
Deep Learning-Based Object Detection Techniques for Remote Sensing Images: A Survey

 , , ,
, , ,  and
and
Abstract
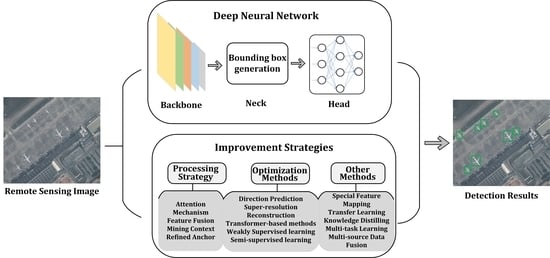
:
1. Introduction
- Complex object characteristics: First, the wide coverage of RSIs leads to the frequent appearance of objects with large-scale variations, such as the coexistence of ships and harbors in the scenarios. A top-down imaging view often causes objects to present a disorderly directional arrangement, as shown in Figure 1a. Therefore, the detection model not only has to be sensitive to the scale but must also be perceptive in terms of orientation [8,9]. Second, the object size of some species may be small or even occupy only a few pixels, as illustrated in Figure 1b. Such objects make up only a very small part of the whole image and make extracting features from fewer pixels more arduous [10]. Third, a high degree of similarity may occur among objects in RSIs that are intensely similar [11], such as tennis courts and baseball fields, or roads and bridges, as pictured in Figure 1c. The extracted similar features may confuse the detector, resulting in incorrect judgments. Finally, RSIs may contain special categories such as mountain roads and cross-sea bridges with extreme aspect ratios, such as in Figure 1d; the slender appearance of such objects makes it challenging for the detector to identify features accurately [12].
- Complex image background: A major characteristic of RSIs is that the background will occupy the majority of the scene. On the one hand, the extensive background may overwhelm the object regions, causing the detector to fail to outline the object effectively. On the other hand, the scene in which the image was taken can be relatively cluttered and noisy, which can affect the detector’s ability to efficiently extract features and correctly locate objects [13]. Therefore, searching and positioning objects from highly complex scenes such as the one shown in Figure 1e turns out to be quite demanding.
- Complex instance annotation: DL-based models rely heavily on accurately labeled training data. In general, a rich and high-quality dataset is more likely to provide relatively satisfactory results in terms of training. Accurately annotating RSIs that often present small and densely distributed objects is a time-consuming, labor-intensive chore, and inaccurate labeling degrades the performance of the model [14]. Therefore, complex sample annotations also inadvertently increase the complexity of detection implementation.
- We provide a comprehensive review of RSI object detection techniques based on DL, including representative methods, implemented processes, benchmark datasets, performance metrics, performance comparisons, etc.
- We systematically summarize the improved strategies proposed in recent years to address the complex challenges facing remote sensing, and classify them into a taxonomy in a hierarchical manner according to their characteristics.
- We discuss existing issues and provide a reference for potential future research directions.
2. Methods
2.1. Review of Object Detection Algorithms
2.1.1. Traditional Remote Sensing Object Detection Methods
2.1.2. Object Detection Methods Based on Deep Learning
2.1.3. Summary
2.2. Remote Sensing Object Detection Based on Deep Learning
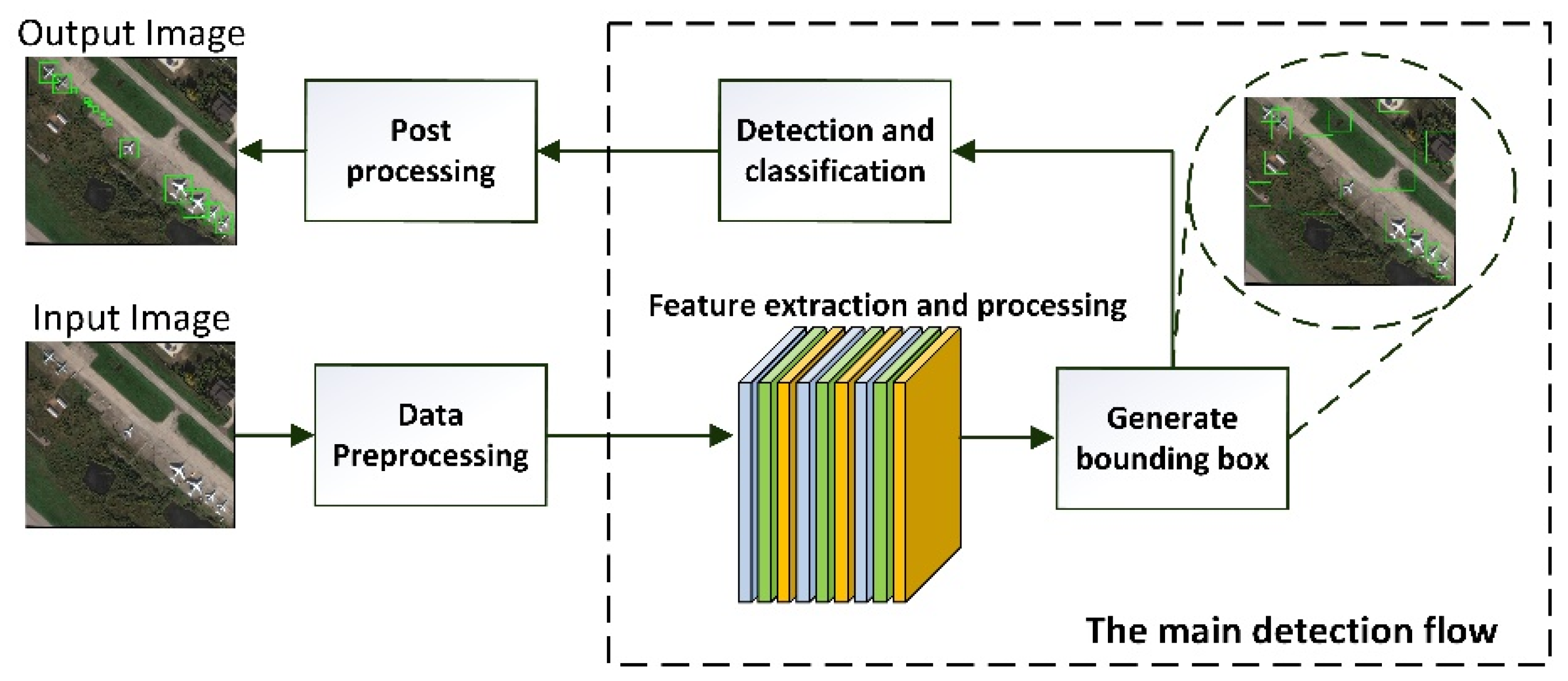
2.2.1. Data Preprocessing
2.2.2. Feature Extraction and Processing
2.2.3. Generating a Bounding Box
2.2.4. Detection and Post-Processing
2.2.5. Summary
2.3. Improved Methods for Object Detection Based on Deep Learning
2.3.1. The Attention Mechanism-Based Method
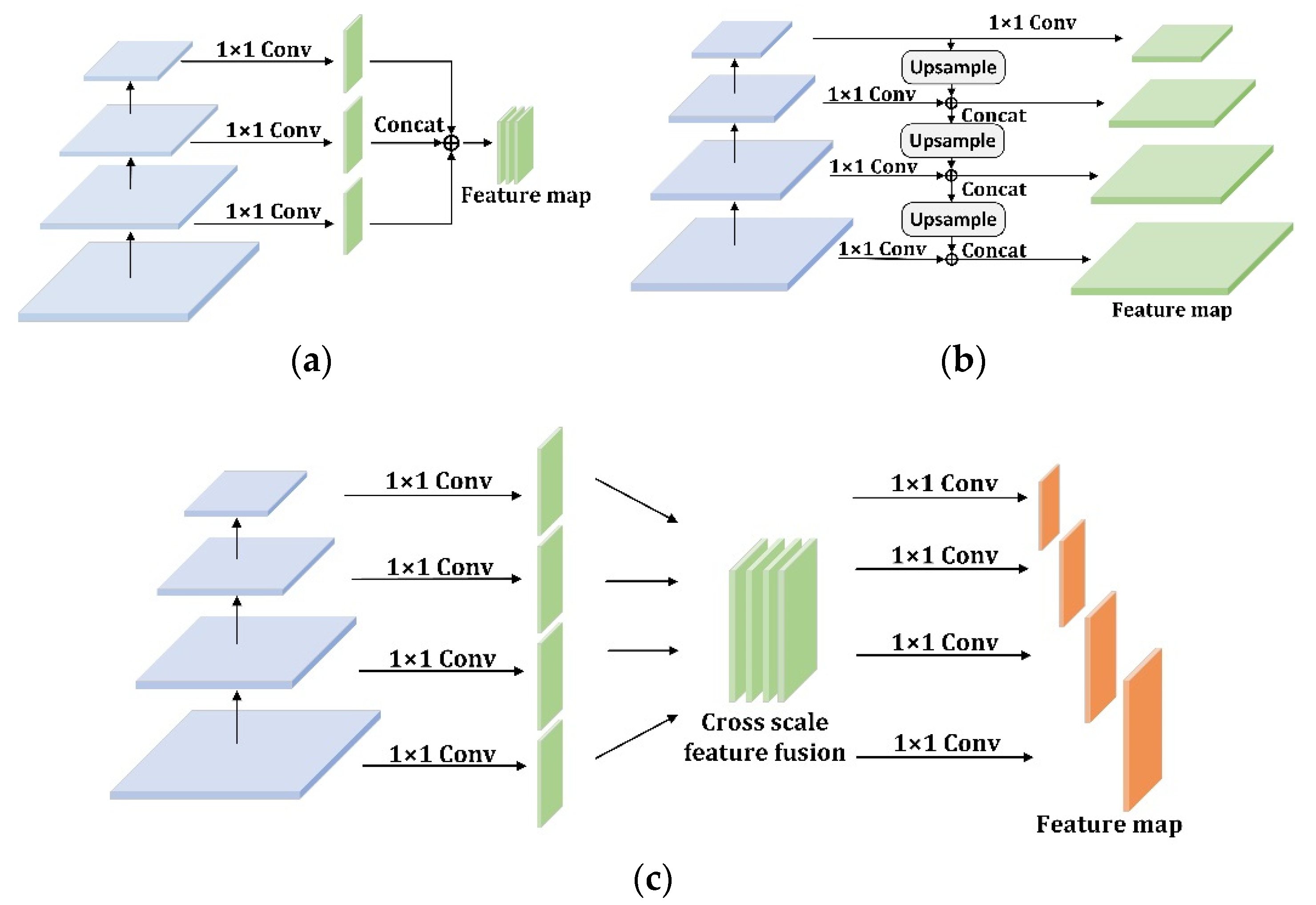
2.3.2. The Multi-Scale Feature Fusion Based Method
2.3.3. The Mining Context Information-Based Method
2.3.4. The Refined Anchor Mechanism Based Method
2.3.5. Direction Prediction-Based Method
2.3.6. The Super-Resolution Based Method
2.3.7. The Transformer-Based Method
2.3.8. Non-Strongly Supervised Learning-Based Method
2.3.9. Other Methods
3. Results
3.1. Benchmark Datasets
- NWPU VHR-10 [162] is a very high-resolution dataset with 800 images and 3651 instances for optical RSI object detection and contains ten categories of objects, where the categories are: airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, and vehicle.
