
Imbalanced Underwater Acoustic Target Recognition with Trigonometric Loss and Attention Mechanism Convolutional Network

 ,
,
Abstract
:1. Introduction
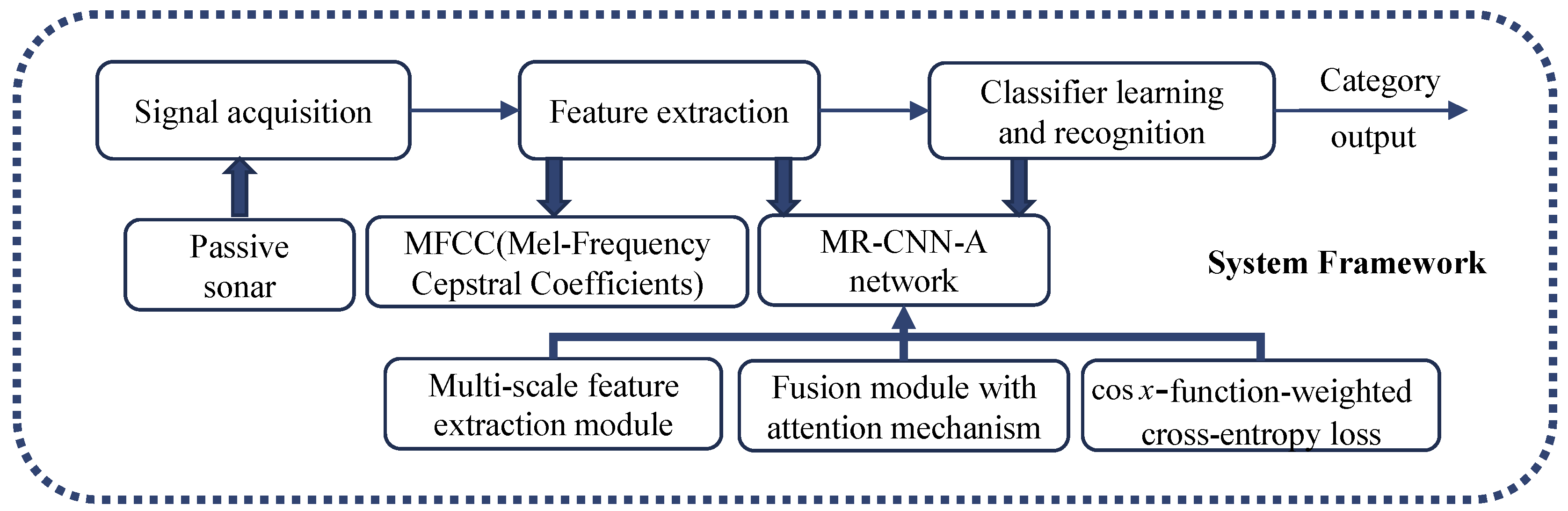
2. Materials and Methods
2.1. Feature Preparing
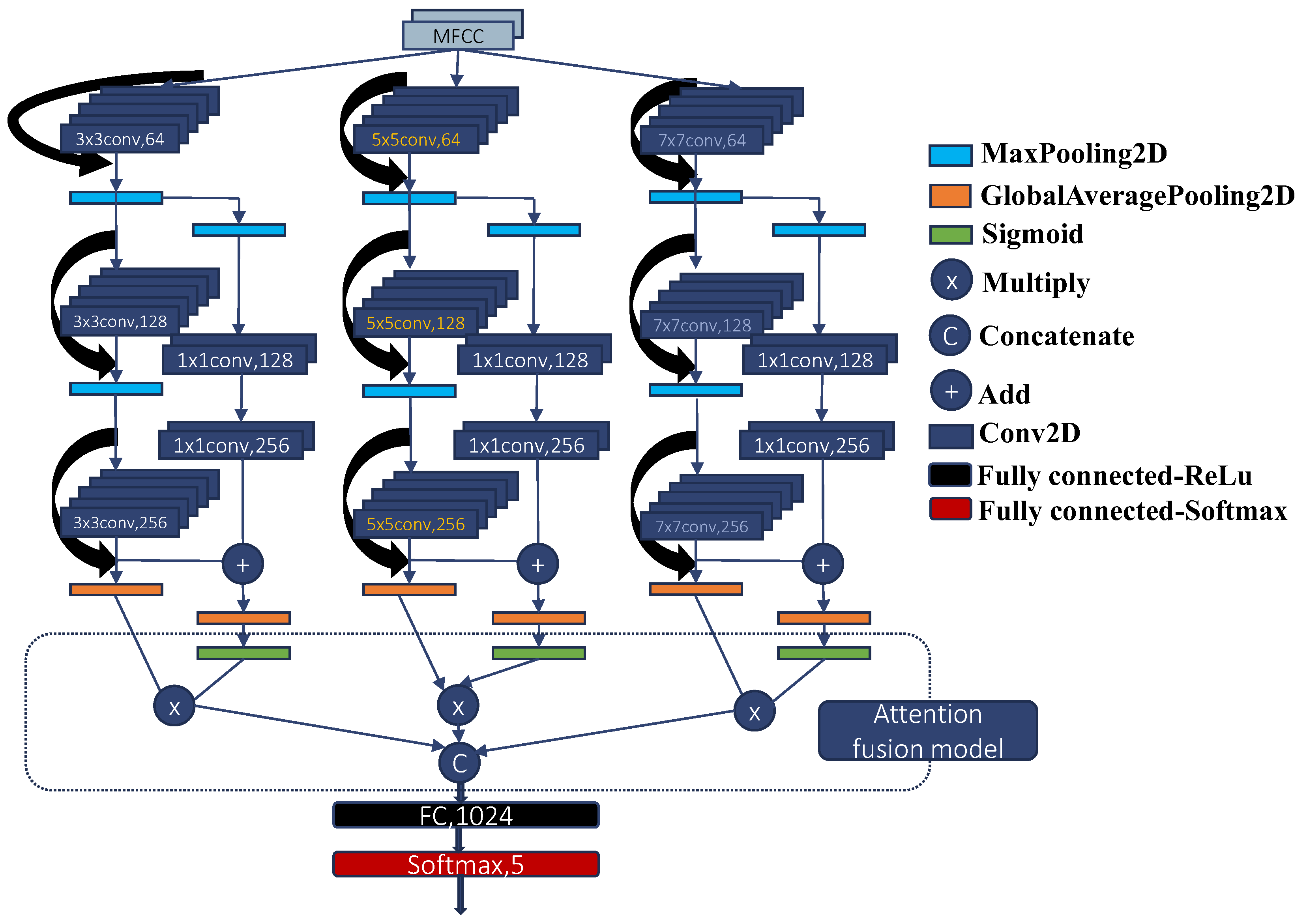
2.2. MR-CNN-A Network
2.2.1. Attention Mechanism Based Multi-Scale Feature Fusion
2.2.2. Residual Learning Block
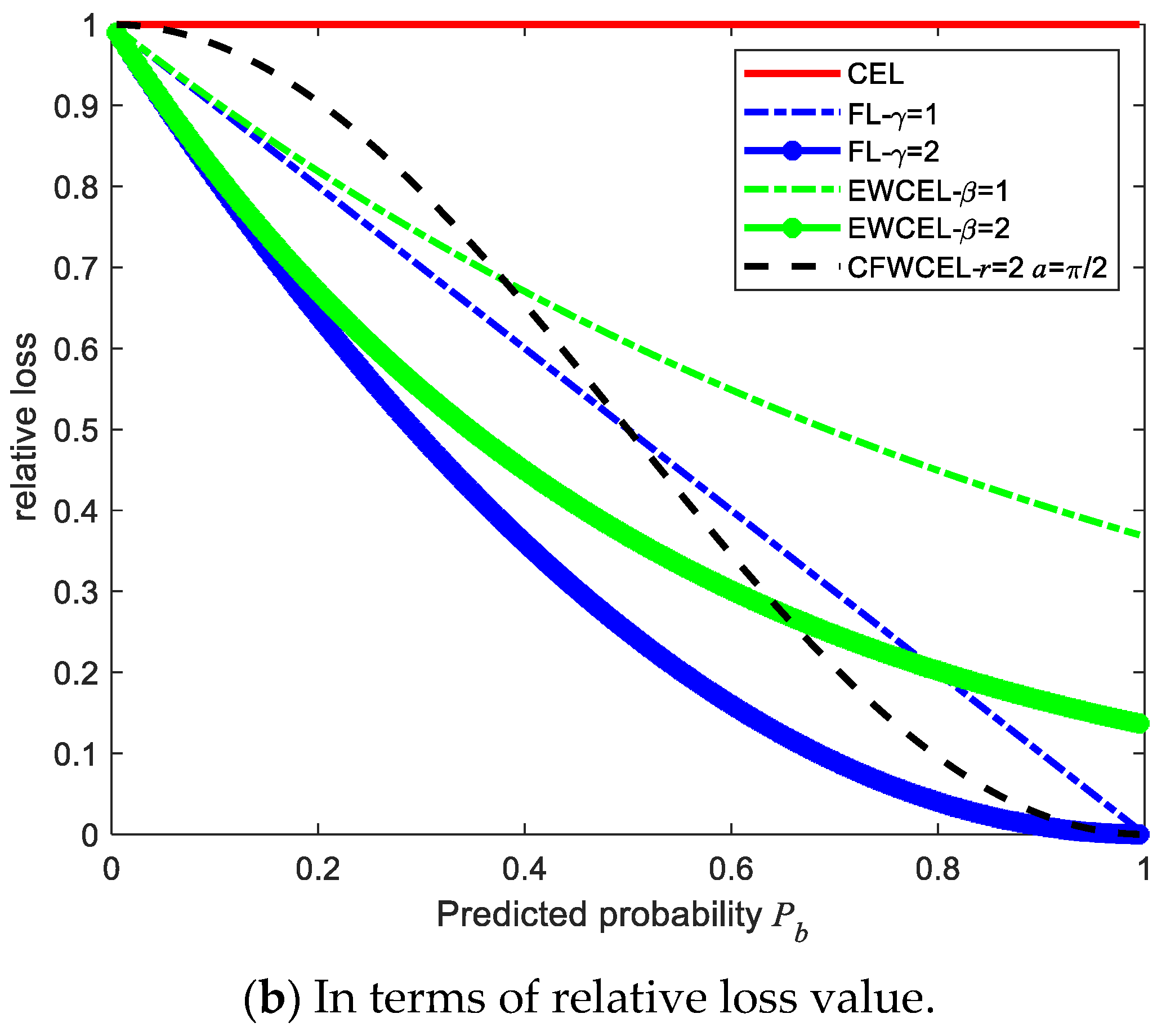
2.2.3. Function-Weighted Cross-Entropy Loss Function
2.2.4. The Whole Network
3. Results and Discussions
3.1. Comparison of Feature Extraction Methods
3.2. Comparison of Classification Methods
3.2.1. Experimental Results with Different Methods
3.2.2. Experimental Results with Different Noise Levels
3.3. Experiments with Different Imbalanced Data
3.3.1. Data Imbalance Definition
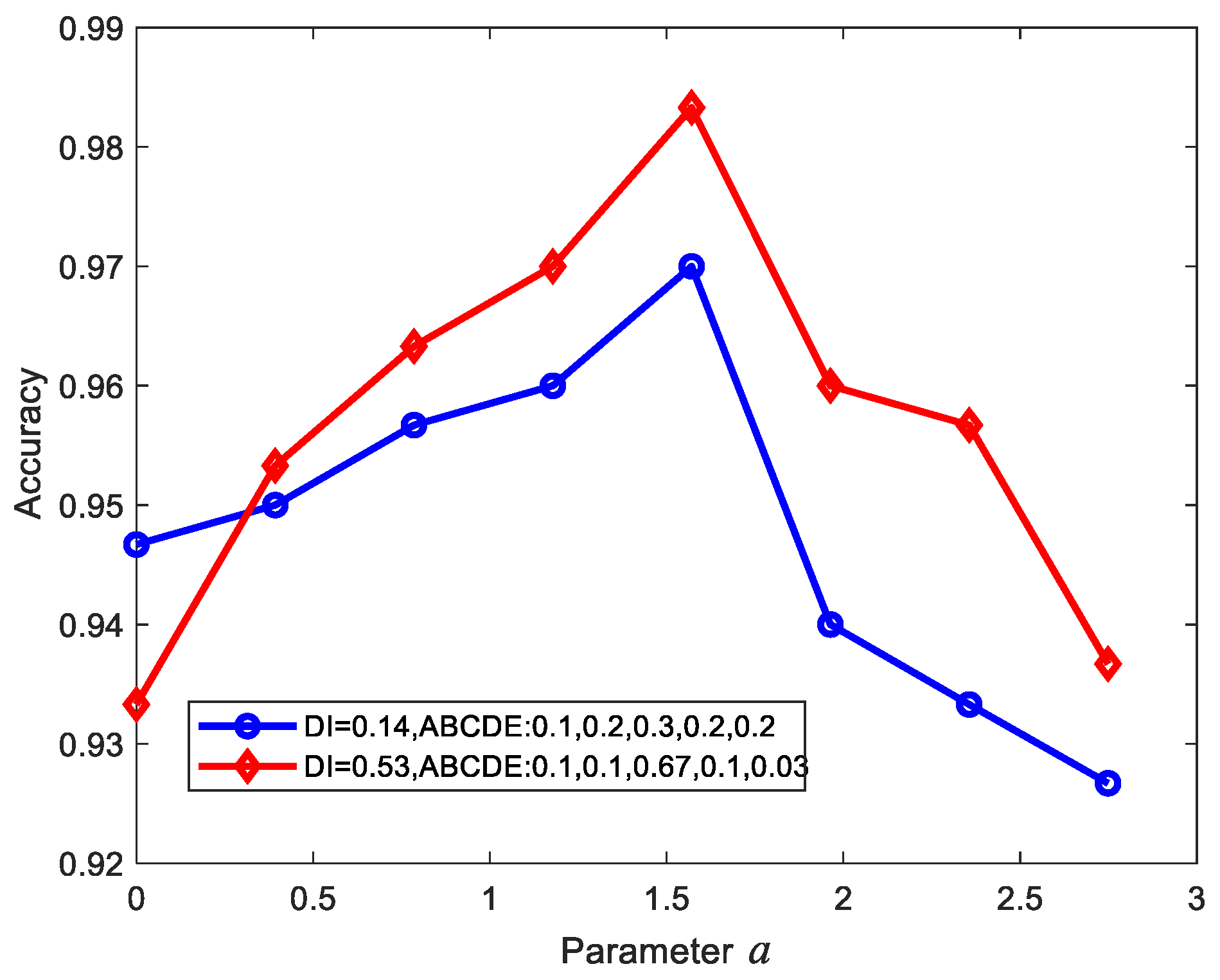
3.3.2. Parameter Selection in CFWCEL
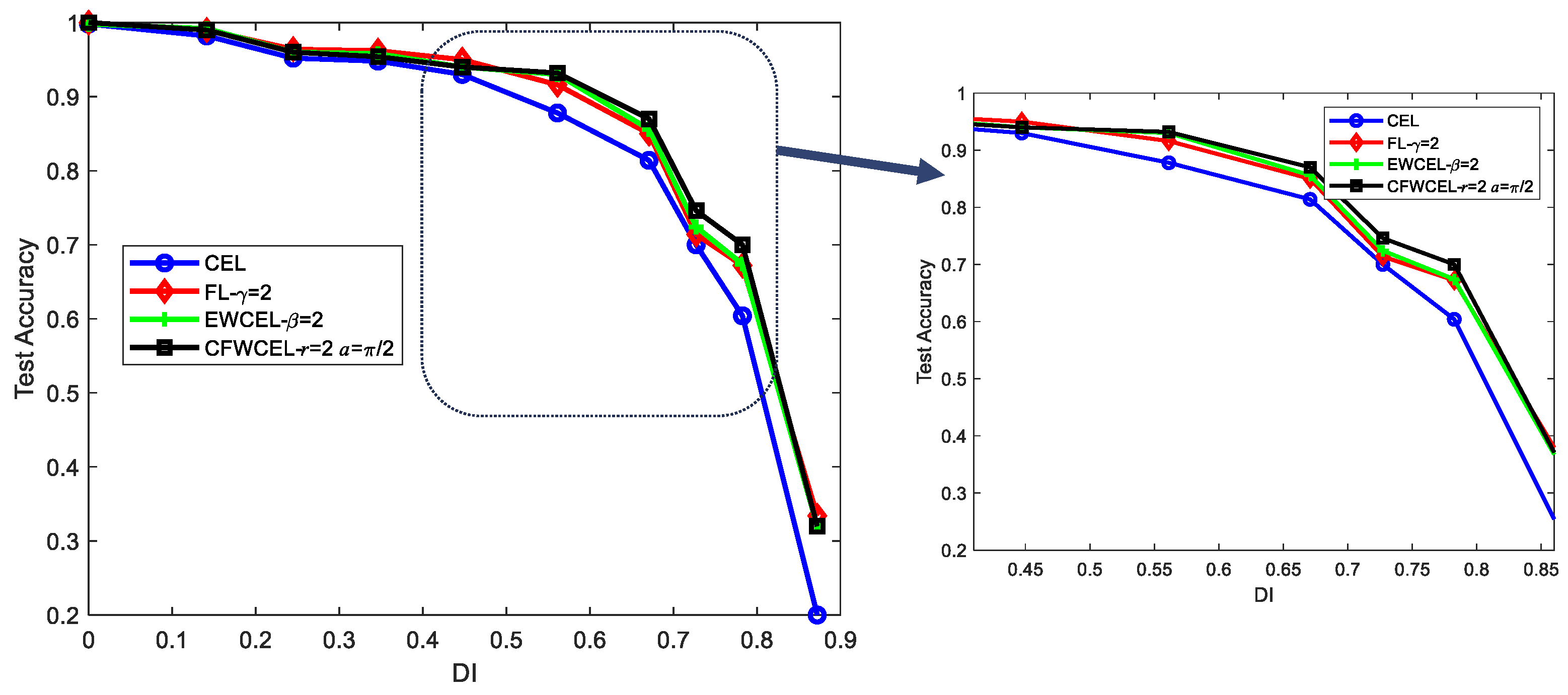
3.3.3. Imbalanced Data Experiments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luo, X.; Zhang, M.; Liu, T.; Huang, M.; Xu, X. An Underwater Acoustic Target Recognition Method Based on Spectrograms with Different Resolutions. J. Mar. Sci. Eng. 2021, 9, 1246. