
Dynamic Object Detection Algorithm Based on Lightweight Shared Feature Pyramid


Abstract
:1. Introduction
2. Related Works
2.1. Object Detection Algorithm Based on Deep Learning
2.2. Feature Pyramids Based on Deep Learning
2.3. Dynamic Neural Networks
3. Method
3.1. Adaptive Inference Settings
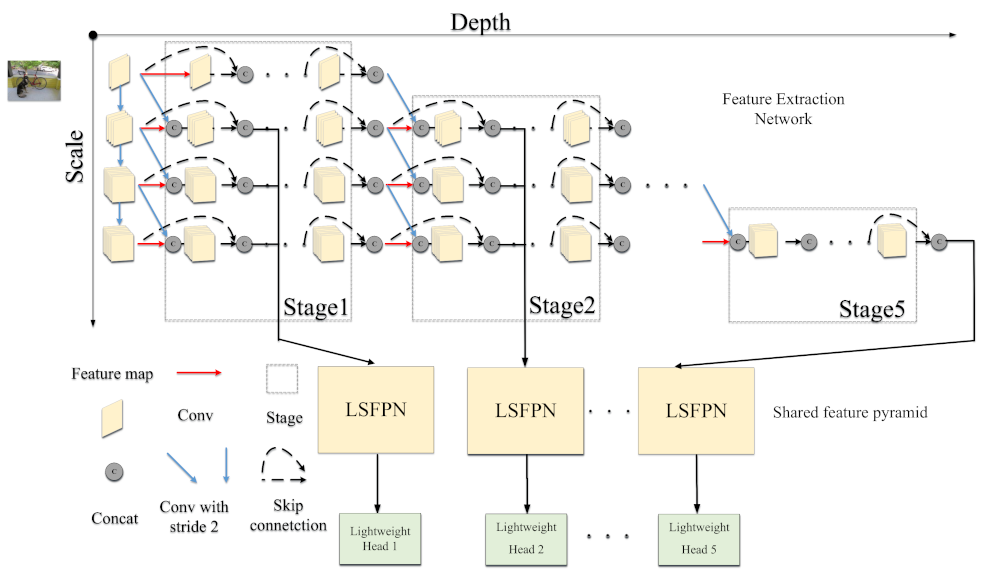
3.2. The Overall Network Architecture
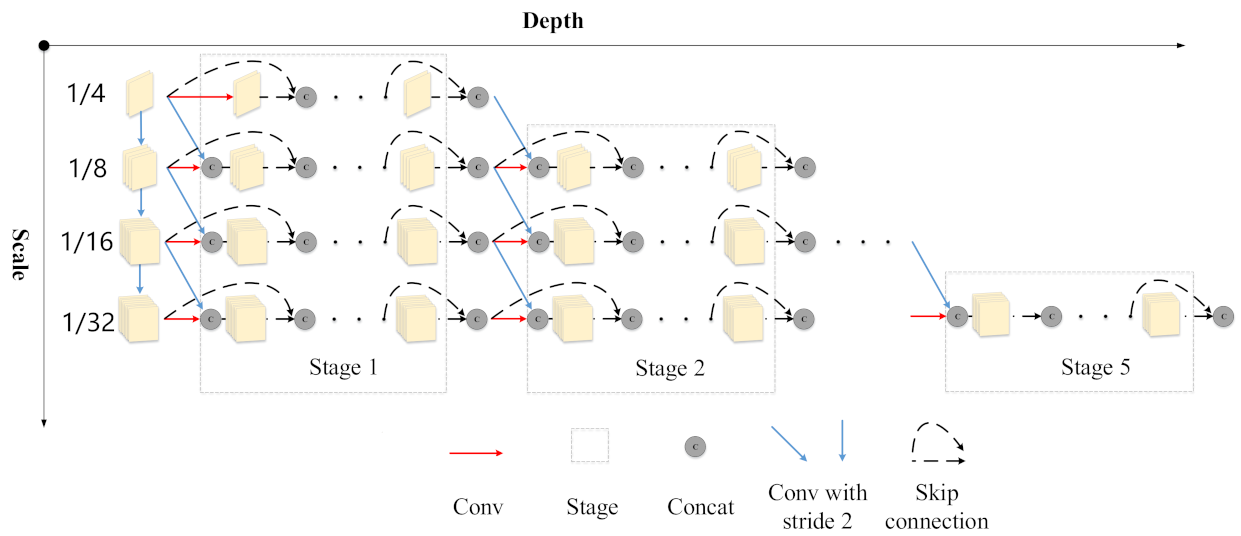
3.2.1. Feature Extraction Network Based on Multiscale Dense Connection
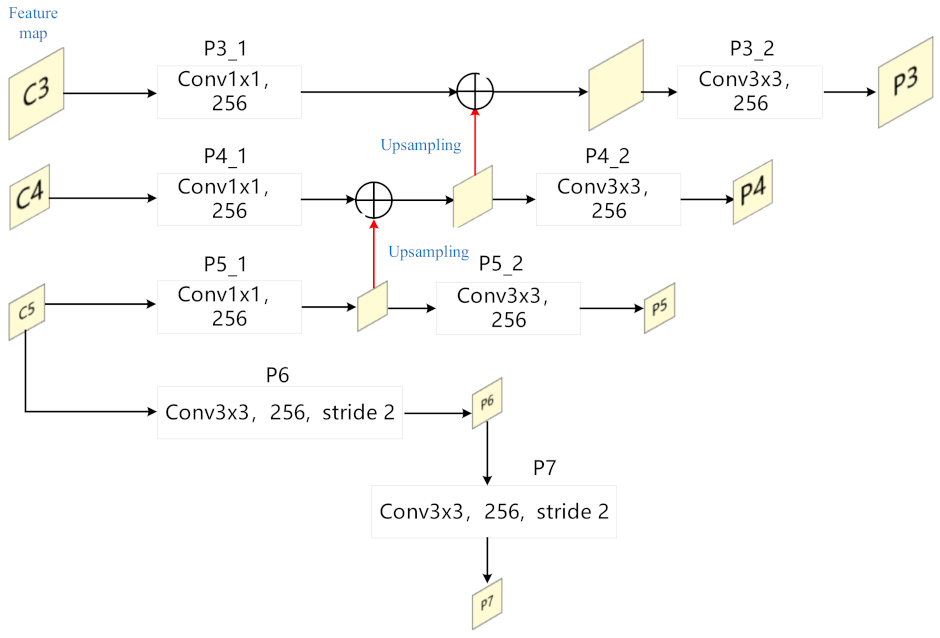
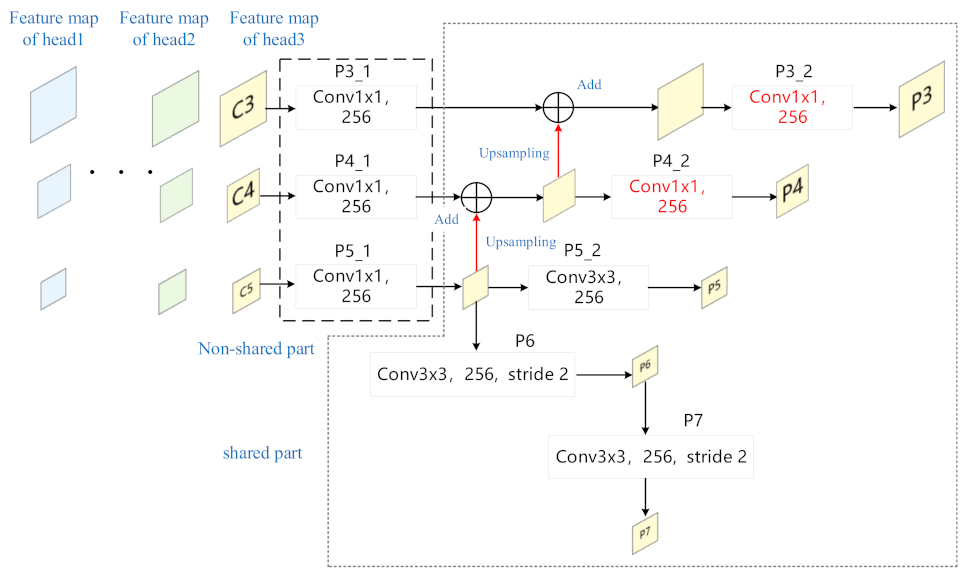
3.2.2. Lightweight Shared Feature Pyramid Network
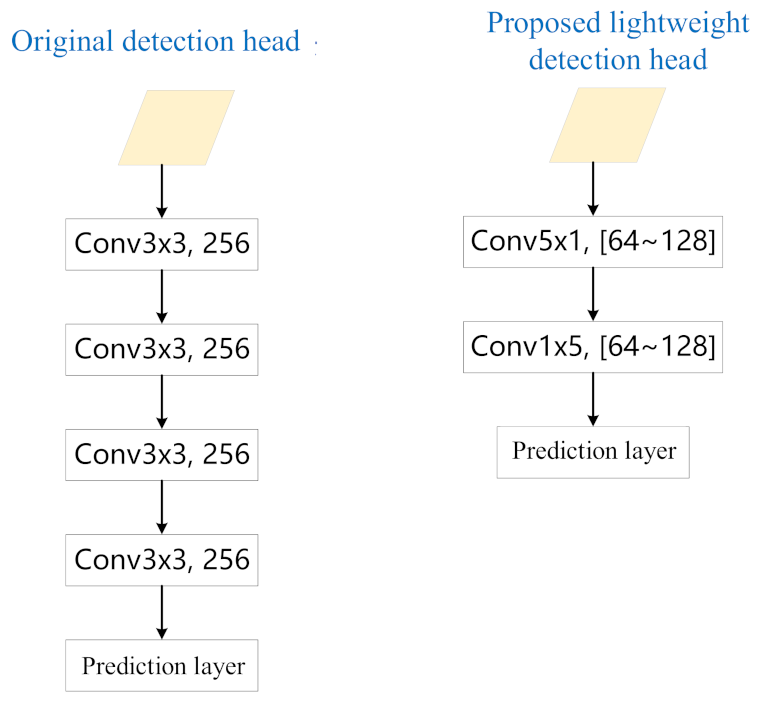
3.2.3. Lightweight Detection Head Network
3.3. Detailed Structure of the Dynamic Model
4. Experimental Results and Discussion
4.1. Implementation Details
4.2. Loss Functions
4.3. Analysis of LSFPN
4.4. Analysis of Lightweight Detection Head Network
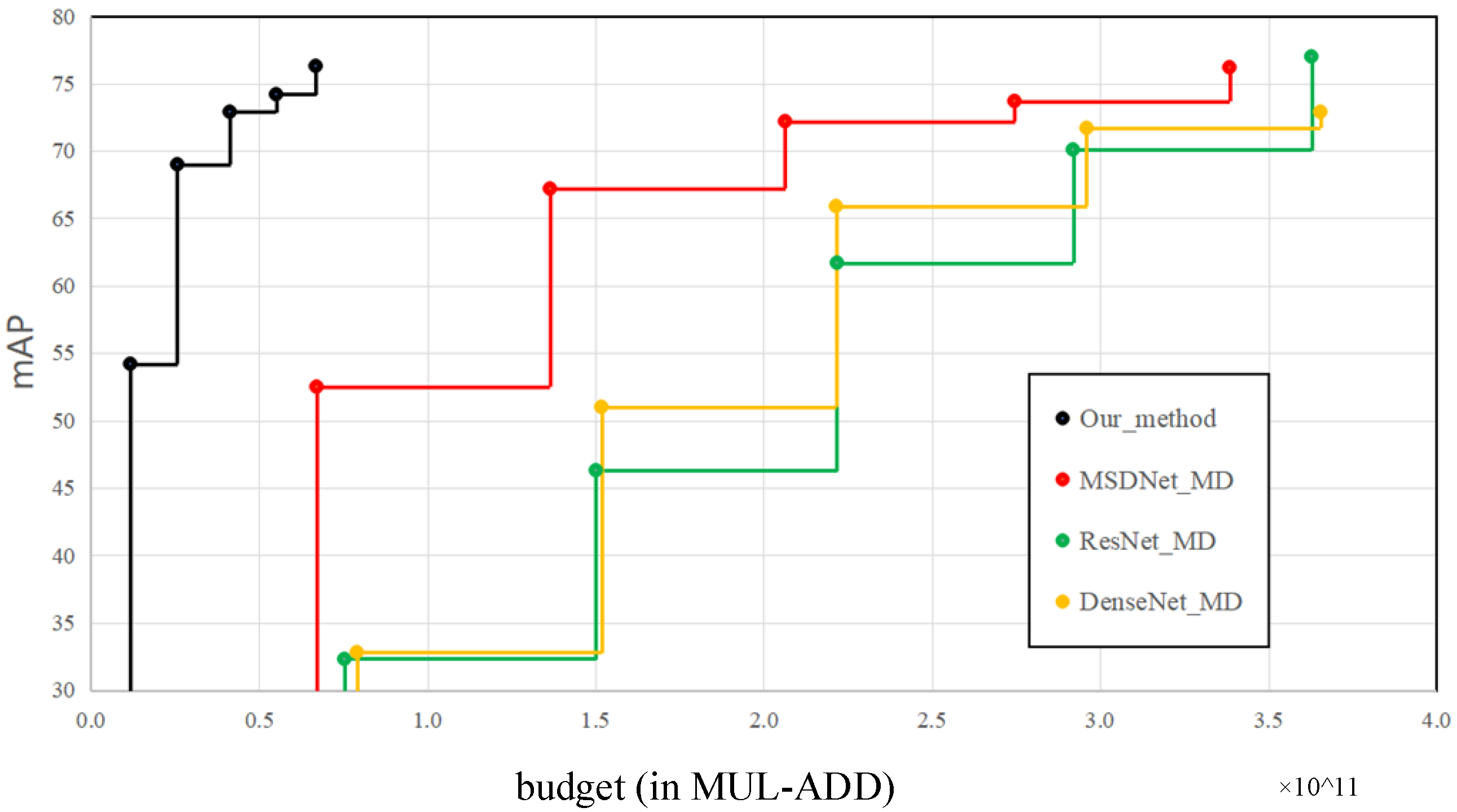
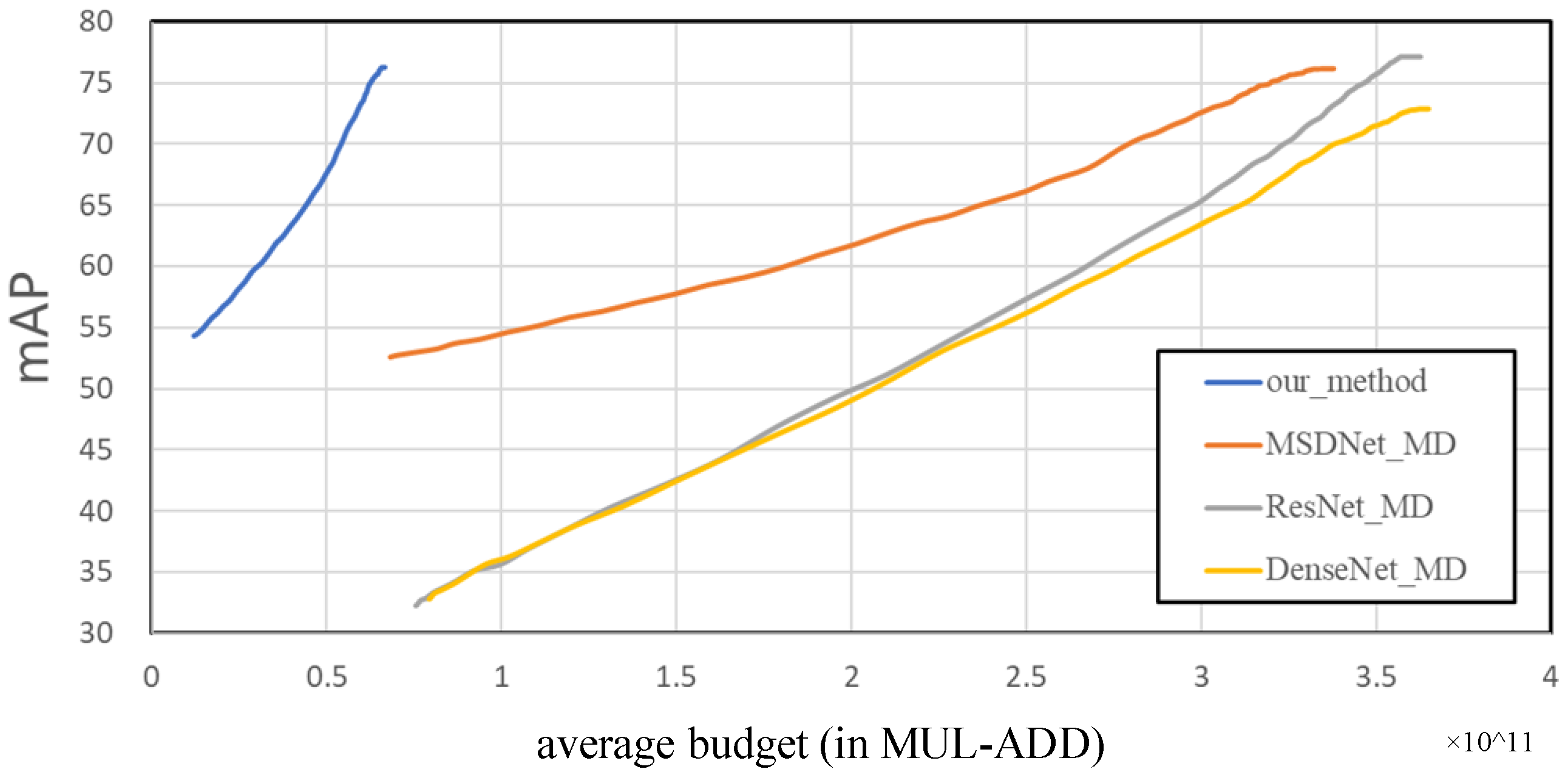
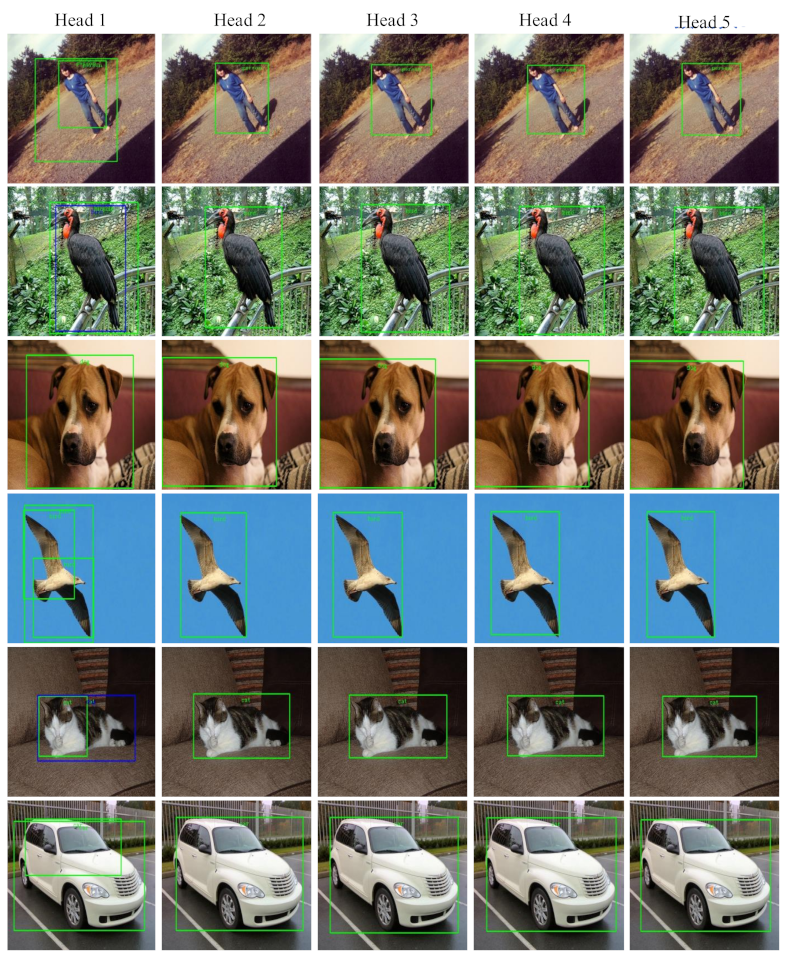
4.5. Experiments Results under Resource-Constrained Conditions
4.6. Evaluation on RSOD Dataset
