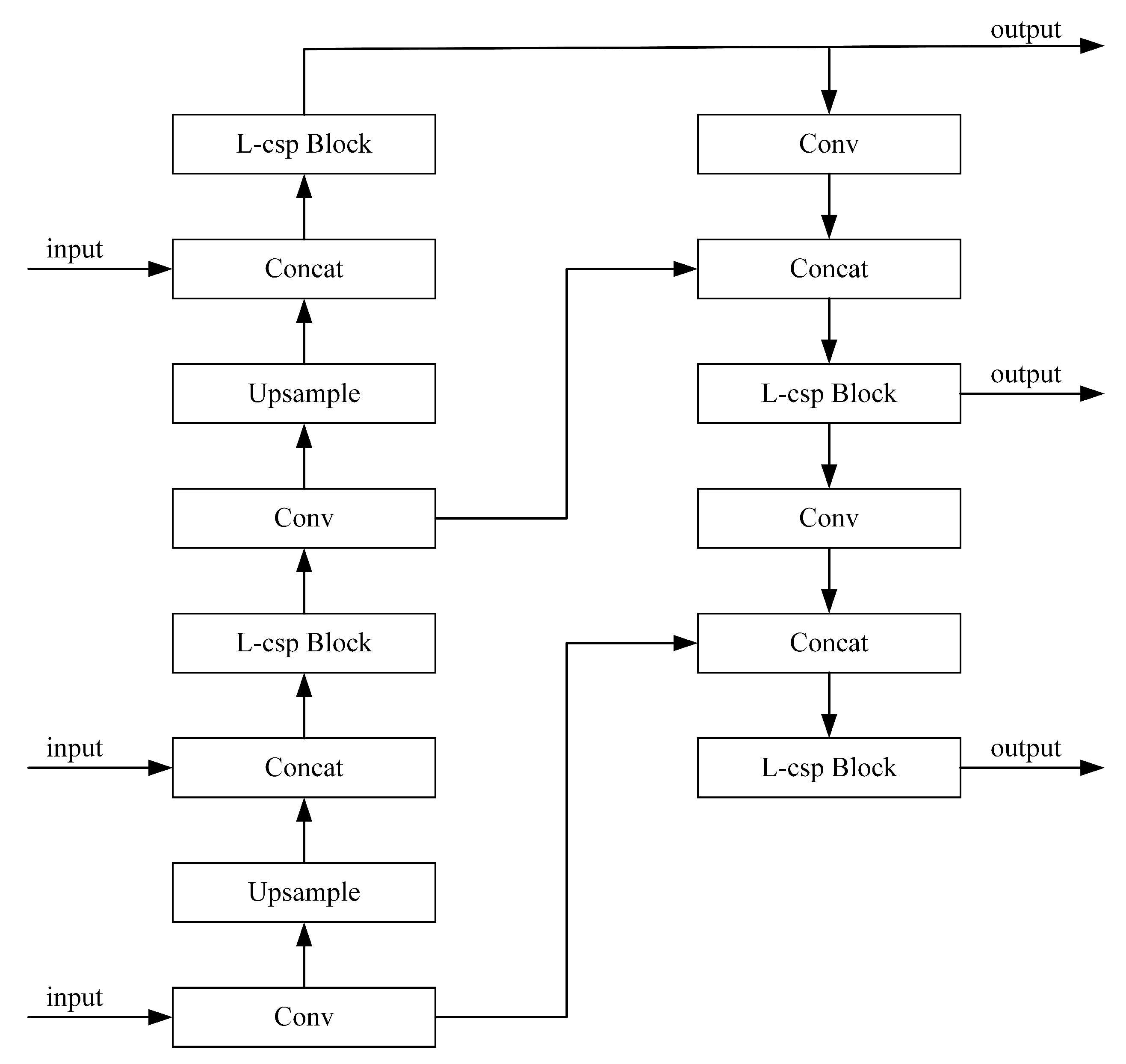
(2) A new fusion network module, the lightweight path aggregation feature pyramid network (L-PAFPN) module, is constructed. This module uses the L-CSP module based on the ghost block design to replace the CSP module in YOLOX PAFPN. By reducing the network’s redundancy, the computational load is reduced, the number of parameters of the method is reduced and the method’s performance for SAR ship detection is improved.
