
A Novel Anti-Drift Visual Object Tracking Algorithm Based on Sparse Response and Adaptive Spatial-Temporal Context-Aware

Abstract
:1. Introduction
- (1)
- The Ad_SASTCA method is presented by incorporating sparse response, adaptive temporal and spatial regularization constraints into the DCF framework. Based on the sparse adaptive spatial-temporal constrain, the Ad_SASTCA tracker provides a more robust appearance to avoid model drift in the case of occlusion, deformation and out-of-plane rotation.
- (2)
- An ADMM algorithm is employed to derive a closed-form solution of the Ad_SASTCA model in the Fourier domain. Thus, a favorable tracking performance is obtained without sacrificing the computational efficiency.
- (3)
- A novel high-confidence updating scheme is proposed based on feedback from the historical response map to enhance the tracking performance further. The Kalman filter is fused in a tracking framework to tackle the situation in which the model is persistently unreliable and abnormality occurs.
2. Related Work
2.1. DCF-Based Trackers
2.2. Modified CF Framework Based Trackers
3. The Proposed Method
3.1. Baseline Tracker
3.2. Adaptive Spatial-Temporal Context-Aware Correlation Filter
3.3. Sparse Adaptive Spatial-Temporal Context-Aware Correlation Filter
| Algorithm 1 The filter optimization using ADMM in frame t. |
|
3.4. High-Confidence Updating Scheme
| Algorithm 2 Ad_SASTCA tracker at time step t. |
|
3.5. Kalman Filter Tracking
- (1)
- The prediction part of the system
- (2)
- The update part of the system
4. Experiments
4.1. Experiment Setup
4.2. Evaluation Criterial on OTB Datasets
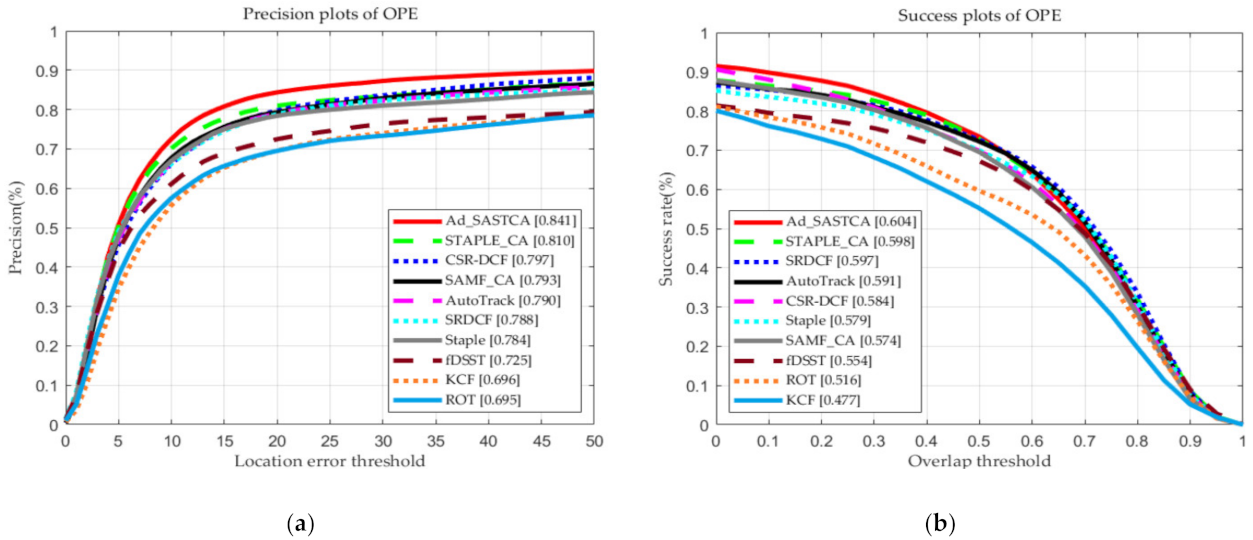
4.3. Overall Performance on OTB Datasets and Discussion
4.3.1. The OTB-2013 Benchmark
4.3.2. The OTB-2015 Benchmark
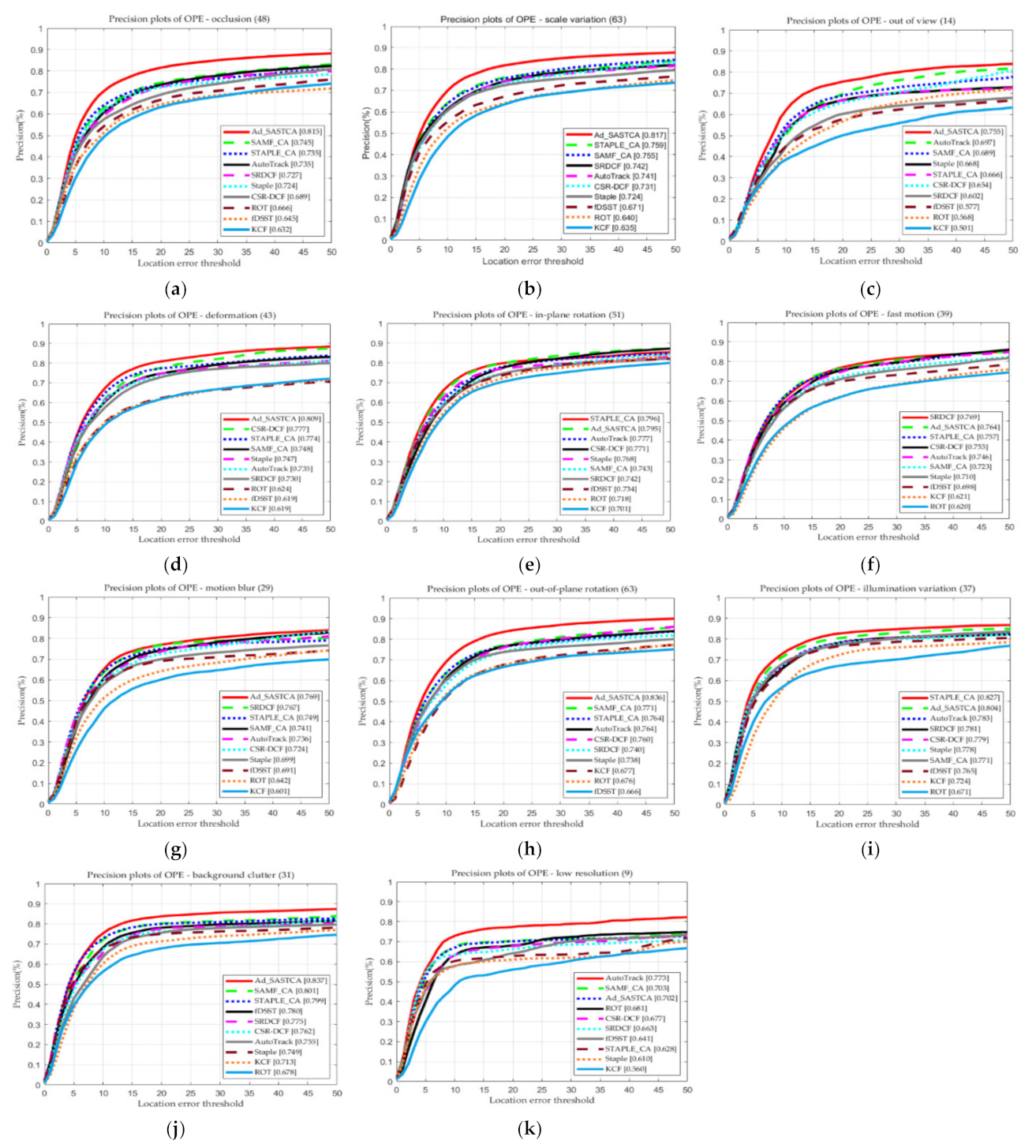
4.4. Attributes Based Evaluation and Discussion
4.5. The Qualitative Analysis and Discussion
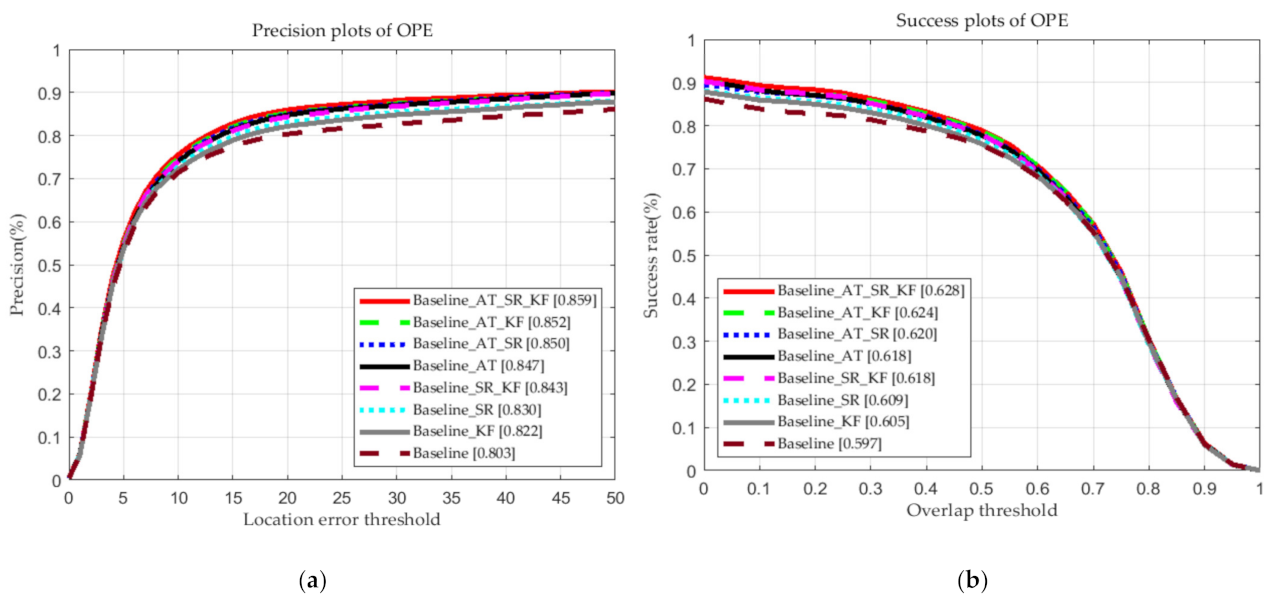
4.6. Ablation Studies and Discussion
4.7. The VOT2018 Benchmark
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Cao, J.; Song, C.; Song, S.; Xiao, F.; Zhang, X.; Liu, Z.; Ang, M.H., Jr. Robust Object Tracking Algorithm for Autonomous Vehicles in Complex Scenes. Remote Sens. 2021, 13, 3234. [Google Scholar] [CrossRef]
