Residual Augmented Attentional U-Shaped Network for Spectral Reconstruction from RGB Images



Abstract
:1. Introduction
- We propose a novel RA2UN network constituted of several DIRB blocks instead of paired plain convolutional units for SR, which can extract increasingly abstract feature representations through powerful residual learning. Experimental results on four established benchmarks demonstrate that the proposed RA2UN network outperforms the state-of-the-art SR methods under quantitative measurements and perceptual comparison.
- A trainable SAA module is developed to bridge the encoder and decoder to emphasize the features in the informative regions selectively, which can strengthen the interaction and fusion between the low-level and high-level features effectively and further boost the spatial feature representations.
- To model interdependencies among channels of intermediate feature maps, we present a novel CAA module embedded in the DIRB to adaptively recalibrate channel-wise feature responses and enhance residual learning by using first-order and second-order statistics for stronger feature expression.
- A boundary-aware constraint is established to guide the network to focus on the salient edge information, which is helpful to alleviate spectral aliasing at the edge position and preserve more accurate high-frequency details.
2. Materials and Methods
2.1. The Proposed RA2UN Network
2.2. Spatial Augmented Attention Module
2.3. Channel Augmented Attention Module
2.4. Boundary-Aware Constraint
3. Experiments Setting
3.1. Datasets and Implementations
3.2. Evaluation Metrics
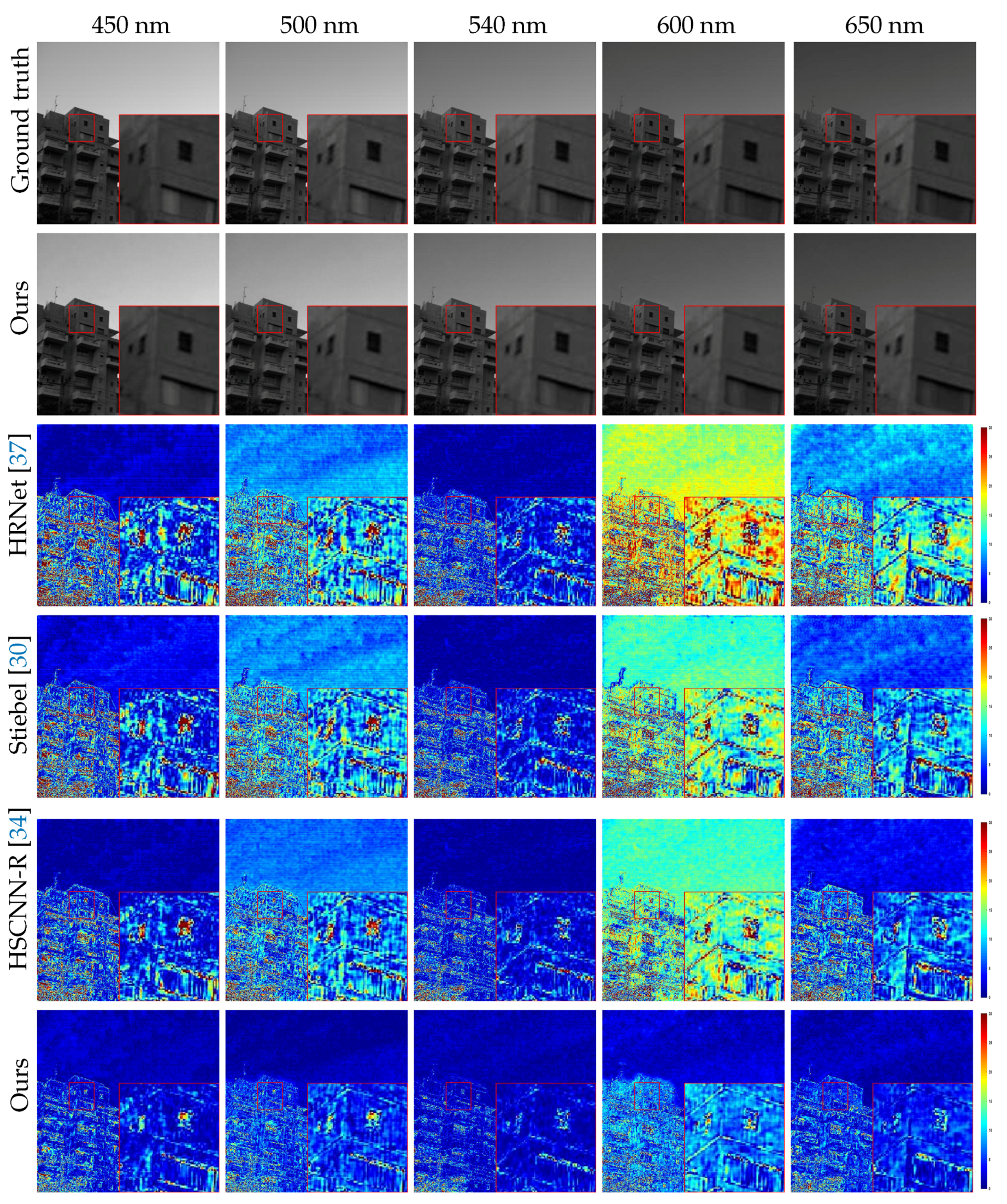
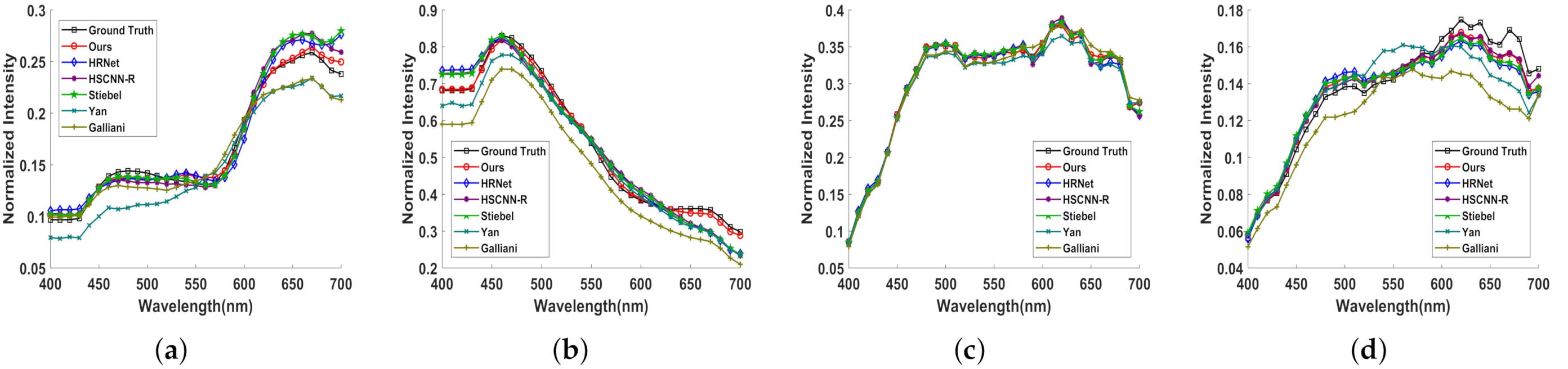
4. Experimental Results and Discussions
4.1. Discussion on the Proposed RA2UN: Ablation Study
4.2. Results of SR and Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chang, C.I. Hyperspectral Data Exploitation: Theory and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Uzair, M.; Mahmood, A.; Mian, A. Hyperspectral face recognition with spatiospectral information fusion and PLS regression. IEEE Trans. Image Process. 2015, 24, 1127–1137. [Google Scholar] [CrossRef]
- Li, J.; Xi, B.; Du, Q.; Song, R.; Li, Y.; Ren, G. Deep Kernel Extreme-Learning Machine for the Spectral–Spatial Classification of Hyperspectral Imagery. Remote Sens. 2018, 10, 2036. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral image classification with imbalanced data based on orthogonal complement subspace projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Tochon, G.; Chanussot, J.; Dalla Mura, M.; Bertozzi, A.L. Object tracking by hierarchical decomposition of hyperspectral video sequences: Application to chemical gas plume tracking. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4567–4585. [Google Scholar] [CrossRef]
