1. Introduction
With the development of earth observation technologies, a large number of high-resolution remote sensing images (HRSIs) are available, raising the high demands of automatic image analysis by intelligent means [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. The ways to interpret remote sensing images, e.g., object detection, instance segmentation, etc., have recently attracted much attention. Instance segmentation for HRSIs aims at accurately detecting the location of the objects of interest (e.g., vehicles, ships, etc.) in the image, predicting their categories and classifying each instance at the pixel level. It is conducive to the automatic analysis and utilization of the spatial and spectral information of HRSIs, which has a wide range of applications in earth observation, e.g., disaster estimation, urban planning, traffic management, etc.
Recently instance segmentation has been extensively studied based on deep learning both for natural images and aerial images [
1,
3,
4,
5,
9,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24]. The generic instance segmentation methods for natural images can be roughly divided into detection-based and segmentation-based approaches from the point of view of top-down and bottom-up schemes, respectively. The detection-based methods first find out the bounding boxes of the instances of interest through an advanced object detector such as Fast-RCNN [
25], Faster-RCNN [
26], and R-FCN [
27]. Then they perform semantic segmentation in the detection boxes to segment the mask for each instance. Early work [
28,
29,
30,
31,
32] adopted mask proposals to perform category-agnostic object segments. FCIS [
33] uses the position-sensitive inside/outside score maps for instance-aware semantic segmentation with the help of fully convolutional network (FCN) [
34]. Mask-RCNN [
11] inherits the classification and regression structure from Faster-RCNN [
26] and adds a fully convolutional mask branch to predict the category of each pixel. Inspired by Mask-RCNN, [
12,
13,
14,
15] introduce different designs and structures to refine mask prediction for two-stage instance segmentation. HTC [
16] integrates the cascade method into joint multi-stage processing and uses spatial context to further improve the accuracy of segmented masks. YOLACT [
35] adds the mask branch to an existing one-stage target detection model, which realizes real-time instance segmentation with competitive results reported by two-stage methods on the MS COCO dataset [
36] for the first time. BlendMask [
17] combines the instance-level information (such as bounding boxes) and the per-pixel semantic information for mask prediction.
The segmentation-based methods first perform the pixel-level prediction on the image and then use a clustering algorithm to group the pixels into different instances. Bai et al. [
37] and Hsu et al. [
38] applied the traditional watershed transform and the pairwise relationship between pixels to perform pixel-wise clustering. Liu et al. [
39] employed a sequence of neural networks to handle the problems of occlusion and large differences in the number of objects in instance segmentation. Neven et al. [
40] proposed a new loss function to achieve real-time instance segmentation with high accuracy. PolarMask [
41] models the instance contours in a polar coordinate and transforms the instance segmentation into center point classification and dense distance regression tasks. While [
42,
43] adopt the location and size information to assign category labels for each pixel within an object, which converts the instance segmentation into a pixel-wise classification problem.
Benefiting from the vigorous success in natural images, the research of instance segmentation for HRSIs has made great progress in recent years. However, Limited by the lack of aerial instance segmentation datasets, previous instance segmentation methods [
1,
3,
4,
5,
9] mainly focused on some or other specific categories, such as ship, vehicle, and building. Since Su et al. [
19,
20] extended the NWPU VHR-10 object detection dataset [
44,
45,
46] for instance segmentation and the release of the first large-scale instance segmentation dataset named iSAID [
47] in the field of aerial imagery, researchers began to turn their attention to multi-category instance segmentation for HRSIs. Su et al. [
19] designed the precise RoI pooling incorporated into Mask-RCNN to improve the performance of object detection and instance segmentation in aerial images. HQ-ISNet [
20] introduces the HRFPN to reserve high-resolution features of HRSIs and utilizes the ISNetV2 to predict more accurate masks. Ran et al. [
21] proposed an adaptive fusion and mask refinement (AFMR) network to learn complementary spatial features and conduct the content-aware mask refinement. CPISNet [
23] presented a novel adaptive feature extraction network and a proposal consistent cascaded architecture to boost the integral network performance. Zhang et al. [
22] proposed a Semantic Attention (SEA) module to alleviate the background interference, and they modified the original mask branch to ameliorate the under-segmentation phenomena.
