
Fine-Scale Sea Ice Segmentation for High-Resolution Satellite Imagery with Weakly-Supervised CNNs

Abstract
:
1. Introduction
2. Materials and Methods
2.1. Imagery and Data Annotation
2.1.1. Hand-Labeled Training Set
2.1.2. Watershed Training Set
2.1.3. Synthetic Image Training Set
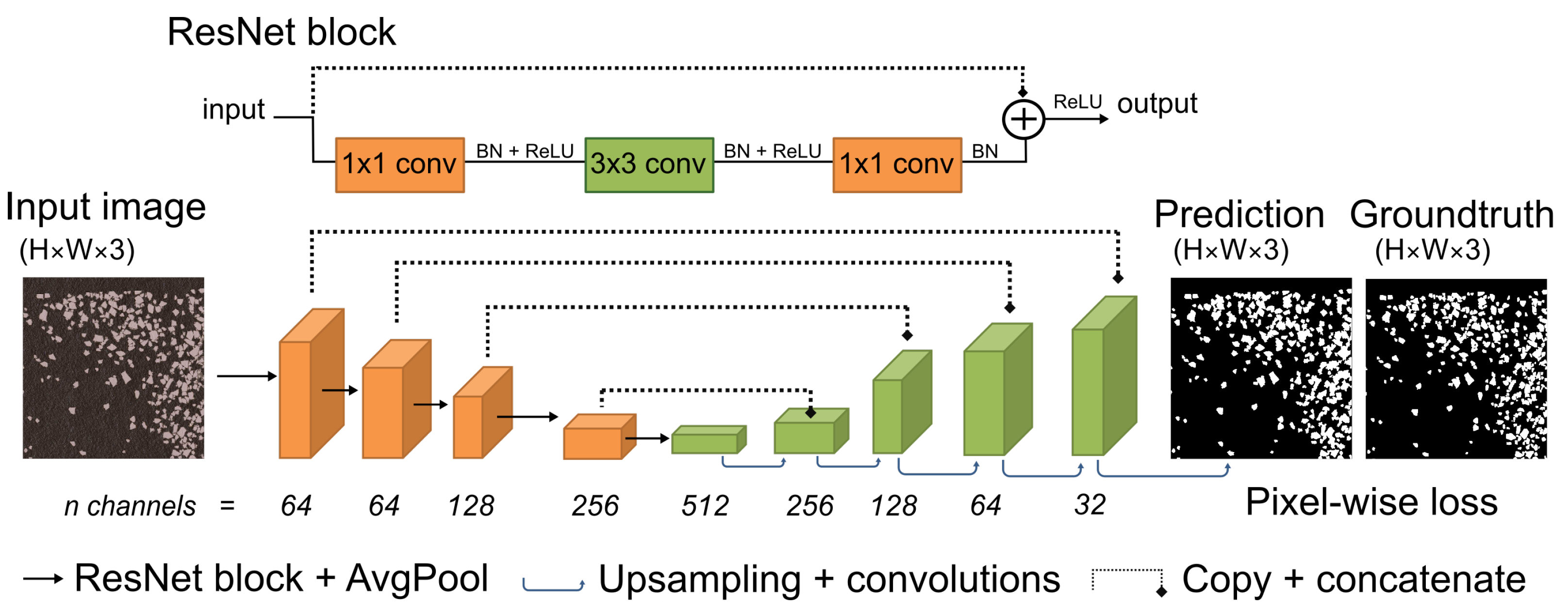
2.2. Segmentation CNNs
2.3. CNN Training and Validation
2.4. Testing
2.5. Loss Functions
2.6. Data Augmentation
2.7. Model Baselines
3. Results
3.1. Model Performance
3.2. Hyperparameter Search
3.3. Qualitative Model Output
4. Discussion
4.1. Model Out-of-Sample Performance
4.2. Hyperparameter Search
4.3. Fine-Tuning Experiments
4.4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goosse, H.; Kay, J.E.; Armour, K.C.; Bodas-Salcedo, A.; Chepfer, H.; Docquier, D.; Jonko, A.; Kushner, P.J.; Lecomte, O.; Massonnet, F.; et al. Quantifying climate feedbacks in polar regions. Nat. Commun. 2018, 9, 1–13. [Google Scholar] [CrossRef]
- Winton, M. Sea ice-albedo feedback and nonlinear Arctic climate change. In Arctic Sea Ice Decline: Observations, Projections, Mechanisms, and Implications; DeWeaver, E., Bitz, C., Tremblay, L.B., Eds.; AGU: Washington, DC, USA, 2008; Volume 180, pp. 111–131. [Google Scholar]
- Arrigo, K.R.; Thomas, D.N. Large scale importance of sea ice biology in the Southern Ocean. Antarct. Sci. 2004, 16, 471–486. [Google Scholar] [CrossRef] [Green Version]
- Eicken, H. The role of sea ice in structuring Antarctic ecosystems. In Weddell Sea Ecology; Springer: Berlin/Heidelberg, Germany, 1992; pp. 3–13. [Google Scholar]
- Thomas, D.N.; Dieckmann, G.S. Sea Ice: An Introduction to Its Physics, Chemistry, Biology and Geology; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Comiso, J.C.; Cavalieri, D.J.; Parkinson, C.L.; Gloersen, P. Passive microwave algorithms for sea ice concentration: A comparison of two techniques. Remote Sens. Environ. 1997, 60, 357–384. [Google Scholar] [CrossRef]
- Peng, G.; Meier, W.N.; Scott, D.; Savoie, M. A long-term and reproducible passive microwave sea ice concentration data record for climate studies and monitoring. Earth Syst. Sci. Data 2013, 5, 311–318. [Google Scholar] [CrossRef] [Green Version]
- Sandru, A.; Hyyti, H.; Visala, A.; Kujala, P. A complete process for shipborne sea-ice field analysis using machine vision. IFAC-PapersOnLine 2020, 53, 14539–14545. [Google Scholar] [CrossRef]
- Millan, J.; Wang, J. Ice force modeling for DP control systems. In Proceedings of the Dynamic Positioning Conference, Houston, TX, USA, 11–12 October 2011. [Google Scholar]
- Hunke, E.C.; Lipscomb, W.H.; Turner, A.K. Sea-ice models for climate study: Retrospective and new directions. J. Glaciol. 2010, 56, 1162–1172. [Google Scholar] [CrossRef] [Green Version]