- DOTA [163] is a fifteen categories of RSOD dataset containing 2806 optical RSIs and a total of 188,282 instances. The dataset is labeled by experts with horizontal annotation and rotating annotation. The categories of objects are as follows: plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, and basketball court.
- DIOR [16] contains 23,463 optical RSIs and 192,472 instances in total, with a spatial resolution of 0.5 to 30 m. Images present different states such as environment, weather, season, illumination with 800 × 800 in size. The twenty categories of objects are as follows: airplane, airport, base-ball field, basketball court, bridge, chimney, dam, expressway service area, expressway toll station, harbor, golf course, ground track field, overpass, ship, stadium, storage tank, tennis court, train station, vehicle, and windmill.
- UCAS-AOD [164] contains vehicle data as well as aircraft data, selected from the Google Earth aerial image dataset. The vehicle data contains 310 images with 2819 vehicle instances. The aircraft data contains 600 images, including 3210 aircraft instances, with an image size of approximately 1000 × 1000.
- HRSC2016 [165] is a dataset created specifically for ship detection. The dataset contains 1070 images with a total of 2917 ship instances, ranging from 300 × 300 to 1500 × 900 in size.
- LEVIR [168] consists of 3791 high-resolution RSIs from Google Earth, with the size of 800 × 600 and a spatial resolution of 0.2–1 m. There are three categories of objects in the dataset: aircraft, ships, and oil tanks.
- HRSSD [81] is a category-balanced RSI dataset, the images are cropped from Google Earth and BaiDu Map. The dataset contains 26,722 images, totaling 13 categories of objects, which are: airplane, baseball diamond, basketball court, bridge, crossroad, ground track field, harbor, parking lot, ship, storage tank, T junction, tennis court, vehicle.
- AI-TOD [169] is a challenging dataset specially designed for remote sensing tiny object detection. 28,036 images with 700,621 instances are collected in the dataset, and the average size of the objects is only 12.8 pixels, which is much smaller than other datasets. Images are mainly collected from multiple datasets with the 800 × 800 pixels, including eight categories of objects: airplane, bridge, storage-tank, ship, swimming-pool, vehicle, person, and wind-mill.
- VEDAI [170] is a dataset for remote sensing vehicle detection, which contains a total of 1210 aerial images with 1024 × 1024 resolution. The nine categories of objects included are: plane, boat, camping car, car, pick-up, tractor, truck, van, and the other category, which contain five categories of vehicles with different appearance. The scale of each category varies widely and presents different orientations.
3.2. Performance Metrics
3.3. Performance Comparison
4. Discussion
- Improve network structures: At present, the slowing improvement rate of remote sensing detector performance indicates that existing methods have reached their limitations, making it difficult to achieve a breakthrough. Thus, the question of how to further improve the technology is the key problem that needs to be solved. The underlying network structure, as the model’s foundation, is likely the key to overcoming the problem. A state-of-the-art network structure designed specifically for RSIs will serve complex objects more effectively; this is certainly a worthwhile research direction.
- Improve light weight models: In order to extract features with rich information representation, networks are mostly designed with extremely deep structures, requiring the optimization of huge numbers of parameters. This increases the model’s demand for data while increasing the burden on computing facilities. Current low arithmetic portable embeddable devices cannot implement such weighty models. The question of how to reduce the parameter scale of existing models in order to improve their practicality is particularly significant. Light weight models involve the participation of various aspects such as network structure and optimization methods.
