1. Introduction
With the rapid development of remote sensing hyperspectral imaging technology, hyperspectral image has been studied and applied in more and more practical applications, including ocean research [
1], vegetation analysis [
2], road detection [
3], geological disaster detection [
4], and environmental analysis [
5], etc. A hyperspectral image (HSI) contains abundant spectral and spatial information, which makes the HSI supervised classification task a hot research topic in the remote sensing analysis field. However, owing to the diversity of ground materials and the Hughes phenomenon coming from the increasing number of spectral bands [
6], how to make full use of and extract the most discriminative features from spectral and spatial dimensions is a crucial issue in the HSI classification task.
In the past, traditional machine learning (ML)-based HSI classification methods mainly contain two steps, i.e., feature engineering and classifier training [
7]. These methods usually focus on feature selection and classifier design, which requires lots of manual design based on specific HSI data. For example, [
8] divided bands into several sets by the cluster method and selected useful bands to construct tasks. Manifold ranking was introduced to eliminate the drawbacks of traditional salient band selection methods [
9]. In [
10], the Markov random field (MRF) was used in combination with band selection. However, inappropriate dimensionality reduction in the spectral domain from the manual design may lead to the loss of much useful spectral information. Therefore, while adopting SVM as the final classifier like [
11], many papers also suggested to explore input data with more spatial information in the feature engineering to improve the classification performance [
12,
13]. For instance, [
14] developed a region kernel to measure the region-to-region distance similarity and extract spectral-spatial combined features. A common problem among these methods is that traditional ML-based methods usually cannot make full use of ground material feature expression due to the difficulty in designing feature extraction methods. Therefore, traditional ML-based methods usually cannot achieve a high classification performance.
In recent years, deep learning (DL) has shown a powerful ability to extract hierarchical and nonlinear features, and DL methods based on the convolutional neural network (CNN) have been widely used in HSI classification tasks. So far, many works based on CNN have demonstrated that the end-to-end approach can reduce the possibility of the information loss during data preprocessing and improve the classification accuracy by learning deep features. For example, a unified framework combining CNN with a stacked autoencoder (SAE) was proposed to adaptively learn weight features for each pixel by one-dimensional (1-D) convolutional layers [
15,
16]. In [
17], SAE was also used to capture the representative stacked features. However, the input data of these 1-D-CNN-based methods must be flattened into 1-D vectors, which means that they cannot make full use of the spatial contextual relationship between pixels from raw HSI data.
To solve the above problems, the two-dimensional convolution neural network (2-D-CNN) was introduced to extract spectral and spatial features at the same time in many papers. For example, [
18] proposed a multiscale covariance maps (MCMs)-based feature extraction method, and combined it with the 2-D-CNN model to integrate the spectral and spatial information. However, the proposed method required specific hand-crafted feature extraction for different HSI datasets, which was difficult to design precise and complete artificial features. Then, a contextual deep CNN was introduced in [
19] to explore local contextual interactions. It used 2-D-CNN to extract spectral and spatial information separately. However, in these methods, when the network is deep, the rapid increase of network parameters will cause these 2-D-CNN-based models to be difficult to train. It may cause a degradation problem and finally lead to low classification accuracies. Therefore, residual connections were used to alleviate this phenomenon. The authors of [
20] adopted residual learning to optimize several convolutional layers as the identity mapping, and constructed a very deep network to extract spectral and spatial features. Since HSIs have both spectral and spatial information, [
21] proposed an end-to-end spectral-spatial residual network (SSRN), which consists of spectral and spatial residual blocks consecutively, to learn spectral and spatial features, respectively. In addition, to obtain a lower training cost and parameter scale, inspired by the densely connected convolutional network [
22], an end-to-end spectral-spatial dual-channel dense network (SSDC-DenseNet) was proposed to reduce the model scale and explore high-level features [
23]. Due to the densely connected structure, each layer will accept feature maps from all previous layers as its additional input data. Though these HSI classification methods based on 2-D-CNN could utilize the spatial context information, they separated spectral-spatial joint features into two independent learning parts. Since HSI is a 3-D data cube, it means that these methods neglect the close correlations between spectral information and spatial information.
