
Modeling Biomass for Natural Subtropical Secondary Forest Using Multi-Source Data and Different Regression Models in Huangfu Mountain, China
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
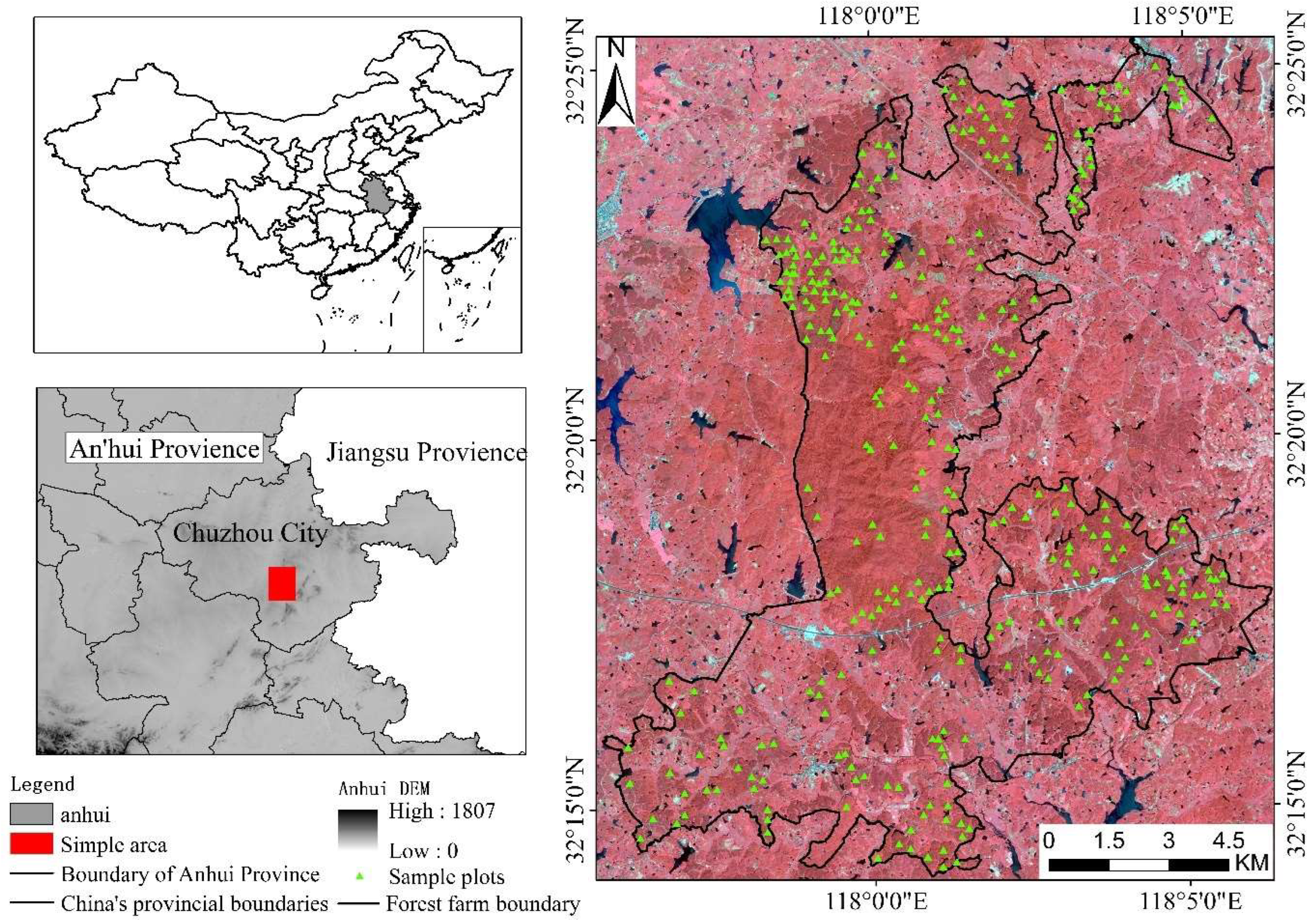
2.1. Study Area
2.2. Data
2.2.1. Ground Survey Data
2.2.2. Remote Sensing Image
