
A Field-Data-Aided Comparison of Three 10 m Land Cover Products in Southeast Asia
 ,
,  , , , , and
, , , , and
Abstract
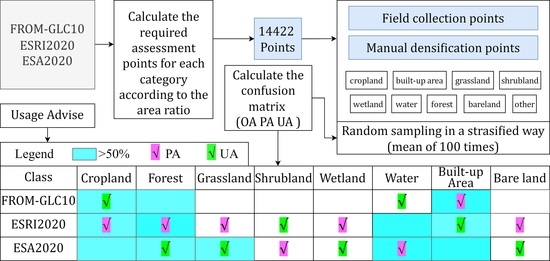
:
1. Introduction
2. Study Area and Data
2.1. Southeast Asia
2.2. Data
2.2.1. Three 10 m Land Cover Products
- (1)
- FROM_GLC10
- (2)
- ESRI2020
- (3)
- ESA2020
2.2.2. The Collection of the Field Data
3. Methods
3.1. Method of Validation Point Processing
3.1.1. Consistency Analysis of the Three Land Cover Products
3.1.2. Method of Determining the Number of Points
3.1.3. Stratified Random Sampling
3.2. Accuracy Validation Method
3.3. Accuracy Validation Uncertainty Analysis Methods
4. Results
4.1. Final Validation Points
4.1.1. Consistency Analysis Results of the Three Land Cover Products
- (1)
- Area consistency analysis results
- (2)
- Spatial consistency analysis results
4.1.2. Final Number of Validation Points
4.1.3. Results of the Stratified Random Sampling
4.2. Accuracy Validation Results Based on a Confusion Matrix
4.3. Accuracy Validation Uncertainty Analysis Results
5. Discussion
5.1. Influence of the Classification Standard Differences on the Accuracy Validation
5.2. Uncertainties of the Different Sampling Method and the Sampling Points
5.3. Suggestions for the Production and Usage of Land Cover Products in Southeast Asia
6. Conclusions
- (1)
- On taking the mean of 100 random samplings in a stratified manner as a reference, ESA2020 was found to have the highest OA (81.11%), followed by ESRI2020 (79.99%) and FROM_GLC10 (75.43%). In terms of single-class accuracy, the cropland, forest, and built-up areas in the three products all had higher accuracies, while the shrubland, wetland, and bare land areas all had lower PA and UA values.
- (2)
- Differences in classification standards are a major problem in the production of the current land cover products, and the unclear definition of a certain land cover class tends to lead to complete confusion during the classification. Land cover producers should pay particular attention to creating a single classification standard.
- (3)
- The sampling method affects the validation results. Both stratification and consideration of the class area ratio are important.
- (4)
- According to the different mixing ratios of the field collection points and the manual densification points, we found that the validation accuracy of the sample points close to the road and the uniform distribution of the sample points have a deviation of nearly 19%.
