
A Geographically Weighted Random Forest Approach to Predict Corn Yield in the US Corn Belt



Abstract
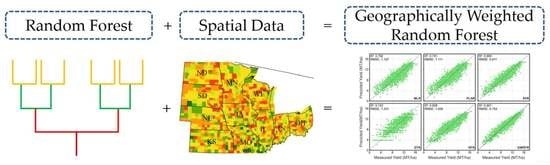
:
1. Introduction
- (1)
- Can GWRFR derive more accurate results in corn yield prediction in the US Corn Belt than other machine learning models?
- (2)
- How does feature selection affect the performance of machine learning models in county-level corn yield prediction?
2. Materials and Methods
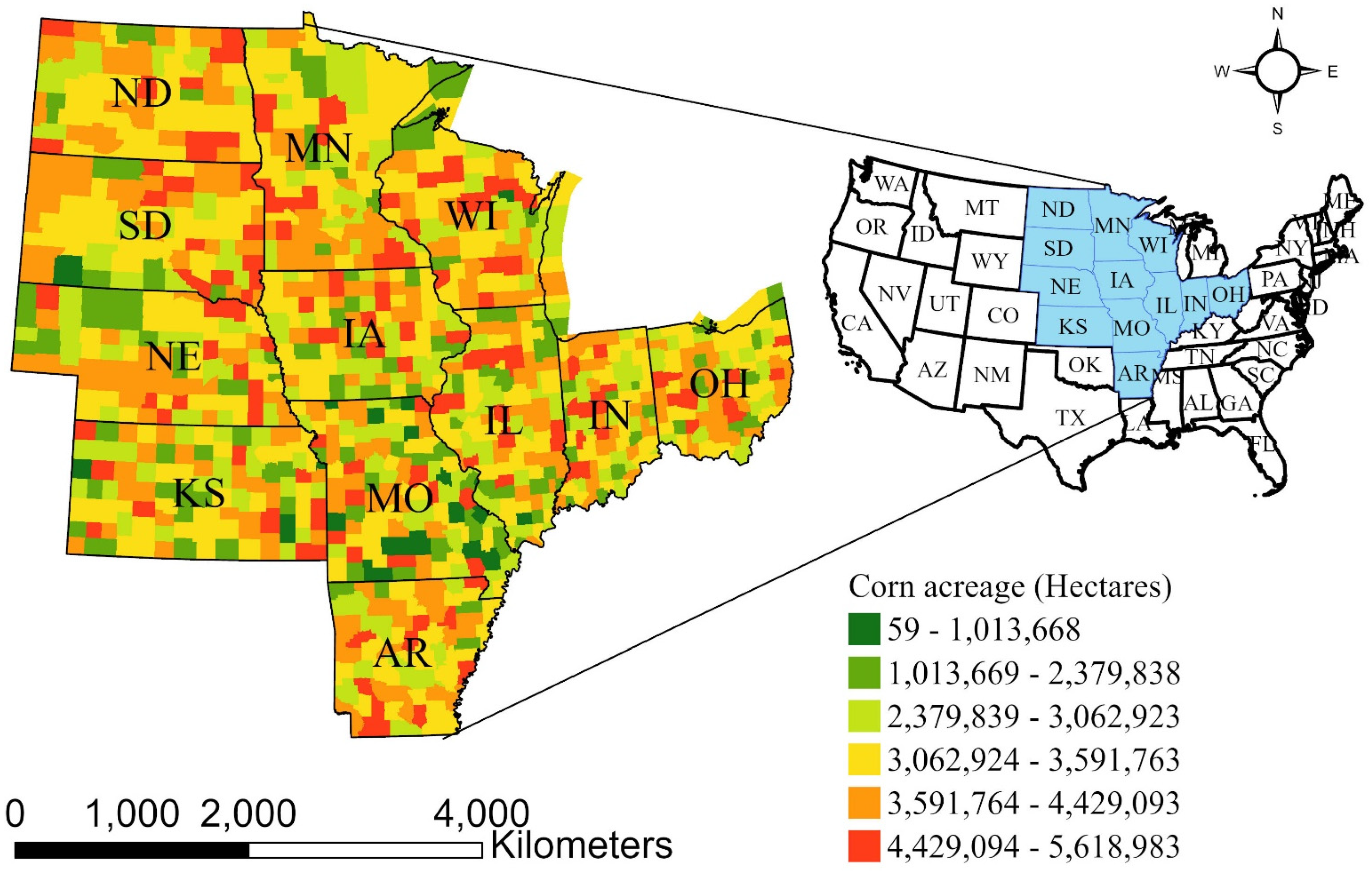
2.1. Study Area
2.2. Datasets
2.2.1. Corn Yield Data
2.2.2. Cropland Data Layer
2.2.3. Vegetation Indices
2.2.4. Soil Data
2.2.5. Climate Data
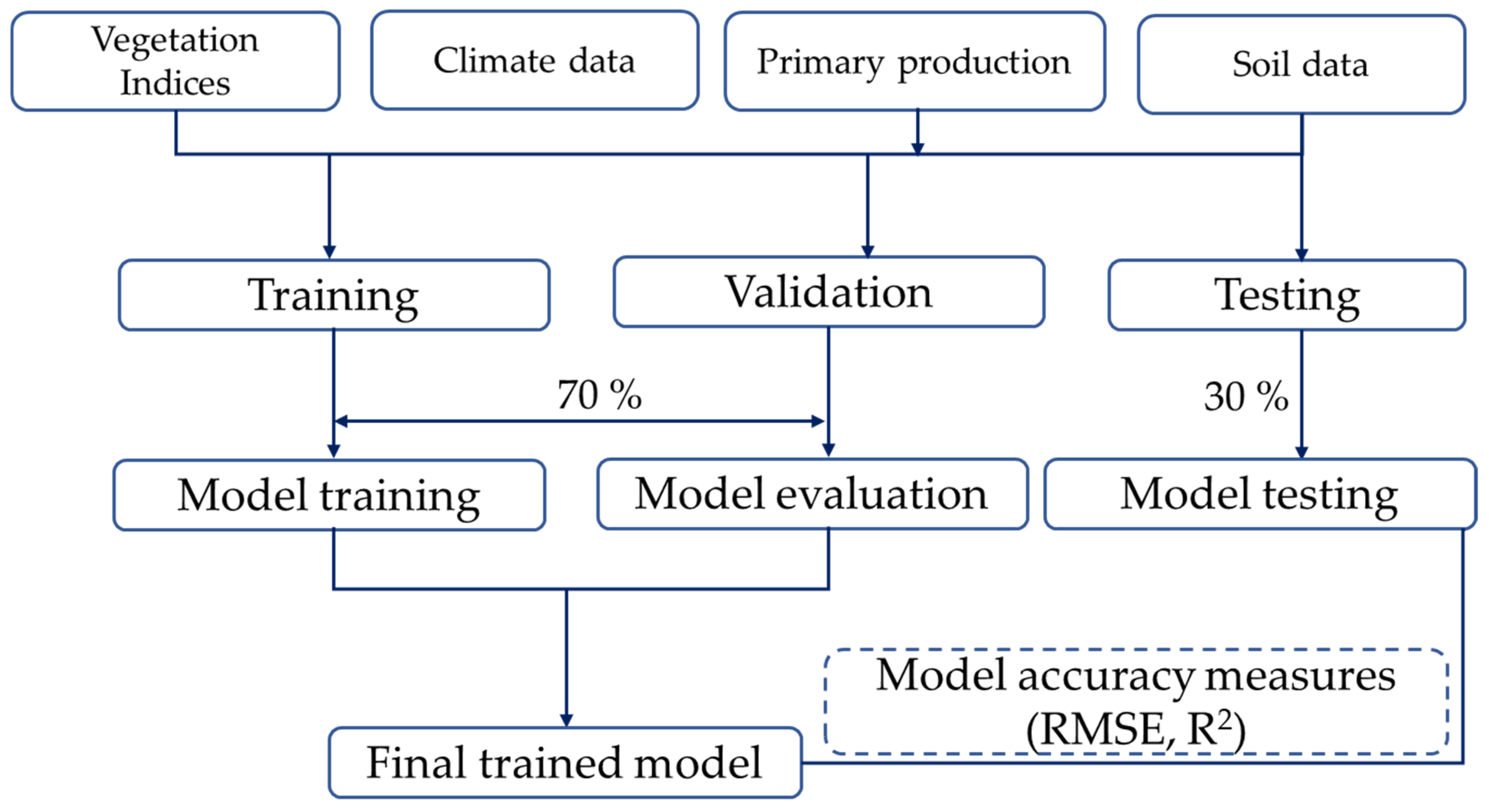
2.3. Data Preprocessing
2.4. Methodology
2.4.1. Multiple Linear Regression (MLR)
2.4.2. Partial Least Square Regression (PLSR)
2.4.3. Support Vector Regression (SVR)
2.4.4. Random Forest Regression (RFR)
2.4.5. Geographically Weighted Random Forest Regression (GWRFR)
2.4.6. Experimental Design
3. Results
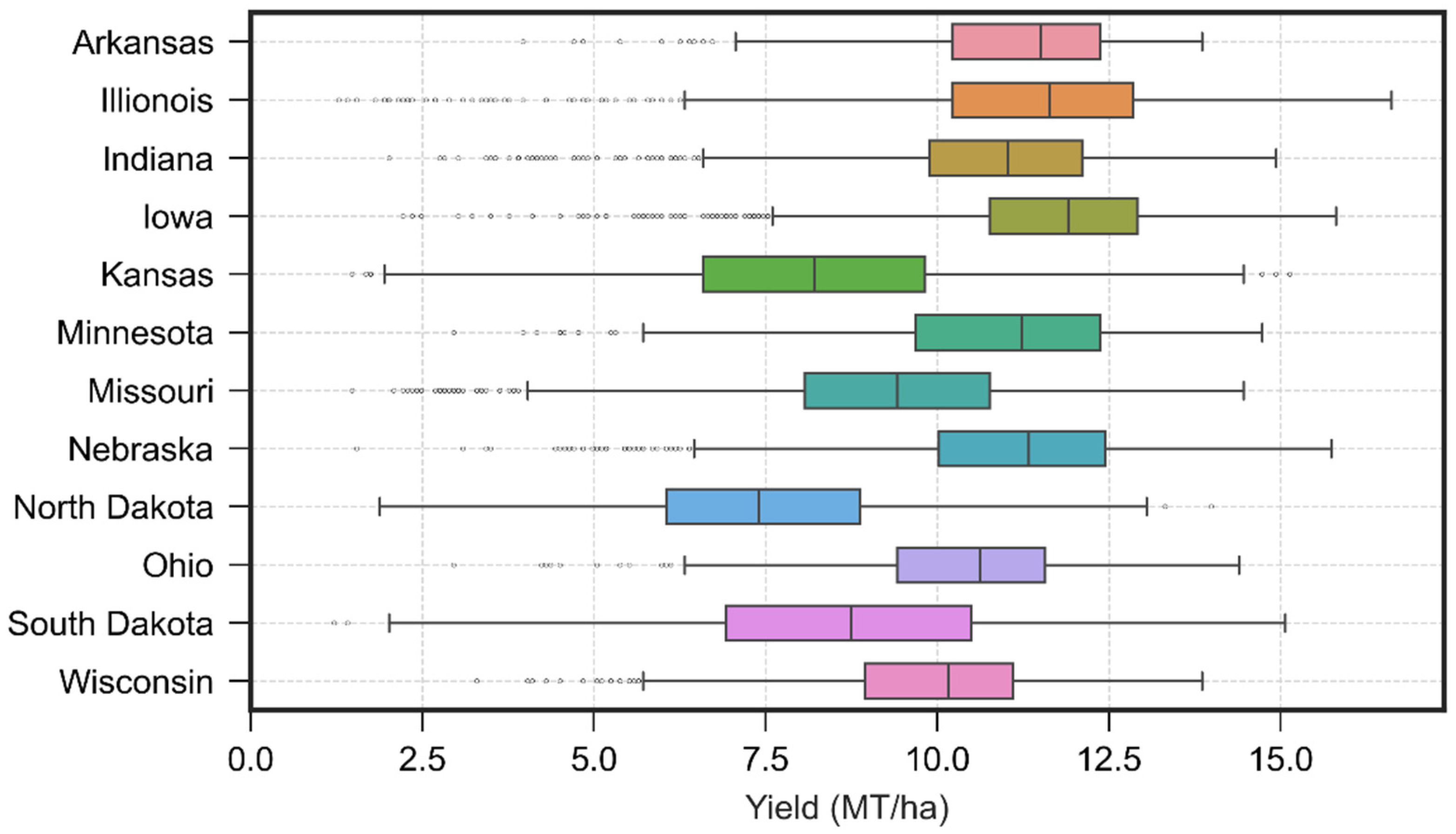
3.1. Descriptive Statistics
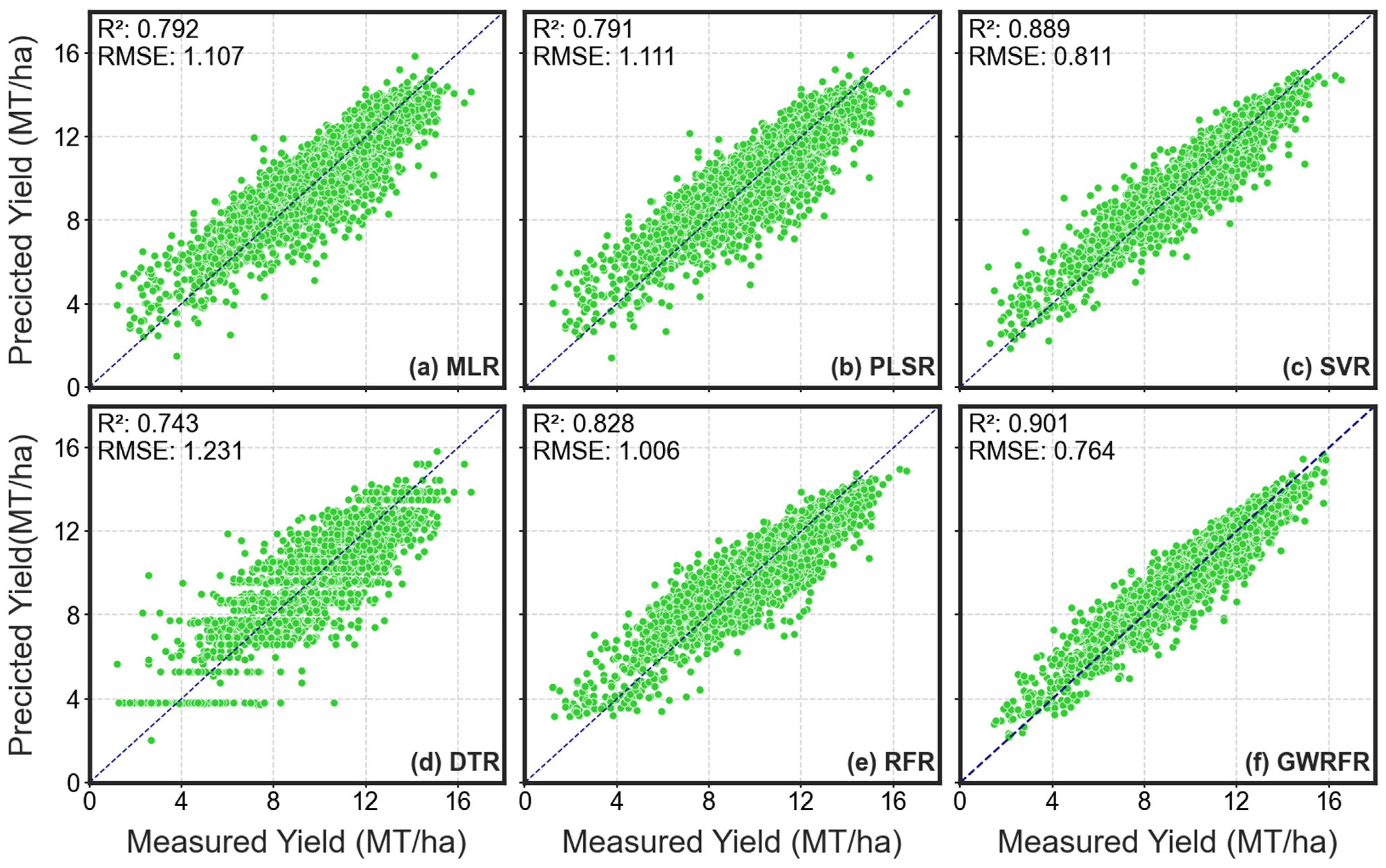
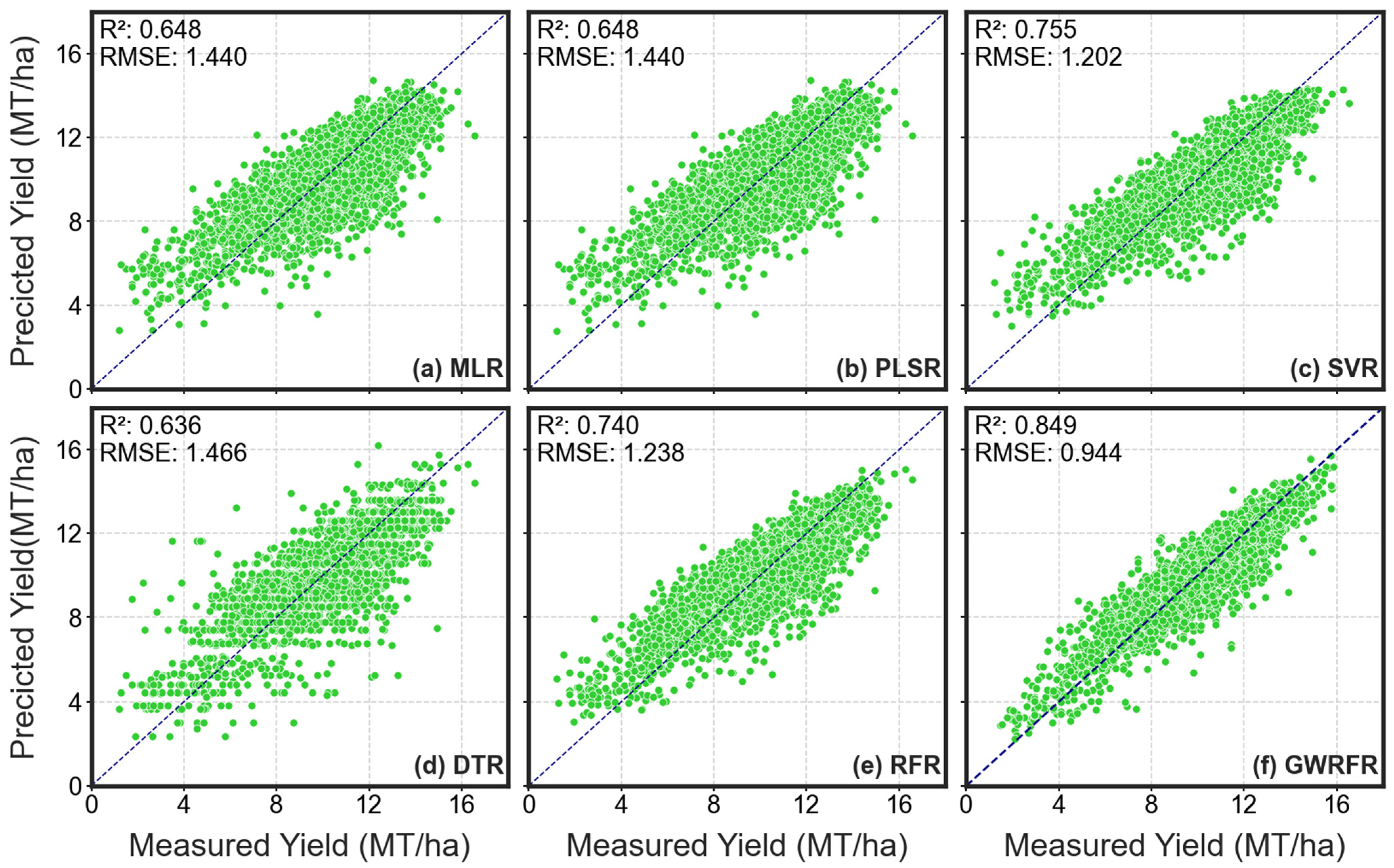
3.2. Model Performance with Different Sets of Input Features
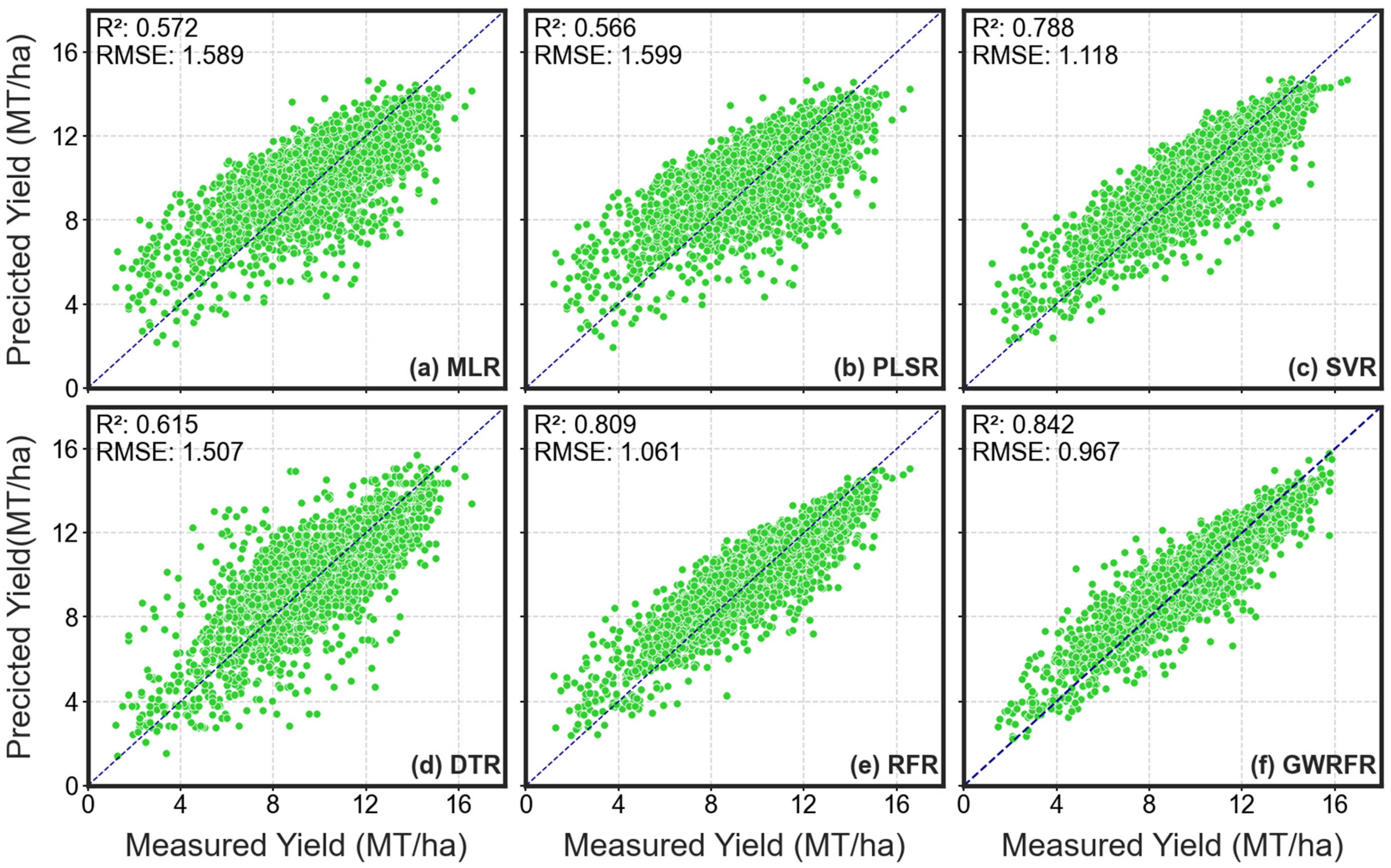
3.2.1. Full-Length Features
3.2.2. Vegetation Indices
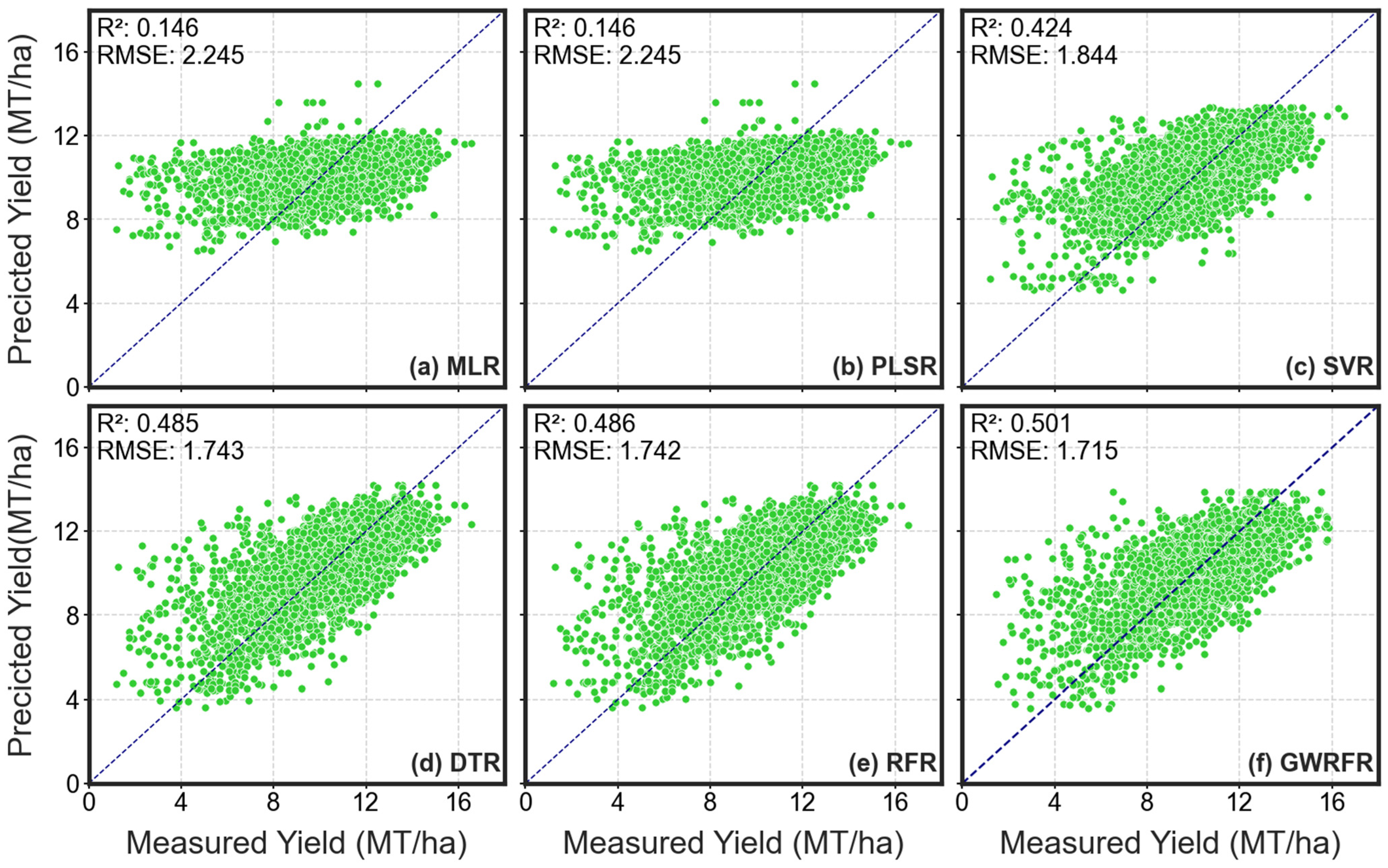
3.2.3. Gross Primary Production
3.2.4. Climate Data
3.2.5. Soil Data
3.3. Spatial Autocorrelation in Residuals
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ranum, P.; Peña-Rosas, J.P.; Garcia-Casal, M.N. Global maize production, utilization, and consumption. Ann. N. Y. Acad. Sci. 2014, 1312, 105–112. [Google Scholar] [CrossRef] [PubMed]
- Green, T.R.; Kipka, H.; David, O.; McMaster, G.S. Where is the USA Corn Belt, and how is it changing? Sci. Total Environ. 2018, 618, 1613–1618. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Panagopoulos, Y.; Gassman, P.W.; Jha, M.K.; Kling, C.L.; Campbell, T.; Srinivasan, R.; White, M.; Arnold, J.G. A refined regional modeling approach for the Corn Belt–Experiences and recommendations for large-scale integrated modeling. J. Hydrol. 2015, 524, 348–366. [Google Scholar] [CrossRef] [Green Version]
