1. Introduction
Benefiting from the significant advantage in spatial resolution, aerial images have opened up a new era in urban observation. However, with the increase in spatial resolution, the influence of shadows is increasingly prominent, particularly in urban areas as there are many tall standing objects such as buildings, towers, and trees. In shaded regions, the undesirable radiometric distortion resulting from sunlight blockage plays a negative role in image processing and analysis [
1]. For instance, it is hard to correctly distinguish a dark water body from shadows because they are both low-reflection [
2,
3], which reduces the accuracy of water mapping. On the other hand, shadows usually carry some helpful spatial semantic cues. The size, shape, and height of the associated obstacle can be obtained by analyzing the geometric attributes of shadows. Utilizing such information could contribute to building recognition, 3D reconstruction, and height estimation [
4,
5,
6]. Consequently, shadow processing is a crucial step for image analysis.
Over the past few years, shadow detection has drawn much scholarly attention. Reviewing the previous literature, existing shadow detection methods can be divided into four main categories: property-, model-, soft-shadow-, and machine-learning-based methods [
7,
8,
9,
10].
Because of their simplicity, both in principle and implementation, property-based methods including three subcategories: thresholding-, color-transformation-, and object segmentation-based, are widely reported. Considering that a shadow pixel usually has lower, even the lowest, intensity, thresholding-based methods obtain the final shadow map by thresholding the original image by using a set threshold, which is usually derived from the Otsu [
11] and bimodal histogram-splitting methods [
12,
13]. A prominent drawback to the methods is that it is rather difficult to obtain the optimal threshold, especially when the gray level distribution pattern of an input image does not present obvious bimodal distribution, resulting in lower accuracy. To improve performance, color-transformation-based methods were developed. For multiband images, the original image is first converted to the specifically invariant color space (e.g., HSV, C1, C2, C3, and CIELCh) [
14,
15,
16]. Several image indices were also developed to enlarge the contrast between shadows and non-shadows [
17,
18], e.g., the normalized saturation-value difference index [
19]. Then, shadows and non-shadows are distinguished by thresholding the converted shadow feature map. As the similarity of spectral characteristics between shadow and other dark non-shadow objects is very high, color-transformation-based methods cannot effectively separate shadows from dark non-shadows. Another weakness of the two types of methods is that additional postprocessing steps, as introduced in [
20], are usually required to eliminate the salt-and-pepper phenomenon and fill the remained holes, which limitedly improves accuracy. Motivated by the limitations of pixel-based property-based methods, object segmentation-based methods were applied to reduce the interference of dark non-shadow objects, and more accurately locate shadow boundaries [
21,
22]. However, the methods still exhibit limited ability to identify nonuniform shadows, particularly the shadows with high brightness.
Model-based methods require specific prior knowledge about the scene and sensor, such as topographic data, atmospheric conditions, and imaging parameters, to construct specific models for shadow detection. With this prior information, the methods can usually acquire reasonable results. Nevertheless, when this information is unavailable, they may fail. There are two typical model-based methods: geometrical and physics-based methods. The former uses digital-surface-model (DSM) data to compute the shade coverage on the basis of solar position throughout a strict mathematical method [
23,
24], and its accuracy is wholly reliant on the quality of the DSM data. The main bottleneck of geometrical methods for shadow detection in urban aerial images its high cost to yield the high-quality DSM data. On the basis of atmospheric and light conditions, physics-based methods employ the spectral information of each pixel to deduce the physical properties of the ground surface to recognize shadows [
25,
26]. Because of the complex principle, and because aerial images usually lack some specific spectral bands, these methods are rarely applied for aerial images.
For soft-shadow methods, the ultimate aim is to produce a shadow-probability map to visualize the possibility of each pixel belonging to a shadow. In contrast with a conventional binary shadow map, each pixel in the soft-shadow map is encoded by a probability value of each pixel belonging to a shadow. Specifically, if a pixel is in umbra, it should be assigned a value of 1; if a pixel belongs to a penumbra, it should be assigned a value between 0 and 1; otherwise, it should be assigned a value of 0. In this way, shadows, particularly the penumbras, are depicted and located more precisely. However, as described in the literature [
27,
28], when the size of an input image is large, not only does it need much manual intervention to label a large quantity of positive and negative samples to get a satisfactory matting result, but it would also be time-consuming to perform the detection procedure.
