
Scene Changes Understanding Framework Based on Graph Convolutional Networks and Swin Transformer Blocks for Monitoring LCLU Using High-Resolution Remote Sensing Images


Abstract
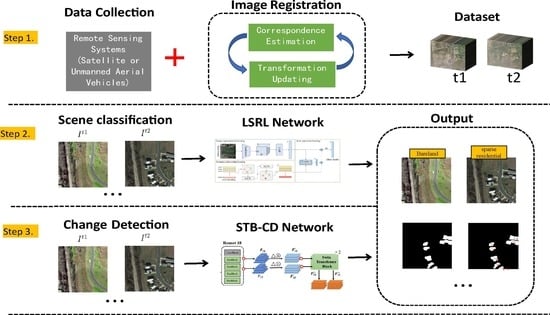
:
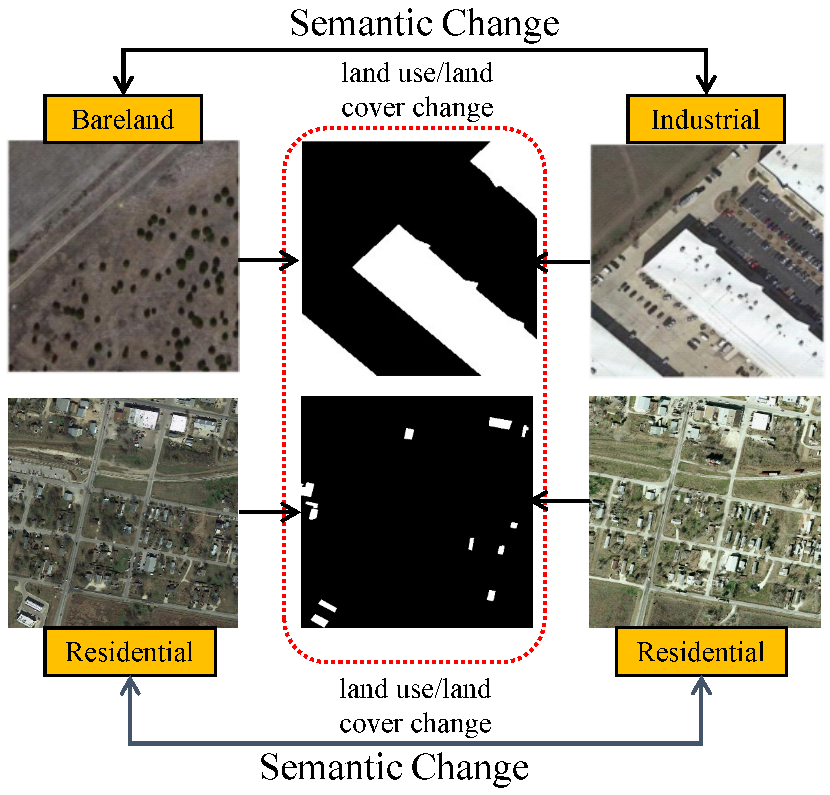
1. Introduction
- 1
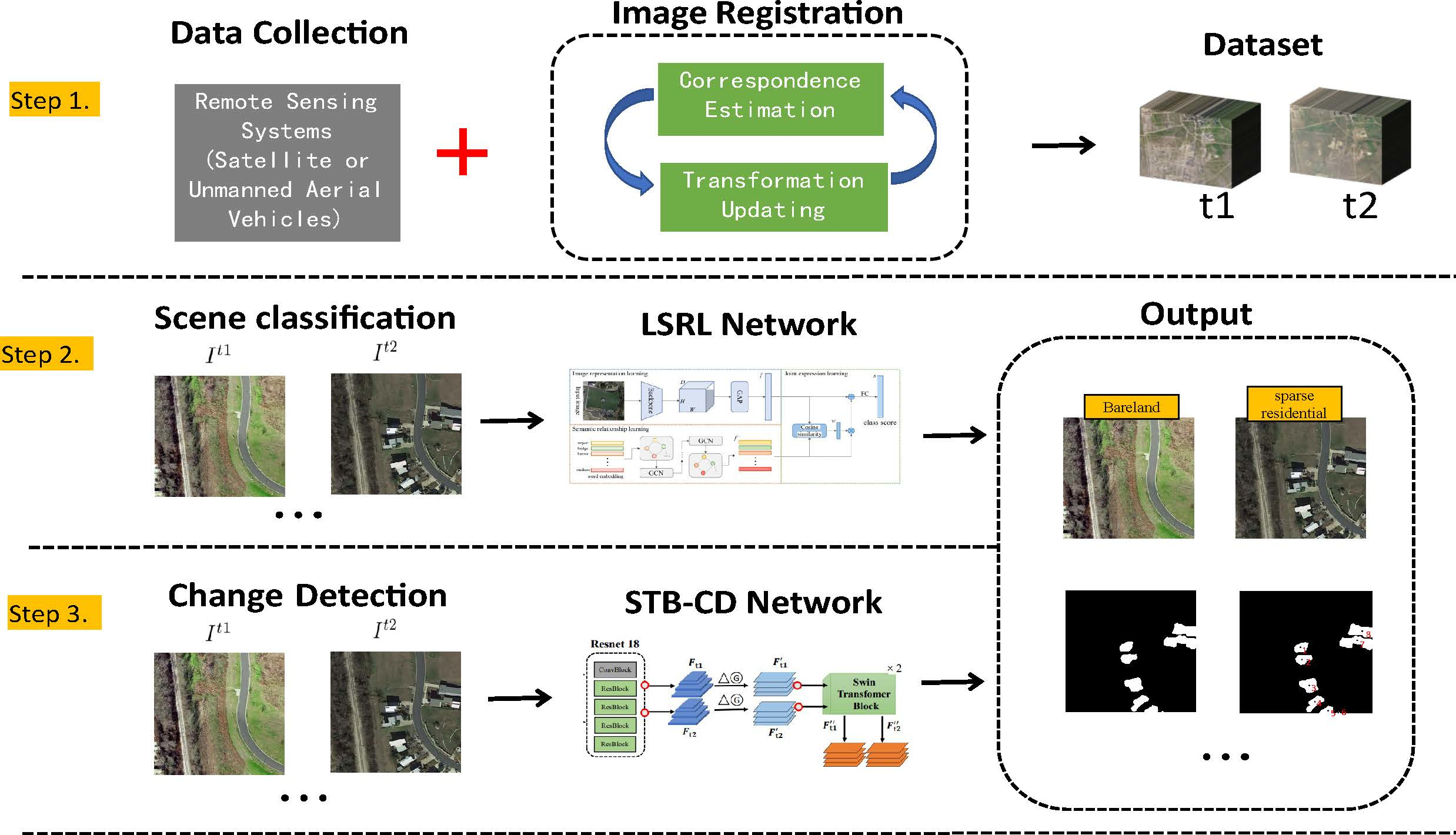
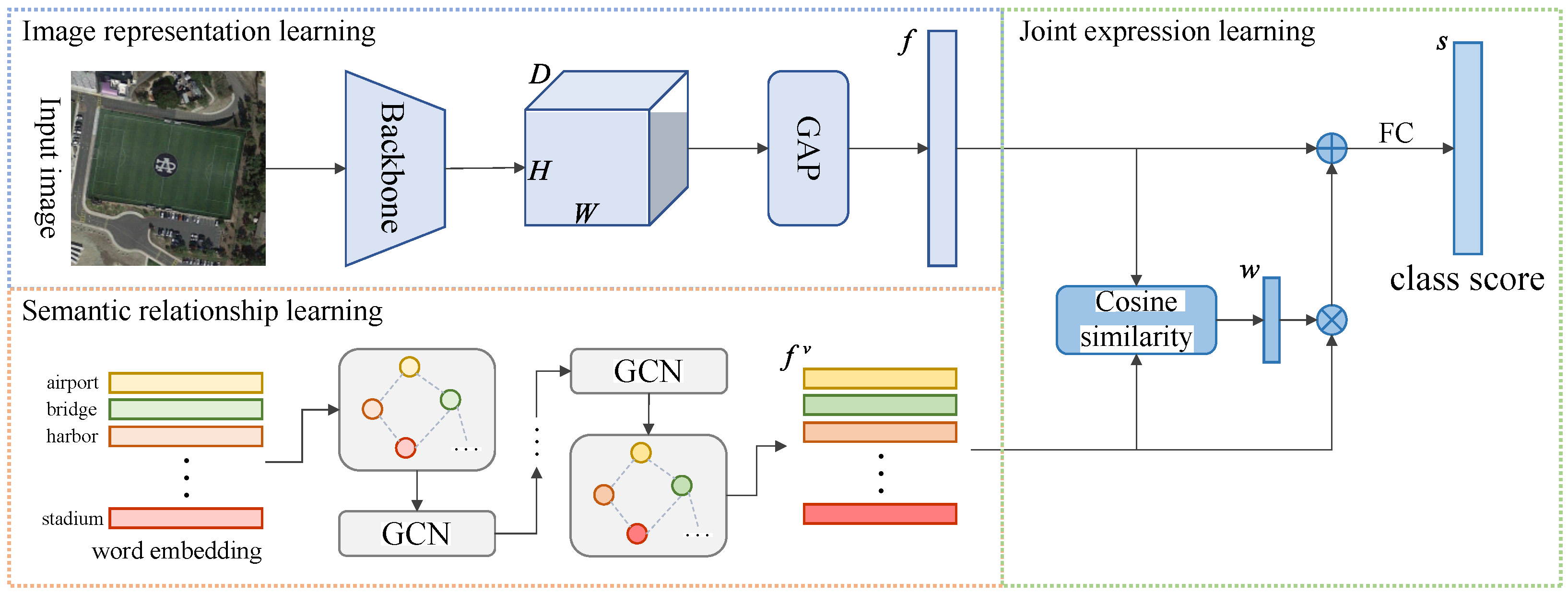
- Based on EfficientNet, a robust LSRL network for scene classification is proposed. It consists of a semantic relation learning module based on graph convolutional networks and a joint expression learning framework based on similarity.
- 2
- Simultaneously, we propose STB-CD for change detection on remote sensing images. STB-CD makes full use of the spatial and contextual relationships of the swin transformer blocks to identify areas of variation in buildings and green spaces of various scales.
- 3
- The experiment results on the LEVIR-CD, NWPU-RESISC45, and AID datasets demonstrate the superiority of the two methods over state-of-the-art.
2. Related Works
2.1. Scene Classification on Remote Sensing Images
2.2. Change Detection on Remote Sensing Images
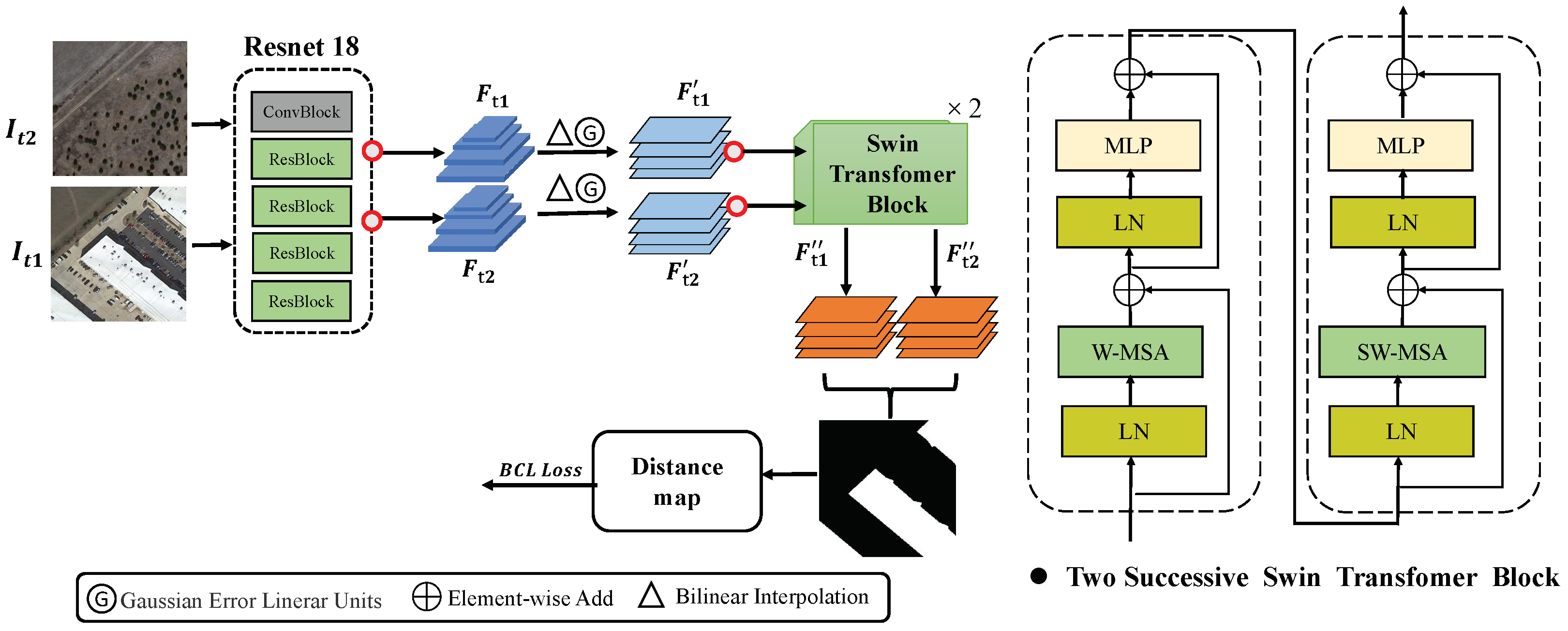
3. Methodology
3.1. Scene Classification of Remote Sensing Images
3.2. Change Detection on Remote Sensing Images
4. Experiments
4.1. Datasets
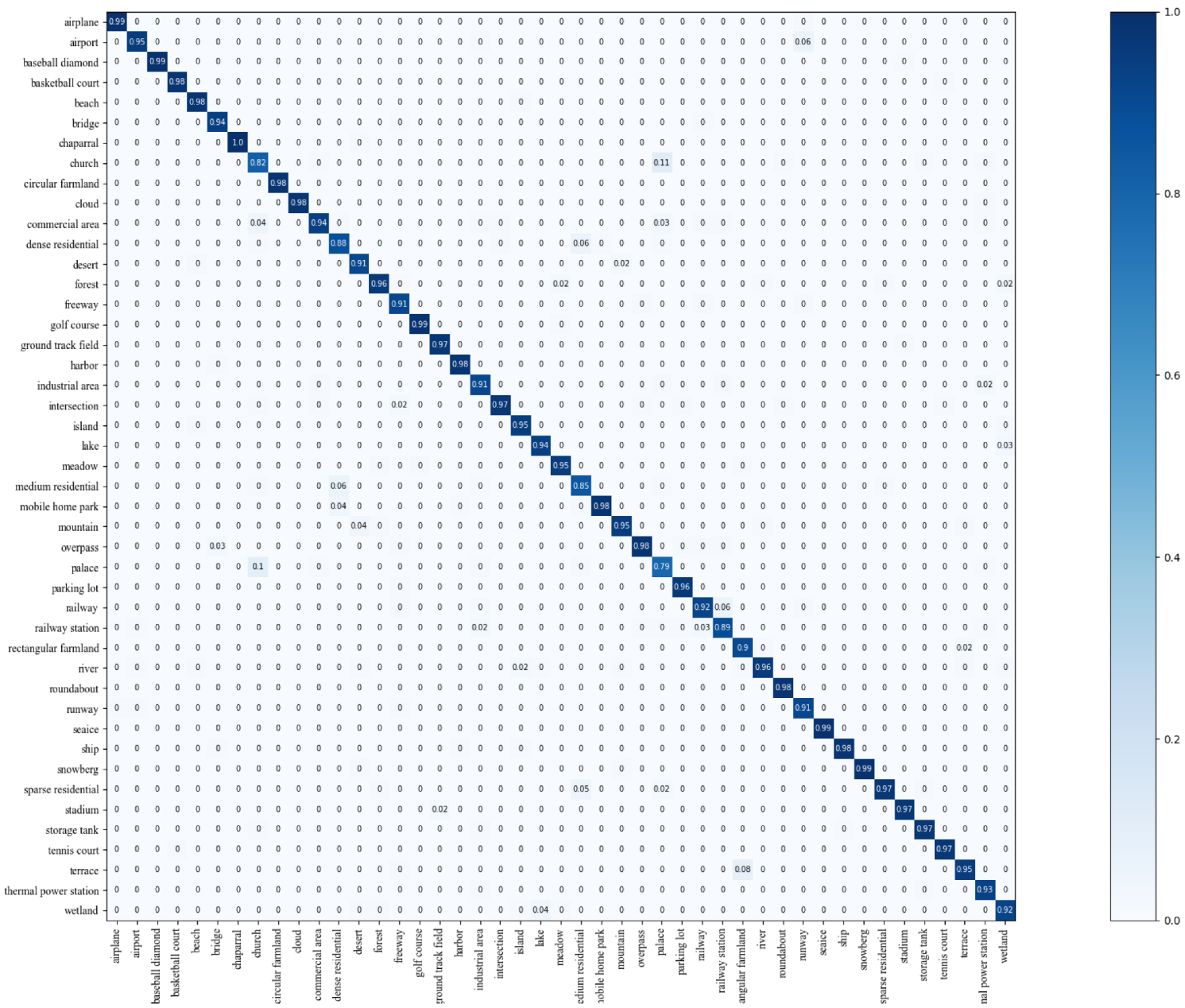
