1. Introduction
The innovations in dense stereo- or multiview photogrammetry, Light Detection and Ranging (LiDAR), synthetic aperture radar, and structure from motion have broadened the availability of 3D point cloud data, which are widely used in many fields, including automatic navigation [
1], 3D city management [
2] and 3D building reconstruction [
3]. Collected images of real 3D scenes may be occluded and are thus complex. Compare with 2D images which lose depth information and relative positions between two or more objects in the real world, 3D point cloud provides an opportunity for a better understanding of the surrounding environment for machines. Point cloud data contain rich semantic information and have high density and high precision. Hence, they have become one of the main data types used in 3D object recognition research. Point cloud data can enrich the understanding and analysis of complex 3D scenes. 3D laser scanners can measure objects without touching them and quickly obtain massive point cloud data, which include spatial coordinates and the color and reflection intensity of objects. These devices operate under any weather condition and achieve high precision, density, and efficiency. These unique advantages of 3D laser scanners provide 3D point cloud data with great application prospects and increase their market demand.
As a new surveying and mapping technology, airborne LiDAR technology can rapidly acquire large-scale and high-density ground information with relatively high precision; it has also been used in high-precision mapping, digital city reconstruction [
4], forest monitoring [
5], cultural heritage protection [
6], natural disaster monitoring, and other fields [
7].
Airborne laser scanning (ALS) point clouds have followed three characteristics: (1) Objects present large-scale variations between different categories, ranging from small spatial neighborhoods (cars, power lines) to large ones (buildings), such variations entail high requirements for data processing. (2) Many categories have evidence of geometric properties, e.g., tracts of roof and façade. (3) The objects in ALS point clouds exhibit discrepancies in elevation distributions [
8]. The ALS point cloud classification is a difficult problem due to terrain complexity, scene’s clutter, overlapping in the vertical direction, and nonuniformity density distribution.
In 3D classification, the point cloud is divided into groups and then a label is assigned according to their type. This step is an important part of laser point cloud data processing. In one method for ALS point cloud classification, each point in a point set is regarded as an independent entity, and only a single-point local feature is used in classification [
9]. However, single-point local feature classification is unstable for cases with a nonuniform point cloud density distribution, especially those involving complex scenes [
10]. Another classification method introduces contextual information for ALS point cloud classification on the basis of single-point local features [
11,
12]. The method using handcrafted features and classifiers require the manual extraction of context features in advance, which need manual intervention in data processing, and consumes 70–80% of the whole processing time [
13]. Meanwhile, low-dimensional handcrafted features have weak representation ability, and automated interpretation and knowledge discovery from 3D point cloud data remains challenging.
The recent research into 3D laser point cloud has already broken through traditional technical methods and has gradually been integrated into multiple disciplines (such as machine learning) [
1,
14,
15]. With the outstanding performance of deep learning technology in target recognition, researchers have also extended it to 3D target recognition to improve the level of automation and intelligence. Convolutional neural networks (CNNs) have achieved great success on 2D image recognition tasks; however, input point sets are different from CNN inputs, which refer to data defined on regular grids with uniform constant density. Many studies have attempted to generate feature images for point clouds and then apply them to 2D CNNs for ALS point cloud classification. However, transforming unstructured 3D point sets into regular representation inevitability causes spatial information loss.
Qi proposed a deep learning framework called PointNet that consumes unordered and unstructured point clouds directly [
16]. PointNet++ network was later developed to enable multiscale point feature learning [
17]. Following the great success of PointNet and PointNet++ network, many PointNet-like architectures have been proposed; they include PointCNN [
18], PointSift [
19], D-FCN [
20], PointLK [
21], KPConv [
22], PV-RCNN [
23] and so on. PointNet++ has been used in 3D object classification, 3D part segmentation, and 3D scene segmentation and has a broad market.
Although PointNet++ has a higher generalization ability than PointNet, its usage in the classification of large-scale airborne point clouds in complex scenes is still challenging. The objects on ALS point clouds cannot be present in CAD models such as ModelNet40, which are small man-made objects containing fixed information and are free from occlusion and noise [
17]. In module training, the process of splitting and sampling is inevitable on ALS point clouds. As ALS point clouds have their own characteristics listed above, a universal point cloud multitarget recognition method should be established, and the need for costly calculations in ALS point cloud classification should be eliminated.
