

Transfer Learning for Renewable Energy Systems: A Survey




Abstract
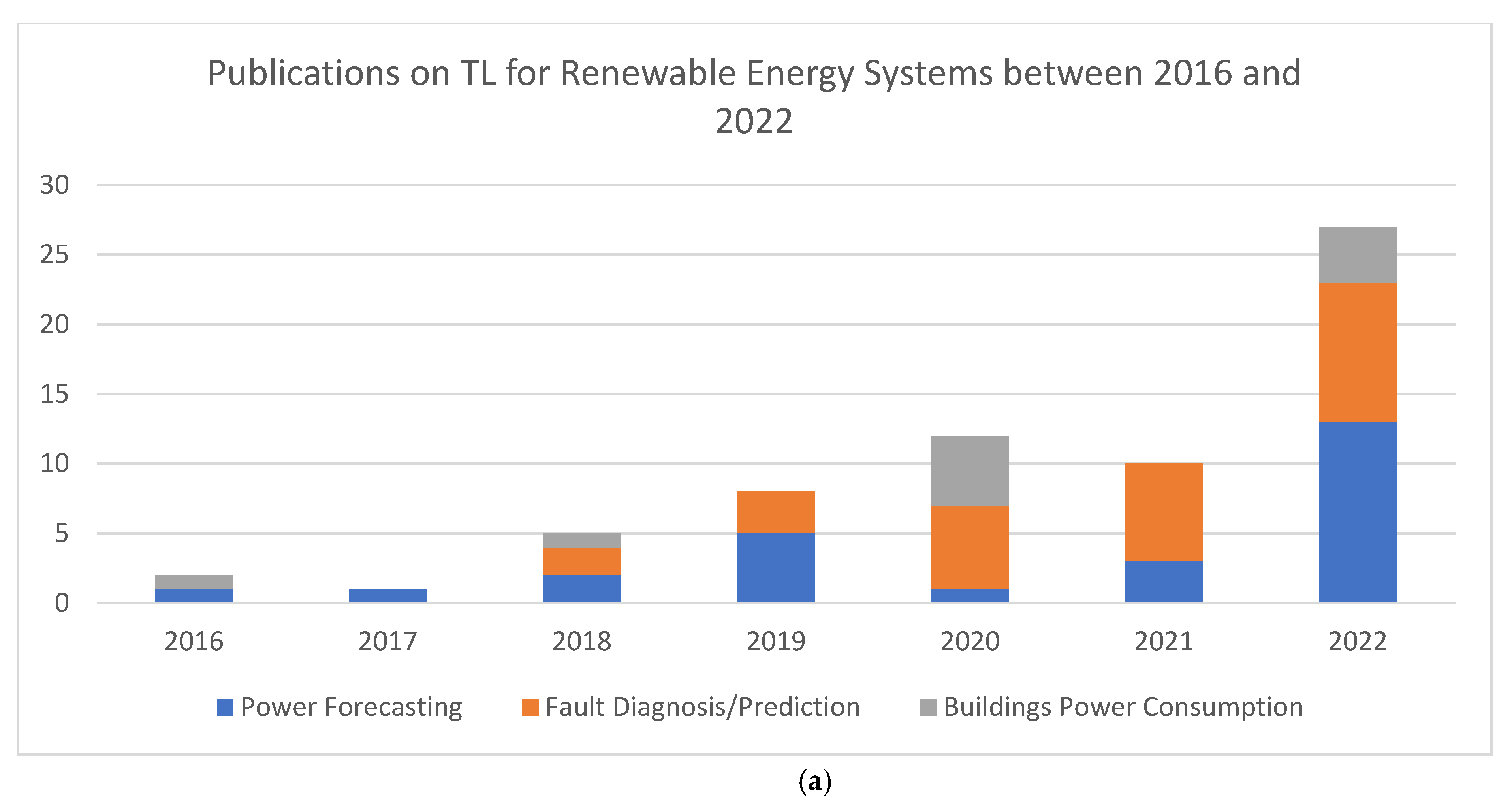
:1. Introduction
2. Transfer Learning
2.1. TL Definitions and Notations
2.2. Categories of TL Techniques
- The inductive TL has a source task, , and a target task, , that are different from each other. However, domains and may be the same or different. The inductive TL requires some labeled data in the target domain, , to deduce an objective predictive function, in the . In addition, if there is a sufficient amount of labeled data in the source domain, , in this case, inductive TL is considered similar to a multitasking learning case. However, if labeled data are not available in the source domain, , inductive TL will be a self-taught learning case [21,23,26].
