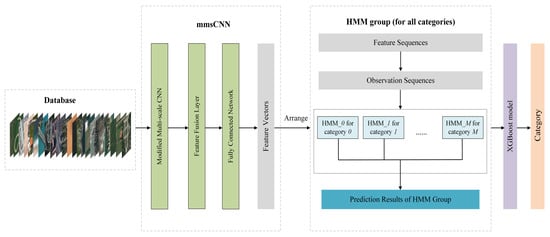
2.1. mmsCNN
Presently, multi-scale convolutional neural networks (msCNNs) mainly include two different types. The first is the msCNN model, on the basis of multi-scale images. This type of model usually inputs images of different scales into the same network model to obtain the features of images of different scales, and then fuses them to obtain multi-scale features. The second is the msCNN model based on multi-scale feature maps, which utilizes convolution kernels of different sizes to process images of the same size. Although msCNN based on multi-scale images has achieved good experimental results, its network structure consumes a lot of memory and cannot adapt to larger and deeper networks. Additionally, the existing msCNN models based on multi-scale feature maps are not perfect either, which introduces convolution kernels of various sizes, causing an explosion in the number of parameters. Therefore, we present a lightweight msCNN model based on multi-scale feature maps to extract multi-scale features with fewer parameters and less calculation, as shown in
Figure 3.
Recently, ref. [
35] showed that the shallow large-kernel CNNs have a larger effective receptive field and are more consistent with the human perception mechanism. In addition, since the large-kernel CNNs need to update more parameters, the gradient vanishing is more likely to occur when the depth is as deep as the small-scale convolution kernel. The above two cases inspire us to introduce the mechanism of shortcut connections into large-kernel CNNs, which are derived from the residual network. First of all, we input the sample images into four different kernel CNNs, i.e.,
,
,
, and
. Unlike the traditional msCNN based on multi-scale feature maps, we perform shortcut connections on the CNNs above. Specifically, we, respectively, invalidate the first 1, 2, and 3 convolution layers of
,
, and
, as shown in the blue dotted box in
Figure 3. In the following description, we refer to the network in the blue dashed box in
Figure 3 as the invalid layer, which is exactly the network we skipped. To ensure the same size of different convolution layers during fusion, we adjust the pooling scale in the network of the next layer of the invalid convolution layer. Concretely speaking, the pooling layer after the invalid layer in
is set to
, that after the invalid layer in
is set to
, and that after the invalid layer in
is set to
. Obviously, the number of layers of large-kernel CNNs and parameters in the model are greatly reduced in the mmsCNN. Numerical experiments verify that the proposed mmsCNN can effectively extract multi-scale features with less computational complexity, and prevent the occurrence of gradient vanishing.
Next, multi-scale features are merged at the feature fusion layer. Since the size of features with different scales is consistent in the previous processing, these features can be added directly in the feature fusion layer. After feature merging, the output of the model contains both the signal details of the high-frequency features extracted from the small-scale feature maps and the low-frequency local feature information extracted from the large-scale feature maps. At the end of the mmsCNN, we utilize the fully connected network to synthesize the previously extracted features. Notably, the export of the mmsCNN is the multi-scale feature sequence and will be fed into the subsequent HMM as the observation sequence.
2.2. HMM
A hidden Markov model (HMM) is a machine learning model used to describe a Markov process [
24]. In this section, we utilize the HMM to further mine the context information (or “hidden state evolution laws”) between the features extracted from the mmsCNN. Specifically speaking, we use the HMM to improve the semantic scores of highly correlated related features and weaken the semantic scores of unrelated features. Then, the HMM gives the preliminary prediction result of the sample, which is fed into XGBoost.
