


Lightweight Network-Based Surface Defect Detection Method for Steel Plates
Abstract
:1. Introduction
2. Methodology
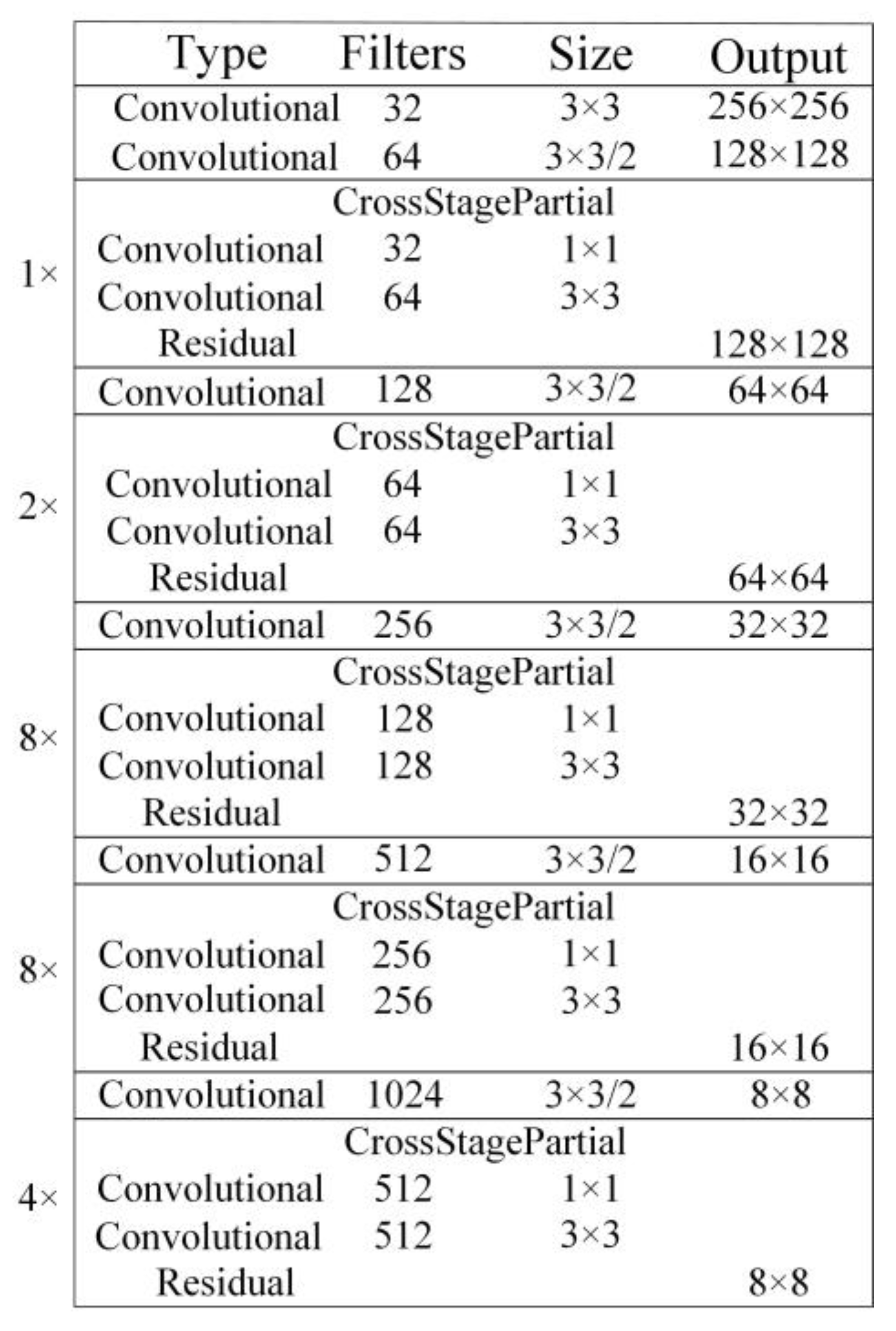
2.1. The YOLOv4 Backbone Network
2.2. GhostNet
2.3. Loss Function
3. Our Approach
3.1. YOLO-ACG Algorithm
3.2. Ghost Module
3.3. Improved ASPP Module
3.4. CA Attention Mechanism Module
4. Experimental Preparation
4.1. Test Environment
4.2. Production of Data Set
5. Results and Discussion
5.1. Training Model
5.2. Comparison Experiment
5.3. Ablation Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, K.; Li, H.; Li, C.; Zhao, X.; Wu, S.; Duan, Y.; Wang, J. An Automatic Defect Detection System for Petrochemical Pipeline Based on Cycle-GAN and YOLO v5. Sensors 2022, 22, 7907. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, T.; Xuan, Z.; Feng, Z. Automated Defect Analysis System for Industrial Computerized Tomography Images of Solid Rocket Motor Grains Based on YOLO-V4 Model. Electronics 2022, 11, 3215. [Google Scholar] [CrossRef]
- Jung, H.; Rhee, J. Application of YOLO and ResNet in Heat Staking Process Inspection. Sustainability 2022, 14, 15892. [Google Scholar] [CrossRef]
- Zhao, Z.; Ge, Z.; Jia, M.; Yang, X.; Ding, R.; Zhou, Y. A Particleboard Surface Defect Detection Method Research Based on the Deep Learning Algorithm. Sensors 2022, 22, 7733. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liu, X.; Guo, J.; Zhou, P. Surface Defect Detection of Strip-Steel Based on an Improved PP-YOLOE-m Detection Network. Electronics 2022, 11, 2603. [Google Scholar] [CrossRef]
- Luo, Q.; Fang, X.; Liu, L.; Yang, C.; Sun, Y. Automated visual defect detection for flat steel surface: A survey. IEEE Trans. Instrum. Meas. 2020, 69, 626–644. [Google Scholar] [CrossRef] [Green Version]
- Shi, T.; Kong, J.; Wang, X.; Liu, Z.; Zheng, G. Improved Sobel algorithm for defect detection of rail surfaces with enhanced efficiency and accuracy. J. Cent. South Univ. 2016, 23, 2867–2875. [Google Scholar] [CrossRef]
- Thomas, B.G.; Jenkins, M.S.; Mahapatra, R.B. Investigation of strand surface defects using mould instrumentation and modelling. Ironmak. Steelmak. 2004, 31, 485–494. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, K.; Wang, D. Online surface defect identification of cold rolled strips based on local binary pattern and extreme learning machine. Metals 2018, 8, 197. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zhu, D. An accurate detection method for surface defects of complex components based on support vector machine and spreading algorithm. Measurement 2019, 147, 106886. [Google Scholar] [CrossRef]
