1. Introduction
Nowadays, various satellite constellations with shorter revisit periods and wider observation coverage have formed the global earth observation system which can quickly obtain huge amounts of high-spatial-resolution, high-temporal-resolution, and high-spectral-resolution remote sensing imagery [
1]. For example, China has 30 to 50 high-resolution remote sensing satellites in orbit, and by a conservative estimation, several hundred TB of data are acquired every day [
2]. However, with regard to the acquisition speed, the rapid intelligent processing of remote sensing data still lags [
3,
4]. In the new era of artificial intelligence, how to realize instant perception and cognition of remote sensing imagery has become an urgent problem to be solved.
Land cover classification is a multiclass segmentation task to classify each pixel into a certain natural or human-made category of the earth’s surface, such as water, soil, natural vegetation, crops, and human infrastructure. The land cover and its change influence the ecosystem, human health, social development, and economic growth. The last several decades of years have witnessed the improvement of the spatial resolution of remote sensing imagery from 30 m to submeter. With richer details and structural information of objects emerging in remote sensing imagery, land cover classification methods have shifted from discriminating the spectral or spectral–spatial information of local pixels to extracting contextual information and spatial relationship of ground objects [
5]. Among them, deep neural networks (DNN) have been widely used for their strong feature extraction and high-level semantic modeling ability. However, a large computational resource consumption brings slow inference speeds and restricts the practical application of DNN in remote sensing imagery. Meanwhile, the incapability of processing large-size image patches causes the cropping size to be too small, and the resulting loss of long-range context information is detrimental to prediction accuracy.
To obtain a high accuracy, conventional semantic segmentation networks, such as UNet [
6], FC-DenseNet [
7], and DeepLabv3+ [
8], usually adopt a wide and deep backbone as an encoder at the cost of a large computational complexity and memory occupation. In the task of land-cover classification, limited by GPU memory capacity, most existing studies preprocess the original remote sensing images by downsampling or cropping them into small patches less than 512 × 512 pixels before sending them to a deep neural network. For example, CFAMNet [
9] proposed a class feature attention mechanism fused with an improved Deeplabv3+ network. To avoid memory overflow, 150 remote sensing images of 7200 × 6800 pixels were cropped into 20,776 images of 128 × 128 pixels. DEANet [
10] used a dual-branch encoder structure that depended on VGGNet [
11] or ResNet [
12]; in the experiments, each image with a resolution of 2448 × 2448 pixels was compressed to half the size and then divided into subimages with a resolution of 512 × 512 pixels. DISNet [
13] integrated the dual attention mechanism module, including the spatial attention mechanism and channel attention mechanism, into the Deeplabv3+ network. In the experiments, the original images were also cropped into small patches of 512 × 512 pixels before being sent into the network.
However, it takes decades of efforts to improve the spatial resolution of remote sensing imagery, and downsampling reverses this progress and incurs a spatial detail loss. The rich details of objects, such as the geometrical shape and structural content of objects, are blurred by downsampling. It renders small segments hard to discriminate, thus offsetting the gain enabled by the large backbone.
On the other hand, cropping the original images into small patches less than or equal to 512 × 512 pixels causes a loss of long-range context information and leads to misjudgments. As shown in
Figure 1, a remote sensing image with a resolution of 2048 × 1536 pixels is cropped into 12 small patches with a resolution of 512 × 512 pixels. If one views the whole original image, it is clear that the water surface is a lake; however, if one views the individual small patches, the water surface may be misjudged as a river. Therefore, compared with images in other domains, such as street view images in the autonomous driving field, the support of large-size image input is more important for the correct semantic segmentation of remote sensing images (in
Section 4.4.1, we investigate the influence of the input image size on prediction accuracy, and demonstrate that the loss of long-range context information caused by a small cropping size would create a misjudgment and yield a lower accuracy). Another drawback of cropping is that cropping the images and restoring the predicted results to their original size incur extra latency. Hence, aimed at the characteristics of top view high-resolution remote sensing imagery, it is necessary to redesign the architecture of semantic segmentation networks to support large-size image patches.
As presented in
Figure 1, the abundant small segments, rich boundaries, and small interclass variance in remote sensing images are all likely to cause semantic ambiguity near the boundaries and small segments. Meanwhile, the areas where multiple land-cover categories exist contain richer information and are more prone to be misjudged. In the other aspect, the number of interior pixels grows quadratically with segment size and can far exceed the number of boundary pixels, which only grows linearly. However, the ground truth masks and conventional loss functions value all pixels equally and are less sensitive to boundary quality. Hence, it is necessary to capture category impurity areas and implement an effective measure to reinject boundary information into the semantic segmentation network.
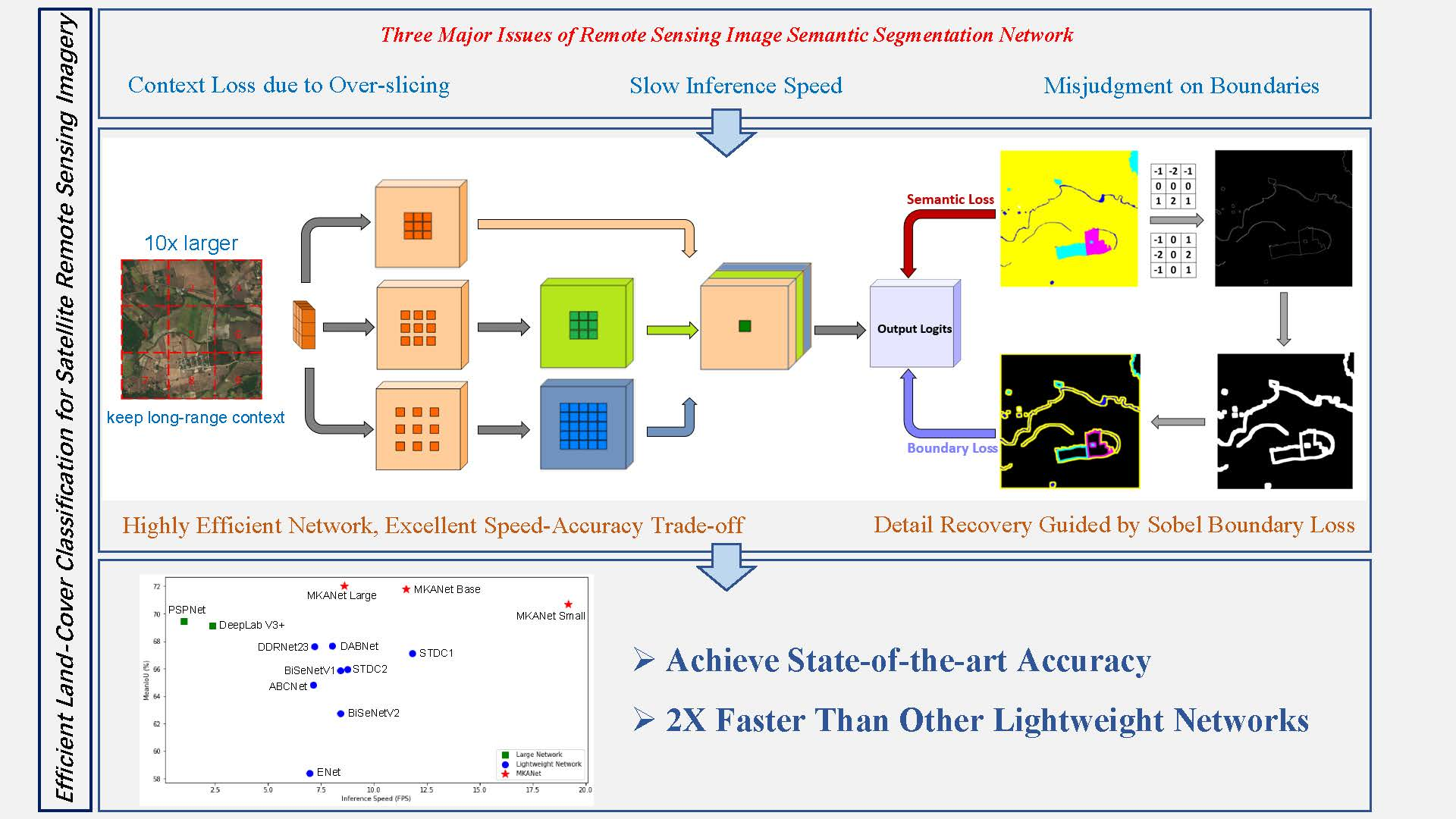
In summary, the slow inference speed, incapability of processing large-size image patches, and easy misjudgment of boundaries and small segments are three factors that restrict the practical applications of semantic segmentation networks. To alleviate these three problems, we present an efficient lightweight semantic segmentation network termed Multibranch Kernel-sharing Atrous convolution network (MKANet) and propose the Sobel Boundary Loss for efficient and accurate land-cover classification of remote sensing imagery. MKANet acquires state-of-the-art accuracy on two land-cover classification datasets and infers 2× faster than other competitive lightweight networks (
Figure 2). The contributions of this paper can be summarized in three aspects:
- 1
Aimed at the characteristics of top view remote sensing imagery, we handcraft the Multibranch Kernel-sharing Atrous (MKA) convolution module for multiscale feature extraction;
- 2
For large input image size support and a fast inference speed, we design a shallow semantic segmentation network (MKANet) based on MKA modules;
- 3
For an accurate prediction of boundaries and small segments, we propose a novel boundary loss named Sobel Boundary Loss.