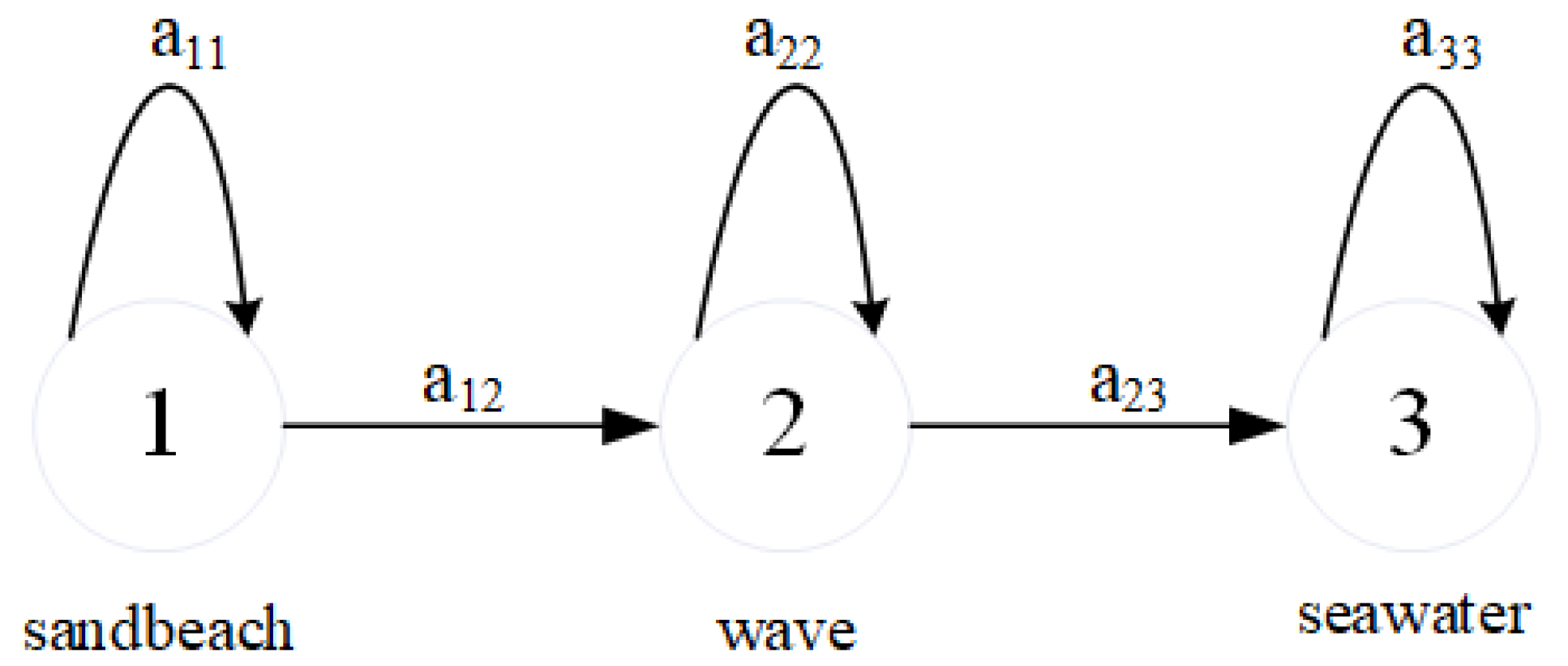
Firstly, we give a description of what the “context information” of HMM mining is. Each remote sensing scene image is composed of several salient regions according to the object composition logic. The hidden states of these salient regions show certain order laws, which can reflect the characteristics of object composition. Different objects have various compositional logics, so the salient regions of different objects have state evolution laws (or “context information”) in different orders. As shown in
Figure 4, “Beach” scene images can be roughly divided into three regions: “sandbeach”, “wave”, and “seawater”. The “Pond” scene images can be roughly divided into three regions: “land”, “lake”, and “land”. The “Port” scene images can be roughly divided into three regions: “land”, “vessels”, and “sea”. The “Playground” scene images can be roughly divided into three regions: “arc rubber runaway”, “soccer field”, and “arc rubber runaway”. There is a certain order law between those regions. For example, “wave” must be in between “sandbeach” and “seawater”. This is the universal logic of objects such as “Beach”, and this logic is reflected in the change of hidden state, as shown in
Figure 5.
What the HMM mines is the state evolution laws hidden behind features, and then it achieves the purpose of classification.