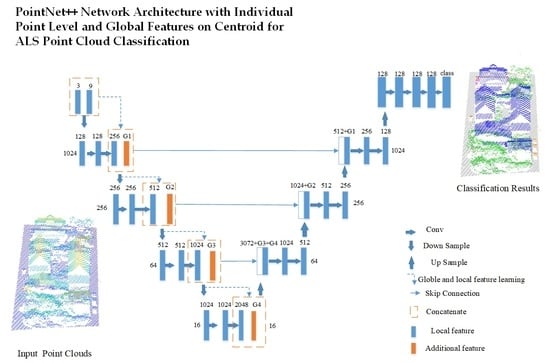
Inspired by the success of PointNet++ network, we proposed a method which fully utilizes point clouds in an end-to-end manner. The proposed method allows us to identify unordered point sets with varying densities without needing us to design complicated handcrafted features. The main contributions of this work are summarized as follows:
The point-level and global information on the centroid point in the sample layer in the PointNet++ network is added to the local feature at multiple scales to extract other useful informative features to solve the uneven distribution of point clouds problem.
One modified loss function based on focal loss function is proposed to solve the extremely uneven category distribution problem.
The elevation- and distance-based interpolation method is proposed for objects in ALS point clouds that exhibit discrepancies in elevation distributions.
In addition to a theoretical analysis, experimental evaluations are conducted using the Vaihingen 3D dataset of the International Society for Photogrammetry and Remote Sensing (ISPRS) and the GML(B) dataset.
2. Related Work
2.1. Using Handcrafted Features and Classifiers
Traditional point cloud classification methods are related to the estimation of single-point local features. In one strategy, only local geometry features are used, and each point in a point set is regarded as an independent entity. Antonarakis et al. used the 3D coordinates, elevation, and intensity of point clouds to classify forest and ground types on the basis of a supervised object-orientated approach [
24]. Zhang et al. calculated the 13 features of 3D point clouds in terms of geometry, radiometry, topology, and echo characteristics and then utilized a support vector machine (SVM) to classify ALS point clouds [
9]. However, classification methods that use single-point local features are unstable in cases involving nonuniform point cloud density distributions as they are influenced by classification noises and label inconsistencies [
10].
Another strategy involves the derivation of suitable 3D descriptors, such as spin image descriptors [
25], point feature histograms [
26] and the signature of histograms of orientations [
27]. Several approaches to 3D point cloud classification rely on 3D structure tensors, hence the proposal of the eigenvalue analysis method [
28], which may derive a set of local 3D shape features. These methods usually need to calculate additional local geometry features, such as planarity, sphericity, and roughness, to use the local structural information in the original 3D space. When the scene is complex, this process is usually time-consuming and results in a high computation cost.
Mallet [
29] classified full-waveform LiDAR data by using a pointwise multiclass SVM. Horvat designed three contextual filters for detecting overgrowing vegetation, small objects attached to planar surfaces, and small objects that do not belong to vegetation according to the nonlinear distribution characteristics on vegetation points [
11,
12]. Chehata used random forests for feature detection and classification of urban scenes collected by airborne laser scanning [
30]. Niemeyer proposed a contextual classification method on the basis of conditional random field (CRF) [
31]. This classification model was later extended, and the spatial and semantic contexts were incorporated into a hierarchical, high-order, two-layer CRF [
12].
These existing methods are generally applied to specific scenes. They also have weak representation ability, and they require manual intervention. In complex ALS point cloud semantic classification, these methods are laborious, and their robustness is unsatisfactory. The automated, machine-assisted solutions are needed amidst the increasing volume, variety, and velocity of digital data.