Therefore, some three-dimensional convolution neural networks (3-D CNNs) models were proposed to learn spectral-spatial joint features directly from raw HSI data. With the help of residual connections, [
24] constructed a three-dimensional residual network (3-D-ResNet) to improve the classification performance. The experimental results demonstrated that 3-D-ResNet could mitigate the declining accuracy effect and achieved promising classification performance with few training samples. The authors of [
25] further studied 3-D CNNs to extract spectral-spatial combined features by using input cubes of HSIs with a smaller spatial size. Based on 3-D CNN and the densely connected convolutional network [
23], [
26] proposed the three-dimensional densely connected convolutional network (3-D-DenseNet) for HSI classification. The network could become very deep and extract more representative spectral-spatial combined features. To further reduce the training time, [
27] proposed an end-to-end fast dense spectral-spatial convolution (FDSSC) by using a dynamic learning rate and parametric rectified linear units. To reduce the number of the parameters and solve the imbalance of classes, [
28] used 3-D-ResNeXt and the label smoothing strategy to simultaneously extract spectral and spatial features, and achieved obvious classification performance improvement. To extract the spectral-spatial features of different scales, [
29] designed a multiscale octave 3-D CNN with channel and spatial attention (CSA-MSO3-DCNN). 3-D-CNN convolution kernels of different sizes could capture diverse features of HSI data. These 3-D-CNN-based methods can indeed make full use of the original characteristics of raw HSI data and the correlation between spectral and spatial information. Furthermore, the graph convolutional network [
30] was applied to alleviate the deficient labeled samples in [
31]. The spatial information was added into the approximate convolutional operation on the graph signal. So, the features obtained by the graph convolutional network made full use of both the adjacency nodes in the graph and neighbor pixels in the spatial domain. However, the features processed by the convolutional layers may contain much useless or disturbing information. If these useless features are sent directly to the next layer without any process, as the network is going deeper, the learning efficiency of the network will be lower, and will finally affect the classification performance. Therefore, how to deal with the feature maps after convolutional layers and pay more attention on those features with a large amount of useful information is another key for HSI classification tasks.
Recently, many classical and effective computer vision methods have been embedded in CNN to improve the performance of DL models. Among them, the CNN model fused with the attention mechanism delivers promising outcomes in improving HSI classification performance. The goal of the attention mechanism is to focus on salient features or regions with a large amount of information. Through a series of weight coefficients, the CNN model with the attention mechanism could improve the quality of feature maps after convolutional layers. For example, to extract more discriminative spectral and spatial features, [
32] combined FDSSC [
27] and the convolutional block attention module (CBAM) [
33], and proposed a double-branch multi-attention mechanism network (DBMA) for HSI classification, which consists of two parallel branches using channel-wise and spatial-wise attention separately. The experimental results demonstrated the effectiveness of channel-wise and spatial-wise attention. However, the parallel branching method did not take the correlation between spectral and spatial information into consideration, so DBMA did not obtain a satisfactory classification accuracy. In order to introduce global spatial information and solve the locality of the convolution operation, the self-attention mechanism [
34] was introduced to construct the non-local neural network. In [
35], this attention module was attached to the spectral-spatial attention network (SSAN). This attention module, which only focuses on spatial information, cannot globally optimize feature maps processed by convolutional layers. The authors of [
36] adopted the squeeze-and-excitation network (SENet) [
37] to adaptively recalibrate channel feature responses by explicitly modelling interdependencies between channels. In addition, [
38] also constructed a spatial-spectral squeeze-and-excitation (SSSE) module based on SENet. There was a problem that the channel features processed by the SSSE module contain much redundant information, which may affect the classification performance. To generate high-quality samples containing a complex spatial-spectral distribution, [
39] proposed a symmetric convolutional GAN based on collaborative learning and the attention mechanism (CA-GAN). The joint spatial-spectral attention module could emphasize more discriminative features and suppress less useful ones. However, although these methods based on the attention mechanism can play a role in optimizing features, they all have limitations: For one thing, the network can only be optimized in a specific spectral or spatial dimension; for another thing, as the network deepens, the channel attention module may lose much useful information because the optimization is operated on the whole channels.