3. Proposed Method
In this section, we first introduce the MKA module which constitutes the backbone of the network; then, we show the network architecture that infers 2× faster than other competitive lightweight networks; at last, we present the Sobel Boundary Loss that helps boundary recovery and improves small segment discrimination.
3.1. Multibranch Kernel-Sharing Atrous Convolution Module
Conventional networks usually accumulate contextual information over large receptive fields by stacking a series of convolutional layers, so they have deep network architectures that consist of dozens of layers. Some networks even have more than one hundred layers, for example, FC-DenseNet [
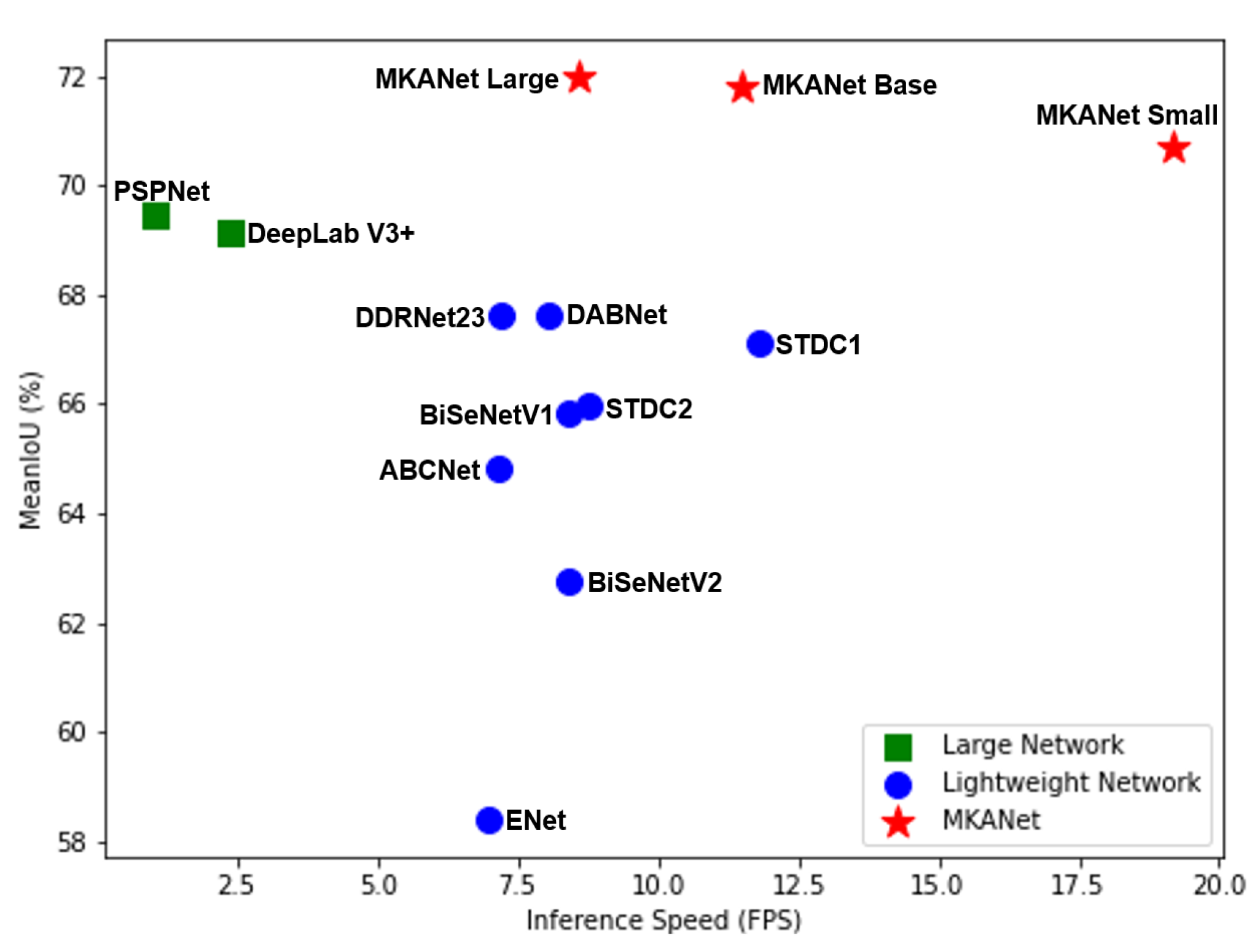
7]. However, one of the costs of building a deep architecture is slow inference speed. For a high efficiency and fast inference speed, we designed the Multibranch Kernel-sharing Atrous (MKA) convolution module, as illustrated in
Figure 3. Its parallel structure and kernel sharing mechanism can simultaneously capture a wider range of contexts for large segments and local detailed information for small segments and boundaries. Specifically, the receptive field of a typical three-branch MKA module equals that of five
convolutional layers connected in series. Different from ASPP or KSAC which can only be applied once as the last part of a backbone, MKA modules can be stacked in series as the backbone for semantic segmentation networks. Hence, with MKA modules, it is no longer necessary to build a deep network architecture. Meanwhile, the computation cost of an MKA module is inexpensive, and along with its parallel structure, the MKA module can greatly boost inference speed.
The MKA module consists of three parts:
Multibranch kernel-sharing depthwise atrous convolutions;
Multibranch depthwise convolutions;
Concatenation and pointwise convolution.
3.1.1. Part 1: Multibranch Kernel-Sharing Depthwise Atrous Convolutions
Assume that the number of channels of the input and output features is N and that the number of branches is M. One kernel is shared by the M depthwise atrous convolutions with dilation rates of 1, 2, …, and M. Next, a batch normalization is applied in each branch.
Compared with KSAC [
22], the MKA module abandons the
convolutional branch and the global average pooling branch. The dilation rates also decrease from (6, 12, 18) to (1, 2, 3). To further reduce the computation complexity and memory occupation, regular atrous convolutions are replaced by depthwise atrous convolutions, decreasing the kernel parameters, computation cost, and memory footprint to
.
This design inherits the merits of the kernel-sharing mechanism. The generalization ability of the shared kernels is enhanced by learning both the local detailed features of small segments and the global semantic features of large segments. The kernel-sharing mechanism can also be considered a feature augmentation performed inside the network, which is complementary to the data augmentation performed in the preprocessing stage, to enhance the representation ability of kernels.
3.1.2. Part 2: Multibranch Depthwise Convolutions
Since atrous convolution introduces zeros in the convolutional kernel, within a kernel of size , the actual pixels that participate in the computation are just , with a gap of between them. Hence, a kernel only views the feature map in a checkerboard fashion and loses a large portion of information. Furthermore, the adjacent points of its output feature map do not have any common pixels participating in the computation, thereby causing the output feature map to be unsmooth. This gridding artifact issue is exacerbated when atrous convolutions are stacked layer by layer. To alleviate this detrimental effect, for the ith branch (), a depthwise regular convolution with kernel size () is added, followed by a batch normalization. Note that an atrous convolution with a dilation rate of 1 is just a regular convolution; thus, for the first branch, nothing is added. Again, depthwise convolutions are applied here to reduce computation and memory costs. With the exception of smoothing the output feature maps of the preceding part, these depthwise convolutions can further extract useful information.
3.1.3. Part 3: Concatenation and Pointwise Convolution
After the second part, the output features of each branch are concatenated, and then a convolution is applied to the fused features. This part has two functions: generating new features through linear combinations and compressing the number of channels of the fused features from to N to reduce the computational complexity of the next module.
3.1.4. Complexity Analysis
The number of parameters in the first part is ; in the second part, it is ; and in the third part, it is . The number of branches M is suggested to be 3, which is substantially less than the number of channels N. Hence, the total parameters of the MKA module are approximately , which is even less than the parameters of one regular convolution.
