1. Introduction
Tabular data are the most common type because it covers many exciting problems in various domains. In addition, the predictive and explanatory modeling on tabular data is a non-trivial task because those models often need to be interpreted by explaining real-world phenomena.
Artificial intelligence (AI) recently has shown super-human performance in many domains including image processing, natural language processing, etc. However, researchers have been developing very complex black box models to achieve the high predictive performance. Nonetheless, such complex deep learning models do not show good predictive accuracy on tabular data, and it is challenging to explain output of them. Therefore, simple interpretable machine learning models are still broadly applied for modeling tabular data. For example, ordinary least squares (OLS) regression has been extensively employed to explain a wide variety of economic relationships [
1,
2]. Because the statistical properties of linear regression make it trustworthy, linear regression coefficients have been used as a model interpreter by determining the effect of each input feature on the output [
3]. Unfortunately, the predictive capacity of OLS regression is not stronger than black box machine learning models [
4]. On the other hand, deep learning models achieved significantly higher predictive performance on those types of data, such as audios, images or videos, and texts. Still, they have not shown better predictive performance than ensemble models, such as lightGBM, CatBoost, etc., on tabular data [
5,
6].
In addition, many techniques for explainability in machine learning (ML) have been proposed to understand the predictions provided by complex ML models. The most popular methods for explainable AI are shapley additive explanations (SHAP) and local interpretable model-agnostic explanations (LIME) [
7,
8]. Unfortunately, researchers have not done much work designing explainable methods for tabular data [
9].
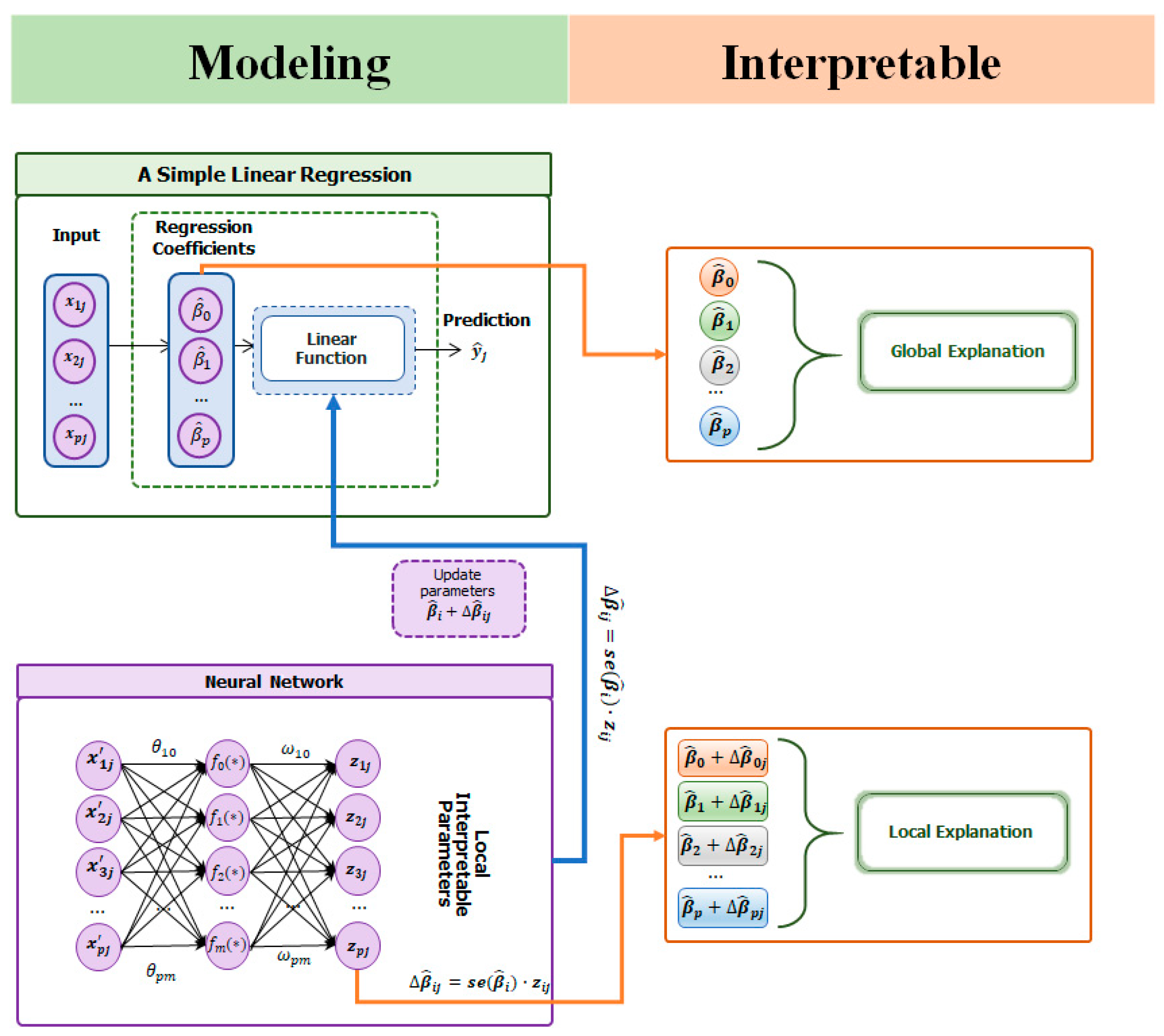
In this study, we introduce a novel neural network-based locally adaptive linear regression model by combining a simple OLS regression and feed-forward neural networks to provide model interpretability with high predictive performance for tabular data. Our proposed framework for tabular data is shown in
Figure 1. We first estimate the linear regression coefficients using OLS method to generalize our base learner. In this phase, we do not normalize the input data (
) to obtain meaningful regression coefficients to calculate the exact effect of each input variable on the output. In the second phase, we train neural network model based on the normalized input data (
) to update the regression coefficients for each current observation. The neural networks are used as our meta-learner to adjust the weight parameter of base-learner as known as regression coefficients for each observation to improve the predictive performance. As shown in
Figure 1, we update each regression coefficient using the formula for the confidence interval (CI) and then rebuild an interpretable local linear model for each observation.
In our proposed model, since we use the formula for a CI, the adjusted regression coefficients should be in a range between their lower and upper confidence intervals. Therefore, our proposed model can avoid overfitting, and the model interpretable is identical with OLS regression. At the same time, we can extend the predictive power of linear regression.
We evaluated the predictive performance and model interpretability of our proposed approach on the benchmark tabular datasets for regression task. Our proposed model achieved slightly higher predictive performance than regression and the state-of-the-art models. Furthermore, we also showed that our proposed model can measure a local effect of each input variable on the output for each observation.
