1. Introduction
Severe convective precipitation can cause secondary disasters such as debris flows and landslides, which have a great impact on economic development and social security. It is extremely difficult to accurately predict severe convective precipitation, because strong convective precipitation has the characteristics of strong locality, rapid development and nonlinear evolution. Observing strong convection processes using weather radar and predicting the development of radar echoes within 0–1 h can improve the accuracy of nowcasting and is an important issue in nowcasting research [
1]. The main difficulty in nowcasting is prediction of strong echo regions and understanding of the evolution meteorological echoes, both of which remain to be addressed despite advances in the past few decades [
2].
Traditional nowcasting methods are based on numerical weather prediction (NWP) [
3]. The model based on NWP is to describe continuous changes in meteorological elements in time and space through complex atmospheric equations, so as to obtain reasonable and accurate forecast results in a few hours to days. With the increasing amount of temporal and spatial information for prediction, high-resolution NWP-based models put forward extremely high requirements on the information extraction capability and processing time of the computer. Therefore, improved prediction accuracy of NWP-based models is limited with the increase in the amount of data; there is still a large room for improvement in short-term nowcasting [
4].
With the development of high-resolution weather radar and meteorological satellites, forecast models based on radar echo and cloud image extrapolation are gradually being applied [
5]. It can extract features of the moving trend of convection, so as to play a certain role in judging the evolution of convection.
Currently, radar extrapolation methods used for operational applications mainly focus on thunderstorm-based identifying and tracking, as well as automatic extrapolation of forecasts, including the single centroid method, cross-correlation method and optical flow method [
6,
7,
8]. Single centroid methods, such as TITAN (Thunderstorm Identification, Tracking, Analysis and Nowcasting) [
9] and SCIT (Storm Cell Identification and Tracking) [
10], provide information on convective cell motion and evolution based on convective cell merging and splitting by identifying and tracking groups of convective cells, whereas the forecast accuracy rapidly decreases when echoes are fused and split. The cross-correlation method, such as TREC (Tracking Radar Echoes by Correlation), calculates spatially optimized correlation coefficients for two proximate moments and subsequently creates a fitting relationship for all radar echoes. It can effectively track stratiform cloud and rainfall systems, but for strong convective processes with fast echo changes, the tracking accuracy is significantly reduced. Optical flow methods, such as ROVER (Real-time Optical flow by Variational methods for Echoes of Radar) [
11], calculate the optical flow field from continuous time radar echo images, replace the radar echo motion vector field with the optical flow field, and extrapolate radar echo based on a motion vector field to achieve nowcasting. The optical flow method differs from the cross-correlation method in that it is based on changes rather than selected invariant features, but the problem of cumulative error exists in calculating optical flow vector and extrapolation. In general, these methods only infer the echo position of the next moment from the radar echo images of a few moments earlier, as well as ignoring the motion nonlinearity of small- and medium-scale convective system in the radar echoes under actual conditions; therefore, there are limitations of underutilization of historical radar data and short extrapolation time [
12].
Artificial-intelligence technology represented by deep learning with the ability to analyze, associate, remember, learn and infer uncertainty problems has made remarkable progress in the fields of image recognition [
13,
14,
15], image segmentation [
16,
17,
18], natural language processing [
19,
20,
21]. Unlike the traditional approach, deep-learning methods have the ability to learn from massive amounts of data, so as to mine the internal characteristics and physical laws of data. They are widely used to establish complex nonlinear models [
22].