2.3. Feature Extraction
2.3.1. Extraction of Spectral Information
2.3.2. Extraction of Principal Component Characteristics
2.3.3. Extraction of Textural Features
2.4. Multiple Stepwise Regression Model
2.5. Machine Learning Algorithm
3. Results
3.1. Data Statistics and Processing
3.2. Determination of Feature Factors
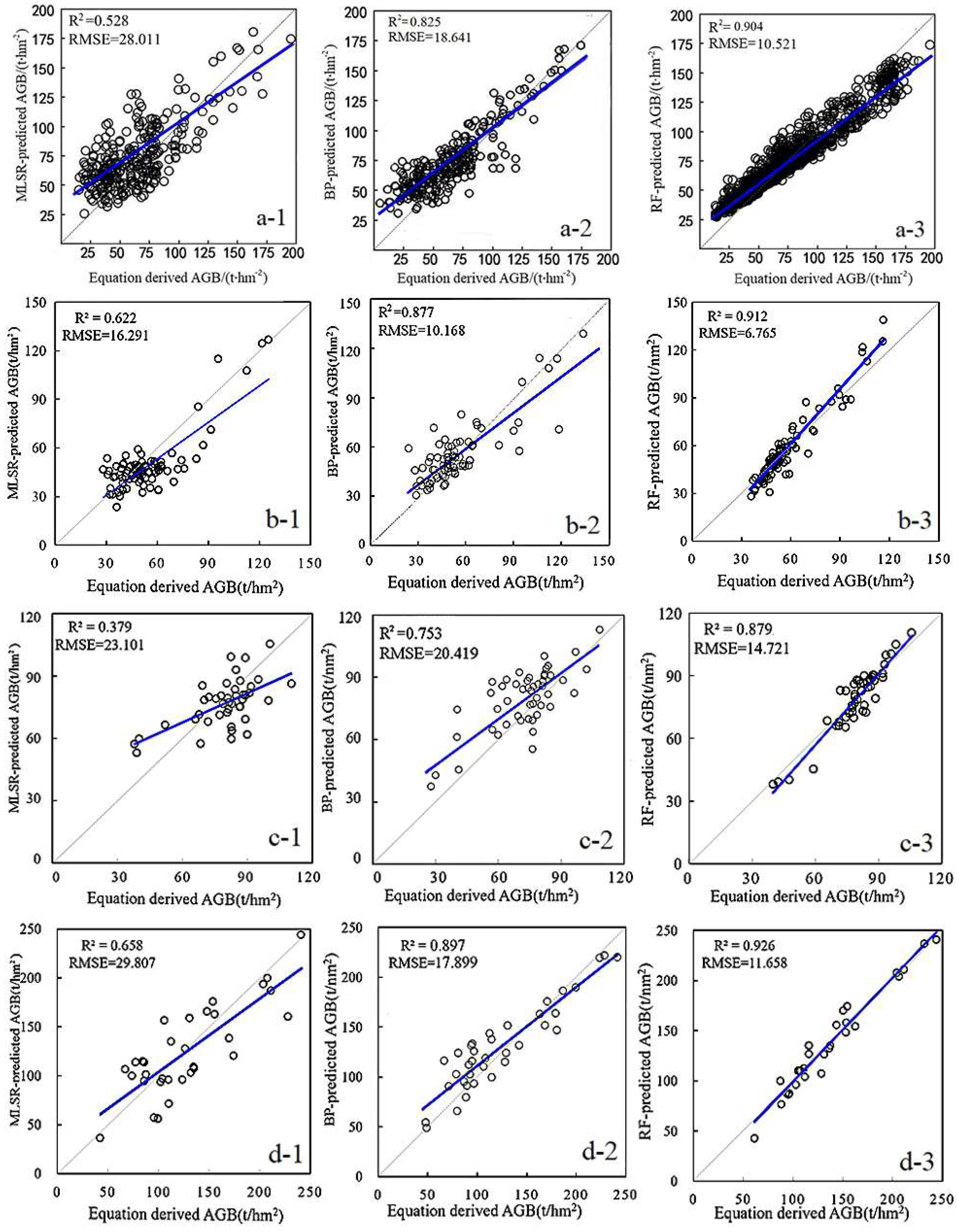
3.3. Analysis of Modeling Results of Different Images
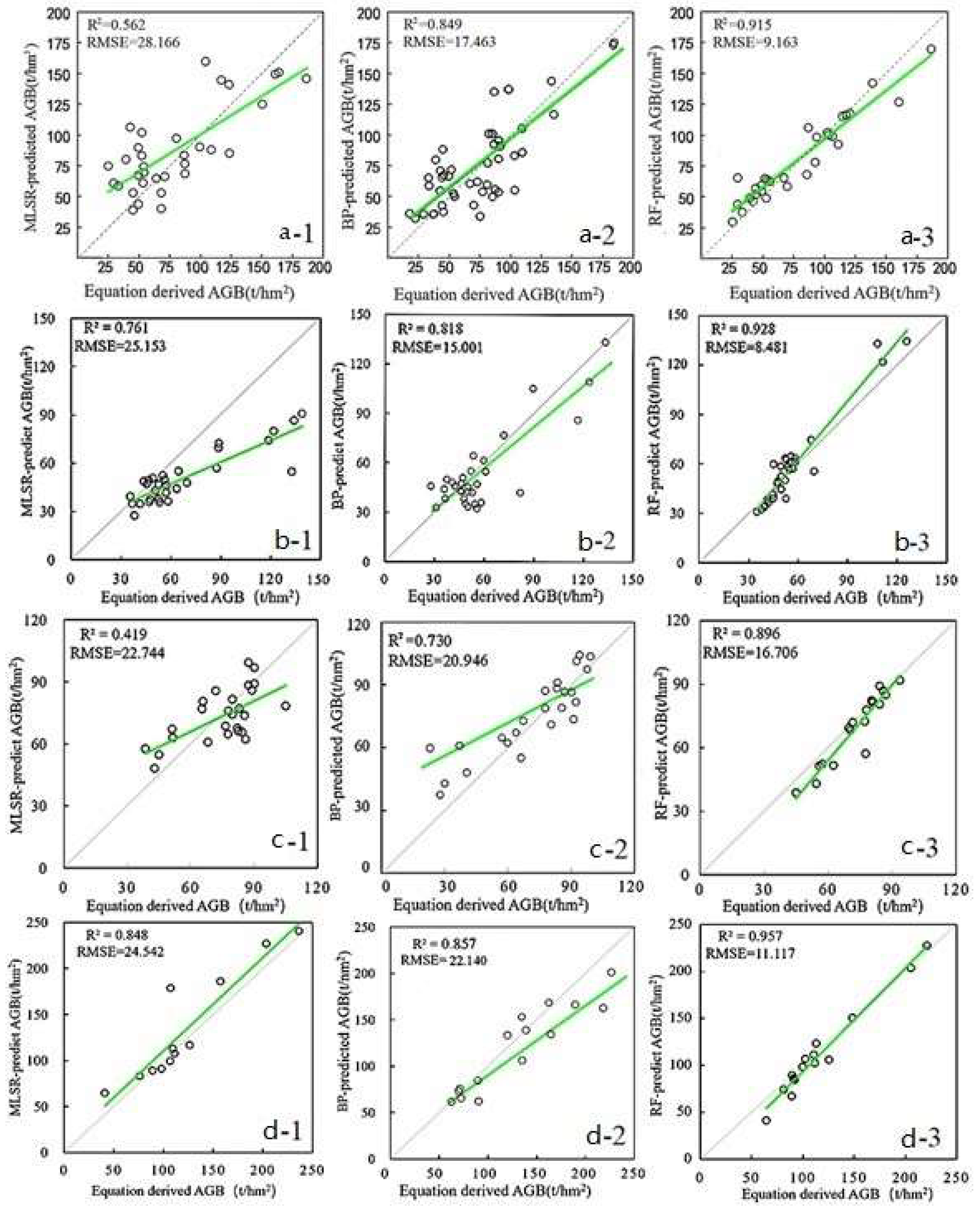
3.4. Modeling Analysis on Different Models for Mixed Forest
3.4.1. BP Neural Network
3.4.2. Random Forest Algorithm
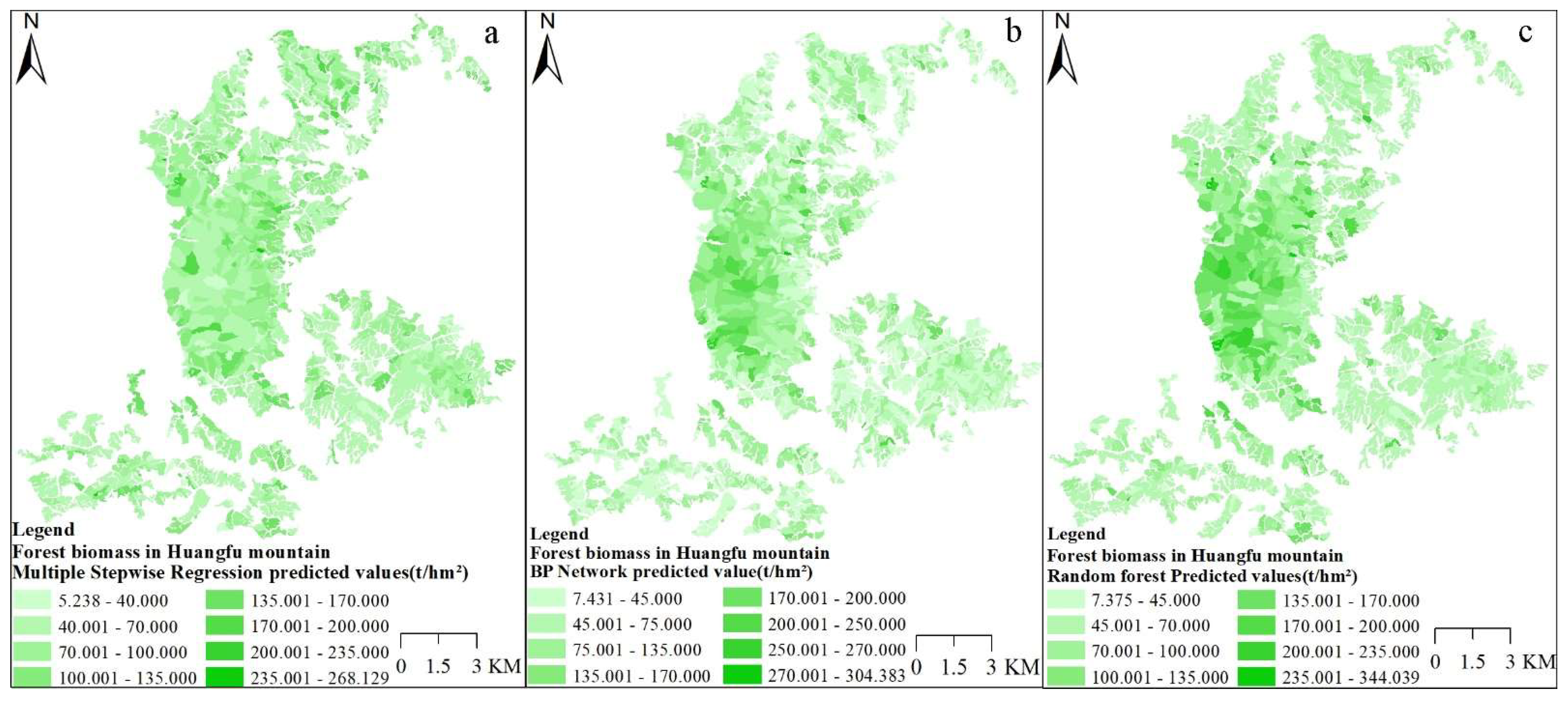
3.5. Distribution Map of Biomass Estimation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Olson, J.S.; Watts, J.A.; Allison, L.J. Carbon in Live Vegetation of Major World Ecosystems; Oak Ridge National Laboratory for the Office of Health and Environmental Research, U.S. Department of Energy: Washington, DC, USA, 1983.
