Automatic Land-Cover Mapping using Landsat Time-Series Data based on Google Earth Engine

 ,
,
Abstract
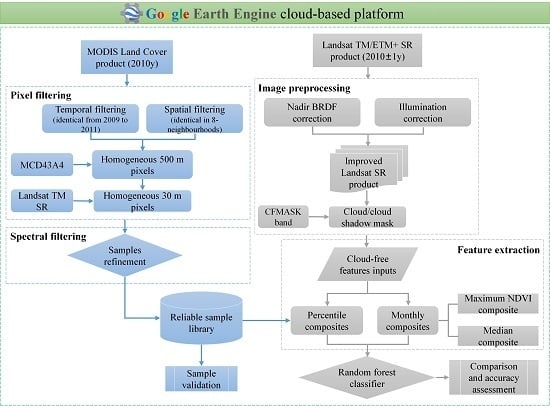
:
1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Landsat TM/ETM+ Data
2.3. MODIS Land Cover Product
2.4. MODIS Nadir BRDF-Adjusted Reflectance Product
3. Method
3.1. Automatic Collection of Samples from MODIS Land Cover Products
- (i)
- the MCD12Q1 pixel values from 2009 to 2011 were identical;
- (ii)
- the MCD12Q1 pixels that had the same values in the 8 surrounding pixels for 2010;
- (iii)
- the 500 m MODIS pixels were homogeneous;
- (iv)
- the 30 m Landsat pixels within the 500 m MODIS pixel were homogenous.
- (a)
- Calculate the spectral centroid of the sample set:where is a vector which consists of the reflectance values of the Landsat TM/ETM+ bands 1–5 and band 7; is the spectral centroid (a vector consisting of six Landsat TM/ETM+ surface reflectance values) and is the median value of a sample set in the spectral dimension.
- (b)
- Calculate the Euclidean distance from an individual sample to the spectral centroid of the sample set:where is the Euclidean distance from sample i to the spectral centroid of the sample set.
- (c)
- Sort the calculated Euclidean distance from small to large and retain the top 50% of the samples.
3.2. Landsat TM/ETM+ Data Pre-Processing
3.3. Landsat TM/ETM+ Composites
3.4. Land-Cover Classification
3.5. Accuracy Assessment
4. Results and Discussion
4.1. Samples Automatically Extracted from MCD12Q1.006
4.2. Validation of the Automatically Extracted Samples
4.3. The Landsat-based Classification Results
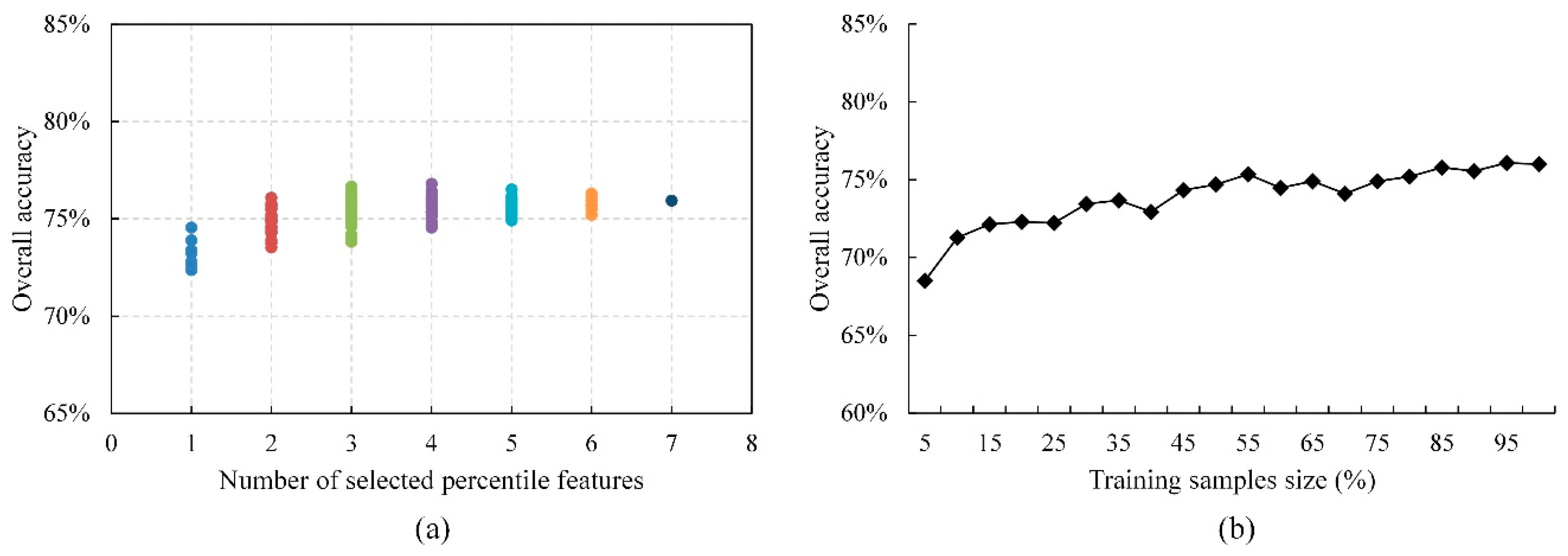
4.4. Effect of Feature Combinations and Training-Sample Size
5. Conclusions
- (i)
- The samples automatically extracted by the proposed method were reliable and accurate with an overall accuracy of 99.2%;
- (ii)
- Both the percentile features and monthly features produced excellent land- cover classification results; however, the classification produced using the median composited monthly features was more accurate than that obtained using the percentile features – average overall accuracy of 80% against 77%. In addition, the monthly features composited using the median values outperformed those composited using the maximum NDVI values in terms of the classification performance – average overall accuracy of 80% against 78%;
- (iii)
- For single class accuracy, WTR, GRL and DBF have the top three highest producer accuracy while CSL and UB have the two lowest accuracies, based on median composited monthly features. Additionally, GRL have higher producer accuracy with the maximum NDVI method, while DBF, CSL, WS, SVN and UB have better producer accuracy with the median method;
- (iv)
- Higher overall accuracies were achieved with an increased number of percentile or monthly features. Both the percentile and monthly features had a low sensitivity to the training-sample size and the OA increased as the size of the training samples increased.