- (5)
- The accuracy of a class differed in different products, and each had its advantages and disadvantages. The overall accuracy of the cropland, forest, and built-up areas in the three land cover products; the accuracy of the grassland area in ESA2020; and the accuracy of the water area in ESRI2020 and ESA2020 exceeded 50%. From the perspective of the PA, we recommend that when producing land cover maps, the built-up area be extracted using FROM_GLC10. For cropland, forest, grassland, wetland, and bare land, ESRI2020 is more applicable. ESA2020 applies to shrubland and water. According to the UA, we recommend that users use these three land cover products comprehensively, for example, the cropland and water areas of FROM_GLC10; the shrubland and built-up areas of ESRI2020; and the forest, grassland, wetland, and bare land areas of ESA2020.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cropland | |
 |  |
| Field Photo CODE: IMG_8322 Acquisition date: 2018/11/30 10:21:03 Latitude: 4°50′36.46″N Longitude: 100°54′1.04″E Elevation: 96.7 m | Remote Sensing Image 10 m image: Sentinel-2 (12/25/2018) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Obvious geometric features, with block or strip distribution, different areas, and clear boundaries Hue: Light green, dark green, brown, orange, yellow, light red, and other colors Texture: Uniform texture, with linear texture features inside |
| Forest | |
 |  |
| Field Photo CODE: IMG_141005 Acquisition date: 2018/12/06 14:10:06 Latitude: 6°2′34.63″N Longitude: 116°42′22.90″E Elevation: 0 m | Remote Sensing Image 10 m image: Sentinel-2 (12/17/2018) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Regular geometric features (planted forests) or irregular boundaries (natural forests) with clear boundaries Hue: Light green, green, and dark green Texture: Rough texture; chaotic, complex, and pitted image texture |
| Grassland | |
 |  |
| Field Photo CODE: IMG_8459 Acquisition date: 2018/12/01 09:29:46 Latitude: 5°56′22.91″N Longitude: 102°26′51.64″E Elevation: 1.3 m | Remote Sensing Image 10 m image: Sentinel-2 (01/14/2019) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Surface, strip, block, irregular geometry, small area distribution Hue: Green, light green, dark green, and yellow Texture: No obvious textural features, more common in the slope areas on both sides of the road |
| Shrubland | |
 |  |
| Field Photo CODE: IMG_8566 Acquisition date: 2018/12/01 15:51:24 Latitude: 4°32′27.64″N Longitude: 103°27′56.71″E Elevation: 19.0 m | Remote Sensing Image 10 m image: Sentinel-2 (02/05/2019) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Irregular shape Hue: Brown and green Texture: Uniform image structure |
| Wetland | |
 |  |
| Field Photo CODE: IMG_8697 Acquisition date: 2018/12/01 18:29:46 Latitude: 4°7′23.15″N Longitude: 103°23′5.51″E Elevation: 8.1 m | Remote Sensing Image 10 m image: Sentinel-2 (02/25/2019) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Distributed in strips and sheets along rivers and seas, coastal zones, and confluence zones Hue: Yellow-white, off-white, yellow, and bright green Texture: Image structure uniform |
| Water | |
 |  |
| Field Photo CODE: IMG_8415 Acquisition date: 2018/11/30 15:45:54 Latitude: 5°33′8.56″N Longitude: 101°20′51.15″E Elevation: 244.6 m | Remote Sensing Image 10 m image: Sentinel-2 (12/25/2018) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Geometric features, natural curvature, and obvious boundaries Hue: Light blue, blue, dark blue, and dark green Texture: Smooth texture; uniform image structure |
