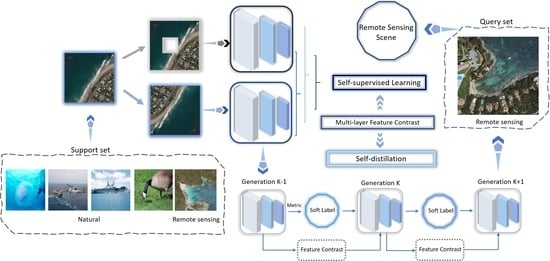
To overcome the challenge of classifying a few-shot remote sensing image scene, we need to consider how to endow the model with enough prior knowledge and how to enforce the model to learn better in a limited number of remote sensing images. Comparing self-supervised learning and meta-learning, we can see that learning by self-supervision and meta-learning solve the problem of how to train the model to realize classification with few or even no labeled data from two aspects. Meta-learning pays more attention to a small number of training samples. In self-supervised learning, the samples have no labels. By constantly mining the supervision information contained in the data, the feature extraction ability of the network is strengthened, and the network has a good effect on downstream tasks. Meta-learning and learning by self-supervision and meta-learning are complementary in few-shot problems. Therefore, the SSMR method proposed in this paper combines them and uses self-supervised learning based on multi-layer feature contrast to train an embedding network for meta-learning training. Furthermore, it uses the self-distillation based on multi-layer feature contrast to improve the performance of the method in the scene classification mission of few-shot remote sensing images. By comparing the differences between the features extracted from different layers, the feature information contained in a small number of remote sensing images can also be used as the supervision for model training. We can obtain many pre-trained models as the embedding network from different sources. These models are pre-trained in large natural datasets and have strong performance. This requires that the target dataset has sufficient data to support the fine-tuning of the pre-trained models, which is a condition difficult to satisfy in few-shot remote sensing scenarios. At the same time, we want the embedding network to provide an excellent form of remote sensing image feature representation (metric) in meta-learning, while avoiding the occurrence of supervision collapse. In order to equip the embedding network with this capability, a series of designs are used in our method for training the model. These are not experienced by the pre-trained models. Therefore, we design a new method instead of using existing pre-trained models. The SSMR method flow diagram is shown in
Figure 1.
3.1. Self-Supervised Learning Embedding Network Training Based on Multilayer Feature Contrast
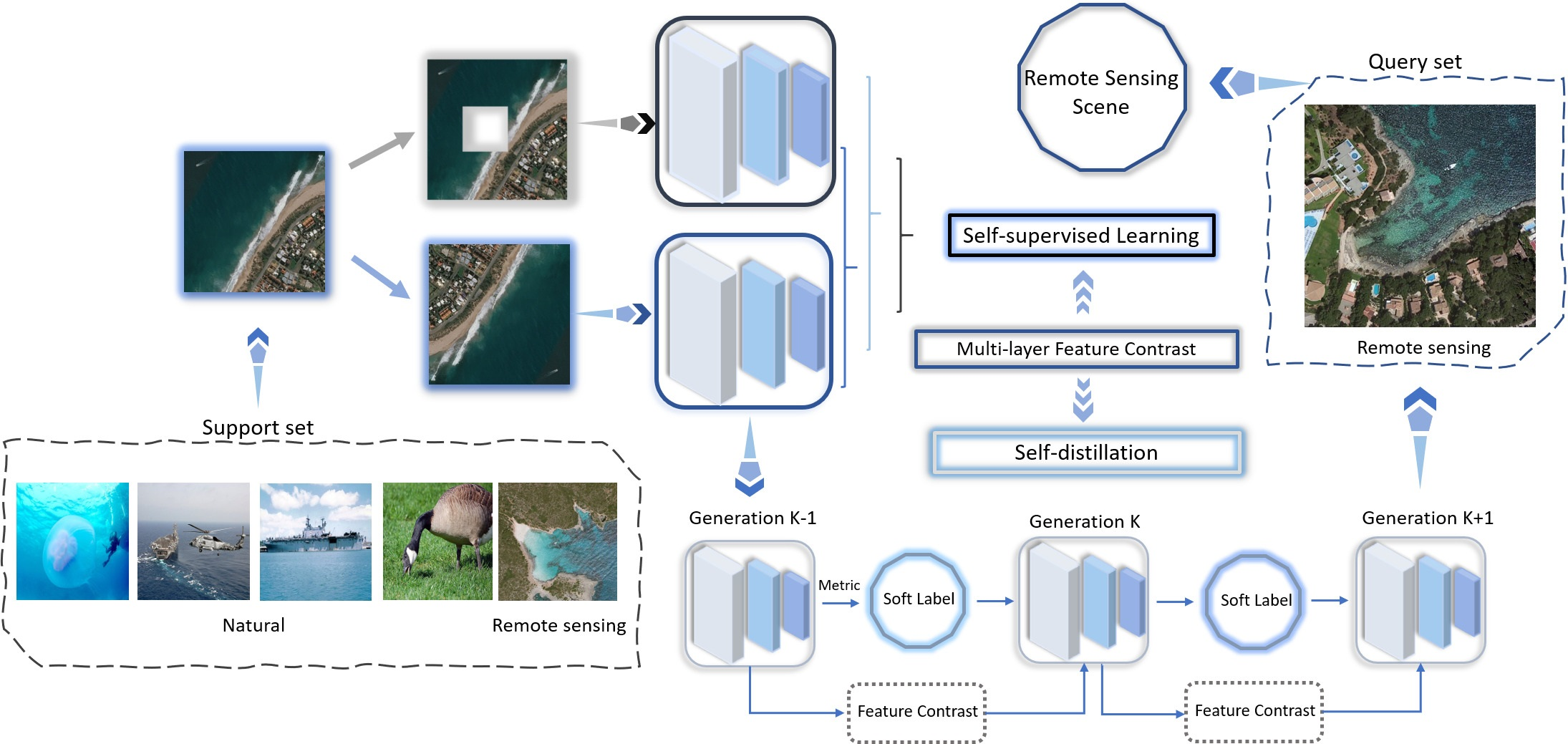
The first step to consider is how to acquire a good neural network embedding network . If the embedding network only obtains the feature information of the seen classes, the subsequent classifier will have difficulty in classifying the unseen classes correctly. The only supervision provided in the few-shot scenarios is a small number of labels. However, unlike the ordinary scene images, remote sensing images have rich texture feature information. Therefore, we choose self-supervised learning that can learn the feature information besides the labels and extract more valuable texture semantic features from the limited labeled input images to better train the embedding network.