- Massom, R.A.; Stammerjohn, S.E. Antarctic sea ice change and variability–physical and ecological implications. Polar Sci. 2010, 4, 149–186. [Google Scholar] [CrossRef] [Green Version]
- Burns, J.; Hindell, M.A.; Bradshaw, C.J.; Costa, D.P. Fine-scale habitat selection of crabeater seals as determined by diving behavior. Deep. Sea Res. Part II Top. Stud. Oceanogr. 2008, 55, 500–514. [Google Scholar] [CrossRef]
- Ballard, G.; Schmidt, A.E.; Toniolo, V.; Veloz, S.; Jongsomjit, D.; Arrigo, K.R.; Ainley, D.G. Fine-scale oceanographic features characterizing successful Adélie penguin foraging in the SW Ross Sea. Mar. Ecol. Prog. Ser. 2019, 608, 263–277. [Google Scholar] [CrossRef]
- Labrousse, S.; Fraser, A.D.; Sumner, M.; Tamura, T.; Pinaud, D.; Wienecke, B.; Kirkwood, R.; Ropert-Coudert, Y.; Reisinger, R.; Jonsen, I.; et al. Dynamic fine-scale sea icescape shapes adult emperor penguin foraging habitat in East Antarctica. Geophys. Res. Lett. 2019, 46, 11206–11218. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.D.; Chen, D. Segmentation for object-based image analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Zhang, Q.; Skjetne, R. Image processing for identification of sea-ice floes and the floe size distributions. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2913–2924. [Google Scholar] [CrossRef]
- Zhang, Q.; Skjetne, R.; Su, B. Automatic image segmentation for boundary detection of apparently connected sea-ice floes. In Proceedings of the 22nd International Conference on Port and Ocean Engineering under Arctic Conditions. Port and Ocean Engineering under Arctic Conditions, Espoo, Finland, 7–14 September 2013; pp. 13–164. [Google Scholar]
- Ijitona, T.B.; Ren, J.; Hwang, P.B. SAR sea ice image segmentation using watershed with intensity-based region merging. In Proceedings of the 2014 IEEE International Conference on Computer and Information Technology, Xi’an, China, 11–13 September 2014; pp. 168–172. [Google Scholar]
- Wright, N.C.; Polashenski, C.M. Open-source algorithm for detecting sea ice surface features in high-resolution optical imagery. Cryosphere 2018, 12, 1307–1329. [Google Scholar] [CrossRef] [Green Version]
- Boulze, H.; Korosov, A.; Brajard, J. Classification of Sea Ice Types in Sentinel-1 SAR Data Using Convolutional Neural Networks. Remote Sens. 2020, 12, 2165. [Google Scholar] [CrossRef]
- Han, Y.; Liu, Y.; Hong, Z.; Zhang, Y.; Yang, S.; Wang, J. Sea ice image classification based on heterogeneous data fusion and deep learning. Remote Sens. 2021, 13, 592. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Dowden, B.; De Silva, O.; Huang, W.; Oldford, D. Sea ice classification via deep neural network semantic segmentation. IEEE Sens. J. 2020, 21, 11879–11888. [Google Scholar] [CrossRef]