The contributions of this study are listed as follows:
- (1)
We introduce a neural network-based interpretable local linear regression model for tabular data.
- (2)
The linear regression coefficients are the same for all observations in a data, further degrading its predictive performance. We design regression coefficients as locally adaptable within their confidence intervals using a meta-level neural network model. Our proposed model parameterizes a local linear function for each example in a given data; therefore, the predictive performance of OLS regression is significantly improved.
- (3)
Our proposed model can avoid overfitting because the adapted coefficients range between their lower and upper confidence intervals.
- (4)
Our proposed model can measure a local effect of each input variable on the output. Therefore, our model can be applicable for many real-world applications, such as economics, biology, management, and social science, where data type is tabular and interpretable models are required.
The work is organized as follows.
Section 2 presented the discussion of related research, and
Section 3 introduced the proposal of our neural network-based architecture. The comparison and experiment results are presented in
Section 4. We summarized this work and described the further research area at the end.
2. Related Work
Developing locally adaptive regression approaches have begun much earlier [
10,
11,
12,
13]. Those approaches can be classified into three main categories—nearest neighbor regression, weighted averaging regression, and locally weighted regression [
14]. Nearest neighbor regression uses
k most relative instances for a query instance to obtain its best fitting function for the target point [
12,
15]. Weighted averaging methods compute a weighted output of neighboring samples, weighted by using their similarities to the target point [
16,
17]. Locally weighted regression (LWR) is very similar to our proposed model because these models do not consider a fixed set of parameters for each instance [
11,
12]. However, the main weakness of nearest neighbor-based models is similar to the memory-based learning algorithms, where they keep full training data to provide the prediction for test data. This disadvantage makes them computationally expensive on large data. Instead, we use the neural networks as our meta-learner model that can adjust the parameters of the base-learner for each instance during the training process; therefore, our proposed model will be more efficient in terms of memory usage and time consumption on large datasets.
Using neural networks (meta-learner) to generate weight parameters for another one (base-learner) has been designed in the meta-learning field [
18,
19,
20]. Based on this idea, we train a meta-learner model to retrieve the local best linear model for each instance by producing the parameters of base-learner. The parameters produced by the meta-learner are known as fast-weights in the field of meta-learning. Our proposed model is similar to the Meta Networks (MetaNet) [
21] that uses an additional neural network model to generate the fast-weights for rapid generalization. This approach has been successfully used on images, text, and audio data [
22,
23,
24]. However, our proposed architecture is interpretable and for tabular data, which is different from MetaNet.
Furthermore, there are several similar approaches for tabular data [
25,
26,
27]. For example, Bildirici and Ersin (2009) [
25] improved GARCH family models by artificial neural networks for financial time-series data. Furthermore, Bildirici and Ersin (2014) [
26] also combined Markov switching ARMA-GARCH model with neural networks to predict exchange rates and stock returns. They used neural network approach to predict the parameter of ARMA and GARCH models, which is very similar with our work. Recently, LocalGLMnet architecture has been proposed in Richman and Wuthrich, (2021) [
27], which is also very similar with our proposed architecture. This model improves the predictive power of GLMs by using neural networks and provides an explainability same as GLMs. The authors predict the parameters of GLMs using neural network to achieve superior predictive performance. The idea of this work is same as our proposed model, but the predicted parameters cannot be consistency of explaining the logical relationship between input and output variables. This is because the predicted parameters of GLMs highly depend on the weight parameter initialization for neural networks since they use gradient descent optimization algorithm to train LocalGLMnet. In other words, the main advantage of our work is that we first perform OLS to obtain unbiased regression coefficients, and then update them into their confidence intervals using neural network approach.
Another similar work is done by Takagi and Sugeno [
28] called the TS fuzzy model. This method offers a new technique to build multi-models representing local input–output relations of a non-linear system. However, due to a large number of variables and the nature of the continuous variables for the regression task, the TS fuzzy model usually utilizes a tremendously enormous number of rules and does not consider the complexity of the model [
29]. Unlike TS fuzzy models, the benefit of our proposed model is that we do not use rules, and our meta-learner learns these rules automatically based on a given data.
In addition, although the state-of-the-art ML models have showed magnificent predictive performance in various domains, the inability to explain them decreases humans’ trust. Subsequently, eXplainable AI (XAI) has become a significant and active research area [
30]. Recently, a large number of studies has been done to understand the black-box model and increase humans’ trust. However, most studies focused on post-explainability rather than explainable models [
5,
8,
31,
32].
4. Experimental Result
4.1. Benchmark Datasets
We presented benchmark public tabular datasets in
Table 1. These datasets for the regression task were employed to evaluate the predictive performance. Datasets from 1 to 5 were retrieved from UCI Machine Learning Repository for regression task [
37]. Other 3 datasets are downloaded from different sources such as California Housing dataset for predicting house price is retrieved from [
38], FICO dataset for credit scoring is download from [
39] and Bodyfat for estimating body fat is downloaded from [
40].
We also trained our model on synthetic and the real-world economic datasets to demonstrate the model interpretability in
Section 4.4.
4.2. Baseline Models and Hyperparameters
For regression baselines, a linear regression (OLS), Bayesian (Bayesian) [
41] lasso [
42], and ridge [
43] regressions are chosen in the predictive performance comparison.
For other alternative baselines, we compare our results to Neural Additive Model (NAM) [
44] and TabNet [
6] models, which are the most popular and high-performance interpretable models for tabular data. We also performed additional experiments using LightGBM [
45] and Catboost [
46] machine learning algorithms to compare their predictive performance to our model.
We also need to configure the model architecture of our meta-learner and its hyperparameters for training. We trained two types of architectures—meta-learner consists of multiple MLPs by assigning each MLP to each regression coefficient (mult MLP), and meta-learner consists of a single MLP with multiple outputs; number of neurons for output layer must be the same as the number of variables including intercept (single MLP). The architecture of each MLP is constructed by three hidden layers with {256, 256, and 256} neurons.
For other hyperparameters, we set the maximum epoch number equal to 10,000 and the learning rate equal to 0.01. We used an Early Stopping algorithm to select the best model on the validation set. We set the same configuration for all datasets and used the five-fold cross-validation method to evaluate and compare the models.
4.3. Evaluation Metrics
The evaluation metrics for regression task mostly calculate the error between the observed and predicted values for target variables [
47]. The root mean square error (RMSE) and mean absolute error (MAE) are used to measure the model performances.
where
is the
i-th predicted value,
is the
i-th observed value, and
is the number of observation in the test set.
4.4. Comparison of Predictive Performance
The aim of this experiment analysis is to show how the predictive performance of OLS regression is improved after being augmented by neural networks.