| Built-up area | |
 |  |
| Field Photo CODE: IMG_145702 Acquisition date: 2018/12/07 14:57:02 Latitude: 5°59′23.20″N Longitude: 116°4′44.74″E Elevation: 63.62 m | Remote Sensing Image 10 m image: Sentinel-2 (01/11/2019) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Obvious geometric features and clear boundaries Hue: Colorful, white, blue, red, yellow, and gray Texture: Complex and rough image structure |
| Bare land | |
 |  |
| Field Photo CODE: IMG_135822 Acquisition date: 2018/12/04 13:58:22 Latitude: 1°2′6.15″N Longitude: 110°40′52.53″E Elevation: 37.4 m | Remote Sensing Image 10 m image: Sentinel-2 (03/23/2019) High-resolution image: From Google Earth Color channels: Red, green, and blue Shape: Different geometric shapes and clear boundaries Hue: Yellow-white, off-white, and white Texture: Fine texture; uniform image structure |
Appendix B. Spatial Consistency Analysis Results








References
- Din, S.U.; Mak, H.W.L. Retrieval of Land-Use/Land Cover Change (LUCC) Maps and Urban Expansion Dynamics of Hyderabad, Pakistan via Landsat Datasets and Support Vector Machine Framework. Remote Sens. 2021, 13, 3337. [Google Scholar] [CrossRef]
- Yu, W.; Zang, S.; Wu, C.; Liu, W.; Na, X. Analyzing and modeling land use land cover change (LUCC) in the Daqing City, China. Appl. Geogr. 2011, 31, 600–608. [Google Scholar] [CrossRef]
- Borrelli, P.; Robinson, D.A.; Fleischer, L.R.; Lugato, E.; Ballabio, C.; Alewell, C.; Meusburger, K.; Modugno, S.; Schütt, B.; Ferro, V. An validation of the global impact of 21st century land use change on soil erosion. Nat. Commun. 2017, 8, 2013. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, C.; Zhang, J.; Liu, Z.; Huang, Q. Characteristics and progress of land use/cover change research during 1990–2018. J. Geogr. Sci. 2022, 32, 537–559. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Wei, X.; Chen, X.; Zhou, P.; Liu, X.; Xiao, Y.; Sun, G.; Scott, D.F.; Zhou, S.; Han, L. Global pattern for the effect of climate and land cover on water yield. Nat. Commun. 2015, 6, 5918. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F.; Magazine, R.S. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar]
- Kibria, M.G.; Nguyen, K.; Villardi, G.P.; Zhao, O.; Ishizu, K.; Kojima, F. Big data analytics, machine learning, and artificial intelligence in next-generation wireless networks. Kibria M G, Nguyen K, Villardi G P, et al. Big data analytics, machine learning, and artificial intelligence in next-generation wireless networks. IEEE Access 2018, 6, 32328–32338. [Google Scholar] [CrossRef]
- Wu, J.; Guo, S.; Li, J.; Zeng, D. Big data meet green challenges: Big data toward green applications. IEEE Syst. J. 2016, 10, 888–900. [Google Scholar] [CrossRef]
- Stoian, A.; Poulain, V.; Inglada, J.; Poughon, V.; Derksen, D. Land cover maps production with high resolution satellite image time series and convolutional neural networks: Adaptations and limits for operational systems. Remote Sens. 2019, 11, 1986. [Google Scholar] [CrossRef] [Green Version]
- Tsendbazar, N.; Herold, M.; De Bruin, S.; Lesiv, M.; Fritz, S.; Van De Kerchove, R.; Buchhorn, M.; Duerauer, M.; Szantoi, Z.; Pekel, J.-F. Developing and applying a multi-purpose land cover validation dataset for Africa. Remote Sens. Environ. 2018, 219, 298–309. [Google Scholar] [CrossRef] [Green Version]
- Venter, Z.S.; Barton, D.N.; Chakraborty, T.; Simensen, T.; Singh, G. Global 10 m Land Use Land Cover Datasets: A Comparison of Dynamic World, World Cover and Esri Land Cover. Remote Sens. 2022, 14, 4101. [Google Scholar] [CrossRef]
