
A Wind Power Scenario Generation Method Based on Copula Functions and Forecast Errors

Abstract
:1. Introduction
1.1. Background
1.2. Literature Survey
1.3. Contributions
- This study proposes a methodology that creates wind power scenarios, considering temporal and spatial correlations, which improves the accuracy of scenario generation. It also solves the problem of computational complexity that arises when temporal and spatial correlation are considered simultaneously.
- This study models forecast errors in the scenario generation process to enhance the forecast accuracy.
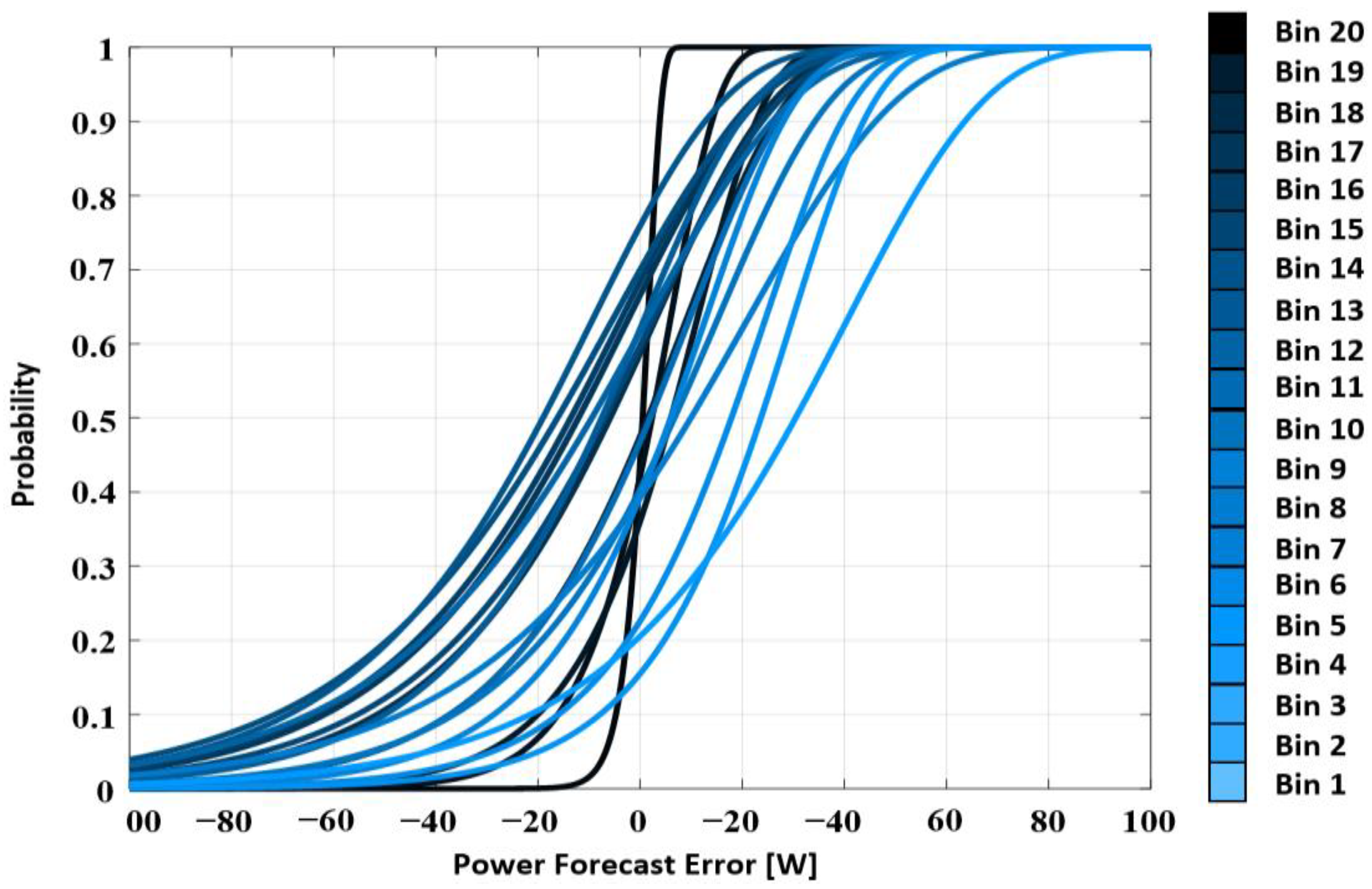
- This study analyses the stochastic properties of forecast errors in different generation bins and reveals that the stochastic properties differ among bins. Applying the result to scenario generation makes it possible to offset the forecast errors with a high probability of occurrence.
- The probabilistic analysis can utilize the scenarios generated by the proposed method to improve its reliability, eventually enhancing the efficiency and reliability of power system operation.
