
Long-Term Hindcasts of Wheat Yield in Fields Using Remotely Sensed Phenology, Climate Data and Machine Learning



Abstract
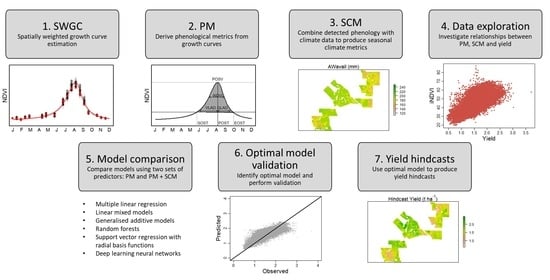
:
1. Introduction
2. Materials and Methods
2.1. Data
2.1.1. Study Area
2.1.2. Landsat Data
2.1.3. Wheat Yield Data
2.1.4. Climate Data
2.2. Methods
2.2.1. Spatially Weighted Growth Curve Estimation
2.2.2. Phenological Metrics
2.2.3. Seasonal Climate Metrics
2.2.4. Data Exploration
2.2.5. Statistical and Machine Learning Models
2.2.6. Yield Predictors
2.2.7. Model Comparison
2.2.8. Optimal Model Validation
2.2.9. Yield Hindcasts
3. Results
3.1. Spatially Weighted Growth Curve Estimation
3.2. Phenological and Seasonal Climate Metrics
3.3. Data Exploration
3.4. Model Comparison
3.5. Optimal Model Validation
3.6. Yield Hindcasts
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Robert, P.C. Precision agriculture: A challenge for crop nutrition management. Plant Soil 2002, 247, 143–149. [Google Scholar] [CrossRef]
- Whelan, B.; Taylor, J. Precision Agriculture for Grain Production Systems; CSIRO Publishing: Melbourne, Australia, 2013. [Google Scholar] [CrossRef] [Green Version]
- Plant, R.E. Site-specific management: The application of information technology to crop production. Comput. Electron. Agric. 2001, 30, 9–29. [Google Scholar] [CrossRef]
- White, E.L.; Thomasson, J.A.; Auvermann, B.; Kitchen, N.R.; Pierson, L.S.; Porter, D.; Baillie, C.; Hamann, H.; Hoogenboom, G.; Janzen, T.; et al. Report from the conference, ‘identifying obstacles to applying big data in agriculture’. Precis. Agric. 2020, 22, 306–315. [Google Scholar] [CrossRef]
- Leonard, E.; Rainbow, R.; Baker, I.; Barry, S.; Darragh, L.; Darnell, R.; George, A.; Heath, R.; Jakku, E.; Laurie, A.; et al. Accelerating Precision Agriculture to Decision Agriculture: Enabling Digital Agriculture in Australia; Cotton Research and Development Corporation: Narrabri, Australia, 2017.