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Herold, M.; Latham, J.; Di Gregorio, A.; Schmullius, C. Evolving standards in land cover characterization. J. Land Use Sci. 2006, 1, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Sesnie, S.E.; Gessler, P.E.; Finegan, B.; Thessler, S. Integrating landsat tm and srtm-dem derived variables with decision trees for habitat classification and change detection in complex neotropical environments. Remote Sens. Environ. 2008, 112, 2145–2159. [Google Scholar] [CrossRef]
- Pflugmacher, D.; Cohen, W.B.; Kennedy, R.E. Using landsat-derived disturbance history (1972–2010) to predict current forest structure. Remote Sens. Environ. 2012, 122, 146–165. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M. Global land cover mapping at 30 m resolution: A pok-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S. Finer resolution observation and monitoring of global land cover: First mapping results with landsat tm and etm+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Johnson, D.M.; Mueller, R. The 2009 cropland data layer. PERS Photogramm. Eng. Remote Sens. 2010, 76, 1201–1205. [Google Scholar]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 national land cover database for the conterminous united states–representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- Zhang, H.K.; Roy, D.P. Using the 500 m modis land cover product to derive a consistent continental scale 30 m landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Xie, S.; Gao, Y. Fine land-cover mapping in china using landsat datacube and an operational speclib-based approach. Remote Sens. 2019, 11, 1056. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google earth engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Azzari, G.; Lobell, D. Landsat-based classification in the cloud: An opportunity for a paradigm shift in land cover monitoring. Remote Sens. Environ. 2017, 202, 64–74. [Google Scholar] [CrossRef]
- Chen, B.; Xiao, X.; Li, X.; Pan, L.; Doughty, R.; Ma, J.; Dong, J.; Qin, Y.; Zhao, B.; Wu, Z. A mangrove forest map of china in 2015: Analysis of time series landsat 7/8 and sentinel-1a imagery in google earth engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2017, 131, 104–120. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X.; Menarguez, M.A.; Zhang, G.; Qin, Y.; Thau, D.; Biradar, C.; Moore III, B. Mapping paddy rice planting area in northeastern asia with landsat 8 images, phenology-based algorithm and google earth engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef] [Green Version]
- Goldblatt, R.; Stuhlmacher, M.F.; Tellman, B.; Clinton, N.; Hanson, G.; Georgescu, M.; Wang, C.; Serrano-Candela, F.; Khandelwal, A.K.; Cheng, W.-H. Using landsat and nighttime lights for supervised pixel-based image classification of urban land cover. Remote Sens. Environ. 2018, 205, 253–275. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Y.; Clinton, N.; Wang, J.; Wang, X.; Liu, C.; Gong, P.; Yang, J.; Bai, Y.; Zheng, Y. Mapping major land cover dynamics in beijing using all landsat images in google earth engine. Remote Sens. Environ. 2017, 202, 166–176. [Google Scholar] [CrossRef]
- Patel, N.N.; Angiuli, E.; Gamba, P.; Gaughan, A.; Lisini, G.; Stevens, F.R.; Tatem, A.J.; Trianni, G. Multitemporal settlement and population mapping from landsat using google earth engine. Int. J. Appl. Earth Obs. Geoinf. 2015, 35, 199–208. [Google Scholar] [CrossRef] [Green Version]