- Kang, G.W.; Liu, H.B. Surface defects inspection of cold rolled strips based on neural network. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 8, pp. 5034–5037. [Google Scholar]
- Di, H.; Ke, X.; Peng, Z.; Zhou, D. Surface defect classification of steels with a new semi-supervised learning method. Opt. Lasers Eng. 2019, 117, 40–48. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International Conference on Information Processing in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2017; pp. 146–157. [Google Scholar]
- Lee, S.Y.; Tama, B.A.; Moon, S.J.; Lee, S. Steel surface defect diagnostics using deep convolutional neural network and class activation map. Appl. Sci. 2019, 9, 5449. [Google Scholar] [CrossRef] [Green Version]
- Tabernik, D.; Šela, S.; Skvarč, J.; Skočaj, D. Segmentation-based deep-learning approach for surface-defect detection. J. Intell. Manuf. 2020, 31, 759–776. [Google Scholar] [CrossRef] [Green Version]
- Prappacher, N.; Bullmann, M.; Bohn, G.; Deinzer, F.; Linke, A. Defect detection on rolling element surface scans using neural image segmentation. Appl. Sci. 2020, 10, 3290. [Google Scholar] [CrossRef]
- Peng, K.; Zhang, X. Classification technology for automatic surface defects detection of steel strip based on improved BP algorithm. In Proceedings of the 2009 Fifth International Conference on Natural Computation, Tianjin, China, 14–16 August 2009; pp. 110–114. [Google Scholar]
- Wang, Y.X.; Guang-Hui, Y.U.; Qiang, X.U. A Machine Vision Based Printing Defect Detection Technology for Product Packaging. J. Jiangsu Univ. Technol. 2019, 25, 7–14. [Google Scholar]
- Wang, Z.Y. Research on steel plate surface defects detection method based on machine vision. Comput. Modern 2013, 7, 97–117. [Google Scholar]
- Wang, L.; Wei, C.; Li, W.; Zhang, Y. Pedestrian detection based on YOLOv2 with pyramid pooling module in underground coal mine. Comput. Eng. Appl. 2018, 55, 133–139. [Google Scholar]
- Yang, W.; Zhou, G.L.; Gu, Z.W.; Jiang, X.D.; Lu, Z.M. Safety Helmet Wearing Detection Based on an Improved Yolov3 Scheme. Int. J. Innov. Comput. Inf. Control. 2022, 18, 973–988. [Google Scholar]