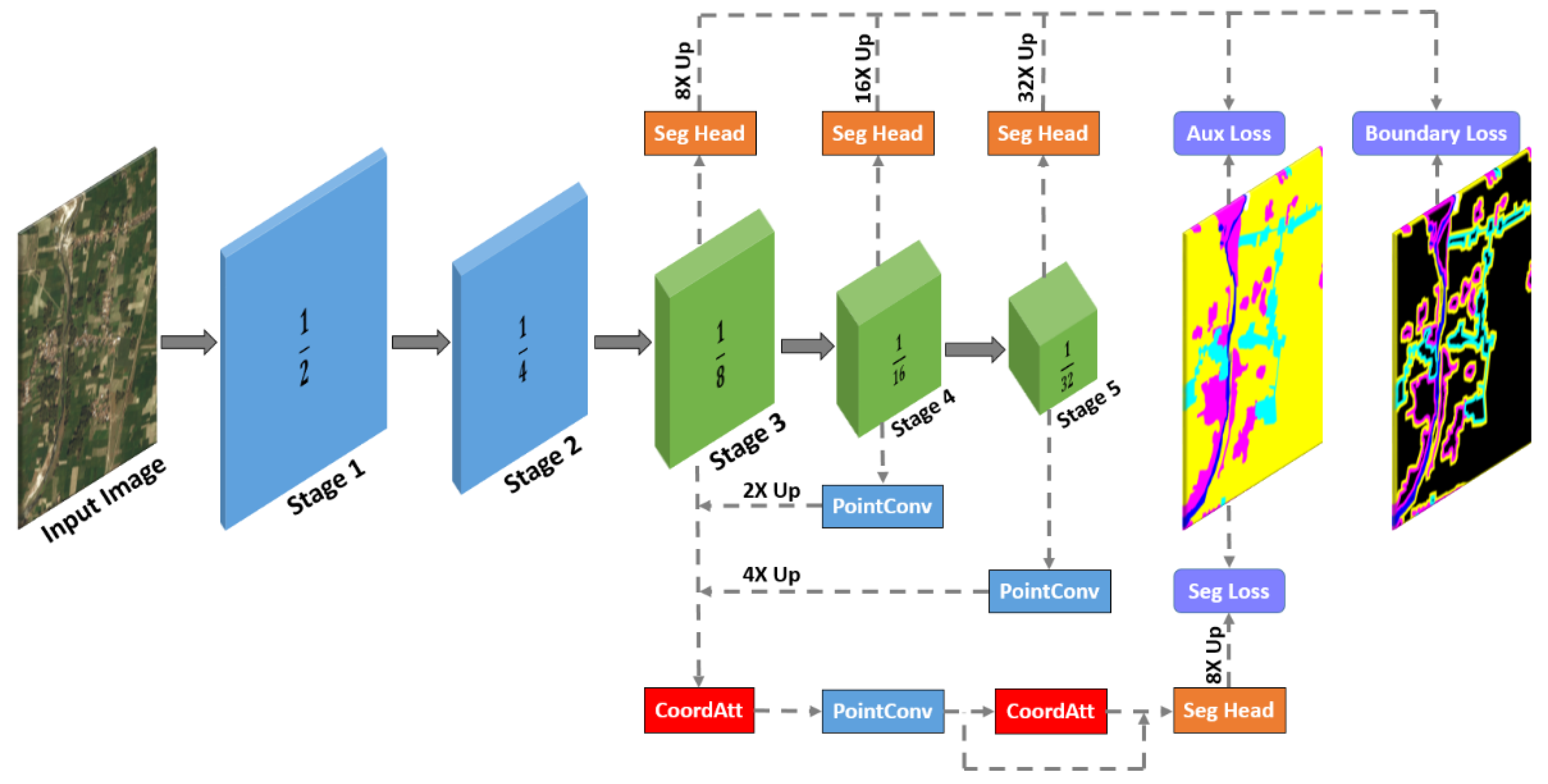
3.2. Network Architecture
For a faster inference speed and small memory occupation, based on MKA modules, we designed a lightweight semantic segmentation network named MKANet, as illustrated in
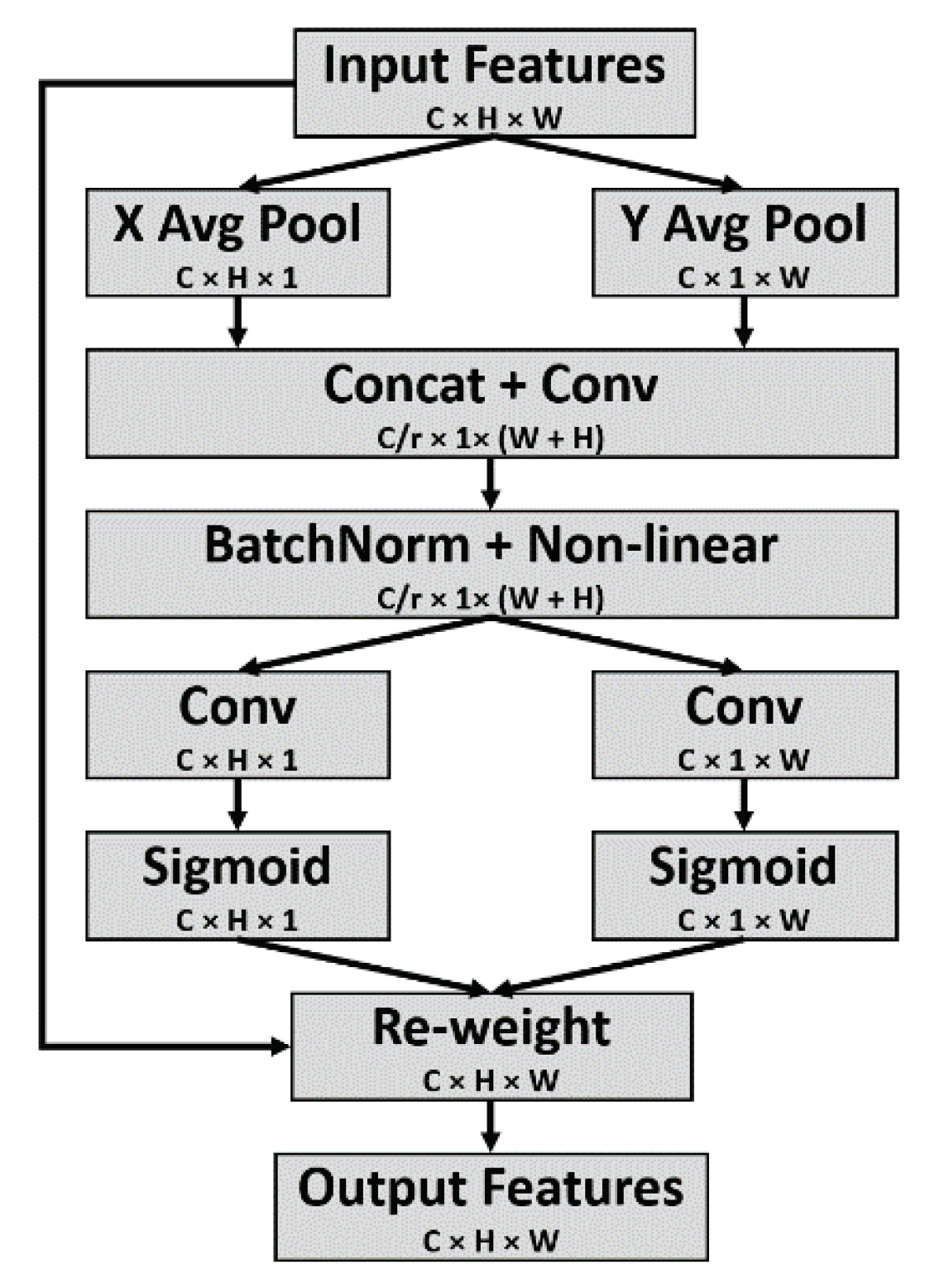
Figure 4. Attributed to the large receptive field of MKA modules, the network architecture of MKANet is very shallow. It consists of two initial convolutional layers and three MKA modules as the encoder and two coordinate attention modules (CAMs) [
24] as the decoder to fuse multiscale feature maps from different stages. By horizontal and vertical extent pooling kernels, CAMs can capture long-range dependencies along one spatial direction and preserve precise positional information along the other spatial direction, thus more accurately augmenting the representations of the objects of interest in the fused feature maps.
As presented in
Section 4.2, this shallow but effective architecture makes MKANet capable of supporting an input image size more than 10 times larger than that supported by conventional networks. Furthermore, compared with other competitive lightweight networks, the inference speed of MKANet is twice as fast.
3.2.1. Encoder
The encoder of MKANet has five stages, with each stage downsizing the feature maps by 2×. Its structure is detailed in
Table 1.
Each stage begins with a convolution of stride 2, followed by a batch normalization and ReLU activation. MKA modules are then repeated r times in each stage until stage 3. r controls the depth, while c controls the width of the backbone. MKANet has 3 typical sizes: Small (), Base () and Large ().
3.2.2. Decoder
The purpose of the first two stages is to extract simple, low-level features and to quickly downsize the resolution to reduce computations. Hence, the decoder only collects the deep context feature representations extracted by the MKA modules in stages 3 to 5.