Our proposed model achieved outstanding predictive performance on 3 out of 8 datasets (Energy Efficiency, Naval Propulsion, and Bodyfat) for RMSE evaluation metric and showed similar predictive performance on the other datasets (see
Table 2). The regression baseline models showed poorer predictive performance than our proposed model on all datasets. As shown in
Table 2, the predictive performance of OLS regression is weaker than that of the Lasso, Ridge, and Bayesian regressions, but its predictive power has improved significantly after being augmented by the neural networks.
Table 3 reported the predictive performance on 8 datasets using the MAE evaluation metric. From the results, we can see that our proposed model notably outperformed the regression and the state-of-the-art baseline models on four datasets (Energy Efficiency, Naval Propulsion, Protein Structure, and Bodyfat).
For machine learning models, LightGBM model showed the best performance on three datasets, (Concrete strength, Power plant, and California House) while the CatBoost model achieved the best results on two datasets (Protein Structure and FICO) using RMSE evaluation metric. In terms of MEA metric, LightGBM and CatBoost models achieved the performance on two datasets, respectively. Although the neural network-based NAM and TabNet models showed comparable results on most datasets, these models could not achieve superior predictive performances.
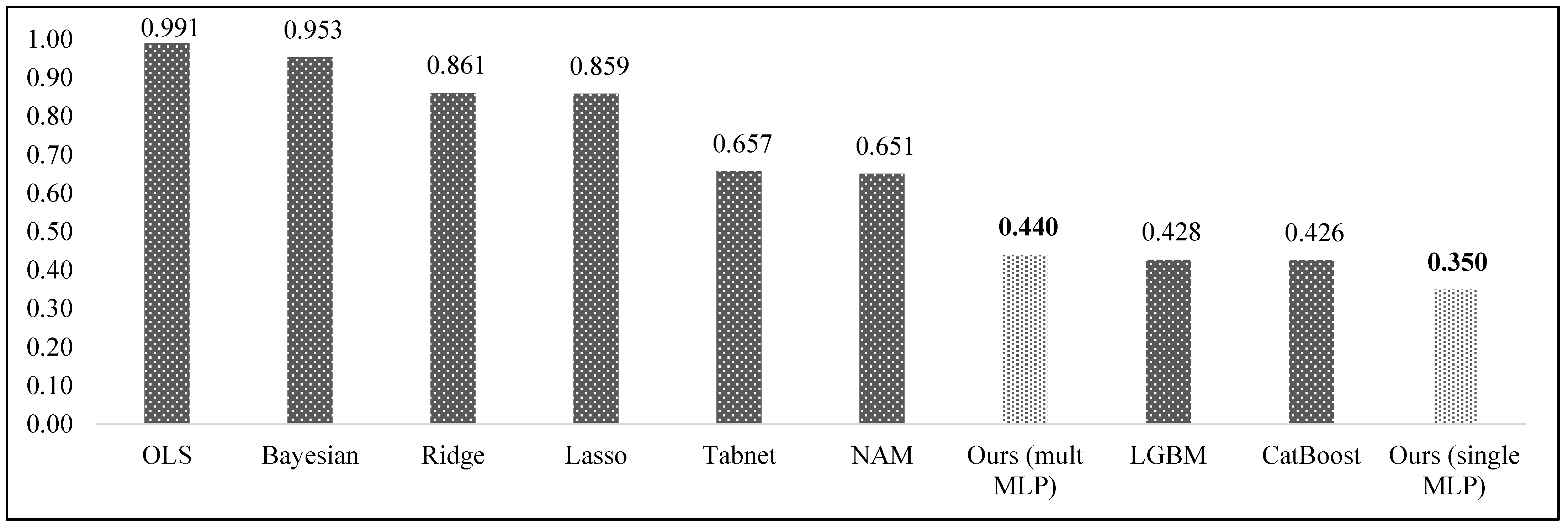
In addition, in order to clearly compare baseline models with our proposed model, we measured normalized average RMSE and MAE on all datasets as shown in
Figure 2 and
Figure 3. Our model is ranked the first and fourth places for the normalized average RMSE evaluation metric (see
Figure 2). LightGBM and Catboost models showed the second and third best predictive performances by achieving 0.428 and 0.426 normalized average RMSE, respectively.
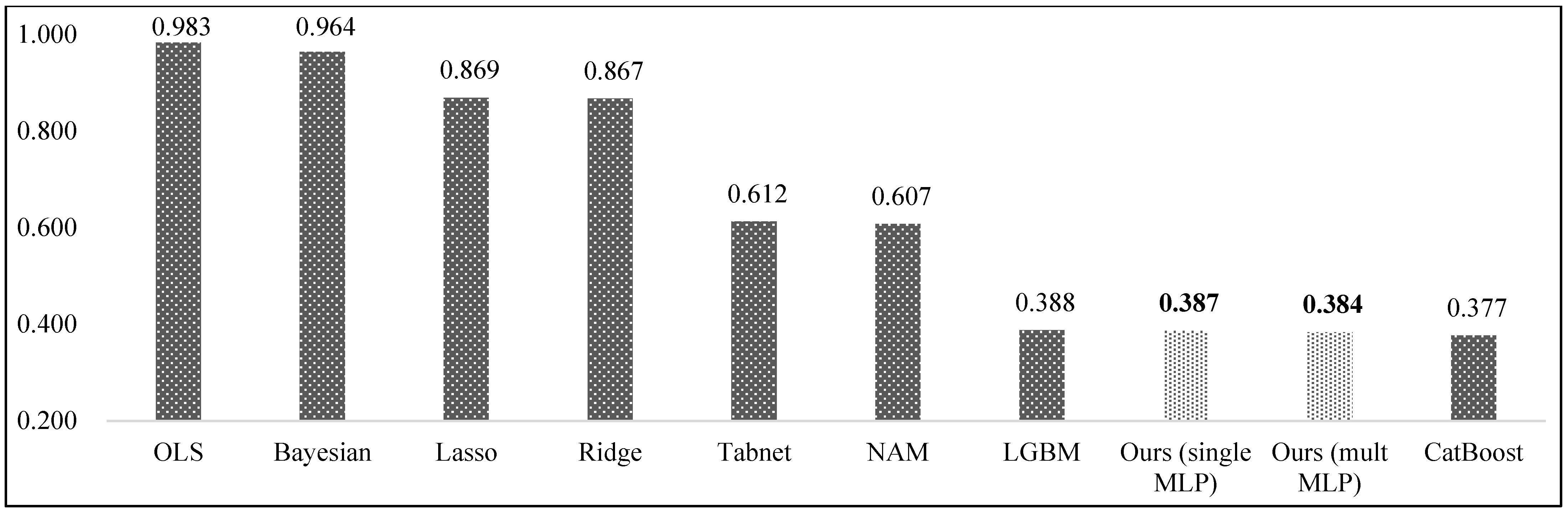
Figure 3 displayed the normalized average MAE for all models and we can see that our proposed model consisting of multiple and single MLP models showed the second and third best predictive performance by achieving 0.384 and 0.387 normalized average MAE scores. From experimental results, we can now observe that augmenting linear regression by neural networks showed the state-of-the-art predictive performance without depreciating its interpretability.