- Pathak, T.B.; Maskey, M.L.; Dahlberg, J.A.; Kearns, F.; Bali, K.M.; Zaccaria, D. Climate change trends and impacts on California agriculture: A detailed review. Agronomy 2018, 8, 25. [Google Scholar] [CrossRef] [Green Version]
- Ehrlich, P.R.; Ehrlich, A.H.; Daily, G.C. Food security, population and environment. Popul. Dev. Rev. 1993, 19, 1–32. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Martinez-Feria, R.A.; Hu, G.; Archontoulis, S.V. Maize yield and nitrate loss prediction with machine learning algorithms. Environ. Res. Lett. 2019, 14, 124026. [Google Scholar] [CrossRef] [Green Version]
- Ali, A.; Rondelli, V.; Martelli, R.; Falsone, G.; Lupia, F.; Barbanti, L. Management Zones Delineation through Clustering Techniques Based on Soils Traits, NDVI Data, and Multiple Year Crop Yields. Agriculture 2022, 12, 231. [Google Scholar] [CrossRef]
- Ahmad, W.; Iqbal, J.; Nasir, M.J.; Ahmad, B.; Khan, M.T.; Khan, S.N.; Adnan, S. Impact of land use/land cover changes on water quality and human health in district Peshawar Pakistan. Sci. Rep. 2021, 11, 16526. [Google Scholar] [CrossRef]
- Yuan, W.; Chen, Y.; Xia, J.; Dong, W.; Magliulo, V.; Moors, E.; Olesen, J.E.; Zhang, H. Estimating crop yield using a satellite-based light use efficiency model. Ecol. Indic. 2016, 60, 702–709. [Google Scholar] [CrossRef] [Green Version]
- Shahhosseini, M.; Hu, G.; Archontoulis, S. Forecasting corn yield with machine learning ensembles. Front. Plant Sci. 2020, 11, 1120. [Google Scholar] [CrossRef]
- Feng, L.; Wang, Y.; Zhang, Z.; Du, Q. Geographically and temporally weighted neural network for winter wheat yield prediction. Remote Sens. Environ. 2021, 262, 112514. [Google Scholar] [CrossRef]
- Iizumi, T.; Shin, Y.; Kim, W.; Kim, M.; Choi, J. Global crop yield forecasting using seasonal climate information from a multi-model ensemble. Clim. Serv. 2018, 11, 13–23. [Google Scholar] [CrossRef]
