1. Introduction
In light of the continuously increasing number of satellites acquiring images of the Earth, data fusion is becoming a key research topic in the remote sensing domain allowing for cross-sensor [
1,
2], cross-resolution [
3] or cross-temporal [
4] analysis and information extraction. Due to technological constraints many satellite systems for Earth observation, think of GeoEye, Plaiades or WorldView, to name a few, provide a single full-resolution panchromatic band, responsible to preserve geometrical information, together with a multispectral image at lower spatial resolution, aligned with the PAN, which gathers spectral information. A multi-resolution fusion process referred to as pansharpening is therefore often employed to merge these components in order to raise the multispectral (MS) resolution to that of the PAN component [
3,
5].
Pansharpening is a challenging task, far from being solved, also because of the continuously increasing resolutions at which new generation satellites operate. The majority of the traditional approaches fall in two main categories. The former is known as component substitution (CS) [
6] and refers to a paradigm that shifts the multispectral component in a suitable transformed domain where the panchromatic band is used to replace one of the transformed bands before an inverse transform brings them back to the original domain. Under the restriction that only three bands are concerned, the Intensity-Hue-Saturation (IHS) transform can be used, with the intensity component replaced by the panchromatic band [
7]. Such approach has been generalized in Reference [
8] (GIHS) to handle a larger number of bands. Many other transforms have been considered for CS, for example, the principal component analysis [
9], the Brovey transform [
10] and the Gram-Schmidt (GS) decomposition [
11]. More recently, adaptive CS methods have also been introduced, such as the advanced versions of GIHS and GS adopted in Reference [
12], the partial substitution method (PRACS) proposed in Reference [
13], or the optimization-based technique of Reference [
14]. The second category, referred to as multiresolution analysis (MRA) [
15], addresses the pansharpening problem from the spatial perspective. In particular, MRA methods resort to the extraction of high frequency spatial details using a prior multiresolution decomposition such as decimated or undecimated Wavelet transforms [
15,
16,
17,
18], Laplacian pyramids [
5,
19,
20,
21,
22], or other nonseparable transforms such as contourlet [
23], and so forth. Extracted details are then properly injected into the resized MS component. A comprehensive review of these two categories can be found in Reference [
3]. Other methods do not fit with the above mentioned categories and are better cast as statistical [
24,
25,
26,
27,
28,
29], variational [
30,
31], or dictionary-based [
32,
33,
34,
35,
36,
37]. In addition, it is also worth mentioning the matrix factorization approaches, examples are References [
38,
39,
40], which are more suited to the fusion of low resolution hyperspectral images with high resolution multispectral ones. In this case, in fact, the spectral variability becomes a serious concern to be handled carefully by means of unmixing oriented methodologies [
41,
42,
43].
In 2012 Krizhevsky et al. have presented a seminal work [
44] that has revolutionized the computer vision research domain. For the first time, they succeeded to train a very deep artificial neural network for classification, showing impressive results on a very challenging dataset (ImageNet). Since then many other vision tasks have been successfully addressed by means of deep learning methods. Notable examples are image segmentation [
45,
46], super-resolution [
47,
48] or object detection [
49], to mention a few. Needless to say, this paradigm shift from model-based to data-driven approaches is involving many related research fields, including remote sensing [
50,
51,
52,
53]. In particular, to the best of our knowledge, the first pansharpening method relying on the use of a convolutional neural network (CNN), named PNN, was proposed in 2016 by Masi et al. [
54] and followed by other similar works in a short time [
50,
55,
56,
57,
58,
59].