- Xue, J.; Su, B. Significant remote sensing vegetation indices: A review of developments and applications. J. Sens. 2017, 2017, 1353691. [Google Scholar] [CrossRef] [Green Version]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS. In Proceedings of the Goddard Space Flight Center 3rd ERTS-1 Symposium, Washington, DC, USA, 10–14 December 1973; pp. 309–317. [Google Scholar]
- De Beurs, K.M.; Henebry, G.M. Spatio-Temporal Statistical Methods for Modelling Land Surface Phenology. In Phenological Research; Hudson, I.L., Keatley, M.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–208. [Google Scholar] [CrossRef]
- Zeng, L.; Wardlow, B.D.; Xiang, D.; Hu, S.; Li, D. A review of vegetation phenological metrics extraction using time-series, multispectral satellite data. Remote Sens. Environ. 2020, 237, 111511. [Google Scholar] [CrossRef]
- Mkhabela, M.S.; Bullock, P.; Raj, S.; Wang, S.; Yang, Y. Crop yield forecasting on the Canadian Prairies using MODIS NDVI data. Agric. For. Meteorol. 2011, 151, 385–393. [Google Scholar] [CrossRef]
- Salazar, L.; Kogan, F.; Roytman, L. Use of remote sensing data for estimation of winter wheat yield in the United States. Int. J. Remote Sens. 2007, 28, 3795–3811. [Google Scholar] [CrossRef]
- Bolton, D.K.; Friedl, M.A. Forecasting crop yield using remotely sensed vegetation indices and crop phenology metrics. Agric. For. Meteorol. 2013, 173, 74–84. [Google Scholar] [CrossRef]
- Sakamoto, T.; Gitelson, A.A.; Arkebauer, T.J. MODIS-based corn grain yield estimation model incorporating crop phenology information. Remote Sens. Environ. 2013, 131, 215–231. [Google Scholar] [CrossRef]
- Gregersen, P.L.; Culetic, A.; Boschian, L.; Krupinska, K. Plant senescence and crop productivity. Plant Mol. Biol. 2013, 82, 603–622. [Google Scholar] [CrossRef]
- Zeleke, K.T.; Nendel, C. Analysis of options for increasing wheat (Triticum aestivum L.) yield in south-eastern Australia: The role of irrigation, cultivar choice and time of sowing. Agric. Water Manag. 2016, 166, 139–148. [Google Scholar] [CrossRef]
- Flohr, B.M.; Hunt, J.R.; Kirkegaard, J.A.; Evans, J.R.; Trevaskis, B.; Zwart, A.; Swan, A.; Fletcher, A.L.; Rheinheimer, B. Fast winter wheat phenology can stabilise flowering date and maximise grain yield in semi-arid Mediterranean and temperate environments. Field Crop. Res. 2018, 223, 12–25. [Google Scholar] [CrossRef]
- Hunt, J.R.; Lilley, J.M.; Trevaskis, B.; Flohr, B.M.; Peake, A.; Fletcher, A.; Zwart, A.B.; Gobbett, D.; Kirkegaard, J.A. Early sowing systems can boost Australian wheat yields despite recent climate change. Nat. Clim. Chang. 2019, 9, 244–247. [Google Scholar] [CrossRef]
- Fischer, R.A.; Kohn, G.D. The relationship of grain yield to vegetative growth and post-flowering leaf area in the wheat crop under conditions of limited soil moisture. Aust. J. Agric. Res. 1966, 17, 281–295. [Google Scholar] [CrossRef]
- Rezaei, E.E.; Ghazaryan, G.; Gonzalez, J.; Cornish, N.; Dubovyk, O.; Siebert, S. The use of remote sensing to derive maize sowing dates for large-scale crop yield simulations. Int. J. Biometeorol. 2021, 65, 565–576. [Google Scholar] [CrossRef] [PubMed]
- Ji, Z.; Pan, Y.; Zhu, X.; Wang, J.; Li, Q. Prediction of Crop Yield Using Phenological Information Extracted from Remote Sensing Vegetation Index. Sensors 2021, 21, 1406. [Google Scholar] [CrossRef] [PubMed]
- Becker-Reshef, I.; Vermote, E.; Lindeman, M.; Justice, C. A generalized regression-based model for forecasting winter wheat yields in Kansas and Ukraine using MODIS data. Remote Sens. Environ. 2010, 114, 1312–1323. [Google Scholar] [CrossRef]
- Lai, Y.R.; Pringle, M.J.; Kopittke, P.M.; Menzies, N.W.; Orton, T.G.; Dang, Y.P. An empirical model for prediction of wheat yield, using time-integrated Landsat NDVI. Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 99–108. [Google Scholar] [CrossRef]