- Improve weakly supervised learning: Defects in performance restrict the application scope of weakly supervised learning, and consequently, this direction is seldom explored. The advantages of labeling also broaden development prospects, and the further use of detection capabilities is a topic that is worthy of in-depth study. In addition, weakly supervised rotation detectors have not been developed due to the absence of boundary information, and the HBB used in current models do not accurately locate remote sensing objects with complex directional distributions. Thus, weakly supervised learning for rotation detection is advancing.
- Improve the direction prediction strategy: Direction is one of the essential manifestations of object position information, and a variety of direction recognition systems have been established for accurate object orientation. However, most such models set the direction in the range of 0–180°, which does not take orientation into account. For instance, a model defining the bow and stern of a ship does not provide a discriminant. Object orientation detection is of great significance for practical applications and deserves further attention. Meanwhile, there is no standard for determining how the position of a rotating object shall be correctly detected. Current IOU evaluation criteria have restrictions due to the drawback that slight deviations in the angle between the two directional boxes will lead to a drastic decrease in the IOU, which hinders the measurement of the IOU for the directional boxes. Therefore, the metric of angle needs to be carefully examined to reasonably assess the rotation of objects. Moreover, direction detection models struggle with objects that have no obvious directional information, such as storage tanks, which is another a matter that is worthy of discussion.
- Improve super-resolution detection: For weak object detection without sufficient structural knowledge, super-resolution reconstruction technology can effectively expand the object scale and provide additional details to boost its identification effect. As such, this approach which has attracted widespread research interest. However, the effective combination of the two tasks turns out to be challenging due to the question of how to guide the super-resolution network to purposefully enhance details that are not adequately expressed in the object itself, instead of enhancing some irrelevant information in a general way. In addition, the double parameters produced by the joint network restrict the actual speed, and optimization algorithms need to be tailored to further reduce the time cost. The implementation of specific reconstruction strategies to enhance the super-resolution effect on the object and weaken the network’s focus on the background is worth investigating.
- Improve small object issues: Small object detection has always been a priority in RSOD. Small objects—whose pixel occupancy is small and features are difficult to extract, making them prone to being obscured during the forward propagation—are commonplace in RSIs. Although researchers are currently studying this phenomenon and proposing various solutions, these tend to only alleviate the issue. Small object issues become problematic in the following three respects: (1) Sample imbalance problem: small objects account for a low proportion of remote sensing data. After statistics, objects with pixels less than 16 × 16 only account for 10% of the DIOR dataset. As such, these few small objects do not get enough attention from the system, resulting in missed detections. (2) Loss imbalance problem: during network training, the contribution of small objects to losses is much smaller than that of others, which is mainly due to the minor regression distance, thus yielding negligible loss. This loss imbalance phenomenon also leads to poor results for small objects. (3) Matching imbalance problem: positive and negative samples have been determined by the IOU threshold selection method. Slight deviations among small objects during label assignment results in large IOU variations, which limits small objects to produce only a small number of matching BBoxes, thereby reducing the chances of small objects being selected and increasing the number of missed matches. Therefore, it would be useful to boost performance regarding small objects. Small objects, such as ships in ports and aircraft in airports, tend to be densely distributed in RSIs, but their detection remains an arduous task. Indeed, there is no definitive way to solve the problem of dense distribution. In the future, densely packed small objects must be taken into account to achieve accurate localization and identification.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
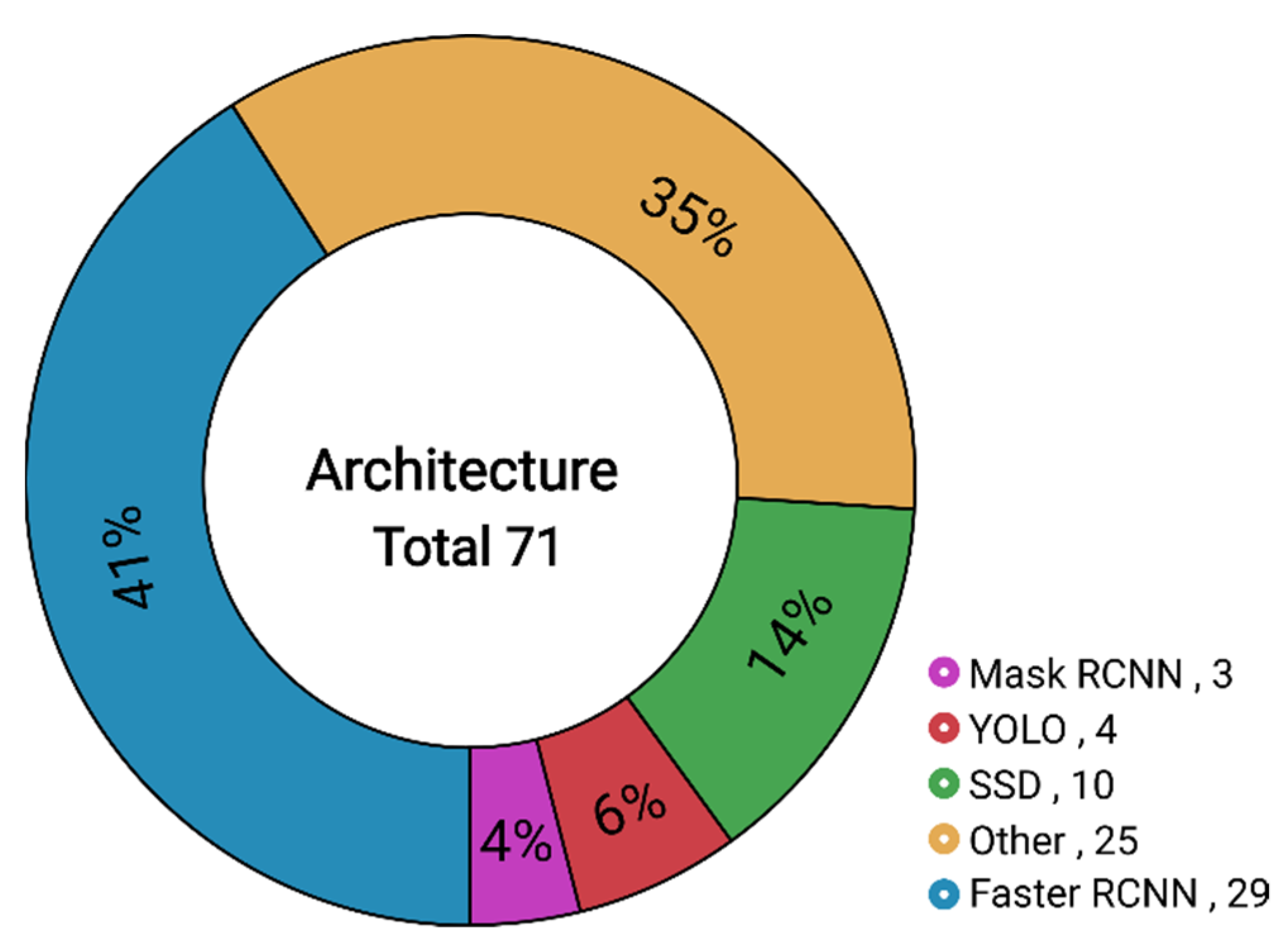
| Method | Characteristics | Ref. | |
|---|---|---|---|
| Attention mechanism | Spatial attention |
| [61,72,73,74,75,76] |
| Channel attention |
| [60,77] | |
| Joint attention |
| [78,79,80] | |
| Multi-scale feature fusion | Simple feature fusion |
| [58,62,81,82,83] |
| Feature pyramid fusion |
| [12,73,75,84,85,86] | |
| Cross-scale feature fusion |
| [11,74,87,88] | |
| Mining context information | Enlarge detection window |
| [91,92,93] |
| Enhance receptive field |
| [58,86,87,94,95] | |
| Attention mechanism |
| [71,73,75] | |
| Refined anchor | Set more scale anchors |
| [58,96,97] |
| Adaptive anchor mechanism |
| [12,80,98] | |
| Anchor-free |
| [71,99,100,101,102,103] | |
| Weakly supervised learning | Multiple instance learning |
| [14,141,142,143,144] |
| Based on segmentation |
| [145,146] | |
| Other methods |
| [147,148,149] | |
| Other methods | Special feature mapping |
| [57,150,151] |
| Transfer Learning |
| [152,153,154] | |
| Knowledge Distilling |
| [156,157,158,159] | |
| Multi-task learning |
| [74,78,110,160,161] | |
| Multi-source data fusion |