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- James, J. Spectrograph Design Fundamentals; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Schechner, Y.Y.; Nayar, S.K. Generalized mosaicing: Wide field of view multispectral imaging. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1334–1348. [Google Scholar] [CrossRef] [Green Version]
- Wagadarikar, A.; John, R.; Willett, R.; Brady, D. Single disperser design for coded aperture snapshot spectral imaging. Appl. Opt. 2008, 47, B44–B51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tanriverdi, F.; Schuldt, D.; Thiem, J. Dual snapshot hyperspectral imaging system for 41-band spectral analysis and stereo reconstruction. In Proceedings of the International Symposium on Visual Computing, Lake Tahoe, NV, USA, 7–9 October 2019; pp. 3–13. [Google Scholar]
- Beletkaia, E.; Pozo, J. More Than Meets the Eye: Applications enabled by the non-stop development of hyperspectral imaging technology. PhotonicsViews 2020, 17, 24–26. [Google Scholar] [CrossRef]
- Descour, M.; Dereniak, E. Computed-tomography imaging spectrometer: Experimental calibration and reconstruction results. Appl. Opt. 1995, 34, 4817–4826. [Google Scholar] [CrossRef] [PubMed]
- Vandervlugt, C.; Masterson, H.; Hagen, N.; Dereniak, E.L. Reconfigurable liquid crystal dispersing element for a computed tomography imaging spectrometer. In Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6565. [Google Scholar]
- Wagadarikar, A.A.; Pitsianis, N.P.; Sun, X.; Brady, D.J. Video rate spectral imaging using a coded aperture snapshot spectral imager. Opt. Express 2009, 17, 6368–6388. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, R.M.; Prasad, D.K.; Brown, M.S. Training-based spectral reconstruction from a single RGB image. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 186–201. [Google Scholar]
- Robles-Kelly, A. Single image spectral reconstruction for multimedia applications. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, QLD, Australia, 26–30 October 2015; pp. 251–260. [Google Scholar]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural RGB images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 19–34. [Google Scholar]
- Jia, Y.; Zheng, Y.; Gu, L.; Subpa-Asa, A.; Lam, A.; Sato, Y.; Sato, I. From RGB to spectrum for natural scenes via manifold-based mapping. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4705–4713. [Google Scholar]
- Aeschbacher, J.; Wu, J.; Timofte, R. In defense of shallow learned spectral reconstruction from RGB images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 471–479. [Google Scholar]