- Hunt, M.L.; Blackburn, G.A.; Carrasco, L.; Redhead, J.W.; Rowland, C.S. High resolution wheat yield mapping using Sentinel-2. Remote Sens. Environ. 2019, 233, 111410. [Google Scholar] [CrossRef]
- Rossato, L.; Alvalá, R.C.; Marengo, J.A.; Zeri, M.; Cunha, A.P.; Pires, L.; Barbosa, H.A. Impact of soil moisture on crop yields over Brazilian semiarid. Front. Environ. Sci. 2017, 5, 73. [Google Scholar] [CrossRef] [Green Version]
- Pede, T.; Mountrakis, G.; Shaw, S.B. Improving corn yield prediction across the US Corn Belt by replacing air temperature with daily MODIS land surface temperature. Agric. For. Meteorol. 2019, 276, 107615. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Sabatino, L.; D’Anna, F.; Iapichino, G.; Moncada, A.; D’Anna, E.; De Pasquale, C. Interactive effects of genotype and molybdenum supply on yield and overall fruit quality of tomato. Front. Plant Sci. 2019, 9, 1922. [Google Scholar] [CrossRef] [Green Version]
- Imran, M.; Zurita-Milla, R.; Stein, A. Modeling Crop Yield in West-African Rainfed Agriculture Using Global and Local Spatial Regression. Agron. J. 2013, 105, 1177–1188. [Google Scholar] [CrossRef]
- Sellam, V.; Poovammal, E. Prediction of crop yield using regression analysis. Indian J. Sci. Technol. 2016, 9, 1–5. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef] [Green Version]
- Petersen, L.K. Real-time prediction of crop yields from MODIS relative vegetation health: A continent-wide analysis of Africa. Remote Sens. 2018, 10, 1726. [Google Scholar] [CrossRef] [Green Version]
- Idso, S.B.; Jackson, R.D.; Reginato, R.J. Remote sensing for agricultural water management and crop yield prediction. Agric. Water Manag. 1977, 1, 299–310. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.; Ciampitti, I.A. Satellite-based soybean yield forecast: Integrating machine learning and weather data for improving crop yield prediction in southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Brown, J.N.; Hochman, Z.; Holzworth, D.; Horan, H. Seasonal climate forecasts provide more definitive and accurate crop yield predictions. Agric. For. Meteorol. 2018, 260, 247–254. [Google Scholar] [CrossRef]