- Labus, M.P.; Nielsen, G.A.; Lawrence, R.L.; Engel, R.; Long, D.S. Wheat yield estimates using multi-temporal NDVI satellite imagery. Int. J. Remote Sens. 2002, 23, 4169–4180. [Google Scholar] [CrossRef]
- Kamir, E.; Waldner, F.; Hochman, Z. Estimating wheat yields in Australia using climate records, satellite image time series and machine learning methods. ISPRS J. Photogramm. Remote Sens. 2020, 160, 124–135. [Google Scholar] [CrossRef]
- Benedetti, R.; Rossini, P. On the use of NDVI profiles as a tool for agricultural statistics: The case study of wheat yield estimate and forecast in Emilia Romagna. Remote Sens. Environ. 1993, 45, 311–326. [Google Scholar] [CrossRef]
- Araya, S.; Ostendorf, B.; Lyle, G.; Lewis, M. Remote sensing derived phenological metrics to assess the spatio-temporal growth variability in cropping fields. Adv. Remote Sens. 2017, 6, 212–228. [Google Scholar] [CrossRef] [Green Version]
- Kouadio, L.; Duveiller, G.; Djaby, B.; El Jarroudi, M.; Defourny, P.; Tychon, B. Estimating regional wheat yield from the shape of decreasing curves of green area index temporal profiles retrieved from MODIS data. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 111–118. [Google Scholar] [CrossRef] [Green Version]
- Waldner, F.; Horan, H.; Chen, Y.; Hochman, Z. High temporal resolution of leaf area data improves empirical estimation of grain yield. Sci. Rep. 2019, 9, 15714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Donohue, R.J.; McVicar, T.R.; Waldner, F.; Mata, G.; Ota, N.; Houshmandfar, A.; Dayal, K.; Lawes, R.A. Nationwide crop yield estimation based on photosynthesis and meteorological stress indices. Agric. For. Meteorol. 2020, 284, 107872. [Google Scholar] [CrossRef]
- Donohue, R.J.; Lawes, R.A.; Mata, G.; Gobbett, D.; Ouzman, J. Towards a national, remote-sensing-based model for predicting field-scale crop yield. Field Crop. Res. 2018, 227, 79–90. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Z.; Feng, L.; Du, Q.; Runge, T. Combining Multi-Source Data and Machine Learning Approaches to Predict Winter Wheat Yield in the Conterminous United States. Remote Sens. 2020, 12, 1232. [Google Scholar] [CrossRef] [Green Version]
- Belward, A.S.; Skøien, J.O. Who launched what, when and why; trends in global land-cover observation capacity from civilian earth observation satellites. ISPRS J. Photogramm. Remote Sens. 2015, 103, 115–128. [Google Scholar] [CrossRef]
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Caccetta, P.; Furby, S.; Richards, G.; Wallace, J.; Waterworth, R.; Wu, X. Long-term monitoring of australian land cover change using Landsat data: Development, implementation, and operation. In Global Forest Monitoring from Earth Observation; Achard, F., Hansen, M.C., Eds.; CRC Press: Boca Raton, FL, USA, 2002; pp. 243–258. [Google Scholar] [CrossRef]
- Furby, S.L.; Caccetta, P.A.; Wallace, J.F.; Lehmann, E.A.; Zdunic, K. Recent development in vegetation monitoring products from Australia’s National Carbon Accounting System. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009. [Google Scholar]
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T.K. A Landsat Surface Reflectance Dataset for North America, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Jin, S.; Yang, L.; Danielson, P.; Homer, C.; Fry, J.; Xian, G. A comprehensive change detection method for updating the National Land Cover Database to circa 2011. Remote Sens. Environ. 2013, 132, 159–175. [Google Scholar] [CrossRef] [Green Version]