Regarding shadow detection as a binary classification task, machine learning-based methods often employ some typical learning-based classifiers such as perceptron classifiers [
29] and support vector machines (SVMs) [
30,
31] to label shadow and non-shadow pixels in an input image on the basis of handcrafted low-level visual features, such as brightness, texture, and color [
32]. Although it was proven that these methods can achieve good performance for images with simple scenes, a trained classifier may be left empty-handed when the scene of an image is complex, since the employed handcrafted features may vary with light conditions and shadow surfaces. Recently, with the success of deep convolutional neural networks (CNNs) in computer-vision tasks (e.g., object detection and image classification) [
33,
34,
35], researchers have also been taking advantage of CNNs to detect shadows. The research in [
36] first introduced a shadow detection method using deep learning technology. Two CNN networks were designed and trained to detect the shadow region and shadow boundary, respectively. Then, the conditional-random-field (CRF) model was used to obtain the final results. Due to the powerful ability of automatically extracting multilevel features, the performance of shadow detection was significantly improved in natural images compared to that of traditional methods. After that, numerous CNN networks, represented by cascaded networks and generated adversary networks (GANs), were designed to further enhance performance [
37,
38,
39,
40,
41]. The major issue for current CNN-based methods is that only local contextual information is considered, and global context is ignored. Herein, the local context means that the correlation between nearby pixels. Instead, the global context means the correlation between all pixels. On the other hand, there are as of yet few studies on using CNNs to extract shadows in urban aerial images.
From the above summary, we can see that the trade-off between automaticity and accuracy for the current methods is not as good as required. The reason for this can be summarized in two aspects. First, the traditional approaches mainly focus on the nonrobustly handcrafted shadow features and do not exploit the rich contextual information contained in a single image, which is insufficient to solve the confusion caused by certain types of objects, resulting in that it cannot be applied in the image with a new scene structure adaptively. On the other hand, there is no prior information in most cases, such as topographic data, imaging parameters, and light conditions, making it arduous to achieve higher accuracy. Therefore, an advanced approach should be developed to resolve this problem. Because traditional methods cannot automatically learn shadow-feature presentation, the limitation could be better addressed using deep-learning technology. Moreover, with the rapid development of remote-sensing technology, aerial images are universally accessible. Sufficient image data have made it possible to utilize CNNs to detect shadows in urban aerial images.
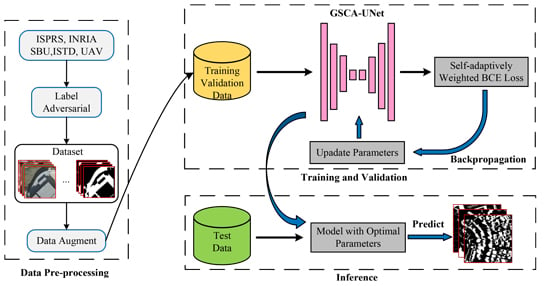
Inspired by the above analysis, in this paper we put forward a novel deep learning-based method, namely, a global-spatial-context attention U-shaped network (GSCA-UNet) to fill the gap between model automaticity and accuracy for shadow detection in urban aerial images. Experiment results on several typical urban aerial images verified the effectiveness and superiority of the proposed method. The main contributions of this work are listed as follows,
- (1)
we developed a spatial-attention module to capture the long-ranged contextual information for each pixel, which contributed to identifying the challenging shadows and non-shadows;
- (2)
on the basis of the UNet network architecture reported in [
42], we realized end-to-end automatic and accurate shadow detection in urban aerial images; and
- (3)
we developed a self-adaptively weighted binary cross-entropy (SAWBCE) loss function that enhanced the training procedure.
The remainder of this paper is organized as follows.
Section 2 introduces the details of the proposed approach.
Section 3 describes the experiment implementation and results. The method and experiments are discussed in
Section 4. Last, this paper is concluded in
Section 5.