To fuse multiscale feature maps, certain efficient networks, such as BiSeNet V1 [
15] and STDC [
25], use squeeze-and-excitation (SE) attention [
26] to transform a feature tensor to a single feature vector via 2D global pooling and rescale the feature maps to selectively strengthen the important feature maps and to weaken the useless feature maps. Although SE attention can raise the representation power of a network at a low computational cost, it only encodes interchannel information without embedding position-sensitive information, which may help locate the objects of interest. To embed positional information into channel attention, Hou et al. proposed the coordinate attention module (CAM), which utilizes two 1D global pooling operations to aggregate features along the horizontal and vertical directions so that the two generated, direction-aware feature maps can capture long-range dependency along one spatial direction and preserve precise positional information along the other spatial direction. The detailed structure of the CAM is shown in
Figure 5.
To tell the network “what” and “where” to attend, two CAMs are employed to fuse the multiscale feature maps output by stages 3 to 5. Specifically, the feature maps output by stage 4 and stage 5 are compressed from and , respectively, to in the channel by pointwise convolution, upsampled by 2× and 4×, respectively, and concatenated with the feature maps output by stage 3. After the feature maps are put through the first CAM to derive a combination of features with enhanced representation, a pointwise convolution is employed to promote the communication of information among the channels and to further compress the number of channels from to . The compressed feature maps pass the second CAM with the residual connection.
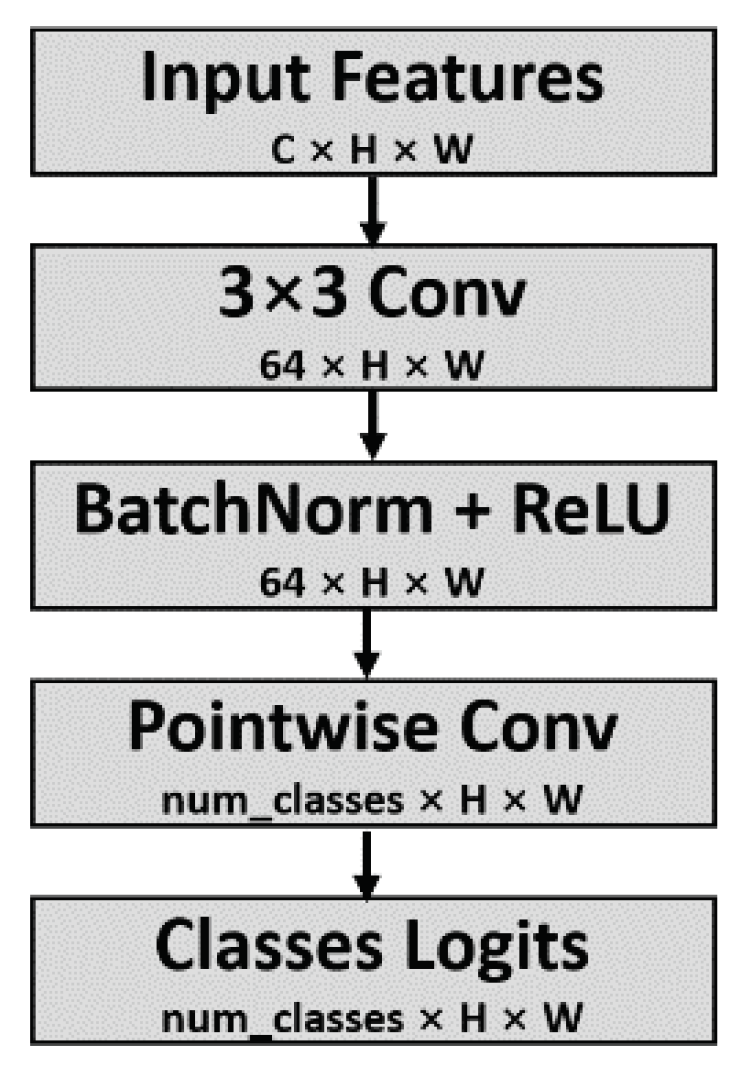
3.3. Semantic Segmentation Losses
The semantic segmentation head, as illustrated in
Figure 6, converts the output feature maps of the decoder into class logits, which are then upsampled by 8× to restore them to the same resolution as the input image. The upsampled class logits are compared with the ground truth by the main semantic segmentation loss function.
To enhance the feature extraction ability of the MKA modules, three auxiliary semantic segmentation heads are added on top of the output features of stage 3 to stage 5 in the training phase. In the inference phase, the three auxiliary heads are discarded, without additional computational cost. The output class logits of the three auxiliary semantic segmentation heads are upsampled 8×, 16×, and 32× before being sent to three auxiliary semantic segmentation loss functions and three boundary loss functions.
3.4. Sobel Boundary Loss
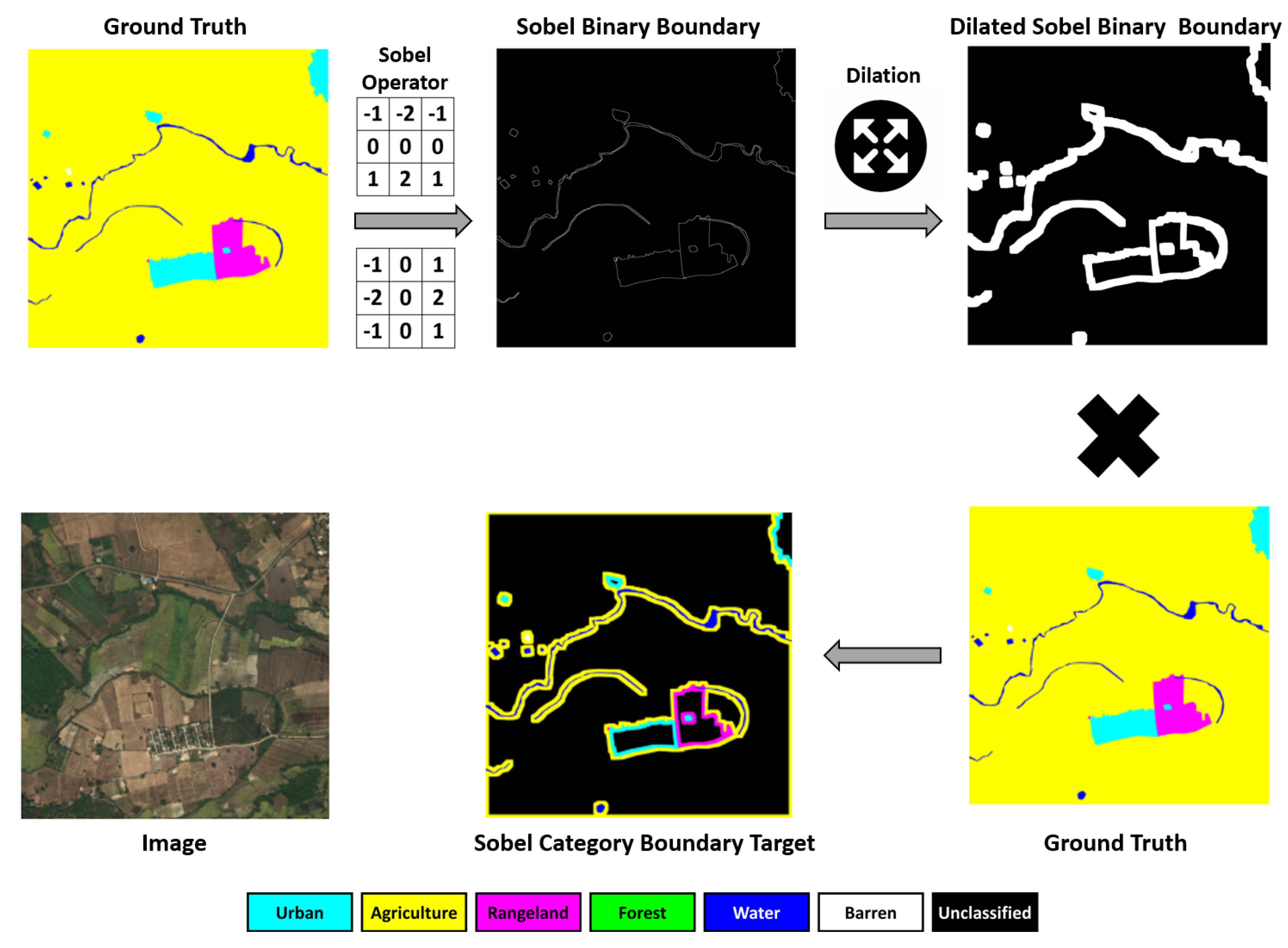
The Sobel operator is a discrete differentiation gradient-based operator that computes the gradient approximation of the image intensity for edge detection. It employs two 3 × 3 kernels to convolve with the input image to calculate the vertical and horizontal derivative approximations, respectively.
