
Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism

Abstract
:1. Introduction
- -
- The band information and angle information provided by the data are fully utilized. The influence of different band information and different observation angle information on experimental accuracy is also considered.
- -
- Use 3D U-net as the benchmark network model. While classifying pixels, the texture information of clouds is preserved as much as possible. This benefits from the jump connection structure between the encoder and the decoder.
- -
- A dual-channel attention mechanism is proposed to extract useful information from band and angle, respectively.
2. Related Work
2.1. Three-Dimensional U-Net
2.1.1. U-Net
2.1.2. Three-Dimensional U-Net
2.2. SE-Net
3. Datasets
3.1. Data Sources and Data Formats
3.2. Data Processing
3.3. Data Augmentation
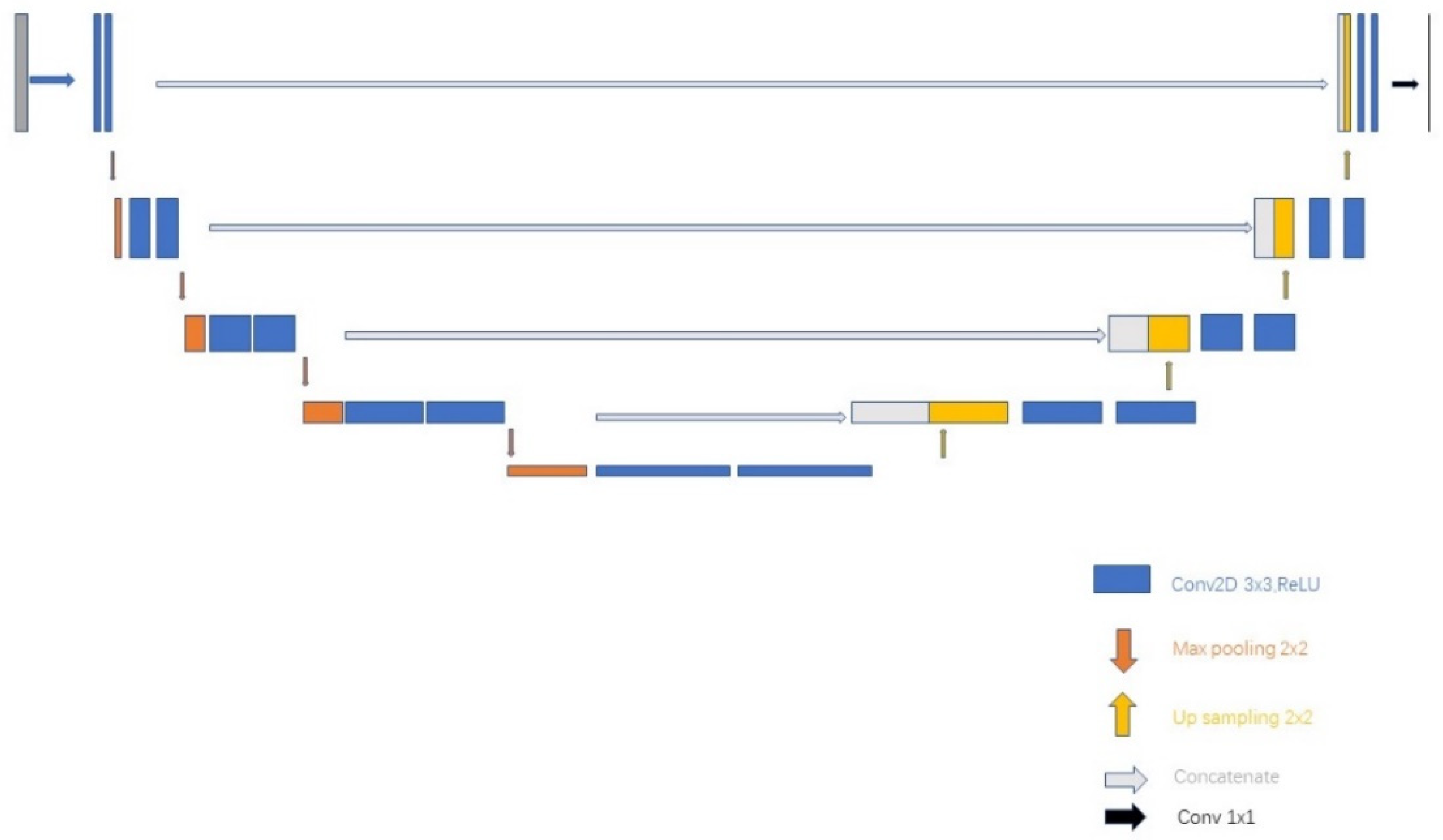
4. Method
4.1. Overall Framework of Network
4.2. Improvement of 3D U-Net
4.3. Loss
5. Experiments
5.1. Experimental Settings
5.2. Ablation Experiments
5.3. Comparative Experiments with Other Methods
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zeng, S.; Parol, F.; Riedi, J.; Cornet, C.; Thieuleux, F. Examination of POLDER/PARASOL and MODIS/Aqua Cloud Fractions and Properties Representativeness. J. Clim. 2011, 24, 4435–4450. [Google Scholar] [CrossRef]
- Dubovik, O.; Li, Z.; Mishchenko, M.I.; Tanré, D.; Karol, Y.; Bojkov, B.; Cairns, B.; Diner, D.J.; Espinosa, W.R.; Goloub, P.; et al. Polarimetric remote sensing of atmospheric aerosols: Instruments, methodologies, results, and perspectives. J. Quant. Spectrosc. Radiat. Transf. 2019, 224, 474–511. [Google Scholar] [CrossRef]
- Yunzhu, S.; Guangwei, J.; Yunduan, L.; Yong, Y.; Haishan, D.; Jun, H.; Qinghao, Y.; Qiong, C.; Changzhe, D.; Shaohua, Z.; et al. GF-5 Satellite: Overview and Application Prospects. Spacecr. Recovery Remote Sens. 2018, 39, 1–13. [Google Scholar]
- Li, Z.; Hou, W.; Hong, J.; Zheng, F.; Luo, D.; Wang, J.; Gu, X.; Qiao, Y. Directional Polarimetric Camera (DPC): Monitoring aerosol spectral optical properties over land from satellite observation. J. Quant. Spectrosc. Radiat. Transf. 2018, 218, 21–37. [Google Scholar] [CrossRef]