- Woodwell, G.M.; Whittaker, R.H.; Reiners, W.A.; Likens, G.E.; Delwiche, C.C.; Botkin, D.B. The Biota and the World Carbon Budget. Science 1978, 199, 141–146. [Google Scholar] [CrossRef] [PubMed]
- Pan, Y.; Birdsey, R.A.; Fang, J.; Houghton, R.; Kauppi, P.E.; Kurz, W.A.; Phillips, O.L.; Shvidenko, A.; Lewis, S.L.; Canadell, J.G.; et al. A large and persistent carbon sink in the world’s forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef] [Green Version]
- Herold, M.; Carter, S.; Avitabile, V.; Espejo, A.B.; Jonckheere, I.; Lucas, R.; McRoberts, R.E.; Næsset, E.; Nightingale, J.; Petersen, R.; et al. The Role and Need for Space-Based Forest Biomass-Related Measurements in Environmental Management and Policy. Surv. Geophys. 2019, 40, 757–778. [Google Scholar] [CrossRef] [Green Version]
- Houghton, R.A. Aboveground forest biomass and the global carbon balance. Glob. Chang. Biol. 2005, 11, 945–958. [Google Scholar] [CrossRef]
- Yang, J.; Dai, G.; Wang, S. China’s National Monitoring Program on Ecological Functions of Forests: An Analysis of the Protocol and Initial Results. Forests 2015, 6, 809–826. [Google Scholar] [CrossRef]
- Fang, J.; Chen, A.; Peng, C.; Zhao, S.; Ci, L. Changes in Forest Biomass Carbon Storage in China Between 1949 and 1998. Science 2001, 292, 2320–2322. [Google Scholar] [CrossRef] [PubMed]
- Jia, K.; Li, Y.; Liang, S.; Wei, X.; Yao, Y. Combining Estimation of Green Vegetation Fraction in an Arid Region from Landsat 7 ETM+ Data. Remote Sens. 2017, 9, 1121. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Wang, C.; Hu, Y.; Liu, S. General Review on Remote Sensing-Based Biomass Estimation. Geomat. Inf. Sci. Wuhan Univ. 2012, 37, 631–635. [Google Scholar]
- Olesk, A.; Praks, J.; Antropov, O.; Zalite, K.; Arumäe, T.; Voormansik, K. Interferometric SAR Coherence Models for Characterization of Hemiboreal Forests Using TanDEM-X Data. Remote Sens. 2016, 8, 700. [Google Scholar] [CrossRef] [Green Version]
- Pang, Y.; Meng, S.; Li, Z. Temperate Forest Aboveground Biomass Estimation Using Fourier-Based Textural Ordination (FOTO) Indices from High Resolution Aerial Optical Image. Sci. Silvae Sin. 2017, 53, 94–104. [Google Scholar]
- Berninger, A.; Lohberger, S.; Stängel, M.; Siegert, F. SAR-Based Estimation of Above-Ground Biomass and Its Changes in Tropical Forests of Kalimantan Using L- and C-Band. Remote Sens. 2018, 10, 831. [Google Scholar] [CrossRef] [Green Version]
- Goodenough, D.G.; Bannon, D. Hyperspectral forest monitoring and imaging implications. Spectr. Imaging Sens. Technol. Innov. Driv. Adv. Appl. Capab. 2014, 9104, 1–9. [Google Scholar]
- Shen, X.; Cao, L.; She, G. Subtropical forest biomass estimation based on hyperspectral and high-resolution remotely sensed date. J. Remote Sens. 2016, 20, 1446–1460. [Google Scholar]