2.2. Using Deep Features and Neural Networks
The development of computer vision research in the past decade has broadened the availability of 3D point cloud data. The unprecedented volume, variety, and velocity of digital data overwhelm the existing capacities to manage and translate data into actionable information. Traditional point cloud classification methods are almost always focused on the design of handcrafted features and use machine learning-based classification models to conduct classification [
12]. Recently, deep learning methods have attracted increasing attention. Driven by the improvement of CNNs, available large-scale datasets, and high-performance computing resources, deep learning has enjoyed unprecedented popularity in recent years. The success of 2D CNNs in various image recognition tasks, such as image labeling, semantic segmentation, object detection, and target tracking, has also encouraged the application of these frameworks to 3D semantic classification. The straightforward extension of 2D CNNs to 3D classification is hampered when dealing with nonuniform and irregular point cloud features. In such a case, the process requires the transformation of input data into views or volumes so as to meet the requirements of image-based CNNs. Therefore, many deep learning approaches involve the transformation of 3D data into regular 2D images, and then back-projection of 2D labels to 3D point clouds; Therefore, the 3D semantic classification labels were generated [
32].
Qi et al. combined two distinct network architectures of the multiview approach with volumetric methods to improve the classification results; in their work, the 3D object was rotated to generate different 3D orientations, and each individual orientation was processed individually by the same network to generate 2D representations [
33]. Su et al. utilized different virtual cameras to recognize 3D shapes from a collection of their rendered views on 2D images and employed a multiview CNN to feed these images and thereby obtain the predicted categories [
34]. Boulch et al. proposed a framework which feeds multiple 2D image views (or snapshots) of point clouds into a fully convolutional network; in this framework, point cloud labels are obtained through back-projection [
35].
However, the convolution applied to regular data (image or volumeter) is not invariant to the permutation of input data. Nonetheless, these transformations of input data into views or volumes suffer from model complexity, computation cost and high space requirements as the storage and computation cost grows cubically with the grid resolution. Pictures may easily be affected by weather conditions, lighting, shooting angle, and images only have plane features and thus lack spatial information. Hence, one cannot realize real 3D scene classification, and exploring the efficient used CNNs in 3D data is still needed.
2.3. PointNet and PointNet++ Network
The PointNet network serves as the foundation of point-based classification methods and has thus become a hotspot for point cloud classification. The PointNet network is an end-to-end learning network for irregular point data that is highly robust to small input point perturbations along with corruption. This network eliminates the need to calculate costly handcrafted features and thereby provides a new paradigm for 3D understanding. The PointNet network also has the potential to train point clouds without requiring parameters that are specific to objects in ALS data; hence, it achieves high efficiency and effectiveness [
13]. Relative to volumetric models, the PointNet model reduces computation costs and memory by over 88% and 80%, respectively. Hence, it is widely preferred in portable and mobile devices.
PointNet has shown encouraging results for the automatic classification of ALS data, and many PointNet-like architectures have been proposed. PointNet only uses local and global information and thus lacks local context information [
36]. Therefore, many scholars have proposed improved algorithms.
PointNet++ is a hierarchical neural network based on PointNet. Features at different scales are concatenated, and multiscale features are formed. The three key layers in PointNet++ are the sampling layer, grouping layer, and PointNet layer. The sampling layer uses farthest point sampling (FPS) to select a set of points from the input points which defines the centroids of local regions. Local region sets are constructed in the grouping layer by finding “neighboring” points around the centroids. Then, a mini- PointNet abstracts the sets of local points or features into higher-level representations. Several state-of-the-art techniques have been proposed to improve the performance of the PointNet++ network. These techniques can be divided into two types: multiscale grouping (MSG) methods and multiresolution grouping (MRG) methods. MSG methods apply grouping layers with different scales to capture multiscale patterns. The features learned at different scales are concatenated for subsequent processing. MSG methods are computationally expensive because they run PointNet for every centroid point at a large scale and select many centroid points at the lowest level; therefore, the time cost is significant. MRG methods are more computationally efficient than MSG methods because they avoid feature extraction in large-scale neighborhoods at the lowest levels.