- Giri, C.; Zhu, Z.; Reed, B. A comparative analysis of the Global Land Cover 2000 and MODIS land cover data sets. Remote Sens. Environ. 2005, 94, 123–132. [Google Scholar] [CrossRef]
- Zhao, J.; Dong, Y.; Zhang, M.; Huang, L. Comparison of identifying land cover tempo-spatial changes using GlobCover and MCD12Q1 global land cover products. Arab. J. Geosci. 2020, 13, 1–12. [Google Scholar] [CrossRef]
- Kang, J.; Yang, X.; Wang, Z.; Cheng, H.; Wang, J.; Tang, H.; Li, Y.; Bian, Z.; Bai, Z. Comparison of Three Ten Meter Land Cover Products in a Drought Region: A Case Study in Northwestern China. Land 2022, 11, 427. [Google Scholar] [CrossRef]
- Wang, J.; Yang, X.; Wang, Z.; Cheng, H.; Kang, J.; Tang, H.; Li, Y.; Bian, Z.; Bai, Z. Consistency Analysis and Accuracy Validation of Three Global Ten-Meter Land Cover Products in Rocky Desertification Region—A Case Study of Southwest China. ISPRS Int. J. Geo-Inf. 2022, 11, 202. [Google Scholar] [CrossRef]
- Chang, C.-P.; Wang, Z.; McBride, J.; Liu, C.-H. Annual cycle of Southeast Asia—Maritime Continent rainfall and the asymmetric monsoon transition. J. Clim. 2005, 18, 287–301. [Google Scholar] [CrossRef]
- Hall, R.J.B.-B. Southeast Asia’s changing palaeogeography. Blumea-Biodivers. Evol. Biogeogr. Plants 2009, 54, 148–161. [Google Scholar] [CrossRef] [Green Version]
- Paradis, E. Forest gains and losses in Southeast Asia over 27 years: The slow convergence towards reforestation. For. Policy Econ. 2021, 122, 102332. [Google Scholar] [CrossRef]
- Rahman, M.S.; Khan, M.; Jolly, Y.; Kabir, J.; Akter, S.; Salam, A. Assessing risk to human health for heavy metal contamination through street dust in the Southeast Asian Megacity: Dhaka, Bangladesh. Sci. Total Environ. 2019, 660, 1610–1622. [Google Scholar] [CrossRef] [PubMed]
- Plummer, M.G.; Morgan, P.J.; Wignaraja, G. Connecting Asia: Infrastructure for Integrating South and Southeast Asia; Edward Elgar Publishing: Cheltenham, UK, 2016. [Google Scholar]
- Yu, H. China’s Belt and Road Initiative and its implications for Southeast Asia. Asia Policy 2017, 24, 117–122. [Google Scholar] [CrossRef]
- Lam, J.S.L.; Cullinane, K.P.B.; Lee, P.T.-W. The 21st-century Maritime Silk Road: Challenges and opportunities for transport management and practice. Transp. Rev. 2018, 38, 413–415. [Google Scholar] [CrossRef] [Green Version]
- Weber, N. Malays in the Indochinese Peninsula: Adventurers, Warlords and Ministers. J. Malays. Branch R. Asiat. Soc. 2021, 94, 1–23. [Google Scholar] [CrossRef]
- Xu, L.; Sun, S.; Chen, H.; Chai, R.; Wang, J.; Zhou, Y.; Ma, Q.; Chotamonsak, C.; Wangpakapattanawong, P. Changes in the reference evapotranspiration and contributions of climate factors over the Indo–China Peninsula during 1961–2017. Int. J. Clim. 2021, 41, 6511–6529. [Google Scholar] [CrossRef]
- Ohtani, M.; Tani, N.; Ueno, S.; Uchiyama, K.; Kondo, T.; Lee, S.L.; Ng, K.K.S.; Muhammad, N.; Finkeldey, R.; Gailing, O.; et al. Genetic structure of an important widely distributed tropical forest tree, Shorea parvifolia, in Southeast Asia. Tree Genet. Genomes 2021, 17, 1–13. [Google Scholar] [CrossRef]
- Lord, F. Transformation to sustainable and resilient urban futures in Southeast Asia. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 6, 43–50. [Google Scholar] [CrossRef]
- Wang, C.; Wang, D.; Abbas, J.; Duan, K.; Mubeen, R. Global financial crisis, smart lockdown strategies, and the COVID-19 spillover impacts: A global perspective implications from Southeast Asia. Front. Psychiatry 2021, 12, 643783. [Google Scholar] [CrossRef]
