
Superpixel-Based Attention Graph Neural Network for Semantic Segmentation in Aerial Images



Abstract
:
1. Introduction
- In the case of images with high resolution, the scale of the foreground object varies greatly (the car in Figure 1a and the building in (b) are both foreground objects, but the scale difference is great).
- The edge of some foreground object is irregular (the tree edge is irregular in Figure 1c,d).
- The background is highly complex and contains a wide variety of features.
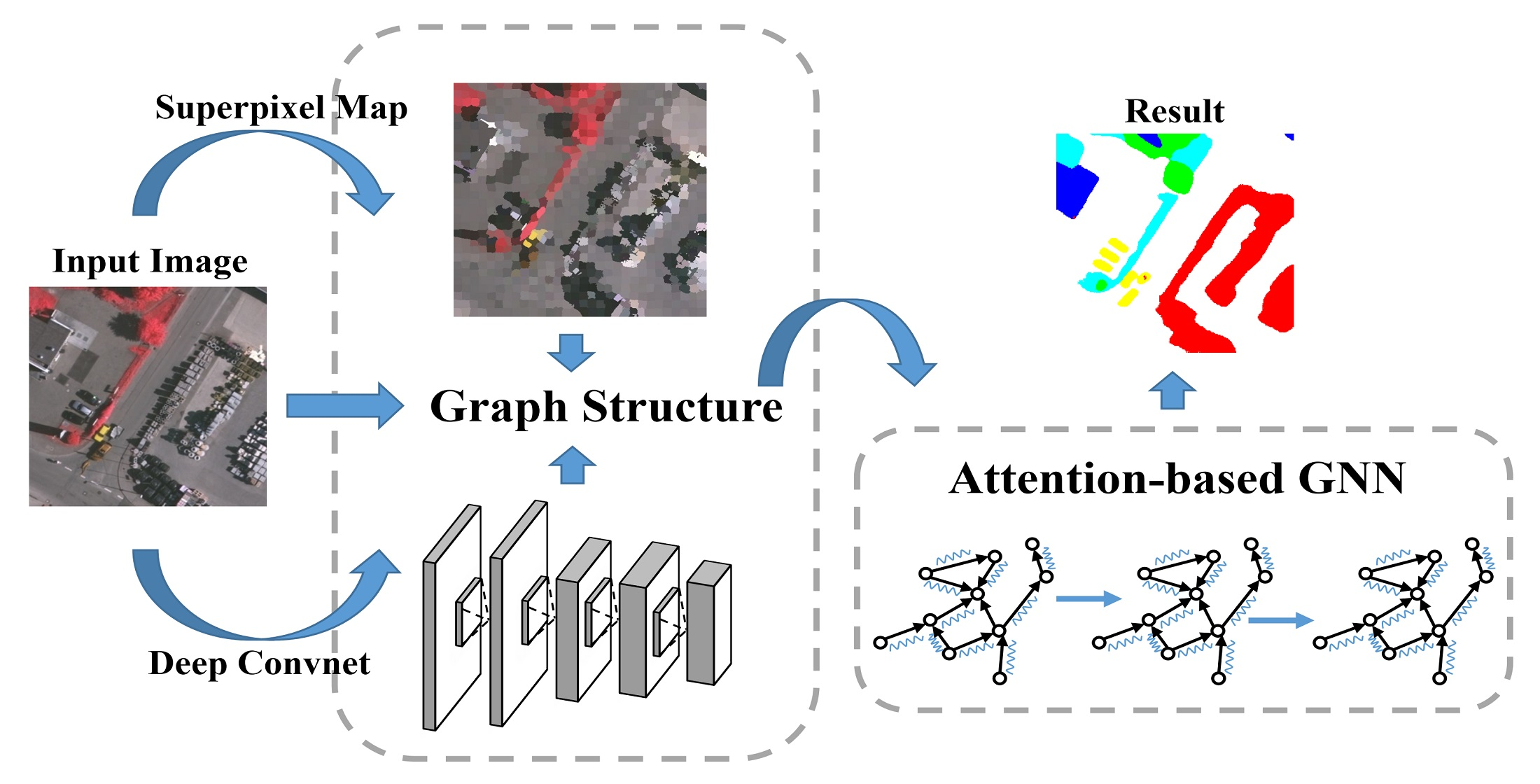
- A GNN-based framework has been proposed for semantic segmentation of aerial images. To get a satisfactory segmentation boundary, superpixels are used as graph nodes for classification, and GNN can learn its representation directly from superpixel graphs. To solve the problem of irregular object edges in aerial images, superpixels are used as graph nodes to construct the graph structure, and GNN can directly learn its representation from the superpixel graph. To overcome the limitations of GNN in extracting features, CNN is used as a feature extractor to provide good feature vectors for the subsequent learning of GNN. Our method takes the complementary advantages of two neural networks (image features extracted by CNN and spatial relations provided by GNN) based on superpixels to achieve satisfactory segmentation results.