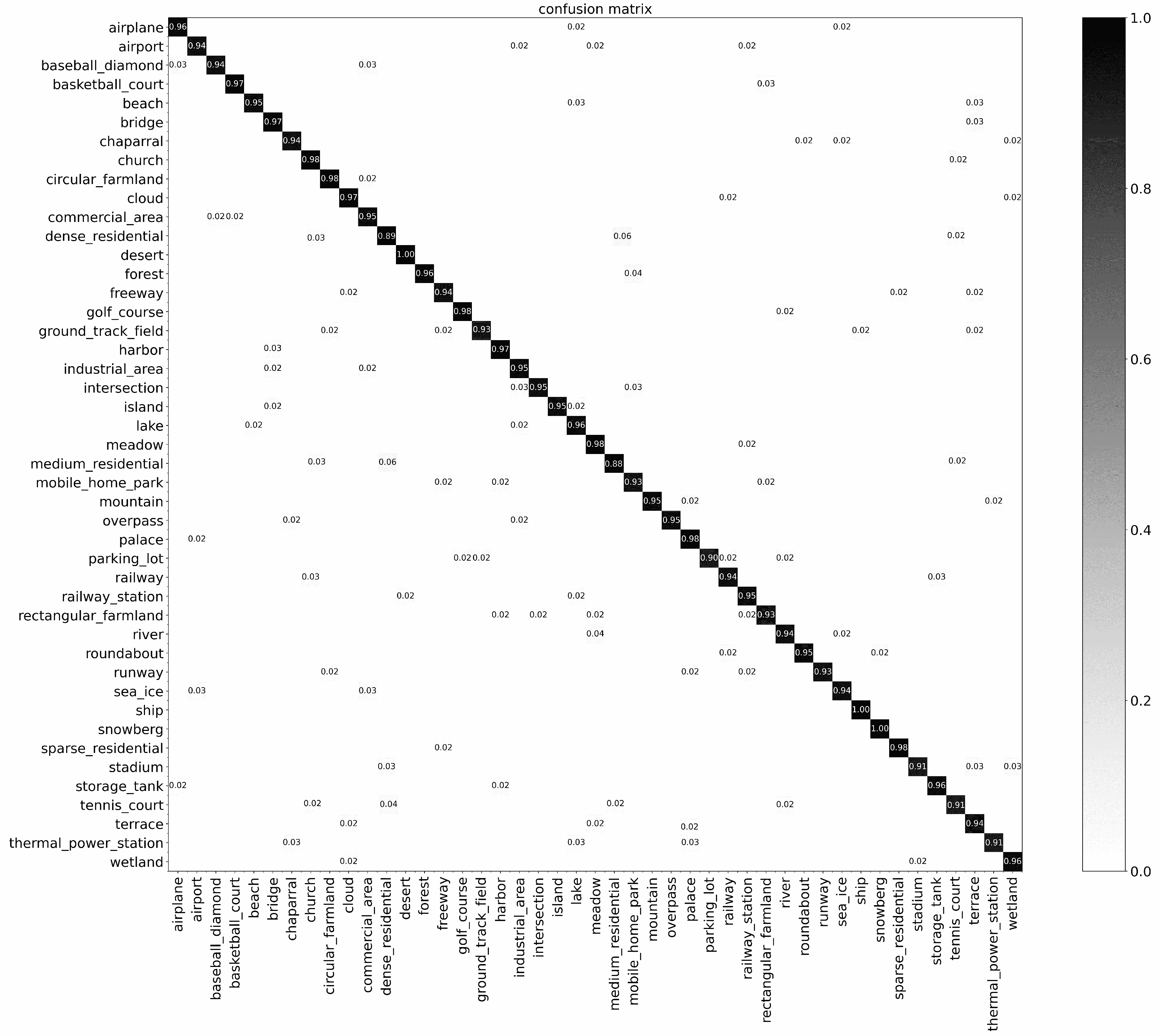
Figure 6 shows the “hidden state evolution laws” or “context information” obtained by the HMM according to several different remote sensing images shown in
Figure 4. Before designing the HMM, we use k-means to determine that there are eight hidden states for each event type signal.
Figure 6a–d, respectively, show the hidden state evolution diagrams of three salient regions in the four scene images of “Beach”, “Pond”, “Port”, and “Playground”, which are obtained according to the Viterbi algorithm. As we can see, “Beach” and “Port” present three different hidden states, while the states of the first and third regions of “Pond” and “Playground” are the same, which is consistent with the image we observed.
In this part, we discuss the importance of the features’ priority exploited by the HMMs. In this paper, we first use the mmsCNN model to extract the features of each salient region in the image, and convert it into a feature sequence according to the order of the salient regions. Then, it is used as the observation sequence of the HMM to learn the internal state evolution law of the object, further excavate the composition logic of the object, and finally classify the image of the object. Therefore, the priority of features is important, and it needs to be arranged in the order of salient regions before it can be used to mine the changing laws of hidden states. In order to prove the importance of the priority of features, we use the “Beach” in
Figure 4 as a sample to carry out comparative experiments. As shown in
Figure 4, the sample contains three salient regions.