- NWPU-RESISC45 dataset [18] is the most widely used benchmark for remote sensing scene classification at the moment. It is made up of 31,500 images, covering 45 scene categories: mountain, runway, sea ice, ship, stadium, airplane, desert, circular farmland, basketball court, forest, meadow, airport, baseball diamond, bridge, beach, mobile home park, overpass, palace, river, roundabout, snow berg, harbor, storage tank, church, cloud, lake, commercial area, railway, intersection, railway station, industrial area, rectangular farmland, tennis court, chaparral, dense residential, freeway, sparse residential, terrace, thermal power station, island, wetland, golf course, ground track field, and medium residential. There are 700 images in each category, each having a resolution of pixels. When conducting evaluation experiments, a wide range of training and test set ratios are used: 1:9 and 2:8.
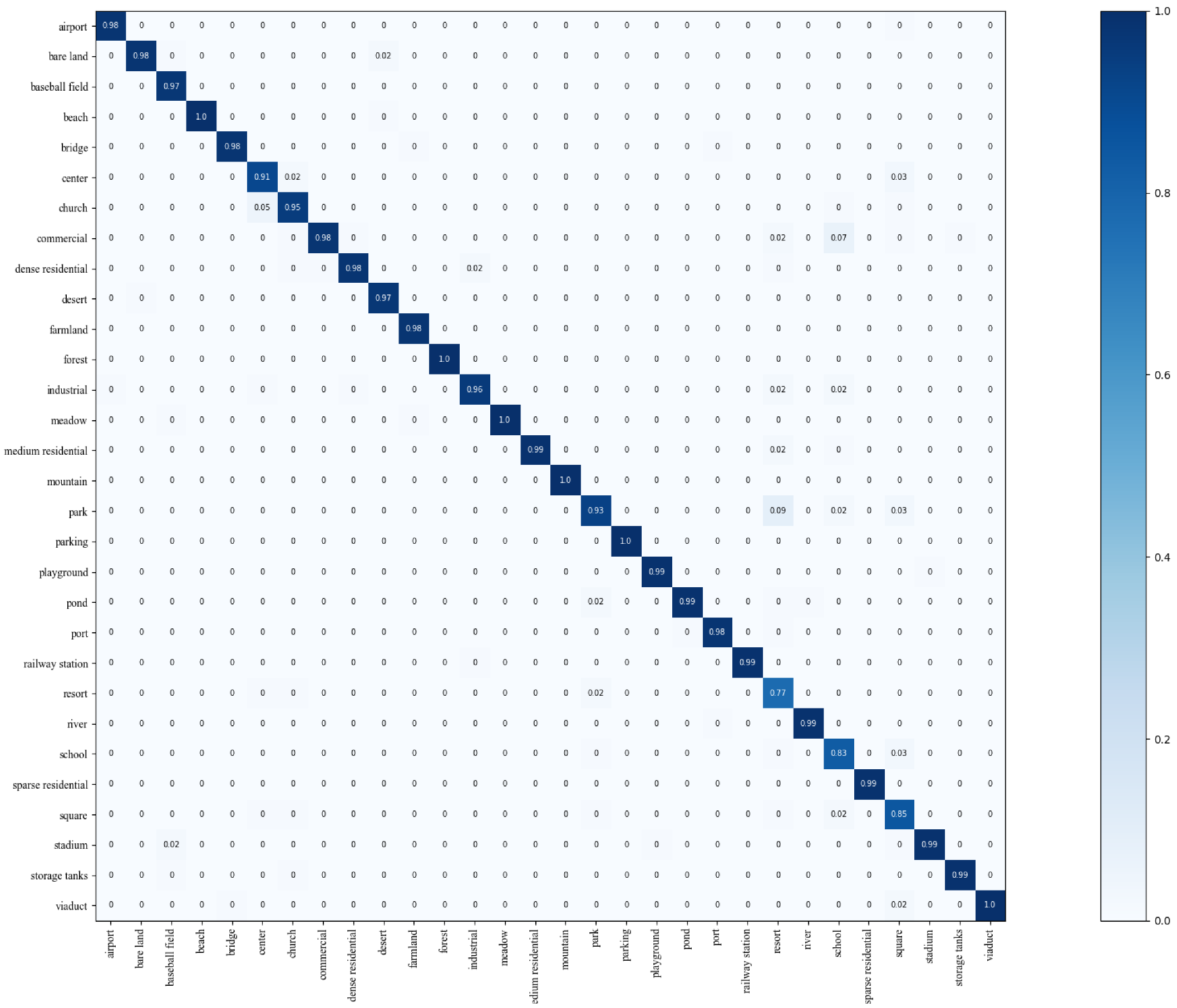
- Aerial Image Dataset (AID) [19] is a multi-source aerial scene classification dataset captured with different sensors. 10,000 photos of a pixel size are included, consisting of 30 scene categories, including mountain, park, desert, farmland, forest, industrial, river, school, sparse residential, square, airport, bare land, baseball field, railway station, resort, stadium, beach, bridge, center, church, parking, playground, pond, commercial, dense residential, meadow, port, storage tanks, viaduct, and medium residential. Each category has 220 to 420 images. When conducting evaluation experiments, a wide range of training and test set ratios are used: 2:8 and 5:5.
