


A Convolutional Neural Network for Large-Scale Greenhouse Extraction from Satellite Images Considering Spatial Features
 , , , and
, , , and
Abstract
:1. Introduction
- We propose the spatial convolutional long short-term memory (Spatial ConvLSTM, SPCLSTM) structure. The learning ability of the network for the spatial continuity of the image feature surface is enhanced by the structure of convolutional long short-term memory (ConvLSTM).
- We introduce a multitask learning strategy in the network to compute auxiliary losses using the intermediate features extracted by the network, reducing the fuzziness of boundaries in greenhouse result extraction during training.
- We propose a superpixel optimization module (SOM) that can better obtain the boundary information of the greenhouse by iterating the features of the decoder using the superpixel segmentation network. Based on this module, the greenhouse extraction results with accurate boundary information can be obtained.
- We also perform large-scale greenhouse mapping from 2.38 m satellite imagery in Shandong Province, China.
2. Materials and Methods
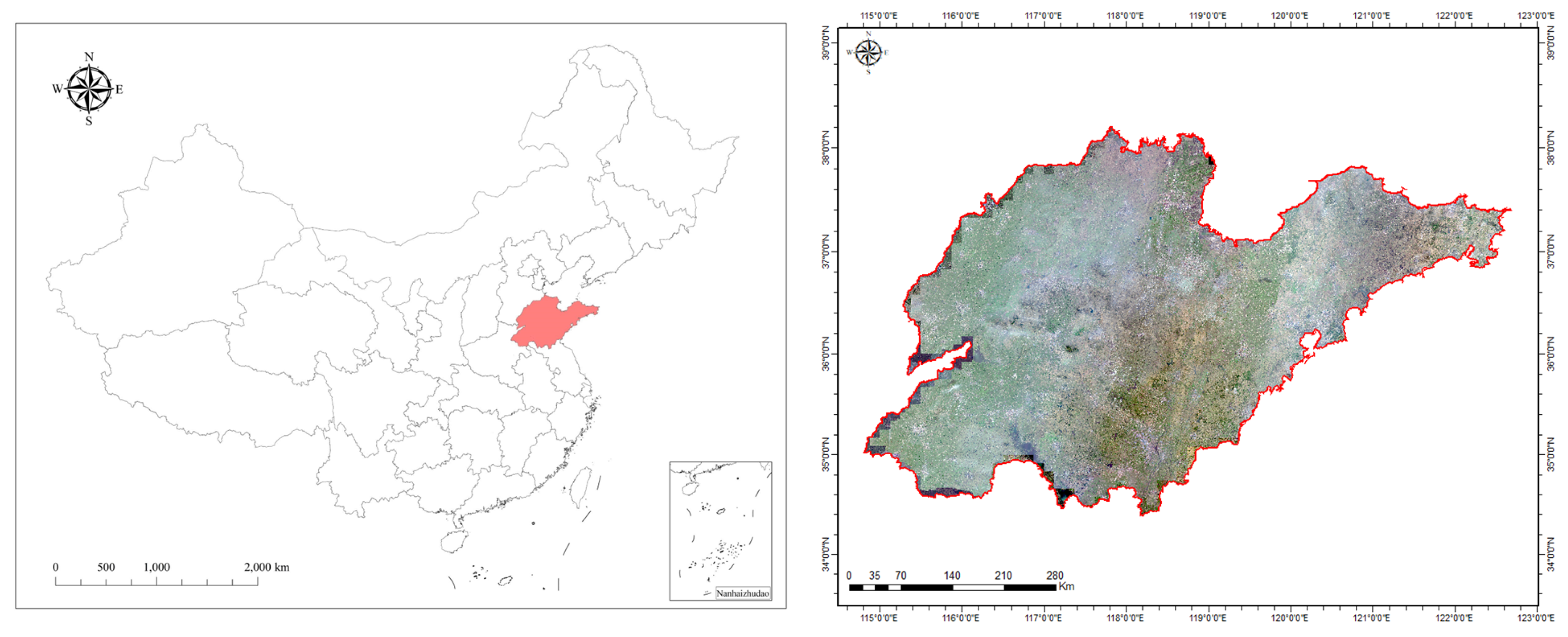
2.1. Study Area
2.2. Data Sets
2.3. Methods
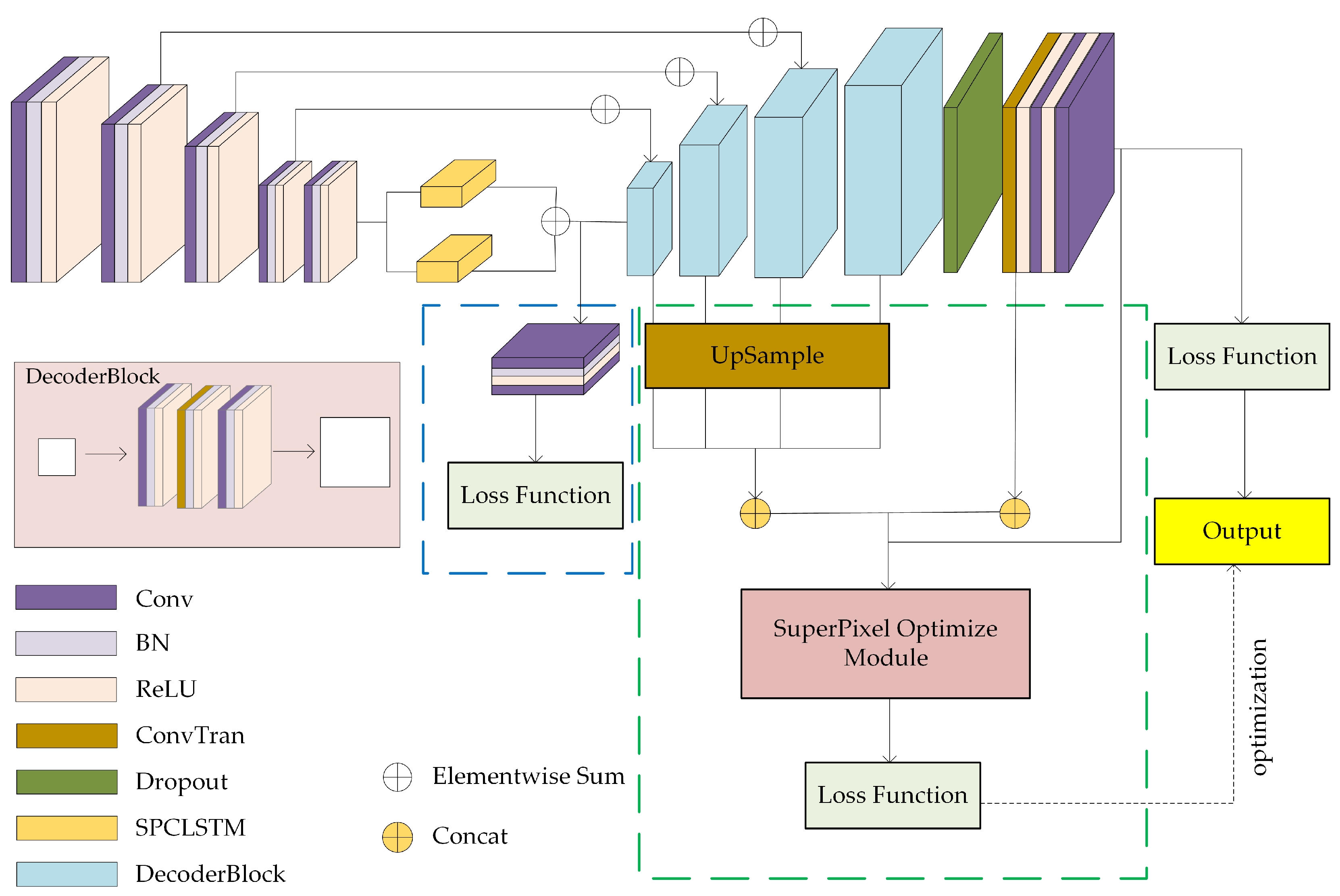
2.3.1. Network Architecture
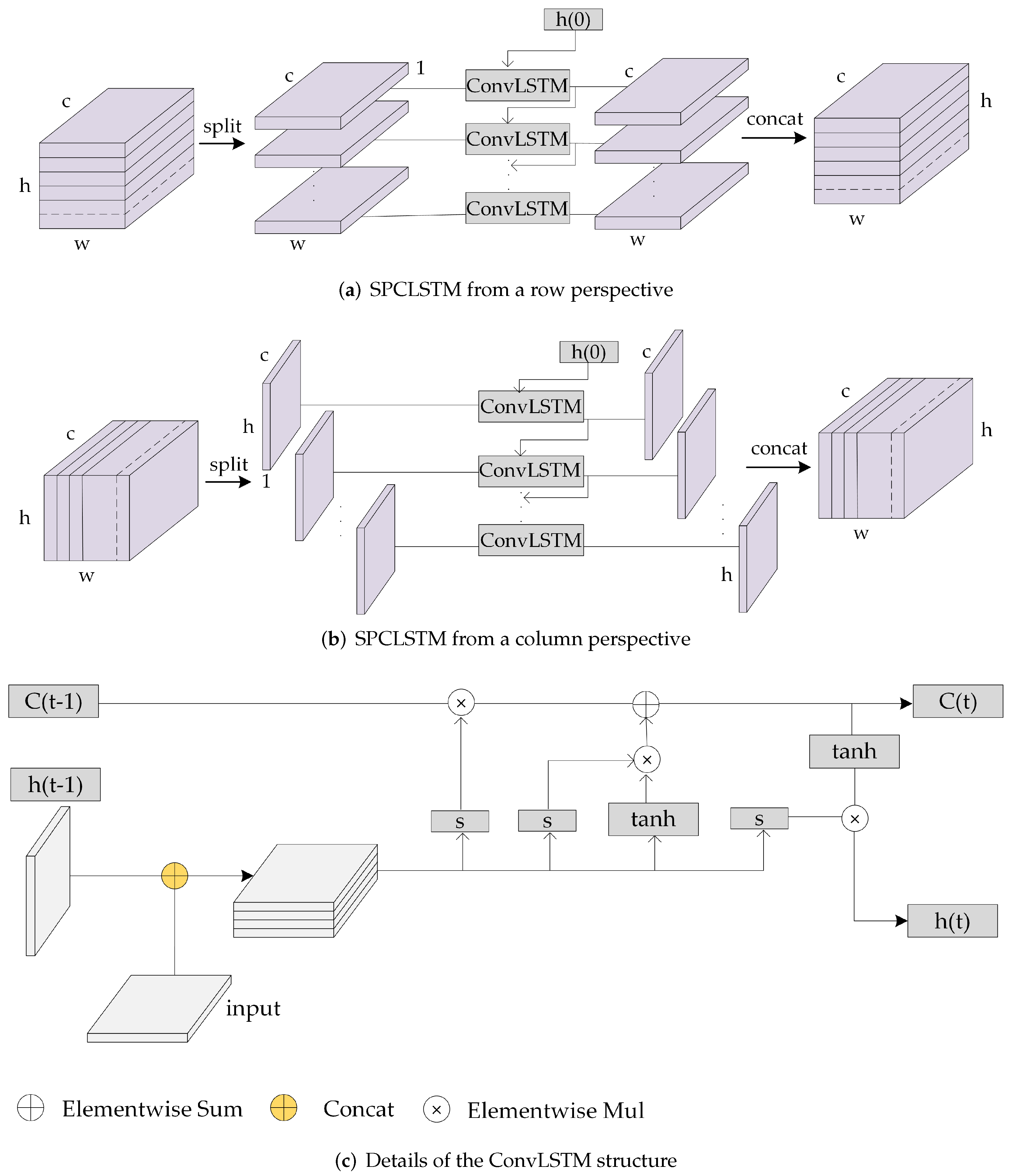
2.3.2. Spatial ConvLSTM
2.3.3. Multitask Learning
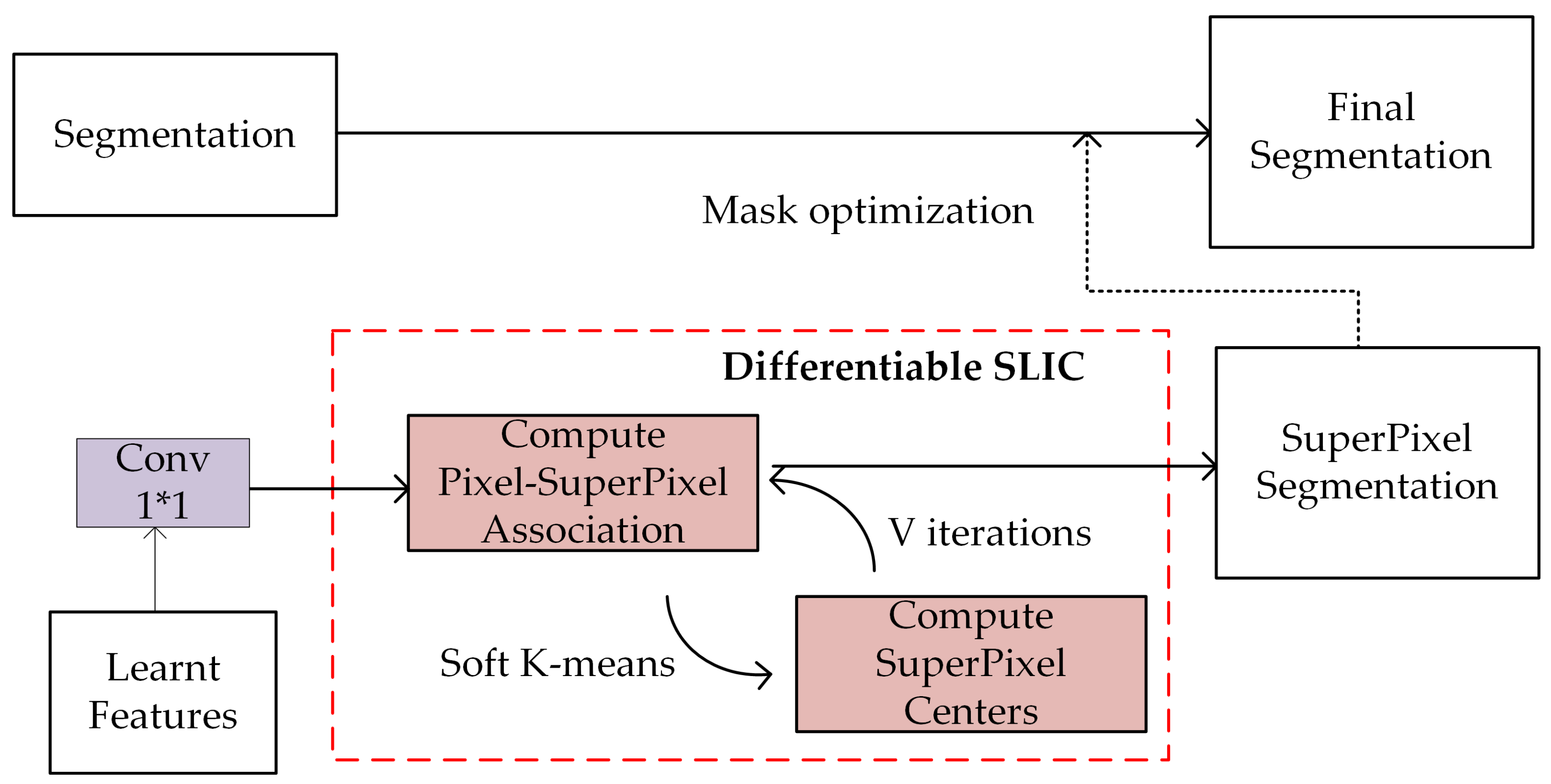
2.3.4. Superpixel Optimization
| Algorithm 1: Superpixel optimization module. |
 |
2.3.5. Loss Function
2.3.6. Evaluation Metrics
2.3.7. Train Details
3. Results