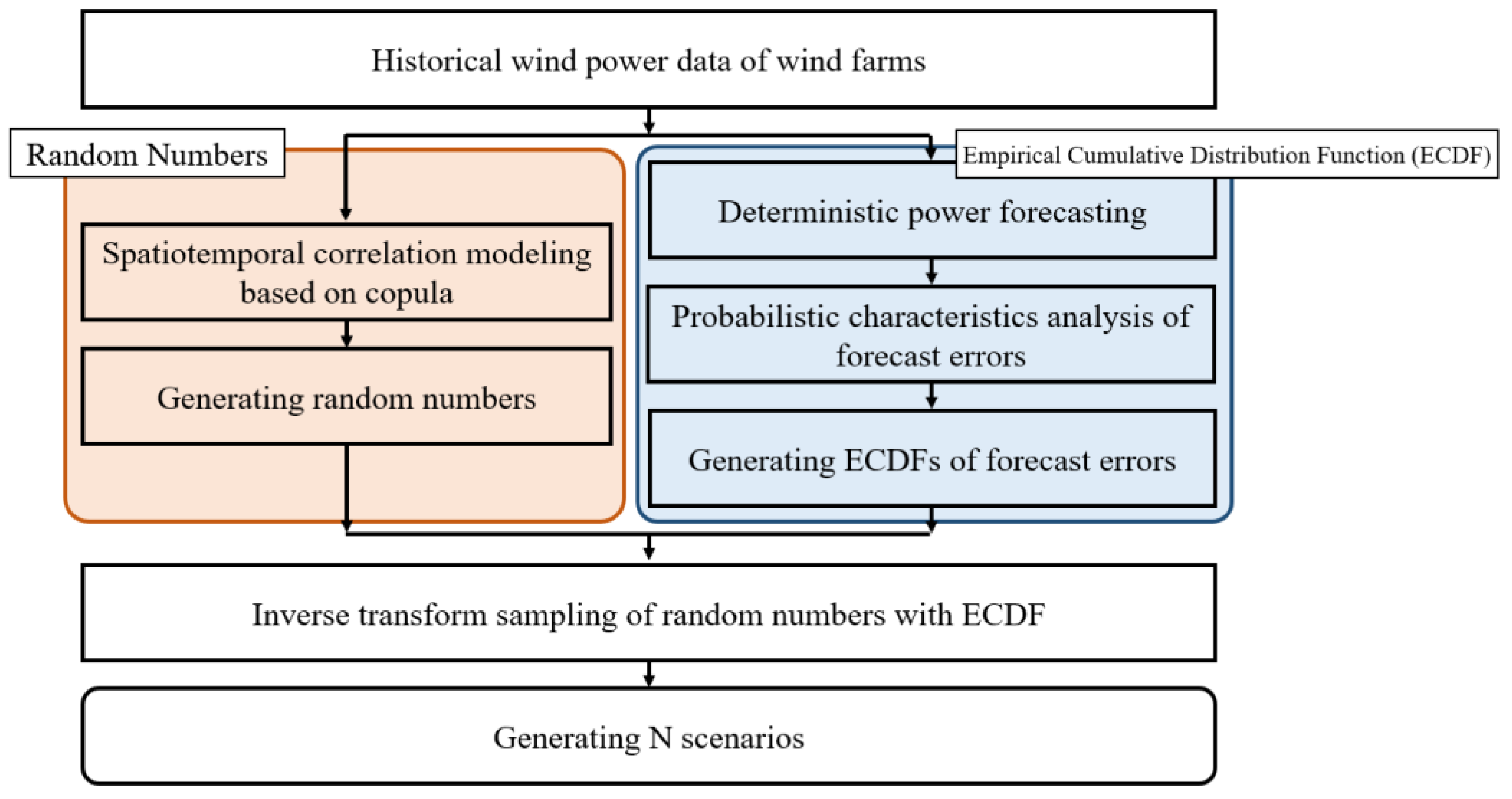
2. Proposed Methodology
2.1. Wind Power Scenario Generation Method
2.2. Generating Spatiotemporally Correlated Random Numbers
2.2.1. Generating Spatial and Temporal Samples Using Copula Function
2.2.2. Generating Spatiotemporal Samples
- (1)
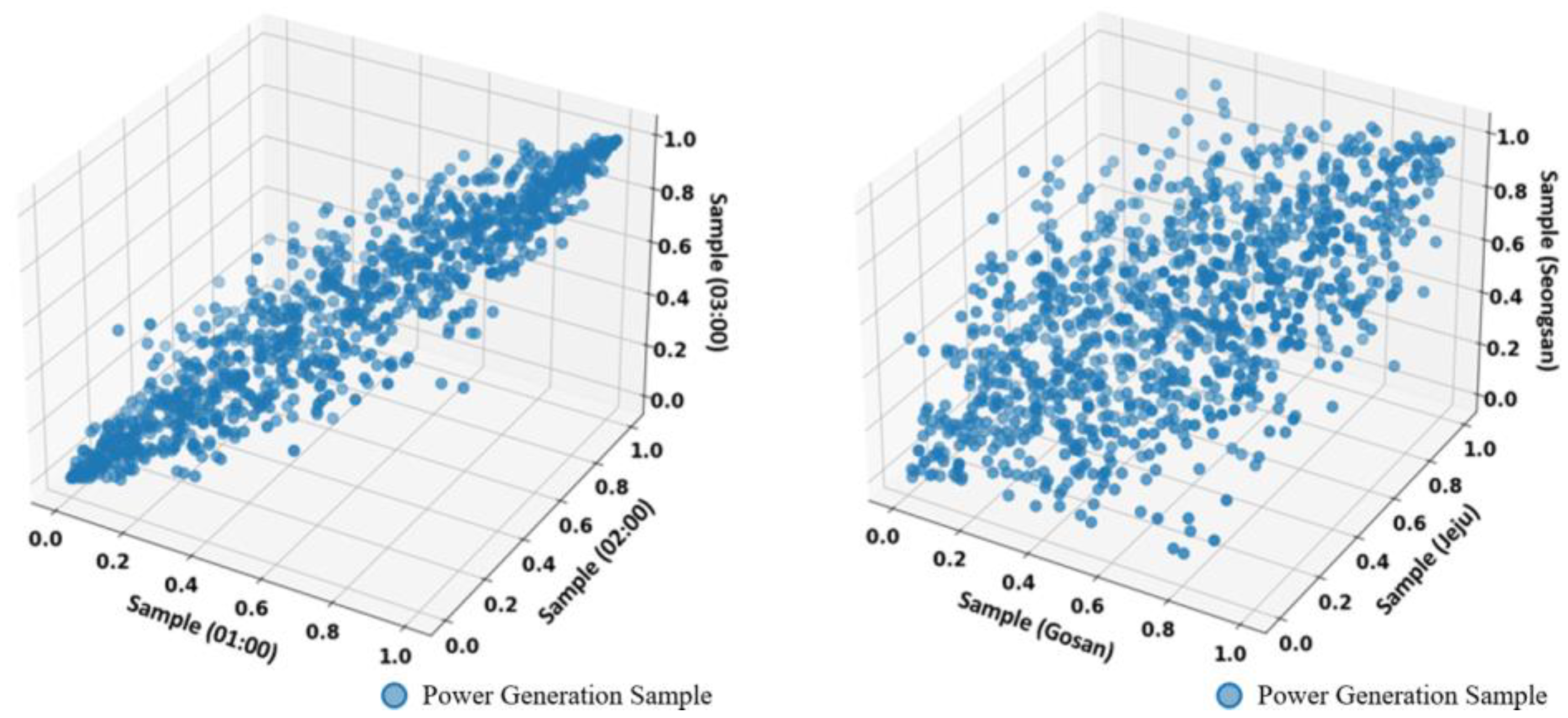
- The temporal wind power samples of each wind turbine are generated using the copula function and are used to create M matrices, ⋯,. The n-th row of the m-th sample matrix has the elements .