- LEVIR-CD [20] is a public large scale building change detection dataset, which contains 637 pairs of very high-resolution (0.5 m/pixel) remote sesing images of size pixels. LEVIR-CD includes different types of buildings, such as small garages, large warehouses, villa residences, and tall apartments. We follow its default dataset segmentation rules. In addition, the image is cut into small pieces without overlap. Finally, patch pairs were obtained for training, validation, and testing, respectively.
| Algorithm 1: Scene Changes Understanding Framework based on Graph Convolutional Networks and Swin Transformer Blocks for Monitoring LCLU using High-Resolution Remote Sensing Images. |
Input: A pair of images of size taken at time and , respectively. Output: Semantic changes and distance map . ⊳Scene classification on remote sensing images (LSRL). (i) Image representation learning: extract a feature map of size via EfficientNet; obtain the D-dimensional image features . (ii) Semantic relationship learning: compute the adjacency matrix A between different scene categories by Equation ; learn to convey information about the potential semantic relationships between different categories using graph GCN. (iii) Joint expression learning: obtain the coefficient vector w by Equation ; Then, to reduce the amount of operations and avoid the interference of redundant features, the category label vectors are calculated by Equation . ⊳Change detection on remote sensing images (STB-CD). (i) Multiscale feature extraction learning. extract multiscale features and via ResNet 18; (ii) Spatial relations learning: compute a distance map D between reconstructed features and by Equation (6); (iii) Loss function: |
4.2. Evaluation Criteria
4.3. Implementation Details
4.4. Comparisons of Scene Classification
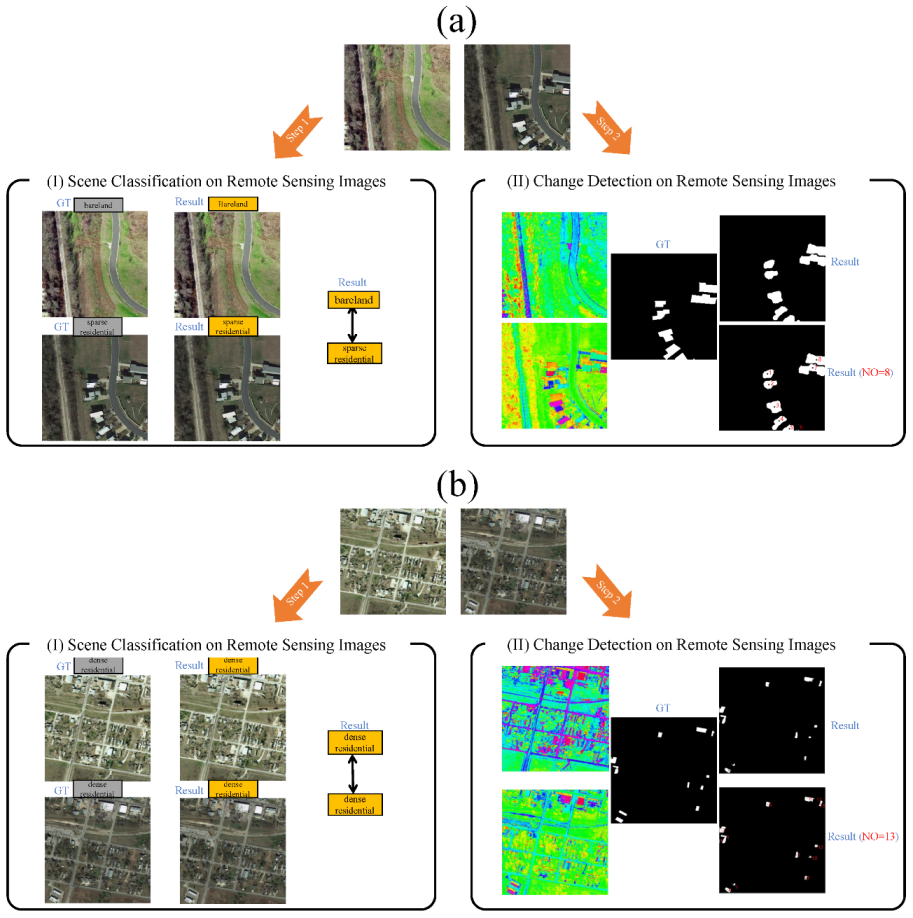
4.5. Comparisons of Change Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CD | Change Detection |
| LCLU | Land Cover and Land Use |
| LSRL | The Label Semantic Relation Learning |
| DCVA | The Deep Change Vector Analysis |
| GCN | Graph Convolutional Networks |
| MDFR | Multi-scale Deep Feature Representation |
| SAFF | Self-attention-based Deep Feature Fusion |
| H-GCN | High-order Graph Convolutional Network |
| DMA | The Dual-Model Architecture |
| SEMSDNet | Multiscale Dense Networks with Squeeze and Excitation Attention |
| LCNN-CMGF | Lightweight Convolutional Neural Network based on Channel |
| Multi-Group Fusion | |
| DSAMNet | Deep Supervised Attention Metric Network |
| FC-Siam-conc, | Three Different Types of Fully Convolutional Neural Networks |
| FC-Siam-diff, and | |
| FC-early fusion | |
