1. Introduction
Within an ecosystem-oriented reflection, the concepts of green infrastructures, nature-based solutions and ecosystem services are today commonly considered an integral part of the theme of the urban bioregion. And an inherent character of complexity is associated with the concept of urban bioregion. Complexity certainly suggests high operational and management difficulties, but it also witnesses the richness of our spatial, relational and social contexts. The present paper is part of a research work aiming to address and manage complex environmental issues using the concept of
semantic web [
1], which allows shared interpretations of knowledge coming from different languages and scientific domains.
According to Thayer, in fact, a bioregion is a space limited by non-political but natural borders around geographical, climatic, hydrological and ecological features supporting living communities [
2]. This interpretation involves the need to define spatial planning and organizations that are capable of structuring those processes in a balanced and sustainable way. The difficulty of such a structuring effort is actually quite clear, even by just recalling the historical roots of this bioregional thought. In fact, one can look at the pioneering reflections of Howard and Geddes between the late nineteenth and early twentieth centuries, up to Lewis Mumford’s studies. It can be noted that the correspondence between ecological regionalism and spatial planning and organization tends to remain a theoretical expectation. In particular, the subsequent human-led transformative actions, especially of a technological and industrial type, tended to break ecosystem cycles rather than to favor natural co-evolution over time [
3,
4,
5]. Cities, especially, which are huge transformation entities on territories, are finally carrying out processes of constant divergence between productions of natural life and consumptions developed by urban metabolism. Newman and Jennings argue that cities stimulate consumption of resources beyond the actual availability of their related regions. This makes that territory essentially unable to support the city as a socioeconomic ecosystem and subject to further passive transformation and consumption [
6], p. 188. The possibility of operationally setting up an urban bioregion is therefore dependent on the possibility of closing local production and consumption cycles. In a world where more than half of the population now resides in urban areas, these processes are clearly and intrinsically necessary for the survival of urban areas themselves [
6], p. 189. Indeed, it is a literally complex context, which calls for the restoration of its sustainable ecosystem layout through suitable environmental planning strategies [
2], p. 144. But this strategic approach actually proves to be similarly complex in itself. In fact, following the previous reasoning, it should involve spatially articulated and dynamically differentiated decisions towards the natural environment, the physically transformed environment, the bioregional environmental regeneration circles, the careful management of local resources, as well as towards the social and individual needs and behaviors, the local closing circles of supply and demand [
6], p. 212. And in order to implement these decisions, the approach should be structured on knowledge bases of related phenomena, processes and agents, as a support to informed and sustainable decisions. Indeed, when environmental planning places a knowledge-oriented emphasis on ecosystem services, green infrastructures and nature-based processes, it fits quite well into this perspective. In that case, it can definitely represent the attempt to structure levels and paths to support the re-functionalization of an urban bioregion [
2], p. 54.
In this context, a famous reflection by Reiniger [
7] states that bioregional planning represents an opportunity for understanding the complexity of ecosystems in relation to regional culture. The theme of knowledge therefore clearly emerges as a central element in eco-systemically sustainable spatial planning activities.
In general, environmental planning today tends to be based on knowledge from social participation. Then, such knowledge becomes more and more structurally integrated with the expert knowledge of the domain [
8,
9]. Plans increasingly use rationalities of multi-agent knowledge [
10], coming from place-based (rather than general) systems of knowledge and reasoning [
11,
12]. Within plans, in particular within territorial community plans, the transition from systems of exclusively expert, formal knowledge to systems of diffused, multi-agent knowledge has created significant problems of understanding and managing the knowledge itself [
13]. This circumstance has paved the way for new methods of environmental planning, in general based more on ‘soft’ and ‘hard’ computations than in the past. They are assisted by specific tools to deal with extended dialogues, with massive amounts of words and associated linguistic variables, as well as with languages from different scientific domains [
12,
14,
15,
16,
17]. New approaches to quantitative geography and spatial cognition have also brought new ideas and methods into the planning domain [
18,
19,
20,
21,
22].
Indeed, even some doubts have arisen about the effectiveness of traditional participatory planning. Urban and territorial systems show highly complex socio-environmental processes and dynamics, difficult to manage in participatory arenas with their typical turbulence and ‘distortions’ [
23]. When only ideals of democracy and mediation shape participatory planning, unaware of the knotty problems and tasks of knowledge engineering to be addressed, the situation clearly becomes very challenging.
