
A Comparison of Various Correction and Blending Techniques for Creating an Improved Satellite-Gauge Rainfall Dataset over Australia


Abstract
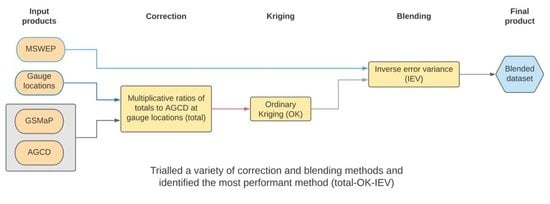
:
1. Introduction
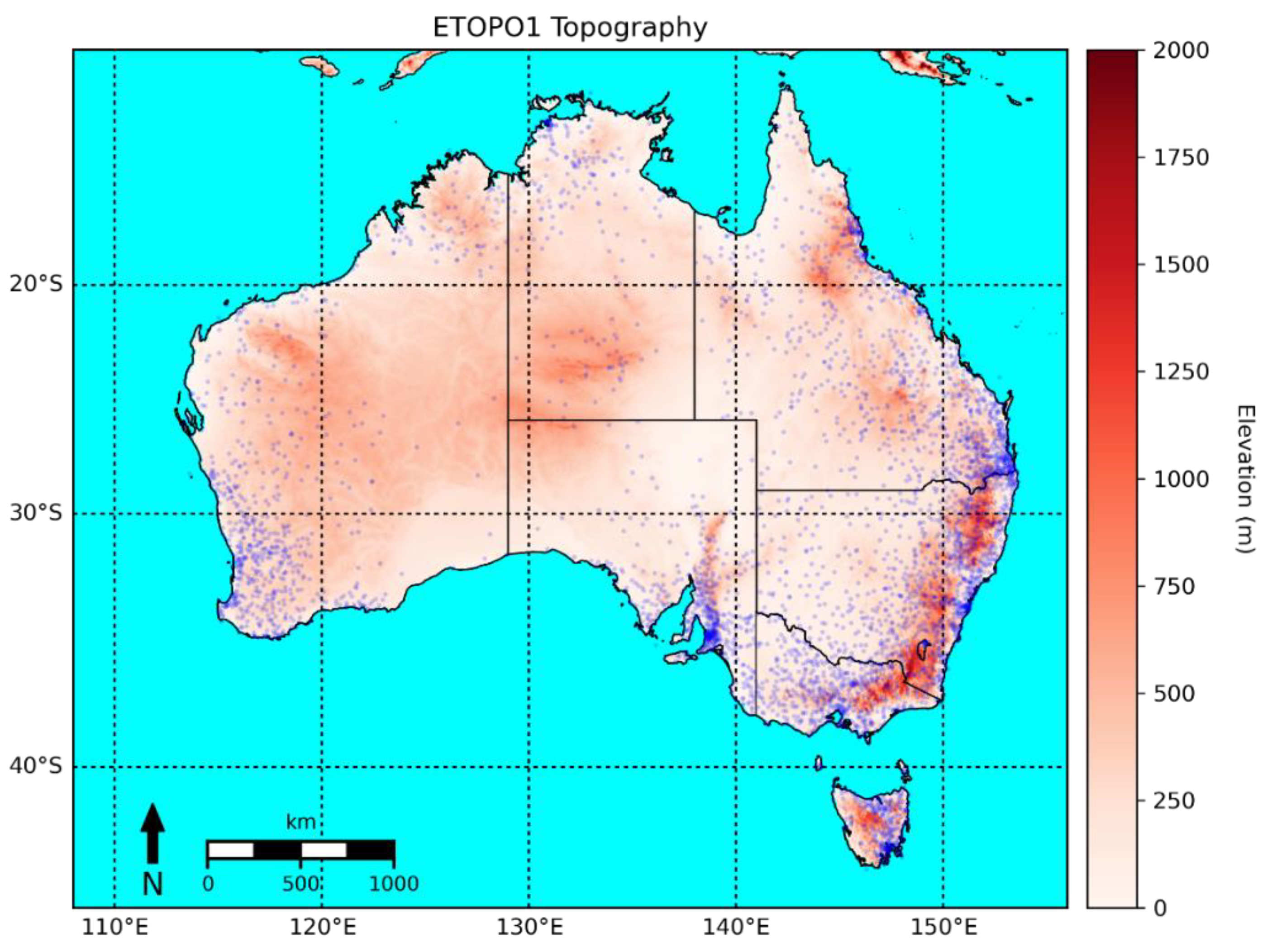
- Several new methods of correction and blending of satellite data to gauge data will be explored. The correction techniques evaluated will be linear correction- to-totals and correction-to-anomalies methods (the former being the original technique), as well as the use of quantile-to-quantile matching. The use of Empirical Bayesian Kriging (EBK) and Empirical Bayesian Kriging Regression Prediction (EBKRP) will also be investigated to find if they offer improvements on Ordinary Kriging (OK). These corrected datasets will be blended with the gauge analysis using the original method of inverse error variance (IEV), in addition to a method that explicitly includes distance and another where the weights come from a triple collocation analysis (TCA);
- The efficacy of datasets built from a combination of all these techniques will be evaluated, along with an analysis of their respective advantages and disadvantages. Performance close to stations will be determined through comparison to station data, while a comparison to MSWEP along with a triple collocation analysis (TCA) will establish performance away from stations.