- Beckschäfer, P. Obtaining rubber plantation age information from very dense landsat tm & etm+ time series data and pixel-based image compositing. Remote Sens. Environ. 2017, 196, 89–100. [Google Scholar]
- Hansen, M.C.; Egorov, A.; Roy, D.P.; Potapov, P.; Ju, J.; Turubanova, S.; Kommareddy, I.; Loveland, T.R. Continuous fields of land cover for the conterminous united states using landsat data: First results from the web-enabled landsat data (weld) project. Remote Sens. Lett. 2011, 2, 279–288. [Google Scholar] [CrossRef]
- Mack, B.; Leinenkugel, P.; Kuenzer, C.; Dech, S. A semi-automated approach for the generation of a new land use and land cover product for germany based on landsat time-series and lucas in-situ data. Remote Sens. Lett. 2017, 8, 244–253. [Google Scholar] [CrossRef]
- Potapov, P.V.; Turubanova, S.; Tyukavina, A.; Krylov, A.; McCarty, J.; Radeloff, V.; Hansen, M. Eastern europe’s forest cover dynamics from 1985 to 2012 quantified from the full landsat archive. Remote Sens. Environ. 2015, 159, 28–43. [Google Scholar] [CrossRef]
- Griffiths, P.; van der Linden, S.; Kuemmerle, T.; Hostert, P. A pixel-based landsat compositing algorithm for large area land cover mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2088–2101. [Google Scholar] [CrossRef]
- Hansen, M.C.; Roy, D.P.; Lindquist, E.; Adusei, B.; Justice, C.O.; Altstatt, A. A method for integrating modis and landsat data for systematic monitoring of forest cover and change in the congo basin. Remote Sens. Environ. 2008, 112, 2495–2513. [Google Scholar] [CrossRef]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. Regional detection, characterization, and attribution of annual forest change from 1984 to 2012 using landsat-derived time-series metrics. Remote Sens. Environ. 2015, 170, 121–132. [Google Scholar] [CrossRef]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. Disturbance-informed annual land cover classification maps of Canada’s forested ecosystems for a 29-year landsat time series. Can. J. Remote Sens. 2018, 44, 67–87. [Google Scholar] [CrossRef]
- Teillet, P.; Barker, J.; Markham, B.; Irish, R.; Fedosejevs, G.; Storey, J. Radiometric cross-calibration of the landsat-7 etm+ and landsat-5 tm sensors based on tandem data sets. Remote Sens. Environ. 2001, 78, 39–54. [Google Scholar] [CrossRef] [Green Version]
- Arvidson, T.; Goward, S.; Gasch, J.; Williams, D. Landsat-7 long-term acquisition plan. Photogramm. Eng. Remote Sens. 2006, 72, 1137–1146. [Google Scholar] [CrossRef]
- Claverie, M.; Vermote, E.F.; Franch, B.; Masek, J.G. Evaluation of the landsat-5 tm and landsat-7 etm+ surface reflectance products. Remote Sens. Environ. 2015, 169, 390–403. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Gray, J.M.; Abercrombie, S.P.; Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The modis collection 6 land cover product. Remote Sens. Environ. 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Friedl, M.A. User Guide to Collection 6 Modis Land Cover (mcd12q1 and mcd12c1) Product; USGS: Reston, VA, USA, 2018.
