
DisasterGAN: Generative Adversarial Networks for Remote Sensing Disaster Image Generation

Abstract
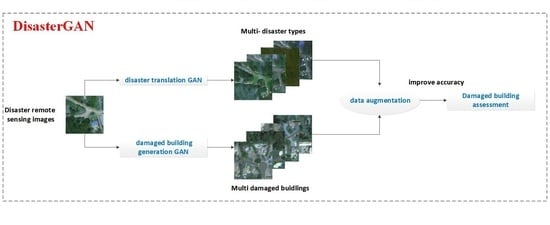
:
1. Introduction
- (1)
- Disaster translation GAN is proposed to realize multiple disaster attributes image translation flexibly using only a single model. The core idea is to adopt an attribute label representing disaster types and then take in as inputs both images and disaster attributes, instead of only translating images between two fixed domains such as the previous models.
- (2)
- Damaged building generation GAN implements specified damaged building attribute editing, which only changes the specific damaged building region and keeps the rest region unchanged. Exactly, mask-guided architecture is introduced to keep the model only focused on the attribute-specific region, and the reconstruction loss further ensures the attribute-irrelevant region is unchanged.
- (3)
- To the best of our knowledge, DisasterGAN is the first GAN-based remote sensing disaster images generation network. It is demonstrated that the DisasterGAN method can synthesize realistic images by qualitative and quantitative evaluation. Moreover, it can be used as a data augmentation method to improve the accuracy of the building damage assessment model.
2. Related Work
2.1. Generative Adversarial Networks
2.2. Image-to-Image Translation
2.3. Image Attribute Editing
2.4. Data Augmentation
3. Methods
3.1. Disaster Translation GAN
3.1.1. Proposed Framework
3.1.2. Objective Function
3.1.3. Network Architecture
3.2. Damaged Building Generation GAN
3.2.1. Proposed Framework
3.2.2. Objective Function
3.2.3. Network Architecture
4. Experiments and Results
4.1. Data Set
4.2. Disaster Translation GAN
4.2.1. Implementation Details
4.2.2. Visualization Results
4.3. Damaged Building Generation GAN
4.3.1. Implementation Details
4.3.2. Visualization Results
4.4. Quantitative Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| GAN | generative adversarial network |
| DNN | deep neural network |
| CNN | convolutional neural network |
| G | generator |
| D | discriminator |
| SAR | synthetic aperture radar |
| FID | Fréchet inception distance |
| F1 | F1 measure |
References
- Gupta, R.; Hosfelt, R.; Sajeev, S.; Patel, N.; Goodman, B.; Doshi, J.; Heim, E.; ChoseT, H.; Gaston, M. Creating xBD: A dataset for assessing building damage from satellite imagery. In Proceedings of the Computer Vision and Pattern Recognition Conference Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 10–17. [Google Scholar]
- Shen, Y.; Zhu, S.; Yang, T.; Chen, C. Cross-Directional Feature Fusion Network for Building Damage Assessment from Satellite Imagery. In Proceedings of the Neural Information Processing Systems Workshops, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Hao, H.; Baireddy, S.; Bartusiak, E.R.; Konz, L.; Delp, E.J. An Attention-Based System for Damage Assessment Using Satellite Imagery. arXiv 2020, arXiv:2004.06643. [Google Scholar]
- Boin, J.B.; Roth, N.; Doshi, J.; Llueca, P.; Borensztein, N. Multi-class segmentation under severe class imbalance: A case study in roof damage assessment. In Proceedings of the Neural Information Processing Systems Workshops, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 13 December 2014; pp. 2672–2680. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-domain Image-to-Image Translation. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.-H.; Lai, S.-H. ByeGlassesGAN: Identity Preserving Eyeglasses Removal for Face Images. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 243–258. [Google Scholar] [CrossRef]
- Zhang, G.; Kan, M.; Shan, S.; Chen, X. Generative Adversarial Network with Spatial Attention for Face Attribute Editing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 422–437. [Google Scholar] [CrossRef]