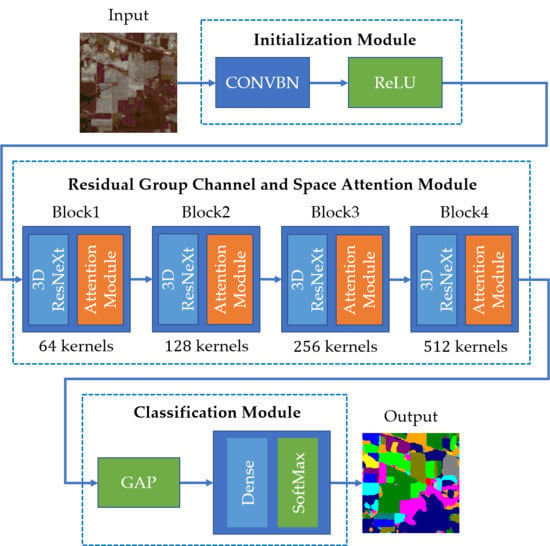
Our motivation was to construct a 3-DCNN-based network using an efficient attention module to solve the problem mentioned above. Inspired by the principle of SENet [
37] and the bottom-up top-down structure that has been applied to image segmentation [
40], we proposed a 3-DCNN-based residual group channel and space attention network (RGCSA) for HSI classification (The code and configurations are released at
https://github.com/Lemon362/RGCSA-master). The framework consists of several building blocks with the same topology. Each block contains a convolutional layer for learning features, a residual group channel-wise attention module, and a residual spatial-wise attention module. According to the principle of bottom-up top-down, we unified the channel attention module and space attention module into the same structure, but their implementation methods of up-sampling are different. To optimize features in the channel dimension to the greatest extent and reduce the loss of useful information, we introduced the principle of grouping into the channel-wise attention module to realize the group channel attention mechanism. Compared with 3-D-ResNeXt [
28], we only need fewer training samples to achieve a better classification accuracy by using the attention mechanism. When compared with DBMA [
32] and SSAN [
35], our network has fully optimized the feature maps processed by each convolutional layer in the channel dimension and spatial dimension, and shows an effective improvement for HSI classification.
In short, the three major contributions of this paper are listed as follows:
Combining the bottom-up top-down attention structure with the residual connection, we constructed residual channel and space attention modules without any additional manual design, and proposed a 3-DCNN-based residual group channel and space attention network (RGCSA) for HSI classification. On the one hand, residual connection can accelerate the flow of information, making the network better training. On the other hand, the structure of channel-wise attention first and then spatial-wise attention could strengthen important information and weaken unimportant information during the training process, and compared to the previous methods, RGCSA can achieve a higher HSI classification accuracy with fewer training samples.
We applied the principle of group convolution to the channel attention structure to construct a residual group channel attention module, which aims to emphasize each piece of useful channel information. Compared with the previous channel attention methods, it can reduce the possibility of losing useful channel information during attention optimization.
We proposed a novel spatial-wise attention module, which utilized transposed convolution as an up-sampling method. It ensures the mapping relationship of spatial pixels in the attention optimization process, and makes full use of context information to optimize the features in the spatial dimension to focus on the most informative areas.
The remaining sections of this paper are organized as follows.
Section 2 illustrates the related work about our proposed network for HSI classifications.