| [55,59] | |
Appendix B
| Dataset: DOTA | ||||||
|---|---|---|---|---|---|---|
| Models | Years | Backbones | Methods | Proposals | Dataset Set | mAP (%) |
| Strongly Supervised | ||||||
| Ref. [79] | 2019 | VGG-16 | Attention mechanism | HBB | 50%, 16%, 34% | 49.16 |
| Ref. [85] 1 | 2018 | ResNet-101 | Feature fusion | OBB | 50%, 16%, 34% | 81.25 |
| CAD-Net [75] | 2019 | ResNet-101 | Context information | OBB | 50%, 16%, 34% | 69.9 |
| SE-SSD [94] | 2019 | VGG-16 | Context information | HBB | 50%, 16%, 34% | 70.8 |
| FSoD-Net [96] | 2021 | MSE-Net | Improved anchor | HBB | 50%, 16%, 34% | 75.33 |
| SARA [12] | 2021 | ResNet-50 | Improved anchor | OBB | 50%, 16%, 34% | 79.91 |
| LO-Det [100] | 2021 | MobileNetv2 | Improved anchor | OBB | 50%, 16%, 34% | 66.17 |
| SKNet [101] 1 | 2021 | Hourglass-104 | Improved anchor | OBB | 75%, 25% | 83.9 |
| CBDA-Net [103] | 2021 | DLA-34 | Improved anchor | OBB | 50%, 16%, 34% | 75.74 |
| Rs-Det [105] | 2019 | ResNet-50 | Direction prediction | HBB | 50%, 16%, 34% | 65.33 |
| FFA [84] | 2020 | ResNet-101 | Direction prediction | OBB | 50%, 16%, 34% | 75.7 |
| F3-Net [109] | 2020 | ResNet-50 | Direction prediction | OBB | 50%, 16%, 34% | 76.02 |
| HBB | 76.48 | |||||
| AMFFA-Net [74] | 2021 | ResNet-101 | Direction prediction | OBB | 50%, 16%, 34% | 76.27 |
| HBB | 78.06 | |||||
| A2S-Det [108] | 2021 | ResNet-50 | Direction prediction | OBB | 50%, 16%, 34% | 70.42 |
| ResNet-101 | 70.64 | |||||
| HyNet [150] | 2020 | ResNet-50 | Feature mapping | HBB | 50%, 16%, 34% | 62.01 |
| Ref. [110] | 2019 | ResNet-101 | Multi-task learning | OBB | 50%, 16%, 34% | 67.96 |
| HBB | 69.88 | |||||
| RADet [78] | 2020 | ResNet-101 | Multi-task learning | OBB | 50%, 16%, 34% | 69.09 |
| ADT-Det [124] | 2021 | ResNet-50 | Transformer | OBB | 50%, 16%, 34% | 79.95 |
| O2DETR [129] | 2021 | ResNet-50 | Transformer | OBB | 50%, 16%, 34% | 79.66 |
| Dataset: NWPU VHR-10 | ||||||
| Strongly Supervised | ||||||
| RICNN [104] | 2016 | AlexNet | Direction prediction | HBB | 20%, 20%, 60% | 72.63 |
| HRCNN [81] | 2019 | AlexNet | Feature fusion | HBB | 20%, 20%, 60% | 73.54 |
| RECNN [160] | 2020 | VGG-16 | Multi-task learning | HBB | 20%, 20%, 60% | 79.2 |
| PSBNet [154] | 2018 | ResNet-101 | Transfer learning | HBB | 20%, 20%, 60% | 82.0 |
| Sig-NMS [152] 1 | 2019 | VGG-16 | Transfer learning | HBB | 20%, 20%, 60% | 82.9 |
| TRD [125] | 2022 | ResNet-50 | Transformer | HBB | 20%, 20%, 60% | 87.9 |
| Ref. [110] | 2019 | ResNet-101 | Direction prediction | HBB | 20%, 20%, 60% | 89.07 |
| F3-Net [109] | 2020 | ResNet-50 | Direction prediction | HBB | 20%, 20%, 60% | 91.89 |
| CA-CNN [92] | 2019 | VGG16 | Context information | HBB | 40%, 10%, 50% | 90.97 |
| MSNet [58] | 2020 | DarkNet53 | Attention mechanism | HBB | 40%, 60% | 95.4 |
| HyNet [150] | 2020 | ResNet-50 | Feature mapping | HBB | 40%, 60% | 99.17 |
| RADet [78] | 2020 | ResNet-101 | Direction prediction | HBB | 60%, 20%, 20% | 90.24 |
| FMSSD [95] | 2019 | VGG-16 | Context information | HBB | 60%, 20%, 20% | 90.40 |
| CANet [88] | 2020 | ResNet-101 | Context information | HBB | 60%, 20%, 20% | 92.2 |
| YOLOv3-Att [73] | 2020 | DarkNet-53 | Attention mechanism | HBB | 60%, 20%, 20% | 94.49 |
| DCL-Net [86] | 2020 | ResNet-101 | Feature fusion | HBB | 60%, 20%, 20% | 94.55 |
| Ref. [57] | 2018 | VGG-16 | Feature mapping | HBB | 60%, 40% | 94.87 |
| Ref. [91] | 2017 | ZFNet | Context information | HBB | 75%, 25% | 87.12 |
| CAD-Net [75] | 2019 | ResNet-101 | Context information | HBB | 75%, 25% | 91.5 |
| LFPNet [90] | 2021 | ResNet-101 | Feature fusion | HBB | 75%, 25% | 93.23 |
| CANet [71] | 2021 | RestNet-101 | Attention mechanism | HBB | 75%, 25% | 93.33 |
| Ref. [79] | 2019 | VGG-16 | Attention mechanism | HBB | 80%, 20% | 85.08 |
| Non-strongly Supervised | ||||||
| Ref. [143] | 2020 | VGG-16 | WSL | HBB | 58%, 17%, 25% | 20.19 |
| Ref. [14] | 2021 | VGG-16 | WSL | HBB | 60%, 20%, 20% | 53.6 |
| PCIR [142] | 2020 | VGG-16 | WSL | HBB | 58%, 17%, 25% | 54.97 |
| TCANet [141] | 2020 | VGG-16 | WSL | HBB | 75%, 25% | 58.82 |
| FSODM [133] | 2021 | DarkNet-53 | SSL | HBB | - | 65.0 |
| Ref. [149] | 2021 | CSPDarkNet-53 | WSL | HBB | 70%, 10%, 20% | 92.4 |
| Dataset: DIOR | ||||||
| Strongly Supervised | ||||||
| LO-Det [100] | 2021 | MobileNetv2 | Improved anchor | HBB | 50%, 50% | 65.85 |
| TRD [125] | 2022 | ResNet-50 | Transformer | HBB | 50%, 50% | 66.8 |
| Ref. [11] | 2020 | ResNet-101 | Attention mechanism | HBB | 50%, 50% | 68.0 |
| MFPNet [87] | 2021 | VGG-16 | Context information | HBB | 50%, 50% | 71.2 |
| FRPNet [72] | 2020 | ResNet-101 | Attention mechanism | HBB | 50%, 50% | 71.8 |
| FSoD-Net [96] | 2021 | MSE-Net | Improved anchor | HBB | 50%, 50% | 71.8 |
| Ref. [80] | 2020 | ResNet-50 | Improved anchor | HBB | 50%, 50% | 73.6 |
| CANet [88] | 2020 | ResNet-101 | Context information | HBB | 50%, 50% | 74.3 |
| Non-strongly Supervised | ||||||
| FCC-Net [144] | 2020 | ResNet-50 | WSL | HBB | 50%, 50% | 18.1 |
| PCIR [142] | 2020 | VGG-16 | WSL | HBB | 50%, 50% | 24.92 |
| TCANet [141] | 2020 | VGG-16 | WSL | HBB | 50%, 50% | 25.82 |
| prototype-CNN [132] | 2021 | ResNet-101 | SSL | HBB | 50%, 50% | 32.6 |
| FSODM [133] | 2021 | DarkNet-53 | SSL | HBB | other | 36.0 |
| Ref. [143] | 2020 | VGG-16 | WSL | HBB | 50%, 50% | 52.11 |
References
- Lim, J.-S.; Astrid, M.; Yoon, H.-J.; Lee, S.-I. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Zhang, J.; Zhang, L.; Liu, T.; Wang, Y. YOLSO: You Only Look Small Object. J. Vis. Commun. Image Represent. 2021, 81, 103348. [Google Scholar] [CrossRef]
- Van der Meer, F. Remote-sensing image analysis and geostatistics. Int. J. Remote Sens. 2012, 33, 5644–5676. [Google Scholar] [CrossRef]
- Van der Meer, F.D.; van der Werff, H.M.A.; van Ruitenbeek, F.J.A.; Hecker, C.A.; Bakker, W.H.; Noomen, M.F.; van der Meijde, M.; Carranza, E.J.M.; Smeth, J.B.D.; Woldai, T. Multi- and hyperspectral geologic remote sensing: A review. Int. J. Appl. Earth Obs. Geoinf. 2012, 14, 112–128. [Google Scholar] [CrossRef]
