Author Contributions
Conceived the foundation, F.F.; designed the methods, F.F. and K.W.; preformed the experiments, K.W.; interpretation of results, F.F. and K.W.; writing-original draft preparation, F.F. and K.W.; writing-review and editing, F.F., Y.L., S.L. and B.W.; data curation, D.Z. and Y.C.; supervision, Y.L.; funding acquisition, F.F. All authors have read and agreed to the published version of the manuscript.
Figure 1.
Visualization examples with classical instance segmentation model-Mask R-CNN. Note: the red boxes represent buildings with blurring contours, the yellow boxes represent undetected small buildings and the green boxes are generated by Mask R-CNN.
Figure 1.
Visualization examples with classical instance segmentation model-Mask R-CNN. Note: the red boxes represent buildings with blurring contours, the yellow boxes represent undetected small buildings and the green boxes are generated by Mask R-CNN.
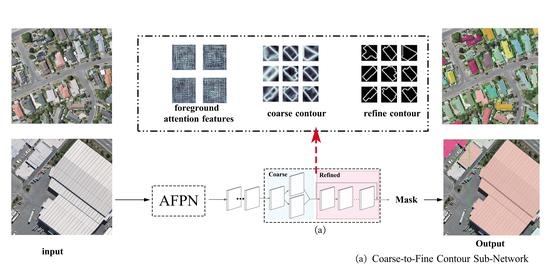
Figure 2.
Overview of the proposed network for building instance extraction: (a) AFPN sub-network, (b) coarse-to-fine contour sub-network.
Figure 2.
Overview of the proposed network for building instance extraction: (a) AFPN sub-network, (b) coarse-to-fine contour sub-network.
Figure 3.
Structure of AFPN. is the i-th layer of FPN.
Figure 3.
Structure of AFPN. is the i-th layer of FPN.
Figure 4.
Structure of coarse-to-fine contour sub-network: (a) coarse contour branch, (b) refined contour branch.
Figure 4.
Structure of coarse-to-fine contour sub-network: (a) coarse contour branch, (b) refined contour branch.
Figure 5.
Samples of the WHU aerial imagery dataset. The ground truth of the buildings is in cyan.
Figure 5.
Samples of the WHU aerial imagery dataset. The ground truth of the buildings is in cyan.
Figure 6.
Samples of CrowdAI. The ground truth of buildings is in cyan.
Figure 6.
Samples of CrowdAI. The ground truth of buildings is in cyan.
Figure 7.
Distribution of the self-annotated building instance segmentation dataset.
Figure 7.
Distribution of the self-annotated building instance segmentation dataset.
Figure 8.
Samples of the self-annotated building instance segmentation dataset. The ground truth of the buildings is in cyan.
Figure 8.
Samples of the self-annotated building instance segmentation dataset. The ground truth of the buildings is in cyan.
Figure 9.
Schematic diagram of CS.
Figure 9.
Schematic diagram of CS.
Figure 10.
Visualized results of building instance extraction using the WHU aerial image dataset: (a) the original remote sensing imagery, (b) Mask R-CNN, (c) HTC, (d) CenterMask, (e) SOLOv2, (f) Proposed model.
Figure 10.
Visualized results of building instance extraction using the WHU aerial image dataset: (a) the original remote sensing imagery, (b) Mask R-CNN, (c) HTC, (d) CenterMask, (e) SOLOv2, (f) Proposed model.
Figure 11.
Visualized results of building instance extraction using CrowdAI: (a) the original remote sensing imagery, (b) Mask R-CNN, (c) HTC, (d) CenterMask, (e) SOLOv2, (f) Proposed model.
Figure 11.
Visualized results of building instance extraction using CrowdAI: (a) the original remote sensing imagery, (b) Mask R-CNN, (c) HTC, (d) CenterMask, (e) SOLOv2, (f) Proposed model.
Figure 12.
Visualized results of building instance extraction using the self-annotated building instance segmentation Dataset: (a) the original remote sensing imagery, (b) Mask R-CNN, (c) HTC, (d) CenterMask, (e) SOLOv2, (f) Proposed model.
Figure 12.
Visualized results of building instance extraction using the self-annotated building instance segmentation Dataset: (a) the original remote sensing imagery, (b) Mask R-CNN, (c) HTC, (d) CenterMask, (e) SOLOv2, (f) Proposed model.
Figure 13.
Visualization of features in different convolution layers: (a) the original remote sensing imagery, (b) feature maps in conv1 without attention module, (c) feature maps in conv1 with attention module, (d) feature maps in conv2 without attention module, (e) feature maps in conv2 with attention module, (f) feature maps in conv3 without attention module, (g) feature maps in conv3 with attention module.