4.7. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Zhuang, Z.; Tan, M.; Zhuang, B.; Liu, J.; Guo, Y.; Wu, Q.; Huang, J.; Zhu, J. Discrimination-aware channel pruning for deep neural networks. arXiv 2018, arXiv:1810.11809. [Google Scholar]
- Singh, P.; Verma, V.K.; Rai, P.; Namboodiri, V.P. Play and prune: Adaptive filter pruning for deep model compression. arXiv 2019, arXiv:1905.04446. [Google Scholar]
- Xiao, X.; Wang, Z. Autoprune: Automatic network pruning by regularizing auxiliary parameters. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Huang, G.; Chen, D.; Li, T.; Wu, F.; van der Maaten, L.; Weinberger, K.Q. Multi-scale dense networks for resource efficient image classification. arXiv 2017, arXiv:1703.09844. [Google Scholar]
- Yang, L.; Han, Y.; Chen, X.; Song, S.; Dai, J.; Huang, G. Resolution adaptive networks for efficient inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2369–2378. [Google Scholar]
- Bolukbasi, T.; Wang, J.; Dekel, O.; Saligrama, V. Adaptive neural networks for efficient inference. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 527–536. [Google Scholar]
- Ruiz, A.; Verbeek, J. Adaptative inference cost with convolutional neural mixture models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1872–1881. [Google Scholar]