| STANet | Spatial–temporal Attention Neural Network |
References
- Zhang, X.; Xiao, P.; Feng, X.; Yuan, M. Separate segmentation of multi-temporal high-resolution remote sensing images for object-based change detection in urban area. Remote Sens. Environ. 2017, 201, 243–255. [Google Scholar] [CrossRef]
- Yang, G.; Zhao, Y.; Xing, H.; Fu, Y.; Liu, G.; Kang, X.; Mai, X. Understanding the changes in spatial fairness of urban greenery using time-series remote sensing images: A case study of Guangdong-Hong Kong-Macao Greater Bay. Sci. Total Environ. 2020, 715, 136763. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Satoh, Y.; Suzuki, R.; Iwata, K.; Kataoka, H. Indoor scene change captioning based on multimodality data. Sensors 2020, 20, 4761. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Satoh, Y.; Suzuki, R.; Iwata, K.; Kataoka, H. 3d-aware scene change captioning from multiview images. IEEE Robot. Autom. Lett. 2020, 5, 4743–4750. [Google Scholar] [CrossRef]
- Hall, D.; Talbot, B.; Bista, S.R.; Zhang, H.; Smith, R.; Dayoub, F.; Sünderhauf, N. The robotic vision scene understanding challenge. arXiv 2020, arXiv:2009.05246. [Google Scholar]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Song, F.; Yang, Z.; Gao, X.; Dan, T.; Yang, Y.; Zhao, W.; Yu, R. Multi-scale feature based land cover change detection in mountainous terrain using multi-temporal and multi-sensor remote sensing images. IEEE Access 2018, 6, 77494–77508. [Google Scholar] [CrossRef]