- (2)
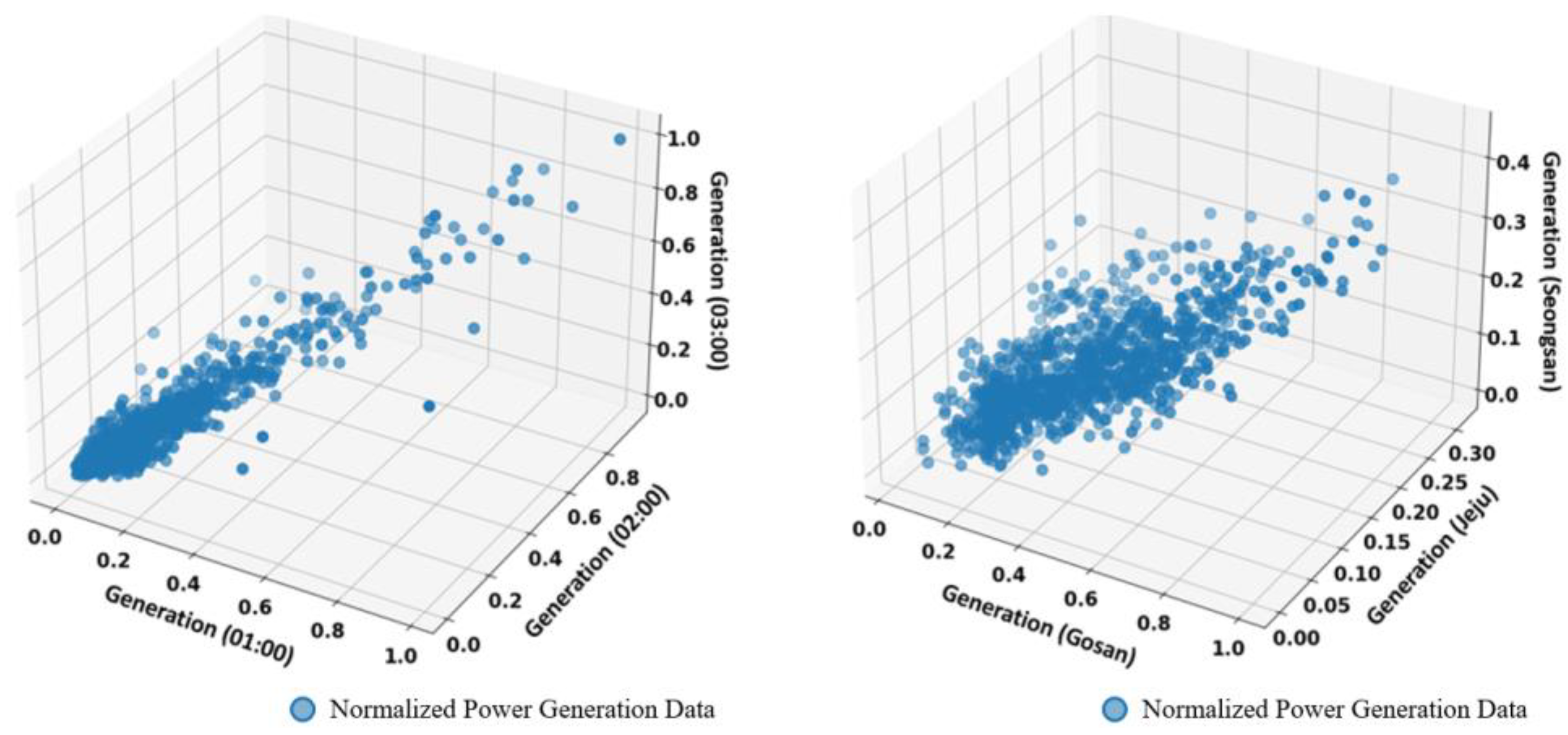
- Neglecting the time series correlation of the wind power, the matrix , representing the spatial correlation among the wind power plants, is generated using the copula function. Its element, , indicates the n-th row element of the m-th sample matrix S.
- (3)
- The random number samples are generated by multiplying the n-th row of the matrix and the n-th row and m-th column elements of the matrix . The random number samples are generated as (). This process is repeated (N × M × T) times to generate the final wind power samples.