- Halme, E.; Pellikka, P.; Mõttus, M. Utility of hyperspectral compared to multispectral remote sensing data in estimating forest biomass and structure variables in Finnish boreal forest. Int. J. Appl. Earth Obs. Geoinf. 2019, 83, 101942. [Google Scholar] [CrossRef]
- Huang, K.; Pang, Y.; Shu, Q.; Fu, T. Aboveground forest biomass estimation using ICESat GLAS in Yunnan, China. J. Remote Sens. 2013, 17, 165–179. [Google Scholar]
- Zhang, J.L.; Xu, H. Establishment of remote sensing based model to estimate the aboveground biomass of Pinus densata for permanent sample plots from national forestry inventory. J. Beijing For. Univ. 2020, 42, 1–11. [Google Scholar]
- Wang, Y.; Sun, Y.; Guo, X. Single-tree biomass modeling of Pinus massoniana based on BP neural network. J. Beijing For. Univ. 2013, 35, 17–21. [Google Scholar]
- Cao, L.; Pan, J.; Li, R.; Li, J.; Li, Z. Integrating Airborne LiDAR and Optical Data to Estimate Forest Aboveground Biomass in Arid and Semi-Arid Regions of China. Remote Sens. 2018, 10, 532. [Google Scholar] [CrossRef] [Green Version]
- Shen, W.; Xu, T.; Li, M. Spatio-temporal changes in forest fragmentation, disturbance patterns over the three giant forested regions of China. J. Nanjing For. Univ. (Nat. Sci. Ed.) 2013, 37, 75–79. [Google Scholar]
- Fang, J.Y.; Liu, G.H.; Xu, S.L. Biomass and net production of forest vegetation in China. Acta Ecol. Sin. 1996, 16, 497–508. [Google Scholar]
- Dash, J.; Curran, P.J. Evaluation of the MERIS terrestrial chlorophyll index (MTCI). Adv. Space Res. 2007, 39, 100–104. [Google Scholar] [CrossRef]
- Hu, Y.; Xu, X.; Wu, F.; Sun, Z.; Xia, H.; Meng, Q.; Huang, W.; Zhou, H.; Gao, J.; Li, W.; et al. Estimating Forest Stock Volume in Hunan Province, China, by Integrating In Situ Plot Data, Sentinel-2 Images, and Linear and Machine Learning Regression Models. Remote Sens. 2020, 12, 186. [Google Scholar] [CrossRef] [Green Version]
- Tsui, O.W.; Coops, N.C.; Wulder, M.A.; Marshall, P.L.; McCardle, A. Using multif requency radar and discrete-return LiDAR measurements to estimate above-ground biomass and biomass components in a coastal temperate forest. ISPRS J. Photogramm. Remote Sens. 2012, 69, 121–133. [Google Scholar] [CrossRef]
- Latifi, H.; Nothdurft, A.; Koch, B. Non-parametric prediction and mapping of standing timber volume and biomass in a temperate forest: Application of multiple optical/LiDAR-derived predictors. Forestry 2010, 83, 395–407. [Google Scholar] [CrossRef]
- Jiang, F.; Sun, H.; Li, C.; Ma, K.; Chen, S.; Long, j.; Ren, L. Retrieving the forest aboveground biomass by combing the red edge bands of Sentinel-2 and GF-6. Acta Ecol. Sin. 2021, 41, 8222–8236. [Google Scholar]
- Xiong, H.; Yu, F.; Gu, X.; Wu, X. Biomass, net production, carbon storage and spatial distrubution features of different forest vegetation in Fanjing Mountains. Ecol. Environ. Sci. 2021, 30, 264–273. [Google Scholar]