A participatory environmental plan involves large amounts of data. They come from informal multi-agent arenas managed to foster democracy and task success but also from the formal knowledge of scientific experts. Therefore, the relevant planning steps are made particularly challenging by the need to interpret and structure both formal and informal, multi-source data sets. The aim is to trigger this multiform system of knowledge on the architectures of a spatial plan, traditionally fixed and rigid, as well as to address the dynamic character of knowledge in environmental processes—a hard nondeterministic (
NP-hard) problem able to produce unsustainable plans, if unproperly managed [
24].
Problems are also emphasized by the fact that the participatory dimension of environmental planning is often oriented to mediate between two extremes of free action or inaction (that is, using urban structures with little or no consideration of the natural environment or conversely leaving the natural environment uncontaminated). Until recently, given a transformational aim, policymakers have sought consensus strategies with the participating community to achieve that aim [
25]. Indeed, it tends to be an outdated approach now, due to a new political and planning consciousness, stimulated by the protection of the systemic and indivisible nature of the natural environment—humans included—and not necessarily prevailing [
26].
Arguably, many facets of the logic of environmental and, in particular, participatory planning can be seen as essentially outdated. Today, democratic planning methods and models are increasingly conceptualized as cognitive exercises [
27]. Many scholars recognize them as voluntary processes of multi-agent, multi-source and cross-domain knowledge in the field of socio-environmental cognition [
10,
28,
29].
Clearly, in this highly complex context, the need for models and architectures of data processing and knowledge management becomes essential. The management of this universe of formal, informal, multi-domain and multi-agent data takes place through conceptualizations of different origins. Yet these conceptualizations need to interact with one another and to remain connected through relations with explicit significance links. This would allow the support of knowledge and decision-managing in bioregional areas. It is also clear that in an environmental context, the treatment of elements and primitives cannot be easily undertaken, given the intricate relations characterizing ecosystems. However, there are still some common peculiarities when dealing with socio-environmental systems, especially based on urban bioregions, which affect structural and infrastructural areas of ecological regeneration. In fact, a common feature of the knowledge domains of ecosystem services, nature-based solutions and green infrastructures is the water resource. It can be said that efforts to implement knowledge management models in the field of water and hydrology can have a double value. On the one hand, the model could act as a support architecture for knowledge management and decisions in an area that is cross-cutting and structural in environmental planning. Secondly, an effort to model knowledge in the hydrological field could represent a flagship initiative. It would aim at possibly extending the approach to more complex and extensive areas of the environmental domain—in a sustainable planning perspective.
A study toward an applied ontology model for environmental decision-making and planning is proposed here, just as in the above context. It is based on the concept of formal interpretation of languages originating from the semantic web to allow shared interpretations of knowledge coming from different languages and scientific domains [
1]. The use of the ontological approach in environmental planning can be found in the recent literature of planning models [
20]. It derives from the need to manage the environmental, social and relational complexity of anthropized ecosystems in a dynamic and multi-agent perspective. For example, previous studies have proved to be interesting for structuring the various spatial and cognitive levels of cities: environmental, social, building, functional, etc. [
30]. These are attempts to include aspects of complexity in environmental management and planning, traditionally linked to more manageable environmental reductionisms and standardizations of social behaviors [
14,
15]. Scientific research is still in a preliminary stage, due to greater difficulty compared to traditional models, and so is the present study; yet it shows encouraging perspectives.
The work is oriented just towards the above research direction. That is, the main research question is to explore the possible setting up of a semantic-based model to manage multiagent water-related knowledge as a reference model for environmental planning purposes. A specific objective has been to analyze the model’s aptitude to support the creation and development of water-related knowledge contents enriched with semantic extensions [
1]. A further research objective has been to investigate the possible interoperability of the system architecture in a sustainable planning perspective. Therefore, after the present introduction, the second section explores aspects of interaction between system and user, framed in the actual research context, as well as the perspectives of realization and implementation of a knowledge management system, particularly concerning knowledge contents. Additionally, a deeper argument on the ontological approach is provided in the same section, for better clarity. The paper ends with a final section commenting on possible ontological modeling based on web ontology language (
OWL) features, with follow-up remarks.