- Wang, X.; Yu, F.; Dou, Z.Y.; Darrell, T.; Gonzalez, J.E. Skipnet: Learning dynamic routing in convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 409–424. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 379–387. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A real-time object detection algorithm optimized for non-GPU computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Uddin, M.S.; Hoque, R.; Islam, K.A.; Kwan, C.; Gribben, D.; Li, J. Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance. Remote Sens. 2021, 13, 3257. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 840–849. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 7036–7045. [Google Scholar]
- Zhu, M.; Han, K.; Yu, C.; Wang, Y. Dynamic Feature Pyramid Networks for Object Detection. arXiv 2020, arXiv:2012.00779. [Google Scholar]
- Veit, A.; Belongie, S. Convolutional networks with adaptive inference graphs. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–18. [Google Scholar]
- Wu, Z.; Nagarajan, T.; Kumar, A.; Rennie, S.; Davis, L.S.; Grauman, K.; Feris, R. Blockdrop: Dynamic inference paths in residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8817–8826. [Google Scholar]
- Lin, J.; Rao, Y.; Lu, J.; Zhou, J. Runtime neural pruning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2178–2188. [Google Scholar]
- Hu, H.; Dey, D.; Hebert, M.; Bagnell, J.A. Learning anytime predictions in neural networks via adaptive loss balancing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3812–3821. [Google Scholar]
- Li, H.; Zhang, H.; Qi, X.; Yang, R.; Huang, G. Improved techniques for training adaptive deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1891–1900. [Google Scholar]
- Feng, J.; Hua, J.; Lai, B.; Huang, J.; Li, X.; Hua, X.S. Learning to Generate Content-Aware Dynamic Detectors. arXiv 2020, arXiv:2012.04265. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Verelst, T.; Tuytelaars, T. Dynamic convolutions: Exploiting spatial sparsity for faster inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2320–2329. [Google Scholar]
- Xie, Z.; Zhang, Z.; Zhu, X.; Huang, G.; Lin, S. Spatially adaptive inference with stochastic feature sampling and interpolation. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 531–548. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MSDNet | Head1 | Head2 | Head3 | Head4 | Head5 |
|---|---|---|---|---|---|
| GFlops | 5.6G | 13G | 20.9G | 27.3G | 28.4G |