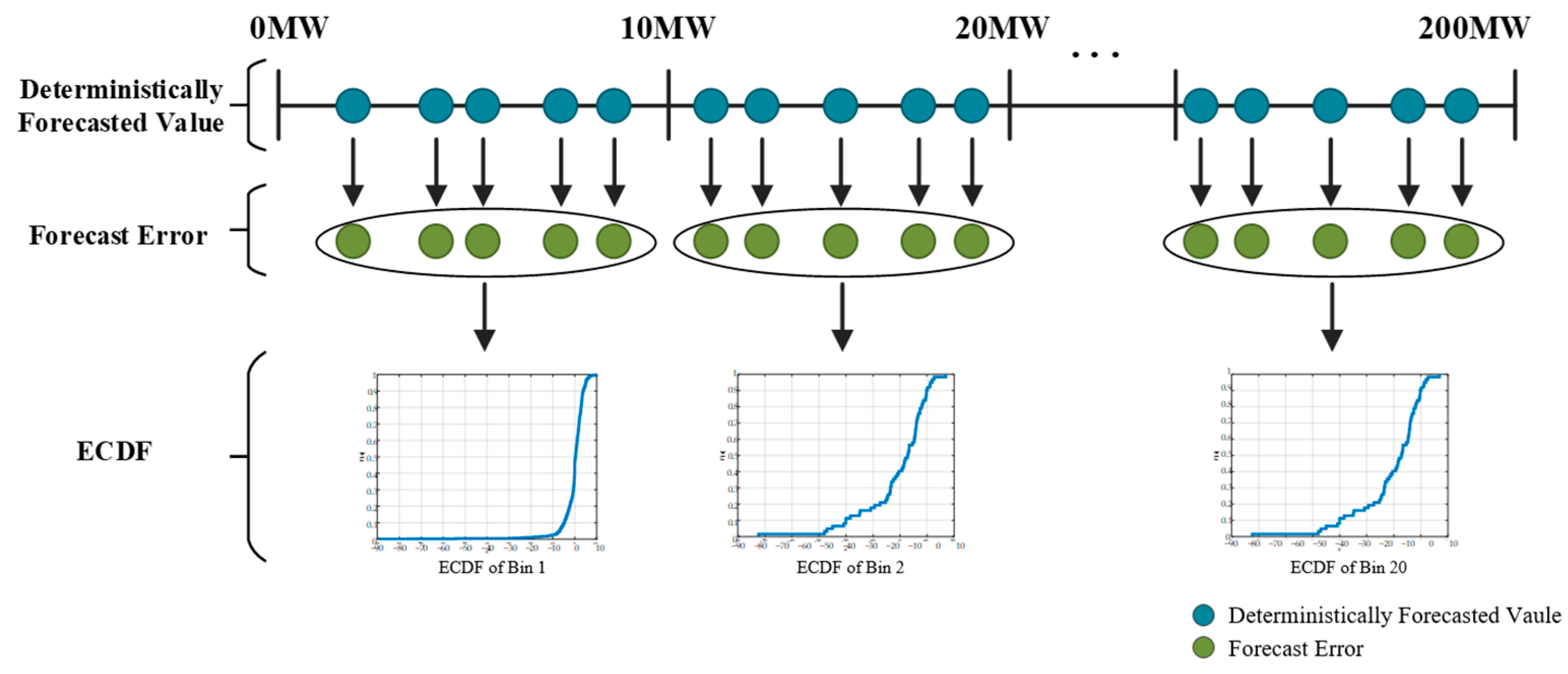
2.3. Generating ECDFs Based on the Errors of a Forecast Model
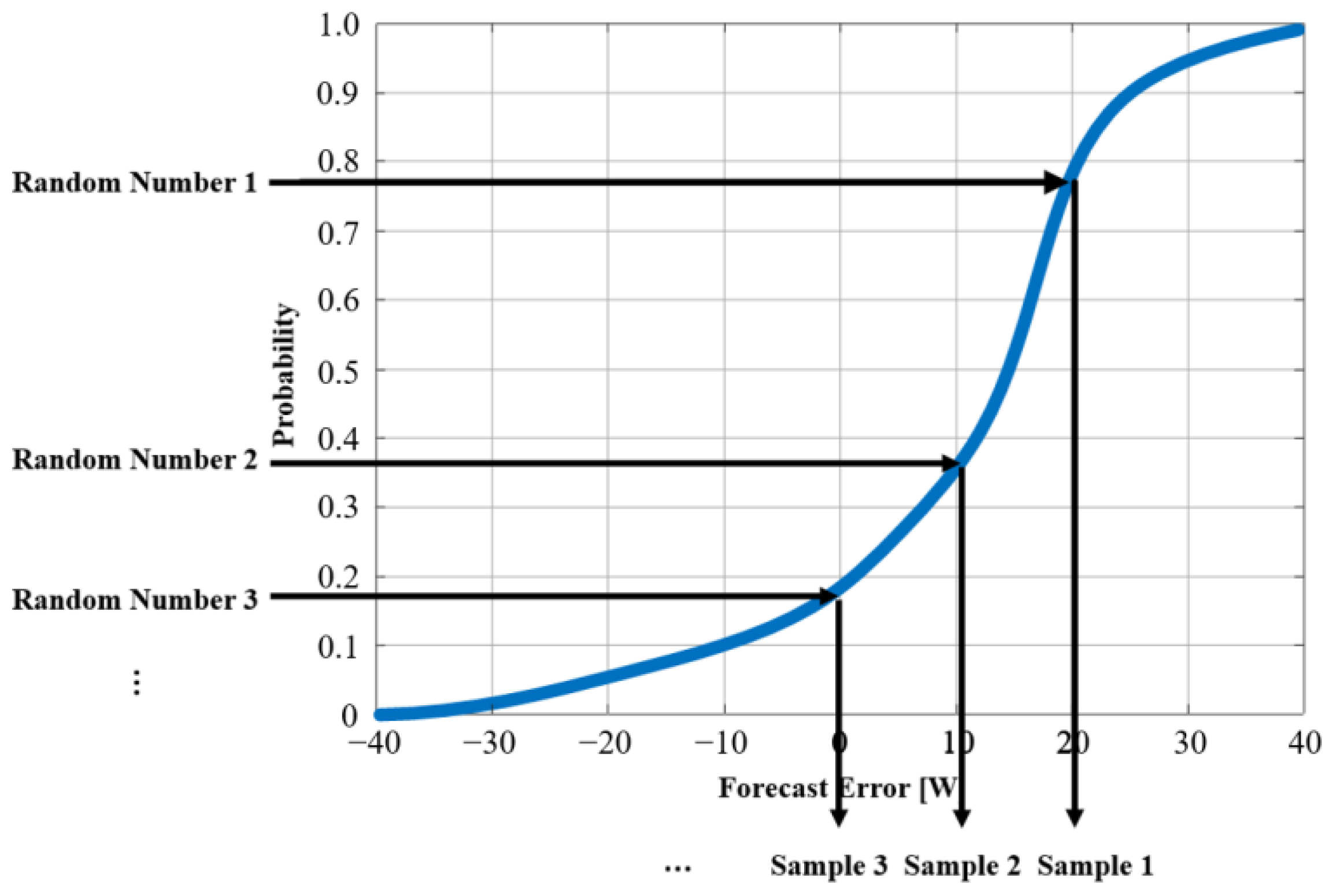
2.4. Generating Scenarios with Inverse Transform Sampling
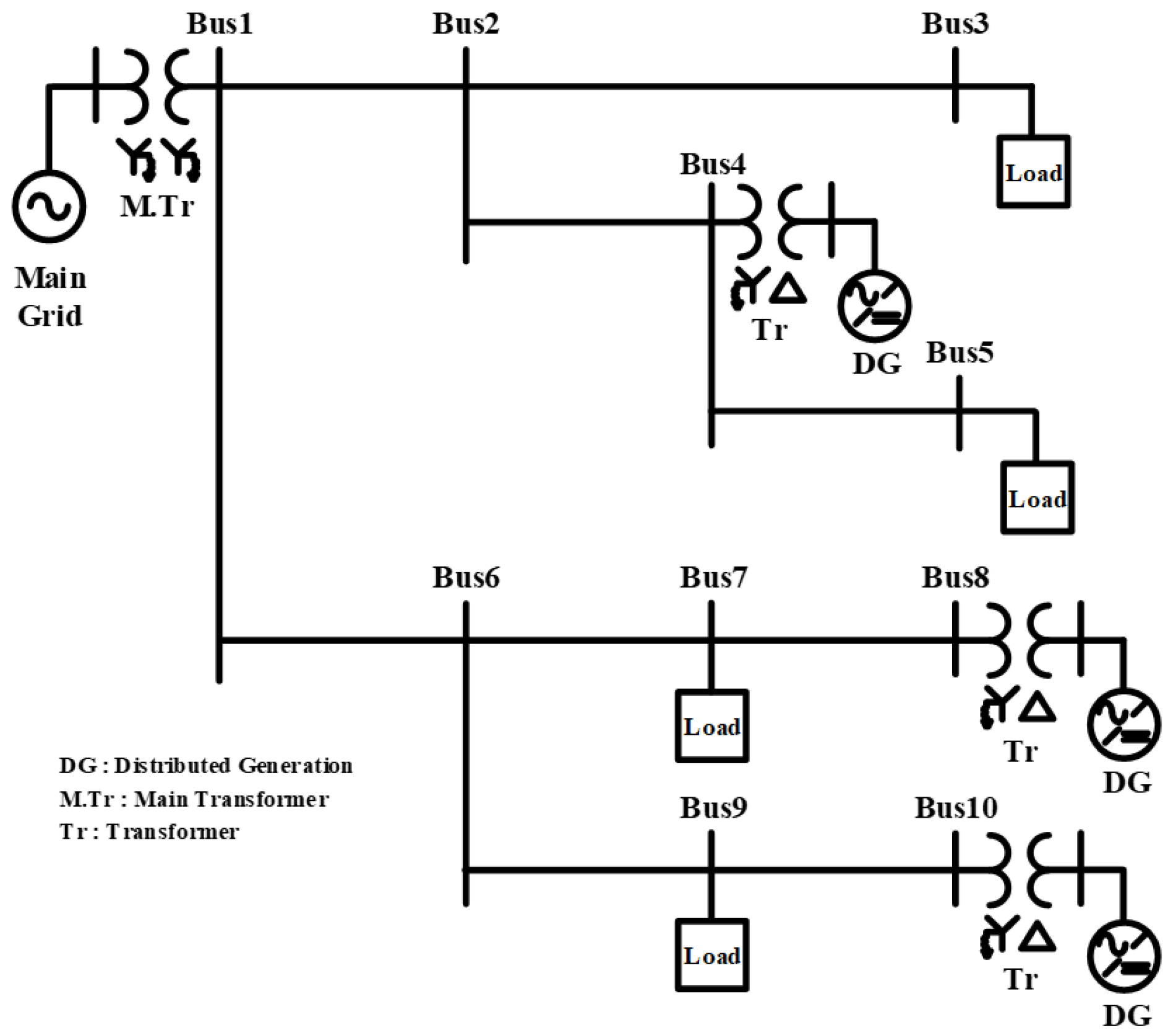
3. Case Study and Discussion
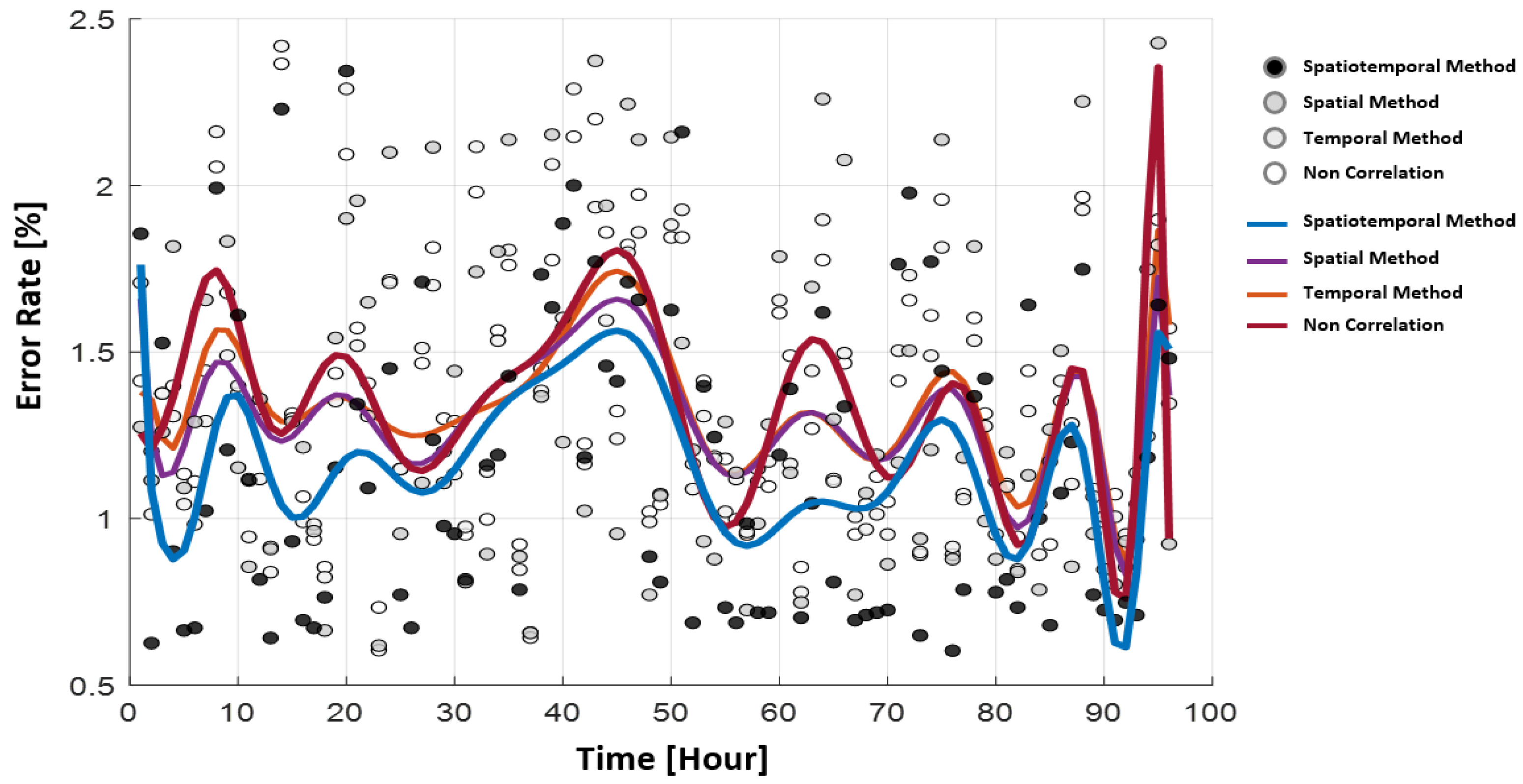
3.1. Verification of Scenario Generation Method
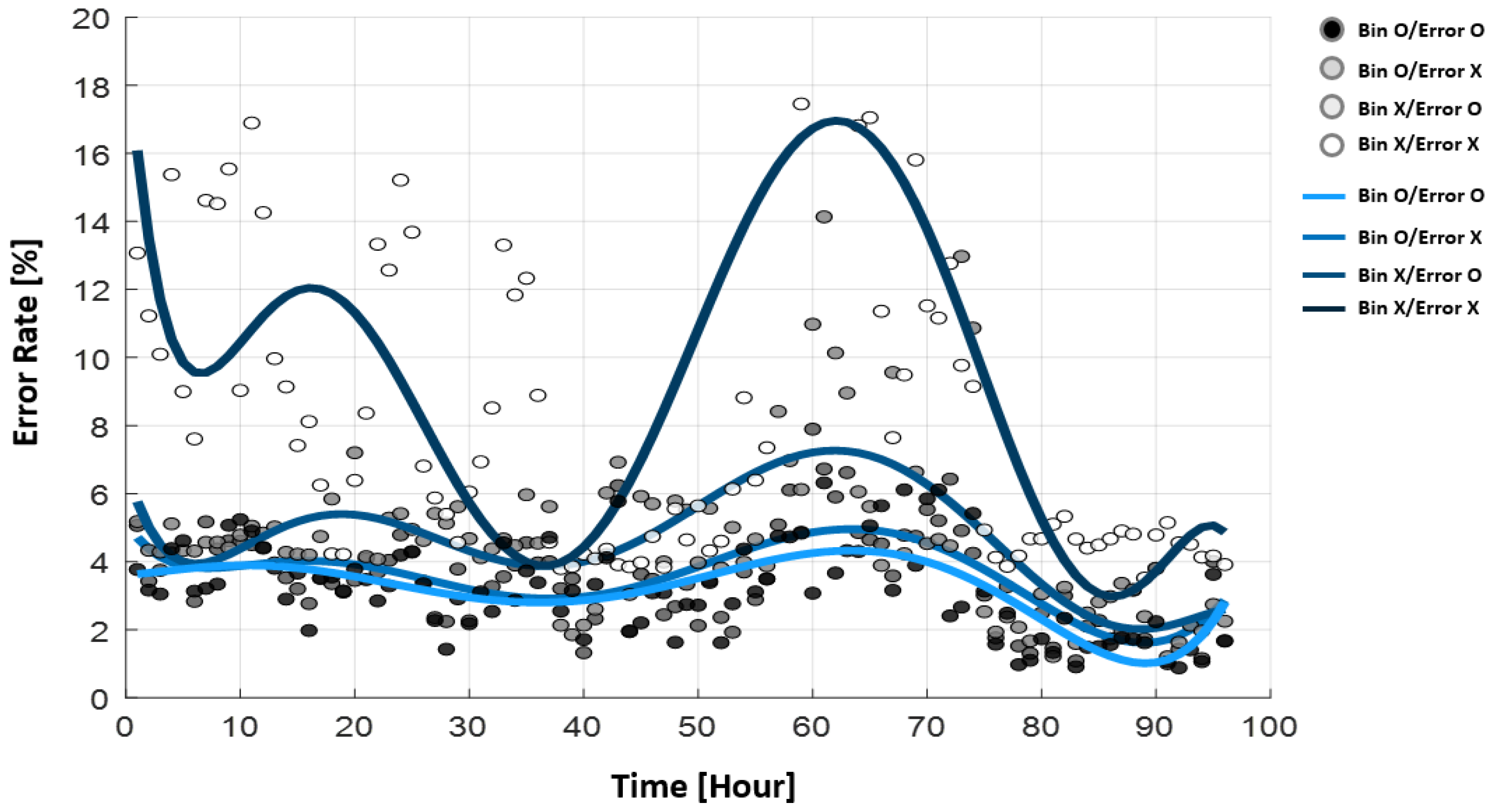
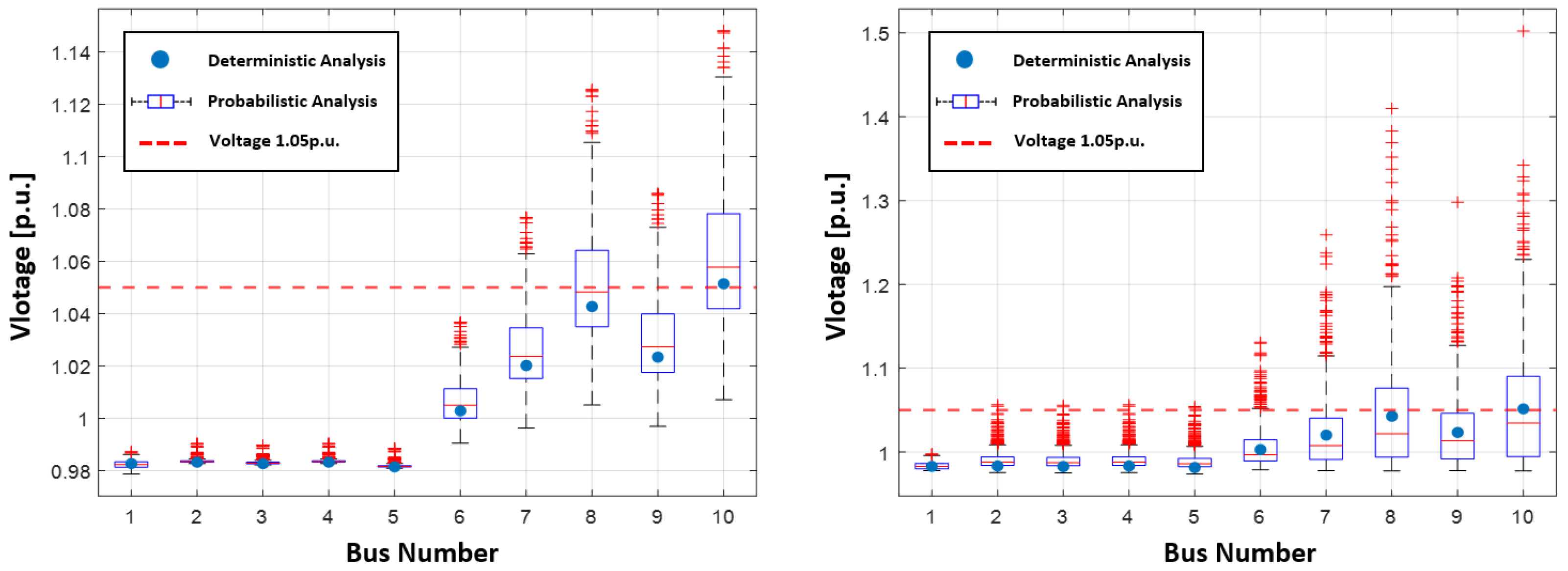
3.2. Probabilistic Distribution System Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmed, F.; Al Kez, D.; McLoone, S.; Best, R.J.; Cameron, C.; Foley, A. Dynamic Grid Stability in Low Carbon Power Systems with Minimum Inertia. Renew. Energy 2023, 210, 486–506. [Google Scholar] [CrossRef]
- Beltrán, J.C.; Aristizábal, A.J.; López, A.; Castaneda, M.; Zapata, S.; Ivanova, Y. Comparative Analysis of Deterministic and Probabilistic Methods for the Integration of Distributed Generation in Power Systems. Energy Rep. 2020, 6, 88–104. [Google Scholar] [CrossRef]
- Hasan, K.N.; Preece, R.; Milanović, J.V. Existing Approaches and Trends in Uncertainty Modelling and Probabilistic Stability Analysis of Power Systems with Renewable Generation. Renew. Sustain. Energy Rev. 2019, 101, 168–180. [Google Scholar] [CrossRef]
- Li, Y.; Peng, X.; Zhang, Y. Forecasting Methods for Wind Power Scenarios of Multiple Wind Farms Based on Spatio-Temporal Dependency Structure. Renew. Energy 2022, 201, 950–960. [Google Scholar] [CrossRef]