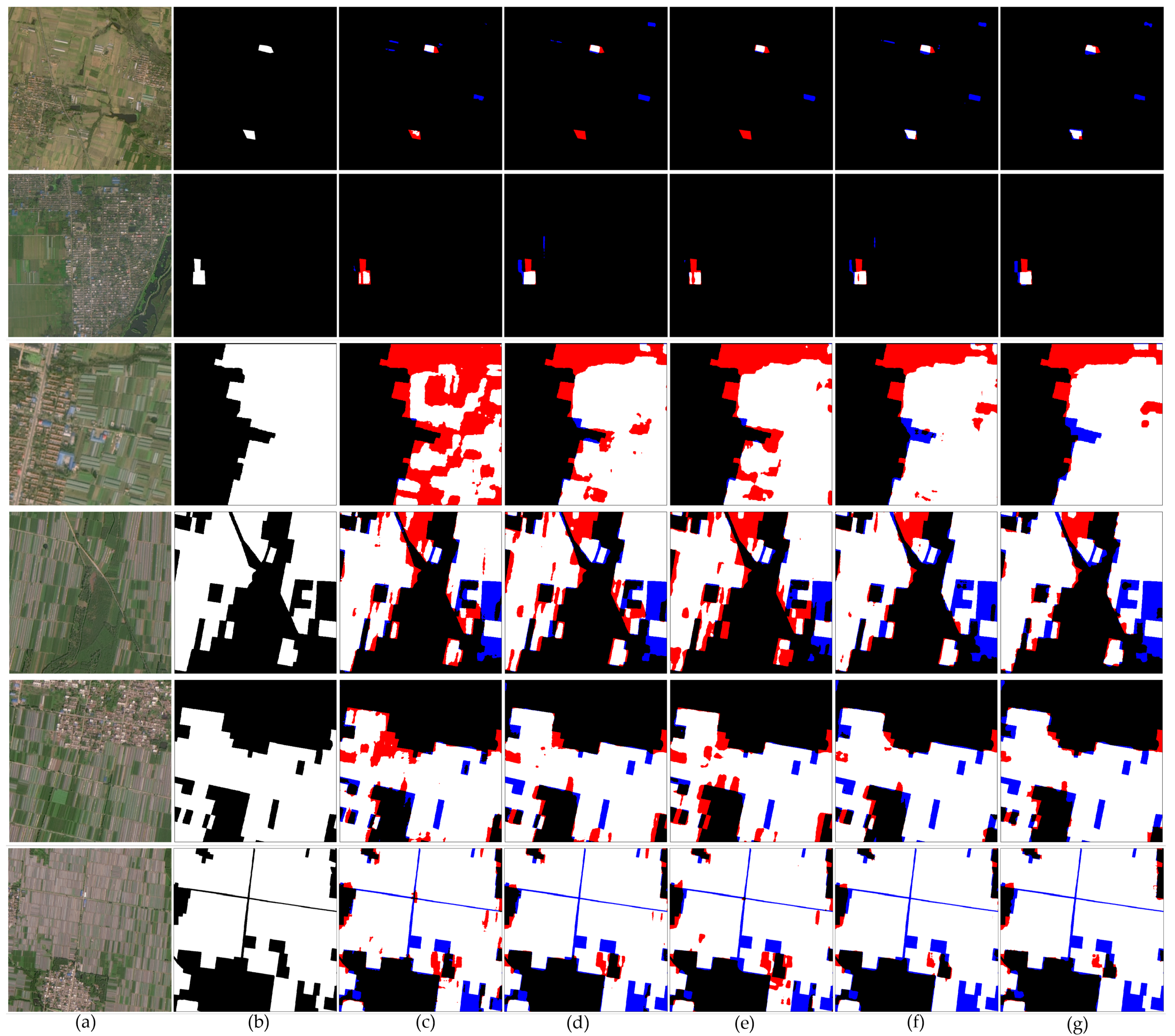
3.1. Ablation Study
3.1.1. Quantitative Comparisons
3.1.2. Visualization Results
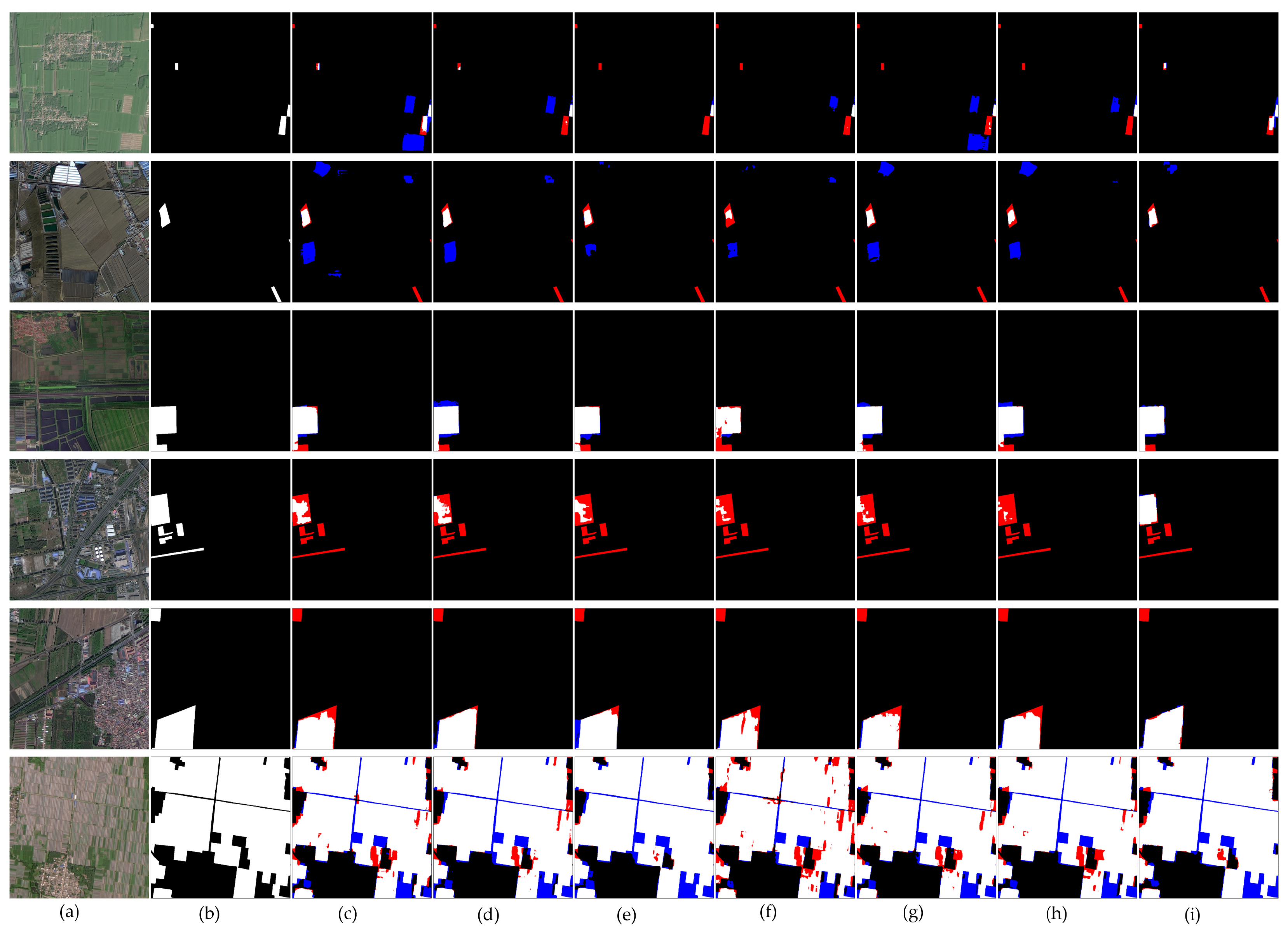
3.2. Comparing Methods
3.2.1. Quantitative Comparisons
3.2.2. Visualization Results
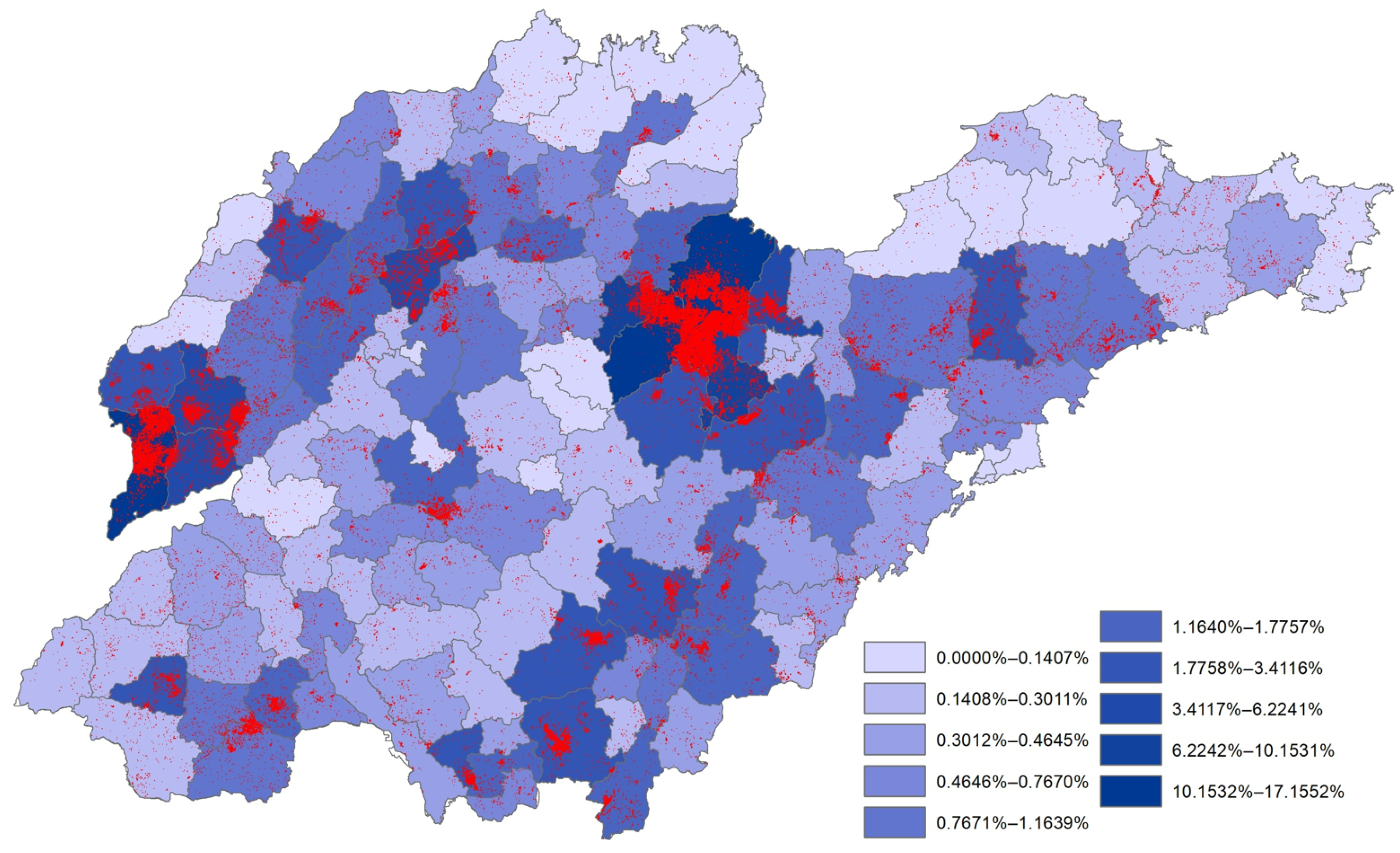
3.3. Large-Scale Greenhouse Mapping
4. Discussion
4.1. Numbers of SPCLSTM Layers
4.2. Applications
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BCE | binary cross entropy |
| CNN | convolutional neural network |
| ConvLST | convolutional long short-term memory |
| FCN | fully convolutional neural network |
| FN | false negative |
| FP | false positive |
| FPA | feature pyramid attention |
| GAU | global attention upsampling |
| IoU | intersection over union |
| LSAG | large-scale agricultural greenhouse |
| LSTM | long short-term memory |
| PAN | pyramid attention network |
| PSPNet | pyramid scene parsing network |
| ReLU | Rectified Linear Unit |
| RNN | recurrent neural network |
| SAR | synthetic aperture radar |
| SCNN | spatial convolutional neural network |
| SLIC | simple linear iterative clustering |
| SOM | superpixel optimization module |
| SPCLSTM | spatial convolutional long short-term memory |
| SSN | superpixel sampling network |
| TP | true positive |
| UAV | unmanned aerial systems |
References
- National Bureau of Statistics. Communiqué on Major Data of the Third National Agricultural Census (No. 2). Available online: http://www.stats.gov.cn/tjsj/tjgb/nypcgb/qgnypcgb/201712/t20171215_1563539.html (accessed on 29 June 2022).