4.5. Model Interpretability
We evaluated our proposed model on synthetic and the real-world economic datasets to demonstrate its interpretability. We first aimed to evaluate how our proposed model accurately predicts the known regression coefficients on synthetic datasets. We also trained our model on the real-world economic data to explore the dynamic effect of the central bank policy rate (MN Policy rate) on inflation. We also performed the analysis on CO2 emission data, and our model discovered some interesting explanations between input and target variables, such as a parabolic relationship between CO2 emissions and gross national product (GNP).
4.5.1. Model Interpretability on Synthetic Data
In order to evaluate model interpretability, we generated the synthetic datasets based on linear and nonlinear functions. We then trained our proposed model on those datasets to predict the known regression coefficients. The coefficients used to create the synthetic datasets were derived from a normal distribution rather than using constant coefficients. Based on these known coefficients, we generated the datasets using linear and nonlinear functions; 1. Linear, 2. Quadric, and 3. Summation of multiplication function, which is a summation of multiplication between input variables. The used functions are as the following:
where
represents number of variable,
and
are parameters used to calculate target variable
,
is input
i-th variable,
j and
k are index for variables (these index should be less than
p), and
is independent, identically distributed random error. For Equation (13), meta-learner in our model should predict
as model coefficients. For Equations (14) and (15), the meta-learner in our model will predict
and
, which are adaptive regression coefficients.
Based on the above three functions, we generated 10,000 samples of synthetic dataset consisting of six variables.
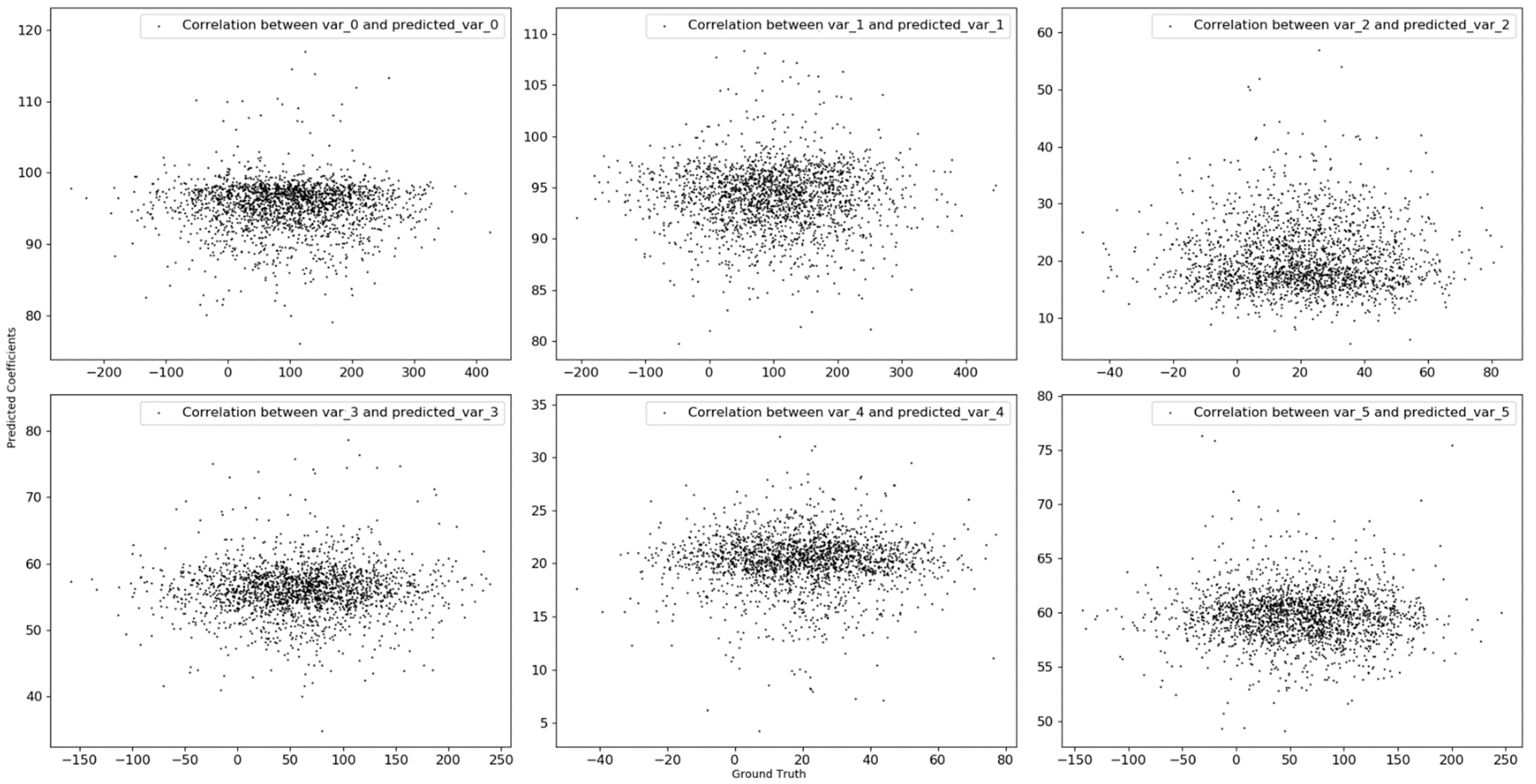
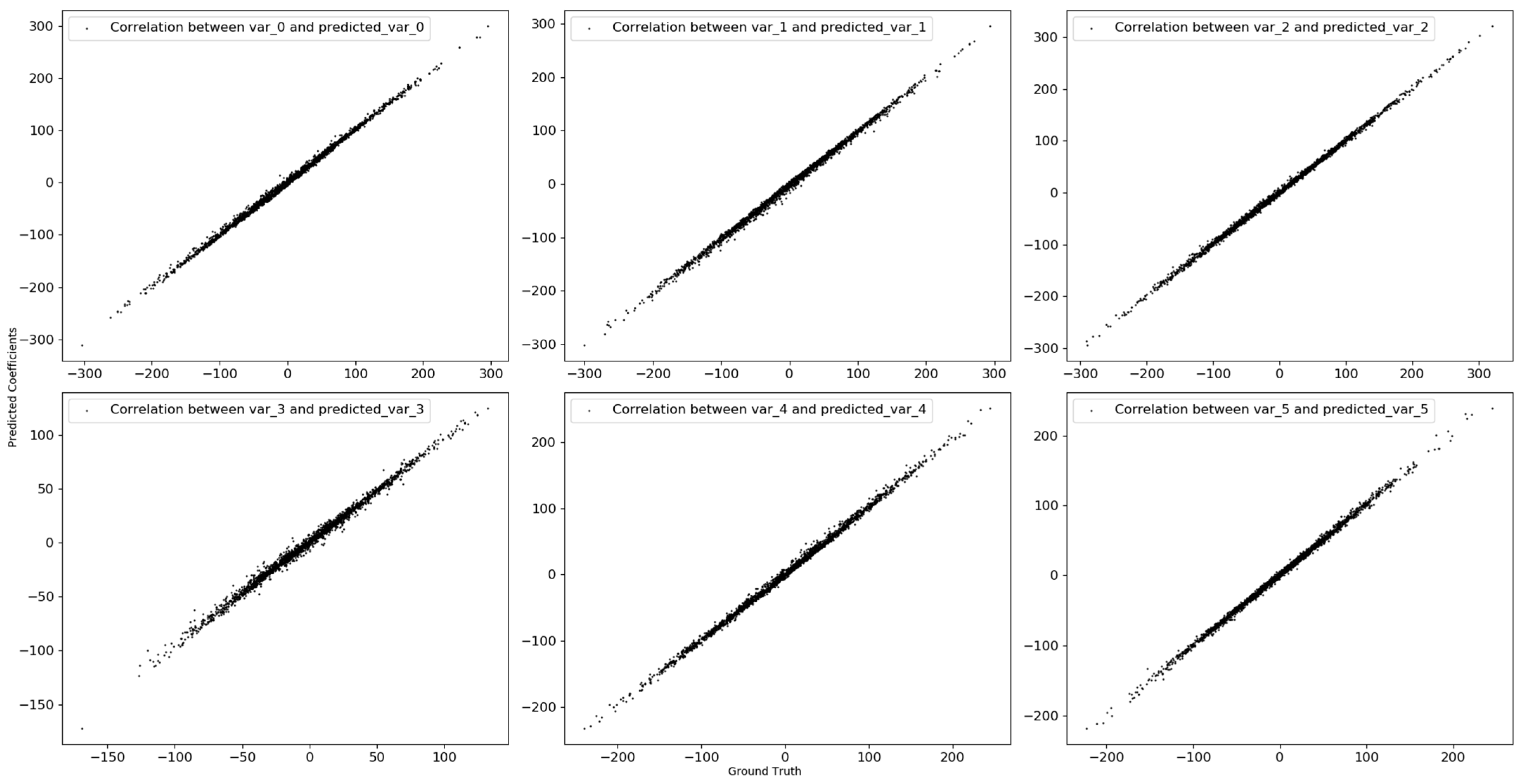
We then displayed the relationship between known and predicted coefficients for the synthetic data generated by using linear function based on scatter plot in
Figure 4. We can see that our proposed model cannot predict the actual coefficients because the known coefficients were randomly derived from normal distribution, and linear regression perfectly predicts target variable.
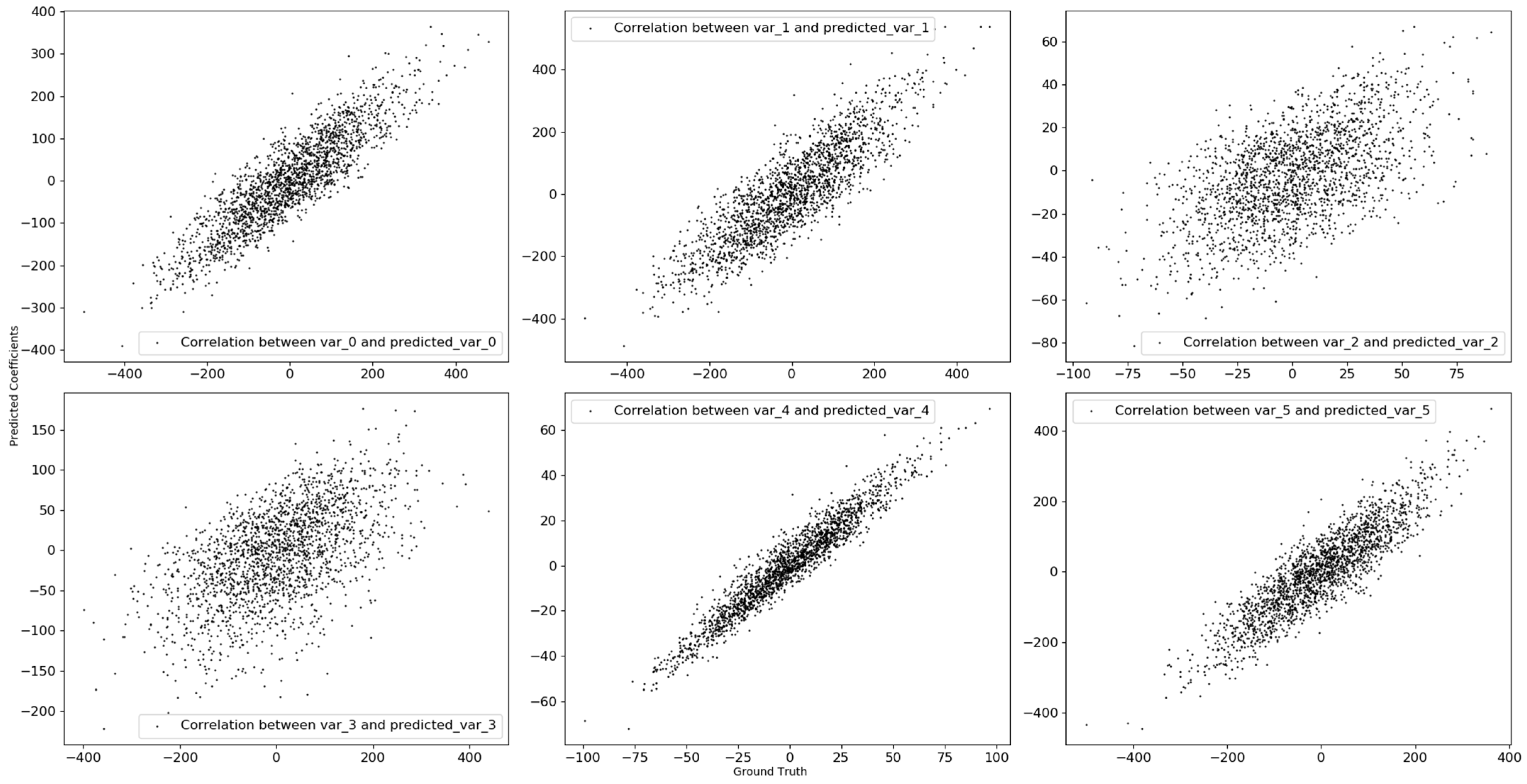
Figure 5 and
Figure 6 showed the relationship between known and predicted coefficients for the synthetic data generated by quadric and summation of multiplication functions. We can see that our model can accurately predict the actual coefficients for the synthetic data generated by using nonlinear functions.