- Khaki, S.; Pham, H.; Wang, L. Simultaneous corn and soybean yield prediction from remote sensing data using deep transfer learning. Sci. Rep. 2021, 11, 11132. [Google Scholar] [CrossRef] [PubMed]
- Bruce, R.; Snyder, W.; Whiter, A., Jr.; Thomas, A.; Langdale, G. Soil variables and interactions affecting prediction of crop yield pattern. Soil Sci. Soc. Am. J. 1990, 54, 494–501. [Google Scholar] [CrossRef]
- Kern, A.; Barcza, Z.; Marjanović, H.; Árendás, T.; Fodor, N.; Bónis, P.; Bognár, P.; Lichtenberger, J. Statistical modelling of crop yield in Central Europe using climate data and remote sensing vegetation indices. Agric. For. Meteorol. 2018, 260, 300–320. [Google Scholar] [CrossRef]
- Li, Y.; Guan, K.; Yu, A.; Peng, B.; Zhao, L.; Li, B.; Peng, J. Toward building a transparent statistical model for improving crop yield prediction: Modeling rainfed corn in the US. Field Crops Res. 2019, 234, 55–65. [Google Scholar] [CrossRef]
- Imran, M.; Stein, A.; Zurita-Milla, R. Using geographically weighted regression kriging for crop yield mapping in West Africa. Int. J. Geogr. Inf. Sci. 2015, 29, 234–257. [Google Scholar] [CrossRef]
- Buckmaster, H.L. The Development of a Crop Yield Prediction Equation for Some Soils in the Blackland and Grand Prairies of Texas. Ph.D. Thesis, Texas A&M University, College Station, TX, USA, 1964. [Google Scholar]
- Ma, Y.; Zhang, Z.; Kang, Y.; Özdoğan, M. Corn yield prediction and uncertainty analysis based on remotely sensed variables using a Bayesian neural network approach. Remote Sens. Environ. 2021, 259, 112408. [Google Scholar] [CrossRef]
- Peng, B.; Guan, K.; Tang, J.; Ainsworth, E.A.; Asseng, S.; Bernacchi, C.J.; Cooper, M.; Delucia, E.H.; Elliott, J.W.; Ewert, F. Towards a multiscale crop modelling framework for climate change adaptation assessment. Nat. Plants 2020, 6, 338–348. [Google Scholar] [CrossRef] [PubMed]
- Leng, G.; Huang, M. Crop yield response to climate change varies with crop spatial distribution pattern. Sci. Rep. 2017, 7, 1463. [Google Scholar] [CrossRef] [PubMed]
