
An Efficient Siamese Network and Transfer Learning-Based Predictive Maintenance System for More Sustainable Manufacturing

Abstract
:1. Introduction
1.1. Review of the Literature
1.2. Proposed Predictive Maintenance Framework for Legacy Machines
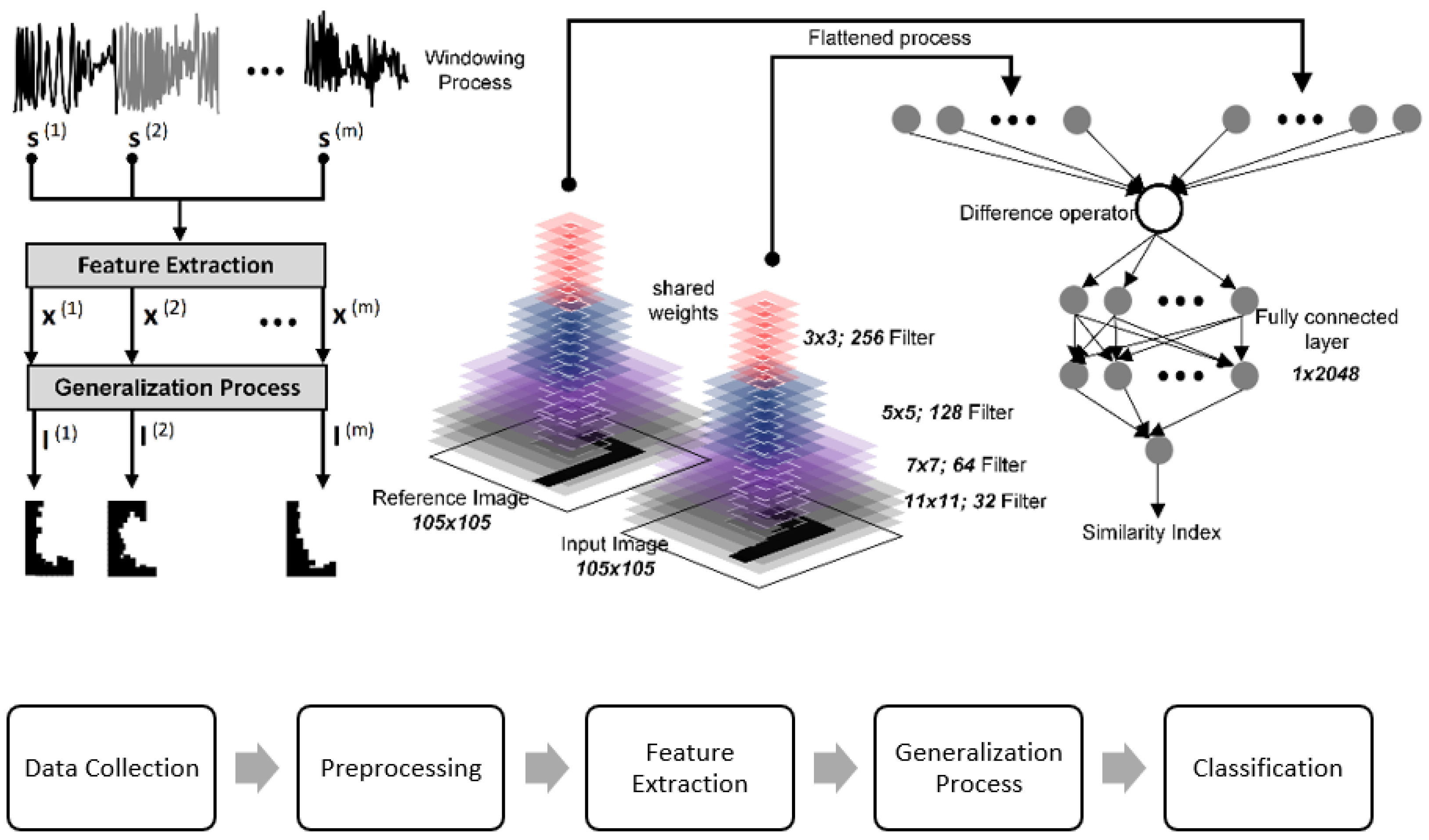
- A Siamese network is trained with the public dataset named Omniglot dataset containing handwriting images [134] to adapt the network, which measures the similarity between two samples given to its input;
- The test images obtained from the machine to be maintained are structured similarly to the Omniglot dataset with a proposed step named the generalization step;
- In the generalization step, a test image is constructed using the feature extracted from the machine to be maintained. The feature is projected to an image with the shape “L” or “C” concerning clustering results;
- The reference image “L” is compared with the obtained image from the machine by using the trained Siamese network;
- The comparison results give a number between zero and one to measure the healthiness of the machine;
- To increase the efficiency of the network, the CNN layer of the Siamese network is preserved, and the fully connected layer of the Siamese network is retrained using a few samples obtained from the machine for further prediction.
