
Evaluation of Tropical Cyclone Disaster Loss Using Machine Learning Algorithms with an eXplainable Artificial Intelligence Approach
 ,
,
Abstract
:1. Introduction
2. Data and Methods
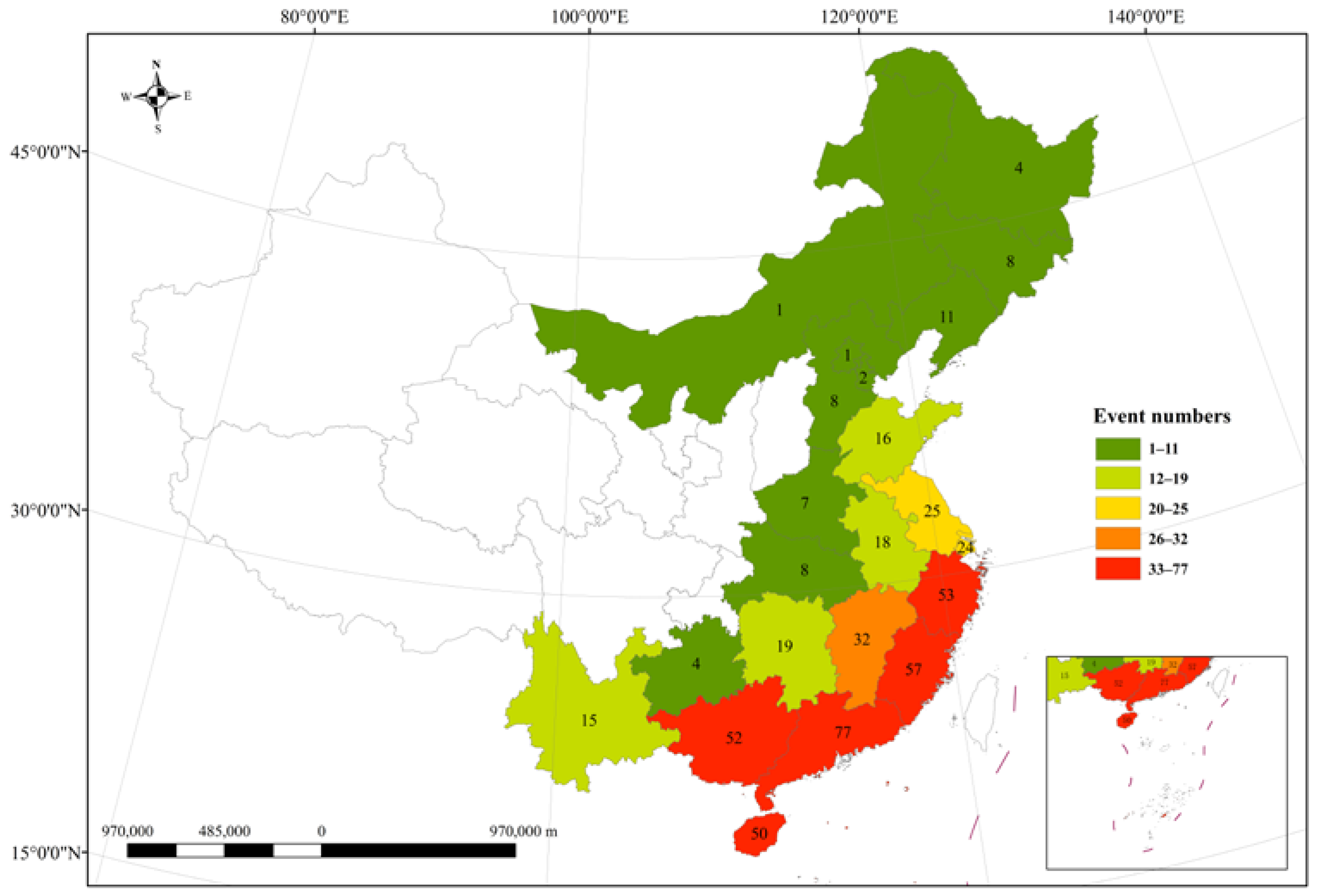
2.1. Data Sources
2.2. Data Preparations
2.2.1. Adjustment of Economic Indicators
2.2.2. Normalization
2.2.3. Comprehensive Disaster Grade
2.3. TCDL Evaluation System
2.3.1. Dataset
2.3.2. Model Tuning
2.3.3. Evaluation Metrics of Models
2.4. SHapley Additive exPlanations (SHAP)
3. Results
3.1. Model Evaluation
3.2. Interpretation of the LightGBM Model
3.2.1. SHAP Summary Plots
3.2.2. SHAP Dependence Plots
3.2.3. Probability Waterfall Plots for Single Samples
4. Discussion
5. Conclusions
- Among the four ML models (LightGBM, RF, SVM, NB), LightGBM demonstrates superior performance, achieving the highest values for accuracy (0.86), recall (0.83), precision (0.83), and F1 score (0.83).