In this experiment, in the first step, the trained mmsCNN is used to extract a feature vector for the sample. In the second step, the mmsCNN feature vector, originally organized according to the channels, is rearranged as the feature sequences arranged in the order of the position of the salient regions of the sample. Specifically, this part of the work is mainly to connect the features of all channels corresponding to the same position of the sample together as the features of the position. The mmsCNN feature sequence finally obtained in this step includes three subsequences, which correspond to the mmsCNN feature vectors of the three salient regions of the sample in turn. The third step is the most critical step, because the difference processing in this step constitutes the control of this experiment. The mmsCNN feature sequence output in the second step is directly used as the input of the control group, while the shuffled mmsCNN feature sequence is used as the input of the experimental group. To be specific, the processing of the experimental group in this step refers to exchanging the second subsequence and the third subsequence of the mmsCNN feature sequence. Although the internal order of each subsequence has not changed, the order of the exchanged mmsCNN feature sequence cannot be consistent with the position order of the salient region of the sample. In other words, after the exchange occurs, the features’ priority of the feature sequence of the experimental group has been destroyed. In the fourth step, we input the feature sequence of the experimental group and the feature sequence of the control group into the HMM model corresponding to the trained “Beach” object. Then, we compare the prediction probabilities of the output of the HMM model in the experimental group and the control group, as shown in
Table 1. In addition, the state evolution diagrams of the experimental group and the control group are shown in
Figure 7.
As shown in
Figure 7, compared with
Figure 6a, there is a significant difference between the state evolution diagrams of the experimental group (the features’ priority is destroyed) and the state evolution diagrams of the typical “Beach” sample, while there is no difference from the control group (the features’ priority is retained). This indicates that when the features’ priority in the observation sequence of HMM is destroyed, the object composition logic contained in the observation sequence changes markedly. As reported in
Table 1, the probability of HMM output in the experimental group (features’ priority is destroyed) is significantly lower than that in the control group (features’ priority is preserved). As we know, the higher the output probability, the more likelyit is that the HMM model thinks it belongs to this category. This proves that it is difficult for HMM to accurately classify according to the observation sequence when the features’ priority in the observation sequence of HMM is destroyed. Based on the above two points, features’ priority is extremely important for the HMM model to correctly match the internal structure logic of objects and thus correctly classify them.
Next, we explain how HMM works. The features output by the mmsCNN are fed into the HMM as the observation sequence, which are described as
assuming there are
M observation states in the Markov chain. In the training phase, the HMM parameters of each kind of image are initialized to
Specifically,
is the original probability of each hidden state,
where
N is the number of hidden states in the Markov chain and
denotes the hidden state variable. In addition,
is denoted as the state transition probability matrix,
which describes the transition probability between states in HMM.
is the probability matrix of the observation,
where
denotes the observation variable. The matrix
is generally obtained by a Gaussian mixed model (GMM). Particularly, the more Gaussian models there are in a GMM, the better the effect of fitting the model, but the greater the computational complexity. The HMM structure is shown in
Figure 6.
The main task in the training phase is to update parameter
by using the feature vector output by mmsCNN. (We arrange the feature vectors extracted by mmsCNN into feature sequences in the order of salient regions. This step is mainly realized by flattening and rearranging the features of each channel.) To be specific,
is updated according to the Baum–Welch algorithm [
36] to obtain the highest probability
. We consider the probability
to reach its maximum value when the probability obtained in two consecutive iterations is almost equal. In the experiment, the convergence of training loss can be ensured after 10 iterations, which means that the difference of probability is close to
. In summary, for a large number of observation sequences of each kind of image, we learn the context characteristics of this kind of image and obtain the parameters of the optimal HMM. Similarly, other HMMs for the scene images of other categories can be built in the same way. Ultimately, the HMMs of all kinds of images form an HMM group, which is used to discriminate all different scene images.
In the test phase, first of all, every image is transformed into a multi-scale feature sequence with the mmsCNN, which is then fed into the HMM group as a observation sequence. Subsequently, the HMMs in the HMM group score the matching degree according to the image features extracted by mmsCNN and the state evolution laws behind the features. In other words, we calculate the posteriori probability of observation sequence in each HMM on the basis of forward–backward algorithm [
37], and then judge that the model with maximum probability is the image category. It is worth mentioning that if it is only feature matching or state evolution laws matching, the HMM will not obtain a high probability value. Only when both the feature sequence and the state evolution law are matched with the parameters of the HMM can a high probability value be obtained and the scene category be determined.
Figure 8 shows the recognition process of the HMM. Overall, for each sample image, the trained HMM group gives the preliminary prediction results and inputs them into XGBoost as training data.