- Ding, J.; Huang, W.; Liu, Y.; Hu, Y. Estimation of Forest Aboveground Biomass in Northwest Hunan Province Based on Machine Learning and Multi-Source Data. Sci. Silvae Sin. 2021, 57, 36–48. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Samples | Number of Samples | DBH/cm | Height of Tree/m | Trees/hm2 | Crown Density | Forest Stock Volume /m3·hm−2 | |||
|---|---|---|---|---|---|---|---|---|---|
| Range | Average | Range | Average | Range | Average | Range | Range | ||
| Single species | 283 | 5.21–18.36 | 12.02 | 1.41–15.12 | 7.36 | 752–2951 | 1674 | 0.6–0.9 | 12.65–238.92 |
| Pinus massoniana | 123 | 6.21–18.28 | 13.28 | 5.86–13.12 | 7.42 | 752–2745 | 1821 | 0.8–0.9 | 30.64–234.15 |
| Pinus elliottii | 69 | 6.61–18.32 | 14.41 | 3.05–8.56 | 7.44 | 825–2350 | 1706 | 0.8–0.9 | 25.53–226.57 |
| Quercus acutissima | 52 | 6.12–15.22 | 9.01 | 2.62–9.56 | 5.52 | 725–2851 | 1224 | 0.9 | 21.86–234.94 |
| Broadleaf forest | 22 | 5.15–15.20 | 8.41 | 4.56–9.75 | 4.14 | 752–2125 | 1114 | 0.8–0.9 | 14.49–220.36 |
| Coniferous forest | 17 | 6.15–18.36 | 14.68 | 4.52–8.56 | 7.81 | 752–2359 | 1350 | 0.8–0.9 | 12.65–185.88 |
| Needle and broad-leaved mixed forest | 32 | 6.15–16.16 | 10.28 | 3.21–8.56 | 4.92 | 1440–2550 | 1241 | 0.7–0.9 | 27.23–170.71 |
| Forest Types | a | b |
|---|---|---|
| Pinus massoniana | 0.51 | 1.0451 |
| Pinus elliottii | 0.5894 | 24.5151 |
| Quercus acutissima | 1.3288 | −3.8999 |
| Broadleaf forest | 0.8392 | 5.4157 |
| Coniferous forest | 0.5168 | 33.2378 |
| Needle and broad-leaved mixed forest | 0.7143 | 16.9654 |
| Sensor type | GF-1 PMS | GF-6 WFV | |
|---|---|---|---|
| Sensor Altitude/km | 645 | ||
| Spectral range/μm | Multispectral | B1:0.45–0.52 | |
| B2:0.52–0.59 | |||
| B3:0.63–0.69 | |||
| B4:0.77–0.89 | |||
| B5:0.69–0.73 | |||
| B6:0.73–0.77 | |||
| B7:0.40–0.45 | |||
| B8:0.59–0.63 | |||
| Panchromatic | 0.45–0.90 | ||
| Pixel Size/m | 2 | 16 | |
| Width/km | 60 | 864.2 | |
| Revisit Cycle | 4 | 2 (Networking with GF-1) | |
| Mixed Forest | Correlation | Pinus massoniana | Correlation | Pinus elliottii | Correlation | Quercus acutissima | Correlation | |
|---|---|---|---|---|---|---|---|---|
| GF-1 | PCA1GF-1 | 0.236 ** | PCA1GF-1 | 0.318 ** | ndvi | 0.503 ** | band2 | −0.675 ** |
| band2 | −0.415 ** | band2 | −0.314 ** | band 4 | 0.522 ** | b3_mean_3 | −0.525 ** | |
| ipvi | 0.293 ** | rvi | 0.280 ** | |||||
| evi | −0.251 ** | evi | −0.277 ** | |||||
| dvi | 0.222 ** | b1_mean_3 | −0.310 ** | |||||
| Land type | SLOPE | 0.468 ** | SLOPE | 0.500 ** | SLOPE | 0.476 ** | ||
| DEM | 0.519 ** | |||||||
| GF-6 | MTCI | 0.548 ** | PCA1GF-6 | −0.385 ** | NDVI | 0.372 ** | MTCI | 0.549 ** |
| B5_mean_13 | −0.262 ** | BAND6 | −0.366 ** | PCA1GF-6 | 0.360 ** | BAND6 | −0.446 ** | |
| NDRE1 | −0.207 ** | BAND4 | 0.380 ** | GNDVI | 0.396 ** | |||
| PCA1GF-6 | −0.513 ** |
| Mixed Forest | R2 | RSME/(t·hm2) | F | Sig | |
|---|---|---|---|---|---|