| Params | 2.2M | 5.6M | 9.9M | 14.5M | 16.8M |
| RetinaNet | Backbone | FPN | Head | Accumulated Amount |
|---|---|---|---|---|
| GFlops | 40.8G | 8.5G | 54.5G | 103.8G |
| GFlops(%) | 39.3 | 8.2 | 52.5 | - |
| Params | 23.51 | 8M | 26.09M | 57.6G |
| Params(%) | 40.8 | 13.9 | 45.3 | - |
| FPN | P3_1 | P3_2 | P4_1 | P4_2 | P5_1 | P5_2 | P6 | P7 |
|---|---|---|---|---|---|---|---|---|
| GFlops(%) | 12.1 | 54.6 | 6.1 | 13.7 | 3 | 3.4 | 6.8 | 0.2 |
| Params(%) | 1.6 | 7.4 | 3.3 | 7.4 | 6.5 | 7.4 | 59 | 7.4 |
| Layers | FPN (GFlops) | LSFPN (GFlops) | FPN (Params) | LSFPN (Params) |
|---|---|---|---|---|
| P3_1 | 1.02G | 1.02G | 0.13M | 0.13M |
| P3_2 | 4.60G | 0.51G | 0.59M | 0.066M |
| P4_1 | 0.51G | 0.51G | 0.26M | 0.26M |
| P4_2 | 1.15G | 0.13G | 0.59M | 0.066M |
| P5_1 | 0.37G | 0.37G | 0.52M | 0.52M |
| P5_2 | 0.29G | 0.29G | 0.59M | 0.59M |
| P6_1 | 0.065G | 0.008G | 4.7M | 0.59M |
| P7_2 | 0.002G | 0.002G | 0.59M | 0.59M |
| Accumulated | 8G | 2.84G | 8M | 2.81M |
| Nums of Head | Head = 1 | Head = 2 | Head = 3 | Head = 4 | Head = 5 |
|---|---|---|---|---|---|
| FPN (GFlops) | 6.95G | 14.28G | 21.75G | 29.25G | 37.16G |
| LSFPN (GFlops) | 1.72G | 3.81G | 6.05G | 8.17G | 10.73G |