2. Materials and Methods
2.1. Data Collection
2.2. Preprocessing
2.3. Feature Extraction
2.4. Generalization Process
| Algorithm 1 Generalization algorithm main steps |
| 1. Collect and denoised signal 2. Divide the signal into m pieces with dimensional windows, which can be shown a matrix: and for 3. Extract features from the windowed signal to obtain a feature matrix defined and for 4. Select features from feature matrix based on unsupervised Local Learning-algorithm [142,143] to obtain reduced matrix where for Apply k-means clustering: [148] 5. Arbitrarily choose k initial centers 6. For every, set 7. For every, set where 1{.} is the indicator function. 8. Repeat 6 and 7 until no longer changes. 9. Return labels 10. Take features found in step 3 and to construct image samples for the siamese network. |
2.5. Siamese Network
2.6. Training and Testing Process
| Algorithm 2 Applicaiton of Transfer Learning. |
| 1. Tune all parameters of the Siamese network with data set. Repeat for k = 1…N 2. Test the Siamese network with the data obtained from kth machine. 3. Find labels related to kth machine 4. Initialize the weights in full connected layer of the network. 5. Tune the weights of the NN with the data obtained from the machines (1…k) 6. Return labels for kth machine. |
3. Results and Discussion
3.1. Test Datasets
3.1.1. Lathe Machine Failure Dataset
3.1.2. Bearing Fault Dataset
3.1.3. Wind Turbine High-Speed Bearing Prognosis
3.1.4. AI4I Dataset
3.2. Training Processing
3.3. The Experimental Results for Public Datasets
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fontana, A.; Barni, A.; Leone, D.; Spirito, M.; Tringale, A.; Ferraris, M.; Reis, J.; Goncalves, G. Circular Economy Strategies for Equipment Lifetime Extension: A Systematic Review. Sustainability 2021, 13, 1117. [Google Scholar] [CrossRef]
- Li, B.; Wang, T.; Li, C.; Dong, Z.; Yang, H.; Sun, Y.; Wang, P. A Strategy for Determining the Decommissioning Life of Energy Equipment Based on Economic Factors and Operational Stability. Sustainability 2022, 14, 16378. [Google Scholar] [CrossRef]
- Lolli, F.; Coruzzolo, A.M.; Peron, M.; Sgarbossa, F. Age-Based Preventive Maintenance with Multiple Printing Options. Int. J. Prod. Econ. 2022, 243, 108339. [Google Scholar] [CrossRef]
- Sun, Z.; Chen, T.; Meng, X.; Bao, Y.; Hu, L.; Zhao, R. A Critical Review for Trustworthy and Explainable Structural Health Monitoring and Risk Prognosis of Bridges with Human-In-The-Loop. Sustainability 2023, 15, 6389. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, Y. Multi-Scale Remaining Useful Life Prediction Using Long Short-Term Memory. Sustainability 2022, 14, 15667. [Google Scholar] [CrossRef]
- van Noortwijk, J.M. A Survey of the Application of Gamma Processes in Maintenance. Reliab. Eng. Syst. Saf. 2009, 94, 2–21. [Google Scholar] [CrossRef]
- Alaswad, S.; Xiang, Y. A Review on Condition-Based Maintenance Optimization Models for Stochastically Deteriorating System. Reliab. Eng. Syst. Saf. 2017, 157, 54–63. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Gontarz, S.; Lin, J.; Radkowski, S.; Dybala, J. A Model-Based Method for Remaining Useful Life Prediction of Machinery. IEEE Trans. Reliab. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, Z.; Wang, W.; Sun, Y. Remaining Useful Life Prediction for a Nonlinear Heterogeneous Wiener Process Model With an Adaptive Drift. IEEE Trans. Reliab. 2015, 64, 687–700. [Google Scholar] [CrossRef]
- Hanachi, H.; Liu, J.; Banerjee, A.; Chen, Y.; Koul, A. A Physics-Based Modeling Approach for Performance Monitoring in Gas Turbine Engines. IEEE Trans. Reliab. 2015, 64, 197–205. [Google Scholar] [CrossRef]
- Dui, H.; Si, S.; Zuo, M.J.; Sun, S. Semi-Markov Process-Based Integrated Importance Measure for Multi-State Systems. IEEE Trans. Reliab. 2015, 64, 754–765. [Google Scholar] [CrossRef]
- Cui, L.; Xu, Y.; Zhao, X. Developments and Applications of the Finite Markov Chain Imbedding Approach in Reliability. IEEE Trans. Reliab. 2010, 59, 685–690. [Google Scholar] [CrossRef]
- Si, X.; Wang, W.; Hu, C.; Zhou, D.; Pecht, M.G. Remaining Useful Life Estimation Based on a Nonlinear Diffusion Degradation Process. IEEE Trans. Reliab. 2012, 61, 50–67. [Google Scholar] [CrossRef]
- Si, X.-S.; Wang, W.; Chen, M.-Y.; Hu, C.-H.; Zhou, D.-H. A Degradation Path-Dependent Approach for Remaining Useful Life Estimation with an Exact and Closed-Form Solution. Eur. J. Oper. Res. 2013, 226, 53–66. [Google Scholar] [CrossRef]
- Yu, J. A Nonlinear Probabilistic Method and Contribution Analysis for Machine Condition Monitoring. Mech. Syst. Signal Process. 2013, 37, 293–314. [Google Scholar] [CrossRef]
- Yu, J. Health Degradation Detection and Monitoring of Lithium-Ion Battery Based on Adaptive Learning Method. IEEE Trans. Instrum. Meas. 2014, 63, 1709–1721. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-Driven Methods for Predictive Maintenance of Industrial Equipment: A Survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.A.M.N.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G.S. A Systematic Literature Review of Machine Learning Methods Applied to Predictive Maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Angelopoulos, A.; Michailidis, E.T.; Nomikos, N.; Trakadas, P.; Hatziefremidis, A.; Voliotis, S.; Zahariadis, T. Tackling Faults in the Industry 4.0 Era—A Survey of Machine-Learning Solutions and Key Aspects. Sensors 2020, 20, 109. [Google Scholar] [CrossRef] [Green Version]
- Patil, S.; Desai, S.; Patil, A.; Phalle, V.M.; Handikherkar, V.; Kazi, F.S. Remaining Useful Life (RuL) Prediction of Rolling Element Bearing Using Random Forest and Gradient Boosting Technique. In Proceedings of the ASME International Mechanical Engineering Congress and Exposition, Pittsburgh, PA, USA, 9–15 November 2018; Volume 13. [Google Scholar]