4. Discussion
4.1. Network-Design Evaluation
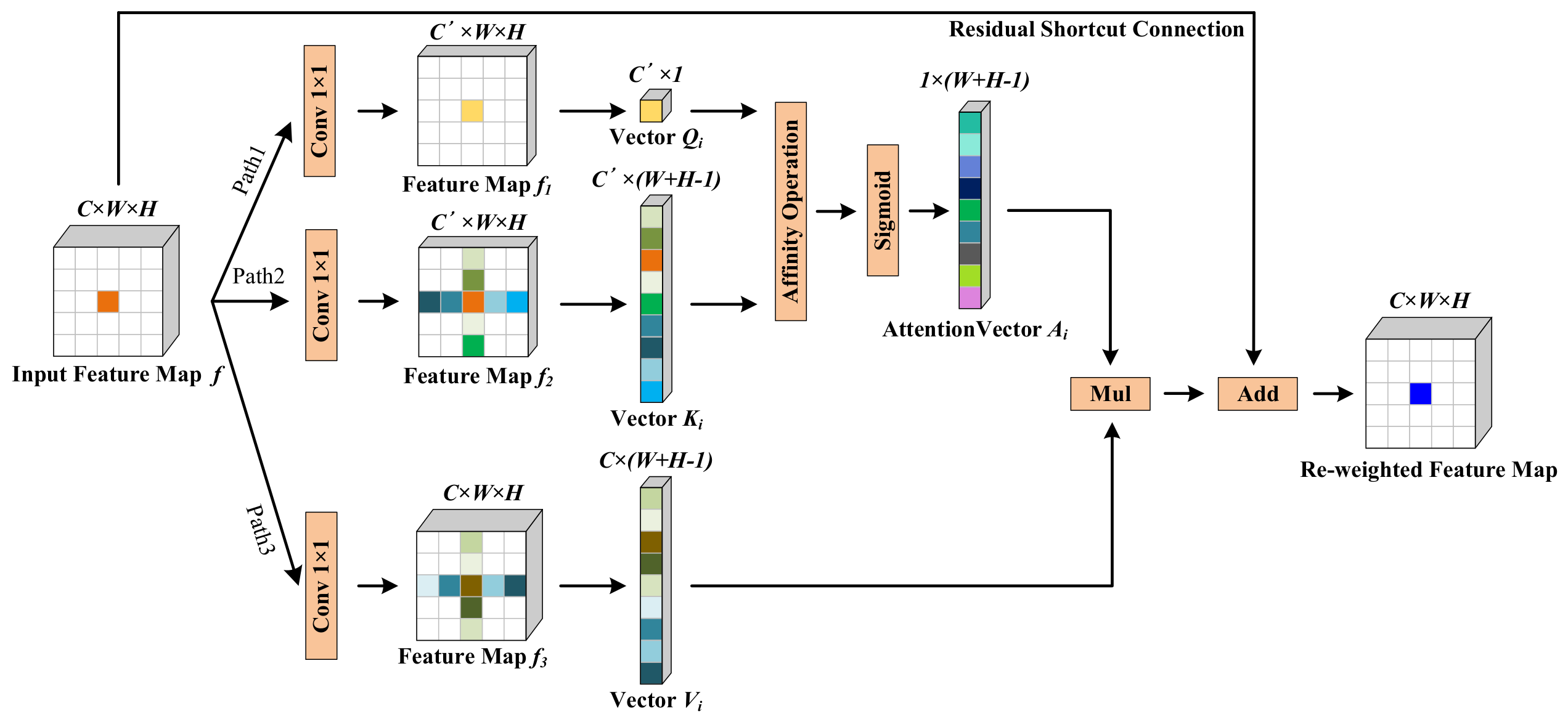
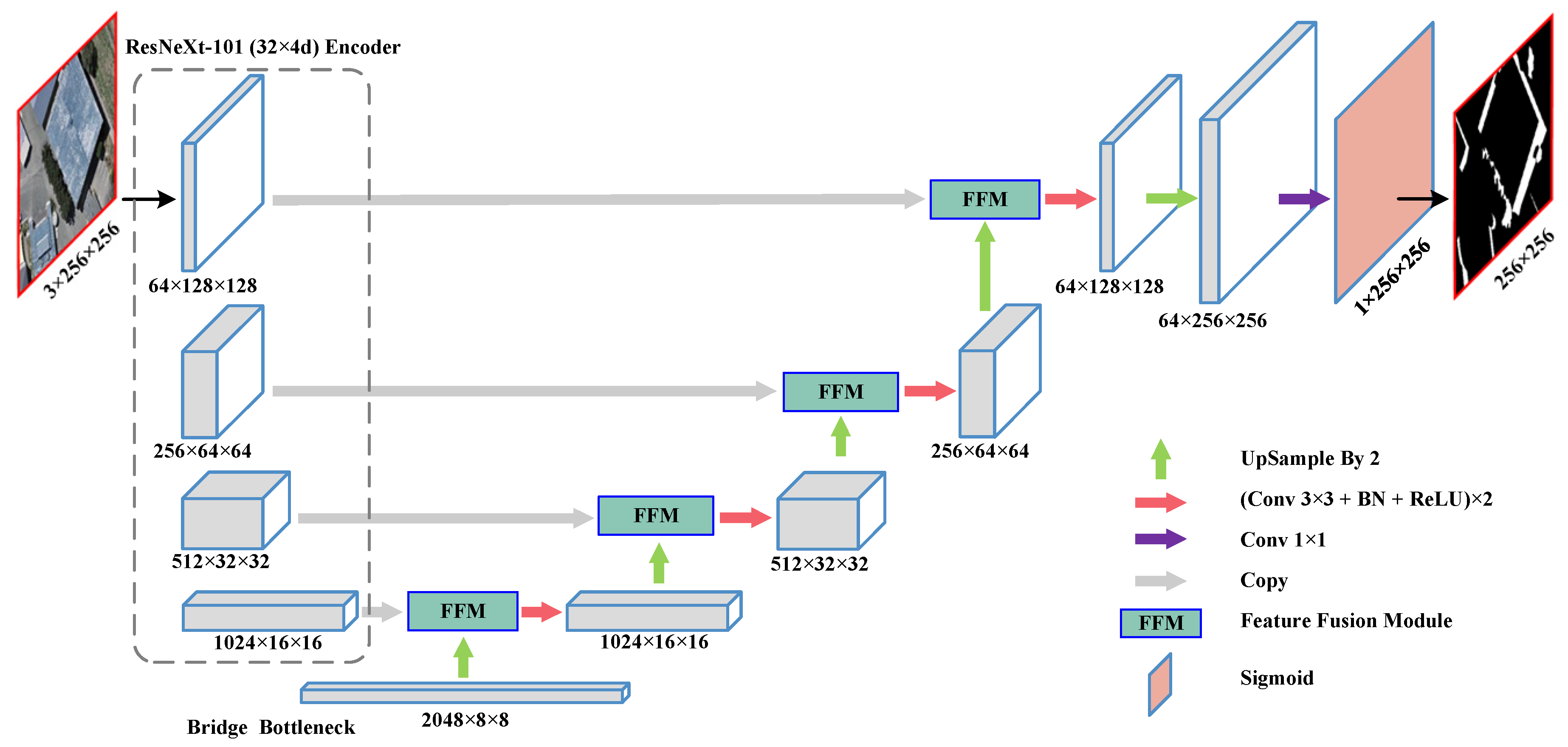
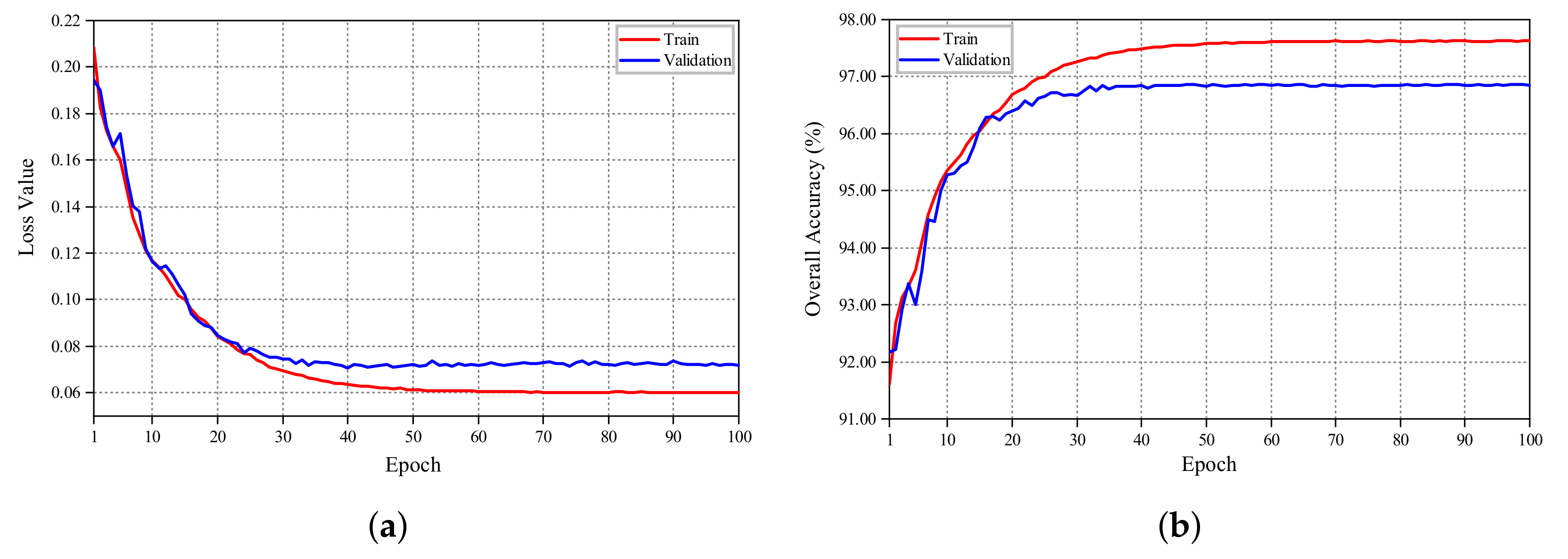
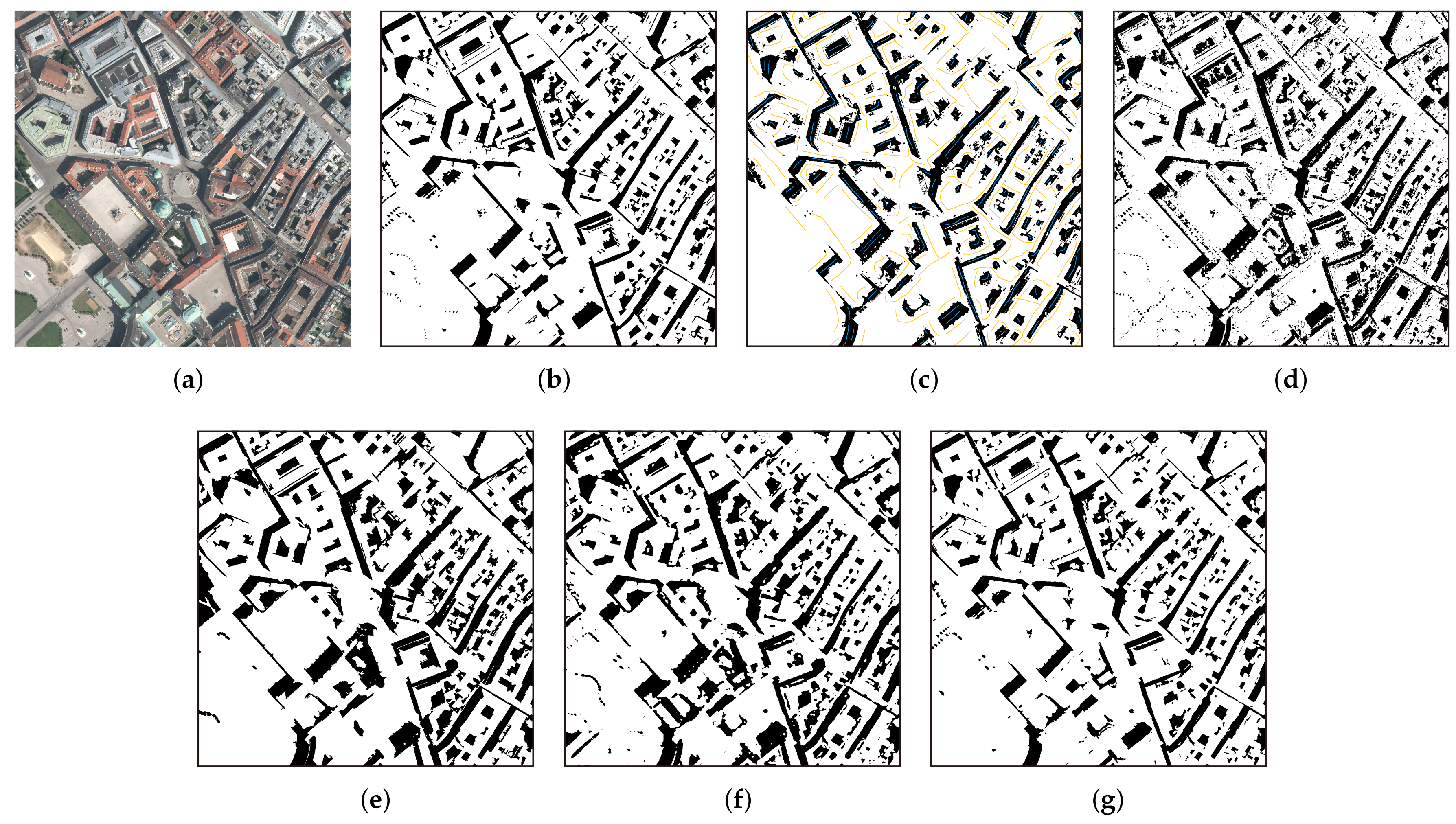
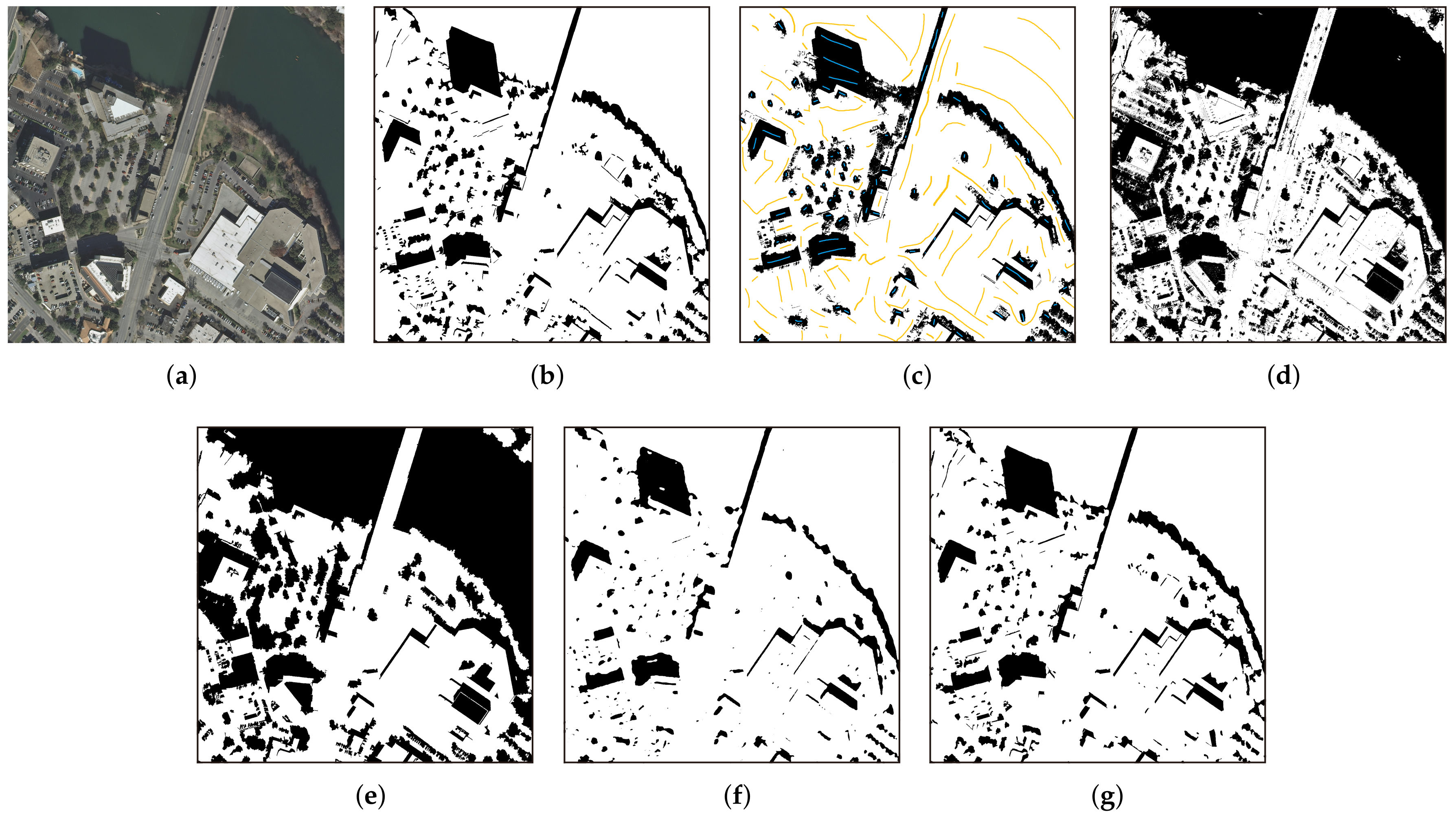
In this section, we evaluate the network design of the proposed GSCA-UNet. To better test and verify the effects of different network structures for shadow detection, we performed comparative experiments with the two other CNNs. The first network was the original UNet without the GSCA module and the ResNeXt-based encoder part, and the second was ResNeXt101-UNet, which was derived by removing the GSCA module from GSCA-UNet. Compared with our network, the complexity of the network structure of the two models above increased, and similarity with our model was high. Accordingly, the two models were suitable to verify