- Sun, X.; Lai, P.; Wang, S.; Song, L.; Ma, M.; Han, X. Monitoring of Extreme Agricultural Drought of the Past 20 Years in Southwest China Using GLDAS Soil Moisture. Remote Sens. 2022, 14, 1323. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Pickens, A.H.; Tyukavina, A.; Hernandez-Serna, A.; Zalles, V.; Turubanova, S.; Kommareddy, I.; Stehman, S.V.; Song, X.P.; et al. Global land use extent and dispersion within natural land cover using Landsat data. Environ. Res. Lett. 2022, 17, 034050. [Google Scholar] [CrossRef]
- Xiang, M.; Deng, Q.; Duan, L.; Yang, J.; Wang, C.; Liu, J.; Liu, M. Dynamic monitoring and analysis of the earthquake Worst-hit area based on remote sensing. Alex. Eng. J. 2022, 61, 8691–8702. [Google Scholar] [CrossRef]
- Liu, G.; Li, J.; Nie, P. Tracking the history of urban expansion in Guangzhou (China) during 1665–2017: Evidence from historical maps and remote sensing images. Land Use Policy 2022, 112, 105773. [Google Scholar] [CrossRef]
- Zhao, G.-X.; Li, J.; Li, T.; Yue, Y.-D.; Warner, T. Utilizing landsat TM imagery to map greenhouses in Qingzhou, Shandong Province, China. Pedosphere 2004, 14, 363–369. [Google Scholar]
- Sekar, C.S.; Kankara, R.S.; Kalaivanan, P. Pixel-based classification techniques for automated shoreline extraction on open sandy coast using different optical satellite images. Arab. J. Geosci. 2022, 15, 1–19. [Google Scholar] [CrossRef]
- Lv, Z.; Yang, X.; Zhang, X.; Benediktsson, J.A. Object-Based Sorted-Histogram Similarity Measurement for Detecting Land Cover Change with VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Aguilar, M.A.; Jiménez-Lao, R.; Ladisa, C.; Aguilar, F.J.; Tarantino, E. Comparison of spectral indices extracted from Sentinel-2 images to map plastic covered greenhouses through an object-based approach. Gisci. Remote Sens. 2022, 59, 822–842. [Google Scholar] [CrossRef]
- Chen, Z.; Li, F. Mapping Plastic-Mulched Farmland with C-Band Full Polarization SAR Remote Sensing Data. Remote Sens. 2017, 9, 1264. [Google Scholar]
- Coslu, M.; Sonmez, N.; Koc-San, D. Object-based greenhouse classification from high resolution satellite imagery: A case study Antalya-Turkey. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, XLI-B7, 183–187. [Google Scholar]
- Aguilar, M.A.; Nemmaoui, A.; Novelli, A.; Aguilar, F.J.; García Lorca, A. Object-based greenhouse mapping using very high resolution satellite data and Landsat 8 time series. Remote Sens. 2016, 8, 513. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Sun, Y.; Han, J.; Chen, Z. Monitoring method for UAV image of greenhouse and plastic-mulched Landcover based on deep learning. Trans. Chin. Soc. Agric. Mach. 2018, 49, 133–140. [Google Scholar]
- Baghirli, O.; Ibrahimli, I.; Mammadzada, T. Greenhouse Segmentation on High-Resolution Optical Satellite Imagery Using Deep Learning Techniques. arXiv 2020, arXiv:2007.11222. [Google Scholar]
- Zhang, X.; Cheng, B.; Chen, J.; Liang, C. High-Resolution Boundary Refined Convolutional Neural Network for Automatic Agricultural Greenhouses Extraction from GaoFen-2 Satellite Imageries. Remote Sens. 2021, 13, 4237. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Sanur, Indonesia, 8–12 December 2021; pp. 802–810. [Google Scholar]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Bi-directional convlstm u-net with densley connected convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 406–415. [Google Scholar]
- Li, X.; Zhang, Z.; Lv, S.; Pan, M.; Ma, Q.; Yu, H. Road Extraction From High Spatial Resolution Remote Sensing Image Based on Multi-Task Key Point Constraints. IEEE Access 2021, 9, 95896–95910. [Google Scholar] [CrossRef]
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the Computer Vision, IEEE International Conference on IEEE Computer Society, Madison, WI, USA, 18–20 June 2003; p. 10. [Google Scholar]
- Chen, Z.; Guo, B.; Li, C.; Liu, H. Review on superpixel generation algorithms based on clustering. In Proceedings of the IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 27–29 September 2020; pp. 532–537. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Jampani, V.; Sun, D.; Liu, M.Y.; Yang, M.H.; Kautz, J. Superpixel sampling networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 352–368. [Google Scholar]