- Rafiee, J.; Arvani, F.; Harifi, A.; Sadeghi, M.H. Intelligent Condition Monitoring of a Gearbox Using Artificial Neural Network. Mech. Syst. Signal Process. 2007, 21, 1746–1754. [Google Scholar] [CrossRef]
- Sakthivel, N.R.; Sugumaran, V.; Babudevasenapati, S. Vibration Based Fault Diagnosis of Monoblock Centrifugal Pump Using Decision Tree. Expert Syst. Appl. 2010, 37, 4040–4049. [Google Scholar] [CrossRef]
- Nasir, V.; Cool, J. Intelligent Wood Machining Monitoring Using Vibration Signals Combined with Self-Organizing Maps for Automatic Feature Selection. Int. J. Adv. Manuf. Technol. 2020, 108, 1811–1825. [Google Scholar] [CrossRef]
- Wu, J.-D.; Liu, C.-H. Investigation of Engine Fault Diagnosis Using Discrete Wavelet Transform and Neural Network. Expert Syst. Appl. 2008, 35, 1200–1213. [Google Scholar] [CrossRef]
- Devasenapati, S.B.; Sugumaran, V.; Ramachandran, K.I. Misfire Identification in a Four-Stroke Four-Cylinder Petrol Engine Using Decision Tree. Expert Syst. Appl. 2010, 37, 2150–2160. [Google Scholar] [CrossRef]
- Jack, L.B.; Nandi, A.K. Support Vector Machines for Detection and Characterization of Rolling Element Bearing Faults. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2001, 215, 1065–1074. [Google Scholar] [CrossRef]
- Wang, G.F.; Yang, Y.W.; Zhang, Y.C.; Xie, Q.L. Vibration Sensor Based Tool Condition Monitoring Using ν Support Vector Machine and Locality Preserving Projection. Sens. Actuators A Phys. 2014, 209, 24–32. [Google Scholar] [CrossRef]
- Lee, S.-B.; Habetler, T.G. An Online Stator Winding Resistance Estimation Technique for Temperature Monitoring of Line-Connected Induction Machines. IEEE Trans. Ind. Appl. 2003, 39, 685–694. [Google Scholar] [CrossRef]
- Ni, Y.Q.; Hua, X.G.; Fan, K.Q.; Ko, J.M. Correlating Modal Properties with Temperature Using Long-Term Monitoring Data and Support Vector Machine Technique. Eng. Struct. 2005, 27, 1762–1773. [Google Scholar] [CrossRef]
- Xiang, D.; Ran, L.; Tavner, P.; Bryant, A.; Yang, S.; Mawby, P. Monitoring Solder Fatigue in a Power Module Using Case-above-Ambient Temperature Rise. IEEE Trans. Ind. Appl. 2011, 47, 2578–2591. [Google Scholar] [CrossRef]
- Chen, H.; Ji, B.; Pickert, V.; Cao, W. Real-Time Temperature Estimation for Power MOSFETs Considering Thermal Aging Effects. IEEE Trans. Device Mater. Reliab. 2014, 14, 220–228. [Google Scholar] [CrossRef] [Green Version]
- Guo, P.; Infield, D.; Yang, X. Wind Turbine Generator Condition-Monitoring Using Temperature Trend Analysis. IEEE Trans. Sustain. Energy 2012, 3, 124–133. [Google Scholar] [CrossRef] [Green Version]
- Mouli, D.S.B.; Rameshkumar, K. Acoustic Emission-Based Grinding Wheel Condition Monitoring Using Decision Tree Machine Learning Classifiers. Lect. Notes Mech. Eng. 2020, 2020, 353–359. [Google Scholar] [CrossRef]
- Motahari-Nezhad, M.; Jafari, S.M. ANFIS System for Prognosis of Dynamometer High-Speed Ball Bearing Based on Frequency Domain Acoustic Emission Signals. Meas. J. Int. Meas. Confed. 2020, 166, 108154. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Zhao, P.; Zhang, X.; Zhou, P. Cutting Tool Operational Reliability Prediction Based on Acoustic Emission and Logistic Regression Model. J. Intell. Manuf. 2015, 26, 923–931. [Google Scholar] [CrossRef]
- Glowacz, A. Diagnostics of Synchronous Motor Based on Analysis of Acoustic Signals with the Use of Line Spectral Frequencies and K-Nearest Neighbor Classifier. Arch. Acoust. 2014, 39, 189–194. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Liang, Y.; Zheng, Y.; Gao, R.X.; Zhang, F. An Integrated Fault Diagnosis and Prognosis Approach for Predictive Maintenance of Wind Turbine Bearing with Limited Samples. Renew. Energy 2020, 145, 642–650. [Google Scholar] [CrossRef]
- Senguler, T.; Karatoprak, E.; Seker, S.; Caglar, R. ICA and Wavelet Packet Decomposition Approaches for Monitoring the Incipient Bearing Damage in Electrical Motors. In Proceedings of the 2008 4th International IEEE Conference Intelligent Systems, Nice, France, 22–26 September 2008; Volume 2, pp. 2413–2417. [Google Scholar]
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Robust Performance Degradation Assessment Methods for Enhanced Rolling Element Bearing Prognostics. Adv. Eng. Inform. 2003, 17, 127–140. [Google Scholar] [CrossRef]
- Bansal, D.; Evans, D.J.; Jones, B. BJEST: A Reverse Algorithm for the Real-Time Predictive Maintenance System. Int. J. Mach. Tools Manuf. 2006, 46, 1068–1078. [Google Scholar] [CrossRef]
- Sánchez, L.; Couso, I. Singular Spectral Analysis of Ill-Known Signals and Its Application to Predictive Maintenance of Windmills with SCADA Records. Soft Comput. 2012, 16, 755–768. [Google Scholar] [CrossRef]
- Zhang, Y.; Randall, R.B. Rolling Element Bearing Fault Diagnosis Based on the Combination of Genetic Algorithms and Fast Kurtogram. Mech. Syst. Signal Process. 2009, 23, 1509–1517. [Google Scholar] [CrossRef]
- Saidi, L.; Ben Ali, J.; Fnaiech, F. Application of Higher Order Spectral Features and Support Vector Machines for Bearing Faults Classification. ISA Trans. 2015, 54, 193–206. [Google Scholar] [CrossRef]
- Tabrizi, A.; Garibaldi, L.; Fasana, A.; Marchesiello, S. Early Damage Detection of Roller Bearings Using Wavelet Packet Decomposition, Ensemble Empirical Mode Decomposition and Support Vector Machine. Meccanica 2015, 50, 865–874. [Google Scholar] [CrossRef]
- Phillips, J.; Cripps, E.; Lau, J.W.; Hodkiewicz, M.R. Classifying Machinery Condition Using Oil Samples and Binary Logistic Regression. Mech. Syst. Signal Process. 2015, 60, 316–325. [Google Scholar] [CrossRef]
- Barbieri, M.; DIversi, R.; Tilli, A. Condition Monitoring of Ball Bearings Using Estimated Ar Models as Logistic Regression Features. In Proceedings of the 2019 18th European Control Conference (ECC), Naples, Italy, 25–28 June 2019; pp. 3904–3909. [Google Scholar]