the feature extractor of ResNeXt-101 and the GSCA module, respectively. We trained UNet and ResNeXt-UNet on our dataset by using the same loss function and training strategy to ensure analysis credibility. Detailed comparison results are displayed in
Table 4. As illustrated in
Table 4, compared with the baseline UNet network, utilizing the ResNeXt-101 as feature encoder improved
,
,
, and
by 0.58%, 0.22%, 6.48%, and 1.03%. The main reason for the improvement is that, compared with the original encoder part, the ResNeXt-101 network not only had the advantage of a residual shortcut, but also had a deeper and wider structure, enhancing its ability to extract shadow features. After embedding the recurrent GSCA module,
Table 4 shows that
,
,
, and
were significantly improved by 4.47%, 1.72%, 31.3%, and 7.77%, respectively, which validated the effectiveness of the GSCA module. The reason why the proposed GSCA module could obviously improve performance could be that we established the global link between pixels by enlarging the receptive filed of the CNN by using the module. Although the receptive filed of a CNN model can be theoretically increased by stacking many convolution layers, or applying the atrous convolution operations [
66] or the spatial-pyramid-pooling (SPP) module [
67,
68], the structural limitation of the convolution kernel makes the model only learn the local dependence for each pixel in each stage even if the network contains deeper layers. Therefore, for each pixel, the global spatial contextual information in the feature maps obtained by the ResNeXt101-UNet network was absent. Applying the GSCA module twice in each feature-fusion module, the concatenated feature map paid attention to global