- Schaaf, C.; Wang, Z. Mcd43a4 Modis/Terra+ Aqua brdf/Albedo Nadir brdf Adjusted Refdaily l3 global-500 m v006; NASA EOSDIS Land Processes DAAC: Washington, DC, USA, 2015.
- Wang, Z.; Liu, L. Assessment of coarse-resolution land cover products using casi hyperspectral data in an arid zone in northwestern china. Remote Sens. 2014, 6, 2864–2883. [Google Scholar] [CrossRef] [Green Version]
- Feng, M.; Huang, C.; Channan, S.; Vermote, E.F.; Masek, J.G.; Townshend, J.R. Quality assessment of landsat surface reflectance products using modis data. Comput. Geosci. 2012, 38, 9–22. [Google Scholar] [CrossRef] [Green Version]
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T.-K. A landsat surface reflectance dataset for north america, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Roy, D.P.; Zhang, H.; Ju, J.; Gomez-Dans, J.L.; Lewis, P.E.; Schaaf, C.; Sun, Q.; Li, J.; Huang, H.; Kovalskyy, V. A general method to normalize landsat reflectance data to nadir brdf adjusted reflectance. Remote Sens. Environ. 2016, 176, 255–271. [Google Scholar] [CrossRef] [Green Version]
- Tan, B.; Masek, J.G.; Wolfe, R.; Gao, F.; Huang, C.; Vermote, E.F.; Sexton, J.O.; Ederer, G. Improved forest change detection with terrain illumination corrected landsat images. Remote Sens. Environ. 2013, 136, 469–483. [Google Scholar] [CrossRef]
- Tan, B.; Wolfe, R.; Masek, J.; Gao, F.; Vermote, E.F. In An Illumination Correction Algorithm on Landsat-tm Data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, IEEE, Honolulu, HI, USA, 25–30 July 2010; pp. 1964–1967. [Google Scholar]
- Markham, B.L.; Storey, J.C.; Williams, D.L.; Irons, J.R. Landsat sensor performance: History and current status. IEEE Trans. Geosci. Remote Sens. 2004, 42, 2691–2694. [Google Scholar] [CrossRef]
- Woodcock, C.E.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.N.; Helder, D.; Helmer, E. Free access to landsat imagery. Science 2008, 320, 1011. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Kline, K.; Scaramuzza, P.L.; Kovalskyy, V.; Hansen, M.; Loveland, T.R.; Vermote, E.; Zhang, C. Web-enabled landsat data (weld): Landsat etm+ composited mosaics of the conterminous united states. Remote Sens. Environ. 2010, 114, 35–49. [Google Scholar] [CrossRef]
- Richardson, A.J.; Wiegand, C.L. Distinguishing vegetation from soil background information. Photogramm. Eng. Remote Sens. 1977, 43, 1541–1552. [Google Scholar]