- Zhang, J.; Nie, H. Experimental Study and Logistic Regression Modeling for Machine Condition Monitoring through Microcontroller-Based Data Acquisition System. J. Adv. Manuf. Syst. 2009, 8, 177–192. [Google Scholar] [CrossRef]
- Knoebel, C.; Strommenger, D.; Reuter, J.; Guehmann, C. Health Index Generation Based on Compressed Sensing and Logistic Regression for Remaining Useful Life Prediction. In Proceedings of the Annual Conference of the PHM Society, Scottsdale, AZ, USA, 21–26 September 2019; Vol. 11. [Google Scholar]
- Langone, R.; Cuzzocrea, A.; Skantzos, N. Interpretable Anomaly Prediction: Predicting Anomalous Behavior in Industry 4.0 Settings via Regularized Logistic Regression Tools. Data Knowl. Eng. 2020, 130, 101850. [Google Scholar] [CrossRef]
- Bodla, M.K.; Malik, S.M.; Rasheed, M.T.; Numan, M.; Ali, M.Z.; Brima, J.B. Logistic Regression and Feature Extraction Based Fault Diagnosis of Main Bearing of Wind Turbines. In Proceedings of the 2016 IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), Hefei, China, 5–7 June 2016; pp. 1628–1633. [Google Scholar]
- Yu, J. Tool Condition Prognostics Using Logistic Regression with Penalization and Manifold Regularization. Appl. Soft Comput. J. 2018, 64, 454–467. [Google Scholar] [CrossRef]
- Gryllias, K.C.; Antoniadis, I.A. A Support Vector Machine Approach Based on Physical Model Training for Rolling Element Bearing Fault Detection in Industrial Environments. Eng. Appl. Artif. Intell. 2012, 25, 326–344. [Google Scholar] [CrossRef]
- Samanta, B.; Al-Balushi, K.R.; Al-Araimi, S.A. Artificial Neural Networks and Support Vector Machines with Genetic Algorithm for Bearing Fault Detection. Eng. Appl. Artif. Intell. 2003, 16, 657–665. [Google Scholar] [CrossRef]
- Konar, P.; Chattopadhyay, P. Bearing Fault Detection of Induction Motor Using Wavelet and Support Vector Machines (SVMs). Appl. Soft Comput. J. 2011, 11, 4203–4211. [Google Scholar] [CrossRef]
- Pandarakone, S.E.; Mizuno, Y.; Nakamura, H. Distinct Fault Analysis of Induction Motor Bearing Using Frequency Spectrum Determination and Support Vector Machine. IEEE Trans. Ind. Appl. 2017, 53, 3049–3056. [Google Scholar] [CrossRef]
- Jack, L.B.; Nandi, A.K. Fault Detection Using Support Vector Machines and Artificial Neural Networks, Augmented by Genetic Algorithms. Mech. Syst. Signal Process. 2002, 16, 373–390. [Google Scholar] [CrossRef]
- Lim, G.-M.; Bae, D.-M.; Kim, J.-H. Fault Diagnosis of Rotating Machine by Thermography Method on Support Vector Machine. J. Mech. Sci. Technol. 2014, 28, 2947–2952. [Google Scholar] [CrossRef]
- Murthy, V.S.; Tarakanath, K.; Mohanta, D.K.; Gupta, S. Insulator Condition Analysis for Overhead Distribution Lines Using Combined Wavelet Support Vector Machine (SVM). IEEE Trans. Dielectr. Electr. Insul. 2010, 17, 89–99. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.-S. Machine Health Prognostics Using Survival Probability and Support Vector Machine. Expert Syst. Appl. 2011, 38, 8430–8437. [Google Scholar] [CrossRef]
- Tran, V.T.; Thom Pham, H.; Yang, B.-S.; Tien Nguyen, T. Machine Performance Degradation Assessment and Remaining Useful Life Prediction Using Proportional Hazard Model and Support Vector Machine. Mech. Syst. Signal Process. 2012, 32, 320–330. [Google Scholar] [CrossRef] [Green Version]
- Shi, D.; Gindy, N.N. Tool Wear Predictive Model Based on Least Squares Support Vector Machines. Mech. Syst. Signal Process. 2007, 21, 1799–1814. [Google Scholar] [CrossRef]
- Muralidharan, V.; Sugumaran, V. A Comparative Study of Naïve Bayes Classifier and Bayes Net Classifier for Fault Diagnosis of Monoblock Centrifugal Pump Using Wavelet Analysis. Appl. Soft Comput. J. 2012, 12, 2023–2029. [Google Scholar] [CrossRef]
- Pandarakone, S.E.; Gunasekaran, S.; Mizuno, Y.; Nakamura, H. Application of Naive Bayes Classifier Theorem in Detecting Induction Motor Bearing Failure. In Proceedings of the 2018 XIII International Conference on Electrical Machines (ICEM), Alexandroupoli, Greece, 3–6 September 2018; pp. 1761–1767. [Google Scholar]
- Mitiche, I.; Nesbitt, A.; Boreham, P.; Stewart, B.G.; Morison, G. Naive Bayes Multi-Label Classification Approach for High-Voltage Condition Monitoring. In Proceedings of the 2018 IEEE International Conference on Internet of Things and Intelligence System (IOTAIS), Bali, Indonesia, 1–3 November 2018; pp. 162–166. [Google Scholar]
- Alamelu Manghai, T.M.; Jegadeeshwaran, R.; Sakthivel, G. Real Time Condition Monitoring of Hydraulic Brake System Using Naive Bayes and Bayes Net Algorithms. IOP Conf. Ser. Mater. Sci. Eng. 2019, 624, 012028. [Google Scholar] [CrossRef]
- Natarajan, S. Condition Monitoring of Bevel Gear Box Using Morlet Wavelet Coefficients and Naïve Bayes Classifier. Int. J. Syst. Control. Commun. 2019, 10, 18–31. [Google Scholar] [CrossRef]
- Sugumaran, V.; Ramachandran, K.I. Automatic Rule Learning Using Decision Tree for Fuzzy Classifier in Fault Diagnosis of Roller Bearing. Mech. Syst. Signal Process. 2007, 21, 2237–2247. [Google Scholar] [CrossRef]
- Jegadeeshwaran, R.; Sugumaran, V. Comparative Study of Decision Tree Classifier and Best First Tree Classifier for Fault Diagnosis of Automobile Hydraulic Brake System Using Statistical Features. Meas. J. Int. Meas. Confed. 2013, 46, 3247–3260. [Google Scholar] [CrossRef]
- Sakthivel, N.R.; Sugumaran, V.; Nair, B.B. Comparison of Decision Tree-Fuzzy and Rough Set-Fuzzy Methods for Fault Categorization of Mono-Block Centrifugal Pump. Mech. Syst. Signal Process. 2010, 24, 1887–1906. [Google Scholar] [CrossRef]
- Sharma, R.K.; Sugumaran, V.; Kumar, H.; Amarnath, M. Condition Monitoring of Roller Bearing by K-Star Classifier and K-Nearest Neighborhood Classifier Using Sound Signal. SDHM Struct. Durab. Health Monit. 2017, 12, 1–16. [Google Scholar]