Self-supervised learning trains the ability of the embedding network to extract feature information through pretext tasks. We choose the pretext task based on contrastive learning. Different views of a remote sensing image are generated and used as a feed to the embedding network. The embedding network is trained so that the difference between the output of two views from the same source becomes smaller and the difference between the output of views from different sources becomes larger. Finally, the embedding network learns the feature information that can be used for classification. However, compared with high-dimensional data, such as remote sensing images, the effect of using Mean Square Error and Cross-Entropy is not good. If a powerful conditional generation model is used to reconstruct each detail, a lot of computation will be required and the context in remote sensing images will be ignored. Therefore, we choose InfoNCE [
43] as the index to measure the mutual information between the comparison objects. InfoNCE compresses high-dimensional data into a more compact hidden space, in which a powerful autoregressive model is used to predict many steps in the future. By calculating the loss function (similar to the method of learning word embedding in the natural language model) through Noise Contrast Estimation, high-level information can be learned from data of multiple modes, such as image, sound, natural language, and reinforcement learning. During the procedure of training, the contrast learning of the embedding network is completed by guiding the increase of InfoNCE. Training the embedding network in this way helps to suppress overfitting in few-shot tasks.
The second step to consider is how to design a reasonable contrastive pretext task for self-supervised learning. Firstly, if we design the pretext task completely relying on the category label for learning, it can only learn the information related to the category and ignore other more general feature representation information. This defect is particularly obvious in few-shot scenarios. Secondly, when using remote sensing images for comparison, some important targets and scenes in remote sensing images are usually local, and the effect of direct contrastive learning with overall features is not necessarily the best. Especially when the resolution of remote sensing image is high, it is quite tough to obtain good results by directly using global features for contrastive learning; if a remote sensing image is directly represented by a feature vector or local feature map, a lot of information that can be used for classification will be lost, and this loss will be further expanded in few-shot scenarios; it is also difficult to directly use two different remote sensing images for local feature comparison. Even if two remote sensing images belong to the same category, their characteristics in local areas can be extremely different.