- Sovacool, B. The political economy of oil and gas in Southeast Asia: Heading towards the natural resource curse? Pac. Rev. 2010, 23, 225–259. [Google Scholar] [CrossRef]
- Kumar, S. Validation of renewables for energy security and carbon mitigation in Southeast Asia: The case of Indonesia and Thailand. Appl. Energy 2016, 163, 63–70. [Google Scholar] [CrossRef]
- Clay, J. World Agriculture and the Environment: A Commodity-by-Commodity Guide to Impacts and Practices; Island Press: Washington, DC, USA, 2004. [Google Scholar]
- Hasan, M.H.; Mahlia, T.I.; Nur, H.J.R.; Reviews, S.E. A review on energy scenario and sustainable energy in Indonesia. Renew. Sustain. Energy Rev. 2012, 16, 2316–2328. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, J.; Li, L.; Yu, L.; Li, J.; Xin, X. Ecological environment monitoring for sustainable development goals in the Belt and Road region. AOGEOSS Prog. 2018, 22, 686–708. [Google Scholar]
- Huang, B.; Hu, X.; Fuglstad, G.-A.; Zhou, X.; Zhao, W.; Cherubini, F. Predominant regional biophysical cooling from recent land cover changes in Europe. Nat. Commun. 2020, 11, 1066. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, L.; Wang, J.; Li, X.; Li, C.; Zhao, Y.; Gong, P. A multi-resolution global land cover dataset through multisource data aggregation. Sci. China Earth Sci. 2014, 57, 2317–2329. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Li, C.; Gong, P.; Wang, J.; Zhu, Z.; Biging, G.S.; Yuan, C.; Hu, T.; Zhang, H.; Wang, Q.; Li, X. The first all-season sample set for mapping global land cover with Landsat-8 data. Sci. Bull. 2017, 62, 508–515. [Google Scholar] [CrossRef] [Green Version]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 v100. Zenodo 2021, 601280. [Google Scholar] [CrossRef]
- Powell, R.; Matzke, N.; de Souza Jr, C.; Clark, M.; Numata, I.; Hess, L.; Roberts, D. Sources of error in accuracy validation of thematic land-cover maps in the Brazilian Amazon. Remote Sens. Environ. 2004, 90, 221–234. [Google Scholar] [CrossRef]
- Ruelland, D.; Tribotte, A.; Puech, C.; Dieulin, C. Comparison of methods for LUCC monitoring over 50 years from aerial photographs and satellite images in a Sahelian catchment. Int. J. Remote Sens. 2011, 32, 1747–1777. [Google Scholar] [CrossRef]
- Lee, S. Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data. Int. J. Remote Sens. 2005, 26, 1477–1491. [Google Scholar] [CrossRef]
- Lu, M.; Wu, W.; Zhang, L.; Liao, A.; Peng, S.; Tang, H. A comparative analysis of five global cropland datasets in China. Sci. China Earth Sci. 2016, 59, 2307–2317. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, L.; Feng, D.; Peng, D.; Li, C.; Huang, X.; Lu, H.; Gong, P. Comparisons of three recent moderate resolution African land cover datasets: CGLS-LC100, ESA-S2-LC20, and FROM-GLC-Africa30. Int. J. Remote Sens. 2019, 40, 6185–6202. [Google Scholar] [CrossRef]
- Hua, T.; Zhao, W.; Liu, Y.; Wang, S.; Yang, S. Spatial consistency validations for global land-cover datasets: A comparison among GLC2000, CCI LC, MCD12, GLOBCOVER and GLCNMO. Remote Sens. 2018, 10, 1846. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Shibasaki, R.; Yang, P.; Ongaro, L.; Zhou, Q.; Tang, H. Validation and comparison of 1 km global land cover products in China. Int. J. Remote Sens. 2008, 29, 3769–3785. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Congalton, R. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Horvitz, D.G.; Thompson, D.J. A generalization of sampling without replacement from a finite universe. J. Am. Stat. Assoc. 1952, 47, 663–685. [Google Scholar] [CrossRef]