- The GNN model in our framework of semantic segmentation of aerial images is an improved version that has introduced the attention mechanism into each node. When the information of neighbor nodes is fused, nodes are aggregated differently depending on their similarity to neighbors, so that the GNN’s expression ability is enhanced. For the challenge of large variation in aerial image scales, we increase the receptive field by increasing the number of neighbors of the graph node when constructing the graph and adding an attention mechanism when merging neighbors’ information. These designs can effectively reduce information fluctuations caused by scale changes, and thus deal with the problem of scale changes. Experimental results show that it has advanced performance on the challenging public datasets of Vaihingen and Potsdam.
2. Related Work
2.1. Semantic Segmentation
2.2. Graph Neural Network
3. Methodology
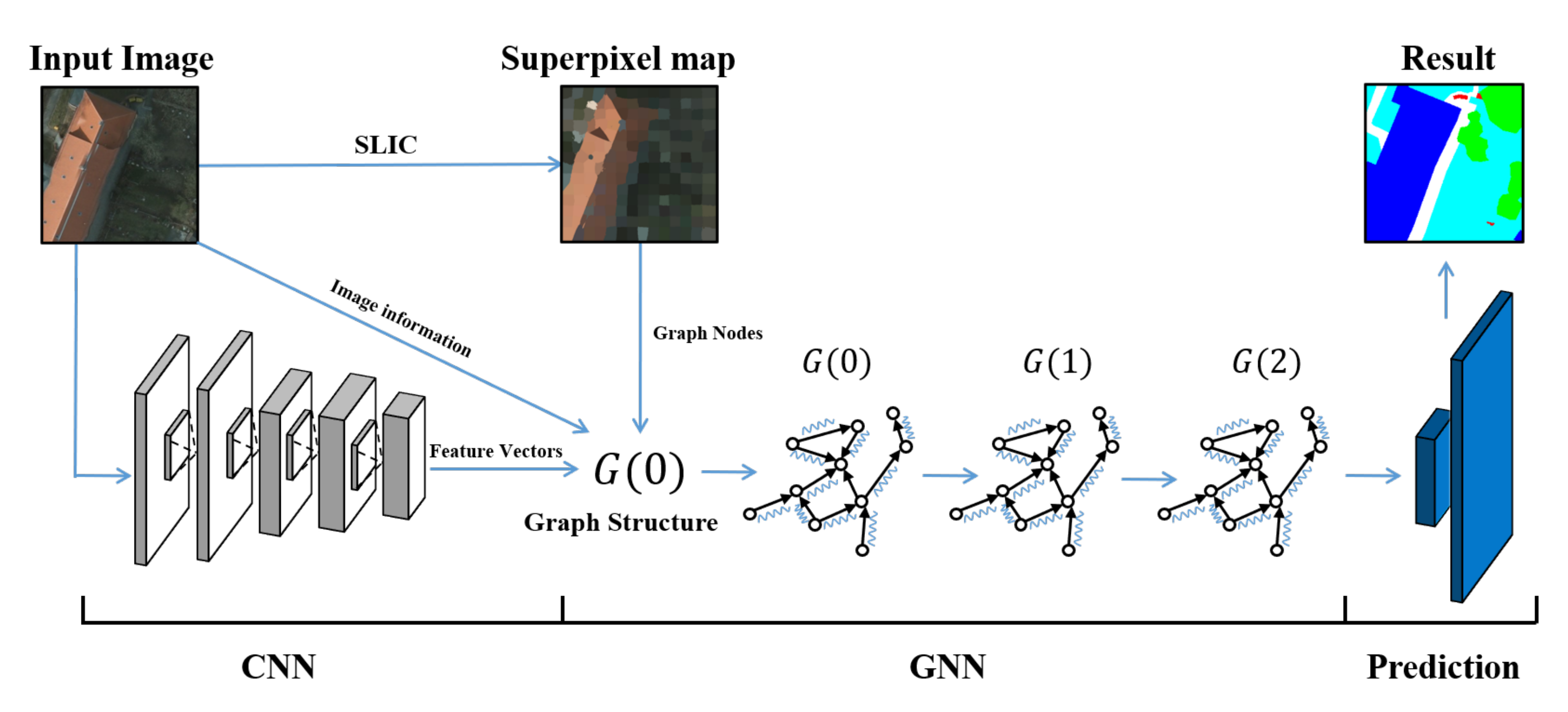
3.1. Overview of the Graph Structure
3.2. Graph Construction
3.2.1. Nodes Determination
3.2.2. Node Features and Labels
3.2.3. Edges Determination
| Algorithm 1. Graph Construction. |
| Input: RGB image |
| Output: Graph |
| 1: compute superpixel map by SLIC method using RGB image |
| 2: each superpixel node is regarded as a graph node |
| 3: graph node → V |
| 4: compute feature map by CNN |
| 5: for each graph node do |
| 6: compute |
| 7: obtain from superpixel center coordinates |
| 8: compute S |
| 9: , |
| 10: obtain node label in feature map |
| 11: end for |
| 12: for every two nodes i and j do |
| 13: compute Euclidean distance between node i and j |
| 14: end for |
| 15: for every node i do |