Remote sensing images are usually taken from a high altitude with the bird’s-eye view depending on the perspective of the earth observation platforms. The particular imaging platforms and various kinds of objects lead to some distinctive characteristics of instances presented in HRSIs, such as large scale variation, complex contours, and dense block distribution, as shown in
Figure 1. These three issues are the main difficulties complicating the instance segmentation task of HRSIs. This paper specifically focuses on the problems of instance segmentation in HRSIs, which is challenging mainly due to the following three aspects:
Huge scale variation. The intra-class and inter-class scale variation among objects in remote sensing images are much more significant than those in natural images. It will increase the difficulty of feature learning in deep neural networks to a great extent. A general solution to this problem is adopting multi-scale feature extraction and fusion, which has been used in [
11,
14,
15,
48,
49,
50,
51,
52]. However, these multi-scale feature pyramid based methods such as feature pyramid network (FPN) usually assume that large objects should be represented by high-level features, while small objects should be associated with shallow features. The inconsistency across multi-scale feature maps limits their capability both in object detection and instance segmentation when the scale of objects changes too sharply. Liu et al. [
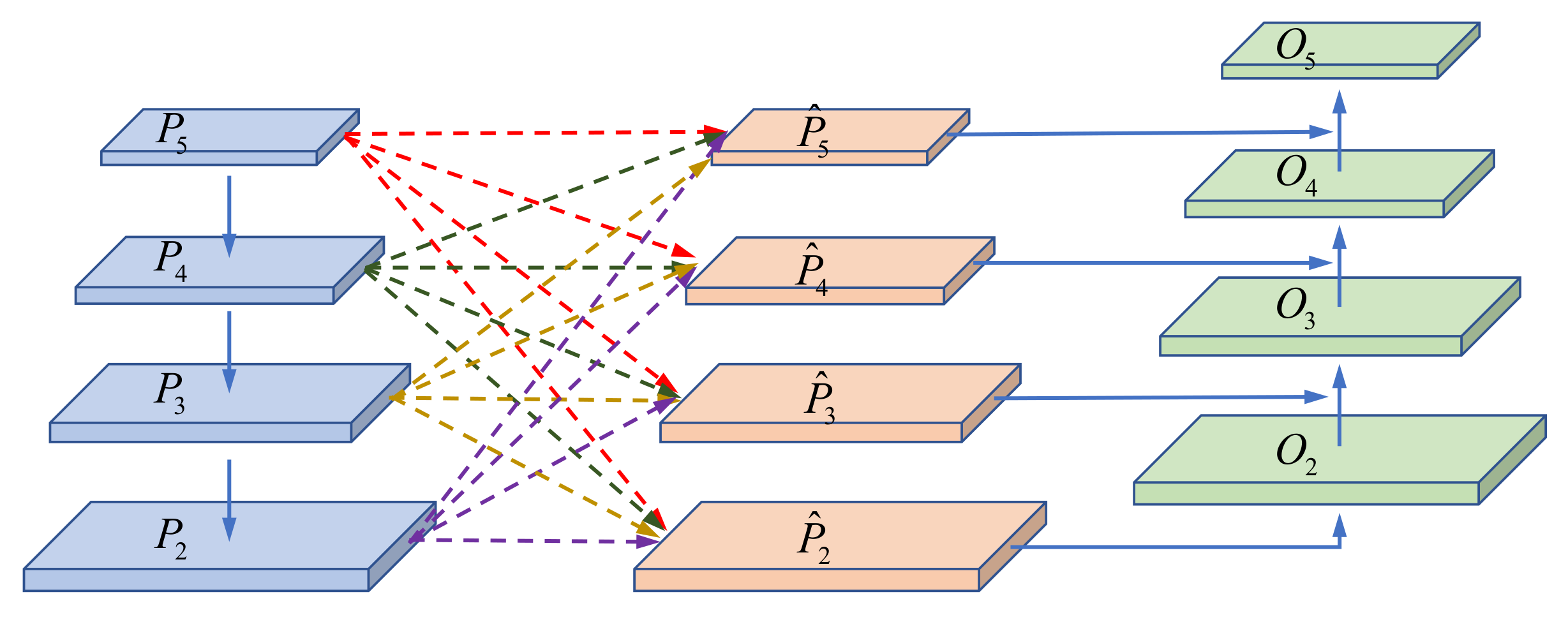
13] proposed a bottom-up path aggregation strategy by using accurate low-level locating information to enhance the feature representation entirely. However, this fixed fusion mechanism does not fully explore the self-learning merit of neural networks. Therefore, it is important to design adaptive feature fusion methods for the combination of useful information at different levels.