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, Y.; Shi, J.; Leng, H.; Zhao, Y.; Guo, J. Surface and Underwater Acoustic Source Discrimination Based on Machine Learning Using a Single Hydrophone. J. Mar. Sci. Eng. 2022, 10, 321. [Google Scholar] [CrossRef]
- Su, T. Multiple neural networks-integrated underwater target classification based on fuzzy theory. J. Acoust. Soc. Am. 2000, 107, 2868. [Google Scholar] [CrossRef]
- Bianco, M.J.; Gerstoft, P.; Traer, J.; Ozanich, E.; Roch, M.A.; Gannot, S.; Deledalle, C.-A. Machine learning in acoustics: Theory and applications. J. Acoust. Soc. Am. 2019, 146, 3590–3628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Y.; Li, X.; Wang, Y. Extraction and classification of acoustic scattering from underwater target based on Wigner-Ville distribution. Appl. Acoust. 2018, 138, 52–59. [Google Scholar] [CrossRef]
- Li, S.; Yang, S.; Liang, J. Recognition of ships based on vector sensor and bidirectional long short-term memory networks. Appl. Acoust. 2020, 164, 107248. [Google Scholar] [CrossRef]
- Ferguson, E.L.; Ramakrishnan, R.; Williams, S.B.; Jin, C.T. Deep learning approach to passive monitoring of the underwater acoustic environment. J. Acoust. Soc. Am. 2016, 140, 3351. [Google Scholar] [CrossRef]
- Yang, K.; Zhou, X. Deep learning classification for improved bicoherence feature based on cyclic modulation and cross-correlation. J. Acoust. Soc. Am. 2019, 146, 2201–2211. [Google Scholar] [CrossRef]
- Wu, H.; Song, Q.; Jin, G. Deep Learning based Framework for Underwater Acoustic Signal Recognition and Classification. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Hohhot, China, 22–24 October 2018; pp. 385–388. [Google Scholar] [CrossRef]
- Dong, Y.; Shen, X.; Jiang, Z.; Wang, H. Recognition of imbalanced underwater acoustic datasets with exponentially weighted cross-entropy loss. Appl. Acoust. 2020, 174, 107740. [Google Scholar] [CrossRef]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3388–3415. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barandela, R.; Rangel, E.; Sánchez, J.S.; Ferri, F.J. Restricted Decontamination for the Imbalanced Training Sample Problem. In Progress in Pattern Recognition, Speech and Image Analysis (CIARP); Springer: Berlin/Heidelberg, Germany, 2003; Volume 2905, pp. 