In recent years, deep-learning technology has been introduced into meteorological nowcasting and achieved excellent application results. Precipitation nowcasting is a sequence prediction problem based on time and space [
23]. To achieve satisfactory results in extrapolation, it is necessary to fully consider the temporal features between continuous time images and the spatial motion features in the images at the same time, which is in-line with the basic characteristics of LSTM-RNN (long short-term memory-recurrent neural network) in deep-learning networks [
24]. Shi et al. [
25] proposed that LSTM cells with convolution layers make up RNN (ConvLSTM), which can extract spatial characteristics by convolution operation compared to the full connection used by a fully connected LSTM in transfer. As the first attempt of precipitation prediction based on deep learning, the accuracy of ConvLSTM in precipitation nowcasting is significantly improved compared with fully connected LSTM and optical flow methods. A tossed stone causes a thousand ripples; a large number of studies based on ConvLSTM have been proposed [
26]. Shi et al. continued to propose a TrajGRU model which can learn from optical flow [
27]. On the basis of inheriting the good sensitivity of a temporal convolution neural network to temporal and spatial characteristics, it can learn from the optical flow movement and simulate the real movement of clouds in nature to improve the performance of model extrapolation.
In the above RNN-based model, CNN (convolutional neural network) also plays an important role. CNN can effectively extract image features and map them on the label image [
28]. UNeT is a classic full convolution neural network structure which includes down sampling and up sampling [
29]. A subsequent improvement of UNet was also implemented to fill its hollow structure, connecting the semantic gap between encoder and decoder feature mappings. This nested UNet is called UNet++ [
30]. At present, a UNet-based model is mostly used in the field of image segmentation, mainly in the recognition and segmentation of medical images. Researchers view precipitation nowcasting as an image-to-image conversion problem and use UNet-based structured convolutional neural networks for forecasting purposes, which is a data-driven short-time precipitation nowcasting model that utilizes none of the atmospheric and physical models [
31]. Ayzel et al. proposed a precipitation prediction model based on UNet which is comparable to the traditional optical flow method [
32]. Nie et al. [
33] proposed SelfAtt-UNet based on the UNet network architecture. SelfAtt-UNet introduces a self-attention mechanism on top of UNet so that it can focus on tracking changes in the most influential regions of the radar echo.
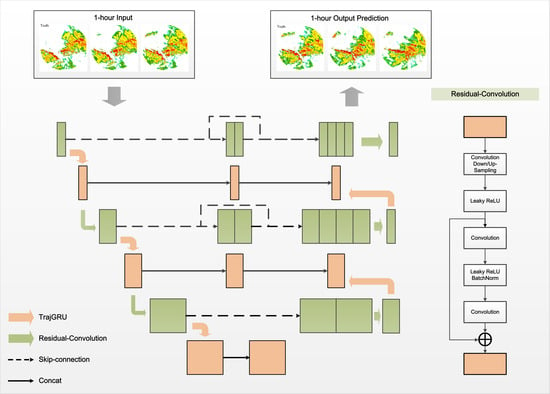
In this paper, a model combining CNN and RNN is proposed to better capture spatial and temporal features. The model is based on a UNet backbone with residual networks, with the addition of TrajGRU in each layer, constituting a new architecture, T-UNet. In addition, the nested dense skip connections are redesigned with the aim of reducing the semantic gap between the feature mappings of the encoder and decoder sub-networks to obtain extra spatio-temporal extraction capability for more accurate echo inference for precipitation nowcasting. The T-UNet model proposed in this paper is a new end-to-end deep network. Compared with other networks, T-UNet nests the recurrent structure of RNN in a complete convolutional network, while extending the ordinary convolution into a residual network. By combining the CNN structure with the RNN structure, the spatio-temporal features in continuous radar echo maps are better captured for more accurate prediction.
The organization of this article is as follows.
Section 2 provides a brief overview of the research on nowcasting of precipitation using CNN-based and RNN-based models. In
Section 3, the detailed structure of T-UNet is described.
Section 4 experimentally evaluates T-UNet against other models. Finally, a summary and concluding comments are presented in
Section 5.
2. Application of CNN-Based and RNN-Based Models in Precipitation Nowcasting
The basic idea of radar extrapolation for precipitation nowcasting is to track the movement of echoes based on radar observations, extrapolate the position of echoes at the future time, and invert the precipitation distribution in the future period through the Z–R relationship [
34].