- ElMikaty, M.; Stathaki, T. Detection of Cars in High-Resolution Aerial Images of Complex Urban Environments. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5913–5924. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Liu, L.; Wang, Z.; Qiu, T.; Chen, Q.; Lu, Y.; Suen, C.Y. Document image classification: Progress over two decades. Neurocomputing 2021, 453, 223–240. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S. A New Spatial-Oriented Object Detection Framework for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4407416. [Google Scholar] [CrossRef]
- You, Y.; Ran, B.; Meng, G.; Li, Z.; Liu, F.; Li, Z. OPD-Net: Prow Detection Based on Feature Enhancement and Improved Regression Model in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6121–6137. [Google Scholar] [CrossRef]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature Split–Merge–Enhancement Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5616217. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-Scale Feature Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 431–435. [Google Scholar] [CrossRef]
- Hou, J.-B.; Zhu, X.; Yin, X.-C. Self-Adaptive Aspect Ratio Anchor for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 1318. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614914. [Google Scholar] [CrossRef]
- Wang, H.; Li, H.; Qian, W.; Diao, W.; Zhao, L.; Zhang, J.; Zhang, D. Dynamic Pseudo-Label Generation for Weakly Supervised Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 1461. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Alganci, U.; Soydas, M.; Sertel, E. Comparative Research on Deep Learning Approaches for Airplane Detection from Very High-Resolution Satellite Images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Lei, L.; Sun, H.; Kuang, G. A Review of Remote Sensing Image Object Detection Algorithms Based on Deep Learning. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; pp. 34–43. [Google Scholar]
- Kim, T.; Park, S.R.; Kim, M.G.; Jeong, S.; Kim, K.O.J.P.E.; Sensing, R. Tracking Road Centerlines from High Resolution Remote Sensing Images by Least Squares Correlation Matching. Photogramm. Eng. Remote Sens. 2004, 70, 1417–1422. [Google Scholar] [CrossRef]
- Chaudhuri, D.; Kushwaha, N.K.; Samal, A. Semi-Automated Road Detection From High Resolution Satellite Images by Directional Morphological Enhancement and Segmentation Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1538–1544. [Google Scholar] [CrossRef]
- Akcay, H.G.; Aksoy, S. Building detection using directional spatial constraints. In Proceedings of the Geoscience & Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010. [Google Scholar]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, Z.; Wang, L.; Tan, T. Feature Coding in Image Classification: A Comprehensive Study. IEEE Trans. Softw. Eng. 2013, 36, 493–506. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Fei-Fei, L.; Perona, P. A Bayesian hierarchical model for learning natural scene categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Yi, J.; Wu, P.; Metaxas, D.N. ASSD: Attentive single shot multibox detector. Comput. Vis. Image Underst. 2019, 189, 102827. [Google Scholar] [CrossRef] [Green Version]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.-G.; Chen, Y.; Xue, X. DSOD: Learning Deeply Supervised Object Detectors from Scratch. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1937–1945. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv, 0096. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Zhang, S.; Wen, L.; Lei, Z.; Li, S.Z. RefineDet++: Single-Shot Refinement Neural Network for Object Detection. IEEE Trans Circuits Syst Video Technol 2021, 31, 674–687. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. In Proceedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2018; pp. 404–419. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer Verlag: Berlin, Germany, 2018; pp. 765–781. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Simonyan, K.; Zisserman, A.J.a.p.a. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 34. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tian, J.; Tao, R.; Du, Q. Vehicle detection of multi-source remote sensing data using active fine-tuning network. ISPRS J. Photogramm. Remote Sens. 2020, 167, 39–53. [Google Scholar] [CrossRef]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Han, W.; Kuerban, A.; Yang, Y.; Huang, Z.; Liu, B.; Gao, J. Multi-Vision Network for Accurate and Real-Time Small Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6001205. [Google Scholar] [CrossRef]
- Sharma, M.; Dhanaraj, M.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. YOLOrs: Object Detection in Multimodal Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1497–1508. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, W.; Zhang, R.; Jiang, F. AMR-Net: Arbitrary-Oriented Ship Detection Using Attention Module, Multi-Scale Feature Fusion and Rotation Pseudo-Label. IEEE Access 2021, 9, 68208–68222. [Google Scholar] [CrossRef]
- Hua, X.; Wang, X.; Rui, T.; Zhang, H.; Wang, D. A fast self-attention cascaded network for object detection in large scene remote sensing images. Appl. Soft Comput. 2020, 94, 106495. [Google Scholar] [CrossRef]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2-CNN: Fast Tiny Object Detection in Large-Scale Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Dong, Z.; Zhu, Y. Multiscale Block Fusion Object Detection Method for Large-Scale High-Resolution Remote Sensing Imagery. IEEE Access 2019, 7, 99530–99539. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In European Conference on Computer Vision, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In European Conference on Computer Vision, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 391–405. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Shi, L.; Kuang, L.; Xu, X.; Pan, B.; Shi, Z. CANet: Centerness-Aware Network for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603613. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Wu, Y.; Zhang, K.; Wang, Q. FRPNet: A Feature-Reflowing Pyramid Network for Object Detection of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8004405. [Google Scholar] [CrossRef]