- Tu, Q.; Miao, S.; Yao, F.; Li, Y.; Yin, H.; Han, J.; Zhang, D.; Yang, W. Forecasting Scenario Generation for Multiple Wind Farms Considering Time-Series Characteristics and Spatial-Temporal Correlation. J. Mod. Power Syst. Clean Energy 2021, 9, 837–848. [Google Scholar] [CrossRef]
- Sweeney, C.; Bessa, R.J.; Browell, J.; Pinson, P. The Future of Forecasting for Renewable Energy. Wiley Interdiscip. Rev. Energy Environ. 2020, 9, e365. [Google Scholar] [CrossRef]
- Li, J.; Zhou, J.; Chen, B. Review of Wind Power Scenario Generation Methods for Optimal Operation of Renewable Energy Systems. Appl. Energy 2020, 280, 115992. [Google Scholar] [CrossRef]
- Löhndorf, N. An Empirical Analysis of Scenario Generation Methods for Stochastic Optimization. Eur. J. Oper. Res. 2016, 255, 121–132. [Google Scholar] [CrossRef]
- Aslett, L.J.M. Sampling from Complex Probability Distributions: A Monte Carlo Primer for Engineers; Springer: Cham, Switzerland, 2022; ISBN 9783030836399. [Google Scholar]
- Xie, S.; Wang, X.; Qu, C.; Wang, X.; Guo, J. Impacts of Different Wind Speed Simulation Methods on Conditional Reliability Indices. Int. Trans. Electr. Energy Syst. 2013, 20, 1–6. [Google Scholar]
- Cui, M.; Feng, C.; Wang, Z.; Zhang, J.; Wang, Q.; Florita, A.; Krishnan, V.; Hodge, B.-M. Probabilistic Wind Power Ramp Forecasting Based on a Scenario Generation Method. In Proceedings of the 2017 IEEE Power & Energy Society General Meeting, Chicago, IL, USA, 16–20 July 2017. [Google Scholar]