Considering the above problems, we adopt self-supervised learning designed as follows: in contrastive learning, the objects used for contrast are taken from multiple views enhanced by different data from the same remote sensing image. Data augmentation is an important method in deep learning, which can significantly enhance the richness of data and the functionality of the deep neural network. According to the characteristics of remote sensing images, we select methods such as random clipping, color jitter, and random gray transformation. Different methods of data augmentation are adopted for the same remote sensing image to expand the differences between different data augmentation results and avoid the collapse of contrastive learning. After obtaining a group of different remote sensing image views with the same source, they are inputted into the embedding network.
To endow the embedding network with the ability to perceive the global features and local features in remote sensing images, we select the feature maps generated by different convolution layers in the embedding network for contrast. The characteristics captured by different layers of the deep neural networks are different. The receptive field of a low-level layer is small and tends to capture local features; high-level layers have larger receptive fields and tend to respond to larger local and even global features. Remote sensing images from the same source will produce a set of similar features, and there will be great differences between the feature sets from different images. At the same time, the features generated by high-level layers come from the features generated by low-level layers. Contrastive learning between them can produce better high-level features. The ones used for contrastive learning may be 5 × 5 local features, 7 × 7 local features, and feature maps outputted after any convolution layer. Suppose
and
are the output of the same remote sensing image through data augmentation performed in two different ways. The process of self-supervised learning in this paper maximizes the mutual information between
and
, where
represents the global features extracted by the convolution network,
represents the 5 × 5 local features extracted by the convolution network, and
represents the local features of the second layer output of the convolution network. The expression of the InfoNCE loss between
and
is:
where
represents the set of all negative samples of remote sensing image
and
represents the square of the Euclidean metric (Euclidean distance). Comparing the output characteristics of different convolution layers will affect the performance of embedding networks.
represents the positive sample pair.
represent the positive sample pair and all negative sample pairs.
The loss of the self-supervised learning stage consists of the InfoNCE loss between local features and local features and the InfoNCE loss between local features and global features. The InfoNCE loss
between
and
is calculated as:
The first term and the fourth term, the second term and the fifth term are dual relations. Therefore, we set equal coefficients for them. Here, we expect the embedding network to learn a good representation of local features and global features by multilayer feature contrast. The comparisons of global features with local features and of local features with local features at different locations are what we need. Therefore, we will not discuss here which one of them is more important and will assign the same coefficients to them as well. Gather the positive samples continuously from the same remote sensing image, push away total negative samples from other remote sensing images, and integrate the contrast loss of local features and global features into the learning objective. By combining these two losses, we make use of the stability of NCE loss in few-shot scenarios and improve the feature extraction ability of embedding networks when we obtain more transferable embedding networks. In the training process, the probability of the embedding network using the correct category is maximized by continuously reducing until it is stable at the minimum value. At this time, the self-supervised learning ends, and an embedding network with the ability to extract global and local features of remote sensing images is obtained.