- Transductive TL has tasks and , which are identical, whereas domains and are different (i.e. either the features spaces in the target and source domains are not the same, , or the same feature spaces are defined in the two domains but with different marginal probability distributions, and ) [21,23]. In this sub-setting, we assume that there are no labeled data in the target domain, , while there are enough in the source domain, .
- Unsupervised TL assumes that the source task, , and target task, , differ, but are related [21,23]. In general, this TL setting is used to solve unsupervised learning problems in the target domain, (e.g., dimensionality reduction and clustering). This type of sub-setting is not widely addressed in the RE literature.
- Instance-based approaches are data oriented and focus on transferring knowledge by adjusting data to reduce the distribution difference between the source and target domains. There are two main approaches for the instance-based category:
- 1.
- Instance weighting: The instances are assigned weights to reduce the marginal distribution difference.
- 2.
- Domain weighting: For multi-source domains, weights are assigned to each source to reduce the conditional distribution difference [27].
- Feature-based approaches are data-oriented and aim to find a new representation for each original feature. The main purpose of constructing a new feature representation is to minimize the conditional and marginal distribution differences and preserve potential data structures. This can be realized by feature augmentation, feature alignment, or feature reduction [21,23].
- Parameter-based approaches are model-based and transfer knowledge using model parameters that reflect the knowledge of those models. The two main approaches are as follows:
- 1.
- 2.
- Parameter restriction: The parameters of the target and source learners must be similar.
- The relational-based approaches transfer the logical relationships and rules accumulated in the source domain to the target.
3. TL for RE Systems
3.1. TL for Power Forecasting
3.2. TL for Cross-Building Energy Load Forecasting
3.3. TL for Fault Diagnosis in Energy Systems
3.3.1. Classical Fault Diagnosis Approaches
3.3.2. TL Approaches to Fault Diagnosis
- A.
- TL for Fault Diagnosis in Wind Turbines
- B.
- TL for the Defect Detection in PV Solar Panel Surfaces
4. Discussions and Challenges
4.1. Research Trends and Challenges
- (1)
- Most of the proposed TL frameworks for RE systems are trained and evaluated using source and target data records that are collected from particular areas and under common weather conditions.
- (2)
- Most of the collected datasets are private and cannot be shared due to security reasons, especially for faults diagnosis and buildings’ load forecasting systems. Most of the operators do not reveal enough information about the status of their systems. In addition, owners do not disclose enough information about the daily power consumption activities of their residential buildings, offices, and factories.
- Further studies are required to define a reliable method to evaluate and select the right source domain(s) to make an optimal transfer of knowledge to a target domain not having enough data. This necessitates a robust method to quantify the similarity between source and target domains, and therefore avoid the negative transfer issue.
- Few or no shared comprehensive benchmark datasets are available to evaluate and compare the already existing and the newly suggested TL-based approaches for RE applications.
- There are no common evaluation metrics to assess the performance of the proposed TL-based approaches for RE applications. The absence of a standard evaluation framework prevents the quantifying of the benefits provided by a TL-based approach to a classical ML-based one.
- There is no clear procedure to determine the amount of data in the source domain necessary for a successful transfer of knowledge. This limitation becomes critical in cases where applications depend on seasonal data; e.g., weather and solar radiation data for RE forecasting, daily activity data for buildings’ load forecasting, and weather conditions data for turbine faults predictions
4.2. Future Directions and Perspectives
- The availability of shared comprehensive datasets for each of the applications in RE is very helpful to evaluate and compare the newly suggested TL-based approaches in RE systems. In addition, preparing a standard evaluation framework with common evaluation metrics to compare and benchmark different TL-based approaches in RE will surely make a true impact in this direction.
- A potential opportunity to improve the TL-based approaches for RE systems consists of preparing robust guidance about the common input features required in the learning datasets that is available in a source domain. That will help in increasing the benefits of applying TL to RE systems. Therefore, studies on quantifying the importance of a particular feature or a specific set of features in a source domain are needed. This will also help to improve the overall performance of a TL-based approach for all three topics mentioned in this survey.
- In addition, the use of standard setups and metrics to evaluate the performance of available TL-based solutions will certainly make the comparison between those solutions in terms of efficiency, stability, and mobility a possible and easy task.
- Reinforcement learning is currently used to optimize energy usage in buildings, and there are potential opportunities to use it within the TL-frameworks to predict energy consumption in buildings. This will definitely allow the development of load prediction models that can be efficient and quickly adapted to different buildings and environments.
- Not all the suggested TL-based approaches in the literature are easily implemented in real-world RE projects since most of the reported challenges and limitations are estimated to become more obvious when deployed in real applications. Therefore, a comprehensive survey about the deployed TL-based approaches in RE systems and smart grids is adequate and beneficial to helping RE researchers identify the challenges in real-world scenarios.