| FPN (Params) | 4M | 8.6M | 12.8M | 18.1M | 23.3M |
| LSFPN (Params) | 2.22M | 2.66M | 3.1M | 3.61M | 4.23M |
| FPN (mAP) | 52.5 | 67.2 | 72.2 | 73.7 | 76.2 |
| LSFPN (mAP) | 53.4 | 67.8 | 72.5 | 73.9 | 76.4 |
| Nums of Head | Head = 1 | Head = 2 | Head = 3 | Head = 4 | Head = 5 |
|---|---|---|---|---|---|
| Normal Head (GFlops) | 54.54G | 109.1G | 163.6G | 218.2G | 272.7G |
| Light Head (GFlops) | 4.38G | 8.76G | 14.25G | 19.73G | 27.48G |
| Normal Head (Params) | 26.1M | 52.2M | 78.3M | 104.4M | 130.5M |
| Light Head (Params) | 2.1M | 4.2M | 6.82M | 9.44M | 13.15M |
| Normal Head (mAP) | 52.5 | 67.2 | 72.2 | 73.7 | 76.2 |
| Light Head (mAP) | 54.7 | 69.0 | 72.6 | 74.0 | 76.3 |
| Method | Head = 1 | Head = 2 | Head = 3 | Head = 4 | Head = 5 |
|---|---|---|---|---|---|
| MSDNet_MD (GFlops) | 69.61G | 140.52G | 220.73G | 276.85G | 339.12G |
| MSDNet_MD (mAP) | 81.98 | 88.80 | 89.07 | 89.28 | 89.39 |
| ResNet_MD (GFlops) | 76.91G | 151.42 | 221.35G | 280.03G | 362.18G |
| ResNet_MD (mAP) | 60.12 | 75.49 | 86.28 | 89.03 | 89.41 |
| DenseNet_MD (GFlops) | 80.62G | 156.72G | 221.49G | 292.38G | 365.21G |
| DenseNet_MD (mAP) | 61.56 | 72.34 | 86.32 | 87.15 | 89.27 |
| Our (GFlops) | 14.05G | 30.87G | 49.65G | 66.22G | 80.37G |