424–431. [Google Scholar] [CrossRef] [Green Version]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Networks 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning Deep Representation for Imbalanced Classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5375–5384. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Deep Imbalanced Learning for Face Recognition and Attribute Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2781–2794. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Liu, Y.; Wang, X. Gradient Harmonized Single-Stage Detector. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI2019), Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8577–8584. [Google Scholar]
- Jensen, J.; Tan, Z.-H. Minimum Mean-Square Error Estimation of Mel-Frequency Cepstral Features–A Theoretically Consistent Approach. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 186–197. [Google Scholar] [CrossRef]
- Brown, G.J.; Mill, R.W.; Tucker, S. Auditory-motivated techniques for detection and classification of passive sonar signals. J. Acoust. Soc. Am. 2008, 123, 3344. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Wu, D.; Han, X.; Zhu, Z. Feature Extraction of Underwater Target Signal Using Mel Frequency Cepstrum Coefficients Based on Acoustic Vector Sensor. J. Sensors 2016, 2016, 7864213. [Google Scholar] [CrossRef] [Green Version]
- Yan, J.; Sun, H.; Cheng, E.; Kuai, X.; Zhang, X. Ship Radiated Noise Recognition Using Resonance-Based Sparse Signal Decomposition. Shock Vib. 2017, 2017, 6930605. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Zhao, X.; Liu, D. Design and Optimization of 1D-CNN for Spectrum Recognition of Underwater Targets. Integr. Ferroelectr. 2021, 218, 164–179. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Shi, T.; Huang, M.; Xiao, Z. Multi-scale spectral feature extraction for underwater acoustic target recognition. Measurement 2020, 166, 108227. [Google Scholar] [CrossRef]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Escalera, S.; Pujol, O.; Radeva, P. Separability of ternary codes for sparse designs of error-correcting output codes. Pattern Recognit. Lett. 2009, 30, 285–297. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dataset | Feature | Accuracy/% |
|---|---|---|---|
| SVM [29] | ShipsEar | MFCC(98, 12) | 81.58% |
| DEMON(60, 50) | 86.06% | ||