At present, in addition to HMM, there are some other classification methods based on feature sequences, such as RNN. However, the RNN is black box since the hidden evolution routes of the signal are difficult to demonstrate, in which the improvement can only be seen from the final classification results, while in the HMM model, the sequential relationship can be also externally demonstrated, and it gives the reason why the model works. In addition, the use of the HMM for classification requires the construction of the HMM group, which naturally coincides with our stacking mechanism. The HMMs in the HMM group can be used as basic learners in the stacking mechanism to further improve the classification ability of the model; that is why we choose the HMM model at the beginning. Presently, we cannot prove that the performance of our model will be better or worse if the HMM is replaced with an RNN or LSTM model. The purpose of our work in this article is to use the HMM to find the state evolution laws of remote sensing image feature sequences and classify them. This is a start, and numerical experiments demonstrate that the effect of our model is considerable. In fact, one of our main tasks in the future is to focus on comparing the roles of HMM, RNN, and LSTM in our model, and find the best model.
2.3. Stacking Ensemble Mechanism
Ensemble learning is a technology to complete learning tasks by building and combining multiple learners [
25]. At present, the three widely used ensemble learning methods are bagging, boosting and stacking. The core idea of bagging is to train a series of independent models in parallel, and then aggregate the output results of each model according to a certain strategy. The main idea of boosting is to train a series of dependent models serially. In other words, the latter model is used to correct the output results of the previous model. The main idea of stacking is to train a series of independent basic learners in parallel, and then combine the output results of each model by training a top-level learner.
In order to select the optimal ensemble learning scheme, we implement the above three ensemble learning methods on the UCM dataset. Presently, the bagging method and boosting method are widely accepted representative algorithms—random forest and XGBoost. Stacking is used as an algorithm framework, and researchers design the details of the top-level learner by themselves, with a higher degree of freedom. Therefore, we directly use mmsCNN–randomforest, mmsCNN–XGBoost and mmsCNN–stacking frameworks for comparison. It is worth mentioning that the trained HMMs in the HMM group are used as the basic learners and XGBoost is used as the top-level learner to construct a single-layer stacking framework. The experimental results are shown in
Table 2, which proves that higher classification accuracy can be obtained by using stacking, which is the reason why we choose stacking.
In the stacking ensemble mechanism, the HMMs in the HMM group are natural basic learners and the top-level learner is the XGBoost model. If the HMM group consists of
m different HMMs in
Section 2.2, the number of basic learners is
m. Then, for each sample, the HMM group will obtain
m different probability values. Finally, these probability values and the label of the sample will be fed to the XGBoost model as training data, as shown in
Figure 9. Different from traditional stacking ensemble mechanism, the proposed model naturally takes advantage of the differences of each HMM in the HMM group and does not rigidly link several models together, which can take advantage of the feature extraction characteristics of the HMMs in the HMM group. This stacking ensemble learning mechanism integrates multiple models to make decisions together, which can effectively avoid overfitting while ensuring accuracy. In addition, this stacking mechanism can handle several problems that basic learners cannot solve. For example, when two or more HMMs in the HMM group give the same highest score to the sample picture, the HMM group cannot judge the category of the sample picture. In this case, the trained XGBoost model in the stacking mechanism can still work.
In this paper, the XGBoost model is used as the top-level learner of the stacking framework, and the mmsCNN–HMM + XGBoost model is constructed. To demonstrate the validity of the XGBoost model, we performed ablation experiments on the UCM dataset. Specifically, we took the following two models as the control test of the mmsCNN–HMM + XGBoost model proposed in this paper: the first is mmsCNN–HMM, and the second is mmsCNN–HMM + SVM. As shown in
Table 3, the experimental results prove that selecting the XGBoost model in stacking can result in higher classification accuracy.
The basic idea of the extreme gradient boosting (XGBoost) model is to stack the outputs of diverse weak classification models to form a strong classification model. The stacking method adds the results of each weak classifier, i.e., classification and regression tree (CART), which is a typical binary decision tree. In the training phase, XGBoost trains the first tree with the training set to obtain the predicted value and the error with the sample truth value. Next, the second tree is trained, whose goal is to fit the residual of the first tree, and this procedure is the same as the first step except that the truth value is replaced by the residual of the first tree. After the second tree is trained, the residual of each sample can be obtained again, and then the third tree can be further trained, and so on. In the test phase, for each sample in the test set, each tree will have an output value, and the sum of these output values is the final predicted value of the sample. Then, the category of sample will be obtained on the basis of the final predicted value. Particularly, ref. [
38] gave a detailed introduction to XGBoost.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