Figure 13.
Visualization of features in different convolution layers: (a) the original remote sensing imagery, (b) feature maps in conv1 without attention module, (c) feature maps in conv1 with attention module, (d) feature maps in conv2 without attention module, (e) feature maps in conv2 with attention module, (f) feature maps in conv3 without attention module, (g) feature maps in conv3 with attention module.
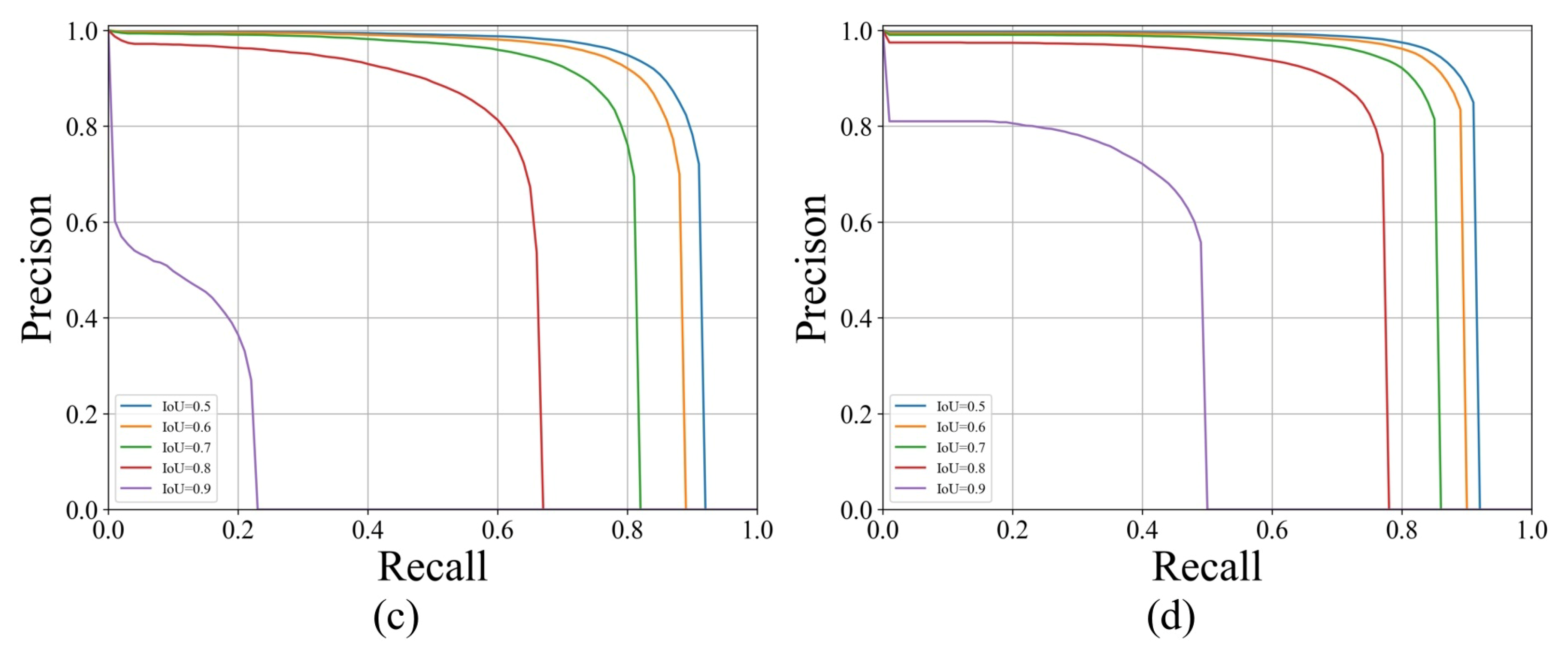
Figure 14.
Precision-recall curve with different IoU thresholds: (a) Mask R-CNN, (b) Hybrid Task Cascade, (c) SOLOv2, (d) Proposed model.
Figure 14.
Precision-recall curve with different IoU thresholds: (a) Mask R-CNN, (b) Hybrid Task Cascade, (c) SOLOv2, (d) Proposed model.
Table 1.
Comparison of different network extraction methods on the WHU aerial image dataset. The best results are highlighted in bold.
Table 1.
Comparison of different network extraction methods on the WHU aerial image dataset. The best results are highlighted in bold.
| Model | | | | | |
|---|
| Mask R-CNN [5] | 0.601 | 0.884 | 0.473 | 0.649 | 0.685 |
| HTC [43] | 0.643 | 0.900 | 0.511 | 0.688 | 0.760 |
| CenterMask [32] | 0.658 | 0.830 | 0.514 | 0.695 | 0.739 |
| SOLOv2 [44] | 0.614 | 0.878 | 0.454 | 0.661 | 0.737 |
| Proposed model | 0.698 | 0.906 | 0.574 | 0.743 | 0.795 |
Table 2.