- Achard, F.; Stibig, H.-J.; Eva, H.D.; Lindquist, E.J.; Bouvet, A.; Arino, O.; Mayaux, P. Estimating tropical deforestation from Earth observation data. Carbon Manag. 2014, 1, 271–287. [Google Scholar] [CrossRef] [Green Version]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Johnson, D.M. Using the Landsat archive to map crop cover history across the United States. Remote Sens. Environ. 2019, 232, 111286. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Sakamoto, T.; Wardlow, B.D.; Gitelson, A.A.; Verma, S.B.; Suyker, A.E.; Arkebauer, T.J. A Two-Step Filtering approach for detecting maize and soybean phenology with time-series MODIS data. Remote Sens. Environ. 2010, 114, 2146–2159. [Google Scholar] [CrossRef]
- Roy, D.P.; Yan, L. Robust Landsat-based crop time series modelling. Remote Sens. Environ. 2020, 238, 110810. [Google Scholar] [CrossRef]
- Whitcraft, A.K.; Vermote, E.F.; Becker-Reshef, I.; Justice, C.O. Cloud cover throughout the agricultural growing season: Impacts on passive optical earth observations. Remote Sens. Environ. 2015, 156, 438–447. [Google Scholar] [CrossRef]
- Younes, N.; Joyce, K.E.; Maier, S.W. All models of satellite-derived phenology are wrong, but some are useful: A case study from northern Australia. Int. J. Appl. Earth Obs. Geoinf. 2021, 97, 102285. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Evans, F.H.; Shen, J. Spatially weighted estimation of broadacre crop growth improves gap-filling of Landsat NDVI. Remote Sens. 2021, 13, 2128. [Google Scholar] [CrossRef]
- Shen, J.; Evans, F.H. The Potential of Landsat NDVI Sequences to Explain Wheat Yield Variation in Fields in Western Australia. Remote Sens. 2021, 13, 2202. [Google Scholar] [CrossRef]
- Gräler, B.; Pebesma, E.; Heuvelink, G. Spatio-temporal interpolation using gstat. R J. 2016, 8, 204–218. [Google Scholar] [CrossRef]
- Pebesma, E.J. Multivariable geostatistics in S: The gstat package. Comput. Geosci. 2004, 30, 683–691. [Google Scholar] [CrossRef]
- Chen, K.; O’Leary, R.A.; Evans, F.H. A simple and parsimonious generalised additive model for predicting wheat yield in a decision support tool. Agric. Syst. 2019, 173, 140–150. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 5 July 2019).
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Proceedings of the Second International Symposium on Information Theory, Tsahkadsor, Armenia, 2–8 September 1971; pp. 267–281. [Google Scholar]
- Pinheiro, J.; Bates, B. Mixed-Effects Models in S and S-PLUS; Springer Science Business Media: New York, NY, USA, 2004. [Google Scholar]
- Zuur, A.F.; Ieno, E.N.; Walker, N.J.; Savelievv, A.A.; Smith, G.M. Mixed Effects Models and Extensions in Ecology with R; Springer: New York, NY, USA, 2009. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 2015, 67. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Generalized Additive Models; Chapman and Hall: London, UK, 1990. [Google Scholar] [CrossRef]
- Wood, S.N. Generalized Additive Models: An Introduction with R; Chapman and Hall: London, UK, 2006. [Google Scholar] [CrossRef]
- Marra, G.; Wood, S.N. Practical variable selection for generalized additive models. Comput. Stat. Data Anal. 2011, 55, 2372–2387. [Google Scholar] [CrossRef]
- Wood, S.N. Thin plate regression splines. J. R. Stat. Soc. Ser. B 2003, 65, 95–114. [Google Scholar] [CrossRef]
- Wood, S.N. Stable and efficient multiple smoothing parameter estimation for generalized additive models. J. Am. Stat. Assoc. 2004, 99, 673–686. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.; Golowich, S.E.; Smola, A.J. Support vector method for function approximation, regression estimation, and signal processing. Adv. Neural Inf. Process. Syst. 1997, 9, 281–287. [Google Scholar]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. Kernlab—An S4 Package for Kernel Methods in R. J. Stat. Softw. 2004, 11. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, I.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems; Software available from tensorflow.org; TensorFlow: Mountain View, CA, USA, 2015. [Google Scholar]
- Allaire, J.J.; Chollet, F. Keras: R Interface to ‘Keras’. Available online: https://keras.rstudio.com (accessed on 5 February 2021).