Two types of deep-learning models that are mainly used for precipitation nowcasting are methods of predicting sequence values between sequences based on RNN and methods of extracting the main features of sequences based on CNN.
Both ConvLSTM and TrajGRU are RNN-based precipitation nowcasting models that have been proven to have excellent performance, in which the latter can better learn the structure and weights of location change, and based on GRU has lower memory requirements than LSTM, saving a lot of computing time [
35]. Wang et al. [
36] proposed a new end-to-end structure, PredRNN, which allows cross-layer interaction of cells belonging to different LSTMSs, and designed a new spatiotemporal LSTM (ST-LSTM) unit, which memorizes spatial and temporal characteristics in a single memory unit and transfers memory at the vertical and horizontal levels. In the test including the radar dataset, PredRNN achieves better prediction results than ConvLSTM. The E3d-LSTM model proposed by Wang et al. [
37] integrates 3D convolution into LSTM, changes the update gate of LSTM, and adds a self-attention module, which enables the network to have better recognition of the early activity of radar echoes, thus combining the two networks at a deeper mechanism level.
With its excellent spatial extraction ability, UNet is widely used as a backbone based on a full CNN model. Trebing et al. [
38] added attention modules to UNet and replaced traditional convolution with depthwise-separable convolution. The results after the radar echo extrapolation experiment show that the SmaAt-UNet proposed by the author can reduce the number of parameters to 1/4 of the original one at the expense of a small number of indicators. Since UNet has a flexible structure, Pan et al. [
39] proposed a new model named FURENet, using UNet as a backbone network, which met the purpose of inputting multivariable information. The polarimetric radar parameters
and
are input into the model to improve the accuracy of precipitation nowcasting.
Convolutional neural networks enable feature learning through image filters by treating the input grid weather elements as images, which sufficiently capture the spatial structure of the correlation, but lack the ability to handle sequential data and are only suitable for ‘fixed-length’ data. A recurrent neural network, which is often used in natural language processing, has an autoregressive structure that allows for flexible processing of sequential data and effective learning in the temporal dimension, with the disadvantage that, like the multilayer perceptron, the input features can only be characterized by a one-dimensional vector, thus losing the inherent spatial characteristics of the lattice data, and the learning ability is relatively poor. Combining the above two models in different forms, which can learn both spatial and temporal features, is more suitable for solving the problem of precipitation nowcasting. In the following, the specific construction of T-UNet combining CNN and RNN structures will be discussed, as well as its performance being verified on the dataset.
4. Dataset and Experiments Design
Quality-control information and details about this dataset are described at length in Fiolleau and Roca (2013b). The identifying and tracking algorithm used here is the tracking of an organized convection algorithm through the 3D segmentation (TOOCAN) approach (Fiolleau and Roca 2013a). The TOOCAN method can be seen as an extension of the detect-and-spread technique.
4.1. Dataset
The HKO-7 dataset, developed by the Hong Kong Observatory, provides radar constant altitude plan position indicator (CAPPI) reflectivity images updated every 6 min, at a covering area of 512 km × 512 km area with 2 km altitude centered in Hong Kong. The radar reflectivity factor is linearly converted to the pixel value of the image range from 0 to 255 using the following formula:
The radar echo image is based on reflectivity conversion, in which the value of the pixel points in the image corresponds to the radar echo intensity. The higher the reflectivity value, the stronger the radar echo intensity, and the larger the value of the corresponding pixel points, the higher the probability of precipitation. Due to the requirement of computational speed for the model, image resolutions of 480 × 480 in the original dataset are scaled to 256 × 256 by resampling regional pixels.
The HKO-7 dataset was selected for the period of January 2009 through December 2015, covering 993 precipitation events. A total of 812 of 993 days with precipitation were screened for training, 50 days for validation, and 131 days for testing. The radar reflectivity data can be converted to rainfall intensity values based on the Z–R relationship: , parameters a, b are calculated separately as 58.53 and 1.56 by linear regression. Based on the six thresholds [0, 0.5], [0.5, 2.0], [2.0, 5.0], [5.0, 10.0], [10.0, 30.0] and [30.0, ∞) of millimeter rainfall per hour, the 993-day precipitation is visualized as follows, where x stands for rainfall intensity values (mm/h):
As shown in
Figure 3, precipitation is unevenly distributed in the dataset, with slight precipitation accounting for 90 percent.