- Balamuralidhar, N.; Tilon, S.; Nex, F. MultEYE: Monitoring System for Real-Time Vehicle Detection, Tracking and Speed Estimation from UAV Imagery on Edge-Computing Platforms. Remote Sens. 2021, 13, 573. [Google Scholar] [CrossRef]
- Chen, L.; Zhao, Y.; Yao, J.; Chen, J.; Li, N.; Chan, J.C.-W.; Kong, S.G. Object Tracking in Hyperspectral-Oriented Video with Fast Spatial-Spectral Features. Remote Sens. 2021, 13, 1922. [Google Scholar] [CrossRef]
- Agarkhed, J.; Kulkarni, A.; Hiroli, N.; Kulkarni, J.; Jagde, A.; Pukale, A. Human Computer Interaction System Using Eye-Tracking Features. In Proceedings of the IEEE Bangalore Humanitarian Technology Conference (B-HTC), Vijiyapur, India, 8–10 October 2020; pp. 1–5. [Google Scholar]
- Wei, H.; Huang, Y.; Hu, F.; Zhao, B.; Guo, Z.; Zhang, R. Motion Estimation Using Region-Level Segmentation and Extended Kalman Filter for Autonomous Driving. Remote Sens. 2021, 13, 1828. [Google Scholar] [CrossRef]
- Wu, J.; Cao, C.; Zhou, Y.; Zeng, X.; Feng, Z.; Wu, Q.; Huang, Z. Multiple Ship Tracking in Remote Sensing Images Using Deep Learning. Remote Sens. 2021, 13, 3601. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Zhang, T.; Bernard, G.; Liu, S.; Narendra, A. Robust Visual Tracking via Multi-Task Sparse Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2042–2049. [Google Scholar]
- Zhang, T.; Xu, C.; Yang, M. Robust Structural Sparse Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 473–486. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, F.; Xu, W.; Yang, M. Object Tracking via Partial Least Squares Analysis. IEEE Trans. Image Process. 2012, 21, 4454–4465. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wang, T.; Liu, K.; Zhang, B.; Chen, L. Recent advances of single-object tracking methods: A brief survey. Neurocomputing 2021, 455, 1–11. [Google Scholar] [CrossRef]
- Babenko, B.; Yang, M.; Belongie, S. Robust Object Tracking with Online Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 13, 1619–1632. [Google Scholar] [CrossRef] [Green Version]
- Ma, B.; Shen, J.; Liu, Y.; Hu, H.; Shao, L.; Li, X. Visual Tracking Using Strong Classifier and Structural Local Sparse Descriptors. IEEE Trans. Multimed. 2015, 17, 1818–1828. [Google Scholar] [CrossRef]