- Shi, G.; Zhang, J.; Liu, J.; Zhang, C.; Zhou, C.; Yang, S. Global Context-Augmented Objection Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10604–10617. [Google Scholar] [CrossRef]
- Chen, L.; Liu, C.; Chang, F.; Li, S.; Nie, Z. Adaptive multi-level feature fusion and attention-based network for arbitrary-oriented object detection in remote sensing imagery. Neurocomputing 2021, 451, 67–80. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Mu, X.; Kou, G.; Zhao, J. Object Detection Based on Efficient Multiscale Auto-Inference in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1650–1654. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine Feature Pyramid Network and Multi-Layer Attention Network for Arbitrary-Oriented Object Detection of Remote Sensing Images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Wan, L.; Zhu, J.; Xu, G.; Deng, M. Multi-Scale Spatial and Channel-wise Attention for Improving Object Detection in Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2020, 17, 681–685. [Google Scholar] [CrossRef]
- Tian, Z.; Zhan, R.; Hu, J.; Wang, W.; He, Z.; Zhuang, Z. Generating Anchor Boxes Based on Attention Mechanism for Object Detection in Remote Sensing Images. Remote Sens. 2020, 12, 2416. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Deng, Z.; Lin, L.; Hao, S.; Zou, H.; Zhao, J. An enhanced deep convolutional neural network for densely packed objects detection in remote sensing images. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017. [Google Scholar]
- Ding, P.; Zhang, Y.; Deng, W.-J.; Jia, P.; Kuijper, A. A light and faster regional convolutional neural network for object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Sun, X.; Yan, M.; Guo, Z.; Fu, K. Position Detection and Direction Prediction for Arbitrary-Oriented Ships via Multitask Rotation Region Convolutional Neural Network. IEEE Access 2018, 6, 50839–50849. [Google Scholar] [CrossRef]
- Liu, E.; Zheng, Y.; Pan, B.; Xu, X.; Shi, Z. DCL-Net: Augmenting the Capability of Classification and Localization for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7933–7944. [Google Scholar] [CrossRef]
- Yuan, Z.; Liu, Z.; Zhu, C.; Qi, J.; Zhao, D. Object Detection in Remote Sensing Images via Multi-Feature Pyramid Network with Receptive Field Block. Remote Sens. 2021, 13, 862. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Chen, Y.; Jiao, L.; Shang, R. Cross-Layer Attention Network for Small Object Detection in Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2148–2161. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Guo, C.; Li, H.; Zhang, C.; Zheng, F.; Zhao, Y. A parallel down-up fusion network for salient object detection in optical remote sensing images. Neurocomputing 2020, 415, 411–420. [Google Scholar] [CrossRef]
- Zhang, W.; Jiao, L.; Li, Y.; Huang, Z.; Wang, H. Laplacian Feature Pyramid Network for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604114. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]
- Gong, Y.; Xiao, Z.; Tan, X.; Sui, H.; Xu, C.; Duan, H.; Li, D. Context-Aware Convolutional Neural Network for Object Detection in VHR Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 34–44. [Google Scholar] [CrossRef]
- Liu, Q.; Xiang, X.; Yang, Z.; Hu, Y.; Hong, Y. Arbitrary Direction Ship Detection in Remote-Sensing Images Based on Multitask Learning and Multiregion Feature Fusion. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1553–1564. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Wang, Z.; Chen, H.; Shi, H.; Chen, L. Spatial Enhanced-SSD For Multiclass Object Detection in Remote Sensing Images. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 318–321. [Google Scholar]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-Merged Single-Shot Detection for Multiscale Objects in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3377–3390. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. FSoD-Net: Full-Scale Object Detection From Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602918. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, M.; Wang, Y.; Zhu, Y.; Zhang, Z. Object Detection in High Resolution Remote Sensing Imagery Based on Convolutional Neural Networks With Suitable Object Scale Features. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2104–2114. [Google Scholar] [CrossRef]
- Yu, Y.; Guan, H.; Li, D.; Gu, T.; Tang, E.; Li, A. Orientation guided anchoring for geospatial object detection from remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 160, 67–82. [Google Scholar] [CrossRef]
- Wang, P.; Niu, Y.; Xiong, R.; Ma, F.; Zhang, C. DGANet: Dynamic Gradient Adjustment Anchor-Free Object Detection in Optical Remote Sensing Images. Remote Sens. 2021, 13, 1642. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.-G.; Wang, H.; Jie, F.; Tao, R. LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603515. [Google Scholar] [CrossRef]
- Cui, Z.; Leng, J.; Liu, Y.; Zhang, T.; Quan, P.; Zhao, W. SKNet: Detecting Rotated Ships as Keypoints in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8826–8840. [Google Scholar] [CrossRef]