To strengthen spatial detail learning and boundary recovery, Sobel operator convolution and dilation operation are performed on the ground truth mask to generate mask pixels that are within distance
d from the contours and to use them as the target of the auxiliary boundary loss. The procedure is illustrated in
Figure 7 and detailed in Algorithm 1. For a segment with a length or width less than
, its whole ground truth is displayed in the boundary target mask, such as the small rivers, narrow strips of rangeland, and individual urban buildings shown in
Figure 8. Therefore, all the small objects and segments, which are more likely misjudged, are selected and penalized again by the Sobel Boundary Loss. For any object or segment whose width exceeds
, only its contour of width
d is displayed in the boundary target mask, such as the vast agricultural land, large rangeland, and urban residential community shown in
Figure 8. By capturing category impurity areas, compared with the ground truth mask, in the boundary target mask, the pixel number ratio of the large segment to the small segments drops from quadratic with the segment size ratio to linear with the segment size ratio. In this way, the Sobel Boundary Loss guides the network to learn the features of spatial details.
| Algorithm 1 Sobel boundary target generation |
- Input:
Ground truth , Sobel operator , , dilation rate d. - Output:
Sobel boundary target .
return
|
d is a hyperparameter that controls the extent of contour pixels participating in the Sobel Boundary Loss calculation. It is not advisable to set d too small for four reasons. Firstly, different from general images in which objects have clear contours, the land boundaries in land-cover satellite images are comparatively vague. Secondly, setting buffer zones of width d benefits the network by learning how to discriminate different categories. Thirdly, if d is set too small, the samples participating in the boundary loss calculation are too scarce. Last, the margin of human labeling error should be considered. It is suggested to set d as the value equal to half of the smaller dimension of most small segments, so the whole bodies of most small segments would remain on the boundary target mask. Without loss of generality, d was set to 50 pixels in the illustration figures and experiments.
Any conventional loss function, for example the cross-entropy loss function or the Dice loss function, can be used for the Sobel Boundary Loss. As illustrated in
Figure 7, in the dilated Sobel binary boundary mask, the pixels with value zero are relabeled as the category Unclassified and ignored in the Sobel Boundary Loss calculation.
3.5. Total Loss
The total loss
is the weighted sum of the main semantic segmentation loss
, auxiliary semantic segmentation losses
, and boundary losses
:
The values of the weights are adjusted according to the values of the loss functions and practical results. If the interiors of large segments are predicted fairly well but the boundaries or small segments are not predicted well, it is advisable to increase . To evaluate whether the existence of the auxiliary losses would boost accuracy, without loss of generality, all the weights were set to 1 in the following experiments to avoid any hyperparameter-tuning trick.
4. Experimental Results
Since the MKA module specializes in multiscale feature extraction, to evaluate its effect, we built an image classification network based on the encoder of MKANet and conducted experiments on a scene classification dataset of multiscale remote sensing images. Then, we measured the inference speeds of MKANet at various image sizes to validate whether its architecture design could boost inference speed and support large image sizes. At last, we conducted experiments on two land-cover classification datasets to examine the accuracy of MKANet and the effectiveness of the Sobel Boundary Loss.
4.1. Image Classification
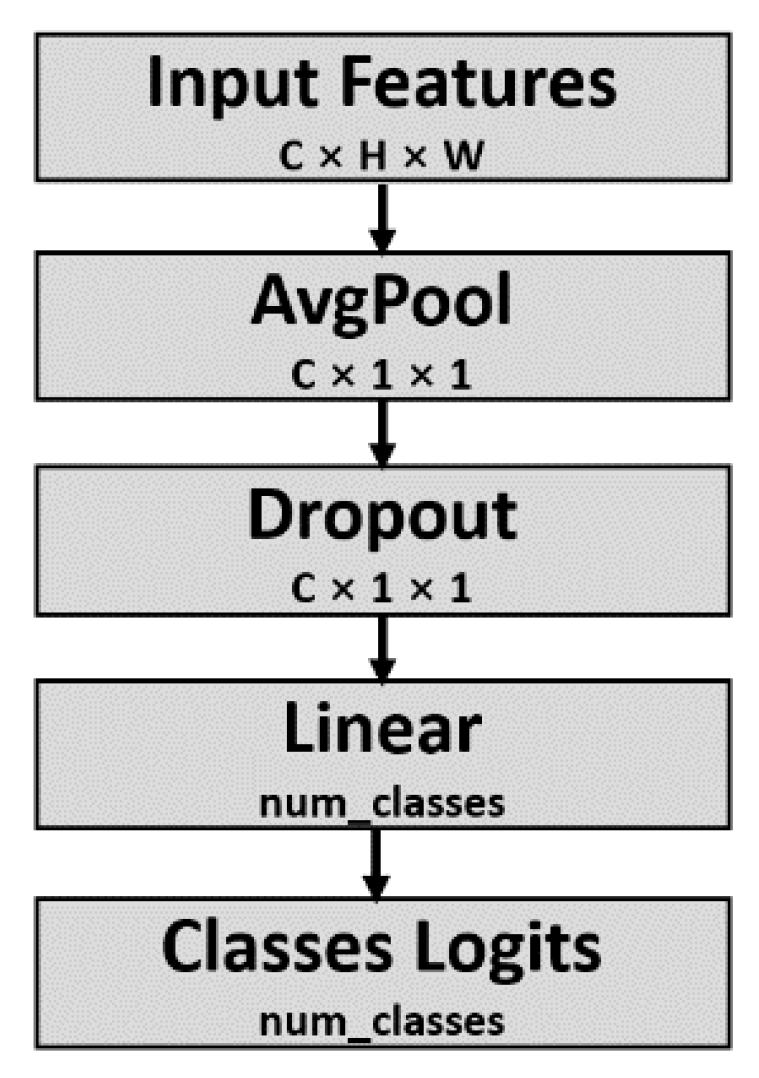
We added an image classification head as illustrated in
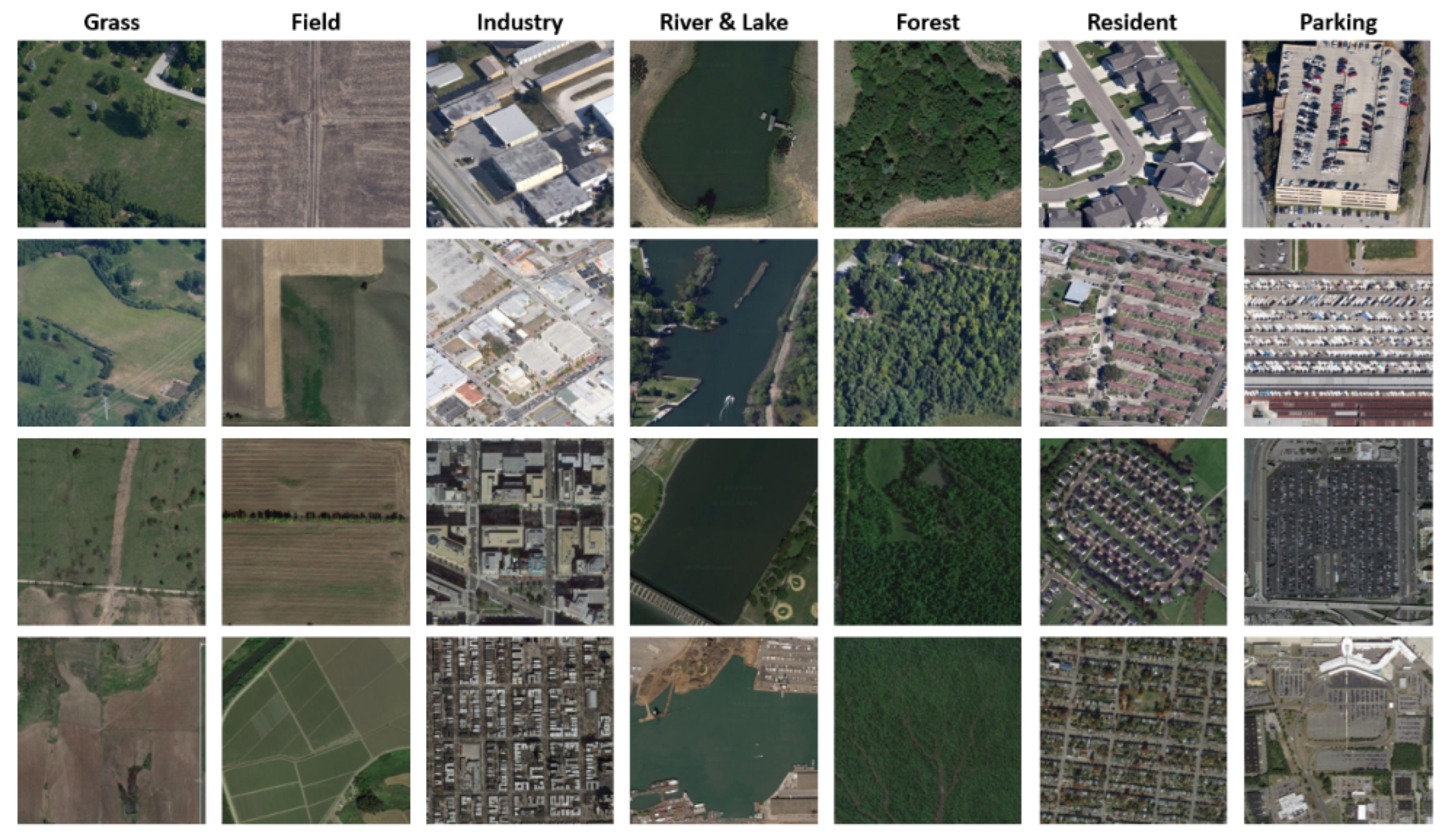
Figure 9 on top of the MKANet encoder for the task of image classification, and named it MKANet-Class. We compared MKANet-Class with other state-of-the-art lightweight classification networks on the RSSCN7 [
27] scene classification dataset of remote sensing images (
Figure 10). RSSCN7 contains seven typical scene categories of image size 400 × 400 pixels. For each category, 400 images were sampled on four different scales with 100 images per scale. A total of 2800 images were resized to 384 × 384 pixels and split into a training set, validation set, and test set at a ratio of 2:1:1.