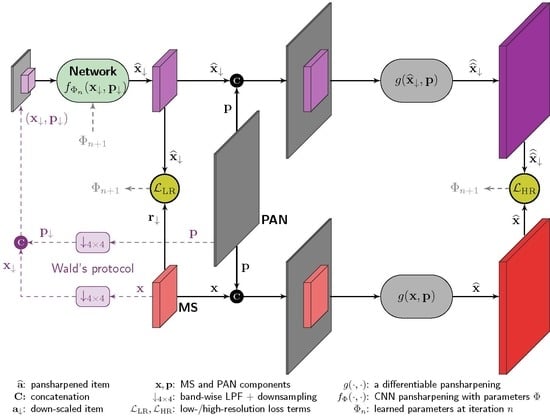
Due to the lack of ideally pansharpened samples to be used for training, the above mentioned deep learning (DL) methods resort to an automatic synthesis process to generate reference samples from unlabeled real data. In particular, the PAN-MS training samples undergo a resolution downgrading process in order for the original MS to play as target reference, since the reduced-resolution PAN-MS pair can be used as corresponding input. By doing so, the network is trained in a lower-resolution domain relying upon the assumption that it will generalize properly when applied in the target full-resolution domain. In this regard the resolution downgrade process plays a critical role. In essence it amounts to a band-wise antialiasing low-pass filtering (LPF) followed by a subsampling. In our previous work [
54,
60,
61] we resorted to Wald’s protocol [
62], a well-established procedure for accuracy assessment of pansharpening methods, that makes use of antialiasing LPFs mimicking the sensor modulation transfer functions (MTF) for an unbiased problem scaling. Unfortunately, even with an accurate scaling of the training images, an information gap exists between scales. Put in simpler words, objects whose typical size amounts to a few pixels in the original resolution space may never be rescaled without loosing their shape in the reduced resolution domain. Hence, there will be no hope for any network to “experience” such tiny geometries by training on rescaled datasets generated as described above. As a result, the trained networks usually behave pretty well in the reduced-resolution space, outperforming with a considerable gain conventional model-based approaches, whereas a less evident gain is observed at full-resolution [
50,
54,
55,
61].
On the basis of the above observations, in this work we propose a training framework that involves also the full-resolution PAN component that, once rescaled, is simply discarded in the previous solutions. Such an integration is achieved by means of a joint low- and high-resolution loss that involves, in the computation of high-resolution loss component, a model-based MRA pansharpening method [
20] with good spatial properties. The proposed learning framework is tested on our recently proposed advanced version of PNN [
61], hereinafter referred to as A-PNN. In summary, the contributions of this paper are the following:
- i.
a new target-adaptive CNN-model for pansharpening with improved capacity at full-resolution;
- ii.
a new general learning framework for CNN-based pansharpening that enforces cross-scale consistency;
- iii.
an extensive experimental validation for the proposed approach, using two different sensors and a wide variety of comparative solutions, both classical and deep learning.
The rest of the paper is organized as follows.
Section 2 introduces the datasets used for training, validation and test, and presents the proposed solution.
Section 3 describes the evaluation framework, gathers comparative methods and presents numerical and visual experimental results with related discussion.
Section 4 presents further experimental analyses, while
Section 5 provides concluding remarks.
3. Experimental Validation
In this section, first we will briefly recall the accuracy evaluation metrics employed (
Section 3.1) and the comparative methods (
Section 3.2), then we will provide and discuss numerical and visual results (
Section 3.3).
3.1. Accuracy Metrics
The numerical assessment of pansharpening methods is commonly carried out on two resolution levels [
3]: the target, or full, resolution level corresponding to the actual resolution of the dataset at hand, and the reduced resolution level obtained by scaling the data with a factor
R (PAN-MS resolution ratio) resorting to Wald’s protocol [
62]. In the full-resolution framework only qualitative measurements (no-reference indexes) are usually possible because of the lack of ground-truth images (ideally pansharpened references). As a consequence, in order to compute objective error measurements (reference-based indexes) it is customary to use Wald’protocol and work in the reduced resolution domain, where the original MS component plays as ground-truth. On the other hand, in addition to the numerical assessment it is always useful to visually inspect sample results at both scales to detect local artefacts that may not be recognized by globally averaged measurements.
In particular, we will make use of the following reference-based metrics in the reduced resolution space:
Universal Image Quality Index (
Q-index) which takes into account three different components: correlation coefficient, mean luminance distance and contrast [
67].
Erreur Relative Globale Adimensionnelle de Synthése (
ERGAS) which measures the overall radiometric distortion between two images [
68].
Spectral Angle Mapper (
SAM) which measures the spectral divergence between images by averaging the pixel-wise angle between spectral signatures [
69].