4.2. Experimental Design
The approach in the experiment is to predict the reflectivity in the next hour through the radar reflectivity echo map within one hour. As shown in
Figure 4, ten consecutive echo maps were fed into the model for training and testing, subsequently outputting ten successive frames of the future maps predicted by the model.
As for the loss function of the model, the weighted B-MSE and B-MAE functions proposed by Shi [
27] are used. Considering the uneven distribution of precipitation in the dataset, B-MSE and B-MAE are improved functions to increase the weight of the loss function for pixels with high precipitation on the basis of conventional MSE and MAE, respectively, which can improve the accuracy of the nowcasting of heavy precipitation and lead to more practical significance. The loss function is obtained by weighting the sum of B-MSE and B-MAE1:1 with the following equation:
The evaluation metric of forecast accuracy in meteorology mainly adopts the idea of binary classification. A confusion matrix is constructed based on the relationship between each grid point and the rain threshold value in the image, which includes TP (prediction = 1, truth = 1), FN (prediction = 0, truth = 1), FP (prediction = 1, truth = 0), and TN (prediction = 0, truth = 0). Five thresholds are mainly used, 0.5, 2, 5, 10, and 30, whose ranges represent light rain, light-to-moderate rain, moderate rain, moderate-to-heavy rain, and heavy rain. Using the above methods, the evaluation metric was defined as follows:
CSI reflects the relative accuracy of prediction; HSS can penalize false or missed alarm and give the expected score of 0 to random and constant predictions. CSI and HSS vary from 0 to 1. The higher their values, the better the predictive performance of the model [
41].
The optical-flow method, encoder-forecaster TrajGRU and SmaAt-UNet are adopted as baselines to evaluate the performance of T-UNet and other precipitation prediction models. In the training section, the batch size is set to 4, with a total of 100,000 iterations. The learning scheduler used is ReduceLROnPlateau, which reduces the learning rate to 50% when the loss of the validation set is no longer reduced for six consecutive iterations. The initial learning rate is set to 0.0001, kernel size is set to 3, and Adam is used as optimizer. All models and algorithms are implemented on Pytorch and run in NVIDIA Tesla P40 with 24 GB of RAM.
5. Results
After training the models, we selected the one with the lowest loss function in each model validation set for testing. The metrics used are described in
Section 4.2.
Table 1 presents the quantitative results of the final prediction results of each model under the regression evaluation metrics, while
Table 2 demonstrates the meteorological metric scores of each model under different precipitation thresholds. It can be seen that, among the various loss functions, the results of T-UNet are superior to the other models, proving its better predictive ability. The CSI and HSS scores of SmaAt-UNet show a substantial decline at thresholds greater than 5 mm/h and especially at thresholds greater than 30 mm/h, showing its poor prediction ability for heavy rainfall prediction, which is also reflected in the B-MSE and B-MAE. It is worth mentioning that the MSE and MAE of SmaAt-UNet do not deviate much compared with other models, indicating that the balanced loss function is more effective in reflecting the ability to predict heavy precipitation, consistent with the needs of practical applications. T-UNet performs best in both CSI and HSS scores with different thresholds, signifying that it maintains good details in both clear-rainy forecast and storm predictions, thus reflecting the actual conditions in the rain area.
In the experiment, ten consecutive radar echo maps are fed into the model to obtain the prediction results for the next 60 min; in other words, the historical 1 h data is used to predict the future 1 h echo data. Two representative cases were selected from the test set, and the extrapolation results of each model were further evaluated using visualization analysis and prediction metrics, so as to assess the accuracy of the extrapolation results of T-UNet.