- Neyman, J. On the two different aspects of the representative method: The method of stratified sampling and the method of purposive selection. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 123–150. [Google Scholar]
- Stehman, S.V. Estimating area and map accuracy for stratified random sampling when the strata are different from the map classes. Int. J. Remote Sens. 2014, 35, 4923–4939. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy validation of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Tsendbazar, N.; Herold, M.; Li, L.; Tarko, A.; de Bruin, S.; Masiliunas, D.; Lesiv, M.; Fritz, S.; Buchhorn, M.; Smets, B.; et al. Towards operational validation of annual global land cover maps. Remote Sens. Environ. 2021, 266, 112686. [Google Scholar] [CrossRef]
- Negassa, M.D.; Mallie, D.T.; Gemeda, D.O. Forest cover change detection using Geographic Information Systems and remote sensing techniques: A spatio-temporal study on Komto Protected forest priority area, East Wollega Zone, Ethiopia. Environ. Syst. Res. 2020, 9, 1. [Google Scholar] [CrossRef] [Green Version]
- Townsend, J.T. Theoretical analysis of an alphabetic confusion matrix. Percept. Psychophys. 1971, 9, 40–50. [Google Scholar] [CrossRef]
- Visa, S.; Ramsay, B.; Ralescu, A.L.; Van Der Knaap, E. Confusion matrix-based feature selection. MAICS 2011, 710, 120–127. [Google Scholar]
- Hay, A. The derivation of global estimates from a confusion matrix. Int. J. Remote Sens. 1988, 9, 1395–1398. [Google Scholar] [CrossRef]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy validation in convolutional neural network-based deep learning remote sensing studies—Part 2: Recommendations and best practices. Remote Sens. 2021, 13, 2591. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy validation in convolutional neural network-based deep learning remote sensing studies—Part 1: Literature review. Remote Sens. 2021, 13, 2450. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy validation. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Benjamini, Y. Opening the box of a boxplot. Am. Stat. 1988, 42, 257–262. [Google Scholar]
- Frigge, M.; Hoaglin, D.C.; Iglewicz, B. Some implementations of the boxplot. Am. Stat. 1989, 43, 50–54. [Google Scholar]
- Rousseeuw, P.J.; Ruts, I.; Tukey, J.W. The bagplot: A bivariate boxplot. Am. Stat. 1999, 53, 382–387. [Google Scholar]
- Congalton, R.G. A comparison of sampling schemes used in generating error matrices for assessing the accuracy of maps generated from remotely sensed data. Photogramm. Eng. Remote Sens. 1988, 54, 593–600. [Google Scholar]
- Stehman, S.V.; Olofsson, P.; Woodcock, C.E.; Herold, M.; Friedl, M.A. A global land-cover validation data set, II: Augmenting a stratified sampling design to estimate accuracy by region and land-cover class. Int. J. Remote Sens. 2012, 33, 6975–6993. [Google Scholar] [CrossRef]
- Di Gregorio, A. Land Cover Classification System: Classification Concepts and User Manual: LCCS; Food & Agriculture Org.: Yokohama, Japan, 2005; Volume 2. [Google Scholar]
- Xie, Y.; Sha, Z.; Yu, M. Remote sensing imagery in vegetation mapping: A review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- He, C.; Zhang, Q.; Li, Y.; Li, X.; Shi, P. Zoning grassland protection area using remote sensing and cellular automata modeling—a case study in Xilingol steppe grassland in northern China. J. Arid. Environ. 2005, 63, 814–826. [Google Scholar] [CrossRef]