- Panchi, N.; Kim, E.; Bhattacharyya, A. Supplementing remote sensing of ice: Deep learning-based image segmentation system for automatic detection and localization of sea ice formations from close-range optical images. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Shanmugam, D.; Blalock, D.; Balakrishnan, G.; Guttag, J. When and why test-time augmentation works. arXiv 2020, arXiv:2011.11156. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. Mixmatch: A holistic approach to semi-supervised learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Jadon, S. A survey of Loss Functions for Semantic Segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB); Available online: https://cibcb2020.uai.cl/ (accessed on 16 August 2021).
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal loss for dense object detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- El Jurdi, R.; Petitjean, C.; Honeine, P.; Cheplygina, V.; Abdallah, F. A surprisingly effective perimeter-based loss for medical image segmentation. In Proceedings of the Medical Imaging with Deep Learning, Lübeck, Germany, 7–9 July 2021. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Skjetne, R.; Metrikin, I.; Løset, S. Image processing for ice floe analyses in broken-ice model testing. Cold Reg. Sci. Technol. 2015, 111, 27–38. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.Y.; Park, S.M.; Sim, K.B. Optimal hyperparameter tuning of convolutional neural networks based on the parameter-setting-free harmony search algorithm. Optik 2018, 172, 359–367. [Google Scholar] [CrossRef]
- Andonie, R.; Florea, A.C. Weighted random search for CNN hyperparameter optimization. arXiv 2020, arXiv:2003.13300. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. Gridmask data augmentation. arXiv 2020, arXiv:2001.04086. [Google Scholar]
- Gong, C.; Wang, D.; Li, M.; Chandra, V.; Liu, Q. KeepAugment: A Simple Information-Preserving Data Augmentation Approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 21–24 June 2021; pp. 1055–1064. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Coon, M.; Maykut, G.; Pritchard, R. Modeling the Pack Ice as an Elastic-Plastic Material; Springer: Berlin/Heidelberg, Germany, 1974. [Google Scholar]
- Blockley, E.; Vancoppenolle, M.; Hunke, E.; Bitz, C.; Feltham, D.; Lemieux, J.F.; Losch, M.; Maisonnave, E.; Notz, D.; Rampal, P.; et al. The future of sea ice modeling: Where do we go from here? Bull. Am. Meteorol. Soc. 2020, 101, E1304–E1311. [Google Scholar] [CrossRef]
- Coon, M.; Kwok, R.; Levy, G.; Pruis, M.; Schreyer, H.; Sulsky, D. Arctic Ice Dynamics Joint Experiment (AIDJEX) assumptions revisited and found inadequate. J. Geophys. Res. Ocean. 2007, 112. [Google Scholar] [CrossRef]