| Our (mAP) | 82.14 | 88.85 | 89.12 | 89.31 | 89.40 |
| Method/mAP | Head = 1 | Head = 2 | Head = 3 | Head = 4 | Head = 5 |
|---|---|---|---|---|---|
| FPN+NH | 52.5 | 67.2 | 72.2 | 73.7 | 76.2 |
| FPN+LH | 54.7 | 69 | 72.6 | 74 | 76.3 |
| LSFPN+NH | 53.4 | 67.8 | 72.5 | 73.9 | 76.4 |
| LSFPN+LH | 54.2 | 69.0 | 72.9 | 74.2 | 76.3 |
| Loss Weight/mAP | Head = 1 | Head = 2 | Head = 3 | Head = 4 | Head = 5 |
|---|---|---|---|---|---|
| 55.5 | 69.9 | 73.1 | 74.1 | 74.6 | |
| 54.2 | 69.0 | 72.9 | 74.2 | 76.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Xie, Z.; Luo, J.; Qi, Y.; Liu, L.; Tao, W. Dynamic Object Detection Algorithm Based on Lightweight Shared Feature Pyramid. Remote Sens. 2021, 13, 4610. https://doi.org/10.3390/rs13224610
Zhu L, Xie Z, Luo J, Qi Y, Liu L, Tao W. Dynamic Object Detection Algorithm Based on Lightweight Shared Feature Pyramid. Remote Sensing. 2021; 13(22):4610. https://doi.org/10.3390/rs13224610
Chicago/Turabian StyleZhu, Li, Zihao Xie, Jing Luo, Yuhang Qi, Liman Liu, and Wenbing Tao. 2021. "Dynamic Object Detection Algorithm Based on Lightweight Shared Feature Pyramid" Remote Sensing 13, no. 22: 4610. https://doi.org/10.3390/rs13224610