4.3. Contribution and Limitations
- (1)
- Among the related research that we found in the literature, few works provide details about the improvement one can obtain by adopting TL for RE forecasting, load forecasting, and fault diagnosis and prediction. Furthermore, researchers who reported the benefit provided by TL have used different performance metrics. This fact prevented a fair comparison among the different suggested solutions.
- (2)
- The limitation and even the absence of comparative analysis in most of the related TL applications for RE systems prevented scholars from concluding the cons and pros of each particular approach.
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Qiu, Y.; Feng, Y.; Li, Y.; Kusiak, A. Diagnosis of wind turbine faults with transfer learning algorithms. Renew. Energy 2021, 163, 2053–2067. [Google Scholar] [CrossRef]
- Ahmed, W.; Hanif, A.; Kallu, K.D.; Kouzani, A.Z.; Ali, M.U.; Zafar, A. Photovoltaic panels classification using isolated and transfer learned deep neural models using infrared thermo graphic images. Sensors 2021, 21, 5668. [Google Scholar] [CrossRef]
- Lai, J.-P.; Chang, Y.-M.; Chen, C.-H.; Pai, P.-F. A Survey of Machine Learning Models in Renewable Energy Predictions. Appl. Sci. 2020, 10, 5975. [Google Scholar] [CrossRef]
- Carneiro, T.C.; De Carvalho, P.C.M.; Dos Santos, H.A.; Lima, M.A.F.B.; Braga, A.P.D.S. Review on Photovoltaic Power and Solar Resource Forecasting: Current Status and Trends. J. Sol. Energy Eng. 2022, 144, 1–84. [Google Scholar] [CrossRef]
- Al-Hajj, R.; Assi, A.; Fouad, M. Short-Term Prediction of Global Solar Radiation Energy Using Weather Data and Machine Learning Ensembles: A Comparative Study. J. Sol. Energy Eng. 2021, 143, 051003. [Google Scholar] [CrossRef]
- Kusiak, A.; Verma, A. Prediction of Status Patterns of Wind Turbines: A Data-Mining Approach. J. Sol. Energy Eng. 2011, 133, 011008. [Google Scholar] [CrossRef]
- Al-Hajj, R.; Assi, A.; Fouad, M.; Mabrouk, E. A Hybrid LSTM-Based Genetic Programming Approach for Short-Term Prediction of Global Solar Radiation Using Weather Data. Processes 2021, 9, 1187. [Google Scholar] [CrossRef]
- Duchesne, L.; Karangelos, E.; Wehenkel, L. Recent developments in machine learning for energy systems reliability managment. Proc. IEEE 2020, 108, 1656–1676. [Google Scholar] [CrossRef]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, Bollywood, Boom-Boxes and Blenders: Domain Adaptation for Sentiment Classification. In Proceedings of the 45th Ann. Meeting of the Assoc. Computational Linguistics, Prague, Czech Republic, 25–26 June 2007; pp. 432–439. [Google Scholar]
- Schreiber, J. Transfer learning in the field of renewable energies—A transfer learning framework providing power forecasts throughout the lifecycle of wind farms after initial connection to the electrical grid. arXiv 2019, arXiv:1906.01168. [Google Scholar]
- Hu, Q.; Zhang, R.; Zhou, Y. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, L.; Mao, M.; Xi, X. Transfer learning for photovoltaic power forecasting with long short-term memory neural network. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 125–132. [Google Scholar]
- Tasnim, S.; Rahman, A.; Oo, A.M.T.; Haque, E. Wind power prediction in new stations based on knowledge of existing Stations: A cluster based multi source domain adaptation approach. Knowl.-Based Syst. 2018, 145, 15–24. [Google Scholar] [CrossRef]
- Ji, L.; Fu, C.; Ju, Z.; Shi, Y.; Wu, S.; Tao, L. Short-Term Canyon Wind Speed Prediction Based on CNN—GRU Transfer Learning. Atmosphere 2022, 13, 813. [Google Scholar] [CrossRef]
- Schreiber, J.; Vogt, S.; Sick, B. Task Embedding Temporal Convolution Networks for Transfer Learning Problems in Renewable Power Time Series Forecast. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 19–23 September 2021; pp. 118–134. [Google Scholar]
- Himeur, Y.; Elnour, M.; Fadli, F.; Meskin, N.; Petri, I.; Rezgui, Y.; Bensaali, F.; Amira, A. Next-generation energy systems for sustainable smart cities: Roles of transfer learning. Sustain. Cities Soc. 2022, 85, 104059. [Google Scholar] [CrossRef]
- Blitzer, J.; McDonald, R.; Pereira, F. Domain Adaptation with Structural Correspondence Learning. In Proceedings of the Conference on Empirical Methods in Natural Language, Sydney, Australia, 22–23 July 2006; pp. 120–128. [Google Scholar]