Section 3 presents a detailed network configuration of the overall framework and individual modules. Then,
Section 4 illustrates experimental datasets and the parameter setting, and then shows the experimental results and analyses. Finally, in
Section 5, we summarize some conclusions and introduce future work.
4. Experiments and Results
In this section, we first introduce three HSI datasets used in this paper, i.e., the Indian Pines (IN) dataset, the Pavia University (UP) dataset, and the Kennedy Space Center (KSC) dataset. Then, we discuss the two main factors affecting the classification performance. Finally, we compare the proposed RGCSA network with several representative HSI classification models, which are introduced in
Section 1, i.e., SVM [
11], SSRN [
21], 3-D-ResNeXt [
28], DBMA [
32], and SSAN [
35]. The overall accuracy (OA), average accuracy (AA), and kappa coefficient (Kappa) are used as the indicators to measure HSI classification performance. OA refers to the ratio of the number of correct classifications to the total number of HSI pixels in the test datasets. AA refers to the average accuracy of all classes. The kappa coefficient is an indicator used for the consistency test between the classification results and ground truth, and it can also be used to measure the classification accuracy. In short, the higher values of these three indicators represent the better classification results. Let
represent the confusion matrix of classification results, where
is the number of land-cover categories. According to [
35], the values of OA, AA, and kappa can be calculated as follows:
where
is a vector of the diagonal elements of
,
represents the sum of all elements of the matrix,
represents the sum of elements in each column
represents the sum of elements in each row,
represents the mean of all elements, and
represents the elementwise division.
To obtain a statistical evaluation, we repeated each experiment 5 times, and calculated the mean value as the final result.
4.1. Experimental Datasets
We used three available commonly used HSI datasets [
42] in our experiment to evaluate the classification performance of the proposed RGCSA model.
The Indian Pines (IN) dataset [
20] was collected by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) in 1992 from Northwest Indiana. It contains 16 classes with the size of
pixels and a spatial resolution of 20 m by pixel. There are 220 bands in the wavelength range of 0.4 to 2.5 um. Since 20 bands are corrupted by water absorption effects; the remaining 200 bands can be adopted for HSI experiments.
The Pavia University (UP) dataset [
20], gathered by Reflective Optics System Imaging Spectrometer (ROSIS) in 2001 in the Pavia region of northern Italy, has
pixels with a resolution of 1.3 m by pixel, and contains 9 vegetation classes. Since 12 bands with strong noise and water vapor absorption were removed, 103 bands ranging from 0.43 to 0.86 um were adopted for analysis.
The Kennedy Space Center (KSC) [
43] was firstly acquired by AVIRIS in 1996 in the Kennedy Space Center, containing 224 bands with center wavelengths in the range of 0.4 to 2.5 um. The image has
pixels with a spatial resolution of 18 m and 13 types of geographic objects. Since water absorption and low signal-to-noise ratio (SNR) bands were removed, 176 bands were adopted for analysis.
Table 4,
Table 5 and
Table 6 list the total number of samples of each class in each dataset and the number of training, validation, and test samples of three datasets under the optimal ratios, which obtained the best classification performance, i.e.,
for the IN dataset, and
for the UP and KSC datasets.
4.2. Experimental Parameter Discussion
We focused on two main factors that affect the classification performance of our proposed network, i.e., the ratio of the training dataset, and the number of groups of the residual group channel-wise attention (RGCA) module. Finally, according to the results of experiments, the ratios of the training, validation, and test datasets for the IN, UP, and KSC datasets are , respectively. Additionally, we set the number of groups of RGCA for three datasets to 8. Furthermore, the spatial input size of the network was constantly set to for all experiments.