Training details: Cross-entropy was selected as the loss function, and AdamW [
28] was selected as the optimizer with a batch size of 32. The base learning rate was 0.001 with cosine decay. The number of epochs was 150 with a warmup strategy in the first 10 epochs. For a fair comparison, all the networks were trained from scratch without pretraining on other datasets.
Data augmentation: random flipping, random rotation, and color jittering operations were employed on the input images in the training process.
As shown in
Table 2, MKANet-Class Small outperformed other state-of-the-art lightweight classification networks with better accuracy and a significantly faster inference speed, which verified the effectiveness of the MKA module and justified the efficiency of the parallel branch design.
4.2. Semantic Segmentation Inference Speed
For the semantic segmentation task, the inference speeds (FPS) of various networks were measured at four image sizes. As shown in
Table 3, all the lightweight networks had an obvious advantage over large networks in large image size support and inference speed. On a computer with an NVIDIA RTX 3060 12G GPU, none of the large networks could process images with a resolution of 4096 × 4096 pixels, but all the lightweight networks could. MKANet Small was even capable of processing images up to 7200 × 7200 pixels and was approximately 2× faster than other lightweight networks and more than 13× faster than the large networks. The large size and fast acquisition speed of satellite images highlight the value of MKANet in accelerating the cognition speed of remote sensing images.
4.3. Land-Cover Classification
To assess the semantic segmentation performance of MKANet, experiments were conducted on two land-cover classification datasets of satellite images: DeepGlobe Land Cover [
34] and GID Fine Land Cover Classification [
5].
The DeepGlobe Land Cover dataset consists of RGB satellite images of size 2448 × 2448 pixels, with a pixel resolution of 50 cm. The total area size of the dataset is 1716.9 km
. There are six rural land-cover categories. Only the labels of the original training set of the competition have been released; thus, the original training set, which contains 803 images, was split into a training set, validation set, and test set at a ratio of 2:1:1, as described in a previous study [
10].
The GID Fine Land Cover Classification dataset consists of 10 submeter RGB satellite tiles of size 6800 × 7200 pixels. There are 15 land-cover categories. Due to the limitation of the GPU memory capacity, the 10 tiles were cropped into 90 subimages of size 2400 × 2400 pixels, and then the 90 subimages were split into a training set, validation set, and test set at a ratio of 3:1:1, similar to a previous study [
35].
Training details: For all the lightweight networks, cross-entropy was selected as the loss function, and AdamW [
28] was selected as the optimizer with a batch size of six, and the base learning rate was 0.001 with cosine decay. The networks were trained for 300 epochs with the DeepGlobe Land Cover dataset and for 500 epochs with the GID dataset, using a warmup strategy in the first 10 epochs. For a fair comparison, all the networks were trained from scratch without pretraining on other datasets.
Data augmentation: Random flipping, random rotation, random scaling of rates (0.7, 0.8, 0.9, 1.0, 1.25, 1.5, 1.75), random cropping into size 1600 × 1600 pixels, and color jittering operations were employed on the input images during the training process. In the test process, no data augmentation operations were implemented.
Evaluation metrics: The performance of the networks was evaluated by the mean intersection over union (MIoU) and the mean F1 score which are defined as:
where
N represents the number of categories, and
,
, and
denote the number of true positive pixels, false positive pixels, and false negative pixels, respectively, in category
c.
4.3.1. DeepGlobe Land Cover Dataset Experimental Results
The DeepGlobe Land Cover Classification dataset provides high-resolution submeter satellite imagery focusing on rural areas. Due to the variety of land cover types, it is more challenging than the ISPRS Vaihingen and Potsdam datasets [
36] and the Zeebruges dataset [
37]. The image size of this dataset is 2448 × 2448 pixels, and only lightweight networks can support such large-size images in training and predicting. We selected this dataset to evaluate the performance of MKANet on high-spatial-resolution remote sensing imagery with image size beyond 2K pixels.
As presented in
Table 4 and
Table 5, MKANets led other competitive lightweight networks by at least 3% and even surpassed the large networks with pretrained backbones. In a previous study [
10], to fit the large networks into GPU memory, the authors compressed the images to half size and then divided them into subimages with a resolution of 512 × 512 pixels. For the large networks, spatial detail loss due to compression offsets their stronger feature extraction ability enabled by a larger backbone, while long-range context information loss due to subdivision weakens their better modeling ability from a more complex structure. Hence, for large-sized remote sensing patches, lightweight networks have their advantage and can have comparable and even better accuracy than large networks.
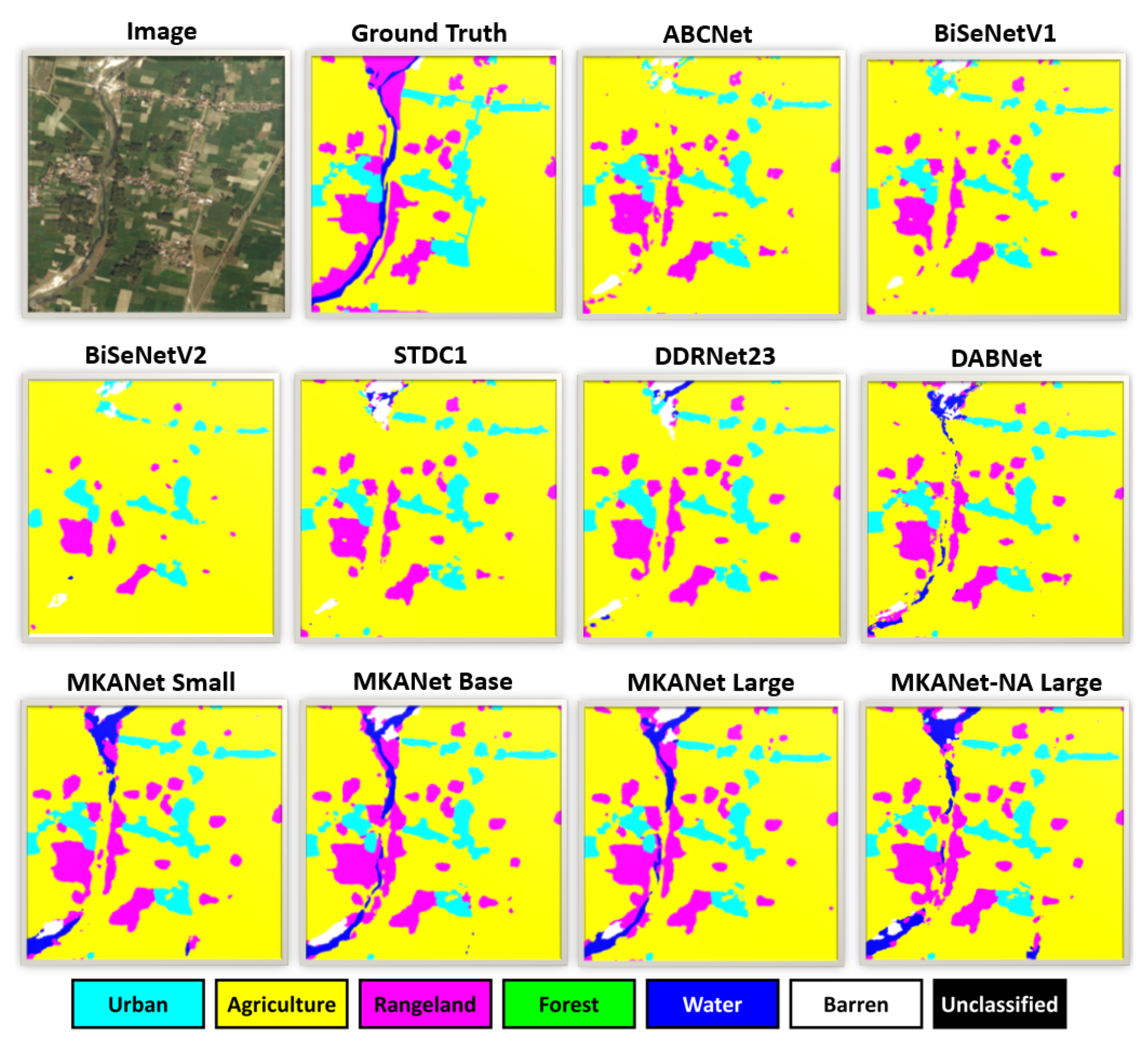
As illustrated in
Figure 11, the predicted masks demonstrate that compared with other lightweight networks, MKANets can better identify land cover of small dimensions, for example, the river. This superiority is attributed to two factors, one is the MKA module, which has multiscale receptive fields without losing spatial resolution, so spatial details can be preserved. As shown in the lower right subfigure, even without any auxiliary loss, MKANet-NA Large still predicted the river better than other networks. The other factor is the Sobel Boundary Loss, which benefits the network in small segments recognition and boundary recovery. As shown in the bottom of
Figure 11, MKANet Base and Large predicted the river more precisely than MKANet-NA Large.