- Wu, P.; Dietterich, T.G. Improving SVM Accuracy by Training on Auxiliary Data Sources. In Proceedings of the Twenty-First International Conference (ICML 2004), Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer learning for activity recognition: A survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zheng, H.; Huang, Y.; Ding, X. Vehicle Type Recognition in Surveillance Images From Labeled Web-Nature Data Using Deep Transfer Learning. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2913–2922. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Baralis, E.; Chiusano, S.; Garza, P. A lazy approach to associative classification. IEEE Trans. Knowl. Data Eng. 2007, 20, 156–171. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef] [Green Version]
- Niu, S.; Liu, Y.; Wang, J.; Song, H. A decade survey of transfer learning (2010–2020). IEEE Trans. Artif. Intell. 2020, 1, 151–166. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P.; Sindhwani, V. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples. J. Mach. Learn. Res. 2006, 7, 2399–2434. [Google Scholar]
- Day, O.; Khoshgoftaar, T.M. A survey on heterogeneous transfer learning. J. Big Data 2017, 4, 29. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 270–279. [Google Scholar] [CrossRef] [Green Version]
- Shao, L.; Zhu, F.; Li, X. Transfer learning for visual categorization: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1019–1034. [Google Scholar] [CrossRef]
- Liu, R.; Shi, Y.; Ji, C.; Jia, M. A Survey of Sentiment Analysis Based on Transfer Learning. IEEE Access 2019, 7, 85401–85412. [Google Scholar] [CrossRef]
- Qureshi, A.S.; Khan, A. Adaptive transfer learning in deep neural networks: Wind power prediction using knowledge transfer from region to region and between different task domains. Comput. Intell. 2019, 35, 1088–1112. [Google Scholar] [CrossRef] [Green Version]
- Yin, H.; Ou, Z.; Fu, J.; Cai, Y.; Chen, S.; Meng, A. A novel transfer learning approach for wind power prediction based on a serio-parallel deep learning architecture. Energy 2021, 234, 121271. [Google Scholar] [CrossRef]
- Liang, T.; Zhao, Q.; Lv, Q.; Sun, H. A novel wind speed prediction strategy based on Bi-LSTM, MOOFADA and transfer learning for centralized control centers. Energy 2021, 230, 120904. [Google Scholar] [CrossRef]
- Yang, X.-S. Multiobjective firefly algorithm for continuous optimization. Eng. Comput. 2012, 29, 175–184. [Google Scholar] [CrossRef] [Green Version]
- Bo, H.; Niu, X.; Wang, J. Wind Speed Forecasting System Based on the Variational Mode Decomposition Strategy and Immune Selection Multi-Objective Dragonfly Optimization Algorithm. IEEE Access 2019, 7, 178063–178081. [Google Scholar] [CrossRef]
- Lin, Y.; Duan, D.; Hong, X.; Han, X.; Cheng, X.; Yang, L.; Cui, S. Transfer Learning on the Feature Extractions of Sky Images for Solar Power Production. In Proceedings of the IEEE Power & Energy Society General Meeting (PESGM), Atlanta, GA, USA, 4–8 August 2019; pp. 1–5. [Google Scholar]
- Cai, L.; Gu, J.; Ma, J.; Jin, Z. Probabilistic Wind Power Forecasting Approach via Instance-Based Transfer Learning Embedded Gradient Boosting Decision Trees. Energies 2019, 12, 159. [Google Scholar] [CrossRef] [Green Version]
- Abubakr, M.; Akoush, B.; Khalil, A.; Hassan, M.A. Unleashing deep neural network full potential for solar radiation forecasting in a new geographic location with historical data scarcity: A transfer learning approach. Eur. Phys. J. Plus 2022, 137, 474. [Google Scholar] [CrossRef]
- Qureshi, A.S.; Khan, A.; Zameer, A.; Usman, A. Wind power prediction using deep neural network based meta regression and transfer learning. Appl. Soft Comput. 2017, 58, 742–755. [Google Scholar] [CrossRef]
- Cao, L.; Wang, L.; Huang, C.; Luo, X.; Wang, J.-H. A transfer learning strategy for short-term wind power forecasting. In Proceedings of the Chinese Automation Congress (CAC), Xi’an, China, 30 November 2018; pp. 3070–3075. [Google Scholar]
- Liu, Y.; Wang, J. Transfer learning based multi-layer extreme learning machine for probabilistic wind power forecasting. Appl. Energy 2022, 312, 118729. [Google Scholar] [CrossRef]