- Liu, M.; Mao, J. Deep Face Recognition Algorithm Based on Improved Mobilenet Algorithm. Inf. Commun. Technol. 2019, 1, 41–46. [Google Scholar]
- Cheng, S.; Zhou, B. Recognition of Characters in Aluminum Wheel Back Cavity Based on Improved Convolution Neural Network. Comput. Eng. 2019, 45, 182–186. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Yang, K.; Jiao, Z.; Liang, J.; Lei, H.; Li, C.; Zhong, Z. An application case of object detection model based on Yolov3-SPP model pruning. In Proceedings of the 2022 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 24–26 June 2022; pp. 578–582. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP | Model Size/MB | FPS |
|---|---|---|---|
| YOLOv4 | 96.35% | 244.7 | 85.3 |
| YOLOv4-MobileNetv1 | 88.39% | 40.95 | 47.6 |
| YOLOv4-MobileNetv2 | 89.52% | 39.06 | 40.1 |
| YOLOv4-MobileNetv3 | 89.75% | 39.99 | 43.2 |
| YOLO-ACG | 92.49% | 69.82 | 102.91 |
| Experiment | SPP | ASPP | SE | ECA | CBAM | CA | mAP | FPS | Size/MB | Recall |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | √ | 89.17% | 95.88 | 43.63 | 67.34% | |||||
| 2 | √ | √ | 88.49% | 96.53 | 44.25 | 71.42% | ||||
| 3 | √ | √ | 88.37% | 95.17 | 44.61 | 71.91% | ||||
| 4 | √ | √ | 87.84% | 96.01 | 44.26 | 70.42% | ||||
| 5 | √ | √ | 88.61% | 97.88 | 43.84 | 68.77% | ||||
| 6 | √ | 91.64% | 97.89 | 69.57 | 75.81% | |||||
| 7 | √ | √ | 91.09% | 94.28 | 70.23 | 76.52% | ||||
| 8 | √ | √ | 90.49% | 96.53 | 69.63 | 72.26% | ||||
| 9 | √ | √ | 89.76% | 95.36 | 70.26 | 72.72% | ||||
| 10 | √ | √ | 92.49% | 102.91 | 69.12 | 77.49% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Sun, M.; Cao, Y.; He, K.; Zhang, B.; Cao, Z.; Wang, M. Lightweight Network-Based Surface Defect Detection Method for Steel Plates. Sustainability 2023, 15, 3733. https://doi.org/10.3390/su15043733
Wang C, Sun M, Cao Y, He K, Zhang B, Cao Z, Wang M. Lightweight Network-Based Surface Defect Detection Method for Steel Plates. Sustainability. 2023; 15(4):3733. https://doi.org/10.3390/su15043733
Chicago/Turabian StyleWang, Changqing, Maoxuan Sun, Yuan Cao, Kunyu He, Bei Zhang, Zhonghao Cao, and Meng Wang. 2023. "Lightweight Network-Based Surface Defect Detection Method for Steel Plates" Sustainability 15, no. 4: 3733. https://doi.org/10.3390/su15043733