- Shi, F.; Zhang, T.; Zhang, T. Orientation-Aware Vehicle Detection in Aerial Images via an Anchor-Free Object Detection Approach. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5221–5233. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, L.; Lu, H.; He, Y. Center-Boundary Dual Attention for Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603914. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Huang, H.; Huo, C.; Wei, F.; Pan, C. Rotation and Scale-Invariant Object Detector for High Resolution Optical Remote Sensing Images. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1386–1389. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Bao, S.; Zhong, X.; Zhu, R.; Zhang, X.; Li, Z.; Li, M. Single Shot Anchor Refinement Network for Oriented Object Detection in Optical Remote Sensing Imagery. IEEE Access 2019, 7, 87150–87161. [Google Scholar] [CrossRef]
- Xiao, Z.; Wang, K.; Wan, Q.; Tan, X.; Xu, C.; Xia, F. A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection. Remote Sens. 2020, 13, 73. [Google Scholar] [CrossRef]
- Ye, X.; Xiong, F.; Lu, J.; Zhou, J.; Qian, Y. 3-Net: Feature Fusion and Filtration Network for Object Detection in Optical Remote Sensing Images. Remote Sens. 2020, 12, 4027. [Google Scholar] [CrossRef]
- Xu, C.; Li, C.; Cui, Z.; Zhang, T.; Yang, J. Hierarchical Semantic Propagation for Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4353–4364. [Google Scholar] [CrossRef]
- Shermeyer, J.; Van Etten, A. The effects of super-resolution on object detection performance in satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; NeurIPS: Vancouver, BC, Canada, 2014; Volume 27. [Google Scholar]
- Mostofa, M.; Ferdous, S.N.; Riggan, B.S.; Nasrabadi, N.M. Joint-SRVDNet: Joint Super Resolution and Vehicle Detection Network. IEEE Access 2020, 8, 82306–82319. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network. In Proceedings of the Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2018; pp. 210–226. [Google Scholar]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Courtrai, L.; Pham, M.-T.; Lefèvre, S. Small Object Detection in Remote Sensing Images Based on Super-Resolution with Auxiliary Generative Adversarial Networks. Remote Sens. 2020, 12, 3152. [Google Scholar] [CrossRef]
- Bashir, S.M.A.; Wang, Y. Small Object Detection in Remote Sensing Images with Residual Feature Aggregation-Based Super-Resolution and Object Detector Network. Remote Sens. 2021, 13, 1854. [Google Scholar] [CrossRef]
- Ji, H.; Gao, Z.; Mei, T.; Ramesh, B. Vehicle Detection in Remote Sensing Images Leveraging on Simultaneous Super-Resolution. IEEE Geosci. Remote Sens. Lett. 2020, 17, 676–680. [Google Scholar] [CrossRef]
- Gao, P.; Tian, T.; Li, L.; Ma, J.; Tian, J. DE-CycleGAN: An Object Enhancement Network for Weak Vehicle Detection in Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3403–3414. [Google Scholar] [CrossRef]
- Liu, W.; Luo, B.; Liu, J. Synthetic Data Augmentation Using Multiscale Attention CycleGAN for Aircraft Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4009205. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision, Proceedings of the Comput Vis ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zheng, Y.; Sun, P.; Zhou, Z.; Xu, W.; Ren, Q. ADT-Det: Adaptive Dynamic Refined Single-Stage Transformer Detector for Arbitrary-Oriented Object Detection in Satellite Optical Imagery. Remote Sens. 2021, 13, 2623. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Y.; Zeng, Y. Transformer with Transfer CNN for Remote-Sensing-Image Object Detection. Remote Sens. 2022, 14, 984. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.; Wa, S.; Chen, S.; Ma, Q. GANsformer: A Detection Network for Aerial Images with High Performance Combining Convolutional Network and Transformer. Remote Sens. 2022, 14, 923. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Ma, T.; Mao, M.; Zheng, H.; Gao, P.; Wang, X.; Han, S.; Ding, E.; Zhang, B.; Doermann, D. Oriented object detection with transformer. arXiv 2021, arXiv:2106.03146. [Google Scholar]
- Zhou, Z.-H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Y.; Zheng, Z.; Ma, A.; Lu, X.; Zhang, L. COLOR: Cycling, Offline Learning, and Online Representation Framework for Airport and Airplane Detection Using GF-2 Satellite Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8438–8449. [Google Scholar] [CrossRef]
- Cheng, G.; Yan, B.; Shi, P.; Li, K.; Yao, X.; Guo, L.; Han, J. Prototype-CNN for Few-Shot Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604610. [Google Scholar] [CrossRef]
- Li, X.; Deng, J.; Fang, Y. Few-Shot Object Detection on Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601614. [Google Scholar] [CrossRef]
- Bilen, H.; Vedaldi, A. Weakly Supervised Deep Detection Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2846–2854. [Google Scholar]
- Tang, P.; Wang, X.; Bai, X.; Liu, W. Multiple Instance Detection Network with Online Instance Classifier Refinement. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3059–3067. [Google Scholar]
- Tang, P.; Wang, X.; Bai, S.; Shen, W.; Bai, X.; Liu, W.; Yuille, A. PCL: Proposal Cluster Learning for Weakly Supervised Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 176–191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wan, F.; Liu, C.; Ke, W.; Ji, X.; Jiao, J.; Ye, Q. C-mil: Continuation multiple instance learning for weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2199–2208. [Google Scholar]
- Kantorov, V.; Oquab, M.; Cho, M.; Laptev, I. ContextLocNet: Context-Aware Deep Network Models for Weakly Supervised Localization. In European Conference on Computer Vision, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 350–365. [Google Scholar]
- Zhang, M.; Zeng, B. A progressive learning framework based on single-instance annotation for weakly supervised object detection. Comput. Vis. Image Underst. 2020, 193, 102903. [Google Scholar] [CrossRef]
- Yi, S.; Ma, H.; Li, X.; Wang, Y. WSODPB: Weakly supervised object detection with PCSNet and box regression module. Neurocomputing 2020, 418, 232–240. [Google Scholar] [CrossRef]
- Feng, X.; Han, J.; Yao, X.; Cheng, G. TCANet: Triple Context-Aware Network for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6946–6955. [Google Scholar] [CrossRef]