- Rodríguez-Pajarón, P.; Hernández, A.; Milanović, J.V. Probabilistic Assessment of the Impact of Electric Vehicles and Nonlinear Loads on Power Quality in Residential Networks. Int. J. Electr. Power Energy Syst. 2021, 129, 106807. [Google Scholar] [CrossRef]
- Kim, S.O.; Hur, J. Probabilistic Power Output Model of Wind Generating Resources for Network Congestion Management. Renew. Energy 2021, 179, 1719–1726. [Google Scholar] [CrossRef]
- Bu, S.Q.; Du, W.; Wang, H.F.; Chen, Z.; Xiao, L.Y.; Li, H.F. Probabilistic Analysis of Small-Signal Stability of Large-Scale Power Systems as Affected by Penetration of Wind Generation. IEEE Trans. Power Syst. 2012, 27, 762–770. [Google Scholar] [CrossRef]
- Rahman, S.; Saha, S.; Haque, M.E.; Islam, S.N.; Arif, M.T.; Mosadeghy, M.; Oo, A.M.T. A Framework to Assess Voltage Stability of Power Grids with High Penetration of Solar PV Systems. Int. J. Electr. Power Energy Syst. 2022, 139, 107815. [Google Scholar] [CrossRef]
- Wang, H.; Xu, X.; Yan, Z.; Yang, Z.; Feng, N.; Cui, Y. Probabilistic Static Voltage Stability Analysis Considering the Correlation of Wind Power. In Proceedings of the 2016 International Conference on Probabilistic Methods Applied to Power Systems (PMAPS), Beijing, China, 16–20 October 2016. [Google Scholar]
- Bourcet, J.; Kubilay, A.; Derome, D.; Carmeliet, J. Representative Meteorological Data for Long-Term Wind-Driven Rain Obtained from Latin Hypercube Sampling–Application to Impact Analysis of Climate Change. Build. Environ. 2023, 228, 109875. [Google Scholar] [CrossRef]