- Choi, Y.; Uh, Y.; Yoo, J.; Jung, W.H. StarGAN v2: Diverse Image Synthesis for Multiple Domains. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Seattle, WA, USA, 16–20 June 2020; pp. 8185–8194. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. (TOG) 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Mounsaveng, S.; Vazquez, D.; Ayed, I.B.; Pedersoli, M. Adversarial Learning of General Transformations for Data Augmentation. arXiv 2019, arXiv:1909.09801. [Google Scholar]
- Zhong, Z.; Liang, Z.; Zheng, Z.; Li, S.; Yang, Y. Camera Style Adaptation for Person Re-identification. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5157–5166. [Google Scholar]
- Huang, S.W.; Lin, C.T.; Chen, S.P. AugGAN: Cross Domain Adaptation with GAN-based Data Augmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 731–744. [Google Scholar]
- Wu, S.; Zhai, W.; Cao, Y. PixTextGAN: Structure aware text image synthesis for license plate recognition. IET Image Process. 2019, 13, 2744–2752. [Google Scholar] [CrossRef]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A deep translation (GAN) based change detection network for optical and SAR remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised Domain Adaptation using Generative Adversarial Networks for Semantic Segmentation of Aerial Images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, J.; Ali, M. Weakly-supervised domain adaptation for built-up region segmentation in aerial and satellite imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 263–275. [Google Scholar] [CrossRef]
- Li, Z.; Wu, X.; Usman, M.; Tao, R.; Xia, P.; Chen, H.; Li, B. A Systematic Survey of Regularization and Normalization in GANs. arXiv 2020, arXiv:2008.08930. [Google Scholar]
- Li, Z.; Xia, P.; Tao, R.; Niu, H.; Li, B. Direct Adversarial Training: An Adaptive Method to Penalize Lipschitz Continuity of the Discriminator. arXiv 2020, arXiv:2008.09041. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Tao, R.; Li, Z.; Tao, R.; Li, B. ResAttr-GAN: Unpaired deep residual attributes learning for multi-domain face image translation. IEEE Access 2019, 7, 132594–132608. [Google Scholar] [CrossRef]
- Federal Emergency Management Agency. Damage assessment operations manual: A guide to assessing damage and impact. Technical report, Federal Emergency Management Agency, Apr. 2016. Available online: https://www.fema.gov/sites/default/files/2020-07/Damage_Assessment_Manual_April62016.pdf (accessed on 21 October 2021).
- Federal Emergency Management Agency. Hazus Hurricane Model Uer Guidance. Technical Report, Federal Emergency Management Agency, Apr. 2018. Available online: https://www.fema.gov/sites/default/files/2020-09/fema_hazus_hurricane_user-guidance_4.2.pdf (accessed on 21 October 2021).
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–10 December 2017; pp. 5767–5777. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–10 December 2017; pp. 6629–6640. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Daudt, R.C.; Le, S.B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Bosch, M.; Conroy, C.; Ortiz, B.; Bogden, P. Improving emergency response during hurricane season using computer vision. In Proceedings of the SPIE Remote Sensing, Online, 21–25 September 2020; Volume 11534, p. 115340H. [Google Scholar] [CrossRef]
- Benson, V.; Ecker, A. Assessing out-of-domain generalization for robust building damage detection. arXiv 2020, arXiv:2011.10328. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Devries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. arXiv 2019, arXiv:1905.04899. [Google Scholar]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. GridMask Data Augmentation. arXiv 2020, arXiv:2001.040862020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Generator, G |
|---|---|
| L1 | Conv(I11, O64, K7, P3, S1), I N, ReLU |
| L2 | Conv(I64, O128, K4, P1, S2), IN, ReLU |
| L3 | Conv(I128, O256, K4, P1, S2), IN, ReLU |