2. Materials and Methods
2.1. Validation
2.2. Datasets
2.3. Correction and Blending Methods
2.3.1. Linear Correction to Totals
2.3.2. Linear Correction to Anomalies
2.3.3. Quantile to Quantile Matching
2.3.4. Distance-Based Weighting Methods
2.3.5. Kriging Variants
2.3.6. TCA Blend
3. Results
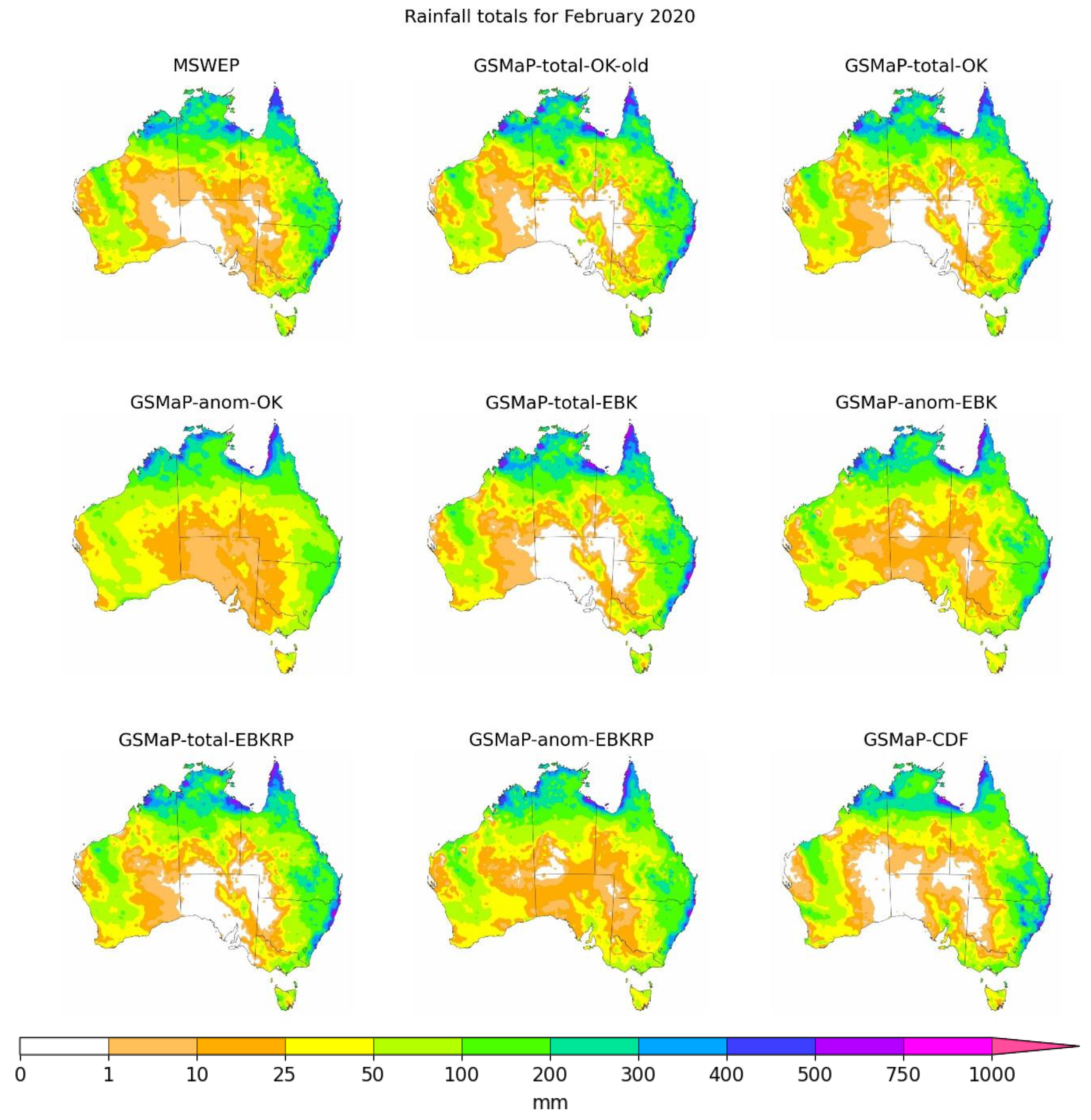
3.1. Corrected Datasets
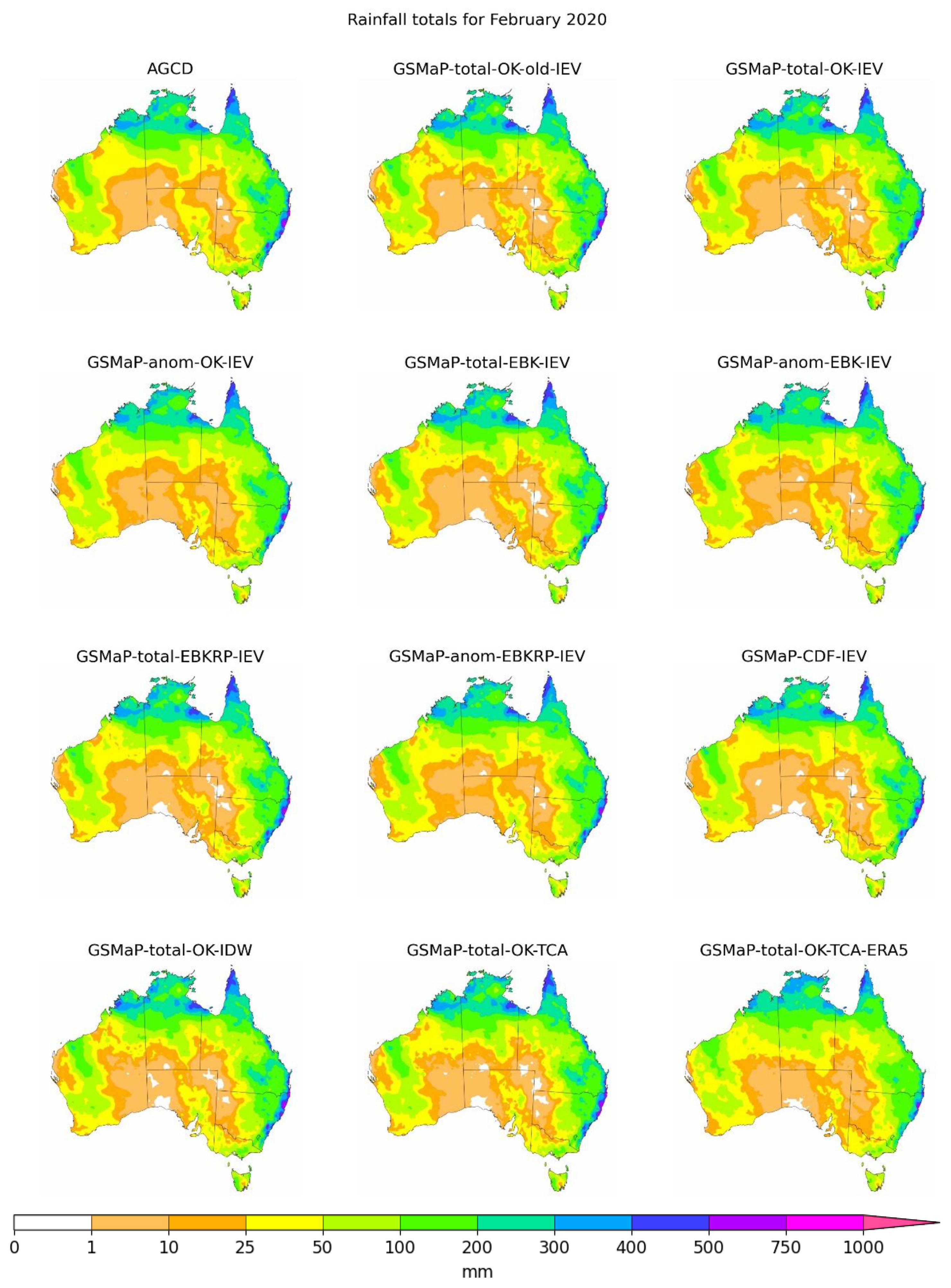
3.2. Blended Datasets
4. Discussion
4.1. Correction Techniques
4.2. Blending Techniques
5. Conclusions
- The most performant correction technique in this study was a linear correction to totals. The choice of kriging technique did not have a strong impact, with EBK slightly outperforming EBKRP and OK;
- The most performant blending technique was an inverse error variance blending technique using a GSMaP dataset linearly corrected to totals. All the blending techniques tested were able to improve the underlying corrected dataset, having a harmonising effect that greatly reduced the differences between the corrected datasets. The improvement was non-linear, resulting in the total-OK-IEV-blended dataset performing the best generally;
- The validation technique used is important, as station-based validation favoured DW-blended datasets while the more general TCA and MSWEP validations favoured the IEV-blended datasets. Triple collocation analysis using satellite data, SM2R, and ERA5 as the triplet yielded results consistent with a traditional comparison to MSWEP, highlighting the versatility of the technique;
- The trade-off between at-station and away-from-station performance was clear. For the correction techniques, the CDF method traded at-station performance for away-from-station performance. For the blending techniques, the DW method traded away-from-station performance for at-station performance. This made them complementary to each other. Likewise, the linear correction methods were complementary to the IEV blending methods.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Stationarity of the data (no autocorrelation).
- 2.
- The datasets can be linearly related to each other.
- 3.
- Orthogonality of errors (their expected sum is zero).
- 4.
- There is no cross-correlation amongst the errors of the datasets, as well as with the truth.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ADF Statistic | p-Value | Ratio of Bias to Mean (%) | R to SM2R | R to ERA5 | R to SM2R (Bias) | R to ERA5 (Bias) |
|---|---|---|---|---|---|---|---|
| SM2R | −11.08 | 0.00 | −7.07 | - | 0.90 | - | 0.18 |
| ERA5 | −7.92 | 0.00 | −5.00 | 0.90 | - | 0.18 | - |
| AGCD | −2.69 | 0.08 | 2.18 | 0.89 | 0.90 | 0.24 | −0.37 |
| GSMaP | −11.86 | 0.00 | −0.67 | 0.83 | 0.85 | 0.12 | 0.32 |
| GSMaP OK-total | −2.27 | 0.18 | 1.39 | 0.88 | 0.90 | 0.17 | 0.36 |
| GSMaP OK-total-IEV | −2.35 | 0.6 | 1.58 | 0.89 | 0.92 | 0.19 | 0.36 |
Appendix B
| Model | Satellite | AGCD | AGCD (100 Years) |
|---|---|---|---|
| Generalised Exponential | 0.25 | 0.17 | 0.17 |
| Generalised Extreme | 0.29 | 0.14 | 0.14 |
| Pearson III | 0.25 | 0.09 | 0.09 |
| Generalised Gamma | 0.25 | 0.08 | 0.08 |
| Inverse Gaussian | 0.28 | 0.10 | 0.10 |
| Inverse Gamma | 0.43 | 0.15 | 0.15 |
| Gamma | 0.29 | 0.08 | 0.08 |
Appendix C
| Station | MSWEP | TCA | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R | Rank | RMSE | R | Rank | σε | R | Rank | Rank (Mean) | |
| GSMaP-total-OK-IEV-old | 0.62 | 0.96 | 9 | 0.57 | 0.94 | 7 | 0.44 | 0.93 | 16 | 10.3 |
| GSMaP-total-OK-IEV | 0.66 | 0.95 | 12 | 0.54 | 0.95 | 2 | 0.40 | 0.94 | 1 | 6.2 |