2. Materials and Methods
Hydrology has always been an interdisciplinary science, with important connections to physical geography, general geosciences and civil engineering. The hydrological cycle joins many other domains of the natural sciences and the integration of the latter, for a broader and more in-depth understanding of water systems, requires the collaboration of several scientists from the respective domains [
31].
Hydrology is also an applied science, and the knowledge that belongs to it has important practical implications. Engineering professionals of different branches, natural science professionals, hydrologists, public health professionals, policy makers, economists, social professionals, ecologists, geoscientists, urban planners, employees of the public and private organizations that are interested in the landscape are part of the water resource management processes [
32]. Thus, even the improvement of water management may depend on an increase in the degree of interdisciplinarity [
33].
The clarification of the theoretical and practical differences of the aforementioned disciplines as well as the correct specification of the respective data and language differences becomes of great importance [
34,
35]. Interdisciplinarity is evidently linked to issues of language and semantic meaning. For this very reason, there is currently an increase in the demand for knowledge management IT platforms that can provide support for the management of water resources [
36]. Here, we intend to explore the establishment and use of a knowledge management system (KMS) extended with semantic technologies in the scientific domains of hydrology, toward the definition of a useful tool to address some of the needs described [
37].
Furthermore, the possibility for a large group of users to easily create, test, reuse, extend and maintain contents and meanings would be a further advantage of the tool in question.
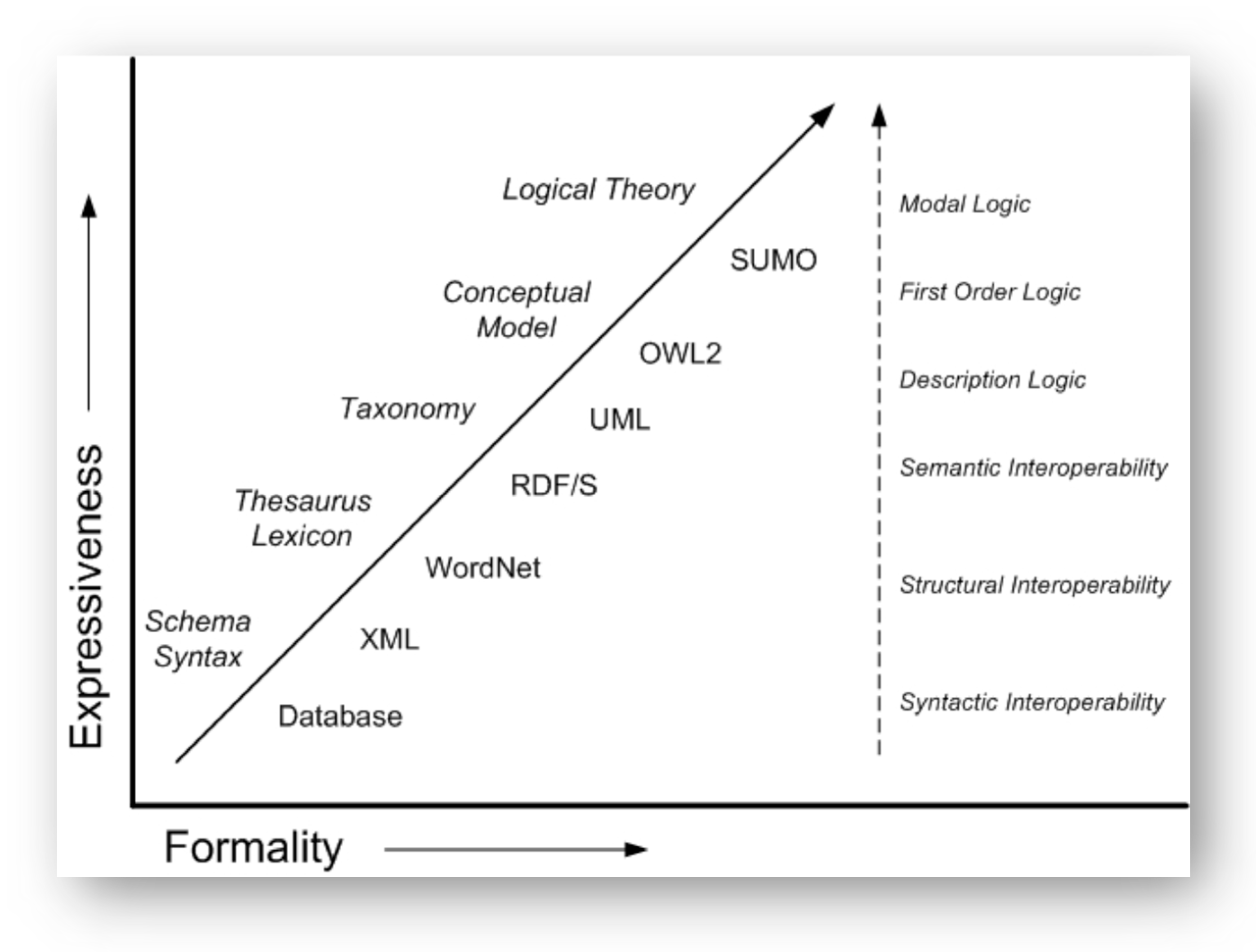
The idea is to create and test a web platform that allows describing a certain set of knowledge in a simple way for the average user (everyone who has the ability to write an email, for example) and automatically obtain a formalized description of this set. This formal description, usable by computers via web semantic technologies (semantic extension), is expressed in the OWL language. As the ability to express and formally represent information increases, the level of complexity of the technology used increases rapidly.