- Zhang, S.; Yu, X.; Sui, Y.; Zhao, S.; Zhang, L. Object Tracking with Multi-View Support Vector Machines. IEEE Trans. Multimed. 2015, 17, 265–278. [Google Scholar] [CrossRef]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.L.; Torr, P.H.S. Struck: Structured output tracking with kernels. IEEE Trans. Pattern Anal. 2016, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dinh, T.B.; Vo, N.; Medioni, G. Context tracker: Exploring Supporters and Distracters in Unconstrained Environments. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1177–1184. [Google Scholar]
- Jiang, N.; Liu, W.Y.; Wu, Y. Learning adaptive metric for robust visual tracking. IEEE Trans. Image Process. 2011, 20, 2288–2300. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual Object Tracking Using Adaptive Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. Lect. Notes Comput. Sci. 2012, 7575, 702–715. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [Green Version]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4293–4302. [Google Scholar]
- Zhu, K.; Zhang, X.; Chen, G.; Tan, X.; Liao, P.; Wu, H.; Cui, X.; Zuo, Y.; Lv, Z. Single object tracking in satellite videos: Deep Siamese network incorporating an interframe difference centroid inertia motion model. Remote Sens. 2021, 13, 1298. [Google Scholar] [CrossRef]
- Huang, B.; Xu, T.; Shen, Z.; Jiang, S.; Zhao, B.; Bian, Z. SiamATL: Online Update of Siamese Tracking Network via Attentional Transfer Learning. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef] [PubMed]
- Kristan, M.; Leonardis, A.; Matas, J. The Sixth Visual Object Tracking vot2018 Challenge Results. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.H. Learning Spatial-temporal Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 4904–4913. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-Aware Correlation Filter Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1387–1395. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient Convolution Operators for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 6638–6646. [Google Scholar]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning Background-aware Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 19–22 October 2017; pp. 1135–1143. [Google Scholar]
- Lukežic, A.; Vojír, T.; Zajc, L.C.; Matas, J.; Kristan, M. Discriminative Correlation Filter with Channel and Spatial Reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4847–4856. [Google Scholar]
- Elayaperumal, D.; Joo, Y.H. Aberrance suppressed spatio-temporal correlation filters for visual object tracking. Pattern Recognit. 2021, 115, 107922. [Google Scholar] [CrossRef]