Objects with arbitrary shapes. There are numerous objects with arbitrary shapes in HRSIs, such as ships, harbors, helicopters. Since instance segmentation requires to achieve pixel-level accurate classification, these irregular shapes will bring significant challenges to the segmentation task. Zhao et al. [
4] attempted to use building boundary regularization to deal with the complex boundary segmentation of buildings. Cheng et al. [
5] constructed an energy map in polar coordinates, and then minimized the energy function to evolve the polygon outlines, thereby achieving accurate automatic building segmentation with arbitrary shapes. Limited by the dataset, [
4,
5] are only for single category segmentation. As for multi-class segmentation, Huang et al. [
14] improved their results by using the mask-IoU score to correct the misalignment between the mask quality and mask score. Kirillov et al. [
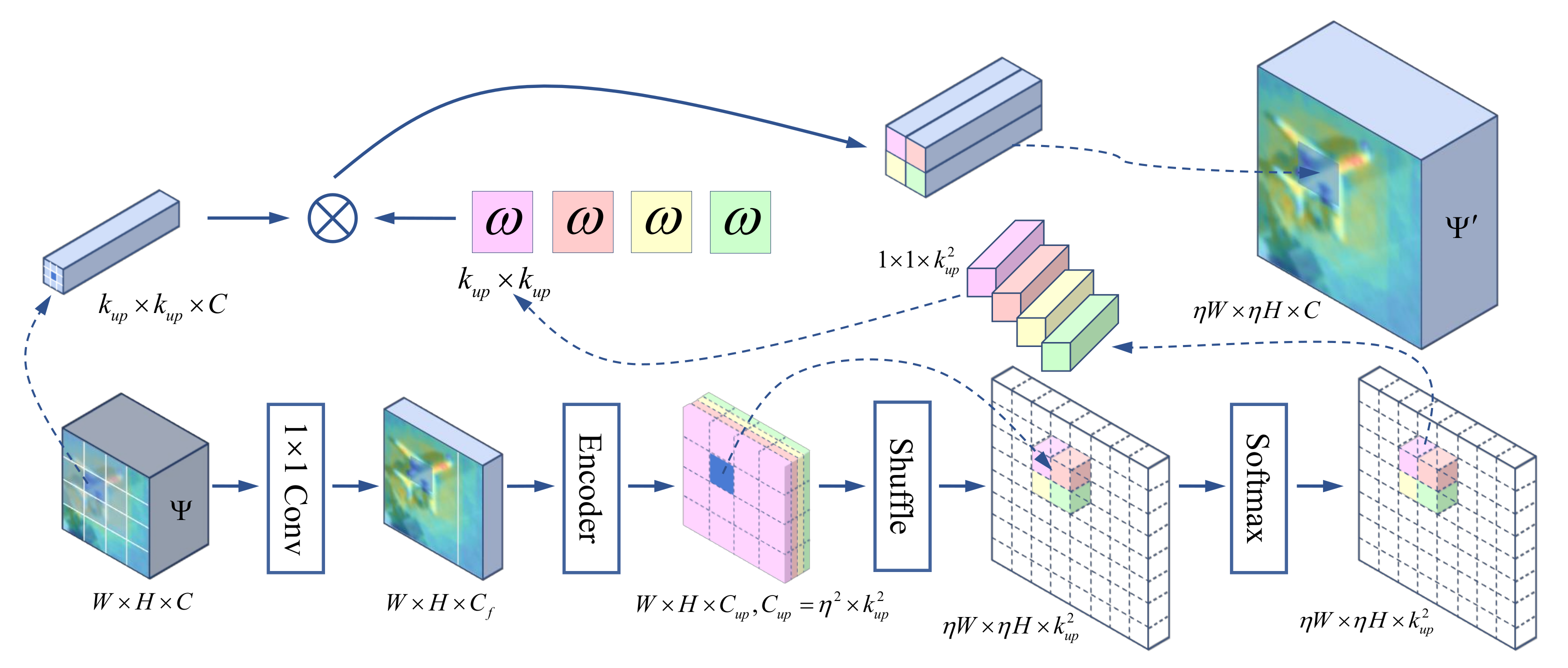
15] converted the instance segmentation into a rendering problem and obtained more nuanced mask predictions on the object contours through an iterative subdivision algorithm. However, current methods ignore the impact of feature upsampling operators when predicting the precise masks. The most widely used bilinear and nearest neighbor interpolation only take the sub-pixel neighborhood into consideration, and the deconvolution operation utilizes the same upsampling kernel across the entire image. These immutable upsampling operators fail to take full advantage of the contextual semantic information required by complex boundary segmentation.
Densely packed small objects. Cities and ports commonly contain considerable densely distributed small objects in aerial images. Since the size of these small objects is only a few to a dozen pixels and they always distribute in blocks, the close arrangements will lead to mutual interference among themselves whether in detection or segmentation. Mou et al. [
1] proposed a semantic boundary-aware unified multitask learning ResFCN for vehicle instance segmentation. Feng et al. [
3] improved the detection and segmentation performance of small dense objects via implementing multi-level information fusion on the mask prediction branch. Another solution is to improve the quality of the candidate proposals which are important for the subsequent detection and segmentation. Most detection-based instance segmentation methods adopt a hard threshold to divide positive and negative samples. However, simply using a constant IoU threshold as the criterion to separate training samples is not sufficient. As illustrated in [
53,
54,
55], the dynamic sample selection strategy can solve the incompatibility between the hard threshold settings and the dynamic training process. For that reason, the network can generate candidate boxes of higher quality to facilitate subsequent localization and pixel-wise classification.