| 16: find its K nearest neighbors |
| 17: node i establishes a edge with those K nearest neighbors |
| 18: end for |
3.3. Superpixel-Based Attention Graph Neural Network
4. Experimental Results
4.1. Datasets
4.1.1. Potsdam
4.1.2. Vaihingen
4.2. Evaluation Metrics
4.3. Implementation Details
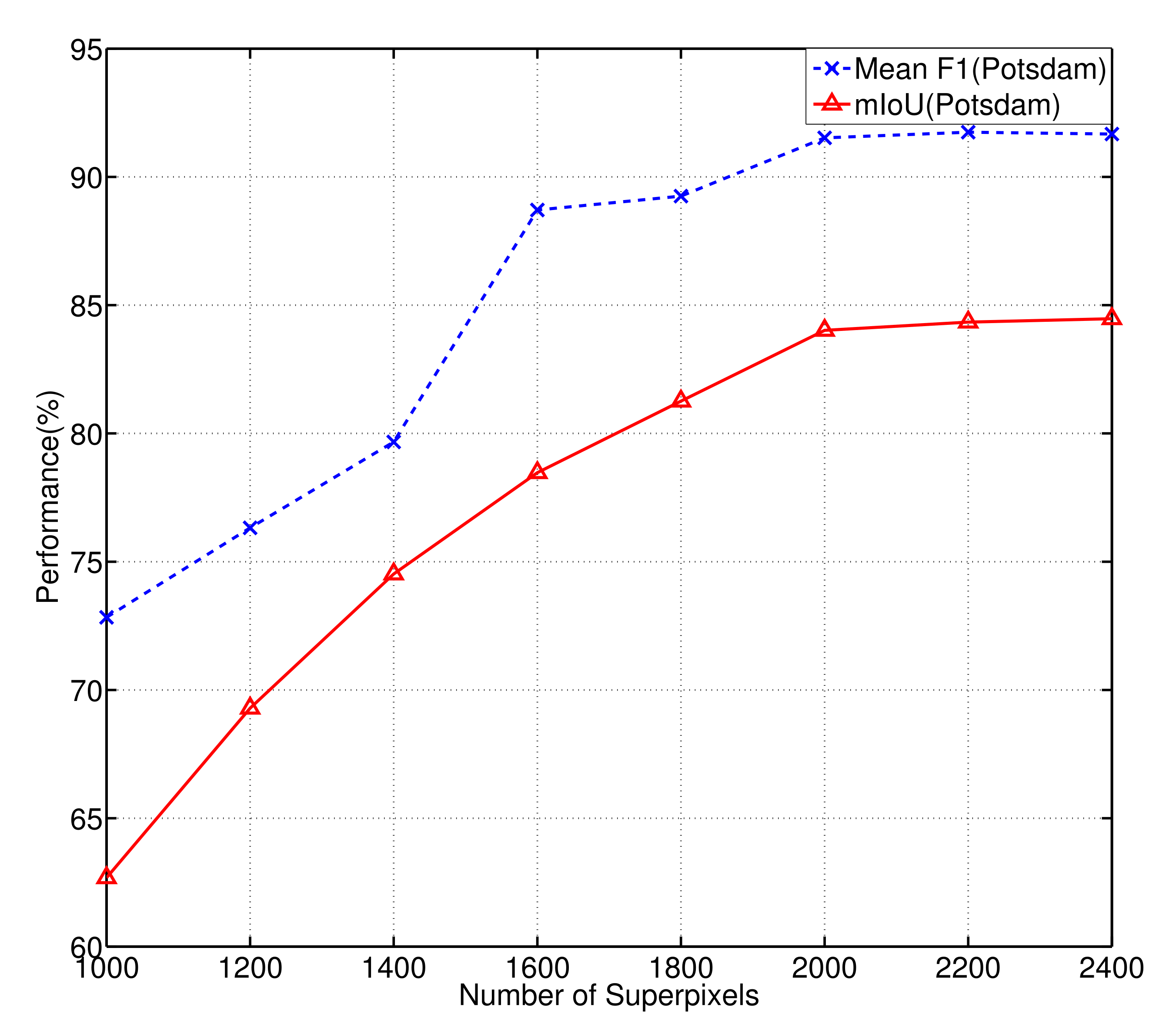
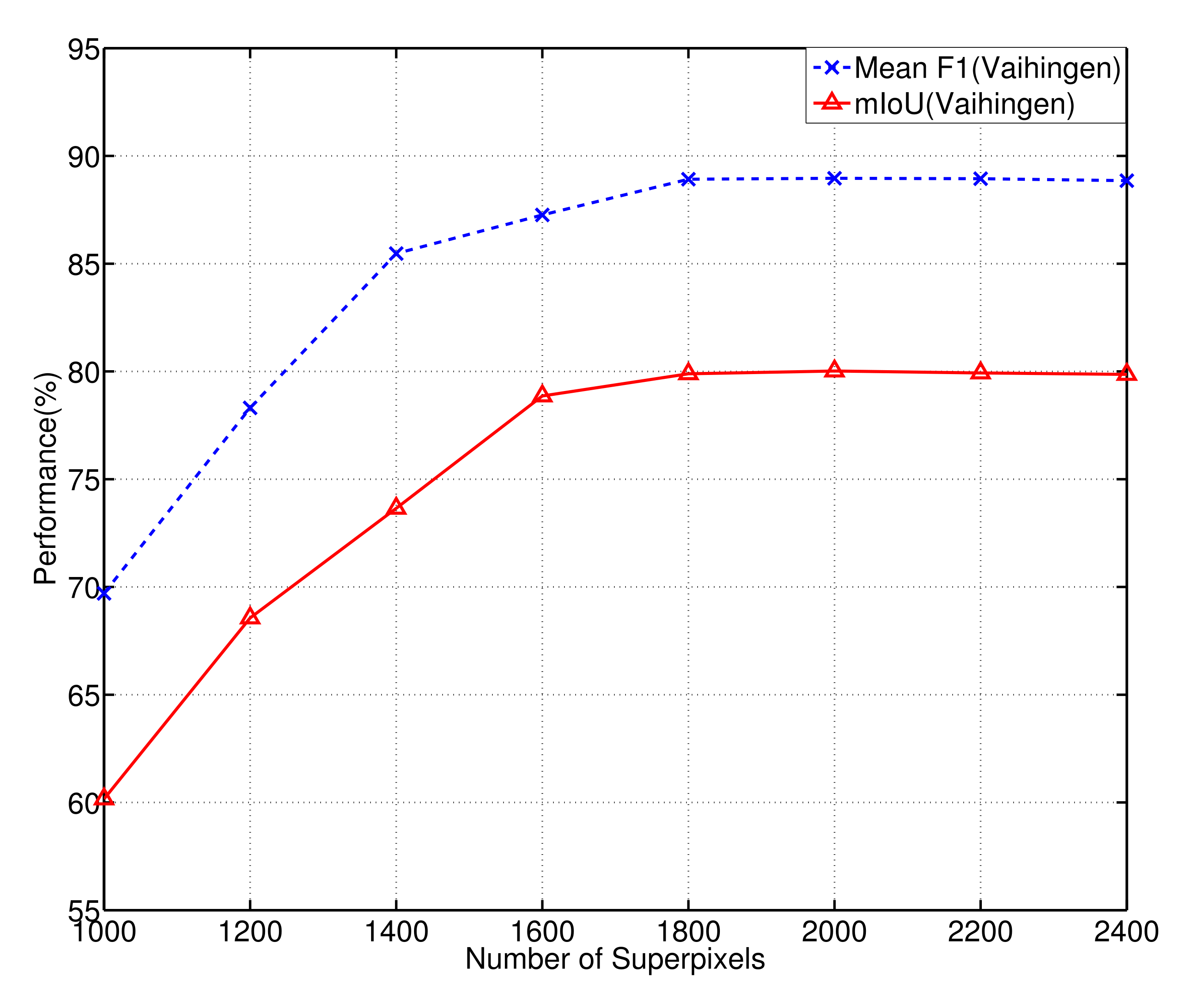
4.4. Superpixel Number
4.5. Comparison with Existing Works
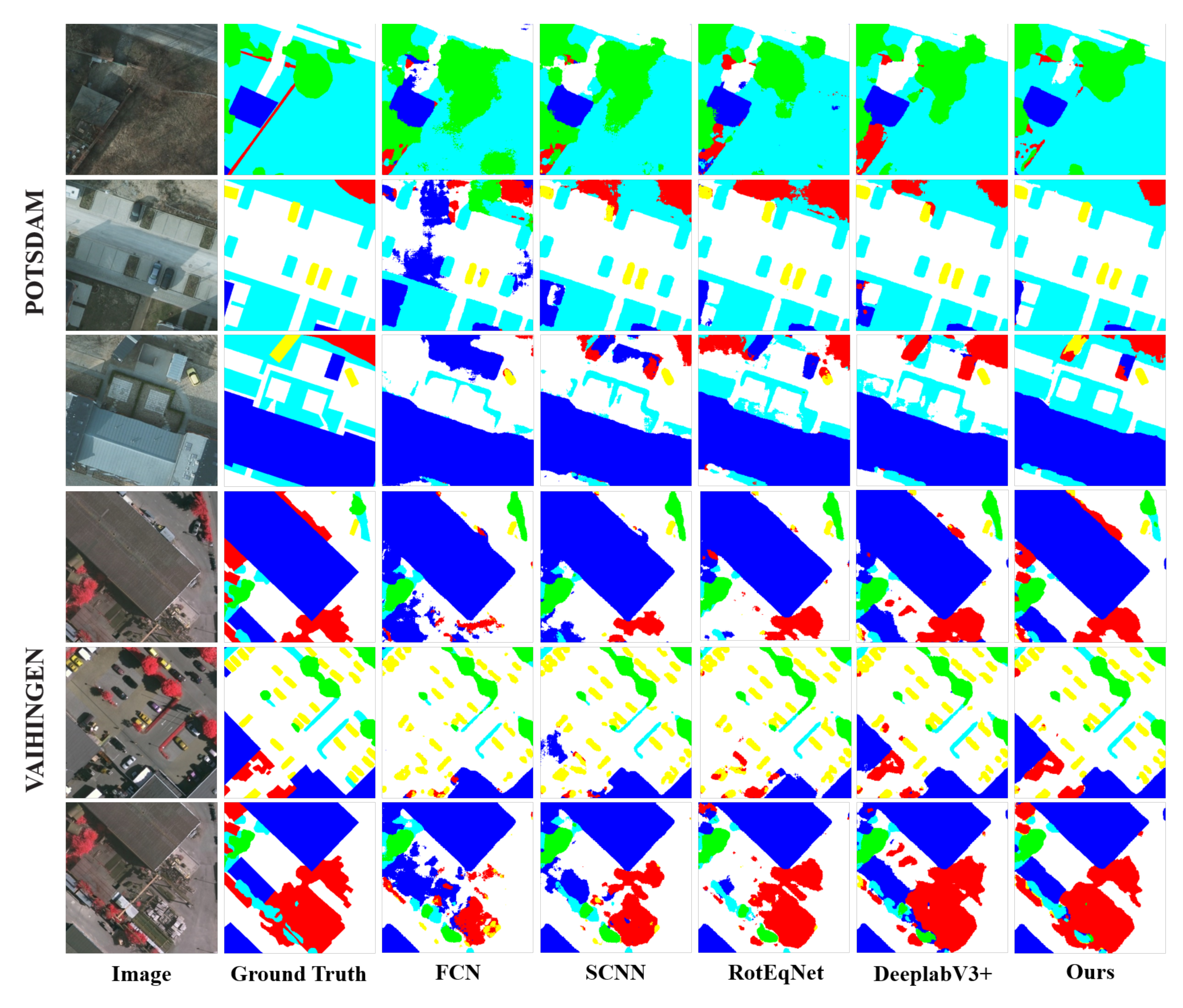
4.6. Qualitative Comparison
5. Discussions
5.1. Ablation Study
5.2. Extensive Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-resolution aerial image labeling with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef] [Green Version]
- Ratajczak, R.; Crispim-Junior, C.F.; Faure, É.; Fervers, B.; Tougne, L. Automatic land cover reconstruction from historical aerial images: An evaluation of features extraction and classification algorithms. IEEE Trans. Image Process. 2019, 28, 3357–3371. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Seto, K.C. Mapping urbanization dynamics at regional and global scales using multi-temporal DMSP/OLS nighttime light data. Remote Sens. Environ. 2011, 115, 2320–2329. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, W.; Li, C.; Wu, J.; Tang, X.; Jiao, L. Fully convolutional network-based ensemble method for road extraction from aerial images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1777–1781. [Google Scholar] [CrossRef]
- Rau, J.Y.; Jhan, J.P.; Hsu, Y.C. Analysis of oblique aerial images for land cover and point cloud classification in an urban environment. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1304–1319. [Google Scholar] [CrossRef]