- Girard, L.; Weiss, J.; Molines, J.M.; Barnier, B.; Bouillon, S. Evaluation of high-resolution sea ice models on the basis of statistical and scaling properties of Arctic sea ice drift and deformation. J. Geophys. Res. Ocean. 2009, 114. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Catalog ID | Lat-Lon | Cloud Cover | Total Area | Date |
|---|---|---|---|---|
| 1040010005B62F00 | −69.3327 158.4884 | 0.0 | 263.1 km | 20 November 2014 |
| 1040010013346700 | −76.9427 166.8715 | 0.0 | 212.6 km | 26 November 2015 |
| 10400100156E6500 | −63.1618 −54.9593 | 0.0 | 268.8 km | 01 January 2016 |
| 10400100156E6500 | −63.8006 −54.959 | 0.0 | 202.7 km | 01 January 2016 |
| 10400100156E6500 | −63.2718 −54.959 | 0.0 | 265.3 km | 01 January 2016 |
| 10400100156E6500 | −63.599 −54.9589 | 0.0 | 259.3 km | 01 January 2016 |
| 1040010016234E00 | −67.256 45.9485 | 0.0 | 266.5 km | 02 January 2016 |
| 1040010016234E00 | −67.668 45.9477 | 0.0 | 172.8 km | 02 January 2016 |
| 1040010016234E00 | −67.0437 45.9485 | 0.0 | 244.6 km | 02 January 2016 |
| 1040010016234E00 | −67.1471 45.9486 | 0.0 | 265.0 km | 02 January 2016 |
| 1040010016234E00 | −67.3652 45.9489 | 0.0 | 268.2 km | 02 January 2016 |
| 1040010016234E00 | −67.4748 45.9489 | 0.0 | 269.9 km | 02 January 2016 |
| 1040010017265B00 | −76.0 −26.6717 | 0.0 | 224.5 km | 07 January 2016 |
| 1040010017A12200 | −67.4771 164.6313 | 0.0 | 168.7 km | 12 January 2016 |
| 10400100167EC800 | −63.4564 −56.8695 | 0.0 | 282.7 km | 17 January 2016 |
| 10400100167EC800 | −63.3475 −56.8686 | 0.0 | 281.0 km | 17 January 2016 |
| 10400100167EC800 | −63.6757 −56.8695 | 0.0 | 287.3 km | 17 January 2016 |
| 10400100167EC800 | −63.2385 −56.8685 | 0.0 | 279.2 km | 17 January 2016 |
| 10400100178F7100 | −63.4235 −54.669 | 0.0 | 186.1 km | 21 January 2016 |
| 104001001762AC00 | −66.2365 110.1896 | 0.0 | 191.1 km | 21 January 2016 |
| 10400100175A5600 | −66.6168 −68.2485 | 0.0 | 122.0 km | 25 January 2016 |
| 10400100175A5600 | −67.575 −68.25 | 0.0 | 269.3 km | 25 January 2016 |
| 104001001747E000 | −64.2565 −56.6693 | 0.0 | 291.3 km | 26 January 2016 |
| 104001001777C600 | −69.0697 76.7836 | 0.0 | 220.4 km | 28 January 2016 |
| 1040010018447F00 | −67.6175 66.5771 | 0.0 | 296.5 km | 28 January 2016 |
| 104001001844A900 | −66.5325 92.5386 | 0.0 | 208.0 km | 28 January 2016 |
| 1040010017764300 | −74.7749 164.0267 | 0.0 | 225.3 km | 29 January 2016 |
| 1040010017823400 | −72.3657 170.2705 | 0.0 | 207.9 km | 04 February 2016 |
| 1040010018694800 | −72.0 170.5882 | 0.0 | 170.7 km | 04 February 2016 |
| 10400100196BE200 | −65.4111 −64.3911 | 0.0 | 274.8 km | 25 February 2016 |
| 10400100196BE200 | −65.4984 −64.3908 | 0.0 | 191.9 km | 25 February 2016 |
| 10400100181F9B00 | −66.8013 50.5412 | 0.0 | 215.6 km | 27 February 2016 |