- Muralidharan, V.; Ravikumar, S.; Kangasabapathy, H. Condition Monitoring of Self Aligning Carrying Idler (SAI) in Belt-Conveyor System Using Statistical Features and Decision Tree Algorithm. Meas. J. Int. Meas. Confed. 2014, 58, 274–279. [Google Scholar] [CrossRef]
- Devendiran, S.; Manivannan, K. Condition Monitoring on Grinding Wheel Wear Using Wavelet Analysis and Decision Tree C4.5 Algorithm. Int. J. Eng. Technol. 2013, 5, 4010–4024. [Google Scholar]
- Qin, S.; Zhang, M.; Ma, X.; Li, M. A New Integrated Analytics Approach for Wind Turbine Fault Detection Using Wavelet, RLS Filter and Random Forest. Energy Sources Part A Recovery Util. Environ. Eff. 2019, 2019, 1–16. [Google Scholar] [CrossRef]
- Prabhu, G.R.; Chandrasekar, S.; Ravindran, R.S. A Novel Random Forest Model Approach for Accurate Classification of Single Partial Discharge Sources of HV Transformer Insulation Faults. J. Comput. Theor. Nanosci. 2016, 13, 9040–9050. [Google Scholar] [CrossRef]
- Aravinth, S.; Sugumaran, V. Air Compressor Fault Diagnosis through Statistical Feature Extraction and Random Forest Classifier. Prog. Ind. Ecol. 2018, 12, 192–205. [Google Scholar] [CrossRef]
- Chen, M.; Pang, X.; Lu, K. Fault Diagnosis of Planetary Gearbox Based on Random Forest and Singular Value Difference Spectrum. Smart Innov. Syst. Technol. 2020, 166, 1529–1540. [Google Scholar] [CrossRef]
- Ravikumar, S.; Muralidharan, V.; Ramesh, P.; Pandian, C. Fault Diagnosis of Self-Aligning Conveyor Idler in Coal Handling Belt Conveyor System by Statistical Features Using Random Forest Algorithm. Lect. Notes Electr. Eng. 2021, 688, 207–219. [Google Scholar] [CrossRef]
- Kartojo, I.H.; Wang, Y.-B.; Zhang, G.-J. Suwarno Partial Discharge Defect Recognition in Power Transformer Using Random Forest. In Proceedings of the 2019 IEEE 20th International Conference on Dielectric Liquids (ICDL), Rome, Italy, 23–27 June 2019; Volume 2019. [Google Scholar]
- Yan, W.; Zhou, J.-H. Predictive Modeling of Aircraft Systems Failure Using Term Frequency-Inverse Document Frequency and Random Forest. In Proceedings of the 2017 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 10–13 December 2017; Volume 2017, pp. 828–831. [Google Scholar]
- Vamsi, I.V.; Abhinav, N.; Verma, A.K.; Radhika, S. Random Forest Based Real Time Fault Monitoring System for Industries. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018. [Google Scholar]
- Li, J.; Wu, Y.; Wang, G.; Peng, X.; Liu, T.; Jiao, Y. Gradient Boosting Decision Tree and Random Forest Based Partial Discharge Pattern Recognition of HV Cable. In Proceedings of the 2018 China International Conference on Electricity Distribution (CICED), Tianjin, China, 17–19 September 2018; pp. 327–331. [Google Scholar]
- Li, X.; Mba, D.; Lin, T.; Yang, Y.; Loukopoulos, P. Just-in-Time Learning Based Probabilistic Gradient Boosting Tree for Valve Failure Prognostics. Mech. Syst. Signal Process. 2021, 150, 107253. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, Z.; Song, H.; Shi, K. Wind Turbine Gearbox Condition Monitoring Based on Extreme Gradient Boosting. In Proceedings of the IECON 2017-43rd Annual Conference of the IEEE Industrial Electronics Society, Beijing, China, 29 October–1 November 2017; Volume 2017, pp. 6017–6023. [Google Scholar]
- Moosavian, A.; Ahmadi, H.; Tabatabaeefar, A.; Sakhaei, B. An Appropriate Procedure for Detection of Journal-Bearing Fault Using Power Spectral Density, K-Nearest Neighbor and Support Vector Machine. Int. J. Smart Sens. Intell. Syst. 2012, 5, 685–700. [Google Scholar] [CrossRef] [Green Version]
- Surti, K.V.; Naik, C.A. Bearing Condition Monitoring of Induction Motor Based on Discrete Wavelet Transform K-Nearest Neighbor. In Proceedings of the 2018 3rd International Conference for Convergence in Technology (I2CT), Pune, India, 6–8 April 2018. [Google Scholar]
- Junior, P.; D’Addona, D.M.; Aguiar, P.; Teti, R. Dressing Tool Condition Monitoring through Impedance-Based Sensors: Part 2—Neural Networks and K-Nearest Neighbor Classifier Approach. Sensors 2018, 18, 4453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hasan, M.J.; Kim, J.-M. Fault Detection of a Spherical Tank Using a Genetic Algorithm-Based Hybrid Feature Pool and k-Nearest Neighbor Algorithm. Energies 2019, 12, 991. [Google Scholar] [CrossRef] [Green Version]
- Moosavian, A.; Ahmadi, H.; Tabatabaeefar, A. Fault Diagnosis of Main Engine Journal Bearing Based on Vibration Analysis Using Fisher Linear Discriminant, K-Nearest Neighbor and Support Vector Machine. J. Vibroeng. 2012, 14, 894–906. [Google Scholar]
- Huang, Y.; Zha, X.F.; Lee, J.; Liu, C. Discriminant Diffusion Maps Analysis: A Robust Manifold Learner for Dimensionality Reduction and Its Applications in Machine Condition Monitoring and Fault Diagnosis. Mech. Syst. Signal Process. 2013, 34, 277–297. [Google Scholar] [CrossRef]
- Khandaker, N.; Zhang, R.; Dong, S.; Xu, B.; Zhang, Z.; Wen, G. Application of Unsupervised Linear Discriminant Analysis for Condition Monitoring of Rotating Machinery. In Proceedings of the 9th International Conference on Modelling, Identification and Control (ICMIC), Kunming, China, 10-12 July 2017; pp. 43–48. [Google Scholar] [CrossRef]
- Liu, T.; Chen, J.; Zhou, X.N.; Xiao, W.B. Bearing Performance Degradation Assessment Using Linear Discriminant Analysis and Coupled HMM. In Proceedings of the 25th International Congress on Condition Monitoring and Diagnostic Engineering (COMADEM 2012), Huddersfield, UK, 18–20 June 2012; Volume 364. [Google Scholar]
- Fernandez-Temprano, M.; Gardel-Sotomayor, P.E.; Duque-Perez, O.; Morinigo-Sotelo, D. Broken Bar Condition Monitoring of an Induction Motor under Different Supplies Using a Linear Discriminant Analysis. In Proceedings of the 2013 9th IEEE International Symposium on Diagnostics for Electric Machines, Power Electronics and Drives (SDEMPED), Valencia, Spain, 27–30 August 2013; pp. 162–168. [Google Scholar]