- Evans, F.H.; Guthrie, M.M.; Foster, I. Accuracy of six years of operational statistical seasonal forecasts of rainfall in Western Australia (2013 to 2018). Atmos. Res. 2020, 233, 104697. [Google Scholar] [CrossRef]
- Brown, J.N.; Hochman, Z.; Holzworth, D.; Horan, H. Seasonal climate forecasts provide more definitive and accurate crop yield predictions. Agric. For. Meteorol. 2018, 260, 247–254. [Google Scholar] [CrossRef]
- Kouadio, L.; Newlands, N.; Davidson, A.; Zhang, Y.; Chipanshi, A. Assessing the Performance of MODIS NDVI and EVI for Seasonal Crop Yield Forecasting at the Ecodistrict Scale. Remote Sens. 2014, 6, 10193–10214. [Google Scholar] [CrossRef] [Green Version]
- Franch, B.; Vermote, E.F.; Becker-Reshef, I.; Claverie, M.; Huang, J.; Zhang, J.; Justice, C.; Sobrino, J.A. Improving the timeliness of winter wheat production forecast in the United States of America, Ukraine and China using MODIS data and NCAR Growing Degree Day information. Remote Sens. Environ. 2015, 161, 131–148. [Google Scholar] [CrossRef]
- Huang, J.; Gómez-Dans, J.L.; Huang, H.; Ma, H.; Wu, Q.; Lewis, P.E.; Liang, S.; Chen, Z.; Xue, J.-H.; Wu, Y.; et al. Assimilation of remote sensing into crop growth models: Current status and perspectives. Agric. For. Meteorol. 2019, 276–277, 107609. [Google Scholar] [CrossRef]
- Skakun, S.; Vermote, E.; Franch, B.; Roger, J.-C.; Kussul, N.; Ju, J.; Masek, J. Winter Wheat Yield Assessment from Landsat 8 and Sentinel-2 Data: Incorporating Surface Reflectance, through Phenological Fitting, into Regression Yield Models. Remote Sens. 2019, 11, 1768. [Google Scholar] [CrossRef] [Green Version]
- Bolton, D.K.; Gray, J.M.; Melaas, E.K.; Moon, M.; Eklundh, L.; Friedl, M.A. Continental-scale land surface phenology from harmonized Landsat 8 and Sentinel-2 imagery. Remote Sens. Environ. 2020, 240, 111685. [Google Scholar] [CrossRef]
- Gao, F.; Anderson, M.C.; Zhang, X.; Yang, Z.; Alfieri, J.G.; Kustas, W.P.; Mueller, R.; Johnson, D.M.; Prueger, J.H. Toward mapping crop progress at field scales through fusion of Landsat and MODIS imagery. Remote Sens. Environ. 2017, 188, 9–25. [Google Scholar] [CrossRef] [Green Version]
- Walker, J.J.; de Beurs, K.M.; Wynne, R.H. Dryland vegetation phenology across an elevation gradient in Arizona, USA, investigated with fused MODIS and Landsat data. Remote Sens. Environ. 2014, 144, 85–97. [Google Scholar] [CrossRef]
- Zhou, F.; Zhong, D. Kalman filter method for generating time-series synthetic Landsat images and their uncertainty from Landsat and MODIS observations. Remote Sens. Environ. 2020, 239, 111628. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Number of Wheat Paddocks | Area of Wheat Grown (ha) | Growing Season Rainfall (mm) |