| L4 | Residual Block(I256, O256, K3, P1, S1) |
| L5 | Residual Block(I256, O256, K3, P1, S1) |
| L6 | Residual Block(I256, O256, K3, P1, S1) |
| L7 | Residual Block(I256, O256, K3, P1, S1) |
| L8 | Residual Block(I256, O256, K3, P1, S1) |
| L9 | Residual Block(I256, O256, K3, P1, S1) |
| L10 | Deconv(I256, O128, K4, P1, S2), IN, ReLU |
| L11 | Deconv(I128, O64, K4, P1, S2), IN, ReLU |
| L12 | Conv(I64, O3, K7, P3, S1), Tanh |
| Layer | Discriminator, D |
|---|---|
| L1 | Conv(I3, O64, K4, P1, S2), Leaky ReLU |
| L2 | Conv(I64, O128, K4, P1, S2), Leaky ReLU |
| L3 | Conv(I128, O256, K4, P1, S2), Leaky ReLU |
| L4 | Conv(I256, O512, K4, P1, S2), Leaky ReLU |
| L5 | Conv(I512, O1024, K4, P1, S2), Leaky ReLU |
| L6 | Conv(I1024, O2048, K4, P1, S2), Leaky ReLU |
| L7 | src: Conv(I2048, O1, K3, P1, S1); cls: Conv(I2048, O8, K4, P0, S1) 1; |
| Layer | Attribute Generation Module, AGM |
|---|---|
| L1 | Conv(I4, O32, K7, P3, S1), I N, ReLU |
| L2 | Conv(I32, O64, K7, P3, S1), I N, ReLU |
| L3 | Conv(I64, O128, K4, P1, S2), IN, ReLU |
| L4 | Conv(I128, O256, K4, P1, S2), IN, ReLU |
| L5 | Residual Block(I256, O256, K3, P1, S1) |
| L6 | Residual Block(I256, O256, K3, P1, S1) |
| L7 | Residual Block(I256, O256, K3, P1, S1) |
| L8 | Residual Block(I256, O256, K3, P1, S1) |
| L9 | Deconv(I256, O128, K4, P1, S2), IN, ReLU |
| L10 | Deconv(I128, O64, K4, P1, S2), IN, ReLU |
| L11 | Deconv(I64, O32, K4, P1, S2), IN, ReLU |
| L12 | Conv(I32, O3, K7, P3, S1), Tanh |
| Layer | Discriminator, D |
|---|---|
| L1 | Conv(I3, O16, K4, P1, S2), Leaky ReLU |
| L2 | Conv(I16, O32, K4, P1, S2), Leaky ReLU |
| L3 | Conv(I32, O64, K4, P1, S2), Leaky ReLU |
| L4 | Conv(I64, O128, K4, P1, S2), Leaky ReLU |
| L5 | Conv(I128, O256, K4, P1, S2), Leaky ReLU |
| L6 | Conv(I256, O512, K4, P1, S2), Leaky ReLU |
| L7 | Conv(I512, O1024, K4, P1, S2), Leaky ReLU |
| L8 | src: Conv(I1024, O1, K3, P1, S1); cls: Conv(I1024, O1, K2, P0, S1) 1; |
| Disaster Types | Volcano | Fire | Tornado | Tsunami | Flooding | Earthquake | Hurricane |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| Number/ Pair | 4944 | 90,256 | 11,504 | 4176 | 14,368 | 1936 | 19,504 |
| Damage Level | Including Damaged Buildings | Undamaged Buildings |
|---|---|---|
| 1 | 0 | |
| Number/Pair | 24,843 | 16,948 |
| Evaluation Metric | Disaster Translation GAN | Damaged Building Generation GAN |
|---|---|---|
| FID | 31.1684 | 21.7873 |
| Evaluation Metric | Original Data Set (Baseline) | Geometric Transformation | CutMix | Disaster Translation GAN | Improvement |
|---|---|---|---|---|---|
| F1_no-damage | 0.9480 | 0.9480 | 0.9490 | 0.9493 | 0.0013 (0.14%) |
| F1_minor- damage | 0.7273 | 0.7274 | 0.7502 | 0.7620 | 0.0347 (4.77%) |
| F1_major- damage | 0.5582 | 0.5590 | 0.6236 | 0.8200 | 0.2618 (46.90%) |
| F1_destoryed | 0.6732 | 0.6834 | 0.7289 | 0.7363 | 0.0631 (9.37%) |
| Evaluation Metric | Original Data Set (Baseline) | Geometric Transformation | CutMix | Damaged Building Generation GAN | Improvment |
|---|---|---|---|---|---|
| F1_undamaged | 0.9433 | 0.9444 | 0.9511 | 0.9519 | 0.0086 (0.91%) |
| F1_damaged | 0.7032 | 0.7432 | 0.7553 | 0.7813 | 0.0781 (11.11%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rui, X.; Cao, Y.; Yuan, X.; Kang, Y.; Song, W. DisasterGAN: Generative Adversarial Networks for Remote Sensing Disaster Image Generation. Remote Sens. 2021, 13, 4284. https://doi.org/10.3390/rs13214284
Rui X, Cao Y, Yuan X, Kang Y, Song W. DisasterGAN: Generative Adversarial Networks for Remote Sensing Disaster Image Generation. Remote Sensing. 2021; 13(21):4284. https://doi.org/10.3390/rs13214284
Chicago/Turabian StyleRui, Xue, Yang Cao, Xin Yuan, Yu Kang, and Weiguo Song. 2021. "DisasterGAN: Generative Adversarial Networks for Remote Sensing Disaster Image Generation" Remote Sensing 13, no. 21: 4284. https://doi.org/10.3390/rs13214284