- Levner, I.; Zhang, H. Classification-driven watershed segmentation. IEEE Trans. Image Process. 2007, 16, 1437–1445. [Google Scholar] [CrossRef] [PubMed]
- Gedeon, T.; Parker, A.E.; Campion, C.; Aldworth, Z. Annealing and the normalized N-cut. Pattern Recognit. 2008, 41, 592–606. [Google Scholar] [CrossRef] [Green Version]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Yu, W.; Zheng, C.; Cheng, W.; Aggarwal, C.C.; Song, D.; Zong, B.; Chen, H.; Wang, W. Learning deep network representations with adversarially regularized autoencoders. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2663–2671. [Google Scholar]
- Liang, X.; Shen, X.; Feng, J.; Lin, L.; Yan, S. Semantic object parsing with graph lstm. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 125–143. [Google Scholar]
- Liang, X.; Lin, L.; Shen, X.; Feng, J.; Yan, S.; Xing, E.P. Interpretable structure-evolving lstm. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1010–1019. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1209–1218. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. isaid: A large-scale dataset for instance segmentation in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 28–37. [Google Scholar]
- Volpi, M.; Tuia, D. Deep multi-task learning for a geographically-regularized semantic segmentation of aerial images. ISPRS J. Photogramm. Remote Sens. 2018, 144, 48–60. [Google Scholar] [CrossRef] [Green Version]
- Luo, H.; Chen, C.; Fang, L.; Zhu, X.; Lu, L. High-Resolution Aerial Images Semantic Segmentation Using Deep Fully Convolutional Network With Channel Attention Mechanism. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3492–3507. [Google Scholar] [CrossRef]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid multiple attention network for semantic segmentation in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603018. [Google Scholar] [CrossRef]