4.2.1. Effect of Different Ratios of the Training, Validation, and Test Datasets
According to the experiment of the effect with different ratios of training samples in [
28], we also divided the HSI datasets into four different rations
, and tested the impact of different numbers of training samples on our proposed model. To obtain accurate results with different training samples, we set the epochs of different ratios to
, respectively. At the same time, the number of groups
was
. Finally, the training time, test time, and results of the three indicators (i.e., OA, AA, and kappa) with different ratios of the proposed model for three HSI datasets are list in
Table 7,
Table 8 and
Table 9.
From
Table 7,
Table 8 and
Table 9, we can find that in general, only with few training samples can our proposed network obtain high OA indicators in all three HSI datasets. Specifically, for the IN dataset, when the ratio changed from
to
, the OA indicator showed a clear and large increasing trend from
to
, and in contrast, the training time increased less. When the number of training samples further increased, as the epochs of the training process were reduced from 100 to 60, the OA decreased slightly. Therefore, we chose the ratio of
for the IN dataset. For the UP and KSC datasets, with the increasing number of training samples, the training time rose rapidly, whereas the accuracy decreased a little because of the epoch decreasing. Especially for the UP dataset, when the ratio was
, it had taken a long time to train the model. Additionally, when the ratio changed to
, the training time showed a dramatic jump from 25,837.94 s to 37,310.21 s, which nearly doubled. Additionally, with the further increase of the ratio, the corresponding training times were all longer than
. While for the KSC dataset, since it has fewer samples than the other two datasets, the training times of the different ratios were all lower, and when the ratio was
, the proposed model had already classified the KSC categories with a classification accuracy OA close to
. Therefore, for the UP and KSC datasets, we chose
as the most suitable ratios. Furthermore, compared with the previous methods, our proposed network reached the highest classification accuracy; the detailed results will be shown later.
In addition, we may notice that the training time and training samples did not show a linear growth relationship. The reason is that the epochs of the four ratios were different, as mentioned above. Considering that when the ratio is or , the number of the training samples is small, we therefore increased the epochs of and to 100 epochs to obtain the best results. While when the ratio came to or , more training samples in each epoch could make the network achieve a high classification performance with fewer epochs.
4.2.2. Effect of the Number of Groups
In the proposed RGCSA network, in order to better optimize the channels, we divided the channels to
groups and then used RCA module for each group, and finally merged the optimized channels of each group. Therefore, the number of groups is the other key factor for our proposed network. At the same time, since we utilized 3-D-ResNeXt to extract spectral-spatial features, for the convenience of the experiment, we set the cardinality (i.e., the size of the set of transformations) and
to the same value. We evaluated the classification performance of the proposed RGCSA network with different numbers of groups
and the results are shown in
Table 10. In this experiment, we set the spatial input size to
, and the ratio to
for the IN dataset and
for the UP and KSC datasets.
From the table, we can find that as the number of groups increases, the number of parameters and training time all gradually increase, while the OA indicators for the three HSI datasets fluctuate a little. It means that the reasonable division of the number channel groups is key to the influence on the classification performance of the network. If the number of groups is small, some channels may not be optimized, and even some useful channel information may be gradually discarded due to the deep network. If is too large, each group has fewer channels to be optimized, and the network cannot accurately extract useful channel information. Finally, we chose the number of groups for three HSI datasets.
4.3. Classification Results Comparison with State-of-the-Art
To verify the effectiveness of our proposed RGCSA network, we compared RGCSA with several classic methods, i.e., SVM [
11], SSRN [
21], 3-D-ResNeXt [
28], DBMA [
32], and SSAN [
35]. To obtain fair comparison results, our proposed RGCSA network and compared methods adopted the same spatial input size of
(
represents the number of spectral bands), the ratio of
for the IN dataset, and
for the UP and KSC dataset for all methods.