- Zhang, S.; Wang, L.; Fu, Y.; Zhong, X.; Huang, H. Computational Hyperspectral Imaging Based on Dimension-Discriminative Low-Rank Tensor Recovery. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Li, J.; Cui, R.; Li, B.; Song, R.; Li, Y.; Dai, Y.; Du, Q. Hyperspectral Image Super-Resolution by Band Attention Through Adversarial Learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4304–4318. [Google Scholar] [CrossRef]
- Li, J.; Cui, R.; Li, B.; Song, R.; Li, Y.; Du, Q. Hyperspectral Image Super-Resolution with 1D–2D Attentional Convolutional Neural Network. Remote Sens. 2019, 11, 2859. [Google Scholar] [CrossRef] [Green Version]
- Galliani, S.; Lanaras, C.; Marmanis, D.; Baltsavias, E.; Schindler, K. Learned spectral super-resolution. arXiv 2017, arXiv:1703.09470. [Google Scholar]
- Rangnekar, A.; Mokashi, N.; Ientilucci, E.; Kanan, C.; Hoffman, M. Aerial spectral super-resolution using conditional adversarial networks. arXiv 2017, arXiv:1712.08690. [Google Scholar]
- Xiong, Z.; Shi, Z.; Li, H.; Wang, L.; Liu, D.; Wu, F. Hscnn: Cnn-based hyperspectral image recovery from spectrally undersampled projections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 518–525. [Google Scholar]
- Yan, Y.; Zhang, L.; Li, J.; Wei, W.; Zhang, Y. Accurate spectral super-resolution from single RGB image using multi-scale CNN. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; pp. 206–217. [Google Scholar]
- Fu, Y.; Zhang, T.; Zheng, Y.; Zhang, D.; Huang, H. Joint Camera Spectral Sensitivity Selection and Hyperspectral Image Recovery. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 788–804. [Google Scholar]
- Nie, S.; Gu, L.; Zheng, Y.; Lam, A.; Ono, N.; Sato, I. Deeply Learned Filter Response Functions for Hyperspectral Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4767–4776. [Google Scholar]
- Arad, B.; Ben-Shahar, O.; Timofte, R. Ntire 2018 challenge on spectral reconstruction from RGB images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 929–938. [Google Scholar]
- Stiebel, T.; Koppers, S.; Seltsam, P.; Merhof, D. Reconstructing spectral images from RGB-images using a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 948–953. [Google Scholar]
- Can, Y.B.; Timofte, R. An efficient CNN for spectral reconstruction from RGB images. arXiv 2018, arXiv:1804.04647. [Google Scholar]
- Alvarez-Gila, A.; van de Weijer, J.; Garrote, E. Adversarial networks for spatial context-aware spectral image reconstruction from RGB. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 480–490. [Google Scholar]
- Koundinya, S.; Sharma, H.; Sharma, M.; Upadhyay, A.; Manekar, R.; Mukhopadhyay, R.; Karmakar, A.; Chaudhury, S. 2D–3D cnn based architectures for spectral reconstruction from RGB images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 844–851. [Google Scholar]