| GSMaP-anom-OK-IEV | 0.69 | 0.95 | 13 | 0.54 | 0.95 | 1 | 0.40 | 0.94 | 2 | 6.7 |
| GSMaP-total -EBK-IEV | 0.64 | 0.95 | 10 | 0.55 | 0.94 | 3 | 0.42 | 0.94 | 3 | 6.8 |
| GSMaP-anom-EBK-IEV | 0.72 | 0.94 | 18 | 0.57 | 0.94 | 4 | 0.40 | 0.93 | 6 | 10.5 |
| GSMaP-total-EBKRP-IEV | 0.64 | 0.95 | 11 | 0.56 | 0.94 | 5 | 0.41 | 0.94 | 3 | 8.2 |
| GSMaP-anom-EBKRP-IEV | 0.72 | 0.94 | 17 | 0.57 | 0.94 | 8 | 0.40 | 0.93 | 3 | 10.7 |
| GSMaP-CDF-IEV | 0.70 | 0.95 | 15 | 0.61 | 0.93 | 15 | 0.45 | 0.93 | 22 | 16.2 |
| GSMaP-total-OK-DW | 0.60 | 0.96 | 4 | 0.60 | 0.94 | 9 | 0.45 | 0.93 | 9 | 9.3 |
| GSMaP-anom-OK-DW | 0.60 | 0.96 | 8 | 0.58 | 0.94 | 5 | 0.44 | 0.92 | 25 | 11.3 |
| GSMaP-total-EBK-DW | 0.60 | 0.96 | 2 | 0.64 | 0.93 | 16 | 0.46 | 0.93 | 21 | 12.2 |
| GSMaP-anom-EBK-DW | 0.60 | 0.96 | 4 | 0.60 | 0.94 | 10 | 0.45 | 0.92 | 25 | 11.7 |
| GSMaP-total-EBKRP-DW | 0.60 | 0.96 | 3 | 0.66 | 0.92 | 21 | 0.46 | 0.93 | 23 | 14.3 |
| GSMaP-anom-EBKRP-DW | 0.60 | 0.96 | 6 | 0.64 | 0.93 | 17 | 0.46 | 0.92 | 28 | 15.5 |
| GSMaP-CDF-DW | 0.60 | 0.96 | 6 | 0.75 | 0.90 | 22 | 0.57 | 0.91 | 29 | 18.8 |
| GSMaP-total-OK-TC | 0.72 | 0.94 | 18 | 0.60 | 0.94 | 10 | 0.44 | 0.93 | 7 | 13.2 |
| GSMaP-total-anom-TC | 0.77 | 0.93 | 22 | 0.61 | 0.93 | 12 | 0.44 | 0.92 | 18 | 17.2 |
| GSMaP-total-EBK-TC | 0.69 | 0.94 | 14 | 0.62 | 0.93 | 13 | 0.45 | 0.93 | 18 | 15.0 |
| GSMaP-anom-EBK-TC | 0.74 | 0.94 | 20 | 0.62 | 0.93 | 14 | 0.44 | 0.92 | 17 | 16.8 |
| GSMaP-total-EBKRP-TC | 0.70 | 0.94 | 16 | 0.63 | 0.93 | 17 | 0.45 | 0.93 | 20 | 17.0 |
| GSMaP-anom-EBKRP-TC | 0.74 | 0.94 | 21 | 0.64 | 0.92 | 20 | 0.45 | 0.92 | 23 | 20.0 |
| GSMaP-CDF-TC | 0.79 | 0.93 | 23 | 0.75 | 0.90 | 23 | 0.57 | 0.91 | 29 | 24.8 |
| GSMaP-total-OK-TC-ERA5 | 1.28 | 0.76 | 26 | 1.23 | 0.68 | 24 | 0.32 | 0.92 | 8 | 21.0 |
| GSMaP-anom-OK-TC-ERA5 | 1.34 | 0.74 | 30 | 1.27 | 0.66 | 30 | 0.31 | 0.91 | 15 | 25.0 |
| GSMaP-total-EBK-TC-ERA5 | 1.27 | 0.76 | 24 | 1.24 | 0.68 | 25 | 0.32 | 0.92 | 12 | 21.3 |
| GSMaP-anom-EBK-TC-ERA5 | 1.32 | 0.75 | 28 | 1.27 | 0.66 | 29 | 0.31 | 0.91 | 9 | 23.7 |
| GSMaP-total-EBKRP-TC-ERA5 | 1.27 | 0.76 | 24 | 1.24 | 0.67 | 26 | 0.32 | 0.92 | 12 | 21.5 |
| GSMaP-anom-EBKRP-TC-ERA5 | 1.32 | 0.75 | 28 | 1.27 | 0.66 | 28 | 0.32 | 0.91 | 12 | 23.7 |
| GSMaP-CDF-TC-ERA5 | 1.30 | 0.75 | 27 | 1.26 | 0.66 | 27 | 0.41 | 0.89 | 27 | 25.0 |
| AGCD | 0.44 | 0.98 | 1 | 0.62 | 0.92 | 19 | 0.42 | 0.93 | 9 | 11.2 |
References
- Mukabutera, A.; Thomson, D.; Murray, M.; Basinga, P.; Nyirazinyoye, L.; Atwood, S.; Savage, K.P.; Ngirimana, A.; Hedt-Gauthier, B.L. Rainfall variation and child health: Effect of rainfall on diarrhea among under 5 children in Rwanda, 2010. BMC Public Health 2016, 16, 731. [Google Scholar] [CrossRef] [Green Version]
- Bhardwaj, J.; Kuleshov, Y.; Watkins, A.B.; Aitkenhead, I.; Asghari, A. Building capacity for a user-centred Integrated Early Warning System (I-EWS) for drought in the Northern Murray-Darling Basin. Nat. Hazards 2021, 107, 97–122. [Google Scholar] [CrossRef]
- Mishra, A.K.; Özger, M.; Singh, V.P. Association between Uncertainties in Meteorological Variables and Water-Resources Planning for the State of Texas. J. Hydrol. Eng. 2011, 16, 984–999. [Google Scholar] [CrossRef]
- Gebregiorgis, A.S.; Hossain, F. Understanding the dependence of satellite rainfall uncertainty on topography and climate for hydrologic model simulation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 704–718. [Google Scholar] [CrossRef]
- Milly, P.C.D.; Dunne, K.A.; Vecchia, A.V. Global pattern of trends in streamflow and water availability in a changing climate. Nature 2005, 438, 347–350. [Google Scholar] [CrossRef]