- Saunders, R.W.; Kriebel, K.T. An improved method for detecting clear sky and cloudy radiances from AVHRR dats. Int. J. Remote Sens. 1988, 9, 123–150. [Google Scholar] [CrossRef]
- Buriez, J.C.; Vanbauce, C.; Parol, F.; Goloub, P.; Seze, G. Cloud detection and derivation of cloud properties from POLDER. Int. J. Remote Sens. 1997, 18, 2785–2813. [Google Scholar] [CrossRef]
- Tengteng, L.; Xinming, T.; Xiaoming, G. Research on Separation of Snow and Cloud in ZY-3 Images Cloud Recognition. Bull. Surv. Mapp. 2016, 2, 46–49. [Google Scholar]
- Souri, A.H.; Saradjian, M.R.; Nia, S.S.; Shahrisvand, M. Comparison of Using SVM and MLP Neural Network for Cloud Detection in MODIS Imagery. Int. J. Remote Sens. 2013, 2, 21–31. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Comput. Sci. 2014, 357–361. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. IEEE Comput. Soc. 2016. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Springer Int. Publ. 2015, 9351, 234–241. [Google Scholar]
- Haitao, W.; Yichen, W.; Yongqiang, W.; Yurong, Q. Cloud Detection of Landsat Image Based on MS-UNet. Laser Optoelectron. Prog. 2021, 58, 8. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient Multi-Scale 3D CNN with Fully Connected CRF for Accurate Brain Lesion Segmentation. Med. Image Anal. 2016, 36, 61. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Hao, W.; Jingjing, Z.; Yuanyuan, L.; Feng, W.; Lina, X. Hyperspectral Image Classification Based on 3D Convolution Joint Attention Mechanism. Infrared Technol. 2020, 42, 8. [Google Scholar]
- Cong’an, X.; Yafei, L.; Xiaohan, Z.; Yu, L.; Chenhao, C.; Xiangqi, G. A Discriminative Feature Representation Method Based on Dual Attention Mechanism for Remote Sensing Image Scene Classification. J. Electron. Inf. Technol. 2021, 43, 683–691. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Xiaomin, S.; Lijuan, Z.; Jun, W.; Qian, C.; Chongbin, X.; Yang, M.; Zhen, C. Land Classification of GF-5 Satellite Hyperspectral Images Using U-net Model. Spacecr. Recovery Remote Sens. 2019, 40, 8. [Google Scholar]
- Jianmin, S.; Lanxin, Y.; Weipeng, J. U-net Based Semantic Segmentation Method for High Resolution Remote Sensing Image. Comput. Eng. Appl. 2019, 55, 207–213. [Google Scholar]