- Khan, M.; Naeem, M.R.; Al-Ammar, E.A.; Ko, W.; Vettikalladi, H.; Ahmad, I. Power Forecasting of Regional Wind Farms via Variational Auto-Encoder and Deep Hybrid Transfer Learning. Electronics 2022, 11, 206. [Google Scholar] [CrossRef]
- Song, J.; Peng, X.; Yang, Z.; Wei, P.; Wang, B.; Wang, Z. A Novel Wind Power Prediction Approach for Extreme Wind Conditions Based on TCN-LSTM and Transfer Learning. In Proceedings of the IEEE/IAS Industrial and Commercial Power System Asia (I&CPS Asia), Shanghai, China, 8–11 July 2022; pp. 1410–1415. [Google Scholar]
- Oh, J.; Park, J.; Ok, C.; Ha, C.; Jun, H.B. A Study on the Wind Power Forecasting Model Using Transfer Learning Approach. Electronics 2022, 11, 4125. [Google Scholar] [CrossRef]
- Schreiber, J.; Sick, B. Multi-Task Auto-encoders and Transfer Learning for Day-Ahead Wind and Photovoltaic Power Forecasts. Energies 2022, 15, 8062. [Google Scholar] [CrossRef]
- Yu, S.; Vautard, R. A transfer method to estimate hub-height wind speed from 10 meters wind speed based on machine learning. Renew. Sustain. Energy Rev. 2022, 169, 112897. [Google Scholar] [CrossRef]
- Geng, R.; Long, H.; Gu, W. Small-Sample Interval Prediction Model based on Transfer Learning for Solar Power Prediction. In Proceedings of the IEEE 5th International Electrical and Energy Conference (CIEEC), Nanjing, China, 27–29 May 2022; pp. 4739–4743. [Google Scholar]
- Tajjour, S.; Chandel, S. Power Generation Forecasting of a Solar Photovoltaic Power Plant by a Novel Transfer Learning Technique with Small Solar Radiation and Power Generation Training Data Sets. 2022, p. 4024225. Available online: https://ssrn.com/abstract=4024225 (accessed on 11 December 2022).
- Ribeiro, M.; Grolinger, K.; ElYamany, H.F.; Higashino, W.A.; Capretz, M.A. Transfer learning with seasonal and trend ad-justment for cross-building energy forecasting. Energy Build. 2018, 165, 352–363. [Google Scholar] [CrossRef]
- Mocanu, E.; Nguyen, P.H.; Kling, W.L.; Gibescu, M. Unsupervised energy prediction in a Smart Grid context using rein-forcement cross-building transfer learning. Energy Build. 2016, 116, 646–655. [Google Scholar] [CrossRef] [Green Version]
- Ahn, Y.; Kim, B.S. Prediction of building power consumption using transfer learning-based reference building and simulation dataset. Energy Build. 2022, 258, 111717. [Google Scholar] [CrossRef]
- Gao, Y.; Ruan, Y.; Fang, C.; Yin, S. Deep learning and transfer learning models of energy consumption forecasting for a building with poor information data. Energy Build. 2020, 223, 110156. [Google Scholar] [CrossRef]
- Jin, Y.; Acquah, M.A.; Seo, M.; Han, S. Short-term electric load prediction using transfer learning with interval estimate adjustment. Energy Build. 2022, 258, 111846. [Google Scholar] [CrossRef]
- Pinto, G.; Wang, Z.; Roy, A.; Hong, T.; Capozzoli, A. Transfer learning for smart buildings: A critical review of algorithms, applications, and future perspectives. Adv. Appl. Energy 2022, 5, 100084. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T. Reinforcement learning for building controls: The opportunities and challenges. Appl. Energy 2020, 269, 115036. [Google Scholar] [CrossRef]
- Wiering, M.A.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 729. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Lazaric, A. Transfer in Reinforcement Learning: A Framework and a Survey. In Reinforcement Learning: State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2012; pp. 143–173. [Google Scholar]
- Taylor, M.E.; Stone, P. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Gonzalez-Vidal, A.; Mendoza-Bernal, J.; Niu, S.; Skarmeta, A.F.; Song, H. A Transfer Learning Framework for Predictive Energy-Related Scenarios in Smart Buildings. IEEE Trans. Ind. Appl. 2022, 59, 26–37. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, W.; Zhang, G.; Shu, L. Wind turbine fault diagnosis based on transfer learning and convolutional autoencoder with small-scale data. Renew. Energy 2021, 171, 103–115. [Google Scholar] [CrossRef]
- Gray, C.S.; Watson, S.J. Physics of Failure approach to wind turbine condition based maintenance. Wind. Energy 2010, 13, 395–405. [Google Scholar] [CrossRef]