- Song, F.; Zhang, S.; Lei, T.; Song, Y.; Peng, Z. MSTDSNet-CD: Multiscale Swin Transformer and Deeply Supervised Network for Change Detection of the Fast-Growing Urban Regions. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6508505. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Shen, J.; Zhang, T.; Wang, Y.; Wang, R.; Wang, Q.; Qi, M. A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 433. [Google Scholar] [CrossRef]
- Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised deep change vector analysis for multiple-change detection in VHR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3677–3693. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Benediktsson, J.A. Object-oriented key point vector distance for binary land cover change detection using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6524–6533. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A deeply supervised attention metric-Based network and an open aerial image dataset for remote sensing change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604816. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, M.; Shi, L.; Yan, W.; Pan, B. A multi-scale approach for remote sensing scene classification based on feature maps selection and region representation. Remote Sens. 2019, 11, 2504. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of high-spatial-resolution remote sensing scenes method using transfer learning and deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Cao, R.; Fang, L.; Lu, T.; He, N. Self-attention-based deep feature fusion for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2020, 18, 43–47. [Google Scholar] [CrossRef]
- Alhichri, H.; Alswayed, A.S.; Bazi, Y.; Ammour, N.; Alajlan, N.A. Classification of remote sensing images using EfficientNet-B3 CNN model with attention. IEEE Access 2021, 9, 14078–14094. [Google Scholar] [CrossRef]
- Gao, Y.; Shi, J.; Li, J.; Wang, R. Remote sensing scene classification based on high-order graph convolutional network. Eur. J. Remote Sens. 2021, 54, 141–155. [Google Scholar] [CrossRef]
- Tian, T.; Li, L.; Chen, W.; Zhou, H. SEMSDNet: A multiscale dense network with attention for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5501–5514. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, X.; Wang, L. A Lightweight Convolutional Neural Network Based on Channel Multi-Group Fusion for Remote Sensing Scene Classification. Remote Sens. 2021, 14, 9. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | 20% Training Ratio | 50% Training Ratio |
|---|---|---|
| MDFR [21] | 90.62 ± 0.27 | 93.37 ± 0.29 |
| VGG19 [22] | 87.73 ± 0.25 | 91.71 ± 0.24 |
| SAFF [23] | 90.25 ± 0.29 | 93.83 ± 0.28 |
| EfficientNetB3-Attn-2 [24] | 92.48 ± 0.76 | 95.39 ± 0.43 |