- Ramirez-Chavez, M.; Saucedo-Dorantes, J.J.; Jaen-Cuellar, A.Y.; Osorniorios, R.A.; Romero-Troncoso, R.D.J.; Delgado-Prieto, M. Condition Monitoring Strategy Based on Spectral Energy Estimation and Linear Discriminant Analysis Applied to an Induction Motor. In Proceedings of the 2018 IEEE International Autumn Meeting on Power, Electronics and Computing (ROPEC), Ixtapa, Mexico, 14–16 November 2019. [Google Scholar]
- Tian, Z.; Wong, L.; Safaei, N. A Neural Network Approach for Remaining Useful Life Prediction Utilizing Both Failure and Suspension Histories. Mech. Syst. Signal Process. 2010, 24, 1542–1555. [Google Scholar] [CrossRef]
- Chow, M.-Y.; Yee, S.O.; Mangum, P.M. A Neural Network Approach to Real-Time Condition Monitoring of Induction Motors. IEEE Trans. Ind. Electron. 1991, 38, 448–453. [Google Scholar] [CrossRef]
- Gebraeel, N.Z.; Lawley, M.A. A Neural Network Degradation Model for Computing and Updating Residual Life Distributions. IEEE Trans. Autom. Sci. Eng. 2008, 5, 154–163. [Google Scholar] [CrossRef]
- Wu, S.-J.; Gebraeel, N.; Lawley, M.A.; Yih, Y. A Neural Network Integrated Decision Support System for Condition-Based Optimal Predictive Maintenance Policy. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 37, 226–236. [Google Scholar] [CrossRef]
- Bangalore, P.; Tjernberg, L.B. An Artificial Neural Network Approach for Early Fault Detection of Gearbox Bearings. IEEE Trans. Smart Grid 2015, 6, 980–987. [Google Scholar] [CrossRef]
- Tian, Z. An Artificial Neural Network Method for Remaining Useful Life Prediction of Equipment Subject to Condition Monitoring. J. Intell. Manuf. 2012, 23, 227–237. [Google Scholar] [CrossRef]
- Fast, M.; Palmé, T. Application of Artificial Neural Networks to the Condition Monitoring and Diagnosis of a Combined Heat and Power Plant. Energy 2010, 35, 1114–1120. [Google Scholar] [CrossRef]
- Liang, B.; Iwnicki, S.D.; Zhao, Y. Application of Power Spectrum, Cepstrum, Higher Order Spectrum and Neural Network Analyses for Induction Motor Fault Diagnosis. Mech. Syst. Signal Process. 2013, 39, 342–360. [Google Scholar] [CrossRef] [Green Version]
- Malik, H.; Mishra, S. Artificial Neural Network and Empirical Mode Decomposition Based Imbalance Fault Diagnosis of Wind Turbine Using TurbSim, FAST and Simulink. IET Renew. Power Gener. 2017, 11, 889–902. [Google Scholar] [CrossRef]
- Paya, B.A.; Esat, I.I.; Badi, M.N.M. Artificial Neural Network Based Fault Diagnostics of Rotating Machinery Using Wavelet Transforms as a Preprocessor. Mech. Syst. Signal Process. 1997, 11, 751–765. [Google Scholar] [CrossRef]
- Samanta, B.; Al-Balushi, K.R.; Al-Araimi, S.A. Artificial Neural Networks and Genetic Algorithm for Bearing Fault Detection. Soft Comput. 2006, 10, 264–271. [Google Scholar] [CrossRef]
- Samanta, B. Artificial Neural Networks and Genetic Algorithms for Gear Fault Detection. Mech. Syst. Signal Process. 2004, 18, 1273–1282. [Google Scholar] [CrossRef]
- Prieto, M.D.; Cirrincione, G.; Espinosa, A.G.; Ortega, J.A.; Henao, H. Bearing Fault Detection by a Novel Condition-Monitoring Scheme Based on Statistical-Time Features and Neural Networks. IEEE Trans. Ind. Electron. 2013, 60, 3398–3407. [Google Scholar] [CrossRef]
- Abu-Mahfouz, I. Drilling Wear Detection and Classification Using Vibration Signals and Artificial Neural Network. Int. J. Mach. Tools Manuf. 2003, 43, 707–720. [Google Scholar] [CrossRef]
- Ghosh, N.; Ravi, Y.B.; Patra, A.; Mukhopadhyay, S.; Paul, S.; Mohanty, A.R.; Chattopadhyay, A.B. Estimation of Tool Wear during CNC Milling Using Neural Network-Based Sensor Fusion. Mech. Syst. Signal Process. 2007, 21, 466–479. [Google Scholar] [CrossRef]
- Kaya, B.; Oysu, C.; Ertunc, H.M. Force-Torque Based on-Line Tool Wear Estimation System for CNC Milling of Inconel 718 Using Neural Networks. Adv. Eng. Softw. 2011, 42, 76–84. [Google Scholar] [CrossRef]
- Dimla, D.E., Jr.; Lister, P.M.; Leighton, N.J. Neural Network Solutions to the Tool Condition Monitoring Problem in Metal Cutting—A Critical Review of Methods. Int. J. Mach. Tools Manuf. 1997, 37, 1219–1241. [Google Scholar] [CrossRef]
- Rangwala, S.; Dornfeld, D. Sensor Integration Using Neural Networks for Intelligent Tool Condition Monitoring. J. Eng. Ind. 1990, 112, 219–228. [Google Scholar] [CrossRef]
- Muniraj, C.; Chandrasekar, S. Adaptive Neuro-Fuzzy Inference System for Monitoring the Surface Condition of Polymeric Insulators Using Harmonic Content. IET Gener. Transm. Distrib. 2011, 5, 751–759. [Google Scholar] [CrossRef]
- Kumbhar, S.G.; Sudhagar, P.E. An Integrated Approach of Adaptive Neuro-Fuzzy Inference System and Dimension Theory for Diagnosis of Rolling Element Bearing. Meas. J. Int. Meas. Confed. 2020, 166, 108266. [Google Scholar] [CrossRef]
- Forouhari, S.; Abu-Siada, A. Application of Adaptive Neuro Fuzzy Inference System to Support Power Transformer Life Estimation and Asset Management Decision. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 845–852. [Google Scholar] [CrossRef] [Green Version]
- Wadhwani, S.; Wadhwani, A.K.; Gupta, S.P.; Kumar, V. Detection of Bearing Failure in Rotating Machine Using Adaptive Neuro-Fuzzy Inference System. In Proceedings of the 2006 International Conference on Power Electronic, Drives and Energy Systems, New Delhi, India, 12–15 December 2006. [Google Scholar]
- Wu, J.-D.; Kuo, J.-M. Fault Conditions Classification of Automotive Generator Using an Adaptive Neuro-Fuzzy Inference System. Expert Syst. Appl. 2010, 37, 7901–7907. [Google Scholar] [CrossRef]
- Salahshoor, K.; Khoshro, M.S.; Kordestani, M. Fault Detection and Diagnosis of an Industrial Steam Turbine Using a Distributed Configuration of Adaptive Neuro-Fuzzy Inference Systems. Simul. Model. Pract. Theory 2011, 19, 1280–1293. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Vachtsevanos, G.; Orchard, M. Machine Condition Prediction Based on Adaptive Neuro-Fuzzy and High-Order Particle Filtering. IEEE Trans. Ind. Electron. 2011, 58, 4353–4364. [Google Scholar] [CrossRef]