- Li, Y.; Fu, C.; Ding, F.; Huang, Z.; Lu, G. AutoTrack: Towards High-Performance Visual Tracking for UAV With Automatic Spatio-Temporal Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11920–11929. [Google Scholar]
- Han, Y.; Deng, C.; Zhao, B.; Zhao, B. Spatial-Temporal Context-Aware Tracking. IEEE Signal Process. Lett. 2019, 26, 500–504. [Google Scholar] [CrossRef]
- Wang, M.; Liu, Y.; Huang, Z. Margin Object Tracking with Circulant Feature Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4800–4808. [Google Scholar]
- Dong, X.; Shen, J.; Yu, D.; Wang, W.; Liu, J.; Huang, H. Occlusion-Aware Real-Time Object Tracking. IEEE Trans. Multimed. 2017, 19, 763–771. [Google Scholar] [CrossRef]
- Han, Y.; Deng, C.; Zhao, B.; Tao, D. State-Aware Anti-Drift Object Tracking. IEEE Trans. Image Process. 2019, 28, 4075–4086. [Google Scholar] [CrossRef] [Green Version]
- Du, S.; Wang, S. An Overview of Correlation-Filter-Based Object Tracking. IEEE Trans. Comput. Soc. Syst. 2021, 1–14. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Danelljan, M.; Shahbaz Khan, F.; Felsberg, M.; Van de Weijer, J. Adaptive Color Attributes for Real-time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1090–1097. [Google Scholar]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 254–265. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 8. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary Learners for Real-time Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1401–1409. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M. Long-Term Correlation Tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5388–5396. [Google Scholar]
- Cheng, J.; Tsai, Y.; Hung, W.; Wang, S.; Yang, M. Fast and Accurate Online Video Object Segmentation via Tracking Parts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7415–7424. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6181–6190. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H.S. Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.H.S.; Leibe, B. Siam R-CNN: Visual Tracking by Re-Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6577–6587. [Google Scholar]