- Ju, J.; Roy, D.P. The availability of cloud-free landsat etm+ data over the conterminous united states and globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L. The shuttle radar topography mission. Rev. Geophys. 2007, 45. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Cihlar, J. Land cover mapping of large areas from satellites: Status and research priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef]
- Liu, J.; Zhuang, D.; Luo, D.; Xiao, X.M. Land-cover classification of china: Integrated analysis of avhrr imagery and geophysical data. Int. J. Remote Sens. 2003, 24, 2485–2500. [Google Scholar] [CrossRef]
- Vieira, C.; Mather, P.; Aplin, P. Multitemporal classification of agricultural crops using the spectral-temporal response surface. In Analysis of Multi-Temporal Remote Sensing Images; World Scientific: Singapore, 2002; pp. 290–297. [Google Scholar]
- Knight, J.F.; Lunetta, R.S.; Ediriwickrema, J.; Khorram, S. Regional scale land cover characterization using modis-ndvi 250 m multi-temporal imagery: A phenology-based approach. GIScience Remote Sens. 2006, 43, 1–23. [Google Scholar] [CrossRef]
- Carrão, H.; Gonçalves, P.; Caetano, M. Contribution of multispectral and multitemporal information from modis images to land cover classification. Remote Sens. Environ. 2008, 112, 986–997. [Google Scholar] [CrossRef]
- Nitze, I.; Barrett, B.; Cawkwell, F. Temporal optimisation of image acquisition for land cover classification with random forest and modis time-series. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 136–146. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Woodcock, C.E.; Rogan, J.; Kellndorfer, J. Assessment of spectral, polarimetric, temporal, and spatial dimensions for urban and peri-urban land cover classification using landsat and sar data. Remote Sens. Environ. 2012, 117, 72–82. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Abbreviation | Description |
|---|---|---|
| Evergreen needleleaf forest | ENF | Dominated by evergreen conifer trees (canopy >2 m). Tree cover >60% |
| Deciduous broadleaf forest | DBF | Dominated by deciduous broadleaf trees (canopy >2 m). Tree cover >60% |
| Mixed forest | MF | Dominated by neither deciduous nor evergreen (40–60% of each) tree type (canopy > 2 m). Tree cover >60% |
| Closed shrublands | CSL | Dominated by woody perennials (1–2 m height) >60% cover |
| Woody savannas | WS | Tree cover 30–60% (canopy > 2 m) |
| Savannas | SVN | Tree cover 10–30% (canopy > 2 m) |
| Grasslands | GRL | Dominated by herbaceous annuals (<2 m) |
| Croplands | CRL | At least 60% of area is cultivated cropland |
| Urban and built-up | UB | At least 30% impervious surface area including building materials, asphalt, and vehicles |