- Li, X.; He, H.; Li, X.; Li, D.; Cheng, G.; Shi, J.; Weng, L.; Tong, Y.; Lin, Z. PointFlow: Flowing semantics through points for aerial image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4217–4226. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Dai, H.; Kozareva, Z.; Dai, B.; Smola, A.; Song, L. Learning steady-states of iterative algorithms over graphs. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1106–1114. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Lee, J.B.; Rossi, R.; Kong, X. Graph classification using structural attention. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1666–1674. [Google Scholar]
- Thekumparampil, K.K.; Wang, C.; Oh, S.; Li, L.J. Attention-based graph neural network for semi-supervised learning. arXiv 2018, arXiv:1803.03735. [Google Scholar]
- Tu, K.; Cui, P.; Wang, X.; Yu, P.S.; Zhu, W. Deep recursive network embedding with regular equivalence. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2357–2366. [Google Scholar]
- Bojchevski, A.; Shchur, O.; Zügner, D.; Günnemann, S. Netgan: Generating graphs via random walks. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 610–619. [Google Scholar]
- You, J.; Ying, R.; Ren, X.; Hamilton, W.; Leskovec, J. Graphrnn: Generating realistic graphs with deep auto-regressive models. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5708–5717. [Google Scholar]
- Min, S.; Gao, Z.; Peng, J.; Wang, L.; Qin, K.; Fang, B. STGSN—A Spatial–Temporal Graph Neural Network framework for time-evolving social networks. Knowl. Based Syst. 2021, 214, 106746. [Google Scholar] [CrossRef]
- Tao, Y.; Wang, C.; Yao, L.; Li, W.; Yu, Y. Item trend learning for sequential recommendation system using gated graph neural network. Neural Comput. Appl. 2021, 1–16. [Google Scholar] [CrossRef]
- Zhao, C.; Liu, S.; Huang, F.; Liu, S.; Zhang, W. CSGNN: Contrastive self-supervised graph neural network for molecular interaction prediction. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Online, 19–27 August 2021; pp. 3756–3763. [Google Scholar]
- Youn, C.H.; Linh, V.L. Dynamic graph neural network for super-pixel image classification. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 20–22 October 2021; pp. 1095–1099. [Google Scholar]
- Avelar, P.H.; Tavares, A.R.; da Silveira, T.L.; Jung, C.R.; Lamb, L.C. Superpixel image classification with graph attention networks. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; pp. 203–209. [Google Scholar]
- Long, J.; Yan, Z.; Chen, H. A Graph Neural Network for Superpixel Image Classification. J. Phys. Conf. Ser. 2021, 1871, 012071. [Google Scholar] [CrossRef]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3d graph neural networks for rgbd semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5199–5208. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D. ISPRS Semantic Labeling Contest; ISPRS: Leopoldshöhe, Germany, 2014. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Hu, X.; Zhao, L.; Lv, Y.; Luo, M.; Pang, S. Learning dual multi-scale manifold ranking for semantic segmentation of high-resolution images. Remote Sens. 2017, 9, 500. [Google Scholar] [CrossRef] [Green Version]