- Chen, C.; Vachtsevanos, G.; Orchard, M.E. Machine Remaining Useful Life Prediction: An Integrated Adaptive Neuro-Fuzzy and High-Order Particle Filtering Approach. Mech. Syst. Signal Process. 2012, 28, 597–607. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, R.; Wang, D.; Yan, R.; Mao, K.; Shen, F. Machine Health Monitoring Using Local Feature-Based Gated Recurrent Unit Networks. IEEE Trans. Ind. Electron. 2017, 65, 1539–1548. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, P.; Yan, R.; Gao, R.X. Deep Learning for Improved System Remaining Life Prediction. Procedia Cirp 2018, 72, 1033–1038. [Google Scholar] [CrossRef]
- Nguyen, K.T.P.; Medjaher, K. A New Dynamic Predictive Maintenance Framework Using Deep Learning for Failure Prognostics. Reliab. Eng. Syst. Saf. 2019, 188, 251–262. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Liu, Y.; Zhang, C.; Wang, Z. Time Series Data for Equipment Reliability Analysis with Deep Learning. IEEE Access 2020, 8, 105484–105493. [Google Scholar] [CrossRef]
- Liao, L.; Jin, W.; Pavel, R. Enhanced Restricted Boltzmann Machine With Prognosability Regularization for Prognostics and Health Assessment. IEEE Trans. Ind. Electron. 2016, 63, 7076–7083. [Google Scholar] [CrossRef]
- Luo, B.; Wang, H.; Liu, H.; Li, B.; Peng, F. Early Fault Detection of Machine Tools Based on Deep Learning and Dynamic Identification. IEEE Trans. Ind. Electron. 2018, 66, 509–518. [Google Scholar] [CrossRef]
- Aydemir, G. Deep Learning Based Spectrum Compression Algorithm for Rotating Machinery Condition Monitoring. In Smart Materials, Adaptive Structures and Intelligent Systems; American Society of Mechanical Engineers: New York, NY, USA, 2018; Volume 1. [Google Scholar]
- Yuan, J.; Wang, K.; Wang, Y. Deep Learning Approach to Multiple Features Sequence Analysis in Predictive Maintenance. Lect. Notes Electr. Eng. 2018, 451, 581–590. [Google Scholar] [CrossRef]
- Udmale, S.S.; Singh, S.K.; Bhirud, S.G. A Bearing Data Analysis Based on Kurtogram and Deep Learning Sequence Models. Meas. J. Int. Meas. Confed. 2019, 145, 665–677. [Google Scholar] [CrossRef]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Huerta Herraiz, Á.; Pliego Marugán, A.; García Márquez, F.P. Photovoltaic Plant Condition Monitoring Using Thermal Images Analysis by Convolutional Neural Network-Based Structure. Renew. Energy 2020, 153, 334–348. [Google Scholar] [CrossRef] [Green Version]
- Zhou, F.; Gao, Y.; Wen, C. A Novel Multimode Fault Classification Method Based on Deep Learning. J. Control. Sci. Eng. 2017, 2017, 3583610. [Google Scholar] [CrossRef] [Green Version]
- Utah, M.N.; Jung, J.C. Fault State Detection and Remaining Useful Life Prediction in AC Powered Solenoid Operated Valves Based on Traditional Machine Learning and Deep Neural Networks. Nucl. Eng. Technol. 2020, 52, 1998–2008. [Google Scholar] [CrossRef]
- Wu, Z.; Guo, Y.; Lin, W.; Yu, S.; Ji, Y. A Weighted Deep Representation Learning Model for Imbalanced Fault Diagnosis in Cyber-Physical Systems. Sensors 2018, 18, 1096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Essien, A.; Giannetti, C. A Deep Learning Model for Smart Manufacturing Using Convolutional LSTM Neural Network Autoencoders. IEEE Trans. Ind. Inform. 2020, 16, 6069–6078. [Google Scholar] [CrossRef] [Green Version]
- Aydemir, G.; Paynabar, K. Image-Based Prognostics Using Deep Learning Approach. IEEE Trans. Ind. Inform. 2020, 16, 5956–5964. [Google Scholar] [CrossRef]
- Su, C.; Li, L.; Wen, Z. Remaining Useful Life Prediction via a Variational Autoencoder and a Time-Window-Based Sequence Neural Network. Qual. Reliab. Eng. Int. 2020, 36, 1639–1656. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, Y.; Liu, X.; Zheng, Y. A Digital-Twin-Assisted Fault Diagnosis Using Deep Transfer Learning. IEEE Access 2019, 7, 19990–19999. [Google Scholar] [CrossRef]
- Booyse, W.; Wilke, D.N.; Heyns, S. Deep Digital Twins for Detection, Diagnostics and Prognostics. Mech. Syst. Signal Process. 2020, 140, 106612. [Google Scholar] [CrossRef]
- Randall, R.B.; Antoni, J. Rolling Element Bearing Diagnostics—A Tutorial. Mech. Syst. Signal Process. 2011, 25, 485–520. [Google Scholar] [CrossRef]
- Antoni, J. Fast Computation of the Kurtogram for the Detection of Transient Faults. Mech. Syst. Signal Process. 2007, 21, 108–124. [Google Scholar] [CrossRef]
- Antoni, J. The Spectral Kurtosis: A Useful Tool for Characterising Non-Stationary Signals. Mech. Syst. Signal Process. 2006, 20, 282–307. [Google Scholar] [CrossRef]
- Zeng, H.; Cheung, Y. Feature Selection and Kernel Learning for Local Learning-Based Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1532–1547. [Google Scholar] [CrossRef] [Green Version]
- Wu, M.; Schölkopf, B. A Local Learning Approach for Clustering. In Proceedings of the Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; Volume 19. [Google Scholar]
- Roffo, G.; Melzi, S.; Castellani, U.; Vinciarelli, A. Infinite Latent Feature Selection: A Probabilistic Latent Graph-Based Ranking Approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1398–1406. [Google Scholar]
- Roffo, G.; Melzi, S. Ranking to Learn. In Proceedings of the New Frontiers in Mining Complex Patterns; Appice, A., Ceci, M., Loglisci, C., Masciari, E., Raś, Z.W., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 19–35. [Google Scholar]
- Roffo, G.; Melzi, S.; Cristani, M. Infinite Feature Selection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 4202–4210. [Google Scholar]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. Human-Level Concept Learning through Probabilistic Program Induction. Science 2015, 350, 1332–1338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA; pp. 1027–1035.