| GF-1 | Bio = 0.103 × DEM + 0.349 × pca1 − 1.118 × band2 − 2569.065 × ipvi + 3259.183 | 0.444 | 30.42 | 68.023 | 0.000 |
| GF-6 | Bio = 449.076 × MTCI + 0.238 × DEM − 12.195 × B5_mea_13 +2.139 × SLOPE + 428.004 | 0.436 | 29.50 | 58.091 | 0.000 |
| GF-1&GF-6 | Bio = 926.384 × MTCI + 0.331 × DEM + 450.665 × NDRE1 + 707.176 × evi + 2.431 × SLOPE + 0.23 × dvi + 573.945 | 0.529 | 28.01 | 53.871 | 0.000 |
| Pinus massoniana | |||||
| GF-1 | Bio = 3.014 × SLOPE + 0.303 × pca1 − 0.777 × band2 − 99.567 × rvi + 1248.711 | 0.550 | 15.24 | 36.985 | 0.000 |
| GF-6 | Bio = −5.256 × SLOPE − 0.045 × PCA1 − 0.043 × BAND6 + 31.638 | 0.388 | 27.74 | 25.787 | 0.000 |
| GF-1&GF-6 | Bio = 3.656 × SLOPE − 0.024 × BAND6 − 0.043 × PCA1GF-6 + 0.313 × PCA1GF-1 + 562.712 × evi − 18.887 × b1_mea_3 + 403.054 | 0.622 | 16.29 | 32.571 | 0.000 |
| Pinus elliottii | |||||
| GF-1 | Bio = 0.076 × band4 + 225.897 × ndvi − 173.935 | 0.365 | 12.53 | 18.973 | 0.000 |
| GF-6 | Bio = 138.501 × NDVI + 0.03 × BAND4 + 0.026 × PCA1 − 26.226 | 0.300 | 13.23 | 9.415 | 0.000 |
| GF-1&GF-6 | Bio = 0.067 × BAND4 + 143.447 × ndvi + 0.027 × band 4 − 149.516 | 0.379 | 13.10 | 13.428 | 0.000 |
| Quercus acutissima | |||||
| GF-1 | Bio = 6.48 × SLOPE − 1.494 × band2 + 89.935 × b3_mea_3 + 1282.171 | 0.540 | 42.17 | 18.813 | 0.000 |
| GF-6 | Bio = 921.562 × MTCI − 22.662 × PCA1 + 1183.028 × GNDVI + 229.813 | 0.613 | 33.34 | 26.326 | 0.000 |
| GF-1&GF-6 | Bio = 728.141 × MTCI − 0.4 × band2 − 0.125 × BAND6 + 879.741 × GNDVI + 649.046 | 0.658 | 29.81 | 21.052 | 0.000 |
| Mean | Standard Deviation | Min | Max | |
|---|---|---|---|---|
| Field survey data | 42.573 | 39.546 | 12.653 | 238.925 |
| Forestry resource data | 49.375 | 42.513 | 0 | 313.482 |
| Multiple stepwise regression | 49.375 | 36.924 | 5.238 | 268.129 |
| BP neural network | 56.456 | 34.946 | 7.431 | 304.384 |
| Random forest model | 66.115 | 32.530 | 7.375 | 344.039 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Chen, D.; Zou, C.; Liu, S.; Li, H.; Liu, Z.; Feng, W.; Zhang, N.; Ye, L. Modeling Biomass for Natural Subtropical Secondary Forest Using Multi-Source Data and Different Regression Models in Huangfu Mountain, China. Sustainability 2022, 14, 13006. https://doi.org/10.3390/su142013006
Liu C, Chen D, Zou C, Liu S, Li H, Liu Z, Feng W, Zhang N, Ye L. Modeling Biomass for Natural Subtropical Secondary Forest Using Multi-Source Data and Different Regression Models in Huangfu Mountain, China. Sustainability. 2022; 14(20):13006. https://doi.org/10.3390/su142013006
Chicago/Turabian StyleLiu, Congfang, Donghua Chen, Chen Zou, Saisai Liu, Hu Li, Zhihong Liu, Wutao Feng, Naiming Zhang, and Lizao Ye. 2022. "Modeling Biomass for Natural Subtropical Secondary Forest Using Multi-Source Data and Different Regression Models in Huangfu Mountain, China" Sustainability 14, no. 20: 13006. https://doi.org/10.3390/su142013006