- Chen, L.; Letu, H.; Fan, M.; Shang, H.; Tao, J.; Wu, L.; Zhang, Y.; Yu, C.; Gu, J.; Zhang, N.; et al. An Introduction to the Chinese High-Resolution Earth Observation System: Gaofen-17 Civilian Satellites. J. Remote Sens. 2022, 2022, 9769536. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. Bt-roadnet: A boundary and topologically-aware neural network for road extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 182–186. [Google Scholar]
- Good, I.J. Rational Decisions. J. R. Stat. Soc. Ser. B Methodol. 1952, 14, 107–114. [Google Scholar] [CrossRef]
- Sheikh, M.A.A.; Maity, T.; Kole, A. IRU-Net: An Efficient End-to-End Network for Automatic Building Extraction From Remote Sensing Images. IEEE Access 2022, 10, 37811–37828. [Google Scholar] [CrossRef]
- Chen, P.; Zhang, B.; Hong, D.; Chen, Z.; Yang, X.; Li, B. FCCDN: Feature constraint network for VHR image change detection. ISPRS J. Photogramm. Remote Sens. 2022, 187, 101–119. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning. PMLR, Paris, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | GF-1 |
|---|---|
| Rail type | Sun synchronous regression orbit |
| Orbital altitude (km) | 645 |
| Orbit inclination () | 98.05 |
| Local time (descending) | 10:30 a.m. |
| Side swing ability (rolling) | ±25, motor time of 25≤ 200 s, ability of emergency side swing roll ±35 |
| Parameter | Panchromatic (PAN)/Multispectral Camera (MS) | Multispectral Camera (MS) | |
|---|---|---|---|
| Spectral range (µm) | PAN | 0.45~0.90 | |
| MS | 0.45~0.52 | 0.45~0.52 | |
| 0.45~0.52 | 0.45~0.52 | ||
| 0.45~0.52 | 0.45~0.52 | ||
| 0.45~0.52 | 0.45~0.52 | ||
| Spatial resolution (m) | PAN | 2 m | 16 m |
| MS | 8 m | ||
| Swath width (km) | 60 | 800 | |
| Revisit cycle (side-sway)/day | 4 | ||
| Covering the period (no side swing)/day | 41 | 4 | |
| Module | Metrics (%) | ||||||
|---|---|---|---|---|---|---|---|
| Baseline | SPCLSTM | Multitask | SOM | Precision | Recall | F1 | IoU |
| √ | 74.87 | 74.96 | 74.92 | 59.89 | |||
| √ | √ | 77.49 | 77.31 | 77.40 | 63.13 | ||
| √ | √ | 78.86 | 73.40 | 76.03 | 61.34 | ||
| √ | √ | √ | 77.44 | 78.21 | 77.83 | 63.70 | |
| √ | √ | √ | √ | 78.82 | 79.52 | 78.66 | 64.83 |
| Method | Params (M) | Train Time (s) | Test Time (s) | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|---|---|---|
| UNet | 286 | 745 | 137 | 74.87 | 74.96 | 74.92 | 59.89 |
| PAN | 251 | 683 | 126 | 79.90 | 62.83 | 70.34 | 54.25 |
| DeepLabV3+ | 175 | 607 | 118 | 79.35 | 67.19 | 72.77 | 57.19 |
| UNet++ | 305 | 1020 | 223 | 82.02 | 64.53 | 72.23 | 56.53 |
| HRNet | 460 | 1528 | 378 | 83.14 | 67.84 | 74.71 | 59.63 |
| AFNet | 810 | 2104 | 583 | 80.26 | 72.08 | 75.95 | 61.22 |
| Ours | 290 | 816 | 162 | 78.82 | 79.52 | 78.66 | 64.83 |
| SPSLSTM Num | Params(M) | Train Time(s) | Test Time (s) | Precision (%) | Recall (%) | F1 Score (%) | IoU (%) |
|---|---|---|---|---|---|---|---|
| 1 | 84.8 | 340 | 68 | 75.51 | 78.85 | 77.14 | 62.59 |
| 2 | 84.8 | 392 | 75 | 77.49 | 77.31 | 77.40 | 63.13 |
| 3 | 84.8 | 447 | 87 | 77.64 | 77.10 | 77.37 | 63.01 |
| 4 | 84.8 | 510 | 98 | 77.16 | 77.64 | 77.40 | 62.92 |
| 5 | 84.8 | 576 | 107 | 78.24 | 76.48 | 77.35 | 62.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Wu, Z.; Gao, J.; Cai, M.; Yang, X.; Chen, P.; Li, Q. A Convolutional Neural Network for Large-Scale Greenhouse Extraction from Satellite Images Considering Spatial Features. Remote Sens. 2022, 14, 4908. https://doi.org/10.3390/rs14194908
Chen Z, Wu Z, Gao J, Cai M, Yang X, Chen P, Li Q. A Convolutional Neural Network for Large-Scale Greenhouse Extraction from Satellite Images Considering Spatial Features. Remote Sensing. 2022; 14(19):4908. https://doi.org/10.3390/rs14194908
Chicago/Turabian StyleChen, Zhengchao, Zhaoming Wu, Jixi Gao, Mingyong Cai, Xuan Yang, Pan Chen, and Qingting Li. 2022. "A Convolutional Neural Network for Large-Scale Greenhouse Extraction from Satellite Images Considering Spatial Features" Remote Sensing 14, no. 19: 4908. https://doi.org/10.3390/rs14194908