- Atik, S.O.; Ipbuker, C. Integrating Convolutional Neural Network and Multiresolution Segmentation for Land Cover and Land Use Mapping Using Satellite Imagery. Appl. Sci. 2021, 11, 5551. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mehtod | Imp. surf. | Building | Low veg. | Tree | Car | Mean F1 | OA (%) | MIoU (%) |
|---|---|---|---|---|---|---|---|---|
| FCN [9] | 86.81 | 92.32 | 82.69 | 79.25 | 92.18 | 86.65 | 84.67 | 77.13 |
| SCNN [54] | 89.66 | 92.75 | 84.23 | 85.67 | 93.86 | 89.23 | 85.96 | 81.83 |
| RotEqNet [55] | 90.32 | 93.80 | 86.94 | 84.53 | 94.10 | 89.94 | 87.25 | 82.04 |
| DeeplabV3+ [19] | 92.05 | 94.83 | 87.79 | 86.10 | 95.94 | 91.34 | 89.88 | 83.82 |
| SAGNN (ours) | 92.59 | 95.96 | 87.86 | 87.78 | 96.18 | 92.01 | 90.23 | 84.64 |
| Mehtod | Imp. surf. | Building | Low veg. | Tree | Car | Mean F1 | OA (%) | MIoU (%) |
|---|---|---|---|---|---|---|---|---|
| FCN [9] | 87.26 | 90.15 | 75.38 | 86.14 | 70.51 | 81.89 | 84.57 | 71.03 |
| SCNN [54] | 88.51 | 91.26 | 77.65 | 87.04 | 79.80 | 84.85 | 86.52 | 74.91 |
| RotEqNet [55] | 89.75 | 93.63 | 78.60 | 82.92 | 77.36 | 85.25 | 87.68 | 76.30 |
| DeeplabV3+ [19] | 91.64 | 94.21 | 83.11 | 87.58 | 86.19 | 88.55 | 88.94 | 79.85 |
| SAGNN (ours) | 92.01 | 95.13 | 83.09 | 88.36 | 87.25 | 89.16 | 89.32 | 80.11 |
| Mehtod | Superpixel | Attention | CNN | OA (%) | MIoU (%) |
|---|---|---|---|---|---|
| ✓ | 84.01 | 76.95 | |||
| ✓ | 82.43 | 75.16 | |||
| ✓ | 84.57 | 77.02 | |||
| SAGNN | ✓ | ✓ | 86.32 | 81.95 | |
| ✓ | ✓ | 89.54 | 83.97 | ||
| ✓ | ✓ | 87.68 | 82.19 | ||
| ✓ | ✓ | ✓ | 90.23 | 84.64 |
| Mehtod | Superpixel | Attention | CNN | OA (%) | MIoU (%) |
|---|---|---|---|---|---|