The first case we selected happened from 4:12–6:12 UTC on 23 May 2015, which coincided with the issuance of a yellow rainstorm warning by the Hong Kong Observatory, when the radar captured the gradual merging of the squall line with the storm monomer to form a larger linear convective system. In
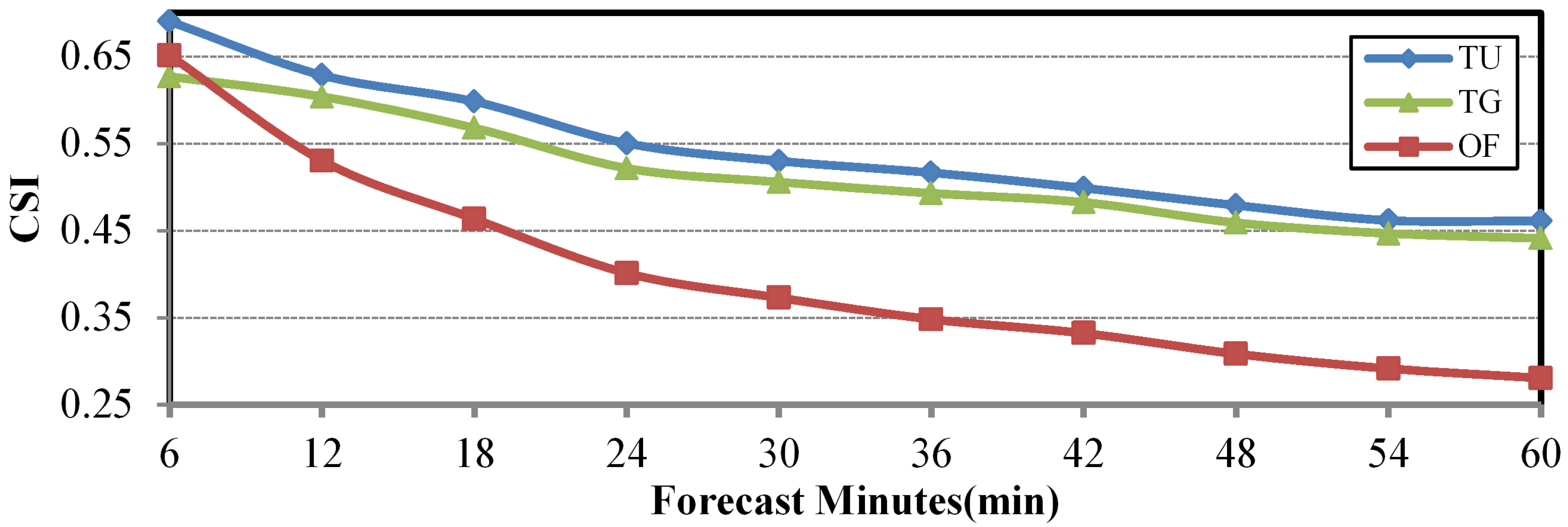
Figure 5, the ground truth used for the evaluation and the outputs of the four experiments, optical flow method (OF), SmaAt-UNet (SU), TrajGRU (TG) and T-UNet (TU), are shown in turn. For convenience of display, we present a radar echo map every 12 min. In OF, although the optical flow method maintains a high resolution, it is completely unable to predict the evolution of the squall line. It can be demonstrated that, in individual cases of rapidly changing thunderstorms, the optical-flow method is unable to predict the area where the strong echo region is located. The shape and intensity of the echoes in SU are barely satisfactory, and its premature conflation of squall lines with thunderstorm monoliths again loses considerable detail. It can be seen from the prediction plots of TG and TU that T-UNet retains some details in prediction. As shown in the black box, the contours of the strong echo region in the box plot are reflected in the TU. In addition, we selected the CSI and HSS scores of each model in forecast time for precipitation greater than 10 mm/h (the 10 mm/h threshold is commonly used to identify strong convection [
9]). SmaAt-UNet is not included in the figure due to its low performance in this section. As shown in
Figure 6, the CSI score of T-UNet gradually decreased from 0.69 to 0.46 as the prediction time increased, but the score remained higher than that of TrajGRU throughout the process, as the same was true for the HSS score. Among them, the mean CSI score of T-UNet improved by 5.17% and the mean HSS score improved by 3.92% compared to TrajGRU during this period.