Comparison of different network extraction methods on CrowdAI. The best results are highlighted in bold.
Table 2.
Comparison of different network extraction methods on CrowdAI. The best results are highlighted in bold.
| Model | | | | | |
|---|
| Mask R-CNN [5] | 0.600 | 0.886 | 0.367 | 0.649 | 0.724 |
| HTC [43] | 0.630 | 0.903 | 0.394 | 0.684 | 0.746 |
| CenterMask [32] | 0.623 | 0.903 | 0.378 | 0.686 | 0.753 |
| SOLOv2 [44] | 0.612 | 0.888 | 0.377 | 0.658 | 0.734 |
| Proposed model | 0.649 | 0.905 | 0.407 | 0.706 | 0.776 |
Table 3.
Comparison of different network extraction methods on the self-annotated building instance segmentation dataset.The best results are highlighted in bold.
Table 3.
Comparison of different network extraction methods on the self-annotated building instance segmentation dataset.The best results are highlighted in bold.
| Model | | | | | |
|---|
| Mask R-CNN [5] | 0.392 | 0.611 | 0.121 | 0.558 | 0.489 |
| HTC [43] | 0.414 | 0.655 | 0.163 | 0.520 | 0.520 |
| CenterMask [32] | 0.400 | 0.670 | 0.160 | 0.520 | 0.517 |
| SOLOv2 [44] | 0.413 | 0.674 | 0.136 | 0.563 | 0.527 |
| Proposed model | 0.437 | 0.683 | 0.191 | 0.570 | 0.546 |
Table 4.
Ablation study with different components combinations on the WHU aerial image dataset. The best results are in bold.
Table 4.
Ablation study with different components combinations on the WHU aerial image dataset. The best results are in bold.
| Model | | | | | |
|---|
| Mask R-CNN [5] | 0.601 | 0.884 | 0.473 | 0.649 | 0.685 |
| +attention | 0.647 | 0.901 | 0.536 | 0.690 | 0.763 |
| +Coarse contour branch | 0.663 | 0.897 | 0.546 | 0.701 | 0.771 |
| +Refined contour branch | 0.698 | 0.906 | 0.565 | 0.737 | 0.795 |
Table 5.
Comparison results of edge detection operators on the WHU aerial image dataset. The best results are in bold.
Table 5.
Comparison results of edge detection operators on the WHU aerial image dataset. The best results are in bold.
| Method | | | | | |
|---|
| Sobel [35] | 0.698 | 0.906 | 0.574 | 0.743 | 0.795 |
| Laplace [45] | 0.691 | 0.898 | 0.565 | 0.737 | 0.787 |
| Canny [46] | 0.675 | 0.864 | 0.541 | 0.716 | 0.770 |
Table 6.
Comparison results on different loss functions on WHU aerial image dataset. The best results are in bold.
Table 6.
Comparison results on different loss functions on WHU aerial image dataset. The best results are in bold.
| Loss | | | | | |
|---|
| no contour loss | 0.659 | 0.860 | 0.516 | 0.695 | 0.752 |
| BCE loss | 0.671 | 0.881 | 0.543 | 0.701 | 0.768 |
| Dice loss | 0.691 | 0.898 | 0.556 | 0.737 | 0.787 |
| both Dice and BCE loss () | 0.696 | 0.905 | 0.563 | 0.743 | 0.793 |
| both Dice and BCE loss () | 0.695 | 0.904 | 0.562 | 0.741 | 0.792 |
| both Dice and BCE loss () | 0.698 | 0.906 | 0.565 | 0.743 | 0.795 |
Table 7.
Comparison results with different IoU thresholds. The best results are in bold.
Table 7.
Comparison results with different IoU thresholds. The best results are in bold.
| Model | | | | | | | CS |
|---|
| Mask R-CNN [5] | 0.601 | 0.886 | 0.845 | 0.758 | 0.561 | 0.077 | 0.685 |
| HTC [43] | 0.643 | 0.902 | 0.875 | 0.812 | 0.667 | 0.213 | 0.760 |
| CenterMask [32] | 0.658 | 0.830 | 0.823 | 0.790 | 0.712 | 0.361 | 0.739 |
| SOLOv2 [44] | 0.614 | 0.878 | 0.864 | 0.787 | 0.613 | 0.113 | 0.737 |
| Proposed model | 0.699 | 0.906 | 0.891 | 0.846 | 0.749 | 0.396 | 0.795 |



 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}