(3) A new feature extraction structure, the Focus module, is introduced. Based on the baseline network, this paper introduces the Focus module to improve the backbone network. It increases the number of feature channels in the feature extraction process, improves the feature extraction capability of the backbone network and enhances the SAR ship detection effect of the method.
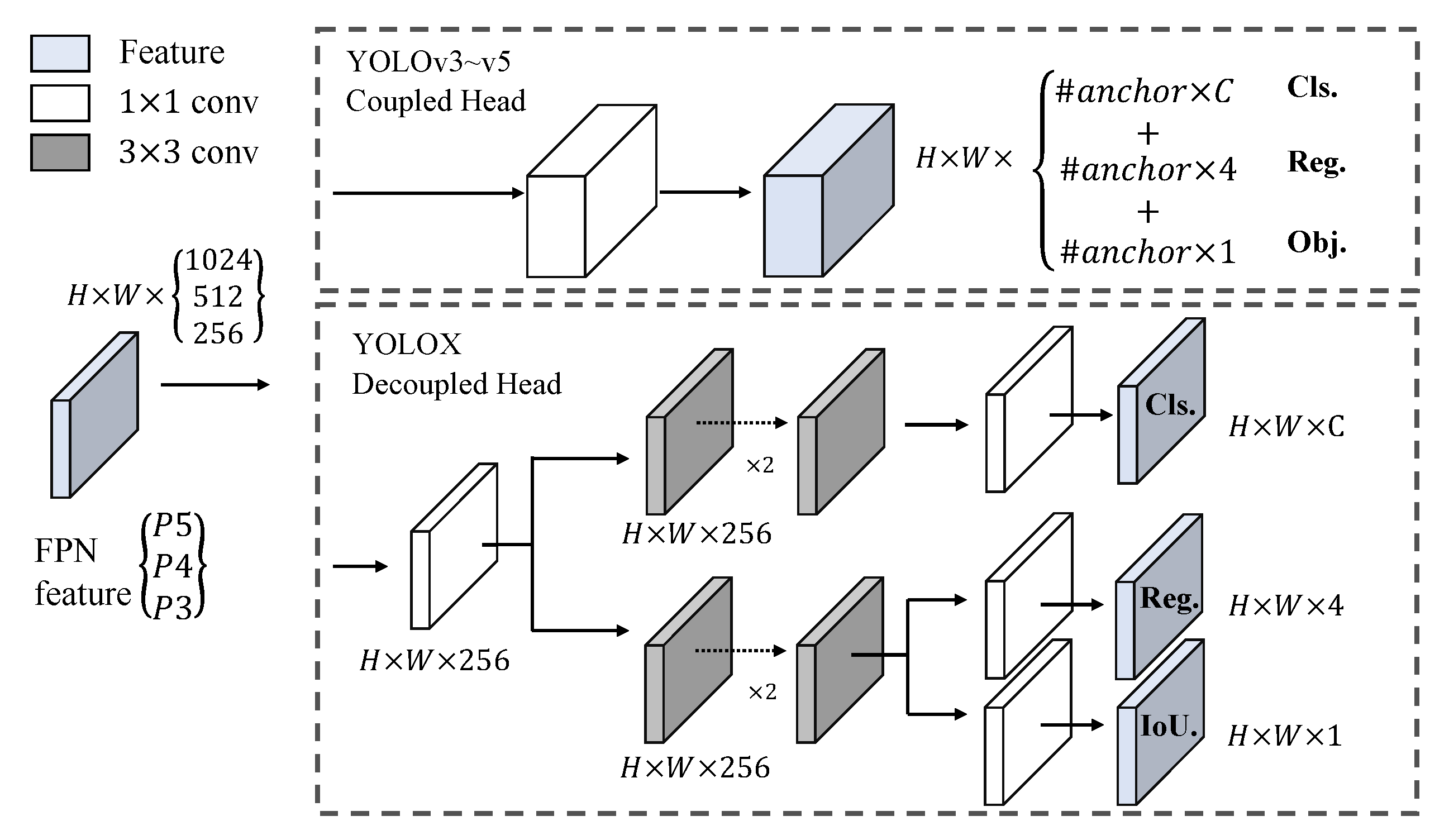
(4) A lightweight SAR ship detector, LssDet, is constructed. Based on the baseline network and the CSAT module, the L-PAFPN module and the Focus module, we proposed LssDet, which achieves competitive performance with low computational complexity and a low number of model parameters. The detector is proposal-free and anchor-free.