Table 4 also presented correlation between known and predicted coefficients for each synthetic data. We now can see that there is no correlation between actual and predicted coefficients for the synthetic dataset generated by linear function. In contrast, for the synthetic datasets generated by quadric and summation of multiplication functions, the actual and predicted coefficients are highly correlated with each other.
Finally, as a result of the experimental analysis on the synthetic datasets, meta-learner in our proposed model can explain correlation between input and output variables by approximating the local linear function for each observation.
4.5.2. Model Interpretability on Economic Data
We then trained our proposed model on Mongolian economic data to explore the relationship between the central bank policy rate (MN Policy rate) and inflation over time. We retrieved quarterly data from various open sources such as The Central Bank of Mongolia, National Statistics Office of Mongolia, and National Bureau of Statistics of China as shown in
Table 5. The data period is from the 4th quarter of 2000 to the 2nd quarter of 2022. For explanatory variables, China’s Real Gross Domestic Product (China RGDP, constant price-2015), China’s consumer price index (China CPI, price index 2015 = 100), the coal price (Coal price), the oil price (Oil price), the Mongolian Real Gross Domestic Product (MN RGDP, constant price-2015), the budget expenditure of Mongolian (MN Budget Exp), the average wage (MN Average wage), the money supply (MN Money Supply M2), the outstanding loan (MN Loan Outstanding), the central bank policy rate (MN Policy rate) and the terms of trade (MN Terms of trade) are used to forecast Mongolian consumer price index (MN CPI).
Before proceeding to OLS estimation, the traditional Augmented Dickey-Fuller (ADF) [
48,
49] and KPSS [
50] unit root tests should be tested to check the hypothesis of stationarity and nonlinearity for all variables [
51].
Table 6 shows the result of unit root tests for variables. The optimal lags are selected based on AIC information criterion and maximum lag is equal to 4. The traditional unit root test results showed that the null hypothesis cannot be rejected for most variables; therefore, the variables must be transformed into stationarity. Only the MN Policy rate variable can reject the null hypothesis, so no transformation is needed. Moreover, since this variable is expressed as a percent, we need to transform the other variables to the same level.
After transforming the variables, as shown in
Table 7, ADF and KPSS test results showed that the null hypothesis cannot be rejected for d4log(China RGDP) and d1log(MN Money Supply M2) variables. On the other hand, the variable d4log(China CPI) was highly correlated with the variable d4log(MN RGDP) and the variable d1log(MN Money Supply M2) was also highly correlated with the variable d1log(MN Loan Outstanding), so we excluded these variables from the regression model.
For the variables for which traditional unit root tests were accepted, we considered that these variables could affect inflation and are included in the OLS estimation.
A total of 78 quarters from the 1st quarter of 2001 to the 2nd quarter of 2020 are used as the training set, and 8 quarters from the 3rd quarter of 2020 to the 2nd quarter of 2022 are considered as a test set.
From the result of the OLS regression (
Table 8 and
Table 9), we can see a negative relationship between the central bank policy rate (MN Policy rate) and inflation d1log(MN CPI). Expressly, in the Mongolian economy, inflation tends to fall by 0.0025 percent if the central bank raises the policy rate by one percent.
Table 10 also showed the predictive performance results, and we can see that our proposed model reduces the error of the OLS model by an average of 0.0107 units of inflation, or 30.7 percent.
Another advantage of our proposed model is to capture how the regression coefficients change over time. In macroeconomics, the impact of explanatory variables on inflation can be changed over time depending on the economic situation [
52]. Therefore, our model can be suitable for developing economic models rather than linear regression.
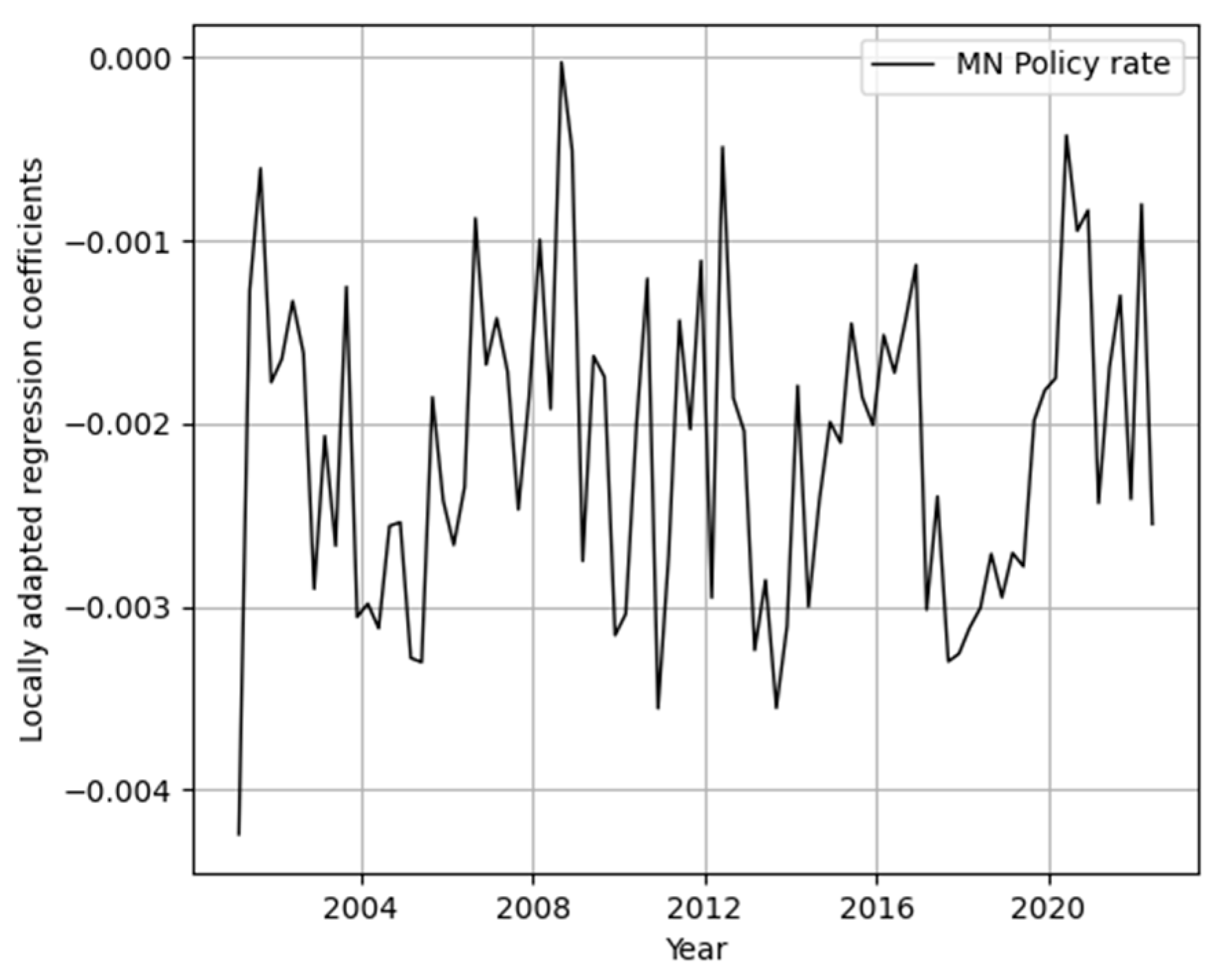
Figure 7 showed how the central bank’s policy rate affects inflation over time. As we know, there was a global economic crisis in the period between 2008 and 2010. During this period, we can see that the effect of the central bank policy rate on inflation is high. In other words, if the central bank raises the policy rate by one percent, inflation tends to fall by more than 0.03 percent. On the contrary, between 2010 and 2012, Mongolia’s largest copper mine called Oyu Tolgoi started and the Mongolian economy was extremely grown. At the same time, the effect of the central bank’s policy rate on inflation weakened.