- For the estimation of all three classes (low, moderate, high) of TCDL, ProRain (proportion of stations with rainfall exceeding 50 mm) and MaxWind (maximum wind speed) exhibit notable significance. And their contributions to TCDL grade prediction are approximately twice as substantial as those of other feature factors. In contrast, the impact of vulnerability factors is relatively lower when compared to hazard and resilience factors in general.
- Specifically, the impact of each feature factor on the model’s prediction varies across in the low, moderate, and high classes of TCDL. In terms of the high class, events characterized by MaxWind (maximum wind speed) with values exceeding 30 m/s, MaxRain (maximum daily rainfall) with values exceeding 200 mm, and ProRain (proportion of stations with rainfall exceeding 50 mm) with values exceeding 30% tend to present a higher risk of TCDL.
- Future work will focus on incorporating remote sensing data for enhanced coverage and spatial resolution, along with exploring other additive SHAP properties for TCDL assessment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bakkensen, L.A.; Mendelsohn, R.O. Global tropical cyclone damages and fatalities under climate change: An updated assessment, hurricane risk. In Hurricane Risk; Collins, J.M., Walsh, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 179–197. [Google Scholar]
- Dube, S.; Jain, I.; Rao, A.; Murty, T. Storm surge modelling for the bay of Bengal and Arabian Sea. Nat. Hazards 2009, 51, 3–27. [Google Scholar] [CrossRef]
- Krapivin, V.F.; Soldatov, V.Y.; Varotsos, C.A.; Cracknell, A.P. An adaptive information technology for the operative diagnostics of the tropical cyclones; solar-terrestrial coupling mechanisms. J. Atmos. Sol. Terr. Phys. 2012, 89, 83–89. [Google Scholar] [CrossRef]
- Sahoo, B.; Bhaskaran, P.K. Multi-hazard risk assessment of coastal vulnerability from tropical cyclones—A GIS based approach for the Odisha coast. J. Environ. Manag. 2018, 206, 1166–1178. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhao, S.; Wang, G. Spatiotemporal variations in meteorological disasters and vulnerability in China during 2001–2020. Front. Earth Sci. 2021, 9, 789523. [Google Scholar] [CrossRef]
- Moon, I.J.; Kim, S.H.; Chan, J. Climate change and tropical cyclone trend. Nature 2019, 570, 3–5. [Google Scholar] [CrossRef]
- Knutson, T.; Camargo, S.J.; Chan, J.C.L.; Emanuel, K.; Ho, C.-H.; Kossin, J.; Mohapatra, M.; Satoh, M.; Sugi, M.; Walsh, K.; et al. Tropical cyclones and climate change assessment: Part ii: Projected response to anthropogenic warming. Bull. Amer. Meteor. Soc. 2020, 101, 303–322. [Google Scholar] [CrossRef]
- Schiermeier, Q. Hurricane link to climate change is hazy. Nature 2005, 437, 461. [Google Scholar] [CrossRef] [Green Version]
- Mendelsohn, R.; Emanuel, K.; Chonabayashi, S.; Bakkensen, L. The impact of climate change on global tropical cyclone damage. Nat. Clim. Chang. 2012, 2, 205–209. [Google Scholar] [CrossRef]
- Peduzzi, P.; Chatenoux, B.; Dao, H.; De, B.A.; Herold, C.; Kossin, J.; Mouton, F.; Nordbeck, O. Global trends in tropical cyclone risk. Nat. Clim. Chang. 2012, 2, 289–294. [Google Scholar] [CrossRef]