Q4/
Q8, a 4/8 bands extension of the universal image quality index [
70].
On the other hand, the no-reference indexes employed in full-resolution framework will be the following [
3,
71]:
Quality No-Reference (QNR) index, is a combination of two indexes that take into account spatial and spectral distortions, DS and D, respectively:
- –
Spectral Distortion (D), measures the distance of the bands correlation between and .
- –
Spatial Distortion (D), measures the spatial consistency between the and .
For further details about the definition of the above indexes the Reader is referred to the corresponding references.
3.2. Compared Methods
Traditional approaches to pansharpening include component substitution, multiresolution analysis, statistical or variational approaches and other hybrid solutions. A critical survey on these methods can be found in [
3]. On the other hand, many deep learning solutions have been proposed in the last years. In this work we compare the proposed method with both traditional and deep learning methods. In particular we have selected the methods listed in
Table 4 that are representative examples of these groups.
3.3. Results and Discussion
According with
Table 2 we compare our solution on two test datasets, Caserta-GE1-C and Washington-WV2, each composed of fifteen image samples whose MS (PAN) component is 320 × 320 (1280 × 1280) pixels wide. The corresponding samples in the reduced resolution evaluation framework will therefore have size 80 × 80 (320 × 320) pixels.
Let us start with the numerical results obtained at both full and reduced resolutions which are gathered in
Table 5 for the GeoEye-1 dataset and in
Table 6 for the WorldView-2 images. Each number is the average value over the related fifteen samples. Among the model-based approaches, PRACS and C-BDSD provide the best performance in the full resolution framework on GeoEye-1 and WorldView-2 datasets, respectively. However, the latter provides also fairly good results in the reduced resolution context. Such a good trade-off between reference-based and no-reference accuracies is also a feature of BDSD on GeoEye-1 images. On the other hand, according to the objective error measurements at reduced resolution, MTF-GLP-HPM provides a superior performance which is consistent over the different indicators and datasets.
Moving to deep learning methods, our baseline, A-PNN and the proposed method get the best overall performance considering both no-reference and reference-based assessments, and for both datasets. In particular, the proposal provides the highest accuracy in the full resolution framework (the QNR is the main indicator to look at, which summarizes spatial and spectral fidelity) while A-PNN performs generally better according to reference-based indicators. This relative positioning of the proposal with respect to A-PNN is coherent with the proposed loss which balances reduced-resolution and full-resolution costs in order to provide cross-scale consistency. Between the two remaining deep learning solutions, DRPNN outperforms PanNet which seem to suffer on our datasets, whereas it provides better scores on other datasets [
50]. This performance variability of deep learning methods with respect to the dataset was investigated in Reference [
61] and motivates further the use of target-adaptive schemes such as A-PNN and the proposal. Overall, with the exception of A-PNN and proposal which outperform consistently all methods, the gap between deep learning methods and the others is not always clear-cut.
For a more comprehensive evaluation of the methods, a careful visual inspection of results is necessary besides numerical assessment, in order to study local patterns and visual artifacts that may not emerge from global averages. To this aim,
Figure 5 and
Figure 6 show some pansharpening results on crops from Caserta-GE1-C and Washington-WV2 images, respectively, at reduced resolution. In particular, for the sake of brevity, we limit the visual analysis to the methods that are more competitive and/or are related to our proposal. These are deep learning methods, MTF-GLP-HPM, which is also involved in the definition of the proposed loss and C-BDSD which is one of the best model-based approaches. For each of the stacked examples the target ground-truth is shown on the leftmost column, followed by the different pansharpening results, with the associated error map shown below. As it can be seen, PanNet introduces a rather visible spatial distortion on GeoEye-1 samples (
Figure 5), which is also present to a minor extent on WorldView-2 tiles (
Figure 6). This agrees with the reduced resolution numerical figures reported in
Table 5 and
Table 6. Although of less intensity, spatial distortions are also clearly visible for C-BDSD, DRPNN and MTF-GLP-HPM, which outperform PanNet at the reduced scale. On the other hand, coherently with the best performance shown in the reduced resolution frame, A-PNN provides the highest fidelity with a nearly zero error map. Finally, the proposed solution gets results that look close to A-PNN in some cases. Some variations in the error maps are also visible for our method which can be justified by the introduction of the additional loss term that operates in the full resolution space for cross-scale consistency.