3.2. Metric-Based Meta-Learning Model Fine-Tuning
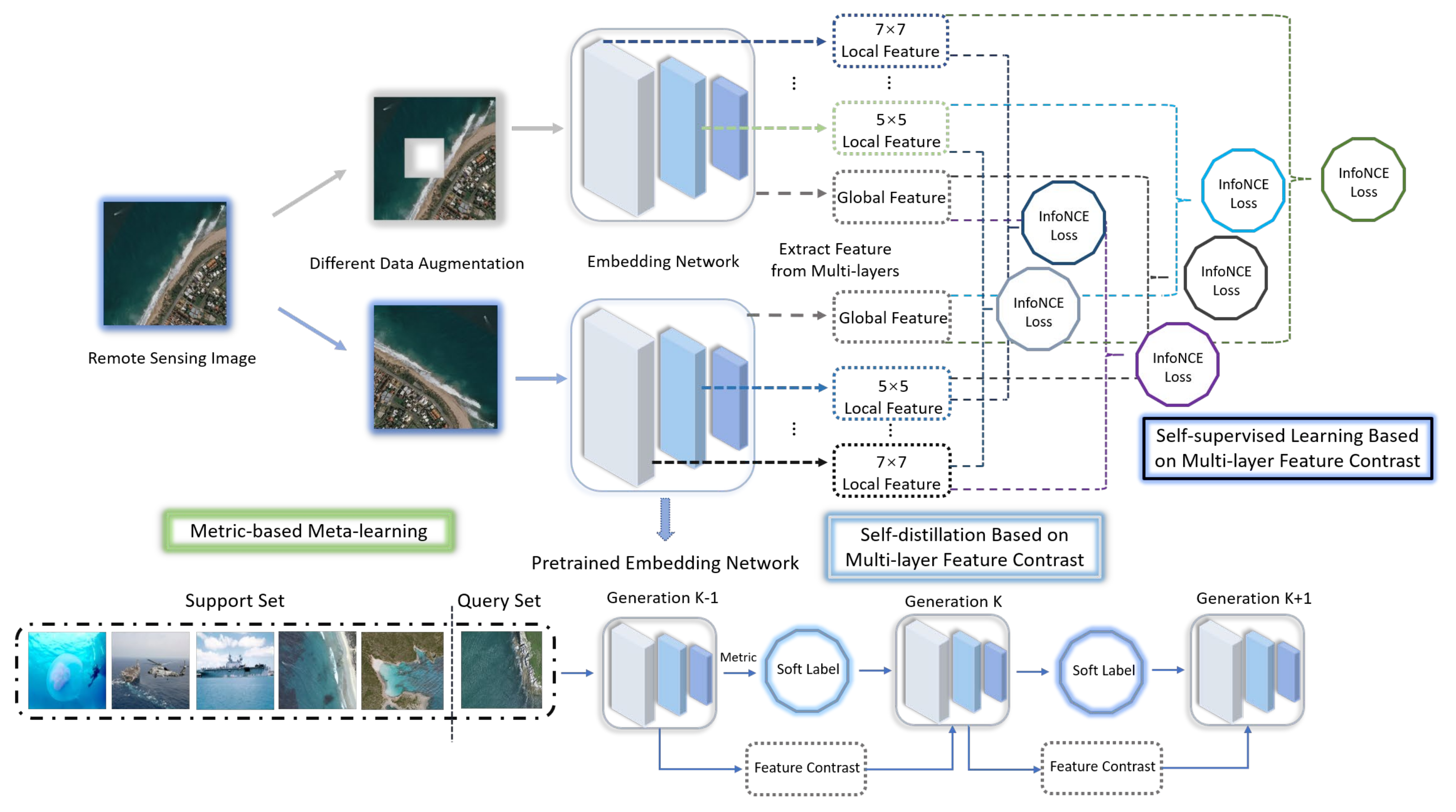
After obtaining an embedding network that has been trained in advance in the self-supervised learning phase, it is embedded in a metric learning framework as an embedding network classifier, which is fine-tuned according to the meta-learning task. Classic meta-learning can be viewed as a multi-task N-way K-shot classification problem [
28]. Firstly, N categories (N-way) of probabilistic samples are selected from the overall dataset P, and K + m (m ≥ 1) stochastic remote sensing images are randomly selected from every class. The number of data categories in the overall dataset is greater than N, and the number of instances in each category is greater than K. The actual training and testing sets for meta-learning are composed of individual episodes, and K samples are continuously and randomly selected from the respective sample sets of the N categories as the support set S, which are inputted to the network model for training. The remaining data samples from each class of samples are set together to constitute the query set Q, which is designed to test the capability of the meta-learning model.
After obtaining an embedding network that has been trained in advance in the self-supervised learning phase, it is embedded in a metric learning framework as an embedding network classifier, which is fine-tuned according to the meta-learning task. Classic meta-learning can be viewed as a multi-task N-way K-shot classification problem [
28]. Firstly, N categories (N-way) of probabilistic samples are selected from the overall dataset P, and K + m (m ≥ 1) stochastic remote sensing images are randomly selected from every class. The number of data categories in the overall dataset is greater than N, and the number of instances in each category is greater than K. The actual training and testing sets for meta-learning are composed of individual episodes, and K samples are continuously and randomly selected from the respective sample sets of the N categories as the support set S, which are inputted to the network model for training. The remaining data samples from each class of samples are set together to constitute the query set Q, which is designed to test the capability of the meta-learning model.