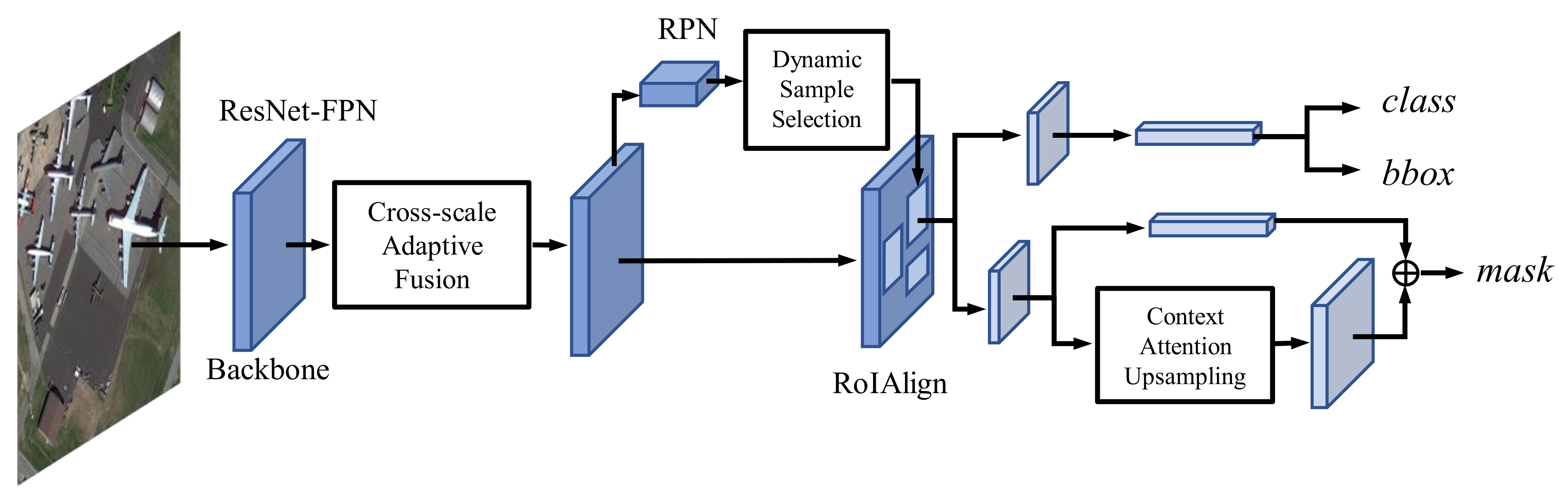
In this paper, we design an end-to-end multi-category instance segmentation network for HRSIs, where three key modules based on adaptive and dynamic feature learning are proposed to address the above three problems. Firstly, a cross-scale adaptive fusion (CSAF) module is proposed to integrate the multi-scale information, which can enhance the capability of the model to detect and segment objects with obvious size variation. Secondly, to deal with the complex boundaries of remote sensing instances, we embed a context attention upsampling (CAU) module in the segmentation branch to get more delicate masks. Thirdly, we devise a Dynamic Sample Selection (DSS) module to select more appropriate candidate boxes, especially for densely packed small objects. We evaluate the proposed method on two public remote sensing datasets.
The main contributions of this paper can be summarized as:
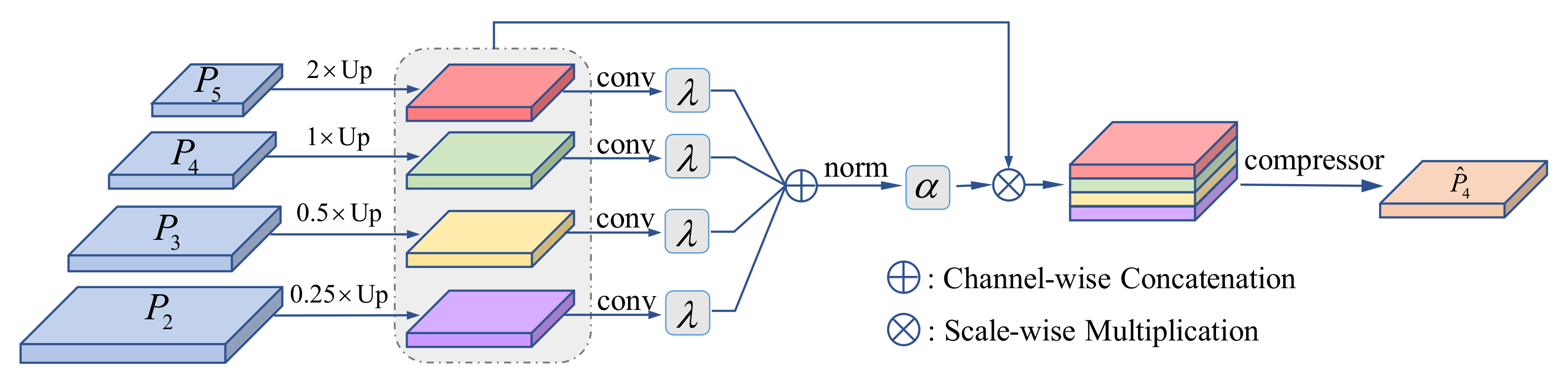
We propose the CSAF module with a novel multi-scale information fusion mechanism that can learn the fusion weights adaptively according to different input feature maps from the FPN.