| 1040010018755100 | −67.4705 61.0185 | 0.0 | 221.4 km | 05 March 2016 |
| 1040010018046800 | −65.938 110.2305 | 0.0 | 207.7 km | 07 March 2016 |
| 1040010019529D00 | −77.7016 −47.6769 | 0.0 | 183.9 km | 13 March 2016 |
| 1040010019417700 | −76.1377 168.3823 | 0.0 | 243.9 km | 15 March 2016 |
| 104001001A625A00 | −70.0097 −1.4187 | 0.0 | 163.3 km | 16 March 2016 |
| 104001001A8FF900 | −67.3803 63.9762 | 0.0 | 237.1 km | 16 March 2016 |
| 104001001A27CC00 | −64.5113 −57.4442 | 0.0 | 264.6 km | 23 March 2016 |
| 104001001B448400 | −69.9403 8.3095 | 0.0 | 163.1 km | 25 March 2016 |
| 104001001A896700 | −67.8698 69.7022 | 0.0 | 181.1 km | 30 March 2016 |
| 104001001A6C8C00 | −70.5887 −60.5685 | 0.0 | 234.1 km | 07 April 2016 |
| 1040010028CD9C00 | −73.2326 −126.7786 | 0.0 | 162.3 km | 25 January 2017 |
| Training Set | Scenes | Area + | Area − |
|---|---|---|---|
| Hand-labeled [train] | 19 | 20.8 km | 240.9 km |
| Hand-labeled [valid] | 18 | 20.2 km | 17.85 km |
| Hand-labeled [test] | 19 | 20.4 km | 16.8 km |
| Watershed [train] | 27 | 393.1 km | 240.9 km |
| Synthetic [train] | 27 | 393.1 km | 240.9 km |
| Model | Input Size | Dataset | F1 (Val) | F1 (Test) | N |
|---|---|---|---|---|---|
| U-Net | 256 | hand | 0.842 | 0.727 ± 0.132 | 34, 12 |
| U-Net | 256 | hand + synthetic | 0.824 | 0.713 ± 0.87 | 36, 16 |
| U-Net | 256 | hand + watershed | 0.855 | 0.628 ± 0.174 | 34, 12 |
| U-Net | 256 | synthetic | 0.732 | 0.739 ± 0.126 | 42, 17 |
| Watershed | 256 | - | - | 0.464 ± 0.139 | - |
| U-Net | 384 | hand | 0.736 | 0.747 ± 0.142 | 31, 16 |
| U-Net | 384 | hand + synthetic | 0.822 | 0.713 ± 0.162 | 41, 19 |
| U-Net | 384 | hand + watershed | 0.848 | 0.633 ± 0.180 | 33, 10 |
| U-Net | 384 | synthetic | 0.769 | 0.727 ± 0.135 | 46, 21 |
| Watershed | 384 | - | - | 0.460 ± 0.141 | - |
| U-Net | 512 | hand | 0.776 | 0.733 ± 0.158 | 40, 13 |
| U-Net | 512 | hand + synthetic | 0.850 | 0.753 ± 0.113 | 32, 14 |
| U-Net | 512 | hand + watershed | 0.839 | 0.696 ± 0.176 | 39, 14 |
| U-Net | 512 | synthetic | 0.830 | 0.734 ± 0.133 | 37, 14 |
| Watershed | 512 | - | - | 0.459 ± 0.136 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonçalves, B.C.; Lynch, H.J. Fine-Scale Sea Ice Segmentation for High-Resolution Satellite Imagery with Weakly-Supervised CNNs. Remote Sens. 2021, 13, 3562. https://doi.org/10.3390/rs13183562
Gonçalves BC, Lynch HJ. Fine-Scale Sea Ice Segmentation for High-Resolution Satellite Imagery with Weakly-Supervised CNNs. Remote Sensing. 2021; 13(18):3562. https://doi.org/10.3390/rs13183562
Chicago/Turabian StyleGonçalves, Bento C., and Heather J. Lynch. 2021. "Fine-Scale Sea Ice Segmentation for High-Resolution Satellite Imagery with Weakly-Supervised CNNs" Remote Sensing 13, no. 18: 3562. https://doi.org/10.3390/rs13183562