- Roberts, M.J.; Braun, N.O.; Sinclair, T.R.; Lobell, D.B.; Schlenker, W. Comparing and combining process-based crop models and statistical models with some implications for climate change. Environ. Res. Lett. 2017, 12, 095010. [Google Scholar] [CrossRef]
- Parihar, C.M.; Jat, S.; Singh, A.; Ghosh, A.; Rathore, N.; Kumar, B.; Pradhan, S.; Majumdar, K.; Satyanarayana, T.; Jat, M. Effects of precision conservation agriculture in a maize-wheat-mungbean rotation on crop yield, water-use and radiation conversion under a semiarid agro-ecosystem. Agric. Water Manag. 2017, 192, 306–319. [Google Scholar] [CrossRef]
- Awad, M.M. Toward precision in crop yield estimation using remote sensing and optimization techniques. Agriculture 2019, 9, 54. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhang, Z.; Feng, L.; Du, Q.; Runge, T. Combining multi-source data and machine learning approaches to predict winter wheat yield in the conterminous united states. Remote Sens. 2020, 12, 1232. [Google Scholar] [CrossRef] [Green Version]
- Shahhosseini, M.; Hu, G.; Huber, I.; Archontoulis, S.V. Coupling machine learning and crop modeling improves crop yield prediction in the US Corn Belt. Sci. Rep. 2021, 11, 1606. [Google Scholar] [CrossRef]
- Mahlein, A.-K.; Oerke, E.-C.; Steiner, U.; Dehne, H.-W. Recent advances in sensing plant diseases for precision crop protection. Eur. J. Plant Pathol. 2012, 133, 197–209. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-level soybean yield prediction using deep CNN-LSTM model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, P.; Mandal, D.; Bhattacharya, A.; Nanda, M.K.; Bera, S. Assessing crop monitoring potential of Sentinel-2 in a spatio-temporal scale. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 425, 227–231. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Q.; Huang, W.; Cui, X.; Shi, Y.; Liu, L. New spectral index for detecting wheat yellow rust using Sentinel-2 multispectral imagery. Sensors 2018, 18, 868. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolanin, A.; Camps-Valls, G.; Gómez-Chova, L.; Mateo-García, G.; van der Tol, C.; Zhang, Y.; Guanter, L. Estimating crop primary productivity with Sentinel-2 and Landsat 8 using machine learning methods trained with radiative transfer simulations. Remote Sens. Environ. 2019, 225, 441–457. [Google Scholar] [CrossRef]