contextual information, and each pixel in the spatial dimension was reweighed. The dense global spatial contextual information for each pixel contributed to better identifying suspected shadows. Therefore, the model could more precisely locate shadows. To test the importance of the SAWBCE loss function, we conducted comparison experiments with the original BCE loss and SAWBCE loss. We used two GSCA-UNet models that were trained with BCE and SAWBCE loss, respectively. As listed in
Table 5, the proposed model with SAWBCE loss had the best shadow detection accuracy.
4.2. Advantages of the Proposed Method
Shadow detection in urban aerial images has been a popular research topic in the last few decades, yet automatic and accurate methods to detect shadows are still lacking. The proposed method in this paper filled this gap. Benefiting from dense global spatial contextual information, our method could yield accurate results without any manual intervention or prior knowledge in diverse cases, even compared with the representative supervised IMM method, which can usually obtain results with high accuracy. The proposed method is based on deep learning technology. Under the support of sufficient image data, it can be transferred to other unknown shadow detection tasks. For practical applications, the precisely detected shadows by our proposed method are more suitable as useful information for corresponding studies, such as urban-building instance recognition, building height estimation, and information recovery. At the same time, the proposed GSCA module has the advantage of flexibility. It can be applied to other CNN-based dense semantic-segmentation tasks for urban aerial remote sensing images, such as building extraction.