- Zhao, J.; Bao, Y.; Chen, G. Probabilistic Voltage Stability Assessment Considering Stochastic Load Growth Direction and Renewable Energy Generation. In Proceedings of the 2018 IEEE Power & Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018. [Google Scholar]
- Saraninezhad, M.; Ramezani, M.; Falaghi, H. Probabilistic Assessment of Wind Turbine Impact on Distribution Networks by Using Latin Hypercube Sampling Method. In Proceedings of the2022 9th Iranian Conference on Renewable Energy & Distributed Generation (ICREDG), Mashhad, Iran, 23–24 February 2022; pp. 1–7. [Google Scholar]
- Ding, X.; Peng, M.; Shen, M.; Zhu, L.; Che, H.; Zhou, S.; Li, G.; Liu, R. Wind Power Forecasting Based on Extended Latin Hypercube Sampling. In Proceedings of the 2016 International Conference on Energy, Power and Electrical Engineering, Shenzhen, China, 30–31 October 2016; pp. 57–60. [Google Scholar]
- Deng, J.; Li, H.; Hu, J.; Liu, Z. A New Wind Speed Scenario Generation Method Based on Spatiotemporal Dependency Structure. Renew. Energy 2021, 163, 1951–1962. [Google Scholar] [CrossRef]
- Leng, R.; Li, Z.; Xu, Y. Two-Stage Stochastic Programming for Coordinated Operation of Distributed Energy Resources in Unbalanced Active Distribution Networks with Diverse Correlated Uncertainties. J. Mod. Power Syst. Clean Energy 2023, 11, 120–131. [Google Scholar] [CrossRef]