- Beck, H.E.; Wood, E.F.; Pan, M.; Fisher, C.K.; Miralles, D.G.; Van Dijk, A.I.J.M.; McVicar, T.R.; Adler, R.F. MSWep v2 Global 3-hourly 0.1° precipitation: Methodology and quantitative assessment. Bull. Am. Meteorol. Soc. 2019, 100, 473–500. [Google Scholar] [CrossRef] [Green Version]
- Michelson, D.B. Systematic correction of precipitation gauge observations using analyzed meteorological variables. J. Hydrol. 2004, 290, 161–177. [Google Scholar] [CrossRef]
- Contractor, S.; Alexander, L.V.; Donat, M.G.; Herold, N. How Well Do Gridded Datasets of Observed Daily Precipitation Compare over Australia? Adv. Meteorol. 2015, 2015, 325718. [Google Scholar] [CrossRef] [Green Version]
- Hofstra, N.; New, M.; McSweeney, C. The influence of interpolation and station network density on the distributions and trends of climate variables in gridded daily data. Clim. Dyn. 2010, 35, 841–858. [Google Scholar] [CrossRef]
- New, M.; Todd, M.; Hulme, M.; Jones, P. Precipitation measurements and trends in the twentieth century. Int. J. Climatol. 2001, 21, 1889–1922. [Google Scholar] [CrossRef]
- Habib, E.; Krajewski, W.F.; Ciach, G.J. Estimation of Rainfall Interstation Correlation. J. Hydrometeorol. 2001, 2, 621–629. [Google Scholar] [CrossRef]
- Kidd, C.; Becker, A.; Huffman, G.J.; Muller, C.L.; Joe, P.; Skofronick-Jackson, G.; Kirschbaum, D.B. So, how much of the Earth’s surface is covered by rain gauges? Bull. Am. Meteorol. Soc. 2017, 98, 69–78. [Google Scholar] [CrossRef]
- Ensor, L.A.; Robeson, S.M. Statistical characteristics of daily precipitation: Comparisons of gridded and point datasets. J. Appl. Meteorol. Climatol. 2008, 47, 2468–2476. [Google Scholar] [CrossRef]
- Xie, P.; Arkin, P.A. Global Precipitation: A 17-Year Monthly Analysis Based on Gauge Observations, Satellite Estimates, and Numerical Model Outputs. Bull. Am. Meteorol. Soc. 1997, 78, 2539–2558. [Google Scholar] [CrossRef]
- Dong, J.; Lei, F.; Wei, L. Triple Collocation Based Multi-Source Precipitation Merging. Front. Water 2020, 2, 1. [Google Scholar] [CrossRef]
- Chua, Z.-W.; Kuleshov, Y.; Watkins, A.; Choy, S.; Sun, C. Developing a blended satellite-gauge rainfall dataset over Australia. J. Hydrometeorol. 2022; under review. [Google Scholar]
- Stoffelen, A. Toward the true near-surface wind speed: Error modeling and calibration using triple collocation. J. Geophys. Res. Ocean 1998, 103, 7755–7766. [Google Scholar] [CrossRef]
- McColl, K.A.; Vogelzang, J.; Konings, A.G.; Entekhabi, D.; Piles, M.; Stoffelen, A. Extended triple collocation: Estimating errors and correlation coefficients with respect to an unknown target. Geophys. Res. Lett. 2014, 41, 6229–6236. [Google Scholar] [CrossRef] [Green Version]
- Roebeling, R.A.; Wolters, E.L.A.; Meirink, J.F.; Leijnse, H. Triple collocation of summer precipitation retrievals from SEVIRI over europe with gridded rain gauge and weather radar data. J. Hydrometeorol. 2012, 13, 1552–1566. [Google Scholar] [CrossRef]
- Alemohammad, S.H.; McColl, K.A.; Konings, A.G.; Entekhabi, D.; Stoffelen, A. Characterization of precipitation product errors across the United States using multiplicative triple collocation. Hydrol. Earth Syst. Sci. 2015, 19, 3489–3503. [Google Scholar] [CrossRef] [Green Version]
- Massari, C.; Crow, W.; Brocca, L. An assessment of the performance of global rainfall estimates without ground-based observations. Hydrol. Earth Syst. Sci. 2017, 21, 4347–4361. [Google Scholar] [CrossRef] [Green Version]