In the training stage, all samples in the sample set are inputted to the embedding network to metric, and a metric space is generated. Based on the idea of theoretical mechanics, this paper regards each sample in the metric space as a particle and regards the process of “metric” as the assignment of an impulse to all sample particles by an embedding network. Samples in the category will acquire characteristics after being measured. The centroid of features of this kind of sample in the metric space is obtained as follows:
It will iterate with the updating of samples and calculate the average of each feature. Similar to the concept of the centroid of the particle system, this representation can represent the metric results of the embedding network for this class of samples.
When classifying the test samples, calculate the difference between the samples and each class of sample through the embedding network measurement evaluation results and compare the types with the smallest difference, that is, the class of samples to be classified. Here, the calculation method of the moment of inertia in theoretical mechanics is analogized: each class of a sample set is regarded as a rigid body, and the characteristic center of each sample is regarded as the momentum at the center of the rigid body. The square ratio of the distance between the measurement result of all samples in each kind and the characteristic center is expressed as the rigid body parallel axis theorem in theoretical mechanics:
Here, we choose Euclidean distance to calculate the distance. Euclidean distance is an effective choice. It is equivalent to a linear model. All the required nonlinearities in our model are learned in the embedding network.
For the type of sample
extracted stochastically from the query set, the softmax prediction is:
In the training process of meta-learning classification, softmax loss is the commonly used loss function. However, softmax loss can only continuously increase the distance between categories; it cannot constrain the distance within categories. Therefore, we choose center loss [
55], which further minimizes the sum of squares of the distances between the features of the samples in the episode and the feature centers based on softmax loss. The final meta-learning loss function is:
where
is a hyperparameter that is used to adjust the proportion of intra-class compactness and inter-class discrepancy.
3.3. Self-Distillation Model Optimization Based on Multi-Layer Feature Contrast
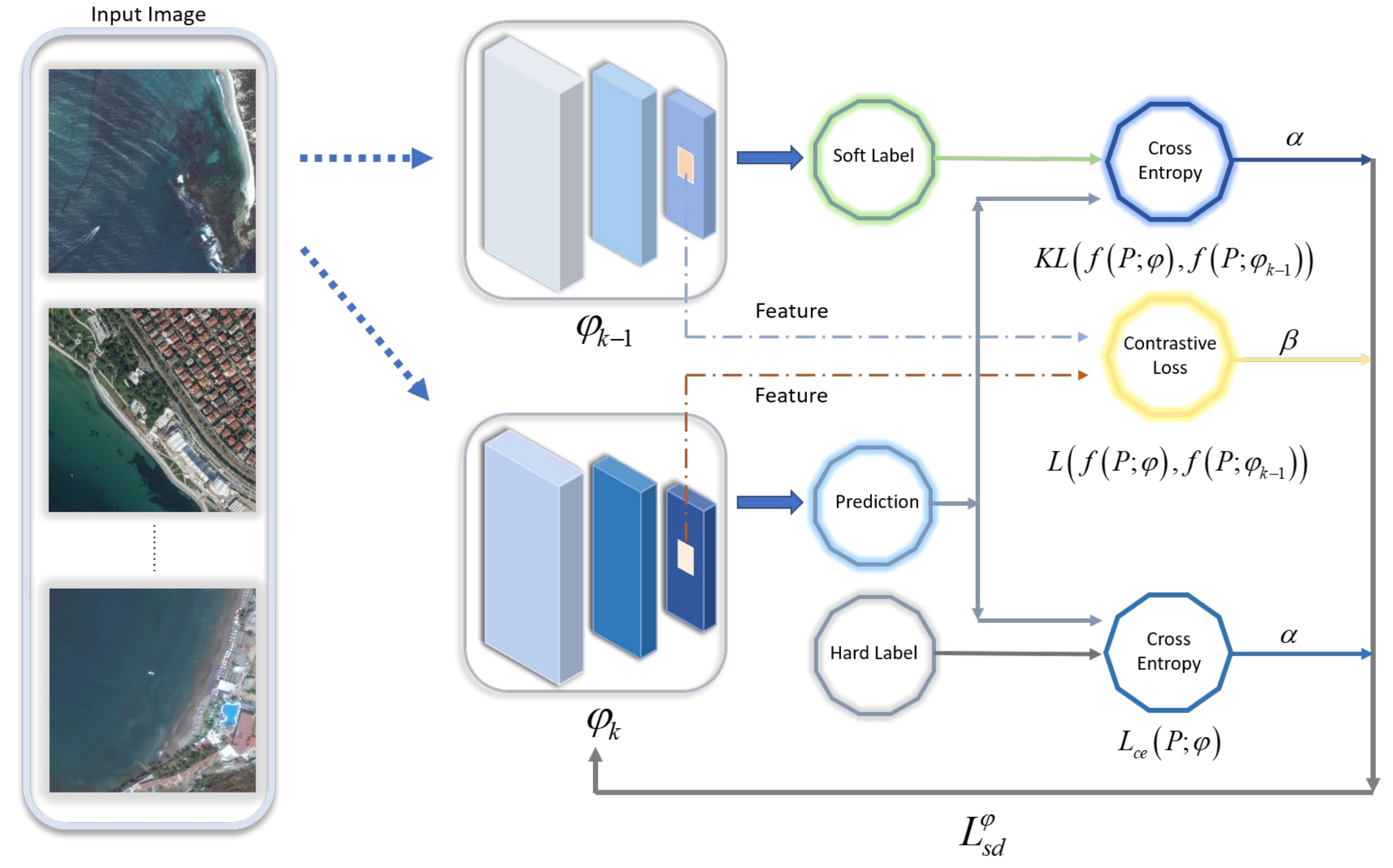