- Gettelman, A.; Bresch, D.N.; Chen, C.C.; Truesdale, J.E.; Bacmeister, J.T. Projections of future tropical cyclone damage with a high-resolution global climate model. Clim. Chang. 2018, 146, 575–585. [Google Scholar] [CrossRef]
- Nam, C.C.; Park, D.R.; Ho, C.; Chen, D. Dependency of tropical cyclone risk on track in South Korea. Nat. Hazard Earth Sys. 2018, 18, 3225–3234. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, S.; Kemfert, C.; Hoeppe, P. The impact of socio-economics and climate change on tropical cyclone losses in the USA. Reg. Environ. Chang. 2010, 10, 13–26. [Google Scholar] [CrossRef] [Green Version]
- Yonson, R.; Noy, I.; Gaillard, J.C. The measurement of disaster risk: An example from tropical cyclones in the Philippines. Rev. Dev. Econ. 2018, 22, 736–765. [Google Scholar] [CrossRef]
- Ye, M.; Wu, J.; Liu, W.; He, X.; Wang, C. Dependence of tropical cyclone damage on maximum wind speed and socioeconomic factors. Environ. Res. Lett. 2020, 15, 094061. [Google Scholar] [CrossRef]
- Sun, H.; Wang, J.; Ye, W. A Data Augmentation-Based Evaluation System for Regional Direct Economic Losses of Storm Surge Disasters. Int. J. Environ. Res. Public Health 2021, 18, 2918. [Google Scholar] [CrossRef]
- Abbot, J.; Marohasy, J. Input selection and optimisation for monthly rainfall forecasting in Queensland, Australia, using artificial neural networks. Atmos. Res. 2014, 138, 166–178. [Google Scholar] [CrossRef]
- Sahin, E.K. Assessing the predictive capability of ensemble tree methods for landslide susceptibility mapping using XGBoost, gradient boosting machine, and random forest. SN Appl. Sci. 2020, 2, 1308. [Google Scholar] [CrossRef]
- Saber, M.; Boulmaiz, T.; Guermoui, M.; Abdrabo, K.I.; Kantoush, S.A.; Sumi, T.; Boutaghane, H.; Nohara, D.; Mabrouk, E. Examining LightGBM and CatBoost models for wadi flash flood susceptibility prediction. Geocarto Int. 2021, 37, 7462–7487. [Google Scholar] [CrossRef]
- Zhang, H.; Song, Y.; Xu, S.; He, Y.; Li, Z.; Yu, X.; Liang, Y.; Wu, W.; Wang, Y. Combining a class-weighted algorithm and machine learning models in landslide susceptibility mapping: A case study of Wanzhou section of the Three Gorges Reservoir, China. Computers. Geosci. 2022, 158, 104966. [Google Scholar] [CrossRef]
- Darvishi, B.A.; Neysani, S.N.; Papi, R.; Soleimani, M. Dust source susceptibility mapping in Tigris and Euphrates basin using remotely sensed imagery. CATENA 2022, 209, 105795. [Google Scholar] [CrossRef]
- Panahi, M.; Rahmati, O.; Rezaie, F.; Lee, S.; Mohammadi, F.; Conoscenti, C. Application of the group method of data handling (GMDH) approach for landslide susceptibility zonation using readily available spatial covariates. CATENA 2022, 208, 105779. [Google Scholar] [CrossRef]
- Zhang, Y.; Ge, T.; Tian, W.; Liou, Y.-A. Debris flow susceptibility mapping using machine-learning techniques in Shigatse Area, China. Remote Sens. 2019, 11, 2801. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Chakraborty, D.; Basagaoglu, H.; Winterle, J. Interpretable vs. noninterpretable machine learning models for data-driven hydro-climatological process modelling. Expert Syst. Appl. 2021, 170, 114498. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B. Why interpretable machine learning algorithms should be used in drought forecasting? In Proceedings of the Natural Hazards Alerts, NSF Convergence Workshop, Online, 24–28 May 2021.