The estimated regression coefficient from the linear regression is consistent with the economic theory for MN Policy rate. We can now see that our proposed model showed how the effect of MN Policy rate changes dynamically on inflation while keeping this consistency.
4.5.3. Model Interpretability on CO2 Emission Data
In this section, we considered real-world CO
2 emission dataset and examined the link between CO
2 emission and gross national product (GNP) [
49,
50]. We explored the relationship between the CO
2 and GNP based our proposed model.
The source of the dataset is the official web page of Our World in Data (
https://ourworldindata.org/, accessed on 1 November 2022) and the data between 1990 and 2015 are the training and data in 2016 are the test set (see
Table 11). In addition, we also performed ADF and KPSS tests on CO
2 emission dataset as shown in
Table 12, and ADF and KPSS test results showed that the null hypothesis can be accepted for logarithm scale of both variables. Furthermore, to investigate the link between CO
2 emission and GNP, we estimated two different regression equations as follows:
In general, assuming that there are positive linear and negative parabolic relationships between CO
2 emission and GNP. Theoretically, the Environmental Kuznets Curve (EKC) hypothesis postulates an inverted-U-shaped relationship between CO
2 emission and GNP [
53,
54].
Our estimates of Equations (16) and (17) are reported in
Table 13 and regression diagnostics result is presented in
Table 14. The regression coefficients are consistent with EKC hypothesis. We then trained our model on these two OLS results and reported the prediction performance in
Table 15. Our model showed slightly better performance than both OLS results. Finally, we captured the relationship between CO
2 emission and GNP.
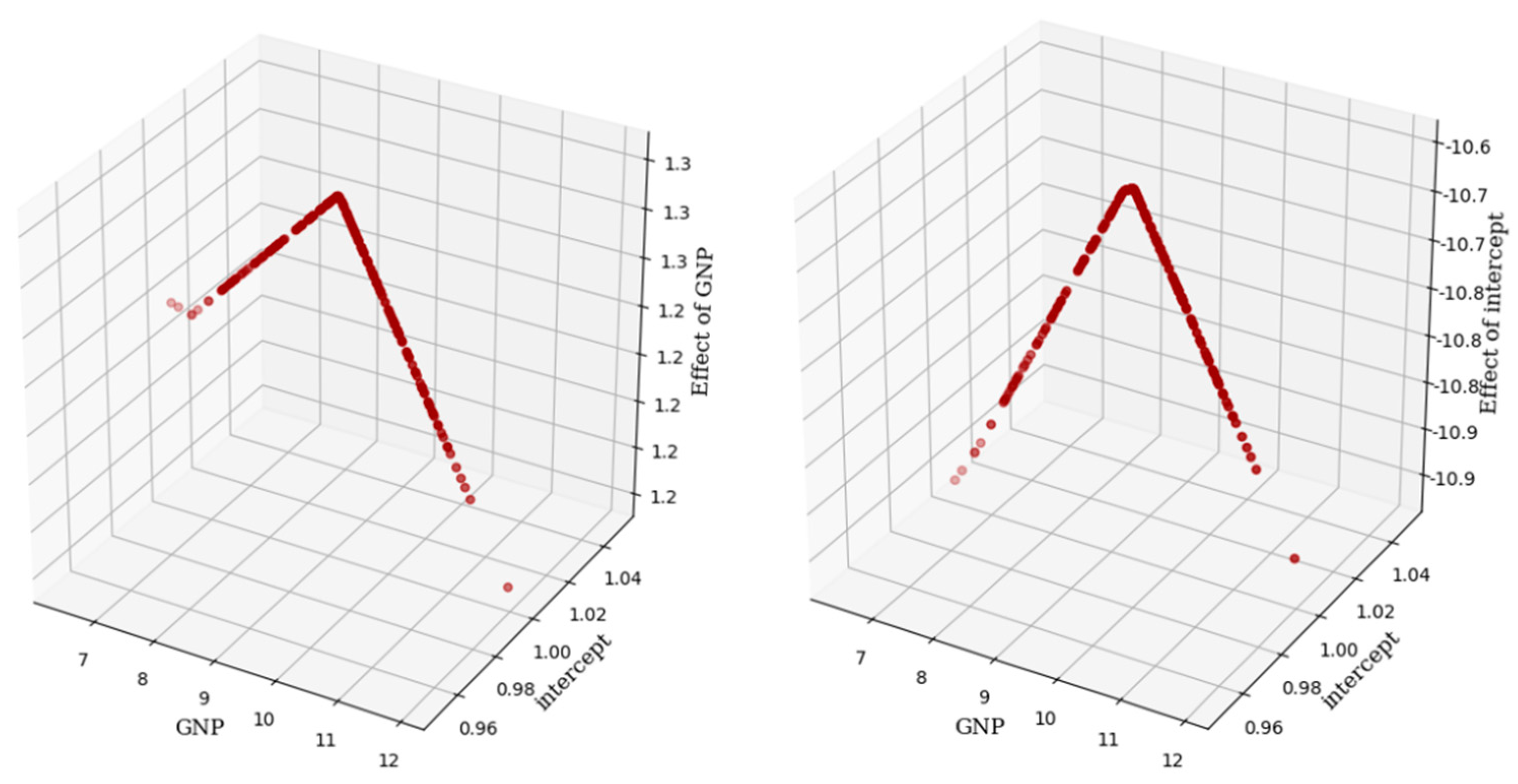
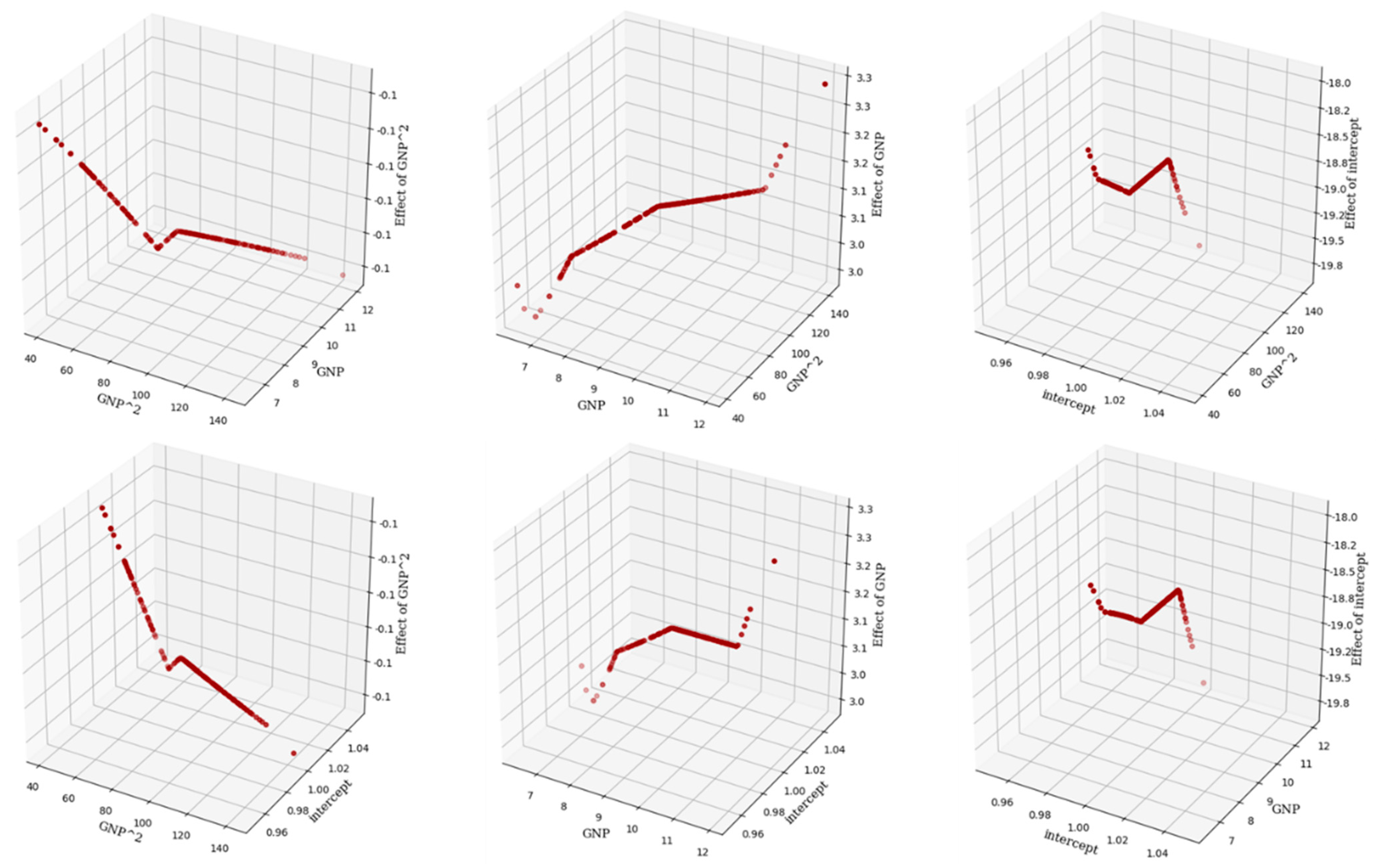
Figure 8 showed the influence of GNP (left) and intercept (right) on CO
2 emission for Equation (16). We can easily see that GNP and intercept are parabolic with CO
2 emission. When GNP goes up to 9.16, it intensively increases CO
2 emission, then when GNP is higher than 9.16 its effect on CO
2 emission starts to decrease. For intercept, average CO
2 emission increases up to a certain level as GNP goes up; after that, it decreases. In Equation (17), we added the quadratic term of GNP as an explanatory variable, and the predictive performance of OLS is improved. Although the predictive performance of our model has not changed much, its interpretability is shifted as shown in