- Shi, Z.; Chen, C.; Xiong, Z.; Liu, D.; Wu, F. Hscnn+: Advanced cnn-based hyperspectral recovery from RGB images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 939–947. [Google Scholar]
- Arad, B.; Timofte, R.; Ben-Shahar, O.; Lin, Y.T.; Finlayson, G.D. Ntire 2020 challenge on spectral reconstruction from an RGB image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 446–447. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Li, Y.; Liu, F. Adaptive weighted attention network with camera spectral sensitivity prior for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 462–463. [Google Scholar]
- Zhao, Y.; Po, L.M.; Yan, Q.; Liu, W.; Lin, T. Hierarchical regression network for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 422–423. [Google Scholar]
- Peng, H.; Chen, X.; Zhao, J. Residual pixel attention network for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 486–487. [Google Scholar]
- Joslyn Fubara, B.; Sedky, M.; Dyke, D. RGB to Spectral Reconstruction via Learned Basis Functions and Weights. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 480–481. [Google Scholar]
- Banerjee, A.; Palrecha, A. MXR-U-Nets for Real Time Hyperspectral Reconstruction. arXiv 2020, arXiv:2004.07003. [Google Scholar]
- Nathan, D.S.; Uma, K.; Vinothini, D.S.; Bama, B.S.; Roomi, S. Light Weight Residual Dense Attention Net for Spectral Reconstruction from RGB Images. arXiv 2020, arXiv:2004.06930. [Google Scholar]
- Kaya, B.; Can, Y.B.; Timofte, R. Towards spectral estimation from a single RGB image in the wild. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 3546–3555. [Google Scholar]
- Zhang, L.; Lang, Z.; Wang, P.; Wei, W.; Liao, S.; Shao, L.; Zhang, Y. Pixel-Aware Deep Function-Mixture Network for Spectral Super-Resolution. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 12821–12828. [Google Scholar]
- Hang, R.; Li, Z.; Liu, Q.; Bhattacharyya, S.S. Prinet: A Prior Driven Spectral Super-Resolution Network. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Xie, W.; Ge, C.; Li, B.; Li, Y. Hybrid 2-D-3-D Deep Residual Attentional Network With Structure Tensor Constraints for Spectral Super-Resolution of RGB Images. IEEE Trans. Geosci. Remote Sens. 2020, 1–15. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Dai, T.; Zha, H.; Jiang, Y.; Xia, S.T. Image Super-Resolution via Residual Block Attention Networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Xia, B.N.; Gong, Y.; Zhang, Y.; Poellabauer, C. Second-order non-local attention networks for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 3760–3769. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3186–3195. [Google Scholar]