The remainder of the paper is organised as follows: In
Section 2, we present LssDet’s baseline network and our proposed architecture. In
Section 3, we present the experiments’ details and results and analyse the experimental results. In
Section 4, we discuss the experimental results and the shortcomings of the experiment. In
Section 5, we draw some conclusions and give an outlook on future research. In addition,
Table A1 offers all the abbreviations and corresponding full terms involved for the convenience of reading.
3. Experiments
This section validates our proposed SAR ship detection method’s performance. Firstly, we introduce the hardware and software environment for the experiments, the dataset used for experiments, the details of the experiments and the experimental evaluation metrics. Next, we introduce the experiments’ results on the SAR Ship Detection Dataset (SSDD) [
44] and the Large-Scale SAR Ship Detection Dataset v1.0 (LS-SSDD-v1.0) [
37] and compare them with the latest detection methods’ results. Finally, we introduce the ablation experiments’ results to verify the validity of each module we proposed.
3.1. Experimental Environment
All experiments used the same environment to run. The environment’s configuration details are shown in
Table 1.
3.2. Dataset
In the experiments, we used two SAR datasets to evaluate our proposed method, the SSDD and the LS-SSDD-v1.0. The SSDD includes 1160 SAR images with 500 × 500 pixels, with various resolutions, from 1 to 15 m. The LS-SSDD-v1.0 includes 15 large-scale images with 24,000 × 16,000 pixels, and the 15 large-scale images were directly cut into 9000 sub-images with 800 × 800 pixels, with various resolutions from 5 m to 20 m.
Table 2 and
Table 3 show the details of the SSDD and the LS-SSDD-v1.0.
To eliminate the impact of a different dataset division on the experimental results, we used the same dataset division as the dataset publisher. Specifically, the SSDD’s training subset contains 928 images, and the test subset contains 232 images. The LS-SSDD-v1.0’s training subset contains 6000 images, and the test subset contains 3000 images.
3.3. Experimental Setup
All experiments used stochastic gradient descent (SGD) with the learning rate lr = 0.01, momentum m = 0.937 and weight decay = 0.0005 as the optimisation algorithm. Furthermore, the batch size was 16; and the input size was
in the SSDD and
in the LS-SSDD-v1.0. All experiments were constructed based on the MMdetection [
45], and the unmentioned parameters were the default parameters of MMdetection.
3.4. Evaluation Criteria
All experiments used
,
,
,
,
and
index in the COCO evaluation [
46], floating-point operations per second (FLOPs) and paraments (Params) to measure the detection performance of the proposed method.
,
,
,
,
and
measure the detection accuracy of the method;
measures the computational complexity of the method; and
measures the parameter size of the method.
where,
TP, FP, TN, and FN are shown in
Table 4.
3.5. Compared with the Latest Detectors in SAR Ship Detection
According to the experimental setup and evaluation criteria, we conducted experiments on the SSDD and LS-SSDD. Furthermore, we compared the SAR ship detection performance of LssDet with that of the latest methods, such as ATSS [
47], AutoAssign [
48], FCOS [
49], YOLO V3 [
32], YOLOX-s [
28] and YOLOX-tiny [
28]. The experiment results on the SSDD are shown in
Table 5, and the experimental results on the LS-SSDD-v1.0 are shown in
Table 6.
The experimental results on the SSDD and the LS-SSDD-v1.0 demonstrate the superiority of the method proposed in this paper. From a quantitative perspective, the of LssDet was the optimal algorithm on the SSDD. Specifically, LssDet had an of 68.1%, which is 3.6%, 4.4%, 5.7%, 6.9%, 0.8% and 5.2% higher than those of ATSS, AutoAssign, FCOS, YOLO V3, YOLOX-s and YOLOX-tiny, respectively. On the LS-SSDD-v1.0, the of LssDet was optimal. Specifically, LssDet had an of 27.8%, which was 3.5%, 7.7%, 4.3%, 5.6%, 0.1% and 1.0% higher than those of ATSS, AutoAssign, FCOS, YOLO V3, YOLOX-s and YOLOX-tiny, respectively. Both and of LssDet were optimal. The of LssDet were 3.57%, 3.63%, 3.65%, 43.72%, 37.23% and 64.88% for ATSS, AutoAssign, FCOS, YOLO V3, YOLOX-s and YOLOX-tiny, respectively. The of LssDet were 7.06%, 6.26%, 7.07%, 61.31%, 38.01% and 67.37% for ATSS, AutoAssign, FCOS, YOLO V3, YOLOX-s and YOLOX-tiny, respectively.