- Bannari, A.; Morin, D.; Bonn, F.; Huete, A. A review of vegetation indices. Remote Sens. Rev. 1995, 13, 95–120. [Google Scholar] [CrossRef]
- Liang, S. Comprehensive Remote Sensing; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Mishra, S.; Mishra, D.; Santra, G.H. Applications of machine learning techniques in agricultural crop production: A review paper. Indian J. Sci. Technol. 2016, 9, 1–14. [Google Scholar] [CrossRef]
- Gilbertson, J.K.; Van Niekerk, A. Value of dimensionality reduction for crop differentiation with multi-temporal imagery and machine learning. Comput. Electron. Agric. 2017, 142, 50–58. [Google Scholar] [CrossRef]
- Ali, A.; Martelli, R.; Lupia, F.; Barbanti, L. Assessing multiple years’ spatial variability of crop yields using satellite vegetation indices. Remote Sens. 2019, 11, 2384. [Google Scholar] [CrossRef] [Green Version]
- Brunsdon, C.; Fotheringham, S.; Charlton, M. Geographically weighted regression. J. R. Stat. Soc. Ser. D (Stat.) 1998, 47, 431–443. [Google Scholar] [CrossRef]
- Santos, F.; Graw, V.; Bonilla, S. A geographically weighted random forest approach for evaluate forest change drivers in the Northern Ecuadorian Amazon. PLoS ONE 2019, 14, e0226224. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Niang Gadiaga, A.; Linard, C.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E.; Kalogirou, S. Geographical random forests: A spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling. Geocarto Int. 2021, 36, 121–136. [Google Scholar] [CrossRef] [Green Version]
- Ort, D.R.; Long, S.P. Limits on yields in the corn belt. Science 2014, 344, 484–485. [Google Scholar] [CrossRef]
- NASS. NASS Quick Stats. In USDA National Agricultural Statistics Service (NASS). Available online: http://quickstats.nass.usda.gov (accessed on 19 December 2021).