Figure 1 shows how increasingly complex computer-based technologies (from databases to xml to RDF up to OWL2) make it possible to represent knowledge expressible with increasingly articulated formal languages (from taxonomies to logical theory). This makes this knowledge increasingly interoperable by information technology (IT) systems, from syntactic interoperability to semantic interoperability.
The web platform allows the tracking of the changes made by users to each content and to decide on the truthfulness of the information in a collective way. Subsequently, by means of the semantic extensions implemented in the platform itself, this information is reformulated, and as a last step, it is possible to extract an ontology relating to the information defined by the users. After having created the platform, in order to verify the functional architecture in a practical way, a set of information from the hydrology domain was entered into the platform—in particular, a classification (taxonomy) of the hydrological models extended up to four models well known in the literature (taxonomy instances).
The first objective of this work is, therefore, the implementation of a knowledge management system with semantic extensions and the creation of an initial knowledge base in the hydrological domain. The second, minor goal is to demonstrate KMS interoperability across water-related disciplinary boundaries by establishing an ontology for the sample knowledge base. The purpose of the ontology is to help improve communication within and outside the hydrology community, ensure a common semantic understanding of concepts and provide a tool for metadata processing.
2.1. The User-System Interaction Scheme
The functional architecture envisaged for the knowledge management system object of this work is articulated in a series of strongly connected processes with both feedback and feedforward characteristics. Generally, all the activities that affect the system are more or less rigidly linked in continuous cycles, due both to the extension of the domain of interest of the hydrological sciences and to the current trend of unlimited growth of information volumes.
The processes have the particularity of being almost all collective and are traced over the entire period of operation in a punctual manner to events. The collective elicitation of knowledge, in this operating scheme, is of particular importance because it ensures the truthfulness of the contents; from this point of view, the possibility of tracing the operations carried out also becomes important.
Four large groups of information activities can be distinguished: processes internal to the knowledge management system of a basic type, internal processes of management of semantic structures, processes to and from the outside oriented to the Semantic Web and processes to and from the ontology-oriented exterior.
In the knowledge management internally allowed by the platform, two cycles of evolution of content and meaning can be identified from a logical point of view: contents can be entered, searched, compared, updated and increased, and at the same time, the meanings can be modified with actions on categories, properties and structures.
The agents that perform operations in this structure can be both human and artificial, and one of the main objectives of the semantic web is precisely to make meanings accessible to software agents. The interaction of the platform could take place both through ad hoc developed connections and through the Application Programming Interfaces (API) made available by the platform itself.
Different kinds of expertise are necessary according to the interaction between system and agent: expertise on the hydrology domain affects the whole system; expertise on ontologies affects the whole system and becomes particularly important in the processes of extraction and processing of internal ontologies; expertise on Semantic Web technologies affects the whole system and assumes greater importance in the connection with other semantic systems; IT system engineering expertise affects the basic level administration of the system. A graphical representation of the processes and actors involved in the functioning of the system is available in
Figure 2.
2.2. The Implementation of the Knowledge Management System
Semantic Mediawiki was chosen among different types of semantic wikis available on the market.