| HHT(16, 350) | 80.08% | ||
| AUV | MFCC(93, 12) | 81.16% | |
| DEMON(60, 50) | 84.86% | ||
| HHT(14, 350) | 53.08% | ||
| Simple-CNN [9,27] | ShipsEar | MFCC(98, 12) | 96.24% |
| DEMON(60, 50) | 30.08% | ||
| HHT(16, 350) | 23.14% | ||
| AUV | MFCC(93, 12) | 92.12% | |
| DEMON(60, 50) | 54.61% | ||
| HHT(14, 350) | 49.15% |
| Dataset | Method | Accuracy/% |
|---|---|---|
| ShipsEar | SVM [29] | 81.58 |
| Simple-CNN [9,27] | 96.24 | |
| MR-CNN-A | 98.87 | |
| AUV | SVM [29] | 81.16 |
| Simple-CNN [9,27] | 92.12 | |
| MR-CNN-A | 98.26 |
| Dataset | SNR/dB | MR-CNN-A | Simple-CNN [9,27] | SVM [29] |
|---|---|---|---|---|
| ShipsEar | ~ | 98.87% | 96.24% | 81.58% |
| 5 | 98.50% | 92.10% | 78.96% | |
| 3 | 97.50% | 91.35% | 78.20% | |
| 1 | 96.36% | 90.98% | 77.82% | |
| 0 | 95.50% | 86.84% | 75.20% | |
| −1 | 95.12% | 78.57% | 72.06% | |
| −3 | 93.62% | 76.69% | 70.30% | |
| −5 | 91.74% | 73.80% | 69.50% | |
| −10 | 88.36% | 72.56% | 64.30% |
| DI of Train Data | Train Samples Distribution | Test Samples Distribution |
|---|---|---|
| 0 | 0.2, 0.2, 0.2, 0.2, 0.2 | 0.2, 0.2, 0.2, 0.2, 0.2 |
| 0.1414 | 0.2, 0.2, 0.3, 0.1, 0.2 | |