The above observation agrees with the per-category IoUs in
Table 4, where MKANets lead other networks by a large margin in the categories of small segments, such as water and range.
4.3.2. GID Fine Land Cover Classification Dataset Experimental Results
The GID Fine Land Cover Classification dataset is very challenging due to its small sample size (only 10 tiles of size 6800 × 7200 pixels) and highly skewed category distribution, within which the proportions of the three categories are scarce, at less than 1%. We selected this rich category dataset to assess the discrimination ability of MKANet on fine and similar land-cover categories, and also evaluate its robustness with regard to highly unbalanced remote sensing imagery.
As shown in
Table 6 and
Table 7, MKANets outperformed all other lightweight networks and the large networks by a large margin. The per-category IoUs in
Table 6 indicated that the superiority of MKANets was mainly manifested in minor categories, small dimensional categories, and hard-discriminating categories. In these categories, MKANet Small surpassed the average IoU of other lightweight networks by more than 18%. For example, the large category of farmland (consisting of paddy land, irrigated land, and dry cropland) was highly skewed in distribution, the samples of irrigated land were approximately 10 times greater than those of paddy land and dry cropland. MKANet Small exceeded the average IoU of other lightweight networks by 37.7% on paddy land and 25.1% on dry cropland.
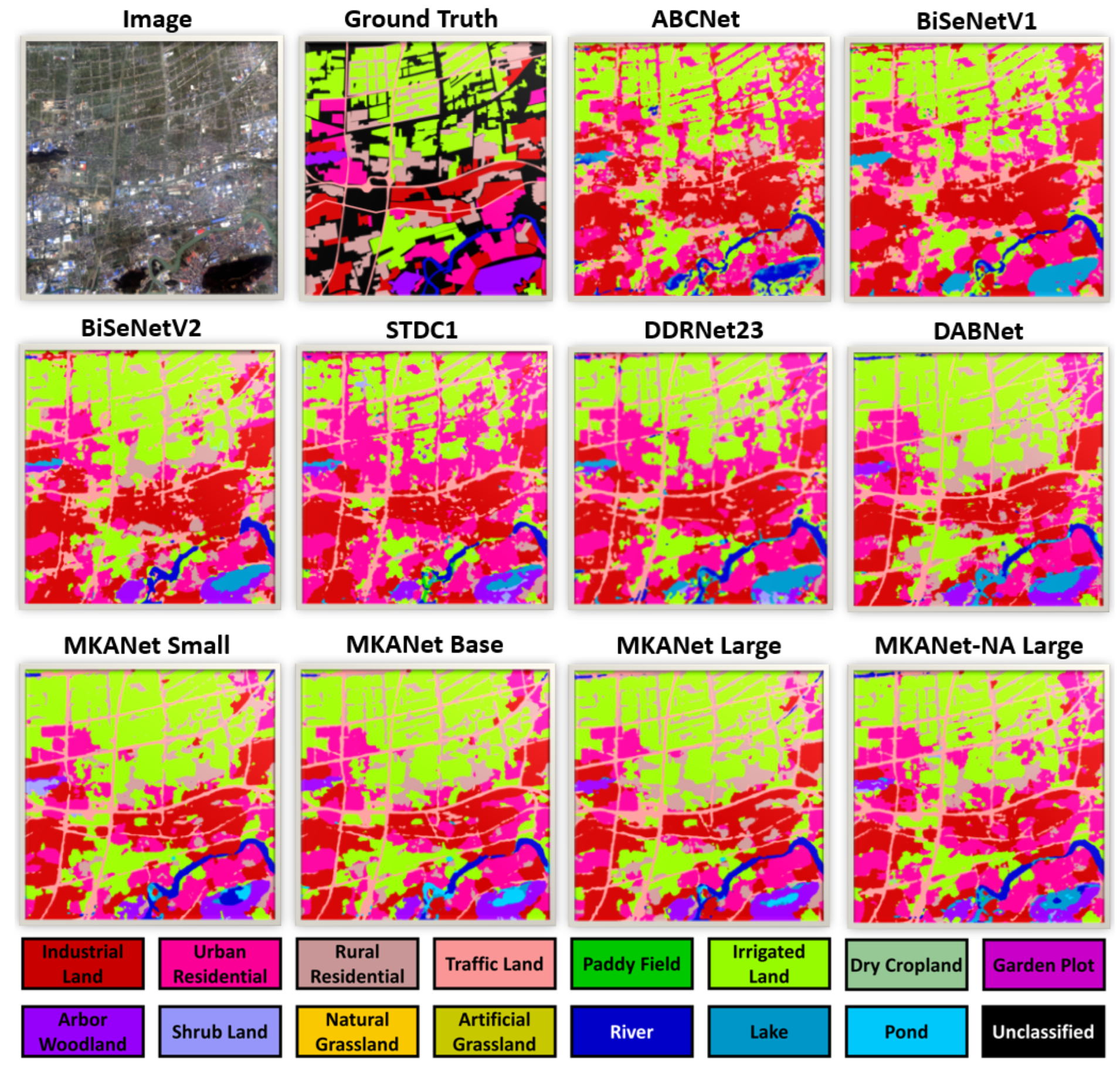
As illustrated in
Figure 12, small-dimensional land covers, such as rivers, streets, and rows of rural houses, were better classified by MKANets. MKANet Small exceeded the average IoU of other efficient networks by 27.1% on traffic land, 18.3% on artificial grass, 24% on rivers, 22.1% on lakes, and 19.3% on ponds. As shown in the bottom right subfigure, even without any auxiliary loss, MKANet-NA Large still outperformed other lightweight networks in small segment discrimination and spatial detail reconstruction.
4.4. Ablation Analysis
To validate the effectiveness of each component, ablation analysis experiments were conducted based on the DeepGlobe Land Cover dataset.
4.4.1. The Influence of Input Image Size on Prediction Accuracy
To investigate the influence of input image size on prediction accuracy, the original DeepGlobe dataset images with a resolution of 2448 × 2448 pixels were cropped into patches with resolutions of 512 × 512 pixels, 1024 × 1024 pixels, and 1600 × 1600 pixels. The prediction accuracies of these three patch sizes were compared with that of the original image size. As shown in
Table 8, the smaller the patch size is, the lower the prediction accuracy is, which demonstrates that the loss of long-range context information caused by cropping images into small patches would cause misjudgments.
4.4.2. Effectiveness of Kernel-Sharing Atrous Convolution
To evaluate the effect of kernel-sharing atrous convolutions in the MKA module, a variant network with kernel-sharing atrous convolutions replaced by regular atrous convolutions was built and denoted as MANet. As shown in
Table 8, compared with regular atrous convolutions, kernel-sharing atrous convolutions had stronger feature extraction ability.
4.4.3. Effectiveness of Coordinate Attention Module
To assess the effect of the two coordinate attention modules (CAMs) in the decoder, a variant network with CAMs replaced by simple concatenation operations was built and denoted as MKANet-Concat. As shown in
Table 8, compared with simple concatenation operations, the two CAMs better fused the multiscale features from various stages and augmented the representations of the objects of interest.