- Didan, K. MOD13Q1 MODIS/Terra Vegetation Indices 16-Day L3 Global 250 m SIN Grid V006. NASA EOSDIS Land Processes DAAC; NASA: Washington, DC, USA, 2015.
- Running, S.W.; Zhao, M. User’s Guide Daily GPP and Annual NPP (MOD17A2/A3) Products NASA Earth Observing System MODIS Land Algorithm; The Numerical Terradynamic Simulation Group: Missoula, MT, USA, 2015. [Google Scholar]
- NRCS. Web Soil Survey. 2009. Available online: http://www.websoilsurvey.ncsc.usda.gov/app (accessed on 29 October 2017).
- Daly, C.; Bryant, K. The PRISM Climate and Weather System—An Introduction; PRISM Climate Group: Corvallis, OR, USA, 2013. [Google Scholar]
- Craig, M. A History of the Cropland Data Layer at NASS; Unpublished manuscript; Research and Development Division, USDA, NASS: Fairfax, VA, USA, 2010. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Curran, P. Multispectral remote sensing of vegetation amount. Prog. Phys. Geogr. 1980, 4, 315–341. [Google Scholar] [CrossRef]
- Jackson, R.D.; Huete, A.R. Interpreting vegetation indices. Prev. Vet. Med. 1991, 11, 185–200. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 4th ed.; Pearson: London, UK, 2015. [Google Scholar]
- Shearer, S.; Burks, T.; Fulton, J.; Higgins, S.; Thomasson, J.; Mueller, T.; Samson, S. Yield prediction using a neural network classifier trained using soil landscape features and soil fertility data. In Proceedings of the Annual International Meeting, Milwaukee, WI, USA, 9–12 July 2000; pp. 5–9. [Google Scholar]
- Khairunniza-Bejo, S.; Mustaffha, S.; Ismail, W.I.W. Application of artificial neural network in predicting crop yield: A review. J. Food Sci. Eng. 2014, 4, 1. [Google Scholar]
- Dahikar, S.S.; Rode, S.V. Agricultural crop yield prediction using artificial neural network approach. Int. J. Innov. Res. Electr. Electron. Instrum. Control. Eng. 2014, 2, 683–686. [Google Scholar]
- Daly, C.; Taylor, G.; Gibson, W.; Parzybok, T.; Johnson, G.; Pasteris, P. High-quality spatial climate data sets for the United States and beyond. Trans. ASAE 2000, 43, 1957. [Google Scholar] [CrossRef] [Green Version]
- Daly, C. Descriptions of PRISM Spatial Climate Datasets for the Conterminous United States; PRISM Climate Group: Corvallis, OR, USA, 2013; p. 14. [Google Scholar]
- ESRI. ArcGIS Pro (Version 2.8); ESRI Inc.: Redlands, CA, USA, 2020. [Google Scholar]
- Santiago, C.B.; Guo, J.-Y.; Sigman, M.S. Predictive and mechanistic multivariate linear regression models for reaction development. Chem. Sci. 2018, 9, 2398–2412. [Google Scholar] [CrossRef] [Green Version]
- Mei, C.-L.; Chen, F.; Wang, W.-T.; Yang, P.-C.; Shen, S.-L. Efficient estimation of heteroscedastic mixed geographically weighted regression models. Ann. Reg. Sci. 2021, 66, 185–206. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Tobias, R.D. An introduction to partial least squares regression. In Proceedings of the Twentieth Annual SAS Users Group International Conference, Orlando, FL, USA, 2–5 April 1995. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Wen, C.; Huang, G.-B.; Chen, Y. Error tolerance based support vector machine for regression. Neurocomputing 2011, 74, 771–782. [Google Scholar] [CrossRef]
- Smith, P.F.; Ganesh, S.; Liu, P. A comparison of random forest regression and multiple linear regression for prediction in neuroscience. J. Neurosci. Methods 2013, 220, 85–91. [Google Scholar] [CrossRef]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control. Eng. 2014, 2, 602–609. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, A.F.; Finan, C. Linear regression and the normality assumption. J. Clin. Epidemiol. 2018, 98, 146–151. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Yan, J.; McClure, S. Distribution of the environmental and socioeconomic risk factors on COVID-19 death rate across continental USA: A spatial nonlinear analysis. Environ. Sci. Pollut. Res. 2021, 28, 6587–6599. [Google Scholar] [CrossRef]
- Quiñones, S.; Goyal, A.; Ahmed, Z.U. Geographically weighted machine learning model for untangling spatial heterogeneity of type 2 diabetes mellitus (T2D) prevalence in the USA. Sci. Rep. 2021, 11, 6955. [Google Scholar] [CrossRef]
- Maiti, A.; Zhang, Q.; Sannigrahi, S.; Pramanik, S.; Chakraborti, S.; Cerda, A.; Pilla, F. Exploring spatiotemporal effects of the driving factors on COVID-19 incidences in the contiguous United States. Sustain. Cities Soc. 2021, 68, 102784. [Google Scholar] [CrossRef]
- Wan, X. Influence of feature scaling on convergence of gradient iterative algorithm. J. Phys. Conf. Ser. 2019, 1213, 032021. [Google Scholar] [CrossRef] [Green Version]
- Griffith, D.A. What is spatial autocorrelation? Reflections on the past 25 years of spatial statistics. L’Espace Géogr. 1992, 21, 265–280. [Google Scholar] [CrossRef]
- Overmars, K.d.; De Koning, G.; Veldkamp, A. Spatial autocorrelation in multi-scale land use models. Ecol. Model. 2003, 164, 257–270. [Google Scholar] [CrossRef]
- Cho, G. Spatial Processes: Models and Applications by AD Cliff and JK Ord. 16 by 24 em, 266 pages, maps, diags., index and bibliography. london: Pion Limited, 1981. (ISBN 08-85086-081-4). £ 20.50. Cartography 1983, 13, 59–60. [Google Scholar] [CrossRef]