- Zuniga, O.A.; Haralick, R.M. Integrated directional derivative gradient operator. IEEE Trans. Syst. Man, Cybern. 1987, 17, 508–517. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Layer | Encoding Parts | Decoding Parts | ||
|---|---|---|---|---|---|
| Kernels | Output Size | Kernels | Output Size | ||
| 1 | Conv | ||||
| 2 | DIRB-1 | ||||
| 3 | DIRB-2 | ||||
| 4 | DIRB-3 | ||||
| 5 | DIRB-4 | ||||
| 6 | DIRB-5 | ||||
| 7 | Bottom | ———— | ———— | ||
| Description | ||||||||
|---|---|---|---|---|---|---|---|---|
| SAA Module | ✘ | ✔ | ✘ | ✘ | ✔ | ✔ | ✘ | ✔ |
| CAA Module | ✘ | ✘ | ✔ | ✘ | ✔ | ✘ | ✔ | ✔ |
| Boundary-aware Loss | ✘ | ✘ | ✘ | ✔ | ✘ | ✔ | ✔ | ✔ |
| MRAE (↓) | 0.03668 | 0.03637 | 0.03396 | 0.03636 | 0.03362 | 0.03590 | 0.03381 | 0.03303 |
| Method | Clean | Real World | ||||
|---|---|---|---|---|---|---|
| MRAE (↓) | RMSE (↓) | SAM (↓) | MRAE (↓) | RMSE (↓) | SAM (↓) | |
| Ours | 0.03446 | 0.01158 | 2.39933 | 0.06554 | 0.01712 | 3.35699 |
| Stiebel [30] | 0.04008 | 0.01518 | 2.73916 | 0.07141 | 0.01912 | 3.68491 |
| HSCNN-R [34] | 0.04406 | 0.01543 | 2.94031 | 0.07039 | 0.01893 | 3.60987 |
| HRNet [37] | 0.04202 | 0.01575 | 2.83058 | 0.07042 | 0.02035 | 3.71418 |
| Yan [26] | 0.10351 | 0.02844 | 4.90422 | 0.09942 | 0.03005 | 4.54294 |
| Galliani [23] | 0.07949 | 0.02788 | 4.52770 | 0.10794 | 0.03307 | 4.79334 |
| Arad [17] | 0.07873 | 0.03305 | 5.57166 | ——— | ——— | ——— |
| Method | Clean | Real World | ||||
|---|---|---|---|---|---|---|
| MRAE (↓) | RMSE (↓) | SAM (↓) | MRAE (↓) | RMSE (↓) | SAM (↓) | |
| Ours | 0.01141 | 10.4923 | 0.80815 | 0.02868 | 22.0813 | 1.52763 |
| HSCNN-R [34] | 0.01330 | 12.8519 | 0.96004 | 0.03014 | 23.5697 | 1.65147 |
| HRNet [37] | 0.01369 | 13.5165 | 1.00645 | 0.02905 | 22.8282 | 1.57253 |
| Stiebel [30] | 0.01536 | 15.5253 | 1.14655 | 0.03118 | 24.0600 | 1.70200 |
| Yan [26] | 0.03036 | 24.2971 | 1.67274 | 0.04576 | 31.8332 | 2.18224 |
| Galliani [23] | 0.05130 | 37.6802 | 1.77410 | 0.07749 | 49.2496 | 2.32531 |
| Arad [17] | 0.08094 | 59.4085 | 5.02125 | ——— | ——— | ——— |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wu, C.; Song, R.; Li, Y.; Xie, W. Residual Augmented Attentional U-Shaped Network for Spectral Reconstruction from RGB Images. Remote Sens. 2021, 13, 115. https://doi.org/10.3390/rs13010115
Li J, Wu C, Song R, Li Y, Xie W. Residual Augmented Attentional U-Shaped Network for Spectral Reconstruction from RGB Images. Remote Sensing. 2021; 13(1):115. https://doi.org/10.3390/rs13010115
Chicago/Turabian StyleLi, Jiaojiao, Chaoxiong Wu, Rui Song, Yunsong Li, and Weiying Xie. 2021. "Residual Augmented Attentional U-Shaped Network for Spectral Reconstruction from RGB Images" Remote Sensing 13, no. 1: 115. https://doi.org/10.3390/rs13010115