- Ma, X.Y.; Sun, Y.Z.; Fang, H.L. Scenario Generation of Wind Power Based on Statistical Uncertainty and Variability. IEEE Trans. Sustain. Energy 2013, 4, 894–904. [Google Scholar] [CrossRef]
- Krishna, A.B.; Abhyankar, A.R. Time-Coupled Day-Ahead Wind Power Scenario Generation: A Combined Regular Vine Copula and Variance Reduction Method. Energy 2023, 265, 126173. [Google Scholar] [CrossRef]
- Lee, R.; Kim, G.; Hur, J.; Shin, H. Advanced Probabilistic Power Flow Method Using Vine Copulas for Wind Power Capacity Expansion. IEEE Access 2022, 10, 114929–114941. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Non-Correlation Method (%) | Spatial Method (%) | Temporal Method (%) | Spatiotemporal Method (%) |
|---|---|---|---|---|
| I | 12.5058 | 11.9763 | 11.9384 | 11.1801 |
| II | 39.2320 | 39.2234 | 38.9961 | 38.9237 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, J.; Son, Y.; Yoon, M.; Choi, S. A Wind Power Scenario Generation Method Based on Copula Functions and Forecast Errors. Sustainability 2023, 15, 16536. https://doi.org/10.3390/su152316536
Yoo J, Son Y, Yoon M, Choi S. A Wind Power Scenario Generation Method Based on Copula Functions and Forecast Errors. Sustainability. 2023; 15(23):16536. https://doi.org/10.3390/su152316536
Chicago/Turabian StyleYoo, Jaehyun, Yongju Son, Myungseok Yoon, and Sungyun Choi. 2023. "A Wind Power Scenario Generation Method Based on Copula Functions and Forecast Errors" Sustainability 15, no. 23: 16536. https://doi.org/10.3390/su152316536