- Stow, D.; Hamada, Y.; Coulter, L.; Anguelova, Z. Monitoring shrubland habitat changes through object-based change identification with airborne multispectral imagery. Remote Sens. Environ. 2008, 112, 1051–1061. [Google Scholar] [CrossRef]
- Rendenieks, Z.; Tērauds, A.; Nikodemus, O.; Brūmelis, G. Comparison of input data with different spatial resolution in landscape pattern analysis–a case study from northern latvia. Appl. Geogr. 2017, 83, 100–106. [Google Scholar] [CrossRef]
- Olofsson, P.; Stehman, S.V.; Woodcock, C.E.; Sulla-Menashe, D.; Sibley, A.M.; Newell, J.D.; Friedl, M.A.; Herold, M. A global land-cover validation data set, part I: Fundamental design principles. Int. J. Remote Sens. 2012, 33, 5768–5788. [Google Scholar] [CrossRef]
- Kang, J.; Wang, Z.; Sui, L.; Yang, X.; Ma, Y.; Wang, J. Consistency analysis of remote sensing land cover products in the tropical rainforest climate region: A case study of Indonesia. Remote Sens. 2020, 12, 1410. [Google Scholar] [CrossRef]












| Land Cover Products | FROM-GLC10 | ESRI2020 | ESA2020 |
|---|---|---|---|
| Producer | The team of Professor Gong Peng of Tsinghua University | ESRI2020 and Microsoft’s Planetary Computer | European Space Agency (ESA2020) |
| Publication date | 2017 | 2020 | 2021 |
| Resolution | 10 m | 10 m | 10 m |
| Source of remote sensing images | 2015 Landsat-8 2017 Sentinel-2 | 2020 Sentinel-2 | 2020 Sentinel-1 2020 Sentinel-2 |
| Number of classes | 10 | 10 | 11 |
| Production method | Random forest algorithm | Deep learning model | Cat boost |
| Validation method | It uses the equal-area stratified sampling method. | The Impact Observatory adjusts the acreage estimates for each class using its respective user’s accuracy as computed from the comparison with the validation set. |
|
| Overall global accuracy | 72.76% | 86% | 74.4% |
| Download link | http://data.ess.tsinghua.edu.cn | https://www.arcgis.com/home/item.html?id=d6642f8a4f6d4685a24ae2dc0c73d4ac | https://ESA2020-worldcover.org/en |
| Country | Start Date–End Date | Duration (Days) |
|---|---|---|
| Thailand | 2018/09/07–2018/09/16 | 10 |
| Malaysia | 2018/11/29–2018/12/07 | 9 |
| Laos-Cambodia | 2019/03/20–2019/03/31 | 12 |
| Cambodia | 2019/08/08–2019/08/14 | 7 |
| Myanmar | 2019/09/20–2019/09/28 | 9 |
| Indonesia | 2019/09/11–2019/09/19 | 9 |
| Field Point Number | A08 | ||
|---|---|---|---|
| Latitude (°) | 18.33061396 | ||
| Longitude (°) | 99.32298898 | ||
| Elevation (m) | 315.356323 | ||
| Field photo | Corresponding remote sensing image | ||
 |  | ||
| Visit date | 2018/09/08 | Road number | 11 |
| Landform class | Plain | ||
| Investigators | Li He, Zhang Chenchen | Land cover class | Plantation |
| Detailed description | Oil palm | ||
| Standardization | FROM_GLC10 | ESRI2020 | ESA2020 |
|---|---|---|---|
| Cropland | Cropland | Crops | Cropland |
| Forest | Forest | Trees | Tree cover |
| Grassland | Grassland | Grass | Grassland |
| Shrubland | Shrubland | Scrub/shrubs | Shrubland |
| Wetland | Wetland Mangroves | Flooded vegetation | Herbaceous wetland |
| Water | Water body | Water | Permanent water bodies |
| Built-up area | Impervious area | Built-up area | Built-up area |
| Bare land | Bare land | Bare ground | Bare/sparse vegetation |
| Other | Snow/ice Moss and lichen forest | Snow/ice Clouds | Snow and ice |
| Class | Actual | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| … | Correct | Total | UA | ||||||
| Predicted | … | ||||||||
| … | |||||||||
| … | |||||||||
| … | … | … | … | … | … | … | … | … | |
| Correct | |||||||||
| Total | |||||||||