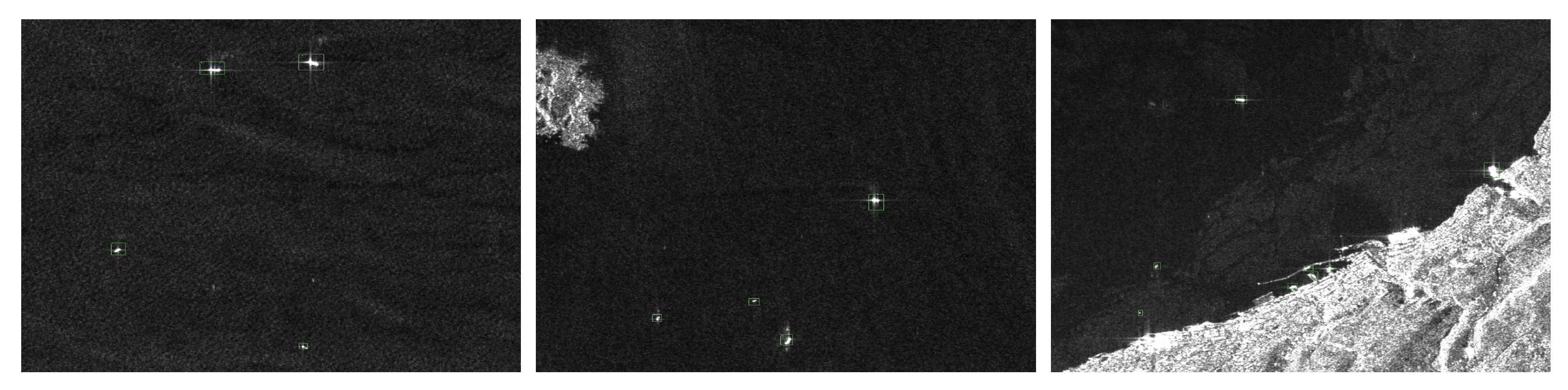
To visualise the detection performance of LssDet,
Figure 9 shows the detection results of LssDet on the SSDD and the LS-SSDD-v1.0. The first and second columns show the label visualisation results and LssDet’s detection results on the SSDD. The third and fourth columns show the label visualisation results and LssDet’s detection results on the LS-SSDD-v1.0.
3.6. Ablation Experiments
To validate the effectiveness of LssDet, we designed two sets of ablation experiments on the SSDD and the LS-SSDD, each containing six sub-experiments.
The first experiment used Shufflenet v2, YOLOX PAFPN and YOLOX Decopuled Head as the baseline networks for comparison in subsequent experiments. The second experiment used the CSAT module inserted into the Shufflenet v2 bottleneck structure primarily to verify the effectiveness of the proposed CSAT module. The third experiment used the L-PAFPN module to replace the YOLOX PAFPN module, mainly to verify the performance of the proposed lightweight feature fusion network. In the fourth experiment, we used the Focus module to replace the first layer of convolution in Shufflenet v2, mainly to verify the effect of feature extraction on the network’s performance. The fifth experiment was a superimposition of the second and third experiments, primarily to verify the effectiveness of the CSAT and L-PAFPN module superimpositions. The sixth experiment was a superposition of the second, third and fourth experiments, mainly to verify the effectiveness of the CSAT, L-PAFPN and Focus module superpositions. The six experiments were carried out step by step to validate our proposed method’s effectiveness and superiority. The datasets and parameter settings were kept constant in all experiments.
The results of the two sets of ablation experiments are shown in
Table 7 and
Table 8.