| ✓ | 83.82 | 70.78 | |||
| ✓ | 82.21 | 70.29 | |||
| ✓ | 84.13 | 71.98 | |||
| SAGNN | ✓ | ✓ | 86.45 | 74.88 | |
| ✓ | ✓ | 88.17 | 78.70 | ||
| ✓ | ✓ | 87.39 | 76.16 | ||
| ✓ | ✓ | ✓ | 89.32 | 80.11 |
| Mehtod | Superpixel | Attention | CNN | PRM (M) | IT (ms) | FLOPs (Giga) |
|---|---|---|---|---|---|---|
| ✓ | 7.03 | 12.96 | 8.65 | |||
| ✓ | 9.20 | 15.19 | 16.78 | |||
| ✓ | 10.56 | 16.28 | 17.80 | |||
| SAGNN | ✓ | ✓ | 7.86 | 14.10 | 10.24 | |
| ✓ | ✓ | 8.02 | 14.24 | 13.78 | ||
| ✓ | ✓ | 11.21 | 16.76 | 18.13 | ||
| ✓ | ✓ | ✓ | 8.96 | 15.07 | 14.51 |
| Method | Dataset | Original Size | No. | Class | Patch Size |
|---|---|---|---|---|---|
| Multi-task learning [26] | Zeebrugges | 10K × 10K | 7 | 8 | 500 × 500 |
| DMSMR [56] | EvLab-SS | 4500 × 4500 | 60 | 11 | 321 × 321 |
| CNN–MRS [57] | Zurich Summer | 1100 × 1100 | 20 | 8 | 128 × 128 |
| SAGNN | Potsdam | 6000 × 6000 | 38 | 6 | 600 × 600 |
| SAGNN | Vaihingen | 2494 × 2064 | 33 | 6 | 512 × 512 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diao, Q.; Dai, Y.; Zhang, C.; Wu, Y.; Feng, X.; Pan, F. Superpixel-Based Attention Graph Neural Network for Semantic Segmentation in Aerial Images. Remote Sens. 2022, 14, 305. https://doi.org/10.3390/rs14020305
Diao Q, Dai Y, Zhang C, Wu Y, Feng X, Pan F. Superpixel-Based Attention Graph Neural Network for Semantic Segmentation in Aerial Images. Remote Sensing. 2022; 14(2):305. https://doi.org/10.3390/rs14020305
Chicago/Turabian StyleDiao, Qi, Yaping Dai, Ce Zhang, Yan Wu, Xiaoxue Feng, and Feng Pan. 2022. "Superpixel-Based Attention Graph Neural Network for Semantic Segmentation in Aerial Images" Remote Sensing 14, no. 2: 305. https://doi.org/10.3390/rs14020305