For the architecture of the platform, we have chosen to use free software in the open source versions in order both to comply with the provisions of the Agency for Digital Italy (AGID) and to have the possibility of directly making changes to any level of the software structure (see
Appendix A). The architecture as a whole has also been implemented on virtual machines to meet among others the following requirements: independence from specific hardware, portability, versioning, development, maintenance, easier backup-recover “baremetal”. The virtualization environment was Oracle VM Virtualbox, and the host operating system was Ubuntu LTS server—both shown in
Figure 3 as Virtual Host tier. The architecture used for Mediawiki with Semantc Mediawiki (SMW), shown as Application Layer in
Figure 3, was implemented on Linux operating system, Apache web server, Mysql database and on an application server developed in php language—all shown as the Lamp Stack in
Figure 3.
For the Mediawiki, the Semantic Mediawiki extension and numerous other development “packages” were installed, configured and modified at a later time (e.g., ICU International Components for Unicode, Lua Scripting Language, Page Forms, TemplateData, Scribunto, DataValues Validators, ParserHooks, WikiEditor) (see
Appendix A). For the purposes of this research, the platform website was made available on the private network of the Department of Civil Engineering at Polytechnic University of Bari.
2.3. The Knowledge Content
The creation of content, within a knowledge management system such as the one used, is a process of continuous creation, enrichment and revision both at the level of basic information and at the level of the structure of meaning.
This system provides for an operation extended to many users, and all the “actions” carried out within it are both subjected to a continuous process of collective verification and validation and punctually tracked.
Specifically, the data used in the initial phase for the population of the KMS were deduced from the scientific literature and monographic texts of the hydrological sciences domain; see, for example, refs. [
32,
33].
The data collected were entered into the KMS using the tools made available by the system itself: a classification of typical topics of hydrology that extends from the general definitions to the properties of some models (instances) known in the literature [
38,
40] has been introduced, enriched and modified over time. The scheme of the highest level taxonomy is shown in
Figure 4.
Then, four instances of hydrological models were selected from specific studies and added to the knowledge base managed by the system:
DREAM [
41]: “a Distributed model for Runoff, Evapotranspiration, and Antecedent soil Moisture simulation” [
39].
A schema of a part of data submitted is reported in
Table 1:
GEOTOP2 [
42,
43]: “it simulates the combined energy and water balance at and below the land surface accounting for soil freezing, snow cover and terrain effects” [
39].
A schema of a part of data submitted is reported in
Table 2:
THALES [
44,
45,
46]: “a physically based hydrologic model, which divides the watershed into irregular elements based on the streamlines and equipotential lines instead of representing them by regular rectangular grids. As many aspects of the hydrologic response depend on topography, this type of terrain-based model is an important development to accurately representing the surface and sub-surface runoff processes” [
39].
A schema of a part of data submitted is reported in
Table 3.
TOPMODEL [
47,
48,
49,
50]: “a physically based, distributed watershed model that simulates hydrologic flux-es of water (infiltration-excess over-land flow, saturation overland flow, infiltration, exfiltration, subsurface flow, evapotranspiration, and channel routing) through a watershed. The model simulates explicit groundwater/surface water interactions by predicting the movement of the water table, which determines where saturated land-surface areas develop and have the potential to produce saturation overland flow” [
39]. A schema of a part of data submitted is reported in
Table 4.
Table 4.
TOPMODEL model features.
Table 4.
TOPMODEL model features.
| Feature | Value |
|---|
| Model Name | TOPMODEL |
| Author’s Name | Keith Beven |
| Model Distribution Type | Distributed |
| Modules Number | NA |
| Time Scale | NA |
| Basin Dimension | Small to Medium Sized |
| Application Zone | NA |
| Developement Language | FORTRAN |
| Last version | NA |
| Online Availability | YES |
| Download Address | NA |
| License Type | open |
| Creation Date | NA |
Table 1,
Table 2,
Table 3 and
Table 4 respectively show some of the fundamental characteristics of the hydrological models chosen. Starting from these characteristics and from the general taxonomy of
Figure 2, using either a simple markup language made available by the platform or forms created ad hoc at the beginning categories, subcategories and then properties with the related datatypes were implemented.