- Fei-Fei, L.; Fergus, R.; Perona, P. One-Shot Learning of Object Categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Society For Machinery Failure Prevention Technology. Fault Data Sets. Available online: https://www.mfpt.org/fault-data-sets/ (accessed on 23 April 2023).
- WindTurbineHighSpeedBearingPrognosis-Data; MathWorks Open Source and Community Projects. 2022. Available online: https://github.com/mathworks/WindTurbineHighSpeedBearingPrognosis-Data (accessed on 23 April 2023).
- Ben Ali, J.; Saidi, L.; Harrath, S.; Bechhoefer, E.; Benbouzid, M. Online Automatic Diagnosis of Wind Turbine Bearings Progressive Degradations under Real Experimental Conditions Based on Unsupervised Machine Learning. Appl. Acoust. 2018, 132, 167–181. [Google Scholar] [CrossRef]
- Matzka, S. Explainable Artificial Intelligence for Predictive Maintenance Applications. In Proceedings of the 2020 Third International Conference on Artificial Intelligence for Industries (AI4I), Irvine, CA, USA, 21–23 September 2020; pp. 69–74. [Google Scholar]
- UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 19 February 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison | LM-2 | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs. SN-2 | 0 | −4.7719 | 0 | 1 |
| Comparison | LM-3 | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs. SN-2 | 0 | −4.7719 | 0 | 1 |
| SN-2 vs. SN-3 | 0.9984 | 2.9413 | 375 | 0 |
| Comparison | LM-4 | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs. SN-2 | 0 | −4.7719 | 0 | 1 |
| SN-2 vs. SN-3 | 0.9999 | 3.6612 | 410 | 0 |
| SN-3 vs. SN-4 | 1 | 4.7924 | 465 | 0 |
| Comparison | LM-5 | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs. SN-2 | 0.0348 | −1.8143 | 86 | 1 |
| SN-2 vs. SN-3 | 1 × 10−4 | −3.6714 | 21 | 1 |
| SN-3 vs. SN-4 | 0.9999 | 3.6714 | 278 | 0 |
| SN-4 vs. SN-5 | 0.9999 | 3.7857 | 282 | 0 |
| Comparison | BFD-1 | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs. SN-2 | 0.0205 | −2.0429 | 78 | 1 |
| SN-2 vs. SN-3 | 0.9554 | 1.7 | 209 | 0 |
| SN-3 vs. SN-4 | 0.9629 | 1.7859 | 212 | 0 |
| SN-4 vs. SN-5 | 0.7923 | 0.8144 | 178 | 0 |
| SN-5 vs. SN-6 | 0.86 | 1.0802 | 173 | 0 |
| Comparison | BFD-2 | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs. SN-2 | 0.9998 | 3.527 | 557 | 0 |
| SN-2 vs. SN-3 | 0.4843 | −0.0393 | 330 | 0 |
| SN-3 vs. SN-4 | 0.3215 | −0.4635 | 303 | 0 |
| SN-4 vs. SN-5 | 0.6143 | 0.2906 | 351 | 0 |
| SN-5 vs. SN-6 | 1 | 4.1083 | 594 | 0 |
| Comparison | AI4I | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs SN-2 | 0 | −6.1948 | 73 | 1 |
| SN-2 vs SN-3 | 1 | 6.7322 | 1829 | 0 |
| SN-3 vs SN-4 | 1 | 6.7395 | 1830 | 0 |
| SN-4 vs SN-5 | 0 | −4.8255 | 259 | 1 |
| SN-5 vs SN-6 | 1 | 4.936 | 1585 | 0 |
| Comparison | WT | |||
| p-Value | Z-Value | Sig. Rank | Sig. | |
| SN-1 vs SN-2 | 0 | −4.5081 | 170 | 1 |
| SN-2 vs SN-3 | 1 | 5.4541 | 1202 | 0 |
| SN-3 vs SN-4 | 1 | 6.1491 | 1274 | 0 |
| SN-4 vs SN-5 | 1 | 4.3247 | 1085 | 0 |
| SN-5 vs SN-6 | 0.9998 | 3.5524 | 1005 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caliskan, A.; O’Brien, C.; Panduru, K.; Walsh, J.; Riordan, D. An Efficient Siamese Network and Transfer Learning-Based Predictive Maintenance System for More Sustainable Manufacturing. Sustainability 2023, 15, 9272. https://doi.org/10.3390/su15129272
Caliskan A, O’Brien C, Panduru K, Walsh J, Riordan D. An Efficient Siamese Network and Transfer Learning-Based Predictive Maintenance System for More Sustainable Manufacturing. Sustainability. 2023; 15(12):9272. https://doi.org/10.3390/su15129272
Chicago/Turabian StyleCaliskan, Abdullah, Conor O’Brien, Krishna Panduru, Joseph Walsh, and Daniel Riordan. 2023. "An Efficient Siamese Network and Transfer Learning-Based Predictive Maintenance System for More Sustainable Manufacturing" Sustainability 15, no. 12: 9272. https://doi.org/10.3390/su15129272