Table 11,
Table 12 and
Table 13 report the OAs, AAs, kappa coefficients, and the classification accuracy for each class for three HSI datasets. From the tables, we can see that the proposed RGCSA achieved the highest classification accuracy than other methods for all three HSI datasets. First of all, SVM achieved the lowest classification accuracy in the three HSI datasets among all the methods. Secondly, since the training samples of class 1, 7, and 9 (alfalfa, grass-pasture-mowed, and oats, respectively) in the IN dataset are lower than 50 and SSRN divided the network into spectral and spatial feature learning parts, 2-D-CNN-based SSRN showed a lower classification accuracy on these classes, especially class 9, than other 3-D-CNN-based methods, such as 3-D-ResNeXt, DBMA, SSAN, and RGCSA. Though DBMA and SSAN used 3-D-CNN to extract features, these two models separated the spectral dimension and spatial dimension. It means that these models cannot make use of the close correlation between these two dimensions, and the results of DBMA and SSAN in
Table 11,
Table 12 and
Table 13 proved it. Thirdly, we find that the models combined with the attention modules can achieve high classification accuracy, especially for the UP and KSC datasets. It means that channel-wise attention and spatial-wise attention can indeed optimize the features extracted by CNN and improve the classification performance. Furthermore, compared with these methods, our proposed RGCSA network could classify all classes for the three datasets more accurately, with classification accuracies higher than
. It means that our proposed network only needs fewer training samples to obtain higher classification performance through our proposed group-channel and space joint attention mechanism.
Figure 10,
Figure 11 and
Figure 12 show the visualization maps of all classes of all methods based on CNN (i.e., SSRN, 3-D-ResNeXt, DBMA, SSAN, and our proposed RGCSA), along with the false color images of the HSI datasets and their corresponding ground-truth maps. In the IN dataset, the visualization maps of SSRN, DBMA, and SSAN did not show class 9 (oats, labeled in dark red). However, our proposed RGCSA network could classify class 9, which is completely displayed in
Figure 10g. In the UP and KSC datasets, we find that the edge contours of each class of our proposed network are clearer and smoother than others. In addition, the prediction effect of our proposed RGCSA network on unlabeled parts is also significantly better than other methods. For example, on the right of class 1 (labeled by bright red) in the IN dataset, it can be seen from the false color map in
Figure 10a that this unlabeled part should belong to class 6. None of the comparison methods can accurately predict this part. In contrast, it can be clearly seen from
Figure 10g that our proposed RGCSA network can predict this part and fully visualize it. Similarly, in the lower middle of the UP dataset, the part marked in dark blue belongs to class 3 (gravel), and our proposed network can visualize it more completely than other methods. In summary, our proposed RGCSA network can clearly visualize all the labeled classes, and can predict and visualize the unlabeled parts more accurately than other methods.
Table 14 and
Figure 13 show the comparison results of the 3D-ResNeXt (without the channel-wise and spatial-wise attention modules), RGCA (only with the group channel-wise attention RGCA module), RSA (only with the spatial-wise attention RSA module), and RGCSA (both with the RGCA module and RSA module). Except for the different attention modules, we set these four models to the same structure. The ratios of the three HSI datasets are
, respectively, and the epochs were all set to
.
Table 14 shows the corresponding network parameters, training time, and test time and
Figure 13 shows the OAs of four different attention mechanisms on the three HSI datasets. We find that the models with attention modules need more time to train, and the proposed RGCSA has the longest training time. Although RGCA, RSA, and RGCSA all generate more computational costs and consumption, from the figure, we can see that 3-D-ResNeXt without any attention modules achieved the lowest accuracies on the three HSI datasets, which proves the effectiveness of the attention mechanism. The OAs of RGCA with only the group channel-wise attention module in the three datasets are all higher than those of RSA with only the spatial-wise attention module, but the gap between RGCA and RSA is not obvious. It means that the proposed attention mechanisms in these two dimensions have optimized the channel and spatial features. Furthermore, when combining these two attention modules, the proposed RGCSA obtained the highest classification accuracies. It fully demonstrated that the proposed channel space joint attention mechanism plays an important role in HSI classification and is suitable for HSI classification tasks.