Although PointNet++ achieves satisfactory performance in many tasks, its drawbacks still require the development of appropriate solutions. For the feature aggregation of local regions, the max pooling operation is implemented in the PointNet++ network, but this method is heuristic and insufficient without learnable parameters [
33,
37]. To address the above problems, Wang et al. put forward the dynamic graph CNN(DGCNN) which incorporates local neighborhood information by concatenating the centroid points features with the feature difference between their k-nearest neighbors and then followed by multilayer perceptron (MLP) and max pooling operation. However, this method only considers the relationship between centroid points and the neighbors’ points, and the information it collects is still limited because of the use of a simple mas pooling operation [
38]. Zhao et al. proposed the adaptive feature adjustment module in the PointWeb network to connect and explore all pairs of points in a region [
39]. PointCNN sorts the points into a potentially canonical order and applies convolution to the points. To use the orientation information of neighborhood points, scholars proposed a directionally constrained fully convolutional neural network (D-FCN), which searches the nearest neighborhood points in each of the eight evenly divided directions [
20]. In sum, the method does not consider individual point-level and global information, and it does not embed the characteristics of ALS point clouds to further improve performance. In this work, the point-level and global information of centroid point is added to support classification, and the characteristics of ALS point cloud which exhibit discrepancies in elevation distributions is also used. We also proposed a modified focal loss function and conducted an experiment on two datasets. The proposed method is shown in the following section.
4. Experimental Results and Analysis
To evaluate the performance of the proposed method, we conduct experiments on two ALS datasets: the ISPRS benchmark dataset of Vaihingen [
31], which is a city in Germany (
Figure 4), and the GML(B) dataset. The ISPRS benchmark dataset’s point density is approximately 4–7 points/m
2. As shown in
Figure 4, it belongs to the cross-flight belt (the overlap in scene I is in the middle whilst the overlap in scene II is at both ends), thus indicating that the point in this dataset is uneven.
The number of points in the training set is 753,876, and that in the test set is 411,722. The proportion in different categories is shown in
Table 1. The proportion of power line is the lowest in the experiment, accounting for only 0.07%. Meanwhile, the proportion of impervious surfaces is the highest, accounting for 25.70%, which is 367 times that of the power line.
The evaluation metrics of precision, recall,
F1 score, overall accuracy (
OA), and mean intersection over union (
MIoU) are applied to evaluate the performance of the proposed method according to the standard convention of the ISPRS 3D labelling contest.
where
TP denotes true positive,
FP denotes false positive and
FN denotes false negative. Average precision (
AvgP), average recall (
AvgR),
OA, and average
F1 score (
AvgF1) are utilized to assess the performance for the whole test dataset.
We train our module by using the PyTorch framework and conduct the experiment on aN NVIDIA Tesla V100 GPU of the Supercomputing Center of WHU. The training set is moved 500 m in the x direction for data augmentation.
The initial input vector is six columns: x, y, z, intensive, return number, and number of returns. After coordinate normalization, three columns are added. The region of a 40 m × 40 m block is selected randomly in the horizontal direction, and the weight on each category is determined. The block is discarded when the number in the block is smaller than 1024. In module training, the training parameters are set as follows: the training epoch is 64, the batch size is 3, the Adam optimizer is used, and the other parameters are the same as those in the literature [
17]. The training parameters are saved in every 5 epochs. A validation set is used to monitor the performance of the proposed model during training. For convenience, the validation set is the same as the training set. In module validation, the
MIoU parameter is used to select the best mode. The highest
MIoU value module is then chosen to investigate the performance of the test set. In the module testing stage, each region in the test dataset is segmented into 40 m × 40 m blocks in the horizontal direction, and the stride is set to 20 m. The voting method is adopted, and the number is set to 10. The highest score is selected as the final result.
4.1. Test of Loss Function
To test the performance of different loss functions in ALS point clouds for the classification task, we select the loss function relative to cross-entropy, focal loss, and the modified focal loss. Two parameters
,
in focal loss (1) are equal to 0.25 and 2, respectively [
41]; and the category weight coefficient
in focal loss (2) is set by inverse class frequency. The results are shown in
Table 2.