The “meaning” in KMS was gradually broadened with progressive new interventions, namely
definition of categories and sub-categories, see an example in
Table 1;
definition of properties and data types, see an example in
Table 2;
implementation of categories and properties with semantic markings;
implementation of templates and modules for both new annotations and special requests;
export/link of contents to other CMSes or data-repositories;
From the simple semantic markup entered by the users of the platform, some of which are shown in
Table 5 and
Table 6. The system is called to reconstruct a space of logical statements in a formalized and machine-understandable way.
2.4. Ontological Approach
In order to check the interoperability of the system in a sustainable planning perspective, the possibility of the system to relate to other open data repositories and to serve as a tool for processing metadata was verified [
51]. This perspective was explored with the bottom-up construction of a simple ontology for the tested knowledge base [
52].
As Gruber [
51] puts it, an ontology defines the “specification of a conceptualization of a domain of knowledge”. It is aimed at the specific characteristics of a conceptual system, with objectives related to understanding the elements of interest and the relationships between those elements. In essence, an ontology is interested in highlighting an explicit set of constraints existing within a domain. In an extended and general perspective, an ontology puts an assertion concerning a way in which the world is seen. In this framework, it is frequently composed through a language that can be read and processed by automatic machines [
53].
There is a preliminary and preparatory phase for the construction and refinement of an ontology. This is the so-called ontological analysis phase of the reference domain. It is an important phase, intrinsically and intimately linked to the process of ontological construction. In fact, it uses and is inspired by ontological principles in order to frame, study and research a given issue, a given theme or problem. This exercise aims to pursue a fine understanding of the elements recognized or recognizable as involved in the construction process, as well as the characters and types of emerging relationships. It also scans the situations that the analyst considers possible [
52].
From what has been said, it is clear that the so-called ontological analysis represents the truly difficult stage in the processes of research and construction of an ontology. However, this also indicates that it is the part that mostly determines the quality level of an ontological characterization effort. In highly complex contexts, situations and/or processes—for example, in social or environmental systems—the quality of the ontological analysis defines the effectiveness or even the real usefulness of an ontology [
54].
A key concept in this framework is the so-called interpretative or semantic interoperability [
52]. One of the structurally emerging problems in these cases is, in fact, the existence of differentiated visions of the world linked to the intrinsic, e.g., agentive, and cognitive meaning of conceptualization. Indeed, it is a matter of dealing with the management of different conceptualizations of reality in methodological and operational terms through the search for appropriate formalizations. The ultimate aim of these formalizations specifically concerns the possibility of guiding the creation of knowledge and information management systems endowed with some relevant characteristics. First of all, it is true that a formal ontology should faithfully reflect the vision of reality with respect to the point of view of the observer. However, it is also true that this representation should not be cryptic or opaque with respect to the cognitive aspects of reference, and it must not be a cognitive black box [
53]. These aspects, together with the need for an internal logical structural consistency, represent the necessary framework to guarantee the aforementioned semantic interoperability.
Starting from the previous Gruber’s definition concerning ontology as a conceptual structure of a domain of knowledge, it is possible to think of a formal ontology as the attempt to formally specialize such a definition. The constitutive constraints of this structuration primarily concern the formalization of the language through univocal and clear terminological and interpretative specifications. They also concern the use of explicit references to the philosophical foundations that motivate the categories adopted.
It is therefore evident that ontologies, through a fine conceptualizing action, perform a critical task in the organization of complex knowledge. An ontology can be expressed in diversified but similarly useful ways, depending on the reference contexts. Its relevance and value lay in the ability to model the content of knowledge, regardless of the use of natural language (e.g., WordNet) or more formalized language (e.g., web ontology language, OWL). In this sense, the construction should be preceded by structural analyses of the subject, as well as of the objectives of the ontology and of the agents involved in the areas of use and operation. Depending on the results of such analyses, it is subsequently possible to identify the object/objects of the modeling and the ways of organizing the knowledge base.
The reference context of the ontological analysis and construction process of this study is a hydrological knowledge domain embedded in an environmental system. These are conceptual areas characterized by significant and recognized complexity [
40]. An ontological approach, articulated according to the previous reasoning, seems suitable to investigate the structuring of KMS based on ontologies.