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. USA 1953, 39, 1095–1100. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Felsche, E.; Ludwi, R. Applying machine learning for drought prediction in a perfect model framework using data from a large ensemble of climate simulations. Nat. Hazards Earth Syst. Sci. 2021, 21, 3679–3691. [Google Scholar] [CrossRef]
- Aydin, H.E.; Iban, M.C. Predicting and analyzing flood susceptibility using boosting-based ensemble machine learning algorithms with SHapley Additive ExPlanations. Nat. Hazards 2023, 116, 2957–2991. [Google Scholar] [CrossRef]
- Iban, M.C.; Bilgilioglu, S.S. Snow avalanche susceptibility mapping using novel tree-based machine learning algorithms (XGBoost, NGBoost, and LightGBM) with eXplainable Artificial Intelligence (XAI) approach. Stoch. Environ. Res. Risk Assess. 2023, 37, 2243–2270. [Google Scholar] [CrossRef]
- An, S.; Wang, J.; Wei, J. Local-Nearest-Neighbors-Based Feature Weighting for Gene Selection. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 15, 1538–1548. [Google Scholar] [CrossRef]
- An, S.; Wang, J.; Wei, J.; Yang, Z. Unsupervised Feature Selection with Joint Clustering Analysis. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, Singapore, 6–10 November 2017; pp. 1639–1648. [Google Scholar]
- Lou, W.; Chen, H.; Shen, X.; Sun, K.; Deng, S. Fine assessment of tropical cyclone disasters based on GIS and SVM in Zhejiang Province, China. Nat. Hazards 2012, 64, 511–529. [Google Scholar] [CrossRef]
- Fricker, T.; Elsner, J.B.; Jagger, T.H. Population and energy elasticity of tornado casualties. Geophys. Res. Lett. 2017, 44, 3941–3949. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, J.; Li, X.; Du, X.; Zhao, T.; Hou, Q.; Jin, X. Estimating the grade of storm surge disaster loss in coastal areas of china via machine learning algorithms. Ecol. Indic. 2022, 136, 108533. [Google Scholar] [CrossRef]
- China Meteorological Administration (CMA). Yearbook of Meteorological Disasters in China 2000–2020; China Meteorological Press: Beijing, China, 2021. (In Chinese) [Google Scholar]
- Wang, X.R.; Zhang, L.S.; Li, W.B. Improvement and application analysis of the comprehensive grade evaluation model of typhoon disaster. Meteor. Mon. 2018, 44, 304–312. (In Chinese) [Google Scholar]
- Mohammadifar, A.; Gholami, H.; Comino, J.R.; Collins, A.L. Assessment of the interpretability of data mining for the spatial modelling of water erosion using game theory. CATENA 2021, 200, 105178. [Google Scholar] [CrossRef]
- Iban, M.C.; Sekertekin, A. Machine learning based wildfire susceptibility mapping using remotely sensed fire data and GIS: A case study of Adana and Mersin provinces. Turk. Ecol. Inf. 2022, 69, 101647. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, H.; Li, Z.; Zhang, H.; Zhang, W. An interpretable model for the susceptibility of rainfall-induced shallow landslides based on SHAP and XGBoost. Geocarto Int. 2022, 37, 13419–13450. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Indicator | Short Name | Data Source |
|---|---|---|---|