- Gething, P.W.; Atkinson, P.M.; Noor, A.M.; Gikandi, P.W.; Hay, S.I.; Nixon, M.S. A local space–time kriging approach applied to a national outpatient malaria data set. Comput. Geosci. 2007, 33, 1337–1350. [Google Scholar] [CrossRef] [Green Version]
- Mendez, K.M.; Pritchard, L.; Reinke, S.N.; Broadhurst, D.I. Toward collaborative open data science in metabolomics using Jupyter Notebooks and cloud computing. Metabolomics 2019, 15, 125. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Barrett, P.; Hunter, J.; Miller, J.T.; Hsu, J.-C.; Greenfield, P. Matplotlib—A Portable Python Plotting Package. In Proceedings of the Astronomical Data Analysis Software and Systems XIV, San Lorenzo de El Escorial, Spain, 2–5 October 2005; p. 91. [Google Scholar]
- Waskom, M.L. Seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Peralta, N.R.; Assefa, Y.; Du, J.; Barden, C.J.; Ciampitti, I.A. Mid-season high-resolution satellite imagery for forecasting site-specific corn yield. Remote Sens. 2016, 8, 848. [Google Scholar] [CrossRef] [Green Version]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Kumar, S.; Lal, R.; Liu, D. A geographically weighted regression kriging approach for mapping soil organic carbon stock. Geoderma 2012, 189, 627–634. [Google Scholar] [CrossRef]
- Mathieu, J.A.; Aires, F. Statistical weather-impact models: An application of neural networks and mixed effects for corn production over the United States. J. Appl. Meteorol. Climatol. 2016, 55, 2509–2527. [Google Scholar] [CrossRef]
- Khan, K.; Iqbal, J.; Ali, A.; Khan, S. Assessment of sentinel-2-derived vegetation indices for the estimation of above-ground biomass/carbon stock, temporal deforestation and carbon emissions estimation in the moist temperate forests of pakistan. Appl. Ecol. Environ. Res 2020, 18, 783–815. [Google Scholar] [CrossRef]
- Daryanto, S.; Wang, L.; Jacinthe, P.-A. Global synthesis of drought effects on maize and wheat production. PLoS ONE 2016, 11, e0156362. [Google Scholar] [CrossRef] [PubMed]
- Daryanto, S.; Wang, L.; Jacinthe, P.-A. Global synthesis of drought effects on cereal, legume, tuber and root crops production: A review. Agric. Water Manag. 2017, 179, 18–33. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Guan, K.; Schnitkey, G.D. Excessive rainfall leads to comparable magnitude of corn yield loss as drought in the US. In Proceedings of the AGU Fall Meeting 2018, Washington, DC, USA, 10–14 December 2018. [Google Scholar]
- Yildirim, T.; Moriasi, D.N.; Starks, P.J.; Chakraborty, D. Using Artificial Neural Network (ANN) for Short-Range Prediction of Cotton Yield in Data-Scarce Regions. Agronomy 2022, 12, 828. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Variables | Unit | Source | Spatial Resolution |
|---|---|---|---|---|
| Satellite data [54] | Normalized difference vegetation index (NDVI) | - | MODIS | 250 m |
| Enhanced vegetation index (EVI) | - | MODIS | 250 m | |
| Primary production [55] | Gross primary production (GPP) | kg C/m2 | MODIS | 500 m |
| Soil [56] | Available water content (AWC) | cm | gSSURGO | 10 m |
| Available water storage (AWS) | mm | gSSURGO | 10 m | |
| Cation exchange capacity (CEC) | meq/100 g | gSSURGO | 10 m | |
| Bulk density | g/cm3 | gSSURGO | 10 m | |
| Percent clay | Percent | gSSURGO | 10 m | |
| Percent sand | Percent | gSSURGO | 10 m | |
| Field capacity | cm/cm | gSSURGO | 10 m | |
| Organic carbon | g C/m2 | gSSURGO | 10 m | |
| pH | - | gSSURGO | 10 m | |
| Saturated hydraulic conductivity | μm/sec | gSSURGO | 10 m | |
| Wilting point | cm/cm | gSSURGO | 10 m | |
| Climate [57] | Precipitation | mm | PRISM | 4 km |
| Minimum temperature | °C | PRISM | 4 km | |
| Maximum temperature | °C | PRISM | 4 km | |
| Mean temperature | °C | PRISM | 4 km | |
| Minimum vapor pressure deficit | hPa | PRISM | 4 km | |
| Maximum vapor pressure deficit | hPa | PRISM | 4 km | |
| Mean dew point temperature | °C | PRISM | 4 km |
| Yield (MT/ha) | GPP (kg C/m2) | NDVI | EVI | Precipitation (mm) | Mean TD (°C) | Max VPD (hPa) | Min VPD (hPa) | |
|---|---|---|---|---|---|---|---|---|
| Minimum | 3.698 | 0.033 | 0.23 | 0.33 | 1.54 | 6.31 | 11.98 | 0.34 |
| Maximum | 14.048 | 0.091 | 0.54 | 0.76 | 4.91 | 18.95 | 33.28 | 3..45 |
| Mean | 9.6376 | 0.072 | 0.39 | 0.53 | 3.35 | 12.53 | 18.73 | 1.28 |
| SD | 1.971 | 0.010 | 0.05 | 0.06 | 0.60 | 2.40 | 3.39 | 0.39 |
| Model | Moran’s I | Z Score | p-Value |
|---|---|---|---|
| MLR | 0.277 | 21.28 | 0.00 |
| PLSR | 0.295 | 21.34 | 0.00 |
| SVR | 0.295 | 22.60 | 0.00 |
| DTR | 0.277 | 21.38 | 0.00 |
| RFR | 0.269 | 20.61 | 0.00 |
| GWRFR | 0.139 | 10.68 | 0.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, S.N.; Li, D.; Maimaitijiang, M. A Geographically Weighted Random Forest Approach to Predict Corn Yield in the US Corn Belt. Remote Sens. 2022, 14, 2843. https://doi.org/10.3390/rs14122843
Khan SN, Li D, Maimaitijiang M. A Geographically Weighted Random Forest Approach to Predict Corn Yield in the US Corn Belt. Remote Sensing. 2022; 14(12):2843. https://doi.org/10.3390/rs14122843
Chicago/Turabian StyleKhan, Shahid Nawaz, Dapeng Li, and Maitiniyazi Maimaitijiang. 2022. "A Geographically Weighted Random Forest Approach to Predict Corn Yield in the US Corn Belt" Remote Sensing 14, no. 12: 2843. https://doi.org/10.3390/rs14122843