|---|---|---|---|
| 2003 | 7 | 629 | 327 |
| 2004 | 18 | 1812 | 265 |
| 2005 | 23 | 2028 | 264 |
| 2006 | 17 | 1572 | 270 |
| 2007 | 9 | 932 | 178 |
| 2008 | 10 | 722 | 275 |
| 2009 | 43 | 4284 | 225 |
| 2010 | 31 | 2549 | 141 |
| 2011 | 28 | 2364 | 353 |
| 2012 | 35 | 3168 | 178 |
| 2013 | 32 | 3176 | 275 |
| 2014 | 31 | 2695 | 215 |
| 2015 | 36 | 2674 | 224 |
| 2016 | 29 | 2554 | 284 |
| 2017 | 30 | 2868 | 218 |
| 2018 | 30 | 2849 | 235 |
| 2019 | 17 | 1385 | 171 |
| Predictor Set | Metrics |
|---|---|
| PM | SOST, POST, EOST, POSV, VLAD, GLAD |
| PM + SCM | SOST, POST, EOST, POSV, VLAD, GLAD, AWavail, VR, GR, VDD, GDD |
| Metric | Metric Type | R | Mean Annual R |
|---|---|---|---|
| SOST | PM | −0.23 | −0.10 |
| POST | PM | −0.03 | −0.12 |
| EOST | PM | 0.32 | 0.08 |
| POSV | PM | 0.34 | 0.36 |
| iNDVI | PM | 0.56 | 0.45 |
| VLAD | PM | 0.49 | 0.33 |
| GLAD | PM | 0.41 | 0.36 |
| AWavail | SCM | 0.64 | 0.12 |
| GSR | SCM | 0.50 | 0.12 |
| VR | SCM | 0.39 | 0.08 |
| GR | SCM | 0.31 | 0.10 |
| GSDD | SCM | 0.29 | 0.08 |
| VDD | SCM | 0.19 | 0.02 |
| GDD | SCM | 0.24 | 0.13 |
| Model | Predictors | MAE (t ha−1) | RMSE (t ha−1) | NRMSE | Timing | |
|---|---|---|---|---|---|---|
| MLR | PM | 0.39 | 0.37 | 0.45 | 0.35 | 1 s |
| PM + SCM | 0.56 | 0.30 | 0.38 | 0.30 | 5 s | |
| LMM | PM | 0.67 | 0.25 | 0.33 | 0.26 | 10 s |
| PM + SCM | 0.68 | 0.25 | 0.33 | 0.25 | 17 s | |
| GAM | PM | 0.44 | 0.34 | 0.43 | 0.33 | 34 s |
| PM + SCM | 0.65 | 0.26 | 0.34 | 0.27 | 80 s | |
| RF | PM | 0.48 | 0.32 | 0.41 | 0.32 | 3 m 5 s |
| PM + SCM | 0.66 | 0.26 | 0.34 | 0.26 | 3 m 42 s | |
| SVR | PM | 0.49 | 0.31 | 0.41 | 0.32 | 3 h 58 m 30 s |
| PM + SCM | 0.68 | 0.25 | 0.32 | 0.25 | 4 h 18 m 6 s | |
| DL | PM | 0.51 | 0.31 | 0.40 | 0.31 | 11 m 20 s |
| PM + SCM | 0.68 | 0.25 | 0.32 | 0.25 | 13 m 13 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evans, F.H.; Shen, J. Long-Term Hindcasts of Wheat Yield in Fields Using Remotely Sensed Phenology, Climate Data and Machine Learning. Remote Sens. 2021, 13, 2435. https://doi.org/10.3390/rs13132435
Evans FH, Shen J. Long-Term Hindcasts of Wheat Yield in Fields Using Remotely Sensed Phenology, Climate Data and Machine Learning. Remote Sensing. 2021; 13(13):2435. https://doi.org/10.3390/rs13132435
Chicago/Turabian StyleEvans, Fiona H., and Jianxiu Shen. 2021. "Long-Term Hindcasts of Wheat Yield in Fields Using Remotely Sensed Phenology, Climate Data and Machine Learning" Remote Sensing 13, no. 13: 2435. https://doi.org/10.3390/rs13132435