- Qiu, Y.; Feng, Y.; Sun, J.; Zhang, W.; Infield, D. Applying thermophysics for wind turbine drivetrain fault diagnosis using SCADA data. IET Renew. Power Gener. 2016, 10, 661–668. [Google Scholar] [CrossRef] [Green Version]
- Bangalore, P.; Tjernberg, L.B. An Artificial Neural Network Approach for Early Fault Detection of Gearbox Bearings. IEEE Trans. Smart Grid 2015, 6, 980–987. [Google Scholar] [CrossRef]
- Xiao, Y.; Kang, N.; Hong, Y.; Zhang, G. Misalignment Fault Diagnosis of DFWT Based on IEMD Energy Entropy and PSO-SVM. Entropy 2017, 19, 6. [Google Scholar] [CrossRef]
- Chen, Z.; Han, F.; Wu, L.; Yu, J.; Cheng, S.; Lin, P.; Chen, H. Random forest based intelligent fault diagnosis for PV arrays using array voltage and string currents. Energy Convers. Manag. 2018, 178, 250–264. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, J.; Qu, C.; Pan, T. Intelligent fault diagnosis of Wind Turbines via a Deep Learning Network Using Parallel Convolution Layers with Multi-Scale Kernels. Renew. Energy 2020, 153, 205–213. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, H.; Hu, W.; Yan, X. Anomaly detection and fault analysis of wind turbine components based on deep learning network. Renew. Energy 2018, 127, 825–834. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, W.; Wang, X.; Gu, H. A novel wind turbine fault diagnosis method based on compressed sensing and DTL-CNN. Renew. Energy 2018, 194, 249–258. [Google Scholar] [CrossRef]
- Zhang, C.; Bin, J.; Liu, Z. Wind turbine ice assessment through inductive transfer learning. In Proceedings of the IEEE Inter-national Instrumentation and Measurement Technology Conference (i2mtc), Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar]
- Zhang, Y.; Liu, W.; Gu, H.; Alexisa, A.; Jiang, X. A novel wind turbine fault diagnosis based on deep transfer learning of im-proved residual network and multi-target data. Meas. Sci. Technol. 2022, 33, 095007. [Google Scholar] [CrossRef]
- Zyout, I.; Oatawneh, A. Detection of PV Solar Panel Surface Defects using Transfer Learning of the Deep Convolutional Neural Networks. In Proceedings of the Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 9 April 2020; pp. 1–4. [Google Scholar]
- Akram, M.W.; Li, G.; Jin, Y.; Chen, X.; Zhu, C.; Ahmad, A. Automatic detection of photovoltaic module defects in infrared images with isolated and develop-model transfer deep learning. Sol. Energy 2020, 198, 175–186. [Google Scholar] [CrossRef]
- Korkmaz, D.; Acikgoz, H. An efficient fault classification method in solar photovoltaic modules using transfer learning and multi-scale convolutional neural network. Eng. Appl. Artif. Intell. 2022, 113, 104959. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Y.; Lv, W.; Wang, D. Image recognition of wind turbine blade damage based on a deep learning model with transfer learning and an ensemble learning classifier. Renew. Energy 2021, 163, 386–397. [Google Scholar] [CrossRef]
- Demirci, M.Y.; Beşli, N.; Gümüşçü, A. Defective PV Cell Detection Using Deep Transfer Learning and EL Imaging. In Proceedings Book; Van Yüzüncü Yıl University: Van, Turkey, 2019; p. 311. [Google Scholar]
- Zhu, Y.; Zhu, C.; Tan, J.; Tan, Y.; Rao, L. Anomaly detection and condition monitoring of wind turbine gearbox based on LSTM-FS and transfer learning. Renew. Energy 2022, 189, 90–103. [Google Scholar] [CrossRef]
- Hou, D.; Ma, J.; Huang, S.; Zhang, J.; Zhu, X. Classification of Defective Photovoltaic Modules in ImageNet-Trained Networks Using Transfer Learning. In Proceedings of the IEEE 12th Energy Conversion Congress & Exposition-Asia (ECCE-Asia), Singapore, 24 May 2021; pp. 2127–2132. [Google Scholar]
- Chatterjee, J.; Dethlefs, N. Deep learning with knowledge transfer for explainable anomaly prediction in wind turbines. Wind. Energy 2020, 23, 1693–1710. [Google Scholar] [CrossRef]
- Liu, X.; Ma, H.; Liu, Y. A Novel Transfer Learning Method Based on Conditional Variational Generative Adversarial Networks for Fault Diagnosis of Wind Turbine Gearboxes under Variable Working Conditions. Sustainability 2022, 14, 5441. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, DC, USA, 28 June 2011; pp. 513–520. [Google Scholar]
- Yu, L.; Qin, S.; Zhang, M.; Shen, C.; Jiang, T.; Guan, X. A Review of Deep Reinforcement Learning for Smart Building Energy Management. IEEE Internet Things J. 2021, 8, 12046–12063. [Google Scholar] [CrossRef]