| Hazard | Maximum daily rainfall (mm) | MaxRain | Dataset of basic meteorological elements from surface meteorological stations in China (v3.0) (http://idata.cma/, accessed on 1 May 2023) |
| Proportion of stations with rainfall exceeding 50 mm (%) | ProRain | ||
| Maximum wind speed (m/s) | MaxWind | ||
| Proportion of stations with wind speed exceeding 14 m/s (%) | ProWind | ||
| Vulnerability | Provincial GDP (billion) | GDP | National bureau of statistics (http://www.stats.gov.cn/, accessed on 1 May 2023) |
| Population | POP | ||
| Population density per km2 | POPDens | ||
| Area of agricultural crop sown (hm2) | CropArea | ||
| Area of buildings constructed (m2) | ConsArea | ||
| Area of buildings completed (m2) | ComArea | ||
| Total line length of bus and trolley bus operation lines (km) | BUS | ||
| Resilience | Beds of medical institutions per 10,000 people | MedBeds | National bureau of statistics (http://www.stats.gov.cn/, accessed on 1 May 2023) |
| Telephones per 100 people | TEL | ||
| Internet per 10,000 people | NET | ||
| Per capita GDP | PCGDP | ||
| TCDL | Direct economic loss (billion) | — | Yearbook of meteorological disasters in China during 2000–2020 [37] |
| Casualties | — | ||
| Affected area (hm2) | — | ||
| Collapsed houses | — |
| Casualty | Actual Economic Loss | Collapsed Houses | Affected Area | |
|---|---|---|---|---|
| Weight | 0.33 | 0.27 | 0.21 | 0.19 |
| Parameter | Dynamic Range | Optimal Value |
|---|---|---|
| num_leaves | Max number of leaves in one tree [10, 15, 20, 25, 30] | 15 |
| max_depth | Maximum depth of the tree [5, 6, 7, 8, 9] | 7 |
| max_bin | Max number of bins [5, 10, 15, 20, 25] | 10 |
| min_leaf | Minimal number of data in one leaf [10, 15, 20, 25, 30] | 20 |
| fea_frac | Fraction of features randomly selected on each tree [0.6, 0.8, 1.0] | 1.0 |
| learn_rate | Shrinkage rate [0.01, 0.03, 0.05, 0.1] | 0.01 |
| n_estimators | Number of boosting iteration [50, 100, 150, 200, 250] | 100 |
| Accuracy | Recall | Precision | F1 | |
|---|---|---|---|---|
| LightGBM | 0.86 | 0.83 | 0.83 | 0.83 |
| RF | 0.71 | 0.7 | 0.72 | 0.7 |
| SVM | 0.64 | 0.54 | 0.52 | 0.53 |
| NB | 0.64 | 0.63 | 0.67 | 0.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Liu, Y.; Chu, Z.; Yang, K.; Wang, G.; Zhang, L.; Zhang, Y. Evaluation of Tropical Cyclone Disaster Loss Using Machine Learning Algorithms with an eXplainable Artificial Intelligence Approach. Sustainability 2023, 15, 12261. https://doi.org/10.3390/su151612261
Liu S, Liu Y, Chu Z, Yang K, Wang G, Zhang L, Zhang Y. Evaluation of Tropical Cyclone Disaster Loss Using Machine Learning Algorithms with an eXplainable Artificial Intelligence Approach. Sustainability. 2023; 15(16):12261. https://doi.org/10.3390/su151612261
Chicago/Turabian StyleLiu, Shuxian, Yang Liu, Zhigang Chu, Kun Yang, Guanlan Wang, Lisheng Zhang, and Yuanda Zhang. 2023. "Evaluation of Tropical Cyclone Disaster Loss Using Machine Learning Algorithms with an eXplainable Artificial Intelligence Approach" Sustainability 15, no. 16: 12261. https://doi.org/10.3390/su151612261