| Water | WTR | At least 60% of area is covered by permanent water bodies |
| MODIS band | Landsat Band | Threshold |
|---|---|---|
| 3 | 1 | 0.03 |
| 4 | 2 | 0.03 |
| 1 | 3 | 0.03 |
| 2 | 4 | 0.06 |
| 6 | 5 | 0.03 |
| 7 | 7 | 0.03 |
| Type I Feature Inputs | Type II Features Inputs |
|---|---|
| 10th percentile (TM/ETM+ band1-5, 7, NDVI) | Apr. (TM/ETM+ band1-5, 7, NDVI) |
| 20th percentile (TM/ETM+ band1-5, 7, NDVI) | May (TM/ETM+ band1-5, 7, NDVI) |
| 25th percentile (TM/ETM+ band1-5, 7, NDVI) | Jun. (TM/ETM+ band1-5, 7, NDVI) |
| 50th percentile (TM/ETM+ band1-5, 7, NDVI) | Jul. (TM/ETM+ band1-5, 7, NDVI) |
| 75th percentile (TM/ETM+ band1-5, 7, NDVI) | Aug. (TM/ETM+ band1-5, 7, NDVI) |
| 80th percentile (TM/ETM+ band1-5, 7, NDVI) | Sep. (TM/ETM+ band1-5, 7, NDVI) |
| 90th percentile (TM/ETM+ band1-5, 7, NDVI) | Oct. (TM/ETM+ band1-5, 7, NDVI) |
| DEM | DEM |
| Slope | Slope |
| Aspect | Aspect |
| Satellite | Scene_123032 | Scene_125034 | Scene_125033 |
|---|---|---|---|
| MODIS (NBAR: MCD43A4.006) | 20 May 2010 | 31 May 2009 | 31 May 2009 |
| Landsat (Landsat-5 TM SR) | 20 May 2010 | 31 May 2009 | 31 May 2009 |
| Class | Tra. | Val. | Per. | Max. | Med. | |||
|---|---|---|---|---|---|---|---|---|
| UA | PA | UA | PA | UA | PA | |||
| DBF | 391 | 209 | 0.82 ± 0.05 | 0.84 ± 0.04 | 0.81 ± 0.05 | 0.83 ± 0.04 | 0.84 ± 0.05 | 0.89 ± 0.04 |
| CSL | 333 | 167 | 0.64 ± 0.07 | 0.56 ± 0.07 | 0.68 ± 0.07 | 0.55 ± 0.07 | 0.73 ± 0.07 | 0.59 ± 0.07 |
| WS | 274 | 126 | 0.80 ± 0.07 | 0.85 ± 0.06 | 0.76 ± 0.07 | 0.84 ± 0.06 | 0.85 ± 0.06 | 0.92 ± 0.04 |
| SVN | 326 | 174 | 0.66 ± 0.07 | 0.55 ± 0.06 | 0.73 ± 0.07 | 0.56 ± 0.06 | 0.82 ± 0.06 | 0.62 ± 0.06 |
| GRL | 529 | 271 | 0.72 ± 0.05 | 0.85 ± 0.04 | 0.75 ± 0.05 | 0.90 ± 0.03 | 0.76 ± 0.05 | 0.88 ± 0.04 |
| CRL | 468 | 232 | 0.79 ± 0.05 | 0.83 ± 0.04 | 0.81 ± 0.05 | 0.83 ± 0.03 | 0.81 ± 0.05 | 0.85 ± 0.03 |
| UB | 225 | 99 | 0.73 ± 0.10 | 0.55 ± 0.08 | 0.66 ± 0.10 | 0.56 ± 0.08 | 0.68 ± 0.10 | 0.57 ± 0.08 |
| WTR | 203 | 97 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| Total | 2749 | 1375 | 0.75 ± 0.03 | 0.77 ± 0.03 | 0.79 ± 0.03 | |||
| Class | Tra. | Val. | Per. | Max. | Med. | |||
|---|---|---|---|---|---|---|---|---|
| UA | PA | UA | PA | UA | PA | |||
| ENF | 85 | 42 | 0.97 ± 0.05 | 0.54 ± 0.20 | 1.00 ± 0.00 | 0.59 ± 0.18 | 0.97 ± 0.05 | 0.47 ± 0.24 |
| DBF | 254 | 130 | 0.95 ± 0.04 | 0.94 ± 0.04 | 0.99 ± 0.02 | 0.94 ± 0.04 | 0.98 ± 0.03 | 0.96 ± 0.03 |
| MF | 396 | 189 | 0.91 ± 0.04 | 0.79 ± 0.06 | 0.89 ± 0.05 | 0.82 ± 0.06 | 0.91 ± 0.04 | 0.83 ± 0.05 |