Another case is shown in
Figure 7 which occurred at 5:36–7:36 UTC, 4 October 2015, when a super typhoon Mujigae made landfall near Zhanjiang City, Guangdong Province. Radar echo maps from the Hong Kong Observatory captured the evolution of the Mujigae’s outer rain belt. The Mujigae brings strong gale and cyclones which make the rain area more unpredictable, greatly enhancing the difficulty of precipitation nowcasting. As can be seen from
Figure 7, T-UNet and TrajGRU can predict the approximate location of the strong echoes more accurately in the first thirty minutes. After thirty minutes, both models lose some echo details, but compared to TrajGRU, T-UNet is still able to maintain the accuracy of predicting the strong echo region, as can be seen from the black box. Admittedly, as the prediction time increases, the prediction details are lost; that is, multiple echo regions are combined into one whole echo in the predicted image, causing the predicted echo intensity larger than the ground truth value, which needs to be improved in future experiments. From the perspective of quantitative assessment (see
Figure 8), none of the models involved in the experiment performed as well as Case 1 in Case 2, which was caused by the more rapid and irregular changes in the strong gale weather process. The CSI and HSS scores of T-UNet in the first 30 min did not widen the gap with TG, which became more sufficient in the last 30 min. Over the prediction time, the CSI and HSS of T-UNET decreased from 0.63 and 0.75 to 0.30 and 0.40, respectively, scoring consistently higher than TrajGRU during this process. In terms of average score, the CSI and HSS of T-UNet improved by 6.86% and 7.37%, respectively. Overall, the prediction performance of T-UNet within 60 min in case 2 is better than that of TrajGRU.
6. Conclusions
In this study, a novel radar echo extrapolation model based on CNN and RNN is proposed, named T-UNet. The model uses the UNet structure as a framework and redesigns the dense jump connections to reduce the semantic gap between feature mappings with different levels of upsampling and downsampling. TrajGRU is introduced into UNet for forming T-UNet to learn spatio-temporal features. In the experiments, the prediction results of T-UNet were compared with those of the CNN model SmaAt-UNet, the RNN model TrajGRU, and the dense optical-flow method on the HKO-7 dataset. The following main conclusions are obtained from the evaluation results:
Visual analysis results from two cases show that T-UNet can relatively effectively preserve the spatio-temporal characteristics of radar images in prediction; particularly, the details of strong echoes are closer to the ground truth.
The results obtained from the test set show that T-UNet improves by 9.6% and 7.05% in terms of B-MSE and B-MAE compared to TrajGRU, and similarly improve by 9.03% and 7.21% in terms of MSE and MAE. In addition, T-UNet performs better than TrajGRU at different thresholds for the common scoring functions CSI and HSS in meteorology, CSI has a maximum improvement by 10.57% at thresholds greater than 30 mm/h, and HSS also reaches a maximum improvement by 7.80% at thresholds greater than 30 mm/h. These numerical results show that T-UNet has higher accuracy than TrajGRU in the prediction of precipitation proximity and better ability in the prediction of strong echoes.
Although T-UNet improves the accuracy of precipitation nowcasting, like other deep-learning models, it also faces the situation that too much detail is lost in the late prediction stage, and the resolution cannot be maintained as the optical flow method, resulting in a significant decrease.
In future experiments, information from multiple input variables will be added to the model to make predictions, such as variables
V,
,
and
of polarimetric radar [
42]. These variables can provide additional critical microphysical and dynamic evolution information of convective storms and help to fully reflect the spatio-temporal characteristics of convective processes.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