| PA | OA | ||||||||
| Unit: km2 | ESA2020 | ESRI2020 | FROM-GLC10 | Average | |||
|---|---|---|---|---|---|---|---|
| CP (Cropland) | 540,447.75 | 23.95% | 644,158.74 | 23.91% | 786,799.12 | 33.80% | 27.22% |
| FR (Forest) | 1124,595.80 | 49.84% | 1167,954.10 | 43.35% | 1142,617.50 | 49.08% | 47.42% |
| GL (Grassland) | 330,066.35 | 14.63% | 40,306.44 | 1.50% | 199,832.56 | 8.58% | 8.24% |
| SL (Shrubland) | 26,184.84 | 1.16% | 501,742.20 | 18.62% | 30,170.35 | 1.30% | 7.03% |
| WL (Wetland) | 19,714.29 | 0.87% | 27,522.65 | 1.02% | 4471.40 | 0.19% | 0.69% |
| WT (Water) | 91,009.76 | 4.03% | 118,099.02 | 4.38% | 106,481.40 | 4.57% | 4.33% |
| BA (Built-up area) | 51,466.86 | 2.28% | 186,863.85 | 6.94% | 46,856.13 | 2.01% | 3.74% |
| BL (Bare land) | 72,832.96 | 3.23% | 7798.59 | 0.29% | 10,539.68 | 0.45% | 1.32% |
| Other | 184.40 | 0.01% | 0 | 0.00% | 340.48 | 0.01% | 0.01% |
| Total | 2256,503.00 | 2694,445.60 | 2328,108.60 | ||||
| Class | Average Area Ratio | Calculation Results (Consider Area Ratio) | Number of Final Validation Points | ||
|---|---|---|---|---|---|
| Field Collection | Manual Densification | Total | |||
| Cropland | 27.2% | 3926 | 3926 | 3971 | 5142 |
| Forest | 47.4% | 6840 | 6840 | 6883 | 8016 |
| Grassland | 8.2% | 1188 | 1188 | 1238 | 1626 |
| Shrubland | 7.0% | 1013 | 1013 | 1067 | 1205 |
| Wetland | 0.7% | 100 | 100 | 189 | 253 |
| Water | 4.3% | 624 | 624 | 645 | 739 |
| Built-up area | 3.7% | 540 | 540 | 552 | 760 |
| Bare land | 1.3% | 191 | 191 | 263 | 393 |
| Total | 100.0% | 14,422 | 3326 | 14,803 | 18,134 |
| Land Cover Products | Class Abbreviations | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CL | FR | GL | SL | WL | WT | BA | BL | OA (%) | ||
| FROM-GLC10 | PA (%) | 73.27 | 88.50 | 72.50 | 12.04 | 13.85 | 32.78 | 83.92 | 35.33 | 75.43 |
| UA (%) | 90.44 | 86.17 | 44.89 | 0.26 | 1.83 | 91.37 | 58.35 | 5.35 | ||
| ESRI2020 | PA (%) | 89.40 | 90.83 | 82.78 | 32.68 | 34.23 | 83.24 | 54.86 | 81.33 | 79.99 |
| UA (%) | 81.18 | 91.70 | 29.22 | 58.45 | 22.51 | 90.29 | 93.07 | 25.48 | ||
| ESA2020 | PA (%) | 89.27 | 84.66 | 55.72 | 41.02 | 30.90 | 90.25 | 80.93 | 37.84 | 81.11 |
| UA (%) | 82.44 | 95.17 | 66.46 | 2.03 | 69.53 | 86.44 | 77.85 | 58.74 | ||
| Land Cover Products | No Stratification | with Stratification | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| with Area Ratio | No Area Ratio (Different Numbers) | |||||||||
| 10 | 50 | 100 | 500 | 1000 | 2000 | 5000 | Average | |||
| FROM_GLC10 | 74.13% | 75.43% | 47.04% | 47.41% | 47.29% | 47.24% | 47.34% | 47.35% | 47.32% | 47.28% |
| ESRI2020 | 78.54% | 79.99% | 61.78% | 61.44% | 61.64% | 61.47% | 61.49% | 61.44% | 61.45% | 61.53% |
| ESA2020 | 80.56% | 81.11% | 66.73% | 67.38% | 67.45% | 67.37% | 67.38% | 67.33% | 67.38% | 67.29% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Yang, X.; Wang, Z.; Fu, D.; Li, H.; Meng, D.; Zeng, X.; Zhang, J. A Field-Data-Aided Comparison of Three 10 m Land Cover Products in Southeast Asia. Remote Sens. 2022, 14, 5053. https://doi.org/10.3390/rs14195053
Ding Y, Yang X, Wang Z, Fu D, Li H, Meng D, Zeng X, Zhang J. A Field-Data-Aided Comparison of Three 10 m Land Cover Products in Southeast Asia. Remote Sensing. 2022; 14(19):5053. https://doi.org/10.3390/rs14195053
Chicago/Turabian StyleDing, Yaxin, Xiaomei Yang, Zhihua Wang, Dongjie Fu, He Li, Dan Meng, Xiaowei Zeng, and Junyao Zhang. 2022. "A Field-Data-Aided Comparison of Three 10 m Land Cover Products in Southeast Asia" Remote Sensing 14, no. 19: 5053. https://doi.org/10.3390/rs14195053