- Mega, T.; Ushio, T.; Matsuda, T.; Kubota, T.; Kachi, M.; Oki, R. Gauge-Adjusted Global Satellite Mapping of Precipitation. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1928–1935. [Google Scholar] [CrossRef]
- Ebert, E.E.; Janowiak, J.E.; Kidd, C. Comparison of near-real-time precipitation estimates from satellite observations and numerical models. Bull. Am. Meteorol. Soc. 2007, 88, 47–64. [Google Scholar] [CrossRef] [Green Version]
- Dinku, T.; Ceccato, P.; Cressman, K.; Connor, S.J. Evaluating detection skills of satellite rainfall estimates over desert locust recession regions. J. Appl. Meteorol. Climatol. 2010, 49, 1322–1332. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Bosilovich, M.G.; Chen, J.; Robertson, F.R.; Adler, R.F. Evaluation of global precipitation in reanalyses. J. Appl. Meteorol. Climatol. 2008, 47, 2279–2299. [Google Scholar] [CrossRef]
- Evans, A.; Jones, D.; Smalley, R.; Lellyett, S. An Enhanced Gridded Rainfall Dataset Scheme for Australia; Bureau of Meteorology: Melbourne, Australia, 2020; ISBN 978-1-925738-12-4. [Google Scholar]
- Brocca, L.; Filippucci, P.; Hahn, S.; Ciabatta, L.; Massari, C.; Camici, S.; Schüller, L.; Bojkov, B.; Wagner, W. SM2RAIN-ASCAT (2007–2018): Global daily satellite rainfall data from ASCAT soil moisture observations. Earth Syst. Sci. Data 2019, 11, 1583–1601. [Google Scholar] [CrossRef] [Green Version]
- Wagner, W.; Hahn, S.; Kidd, R.; Melzer, T.; Bartalis, Z.; Hasenauer, S.; Figa-Saldaña, J.; De Rosnay, P.; Jann, A.; Schneider, S.; et al. The ASCAT soil moisture product: A review of its specifications, validation results, and emerging applications. Meteorol. Zeitschrift 2013, 22, 5–33. [Google Scholar] [CrossRef] [Green Version]
- Huffman, G.J.; Bolvin, D.T.; Braithwaite, D.; Hsu, K.L.; Joyce, R.J.; Kidd, C.; Nelkin, E.J.; Sorooshian, S.; Stocker, E.F.; Tan, J.; et al. Integrated Multi-satellite Retrievals for the Global Precipitation Measurement (GPM) Mission (IMERG). In Advances in Global Change Research; Springer: Berlin/Heidelberg, Germany, 2020; Volume 67, pp. 343–353. [Google Scholar]
- Rudolf, B.; Hauschild, H.; Rueth, W.; Schneider, U. Terrestrial Precipitation Analysis: Operational Method and Required Density of Point Measurements. In Global Precipitations and Climate Change; Springer: Berlin/Heidelberg, Germany, 1994; pp. 173–186. [Google Scholar]
- Chen, M.; Xie, P.; Janowiak, J.E. Global land precipitation: A 50-yr monthly analysis based on gauge observations. J. Hydrometeorol. 2002, 3, 249–266. [Google Scholar] [CrossRef]
- Xie, P.; Xiong, A.Y. A conceptual model for constructing high-resolution gauge-satellite merged precipitation analyses. J. Geophys. Res. Atmos. 2011, 116, D21106. [Google Scholar] [CrossRef]
- Mastrantonas, N.; Bhattacharya, B.; Shibuo, Y.; Rasmy, M.; Espinoza-Dávalos, G.; Solomatine, D. Evaluating the benefits of merging near-real-time satellite precipitation products: A case study in the Kinu basin region, Japan. J. Hydrometeorol. 2019, 20, 1213–1233. [Google Scholar] [CrossRef]
- Piani, C.; Haerter, J.O.; Coppola, E. Statistical bias correction for daily precipitation in regional climate models over Europe. Theor. Appl. Climatol. 2010, 99, 187–192. [Google Scholar] [CrossRef] [Green Version]
- Ines, A.V.M.; Hansen, J.W. Bias correction of daily GCM rainfall for crop simulation studies. Agric. For. Meteorol. 2006, 138, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Pombo, S.; de Oliveira, R.P. Evaluation of extreme precipitation estimates from TRMM in Angola. J. Hydrol. 2015, 523, 663–679. [Google Scholar] [CrossRef]