| H-GCN [25] | 93.06 ± 0.26 | 95.78 ± 0.37 |
| DMA [12] | 94.05 ± 0.10 | 96.12 ± 0.14 |
| LSRL (ours) | 96.44 ± 0.10 | 97.36 ± 0.21 |
| Methods | 10% Training Ratio | 20% Training Ratio |
|---|---|---|
| MDFR [21] | 83.37 ± 0.26 | 86.89 ± 0.17 |
| VGG19 [22] | 81.34 ± 0.32 | 83.57 ± 0.37 |
| SAFF [23] | 84.38 ± 0.19 | 87.86 ± 0.14 |
| H-GCN [25] | 91.39 ± 0.19 | 93.62 ± 0.28 |
| SEMSDNet [26] | 91.68 ± 0.39 | 93.89 ± 0.63 |
| LCNN-CMGF [27] | 92.53 ± 0.56 | 94.18 ± 0.35 |
| LSRL (ours) | 93.45 ± 0.16 | 94.27 ± 0.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Song, F.; Jeon, G.; Sun, R. Scene Changes Understanding Framework Based on Graph Convolutional Networks and Swin Transformer Blocks for Monitoring LCLU Using High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3709. https://doi.org/10.3390/rs14153709
Yang S, Song F, Jeon G, Sun R. Scene Changes Understanding Framework Based on Graph Convolutional Networks and Swin Transformer Blocks for Monitoring LCLU Using High-Resolution Remote Sensing Images. Remote Sensing. 2022; 14(15):3709. https://doi.org/10.3390/rs14153709
Chicago/Turabian StyleYang, Sihan, Fei Song, Gwanggil Jeon, and Rui Sun. 2022. "Scene Changes Understanding Framework Based on Graph Convolutional Networks and Swin Transformer Blocks for Monitoring LCLU Using High-Resolution Remote Sensing Images" Remote Sensing 14, no. 15: 3709. https://doi.org/10.3390/rs14153709