| 0.2449 | 0.1, 0.2, 0.4, 0.1, 0.2 | |
| 0.3464 | 0.1, 0.2, 0.5, 0.1, 0.1 | |
| 0.4472 | 0.1, 0.1, 0.6, 0.1, 0.1 | |
| 0.5612 | 0.1, 0.1, 0.7, 0.05, 0.05 | |
| 0.6708 | 0.05, 0.05, 0.8, 0.05, 0.05 | |
| 0.7272 | 0.025, 0.025, 0.85, 0.05, 0.05 | |
| 0.7826 | 0.025, 0.025, 0.9, 0.025, 0.025 | |
| 0.8721 | 0.005, 0.005, 0.98, 0.005, 0.005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Liu, M.; Zhang, Y.; Zhang, B.; Xu, K.; Zou, B.; Huang, Z. Imbalanced Underwater Acoustic Target Recognition with Trigonometric Loss and Attention Mechanism Convolutional Network. Remote Sens. 2022, 14, 4103. https://doi.org/10.3390/rs14164103
Ma Y, Liu M, Zhang Y, Zhang B, Xu K, Zou B, Huang Z. Imbalanced Underwater Acoustic Target Recognition with Trigonometric Loss and Attention Mechanism Convolutional Network. Remote Sensing. 2022; 14(16):4103. https://doi.org/10.3390/rs14164103
Chicago/Turabian StyleMa, Yanxin, Mengqi Liu, Yi Zhang, Bingbing Zhang, Ke Xu, Bo Zou, and Zhijian Huang. 2022. "Imbalanced Underwater Acoustic Target Recognition with Trigonometric Loss and Attention Mechanism Convolutional Network" Remote Sensing 14, no. 16: 4103. https://doi.org/10.3390/rs14164103