- Alam, M.A.; Emura, K.; Farnham, C.; Yuan, J. Best-fit probability distributions and return periods for maximum monthly rainfall in Bangladesh. Climate 2018, 6, 9. [Google Scholar] [CrossRef] [Green Version]
- Yue, S.; Hashino, M. Probability distribution of annual, seasonal and monthly precipitation in Japan. Hydrol. Sci. J. 2007, 52, 863–877. [Google Scholar] [CrossRef]
- Mamoon, A.A.; Rahman, A. Selection of the best fit probability distribution in rainfall frequency analysis for Qatar. Nat. Hazards 2017, 86, 281–296. [Google Scholar] [CrossRef]
- Enayati, M.; Bozorg-Haddad, O.; Bazrafshan, J.; Hejabi, S.; Chu, X. Bias correction capabilities of quantile mapping methods for rainfall and temperature variables. J. Water Clim. Chang. 2021, 12, 401–419. [Google Scholar] [CrossRef]
- Becker, A.; Finger, P.; Meyer-Christoffer, A.; Rudolf, B.; Schamm, K.; Schneider, U.; Ziese, M. A description of the global land-surface precipitation data products of the Global Precipitation Climatology Centre with sample applications including centennial (trend) analysis from 1901-present. Earth Syst. Sci. Data 2013, 5, 71–99. [Google Scholar] [CrossRef] [Green Version]
- Funk, C.; Peterson, P.; Landsfeld, M.; Pedreros, D.; Verdin, J.; Shukla, S.; Husak, G.; Rowland, J.; Harrison, L.; Hoell, A.; et al. The climate hazards infrared precipitation with stations—A new environmental record for monitoring extremes. Sci. Data 2015, 2, 150066. [Google Scholar] [CrossRef] [Green Version]
- Wackernagel, H. Multivariate Geostatistics: An Introduction with Applications; Multivar. geostatistics an Introd. with Appl; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar] [CrossRef]
- Ali, G.; Sajjad, M.; Kanwal, S.; Xiao, T.; Khalid, S.; Shoaib, F.; Gul, H.N. Spatial–temporal characterization of rainfall in Pakistan during the past half-century (1961–2020). Sci. Rep. 2021, 11, 6935. [Google Scholar] [CrossRef] [PubMed]
- Frazier, A.G.; Giambelluca, T.W.; Diaz, H.F.; Needham, H.L. Comparison of geostatistical approaches to spatially interpolate month-year rainfall for the Hawaiian Islands. Int. J. Climatol. 2016, 36, 1459–1470. [Google Scholar] [CrossRef] [Green Version]
- Adhikary, S.K.; Muttil, N.; Yilmaz, A.G. Cokriging for enhanced spatial interpolation of rainfall in two Australian catchments. Hydrol. Process. 2017, 31, 2143–2161. [Google Scholar] [CrossRef] [Green Version]
- Gribov, A.; Krivoruchko, K. Empirical Bayesian kriging implementation and usage. Sci. Total Environ. 2020, 722, 137290. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Kamble, T.; Machiwal, D. Comparison of ordinary and Bayesian kriging techniques in depicting rainfall variability in arid and semi-arid regions of north-west India. Environ. Earth Sci. 2017, 76, 512. [Google Scholar] [CrossRef]
- Valdés-Pineda, R.; Demaría, E.; Valdés, J.; Wi, S.; Serrat-Capdevilla, A. Bias correction of daily satellite-based rainfall estimates for hydrologic forecasting in the Upper Zambezi, Africa. Hydrol. Earth Syst. Sci. Discuss. 2016, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Katiraie-Boroujerdy, P.S.; Naeini, M.R.; Asanjan, A.A.; Chavoshian, A.; Hsu, K.L.; Sorooshian, S. Bias correction of satellite-based precipitation estimations using quantile mapping approach in different climate regions of Iran. Remote Sens. 2020, 12, 2102. [Google Scholar] [CrossRef]
- Gumindoga, W.; Rientjes, T.H.M.; Tamiru Haile, A.; Makurira, H.; Reggiani, P. Performance of bias-correction schemes for CMORPH rainfall estimates in the Zambezi River basin. Hydrol. Earth Syst. Sci. 2019, 23, 2915–2938. [Google Scholar] [CrossRef] [Green Version]