The ontology should help improve discussion within and outside the communities of involved agents to ensure a common semantic understanding of concepts as well as to provide a useful tool for the rigorous definition of descriptive metalevels [
55]. Concerning the knowledge base, an ontology is proposed which describes concepts and relationships extracted from the KMS using the implemented and characterized features and expressed firstly using OWL and then Json-LD [
55]. A thorough representation of the ontology cannot be included in the paper as it is too rich, nested and articulated in several relational levels. However, in order to give a general idea of the organizational structure of the ontology, sketchy representations are provided as excerpts to help a larger awareness. In particular, a graphical representation of a small part of the final ontology is shown in
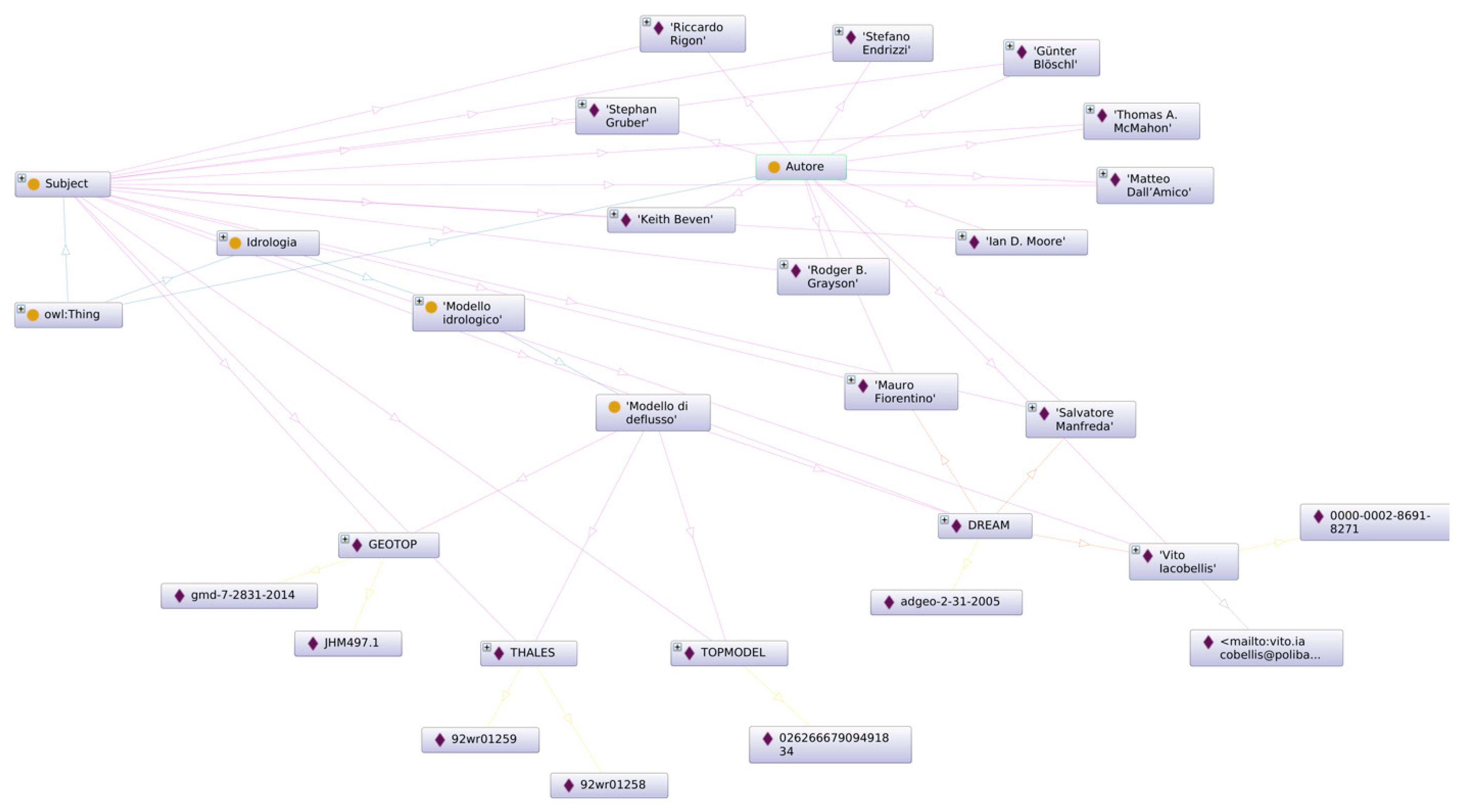
Figure 5 using OntoGraph—a tool providing support for interactive navigation of OWL ontology relationships.