Figure 9. We can now see that the parabolic relationship between CO
2 and GNP on Equation (17) has transformed to linear. Our model can also measure how much CO
2 will change due to the change in GNP for each country.
5. Conclusions
In this work, we aimed to create a white-box model for regression tasks on tabular data. In order to provide both high predictive accuracy and explainability, we proposed a novel locally adaptive interpretable regression model augmented by neural networks. The proposed model relies on two key aspects. First, a base-learner should be a simple interpretable model. In this work, we obtain our base-learner using OLS regression and its statistical properties. Second, we use neural networks as our meta-learner to re-parameterize our base-learner to produce a local interpretable linear model for each observation. We can locally explain the relationship between input and output variables based on the adapted local regression coefficients. We evaluate the predictive performance and interpretability of our proposed model on several tabular datasets. Experimental results showed that our model greatly improved the predictive performance of OLS regression after being augmented by neural networks. Our model is ranked first by the normalized average RMSE and second by the normalized average MAE from experimental results.
In addition, in order to evaluate model explainability, we perform additional experiments on the synthetic, economic, and CO2 emission datasets. For the synthetic data generated by non-linear functions, our proposed model can explain the relationship between input and output features by approximating a local linear function for each observation. We then perform an analysis of economic time-series data, and our model explores the dynamic relationship between input and output variables. As a result, we have observed that the impact of central bank policy rates on inflation tends to weaken during a recession and rises during an expansion, consistent with the economic theory. Lastly, we applied our model to CO2 emission data, and our model discovers some interesting explanations between input and target variables, such as a parabolic relationship between CO2 emissions and gross national product (GNP).
We believe that our proposed model can be applicable for many real-world domains where data type is tabular and interpretable models are required.




 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}