- Chatfield, C.; Fuller, W.A. Introduction to Statistical Time Series. J. R. Stat. Soc. Ser. A 1977, 140, 379. [Google Scholar] [CrossRef]
- Massey, F.J. The Kolmogorov-Smirnov Test for Goodness of Fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]





| Dataset and Data Source | Explanation | Biases | Resolution and Domain |
|---|---|---|---|
| Global Satellite Mapping of Precipitation (GSMaP) from Japan Aerospace Exploration Agency (JAXA), microwave-based estimates from satellites [22]. | A rain rate is estimated from the emission and change in the scattering of microwaves due to precipitation. These microwave estimates are advected using cloud motion vectors to increase their spatiotemporal coverage. | Measurement error from the sensors and the reliance on algorithms to obtain a rain rate. The algorithms are known to have a deficiency over topography and coastal boundaries. The detection of light rain from warm clouds [23] and sub-cloud evaporation of rainfall in arid environments [24] are also known problems. | 0.1° × 0.1° global from 60° S to 60° N, hourly |
| ERA5 from the European Centre for Medium-Range Forecast (ECMWF), model reanalysis [25]. | Created using 4D-Var assimilation of observations into their weather forecast model, the Integrated Forecast System (IFS). Assimilation does not include rainfall from gauges but gauge-corrected radar over the United States of America (US) as well as satellite radiances and atmospheric motion vectors are ingested. | Biases arise from the observations ingested, as well as from the assimilation and modelling processes with reduced observations leading to a deterioration in quality [26]. In line with other reanalyses, ERA5 has reduced variability, with spurious low-end rainfall being a contributing factor [6]. | 0.1° × 0.1° global, hourly |
| Multi-Source Weighted Ensemble Product (MSWEP) from GloH2O, gauge-reanalysis-satellite-blended dataset [6]. | Formed from a blend of gauge, satellite, and reanalysis data. The weights for each dataset are based on their correlation to rain gauge data. | Inherent biases from source datasets as well as that introduced from the blending algorithm. | 0.1° × 0.1° global, 3 hourly |
| Australian Gridded Climate Dataset (AGCD) from Bureau of Meteorology (BOM), gauge analysis [27]. | Created using optimal interpolation. Station climatology is used to form the background field onto which incremental adjustments are made using monthly observations. | The density of rain gauges presents the largest control on the quality of the analysis, with the interpolation method generally having a much less significant effect [9]. Quality of the gauge data is also a factor, though quality control is performed on input stations prior to and during interpolation [27]. | 0.01° × 0.01° over Australia, monthly |
| Australian Data Archive for Meteorology (ADAM) rain gauges from BOM. | Contains the data of over 6700 rain gauges across the country. Only stations which had a quality flag of less than six (i.e., checked as not being suspect) were used in this study. | As described in Section 1. | Number of stations ranged from 4346 to 6664 over the study period, daily |