With the help of
Figure 7 and
Figure 8, we can now analyze some results obtained at the target full resolution. Unfortunately, at this scale there are no reference images and all considerations are necessarily subjective. Ideally, a good pansharpening should be able to provide the spatial detail level of the PAN while keeping the spectral response of the ground objects according to the MS image. Therefore, in
Figure 7 and
Figure 8 we show the PAN and MS components as reference for each sample in the first two columns. Then, several compared pansharpening results are shown moving rightward. With the premises made above, we formulate the following observations.
Overall, the compared methods seem to provide quite similar performances on the GeoEye-1 dataset. Differences are therefore quite subtle and difficult to be noticed. In particular, C-BDSD, MTF-GLP-HPM and PanNet present a tendency to over-emphasize spatial details. This is particularly visible for PanNet which introduces also micro-textural patterns. Such a feature is somehow reflected in the spatial distortion indicator
D (
Table 5) which almost doubles for these three methods in comparison to the other selected methods. On the contrary, DRPNN results look too smooth, while A-PNN and the proposed method seem to give sharpness levels which are closer to that of the PAN image, with the proposed being sharper than A-PNN, as it can be seen in the last example.
On WorldView-2 images (
Figure 8) some of the above considerations still apply but are much easier to be seen. In particular, the smoothness of DRPNN, as well as the over-emphasis on spatial details of C-BDSD are clearly visible. Here, PanNet and MTF-GLP-HPM provide much better spatial descriptions, sharper for the former, smoother for the latter. Finally, A-PNN and the proposed method look in between PanNet and MTF-GLP-HPM in terms of spatial details. However, A-PNN presents a visible spectral distortion particularly evident on vegetated areas.
On the basis of the above discussion on numerical and visual results at both full and reduced resolution, we can conclude that A-PNN and its variant proposed in this work show the most robust behaviour across scales and sensors. Besides, we have to keep in mind that the evaluation of pansharpening methods is itself still an open problem, since objective error measurements are only possible at the reduced scale which is not the target one. For this reason, our goal was to improve the full resolution performance by means of a suitably defined cross-scale training process, although we had to suffer a slight loss in the reduced resolution framework. In contrast, we observed an improvement in both numerical and visual terms, reducing spectral distortions, in the case of WorldView-2, and spatial blur, for GeoEye-1. Moreover, the proposed solution can be easily generalized to different mappings (MTF-GLP-HPM, in this work) which do not necessarily need to be a pansharpening function. It could be, for example, any kind of differentiable detector or whatever feature extractor defined on multispectral images. In this last case one can adapt the pansharpening network to the user application.
4. Further Analyses
In this section we present complementary results for a more comprehensive evaluation of the proposed method. In particular, we provide three additional analyses: a comparison restricted to the DL methods where the fine-tuning is used for all, an ablation study for the proposal and an assessment of the computational burden.
In the previous section the proposed solution has been compared to both traditional and DL models. DL models have been taken already pre-trained as provided by the authors. Therefore, criticisms could be made of this approach to the comparison of DL models. In fact, in the computer vision community it is customary to fix both training and test datasets to ensure that all compared model access to the same information in the learning phase. Unfortunately, this way to proceed cannot always be extended to the remote sensing domain because of the restrive policies frequently occurring. This is also the case here. Of course, we could train from scratch on our datasets all compared models but this would open many issues such as “is our dataset properly sized to train others’ models?” Deeper networks, in fact, require larger datasets to avoid overfitting. Or, “is our training schedule suited to let others’ models converge properly?” Letting a DL model to “converge” toward a reasonably small loss is never an easy task and requires usually an extensive trial and error process. If this job is not carried out by the same authors that have conceived the model, who are confident with it, there is a high risk to penalize the model.
Aware of the above mentioned issues, we decided to make a further comparison by extending the fine-tuning stage to all DL solutions.