4.3. Limitations and Further Improvements
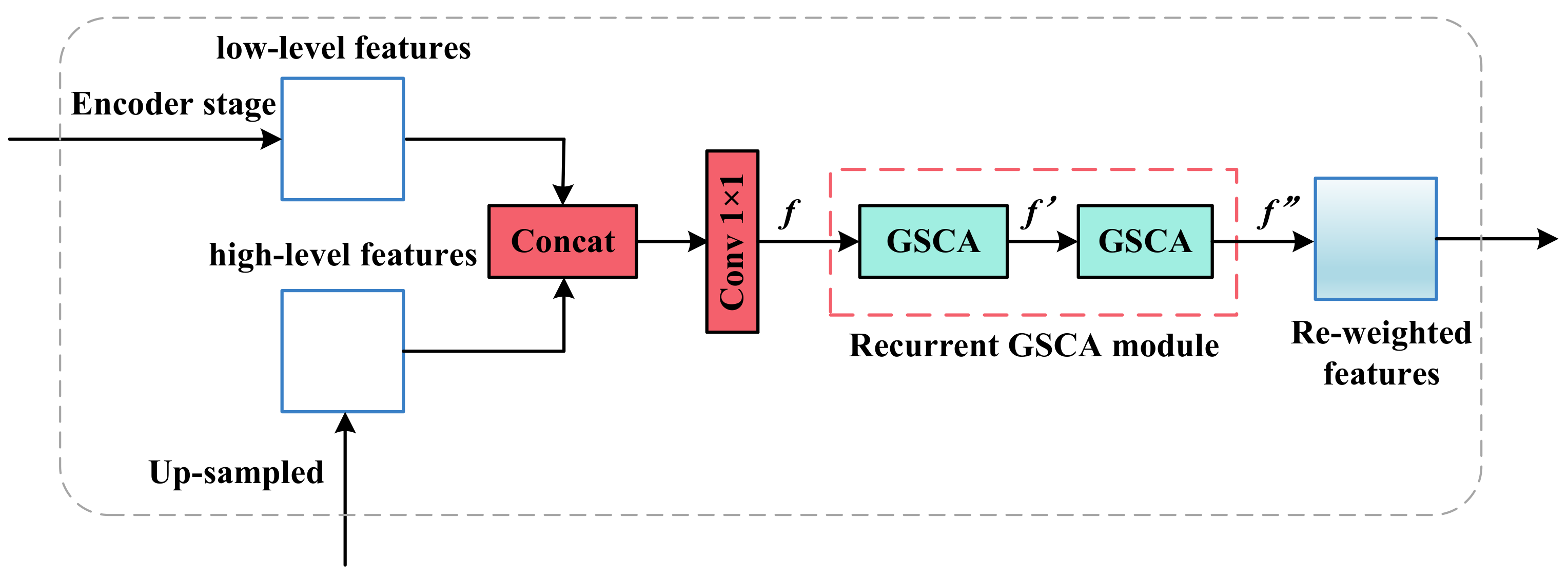
Although the proposed shadow detection method filled the gap left by the inadequate balance between automaticity and accuracy, some inherent weaknesses should not be ignored. Generally, spatial information in low-level features helps to locate shadow regions, but low-level features might bring unexpected noise that could cause detection errors. In this study, we directly concatenated the low- and high-level features via skip connection, and the spatial information of the shallow layer and contextual information were not leveraged. Thus, an individual feature fusion module is suggested to rethink the relationship between low- and corresponding high-level features in the feature fusion model.
To aggregate spatial contextual information in the horizontal and vertical directions requires to perform the iterative process pixel by pixel, which comes with high computation cost. The time complexity is on the channel dimension when the size of the input tensor is (), where B, C, W, and H are batch size, channel number, width, and height, receptively. In this study, with size (12, 3, 256, 256) of the initial input, it took about 75.40 min to train each epoch, and 0.11 s to inference, which was relatively slow. On the other hand, the number of parameters for the proposed GSCA-UNet was 106.04 million, making the GSCA-UNet impractical for implementation on some lightweight platforms. Future work should pay more attention to decreasing the number of network parameters to achieve real-time detection.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}