Table 7 shows the results of the ablation experiments on the SSDD, and
Table 8 shows the results of the ablation experiments on the LS-SSDD-v1.0. In Experiment 2, the CSAT module was used to assign attention weights and simulate the long-range dependence of channel and spatial information on the cross sidelobe region of the SAR ship, thereby obtaining a 1.7%
boost on the SSDD and a
boost of 0.5% on the LS-SSDD-v1.0. In Experiment 3, L-PAFPN was used to reduce the computational load and parametric counts of YOLOX PAFPN, thereby obtaining a 1.8%
boost on the SSDD and a
boost on the LS-SSDD-v1.0 by 0.3%. Meanwhile,
were reduced by 13.9% and
was reduced by 24.9%. In Experiment 4, the Focus module was used to improve the backbone network’s feature extraction, thereby obtaining a 1.4%
improvement on the SSDD and a
improvement of 0.4% on the LS-SSDD-v1.0. In Experiment 5, the introduction of both the CSAT module and the L-PAFPN module resulted in a 2.6%
boost on the SSDD and a
boost of 0.8% on the LS-SSDD-v1.0. In Experiment 6, the CSAT module, the L-PAFPN module and the Focus module were introduced simultaneously, resulting in an
boost of 3.6% on the SSDD and a 1.5%
boost on the LS-SSDD-v1.0. Compared to the baseline,
were reduced by 7.1% and
were reduced by 23.2%. The quantitative analysis of the performance evaluation metrics confirmed the superiority of our proposed SAR ship detection method and the effectiveness of the individual modules.
4. Discussion
Experimental results on the SSDD and the LS-SSDD-v1.0 demonstrated the superiority of the method proposed in this paper. Based on Shufflenet v2, YOLOX PAFPN and YOLOX Decopuled Head, we proposed the CSAT module and the L-PAFPN module and introduced the Focus module. The CSAT module improves the SAR ship detection performance by assigning attention weights to SAR ship cross sidelobe regions and models the long-range dependence of the channel and spatial information. The L-PAFPN module improves the SAR ship detection performance by lightening the YOLOX PAFPN module. The Focus module improves the SAR ship detection performance by enhancing the feature extraction capability of the backbone network. We demonstrated the effectiveness of each module through ablation experiments. The SSDD’s imaging results were better with fewer cross sidelobe phenomena. However, the LS-SSDD-v1.0 imaging results were poor with more cross sidelobe phenomena. Therefore, on the SSDD, the CSAT module improved performance mainly by modelling the long-range dependence of channel and spatial information. On the LS-SSDD-v1.0, the CSAT module obtained performance gains by assigning attention weights and modelling the long-range dependence of channel and spatial information. Thus, the L-PAFPN module most significantly improved performance on the SSDD, and the CSAT module most significantly improved performance on the LS-SSDD-v1.0.
However, the CSAT module is based on Shufflenet v2, and the effectiveness of applying it to other backbone networks needs further study. LssDet achieved excellent performance gains on both and , but the performance gain on was not as good as the former. The research in this paper was mainly concerned with backbone and feature fusion networks, and other parts of the detection method, such as prediction networks, were not further investigated. As the existing datasets only include factors such as ships, ports and land, we did not find other objects with cross sidelobes identified as ships on the existing dataset. Misidentification may occur if future datasets include more samples with cross sidelobe phenomena.
5. Conclusions
In this paper, we proposed a lightweight, anchor-free detector, LssDet, for SAR ship detection tasks. We used Shufflenet v2, YOLOX PAFPN and YOLOX Decopuled Head as the baseline models. Moreover, we proposed the CSAT module and the L-PAFPN module, and introduced the Focus module, to improve the detection performance. Among them, the CSAT module was responsible for cross sidelobe region feature enhancement and modelling the long-range dependence of channel and spatial information. The L-PAFPN module is responsible for lightly modifying the feature fusion network. The Focus module is responsible for enhancing the feature extraction capability. Experimental results on the SSDD showed that LssDet achieves an of 68.1%, a of 2.60 G and a of 2.25 M. Experimental results on the LS-SSDD-v1.0 showed that LssDet achieved an of 27.8%, a of 4.49 G and of 2.25 M. LssDet had superior detection performance from both quantitative and qualitative perspectives. Comparison with other recent detection methods showed that LssDet achieved optimal detection results with minimal computational effort and minimal parameters. Further, the results of ablation experiments demonstrated the effectiveness of each module of LssDet.
In the future, we will further investigate the effectiveness of CSAT on different backbone networks, find methods for improving the performance gains of LssDet on and investigate improvements to other structures in the detection method to achieve better detection results in SAR ship detection tasks.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