- Zhang, X.; Jin, X.; Tripp, C.; Biagioni, D.J.; Graf, P.; Jiang, H. Transferable reinforcement learning for smart homes. In Proceedings of the 1st International Workshop on Reinforcement Learning for Energy Management in Buildings & Cities, Virtual, 17 November 2020; pp. 43–47. [Google Scholar]
- Zhu, Z.; Lin, K.; Jain, A.K.; Zhou, J. Transfer learning in deep reinforcement learning: A survey. arXiv 2020, arXiv:2009.07888. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transfer Type | Features Domain | Task | ||
|---|---|---|---|---|
| Homogeneous | Inductive Learning | and have the same input features. For instance, temperature, humidity, and solar radiation. The is tuned to forecast solar power instead of heat index or dew point [17]. | ||
| Transductive Learning | and have the same input features but different marginal distribution. For instance, temperature, humidity, and air density. The and are both used to forecast solar radiation [11]. | |||
| Heterogeneous | Inductive Learning | and have a different number of features. For instance, the air pressure is additionally used in the to forecast solar power instead of heat index or dew point [25,26]. | ||
| Transductive Learning | , | and have different but related features of one solar station location. The underlying marginal distributions are equal due to the similar location of solar station. and forecast the solar power [12,13]. |
| Authors | TL Sub Setting | Transfer Type | Features | Target to Predict | ML Models |
|---|---|---|---|---|---|
| Hu, Q., et al. (2016) [11] | Homogeneous Transductive | Feature-based Transfer | Wind speed | Wind speed | Deep learning with shared hidden layers |
| Zhou, S., et al. (2020) [12] | Heterogeneous Inductive | Feature-based Transfer | Solar irradiance data, PV output data | Photovoltaic power forecasting | LSTM with sequential model-based global optimization SMBO |
| Tasnim, S., et al. (2018) [13] | Homogeneous inductive | Instance-based Transfer | Statistical features of wind speed (mean, std deviation, skewness, …) | Wind power | Regression models with multi-Source data adaptation MSDA |
| Ji, L., et al. (2022) [14] | Homogeneous transductive | Instance-based Transfer | Meteorological features | Wind speed | CNN and GRU |
| Qureshi, A., et al. (2018) [32], (2017) [41] | Homogeneous inductive | Feature-based Transfer | Wind speed and wind direction | Wind speed | DNN and ensemble learning |
| Yin, H., et al. (2021) [33] | Homogeneous transductive | Model-based (parameters passed) | Weather features | Wind power | CNN, LSTM, and fully connected networks. |
| Liang, T., et al. (2021) [35] | Homogeneous transductive | Model-based | Wind speed and direction | Wind speed | Bi-LSTM with multi-objective optimization |
| Lin, Y., et al. (2019) [38] | Homogeneous transductive | Parameters-based | Sky images | Solar radiation | Deep CNN |
| Cai, L., et al. (2019) [39] | Homogeneous transductive | Instance-based | Power energy statistics, wind speed, wind directions | Wind power | GBDT |
| Abubak et al. (2022) [40] | Homogenous inductive | Parameter-based | Solar radiation | Solar radiation | Recurrent neural network |
| Cao, L., et al. (2018) [42] | Homogeneous transductive | Instance-based | Time series wind power | Wind power | Extreme gradient boosting |
| Liu, Y., et al. (2022) [43] | Homogeneous transductive | Model-based | Wind power | Wind power | MLP + particle swarm optimization |
| Abubak et al. (2022) [43] | Homogenous inductive | Parameter-based | Solar radiation | Solar radiation | Recurrent neural network |
| Khan et al. (2022) [44] | Homogeneous inductive | Parameter-based | Wind and energy measurements | Wind power | Deep neural network |
| Jifeng Song et al. (2022) [45] | Homogeneous inductive | Parameter-based | Weather, turbine, and rotor functions | Wind power | Temporal convolutional network + LSTM |
| JeongRim et al. (2022) [46] | Homogeneous inductive | Model-based | Weather data and wind power generation data | Wind power | Light gradient boosting machine |
| Schreiber et al. (2022) [47] | Homogeneous inductive | Parameter-based | Weather data | Wind/Solar power | Temporal convolutional network + auto encoders |