Another part of the extracted ontology is shown in the Class Hierarchy view of Protégé, an open source ontology editor and framework for building OWL-based ontological models (
Figure 6). Concepts, instances, properties and relations are structured here as multi-nested classification trees, which in fact represent the backing framework of the image previously excerpted in
Figure 5.
Therefore, the final part of the research has focused on the management of complexity in hydrological knowledge, proposing to investigate the construction of a knowledge management system useful for operational decisions in the water domain.
3. Discussion and Conclusions
The domain of reference of the present work is the concept of the urban bioregion with its inherent system complexity. In this context, the setting up of a semantic-based model to deal with multiagent water-related concepts has been explored. The research first explored the system’s ability to support the creation and development of knowledge contents enriched with semantic expression. Subsequently, a second objective was to investigate the possible interoperability of the system in a sustainable planning perspective. Particularly, the possibility of the system to relate to other open data repositories and to serve as a tool for processing metadata was explored [
51]. This perspective was explored in the final part of the work with the bottom-up construction of a simple ontology for the tested knowledge base [
52], thus further showing the platform’s ability to clarify the disciplinary boundaries related to water.
Concerning the manageability of complex hydrological knowledge, the model seems to be more effective than traditional approaches [
40]. In particular, it gives operational suggestions towards the management of multisource and multiagent knowledge, both in formal and informal contexts. This represents an interesting improvement perspective, as it allows for the creation of integrated and dynamically updatable knowledge bases—complex, in one word [
37].
Looking at a system capable of dealing with the complexity of hydrological knowledge, the research therefore seems to confirm the possibility of supporting water-oriented decisions and policies in more informed ways—being akin to complex knowledge. The consequent greater ability to fine-tune concepts and meanings seems to also suggest better perspectives of unambiguity and, therefore, less discretionary interpretations of knowledge—a well-known problem in policymaking [
11].
In this framework, the model seems therefore useful to support more informed and effective decisions and policies in the water domain at different scales of environmental planning. And based on the above, it seems that this type of approach to knowledge management can represent an encouraging perspective for broader sustainable land management and planning operations. In fact, water and hydrology are structural aspects for any decision-making question related to the futures of cities and environments, especially in terms of urban bioregion. In particular, various objectives of the UN 2030 Agenda consider water resources as essential in the bioregional future of the territories, with specific references in goals 11 and 12 [
56], p. 423.
Indeed, the aspects of social, environmental, procedural, relational and cognitive complexity represent intrinsic parts of the domain addressed by planning actions. Therefore, an approach that operationally preserves this complexity should be extremely useful for those planning actions. In fact, the issue of knowledge management is one of the most intricate parts of environmental planning. There is extensive literature on the importance of the contributions of expert knowledge, which is codified, formalized and based on domain-dependent scientific conceptualizations [
13]. An architecture based on ontological models with semantic extensions could manage such multisource knowledge data in a systemic and structured way. But even non-expert knowledge, the unstructured and informal knowledge exchanged by community members is today an indispensable contribution to planning processes [
57]. That is, the management of both expert and non-expert knowledge, characterized by different languages and conceptualizations, represents a very interesting objective for environmental planning, despite the underlying complexity. And this is a very topical objective, particularly when dealing with possible architectures to support the multiscale governance of urban bioregions [
55]. The planning, decision-making and management activities of urban bioregions today need to look at the aspects of resources with a diffused, formal and informal cognitive approach. This could largely benefit from the large amount of data now available and from the various forms of ordering and classification that are increasingly available. In this complex but critical and unavoidable context of knowledge, the effort to explore and define knowledge management architectures represents a very interesting perspective. The present study about the analysis and structuring of water-resource ontologies makes it possible to reflect on the potential of approaches of this kind. Furthermore, its inherent interoperability and structural trans-domain interconnectivity suggest possible scope enlargements and generalizations. Indeed, a perspective would be to aim at its possible replicability, or possible extension at least, to other complex domains in the bioregional context.
Clearly, the present study provides only synthetic accounts and operational scenarios in this sense. Nonetheless, it is able to open interesting follow-up perspectives, and its development will be pursued by our group in the near future.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