- Yuyang, C.; Bin, S.; Chan, H.; Jin, H.; Yanli, Q. Cloud Detection and Parameter Inversion Using Multi-Directional Polarimetric Observations. Acta Opt. Sin. 2020, 40, 11. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Parameter Setting |
|---|---|
| Conv3D | 3 × 3 × 3,” relu”, padding = same, BatchNormalization |
| Dropout | 0.5 |
| Maxpooling3D | 2 × 2 × 1 |
| UpSampling3D | 2 × 2 × 1 |
| Conv2D | 3 × 3,” relu”, padding = same, BatchNormalization |
| Evaluation Index | Computational Formula |
|---|---|
| PA | |
| CPA | |
| Recall | |
| F1 | |
| IoU |
| PA | CPA | Recall | F1 | IoU | |
|---|---|---|---|---|---|
| 3D U-net | 86.12% | 83.97% | 96.38% | 89.75% | 81.13% |
| 3D U-net + BA | 86.96% | 85.02% | 97.17% | 90.69% | 82.96% |
| 3D U-net + AA | 92.53% | 91.41% | 96.58% | 93.92% | 89.58% |
| 3D U-net + BA + AA (Concatenation Fusion) | 92.13% | 90.64% | 98.08% | 94.21% | 89.06% |
| 3D U-net + BA + AA (Maximum Fusion) | 92.66% | 92.51% | 97.76% | 95.06% | 89.63% |
| PA | CPA | Recall | F1 | IoU | Efficiency (Seconds) | |
|---|---|---|---|---|---|---|
| Seg-Net | 88.32% | 87.91% | 90.55% | 89.21% | 83.56% | 60.01 |
| FCN | 86.20% | 86.62% | 92.08% | 89.27% | 80.61% | 46.53 |
| PSP-Net | 90.55% | 89.43% | 93.06% | 91.20% | 81.96% | 75.10 |
| U-Net | 91.26% | 90.73% | 95.76% | 93.18% | 87.23% | 49.95 |
| Ours | 92.66% | 92.51% | 97.76% | 95.06% | 89.63% | 132.19 |
| PA | CPA | Recall | F1 | IoU | |
|---|---|---|---|---|---|
| Seg-Net | 88.18% | 88.43% | 58.06% | 73.04% | 80.53% |
| FCN | 82.59% | 73.31% | 57.87% | 64.68% | 75.80% |
| PSP-Net | 90.62% | 90.74% | 76.62% | 83.08% | 77.10% |
| U-Net | 91.84% | 93.78% | 77.30% | 84.74% | 83.34% |
| Ours | 92.81% | 93.83% | 79.12% | 85.86% | 86.22% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Q.; Liu, H.; Zhang, J.; Sun, X.; Xiong, W.; Zou, M.; Xia, Y.; Xun, L. Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism. Remote Sens. 2022, 14, 3710. https://doi.org/10.3390/rs14153710
Yan Q, Liu H, Zhang J, Sun X, Xiong W, Zou M, Xia Y, Xun L. Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism. Remote Sensing. 2022; 14(15):3710. https://doi.org/10.3390/rs14153710
Chicago/Turabian StyleYan, Qing, Hu Liu, Jingjing Zhang, Xiaobing Sun, Wei Xiong, Mingmin Zou, Yi Xia, and Lina Xun. 2022. "Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism" Remote Sensing 14, no. 15: 3710. https://doi.org/10.3390/rs14153710