| Shuang Yu et al. (2022) [48] | Homogeneous inductive | Model-based | Weather and climate data | Wind speed | Random forest + XGBoost |
| Runhao et al. (2002) [49] | Homogeneous | Instance-based | Solar power data of PV power station | Solar power | Extreme learning machine + TrAdaBoost |
| Tajjour et al. [50] | Homogeneous inductive | Model-based | Satellite data of solar radiation | Photovoltaic power | Deep neural networks DNN |
| Authors | TL Sub Setting | Transfer Type | Features | Type-of Building | ML Models |
|---|---|---|---|---|---|
| Ribeiro, M. et al. (2018) [51] | Inductive | Instance-based | Time data + weather features + energy consumption | Schools | Regression models: MLP and SVR |
| Mocanu, E.et al. (2016) [52] | Unsupervised | Model-based | Loads profiles (time-of-use, lightening, existence of electrical heater,…) | Cross-types residential + commercial | Reinforcement learning models + DBN |
| Ahn, Y. (2022) [53] | Transductive | Instance-based | Meteorological + time data | Offices | LSTM |
| Gao, Y. (2020) [54] | Inductive | Model-based | Numerical weather features + categorical (holiday, day of weak) | Offices | LSTM + 2D-CNN |
| Jin, Y. (2022) [55] | Transductive | Parameters-based | Time data + weather features + energy load | Residential + commercial | Hybrid CNN-GRU |
| Gonzalez-Vidal et al. (2022) [62] | Transductive | Instance-based | Weather features + building meta data | Non-residential + offices | LSTM + CNN |
| Research | Energy | Base Model | Transfer Type | Source Data | Target Data |
|---|---|---|---|---|---|
| Li et al. (2021) [63] | Wind | Convolutional autoencoder | Homogenous, parameter-based | Operational data of 14 wind turbine | Operational data of 1 wind turbine |
| Zhang et al. (2022) [73] | Wind | Deep ResNet | Transductive model-based | Bearing datasets + gears datasets | Bearing datasets + gears datasets |
| Zyout et al. (2020) [74] | Solar | Alexnet CNN | Heterogeneous, parameter-based | Large object recognition dataset | RGB images of solar panels |
| Akram et al. (2020) [75] | Solar | CNN | Heterogeneous, parameter-based | Infrared images | Electroluminescence images |
| Yan Zhang et al. (2020) [71] | Wind | CNN | Heterogeneous, parameter-based | Bearing dataset | Gear dataset |
| Zhang et al. (2018) [72] | Wind | Fully-connected NN | Inductive, parameter-based | SCADA dataset | SCADA dataset |
| Korkmaz et al. (2022) [76] | Solar | Multi-scale CNN (Alexnet variant) | Heterogeneous, parameter-based | Large object recognition dataset | Infrared images |
| Yang et al. (2021) [77] | Wind | Alexnet CNN | Heterogeneous, parameter-based | Large object recognition dataset | UAV images |
| Demirci et al. (2019) [78] | Solar | CNN | Homogenous, parameter-based | Electroluminescent imaging | Electroluminescent Imaging |
| Zhu et al. (2022) [79] | Wind | LSTM | Feature-based | Monitoring data | Monitoring data |
| Hou et al. (2021) [80] | Solar | CNN | Heterogeneous, parameter-based | ImageNet | Electroluminescent Imaging |
| Chatterjee et al. (2020) [81] | Wind | LSTM, XGBoost | Transductive, feature-based | SCADA dataset | SCADA dataset |
| Korkmaz et al. (2022) [76] | Solar | Multi-scale CNN | Homogeneous parameters-based | Thermographic images | Thermographic images |
| Chen et al. (2021) [1] | Wind | CNN | Parameter-based | SCADA dataset | SCADA dataset |
| Liu et al. (2022) [82] | Wind | DLL generative adversarial Nets GAN | Transductive feature-based | Wind turbine transmission dataset (unbalanced) | Wind turbine transmission dataset |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Hajj, R.; Assi, A.; Neji, B.; Ghandour, R.; Al Barakeh, Z. Transfer Learning for Renewable Energy Systems: A Survey. Sustainability 2023, 15, 9131. https://doi.org/10.3390/su15119131
Al-Hajj R, Assi A, Neji B, Ghandour R, Al Barakeh Z. Transfer Learning for Renewable Energy Systems: A Survey. Sustainability. 2023; 15(11):9131. https://doi.org/10.3390/su15119131
Chicago/Turabian StyleAl-Hajj, Rami, Ali Assi, Bilel Neji, Raymond Ghandour, and Zaher Al Barakeh. 2023. "Transfer Learning for Renewable Energy Systems: A Survey" Sustainability 15, no. 11: 9131. https://doi.org/10.3390/su15119131