| Soil Moisture to Rain (SM2R) from ESA Climate Change Initiative (CCI), rainfall analysis derived from satellite soil moisture data [28]. | Based on soil moisture estimates from scatterometers on board the MetOp satellites to infer accumulated rainfall. This ‘bottom-up’ approach contrasts with the ‘top-down’ approach of microwave estimates which estimate instantaneous rain rates from upwelling radiation. | Performance degrades over arid areas, frozen soils, tropical rainforests, and topography as the algorithm cannot directly account for the changes in backscatter caused by these surfaces [29]. S2MR has known biases with spurious rainfall due to high-frequency soil moisture fluctuations and underestimation of high-end rainfall [28]. A triple collocation study performed globally demonstrated the performance of SM2R was similar and at times superior to ERA5 and IMERG (Integrated Multi-satellite Retrievals for GPM; see [30] for details) over gauge-sparse regions of the world, including parts of Australia [28]. | 0.25° × 0.25° global, daily |
| Station | MSWEP | TCA | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R | Rank | RMSE | R | Rank | σε | R | Rank | Mean Rank | |
| GSMaP | 1.56 | 0.7 | 9 | 1.01 | 0.82 | 8 | 0.78 | 0.79 | 9 | 8.5 |
| GSMaP-total-OK-old | 0.81 | 0.92 | 1 | 1.11 | 0.87 | 7 | 0.74 | 0.87 | 6 | 4.8 |
| GSMaP-total-OK | 0.91 | 0.89 | 4 | 0.72 | 0.91 | 1 | 0.54 | 0.91 | 3 | 2.8 |
| GSMaP-anom-OK | 1.24 | 0.81 | 7 | 0.88 | 0.86 | 6 | 0.63 | 0.84 | 7 | 7 |
| GSMaP-total-EBK | 0.81 | 0.91 | 2 | 0.72 | 0.92 | 1 | 0.53 | 0.92 | 1 | 1.5 |
| GSMaP-anom-EBK | 1.09 | 0.85 | 5 | 0.82 | 0.87 | 4 | 0.56 | 0.88 | 4 | 4.5 |
| GSMaP-total-EBKRP | 0.83 | 0.91 | 3 | 0.74 | 0.9 | 3 | 0.54 | 0.91 | 2 | 2.7 |
| GSMaP-anom-EBKRP | 1.1 | 0.85 | 6 | 0.86 | 0.86 | 5 | 0.59 | 0.88 | 4 | 5.3 |
| GSMaP-CDF | 1.32 | 0.81 | 7 | 1.08 | 0.82 | 8 | 0.88 | 0.85 | 8 | 7.8 |
| AGCD | 0.44 | 0.98 | 1 | 0.62 | 0.92 | 19 | 0.42 | 0.93 | 9 | 11.2 |
| Station | MSWEP | TCA | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R | Rank | RMSE | R | Rank | σε | R | Rank | Rank (Mean) | |
| GSMaP-total-OK-IEV-old | 0.62 | 0.96 | 9 | 0.57 | 0.94 | 7 | 0.44 | 0.93 | 16 | 10.3 |
| GSMaP-total-OK-IEV | 0.66 | 0.95 | 12 | 0.54 | 0.95 | 2 | 0.40 | 0.94 | 1 | 6.2 |
| GSMaP-anom-OK-IEV | 0.69 | 0.95 | 13 | 0.54 | 0.95 | 1 | 0.40 | 0.94 | 2 | 6.7 |
| GSMaP-total-EBK-IEV | 0.64 | 0.95 | 10 | 0.55 | 0.94 | 3 | 0.42 | 0.94 | 3 | 6.8 |
| GSMaP-anom-EBK-IEV | 0.72 | 0.94 | 18 | 0.57 | 0.94 | 4 | 0.40 | 0.93 | 6 | 10.5 |
| GSMaP-total-EBKRP-IEV | 0.64 | 0.95 | 11 | 0.56 | 0.94 | 5 | 0.41 | 0.94 | 3 | 8.2 |
| GSMaP-anom-EBKRP-IEV | 0.72 | 0.94 | 17 | 0.57 | 0.94 | 8 | 0.40 | 0.93 | 3 | 10.7 |
| GSMaP-total-OK-DW | 0.60 | 0.96 | 4 | 0.60 | 0.94 | 9 | 0.45 | 0.93 | 9 | 9.3 |
| GSMaP-total-OK-TC | 0.72 | 0.94 | 18 | 0.60 | 0.94 | 10 | 0.44 | 0.93 | 7 | 13.2 |
| GSMaP-total-OK-TC-ERA5 | 1.28 | 0.76 | 26 | 1.23 | 0.68 | 24 | 0.32 | 0.92 | 8 | 21.0 |
| AGCD | 0.44 | 0.98 | 1 | 0.62 | 0.92 | 19 | 0.42 | 0.93 | 9 | 11.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chua, Z.-W.; Kuleshov, Y.; Watkins, A.B.; Choy, S.; Sun, C. A Comparison of Various Correction and Blending Techniques for Creating an Improved Satellite-Gauge Rainfall Dataset over Australia. Remote Sens. 2022, 14, 261. https://doi.org/10.3390/rs14020261
Chua Z-W, Kuleshov Y, Watkins AB, Choy S, Sun C. A Comparison of Various Correction and Blending Techniques for Creating an Improved Satellite-Gauge Rainfall Dataset over Australia. Remote Sensing. 2022; 14(2):261. https://doi.org/10.3390/rs14020261
Chicago/Turabian StyleChua, Zhi-Weng, Yuriy Kuleshov, Andrew B. Watkins, Suelynn Choy, and Chayn Sun. 2022. "A Comparison of Various Correction and Blending Techniques for Creating an Improved Satellite-Gauge Rainfall Dataset over Australia" Remote Sensing 14, no. 2: 261. https://doi.org/10.3390/rs14020261