To test the robustness and generalizability of the proposed RGCSA under different ratios of training datasets, three models, i.e., SSRN based on 2-D-CNN, 3-D-ResNeXt based on 3-D-CNN, and the proposed RGCSA based on 3-D-CNN and attention mechanism, were selected to do this experiment.
Figure 14,
Figure 15 and
Figure 16 illustrate the overall accuracies (OAs) of these models using different ratios of training datasets. When the number of training samples is small, such as the ratios of
and
in the three HSI datasets, the proposed RGCSA network obtained the highest OA indicators among the three methods. Especially for the IN and KSC datasets, the OAs of our proposed network always maintain a high level under different ratios. It means that we can achieve better classification results by the proposed RGCSA network with fewer training samples. It is important that when the total number of samples is small, or when there are few samples of some classes, such as class 1, 7, and 9 in the IN dataset, the proposed RGCSA can still generate a superior classification performance. As the training samples increase, the OAs of the proposed network in the three HSI datasets show a slight fluctuation but can still maintain over
. Since SSRN divided the network into the spectral learning part and spatial learning part, it cannot make full use of the relationship between the spectral and spatial dimensions. Therefore, in the three HSI datasets, the OAs of SSRN are the lowest among the three methods. It means that 3-D-CNN can extract spectral-spatial features with more useful information than 2-D-CNN. When compared with 3-D-ResNeXt, which needs more training samples to achieve high classification accuracies, our proposed network benefits from the residual attention mechanism to obtain the same high OA indicators with fewer training samples, and the classification accuracies are all higher than 3-D-ResNeXt under different ratios. In summary, it is obvious that the proposed channel-wise and spatial-wise attention modules, which can pay attention to the informative features, strengthen the representation of these features, and suppress the interference of useless information, are more suitable for HSI classification tasks. It can be demonstrated that our proposed RGCSA network has strong robustness and stability under different ratios of training datasets.
At the same time,
Table 15,
Table 16 and
Table 17 show the training time and test time of the above three models under different ratios. The epochs of the corresponding ratios are
}, respectively. From the tables, we can see that our proposed network needs more training time and test time in the three HSI datasets. The reason is that the proposed RGCA and RSA completely use 3-D-CNNs instead of FC layers to extract channel information and spatial context information. The proposed network is much deeper than the other networks, which results in more time to train the model. However, from the perspective of the classification results, it is feasible to exchange more computational costs for higher classification accuracies.
5. Conclusions
In this paper, we proposed a supervised 3-D deep learning framework for HSI classification, using the bottom-up top-down attention structure with the residual connection. Compared with the previous traditional ML-based methods, the end-to-end deep learning methods can make full use of the GPU performance to accelerate network training and avoid complex artificial design of feature extraction. Compared with the deep learning methods based only on CNN, the proposed attention mechanism could strengthen important information and weaken unimportant information.
The above experiments verify the effectiveness of the proposed residual group channel and space attention module in the HSI classification tasks. In summary, the three major differences between our proposed RGCSA classification model and other deep learning-based models are as follows: First, the designed residual group channel-wise attention module and spatial-wise attention module have the same basic structure, which is easily inserted into any networks. Additionally, the residual connection can accelerate the flow of information for better training. Second, the group channel-wise attention module can reduce the possibility of losing useful information during the attention optimization. Additionally, the novel spatial-wise attention module can learn the context information and maintain the mapping relationship of spatial pixels before and after the optimization process. Third, the most important point is that in the face of poorly distributed HSI datasets, we can use the proposed RGCSA to optimize the learning process and obtain a higher classification performance with fewer training samples. In summary, the above advantages enable our RGCSA network to gain higher classification results than previous models, whether it is a CNN-based network or an attention-based network.
From the perspective of network complexity, the future work will focus on how to effectively reduce the number of network parameters and computational costs while maintaining high classification accuracy through the attention mechanism.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}