Considering that the features obtained by meta-learning will be over-learned in the training episodes, leading to the occurrence of supervision collapse, we adopt the method of knowledge distillation to simplify the embedding network after self-supervised learning training and meta-learning training, to heighten the generalization ability needed to face new unseen data in the embedding network. Knowledge distillation transfers the knowledge in the teacher model to the student model. Considering that this paper solves the problem in few-shot scenarios, there are not very many labeled data for training the teacher network with good performance. Therefore, we chose self-distillation [
56] for model optimization. Since the beginning of distillation training, the structure of the network as a teacher is the same as the structure of the network acting as a student. During training, the output of the teacher network is used as a high-quality soft label to train the student network, which is equivalent to taking the output of the model as the soft training label of the next-generation model. The demand for labeled data is lower than that for the usual knowledge distillation.
Self-distillation iterates the model, and the model of generation K is distilled from the model of generation K-1. The network obtained by self-distillation is expressed by
. In the process of self-distillation, there is a difference loss of prediction label, including the difference between the predictions of the generation K model and ground-truth labels, as well as the difference between the predictions of generation K and generation K-1. These differences are at the label level and are constrained by known data labels and soft labels. Considering the lack of data labels in few-shot scenarios, we introduce feature distillation [
52,
57]. As shown in
Figure 2, we add the difference of feature level to the self-distillation: the difference of the feature extracted from a remote sensing image between the convolution of a layer in the K-generation model and the same layer in the K-1 generation model. The feature distillation can be focal distillation or global distillation, which bridges the gap between the contexts of the adjoining generations.
The difference between the predictions of the generation K model and the actual value is measured by cross-entropy loss (contrastive loss), the distinction between the predictions of generation K and generation K-1 is measured by Kullback–Leibler Divergence, and the feature difference extracted from generation K and generation K-1 is measured by InfoNCE. By continuously reducing these differences, the model’s classification accuracy is improved. The model that minimizes the sum of these three differences is the K-generation self- distillation model
. The expression of
is:
where
represents Kullback–Leibler divergence,
is on behalf of the cross-entropy loss,
is the InfoNCE loss,
is the overall dataset, and
and
are the hyperparameters. The loss function
in the self-distillation process is expressed as:









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}