Table 7 gathers the numerical results obtained on the test images of GeoEye-1 and WorldView-2, at both resolutions. A-PNN and the proposed model have been already comparatively discussed in the previous section with the overall conclusion that the latter performs better in the full-resolution domain on both sensors. Moving to DRPNN and PanNet, observe first that all reduced resolution indexes register a large gain with respect to the non fine-tuned versions (compare with
Table 5 and
Table 6), particularly DRPNN on WorldView-2. This is perfectly in line with our expectations since the fine-tuning occurs on the reduced resolution test image. However, this comes at the cost of a large performance loss at full-resolution (except for PanNet on WorldView-2). Here, to have an idea, the QNR drops from about 0.91 to 0.87 for DRPNN on GeoEye-1. In essence, this reflects an overfitting of the models on the reduced-resolution samples, which is much heavier for deeper networks like DRPNN and PanNet. This phenomenon, which was also observed to a much smaller extent for A-PNN in the original work [
61], allows us to further appreciate the mitigating contribute of the full-resolution loss component
that acts as regularization term, keeping high accuracy levels at the target scale.
Besides, it is also worth to assess the marginal contribute of the two loss components involved in the proposed learning scheme. In
Table 8 the proposed model is compared with its ablated versions obtained training on a single loss term. As it can be seen, the use of the
component alone is sufficient to gain accuracy at full resolution, although it comes with a larger performance loss in the reduce-resolution frame. The joint optimization, instead, allows also to preserve to some extent the performance at reduced resolution.
Last but not least, a look to the computational burden allows us to have a complete picture of our proposal. To this aim we have run dedicated tests to quantify experimentally the computational time needed by each compared method on fixed hardware and image size (1280 × 1280 at PAN scale). In particular, we have considered both CPU and GPU equipped computers.
Table 9 summarizes the running time for DL methods, telling apart (within brackets) the additional contribute due to the fine-tuning. The other non-DL methods were tested on CPU only showing an execution time ranging from half a second (Indusion, GSA, BDSD) to about six seconds (ATWT-M3). As expected, due to their inherent complexity, deep learning methods are much slower than non-DL ones on CPU, with the fine-tuning phase responsible for the dominant cost. On the other hand, we can resort to parallel implementations for these methods and hence rely on the use of GPUs to save time. In particular, observe that two main aspects impact on complexity: the network size and the batch size for parameters training. Here, DRPNN and PanNet are much deeper than A-PNN and proposal. On the other hand, different from the others, the proposed model is trained using the full-resolution version of the target image, hence requiring a 16 times larger batch. This latter observation explains why the proposal, although sharing the same (relatively small) architecture of A-PNN, is computationally much more expensive. To conclude, we have also to underline that the focus of this work was on accuracy rather than on complexity. Therefore, there is a room left for improvement from the computational perspective, for example using cropping strategies to reduce the volume of the image to be used in fine-tuning, or resorting to mini-batch decompositions, since the current implementation relies on a single-batch optimization schedule.
5. Conclusions
In this work we have proposed an enhanced version of the CNN-based method A-PNN. This contribution comes with the introduction of a new learning scheme that can be straightforwardly extended to any CNN model for pansharpening. The new learning scheme involves loss terms computed at reduced and full resolutions, respectively, enforcing cross-scale consistency. Our experiments show a clear performance improvement over the single-scale training scheme in the full-resolution evaluation framework according to both numerical and visual assessments. This achievement is paid with an increased computational cost and a negligible accuracy loss in the reduced-scale domain, which is in principle not an issue in real-world practical applications as full-resolution images are concerned. Moreover, numerical and visual results confirm the superior accuracy levels achievable by DL-based solutions in comparison to traditional model-based approaches, with the proposed one being the best in the full-resolution evaluation framework, and its baseline A-PNN being the best in the reduced-resolution domain.
There is a room left for the improvement of the proposed learning scheme that is worth to explore in future work. First, the increased computational cost can be limited by means of a suitable cropping strategy aimed to reduce the volume of data to be processed. Second, different auxiliary fusion functions can be tested, which do not necessarily have to be pansharpening models. For example any application-oriented feature extractor which is differentiable (to allow gradient backpropagation) may also be used, allowing for an application-driven learning. Finally, needless to say, many different core CNN models can be tested in place of A-PNN.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}