The
OA in cross-entropy is consistent with that in the PointNet++ network on the Vaihingen dataset [
20]; hence, the strategy setting the radius size, batch size, and other parameters in the current work is feasible. In focal loss (1), the
OA is 82.5, which is the highest value. Moreover, the loss function in estimation is 0.044, which is one-fourth of the cross-entropy; this result indicates that the focal loss has a low loss value. However, the
F1 score is small in focal Loss (1), which indicates that parameter
is unsuitable. When the reverse percentage weight is used in focal loss (2), the small category power line is recognized in the first epoch. However, the
OA does not improve later. The power line weight is 1380 in focal loss (2), whereas that of the impervious surfaces is 3.8, which is far from the weight of the former. The experiment in focal loss (2) indicates that an incorrect weight makes the model mainly focus on minority categories whilst ignoring other categories completely. This condition leads to incorrect classification. The modified focal Loss method obtains the highest
F1 scores, thus indicating that the category weight coefficient
is set correctly. Therefore, the modified focal loss is used in the following operation.
4.2. Test of Interpolation Method
A hierarchical propagation strategy with elevation- and distance-based interpolation is set as follows:
where
,
.
The
denotes the distance from the centroid to the
point and
denotes the corresponding elevation difference. To test whether the interpolation method is effective, parameters
,
are set. The results are shown in
Table 3.
Through the comparison of the four models, we find that the
OA of method (a) is the lowest and that the
F1 scores on the roof, façade, shrub, and tree are also the lowest. These categories have high elevation and large inherent differences. Hence, the sole use of distance-based interpolation is not conducive to the improvement of accuracy for high objects. The
F1 scores of method (d) for the power line, low vegetation, impervious surfaces, and fence are the lowest. The
AvgF1 score is also the lowest, thus indicating that distance information is more useful than elevation information in areas with gentle change. Therefore, elevation information proportions should not be larger than those of distant information. Methods (b) and (c) achieve satisfactory performance, and their
AvgF1 score and
OA are large. We chose method (c) as our final interpolation module to capture geometry features at different scales for the highest
OA.
Figure 5 shows the performance of different interpolation methods in some areas. The roof is easily misjudged as a tree in method (a) because the elevation information is not calculated separately. The auxiliary calculation of elevation information can help capture geometry features at different scales.
4.3. Test of Point-Level and Global Information
The individual point-level features include location information, intensive information, return number, and so on. These features are useful for semantic classification. Relevant experiments are conducted to test whether adding point-level information and global information is conducive to improving accuracy and to select the appropriate parameters.
The size of MLP layers is of great importance in deep learning. A large layer size results in models that are difficult to converge and in issues such as overfitting and high computation complexity. Meanwhile, a small layer size result in underfitting. Therefore, selecting a suitable layer size is vital for classification tasks. Different layer sizes number is selected in
Table 4 to test their performance.
In the individual point level test, methods (1) and (2) are used to test whether the layer sizes should be the same across different layers. Methods (3) and (4) are used to test the global feature characters. The result is shown in
Table 5.
In
Table 5, method (1) has the lowest accuracy, which is even smaller than that of method (c) in
Table 4. This result indicates that the layer size’s number is unsuitable for the point level. The same can be inferred from the comparison involving method (2), which has large layer sizes number on high layers. This result is consistent with the situation in which a high receptive field needs further information and sizes should be large. The same conclusion can be drawn from the comparison of methods (3) and (4) which have different layer sizes number at the global level. The comparison of methods (2) and (4) shows that adding global information also improves model accuracy.
Figure 6 shows the classification result and error map of method (4), and
Table 6 shows a confusion matrix of the per-class accuracy of our proposed method.
In
Figure 6, many points are classified correctly, and errors are mainly distributed over object edges. In
Table 6, the best performance is impervious surfaces and roof, and the worst is fence/hedge and shrub due to the confusion between closely-related classes. From the confusion matrix, the powerline is mainly confused with roof. Likewise, the classification accuracy on impervious surfaces is affected by low vegetation for the similar topological and spectral characteristics. Fence/hedge is confused with shrub and tree for the similar spectral characteristics. The classification accuracy on shrub is easily affected by the low vegetation and tree for the overlap in the vertical direction. We also compare this confusion matrix with the one handled by pointnet++ network, and find that the proportion on powerline misclassified as roof is reduced by 17%. and the tree misclassified as roof reduced by 8.6%. the pointnet++ network does not work as well as proposed network.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}