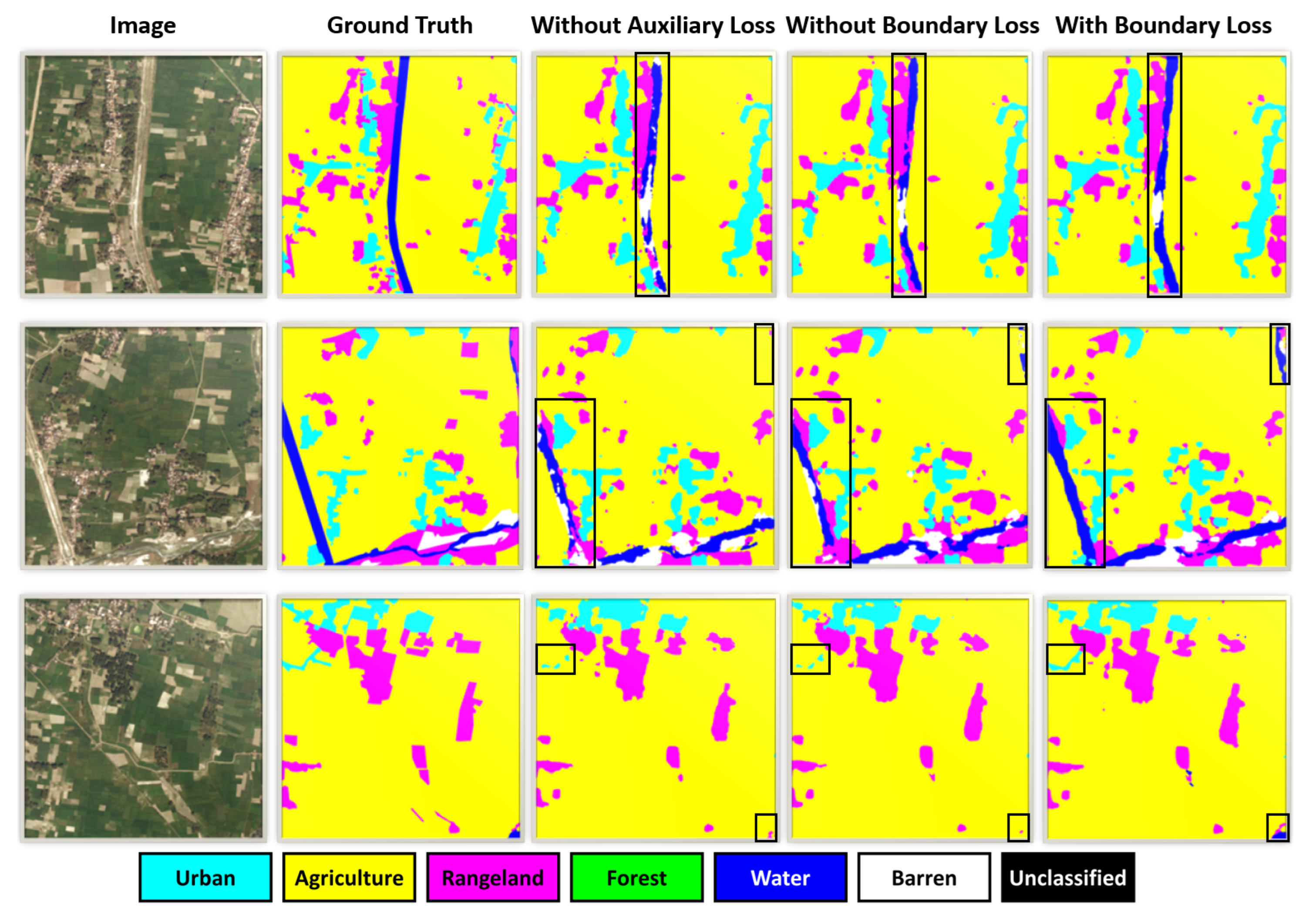
4.4.4. Effectiveness of Auxiliary Losses
To estimate the contribution of auxiliary semantic segmentation loss and auxiliary boundary loss, a variant network without any auxiliary loss was built and denoted as MKANet-NA, and another variant network without auxiliary boundary loss was built and denoted as MKANet-NB. As shown in
Table 8, on the DeepGlobe Land Cover dataset, auxiliary semantic segmentation loss improved the MIoU by nearly 1%, and auxiliary boundary loss further boosted the MIoU by approximately 1.5%. On the GID Fine Land Cover Classification dataset, both improvements were broadened to 1.9% (
Table 9). The IoUs of most categories were boosted by the two kinds of auxiliary losses, indicating that these auxiliary heads could promote spatial detail learning at lower levels and semantic context learning at higher levels.
To visualize the effect of the auxiliary losses, the predicted labels of the above three networks are displayed in
Figure 13. The results showed that the auxiliary losses, especially the boundary loss, can guide the networks to better recognize small segments and restore boundaries, which is in accordance with our design.
4.4.5. Stacking More MKA Modules per Stage
MKANet can be expanded not only in width by increasing the number of base channels
c but also in depth by increasing the repeating times
r of MKA modules in each stage. As shown in
Table 10, the performance of MKANet increased by stacking additional MKA modules in each stage.
4.4.6. The Optimal Value for the Number of Branches
In the MKA module, the number of parallel branches
b is a hyperparameter, which is proportional to the receptive field and computational cost. To determine the optimal value for
b, different values were tested. As shown in
Table 11, with one more branch of a larger dilation rate atrous convolution to sense larger-scale features, MKANet
performed better than MKANet
by 0.54% on the MIoU metric. However, as more branches were added, the MIoU dropped. This negative effect was mainly attributed to Part 3 of the MKA module, where the output features of each branch were concatenated and a pointwise convolution was then applied to them to compress the channels to
. The larger
b is, the more information losses there are in the channel compression process.
strikes a good balance among the multiscale receptive field, information loss, and computation efficiency; thus,
b defaults to the optimal value of 3 in the MKA module.
5. Discussion
Aimed at the characteristics of multiscale and large image size of top view remote sensing imagery, we merged the specialized multibranch module and the shallow architecture design into MKANet. Through extensive experiments and an ablation analysis, MKANet reached our initial expectation and alleviated the three problems (slow inference speed, incapability of processing large size image patches, and easy misjudgment on boundaries and small segments) that restrict the practical applications of semantic segmentation networks in remote sensing imagery.
In the land-cover classification experiments, the original images of 2448 × 2448 pixels and large patches of 2400 × 2400 pixels were employed as the input of MKANet. Compared with a cropping size of 512 × 512 pixels or even smaller in most existing studies, the number of subimages was reduced to 1/25. In the inference speed experiments, MKANet Small could support an even larger image size of 7200 × 7200 pixels on an NVIDIA RTX 3060 12G GPU and image size up to 10k × 10k pixels on an NVIDIA RTX3090 24G GPU. Its friendly support of large subimages greatly alleviated spatial detail loss due to downsampling or long-range context information loss due to cropping. Meanwhile, MKANet Small was approximately 2× faster than other lightweight networks and 13× faster than large networks. Both merits highlight the value of MKANet for accelerating the perception and cognition speed of remote sensing imagery.
In response to the problem that prediction errors are more likely to occur on boundaries and small segments, the Sobel operator’s convolution and dilation operation were innovatively utilized to capture category impurity areas, exploit boundary information, and exert an extra penalty on boundaries and small segments misjudgment. Both quantitative metrics and visual interpretations verified that the Sobel Boundary Loss could promote spatial detail learning and boundary reconstruction.
For the task of land-cover classification, MKANet successfully raised the benchmark on accuracy and demonstrated that if lightweight efficient networks were properly designed, they could have comparable accuracy with that of large networks. In addition, due to the merits of a fast inference speed and a low requirement on hardware, lightweight networks have immense potential in practical applications and are equally important. Notably, MKANet outperformed other state-of-the-art lightweight networks with a significantly better accuracy.
6. Conclusions
Conventional semantic segmentation networks are not able to process large-size satellite images under mainstream hardware resources. To avoid a loss of spatial resolution due to downsampling and a loss of long-range context information due to cropping, we proposed an efficient lightweight network for land-cover classification of satellite remote sensing imagery. Extensive experimental results demonstrated that the MKANet achieved state-of-the-art speed–accuracy trade-off; it ran 2× faster than other lightweight networks and could support large-size images. In addition, the proposed Sobel Boundary Loss could enhance boundary and small segment discrimination.
With the increasing demands of onboard autonomous applications, the next generation of satellites are required to possess the ability to process collected images and execute intelligent tasks on orbit. Although MKANet consumes much less hardware resources than other networks, it still cannot satisfy the tight constraints imposed on the onboard embedded systems. In future research, we will focus on image onboard processing and explore effective methods, such as network pruning, parallel optimization, and hardware acceleration, for embedded system adaptation and deployment.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}