| CSL | 264 | 126 | 0.93 ± 0.04 | 0.87 ± 0.11 | 0.97 ± 0.03 | 0.86 ± 0.09 | 0.94 ± 0.04 | 0.82 ± 0.13 |
| WS | 342 | 138 | 0.80 ± 0.07 | 0.82 ± 0.08 | 0.82 ± 0.06 | 0.82 ± 0.08 | 0.85 ± 0.06 | 0.91 ± 0.05 |
| SVN | 474 | 211 | 0.76 ± 0.06 | 0.72 ± 0.09 | 0.77 ± 0.05 | 0.74 ± 0.09 | 0.82 ± 0.05 | 0.82 ± 0.08 |
| GRL | 543 | 237 | 0.66 ± 0.05 | 0.98 ± 0.01 | 0.66 ± 0.05 | 0.98 ± 0.01 | 0.68 ± 0.05 | 0.98 ± 0.01 |
| CRL | 512 | 288 | 0.92 ± 0.04 | 0.68 ± 0.04 | 0.89 ± 0.04 | 0.71 ± 0.04 | 0.89 ± 0.04 | 0.70 ± 0.04 |
| UB | 173 | 72 | 0.78 ± 0.11 | 0.51 ± 0.10 | 0.84 ± 0.10 | 0.44 ± 0.09 | 0.79 ± 0.11 | 0.47 ± 0.09 |
| WTR | 140 | 56 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| Total | 3183 | 1489 | 0.78 ± 0.03 | 0.79 ± 0.03 | 0.80 ± 0.03 | |||
| Class | Tra. | Val. | Per. | Max. | Med. | |||
|---|---|---|---|---|---|---|---|---|
| UA | PA | UA | PA | UA | PA | |||
| DBF | 325 | 175 | 0.91 ± 0.04 | 0.92 ± 0.05 | 0.95 ± 0.03 | 0.88 ± 0.07 | 0.95 ± 0.03 | 0.94 ± 0.04 |
| MF | 239 | 116 | 0.93 ± 0.05 | 0.88 ± 0.08 | 0.92 ± 0.05 | 0.88 ± 0.09 | 0.93 ± 0.05 | 0.91 ± 0.09 |
| CSL | 351 | 149 | 0.80 ± 0.06 | 0.74 ± 0.09 | 0.79 ± 0.06 | 0.69 ± 0.09 | 0.86 ± 0.05 | 0.82 ± 0.11 |
| WS | 56 | 43 | 0.97 ± 0.06 | 0.17 ± 0.09 | 0.97 ± 0.05 | 0.35 ± 0.21 | 0.97 ± 0.05 | 0.50 ± 0.22 |
| SVN | 416 | 184 | 0.77 ± 0.06 | 0.67 ± 0.08 | 0.76 ± 0.06 | 0.78 ± 0.07 | 0.84 ± 0.05 | 0.80 ± 0.07 |
| GRL | 511 | 289 | 0.73 ± 0.05 | 0.97 ± 0.01 | 0.76 ± 0.04 | 0.97 ± 0.01 | 0.75 ± 0.04 | 0.97 ± 0.01 |
| CRL | 452 | 248 | 0.82 ± 0.05 | 0.71 ± 0.05 | 0.82 ± 0.05 | 0.74 ± 0.05 | 0.84 ± 0.05 | 0.73 ± 0.05 |
| UB | 334 | 166 | 0.98 ± 0.03 | 0.28 ± 0.05 | 0.91 ± 0.05 | 0.35 ± 0.06 | 0.92 ± 0.05 | 0.34 ± 0.06 |
| WTR | 219 | 81 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| Total | 2903 | 1451 | 0.77 ± 0.03 | 0.79 ± 0.03 | 0.80 ± 0.03 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, S.; Liu, L.; Zhang, X.; Yang, J.; Chen, X.; Gao, Y. Automatic Land-Cover Mapping using Landsat Time-Series Data based on Google Earth Engine. Remote Sens. 2019, 11, 3023. https://doi.org/10.3390/rs11243023
Xie S, Liu L, Zhang X, Yang J, Chen X, Gao Y. Automatic Land-Cover Mapping using Landsat Time-Series Data based on Google Earth Engine. Remote Sensing. 2019; 11(24):3023. https://doi.org/10.3390/rs11243023
Chicago/Turabian StyleXie, Shuai, Liangyun Liu, Xiao Zhang, Jiangning Yang, Xidong Chen, and Yuan Gao. 2019. "Automatic Land-Cover Mapping using Landsat Time-Series Data based on Google Earth Engine" Remote Sensing 11, no. 24: 3023. https://doi.org/10.3390/rs11243023