- Feng, X.; Han, J.; Yao, X.; Cheng, G. Progressive Contextual Instance Refinement for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8002–8012. [Google Scholar] [CrossRef]
- Yao, X.; Feng, X.; Han, J.; Cheng, G.; Guo, L. Automatic Weakly Supervised Object Detection From High Spatial Resolution Remote Sensing Images via Dynamic Curriculum Learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 675–685. [Google Scholar] [CrossRef]
- Chen, S.; Shao, D.; Shu, X.; Zhang, C.; Wang, J. FCC-Net: A Full-Coverage Collaborative Network for Weakly Supervised Remote Sensing Object Detection. Electronics 2020, 9, 1356. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Wu, Z.-Z.; Weise, T.; Wang, Y.; Wang, Y. Convolutional neural network based weakly supervised learning for aircraft detection from remote sensing image. IEEE Access 2020, 8, 158097–158106. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object Detection in Optical Remote Sensing Images Based on Weakly Supervised Learning and High-Level Feature Learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; He, B.; Melgani, F.; Long, T. Point-Based Weakly Supervised Learning for Object Detection in High Spatial Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5361–5371. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Ma, A.; Han, X.; Zhao, J.; Liu, Y.; Zhang, L. HyNet: Hyper-scale object detection network framework for multiple spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 166, 1–14. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X.X. HSF-Net: Multiscale Deep Feature Embedding for Ship Detection in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Dong, R.; Xu, D.; Zhao, J.; Jiao, L.; An, J. Sig-NMS-Based Faster R-CNN Combining Transfer Learning for Small Target Detection in VHR Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8534–8545. [Google Scholar] [CrossRef]
- Li, S.; Xu, Y.; Zhu, M.; Ma, S.; Tang, H. Remote Sensing Airport Detection Based on End-to-End Deep Transferable Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1640–1644. [Google Scholar] [CrossRef]
- Zhong, Y.; Han, X.; Zhang, L. Multi-class geospatial object detection based on a position-sensitive balancing framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 138, 281–294. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, Y.; Mao, H.; Liu, R.; Pei, X.; Jiao, L.; Shang, R. A Lightweight Keypoint-Based Oriented Object Detection of Remote Sensing Images. Remote Sens. 2021, 13, 2459. [Google Scholar] [CrossRef]
- Liu, B.-Y.; Chen, H.-X.; Huang, Z.; Liu, X.; Yang, Y.-Z. ZoomInNet: A Novel Small Object Detector in Drone Images with Cross-Scale Knowledge Distillation. Remote Sens. 2021, 13, 1198. [Google Scholar] [CrossRef]
- Zhang, Y.; Yan, Z.; Sun, X.; Diao, W.; Fu, K.; Wang, L. Learning Efficient and Accurate Detectors with Dynamic Knowledge Distillation in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5613819. [Google Scholar] [CrossRef]
- Chen, J.; Wang, S.; Chen, L.; Cai, H.; Qian, Y. Incremental Detection of Remote Sensing Objects with Feature Pyramid and Knowledge Distillation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5600413. [Google Scholar] [CrossRef]
- Lei, J.; Luo, X.; Fang, L.; Wang, M.; Gu, Y. Region-enhanced convolutional neural network for object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5693–5702. [Google Scholar] [CrossRef]
- Wu, Q.; Feng, D.; Cao, C.; Zeng, X.; Feng, Z.; Wu, J.; Huang, Z. Improved Mask R-CNN for Aircraft Detection in Remote Sensing Images. Sensors 2021, 21, 2618. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic Fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random Access Memories: A New Paradigm for Target Detection in High Resolution Aerial Remote Sensing Images. IEEE Trans. Image Process. 2018, 27, 1100–1111. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.-S. Tiny Object Detection in Aerial Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3791–3798. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]













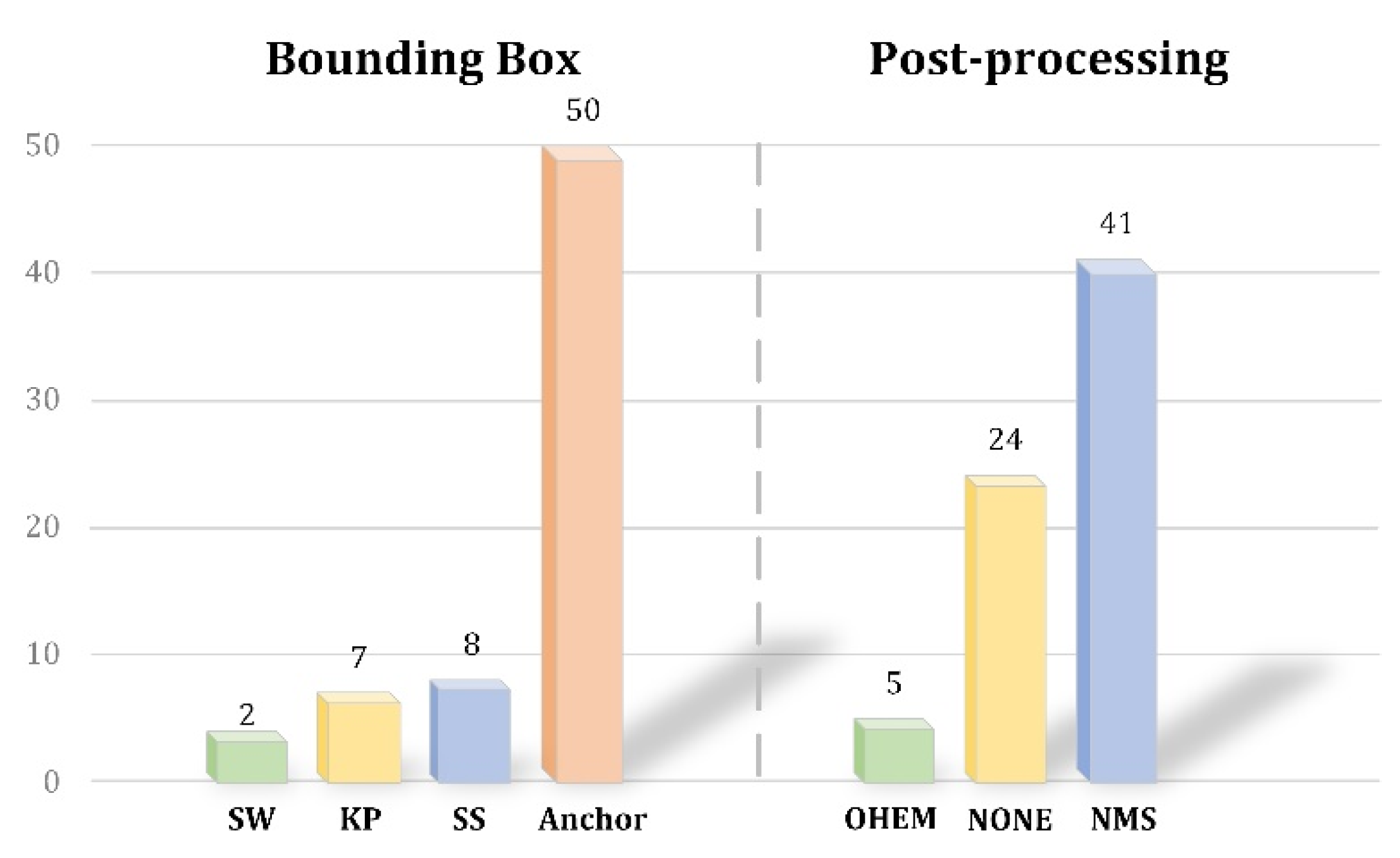
| Methods | Characteristics | Representatives | |
|---|---|---|---|
| Generate BBox | Based on Traversal method |
| Slide window |
| Selective search | ||
| Edge box | ||
| Based on anchor |
| Anchor | |
| |||
| |||
| Based on key points |
| Anchor-free | |
| |||
| |||
| Dataset | Quantity | Category | Size | Instance | Resolution | Label |
|---|---|---|---|---|---|---|
| NWPU VHR-10 [162] | 800 | 10 | 350 × 350–1200 × 1200 | 3651 | 0.5–2 m, 0.08 m | HBB |
| DOTA [163] | 2806 | 15 | 800 × 800–4000 × 4000 | 188,282 | 0.1–1 m | HBB, OBB |
| DIOR [16] | 23,463 | 20 | 800 × 800 | 192,472 | 0.5–30 m | HBB |
| UCAS-AOD [164] | 910 | 2 | 1000 × 1000 | 6029 | - | HBB, OBB |
| HRSC2016 [165] | 1070 | 1 | 300 × 300–1500 × 900 | 2917 | 0.4–2 m | HBB, OBB |
| RSOD [166,167] | 976 | 4 | 800 × 1000 | 6950 | 0.3–3 m | HBB |
| LEVIR [168] | 3791 | 3 | 800 × 600 | 11,028 | 0.2–1 m | HBB |
| HRSSD [81] | 26,722 | 13 | - | 55,740 | 0.15–1.2 m | HBB |
| AI-TOD [169] | 28,036 | 8 | 800 × 800 | 700,621 | - | HBB |
| VEDAI [170] | 1210 | 9 | 1024 × 1024 | - | 0.125 m | OBB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z.; Xu, D.; Ben, G.; Gao, Y. Deep Learning-Based Object Detection Techniques for Remote Sensing Images: A Survey. Remote Sens. 2022, 14, 2385. https://doi.org/10.3390/rs14102385
Li Z, Wang Y, Zhang N, Zhang Y, Zhao Z, Xu D, Ben G, Gao Y. Deep Learning-Based Object Detection Techniques for Remote Sensing Images: A Survey. Remote Sensing. 2022; 14(10):2385. https://doi.org/10.3390/rs14102385
Chicago/Turabian StyleLi, Zheng, Yongcheng Wang, Ning Zhang, Yuxi Zhang, Zhikang Zhao, Dongdong Xu, Guangli Ben, and Yunxiao Gao. 2022. "Deep Learning-Based Object Detection Techniques for Remote Sensing Images: A Survey" Remote Sensing 14, no. 10: 2385. https://doi.org/10.3390/rs14102385