- Boyd, S.; Parikh, E.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Huang, B.; Xu, T.; Jiang, S.; Chen, Y.; Bai, Y. Robust Visual Tracking via Constrained Multi-Kernel Correlation Filters. IEEE Trans. Multimed. 2020, 22, 2820–2832. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Published at | Feature Representations | High-Confidence Updating | Multimodal Tracking | Scale Estimation | Baseline |
|---|---|---|---|---|---|---|
| Ours | This work | HOG+CN+gray | Yes | Yes | Yes | SAMF_CA |
| STAPLE_CA [28] | CVPR2017 | HOG+CH | No | No | Yes | Staple |
| AutoTrack [34] | CVPR2020 | HOG+CN+gray | No | No | Yes | STRCF |
| CSR_DCF [32] | CVPR2017 | HOG+CN+HSV | No | No | Yes | KCF |
| Staple [45] | CVPR2016 | HOG+CH | No | No | Yes | KCF |
| SRDCF [26] | ICCV2015 | HOG+CN+gray | No | No | Yes | KCF |
| SAMF_CA [28] | CVPR2017 | HOG+CN+gray | No | No | Yes | SAMF |
| fDSST [44] | PAMI017 | HOG+gray | No | No | Yes | DSST |
| ROT [37] | IEEE2017 | CN+gray | Yes | Yes | Yes | CN |
| KCF [21] | PAMI2015 | HOG | No | No | No | CSK |
| Ours | STAPLE_CA | AutoTrack | CSR_DCF | Staple | SRDCF | SAMF_CA | fDSST | ROT | KCF | |
|---|---|---|---|---|---|---|---|---|---|---|
| OTB-2013 | 85.9 | 83.2 | 83.0 | 80.3 | 78.2 | 83.8 | 80.3 | 80.3 | 74.4 | 74.0 |
| OTB-2015 | 84.1 | 81.0 | 79.0 | 79.7 | 78.4 | 78.8 | 79.3 | 72.5 | 69.5 | 69.6 |
| Avg.FPS | 26.87 | 61.69 | 32.22 | 13.2 | 112.03 | 9.89 | 26.87 | 39.68 | 62.00 | 413.42 |
| Tracker | Our | CSR_DCF | Staple | SAMF_CA | SRDCF | DSST | KCF |
|---|---|---|---|---|---|---|---|
| Accuracy | 0.5122 | 0.4728 | 0.5035 | 0.4881 | 0.4634 | 0.3849 | 0.4394 |
| Robustness | 39.9532 | 24.9102 | 45.3015 | 52.3152 | 66.8433 | 96.7834 | 50.9617 |
| EAO | 0.1825 | 0.2503 | 0.1621 | 0.1490 | 0.1134 | 0.0780 | 0.1347 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Y.; Liu, J.; Xu, F.; Zhang, X.; Zuo, Y. A Novel Anti-Drift Visual Object Tracking Algorithm Based on Sparse Response and Adaptive Spatial-Temporal Context-Aware. Remote Sens. 2021, 13, 4672. https://doi.org/10.3390/rs13224672
Su Y, Liu J, Xu F, Zhang X, Zuo Y. A Novel Anti-Drift Visual Object Tracking Algorithm Based on Sparse Response and Adaptive Spatial-Temporal Context-Aware. Remote Sensing. 2021; 13(22):4672. https://doi.org/10.3390/rs13224672
Chicago/Turabian StyleSu, Yinqiang, Jinghong Liu, Fang Xu, Xueming Zhang, and Yujia Zuo. 2021. "A Novel Anti-Drift Visual Object Tracking Algorithm Based on Sparse Response and Adaptive Spatial-Temporal Context-Aware" Remote Sensing 13, no. 22: 4672. https://doi.org/10.3390/rs13224672