We extend the original deconvolution layer into the CAU module in the segmentation branch which can obtain more refined predicted masks by generating different upsampling kernels with contextual information.
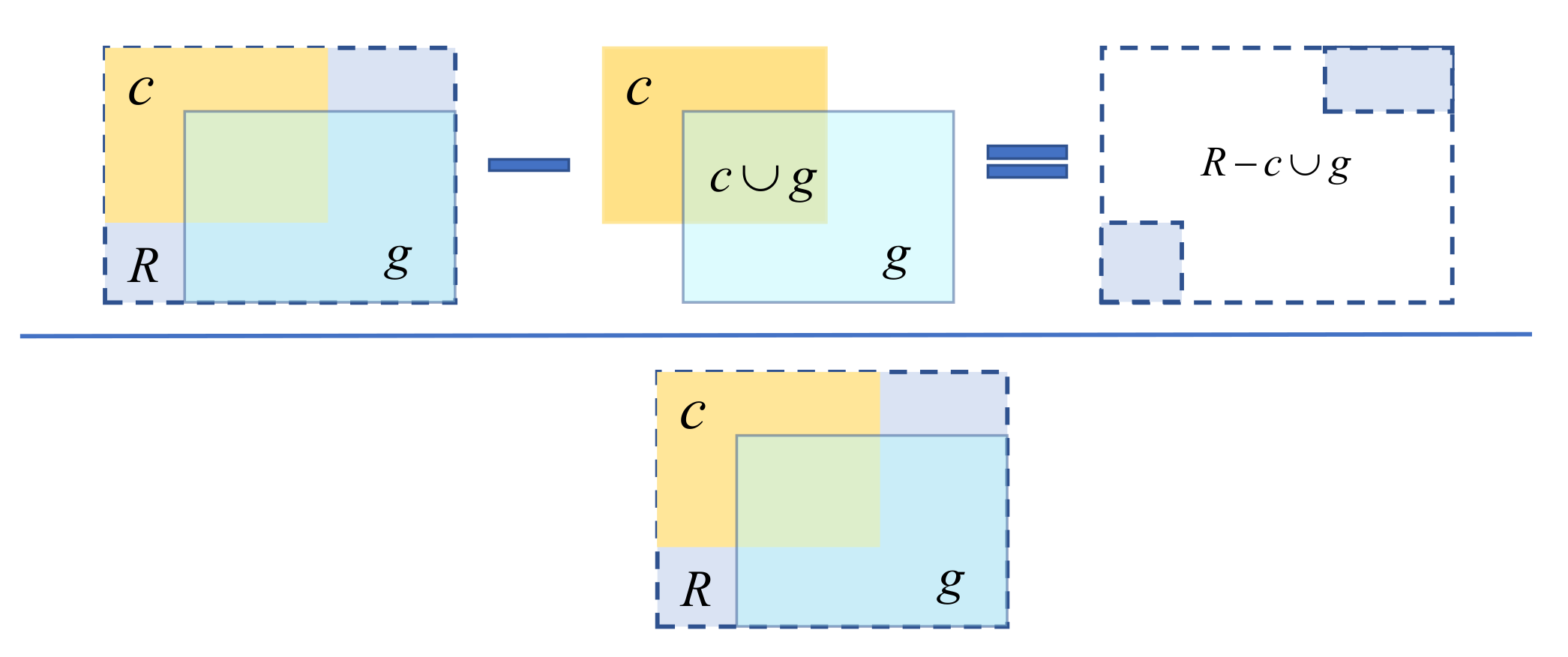
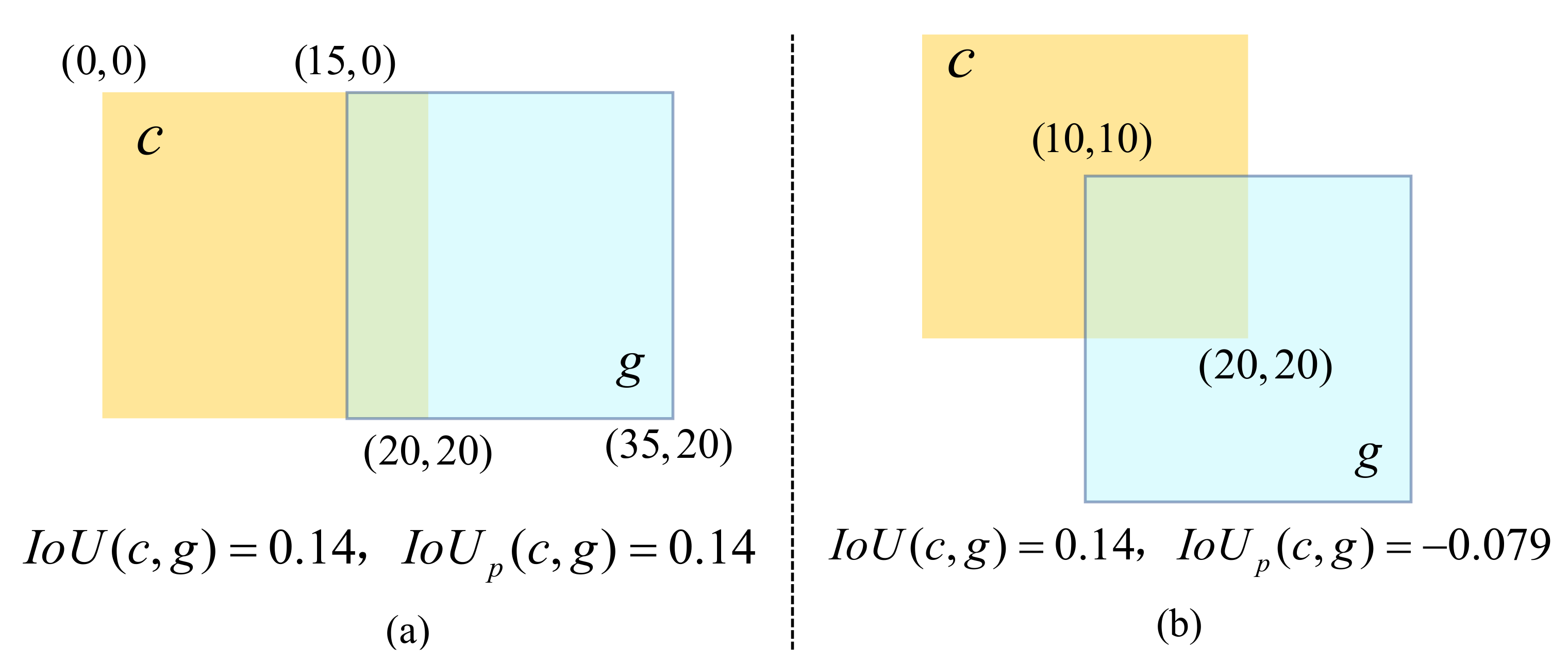
Instead of the traditional fixed threshold for determining positive and negative samples, the DSS module employs a dynamic threshold calculation algorithm to select more representative positive/negative samples.
The proposed method has achieved state-of-the-art performance on two challenging public datasets for instance segmentation task in HRSIs.
The rest of this paper is organized as follows.
Section 2 describes the proposed method in detail. The experimental results and analysis are reported in
Section 3.
Section 4 gives some discussions about the proposed method. Finally, we draw a conclusion in
Section 5.


 and
and 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}