
An Optimized Clustering Approach to Investigate the Main Features in Predicting the Punching Shear Capacity of Steel Fiber-Reinforced Concrete

 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Experimental Setup
2.1. Governing Equations
2.2. Dataset Study
3. Methodology
3.1. K-Means
- (1)
- Placing the points of centers (k) in the computing space so that the primary centers can be determined by them.
- (2)
- Assigning the points that have the most similarity (in terms of proximity or distance) to these defined points.
- (3)
- Recalculating the positions of the centers after the end of the point allocation process.
- (4)
- Stages (2) and (3) will continue until there is no change in the centers. This process seeks to find better groups or clusters.
3.2. Multi-Layer Perceptron (MLP)
3.3. Random Tree (RT)
3.4. Support Vector Regression (SVR)
3.5. Sparrow Search Algorithm (SSA)
4. Simulation
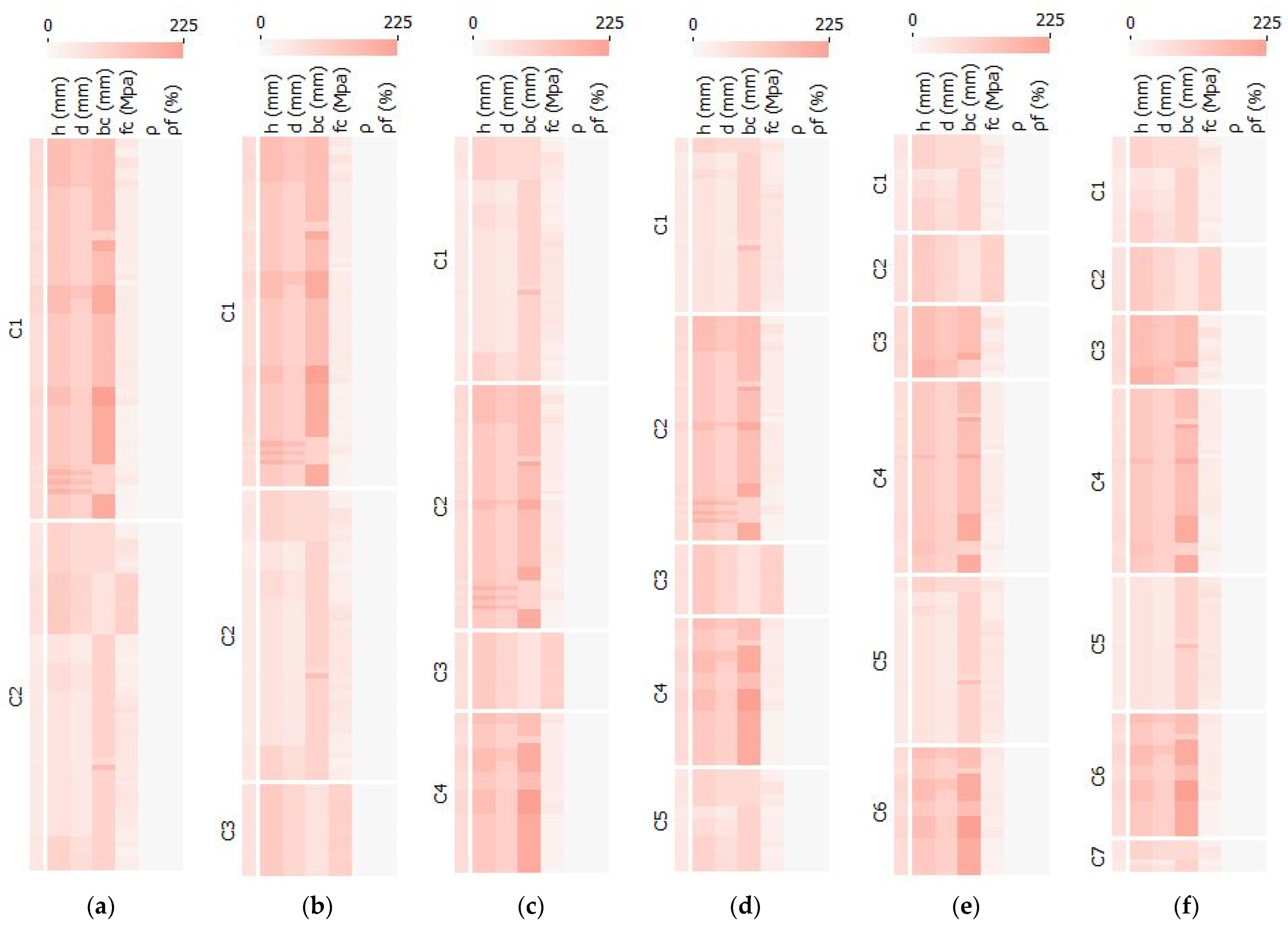
4.1. Clustering Step
4.2. K-Means Models
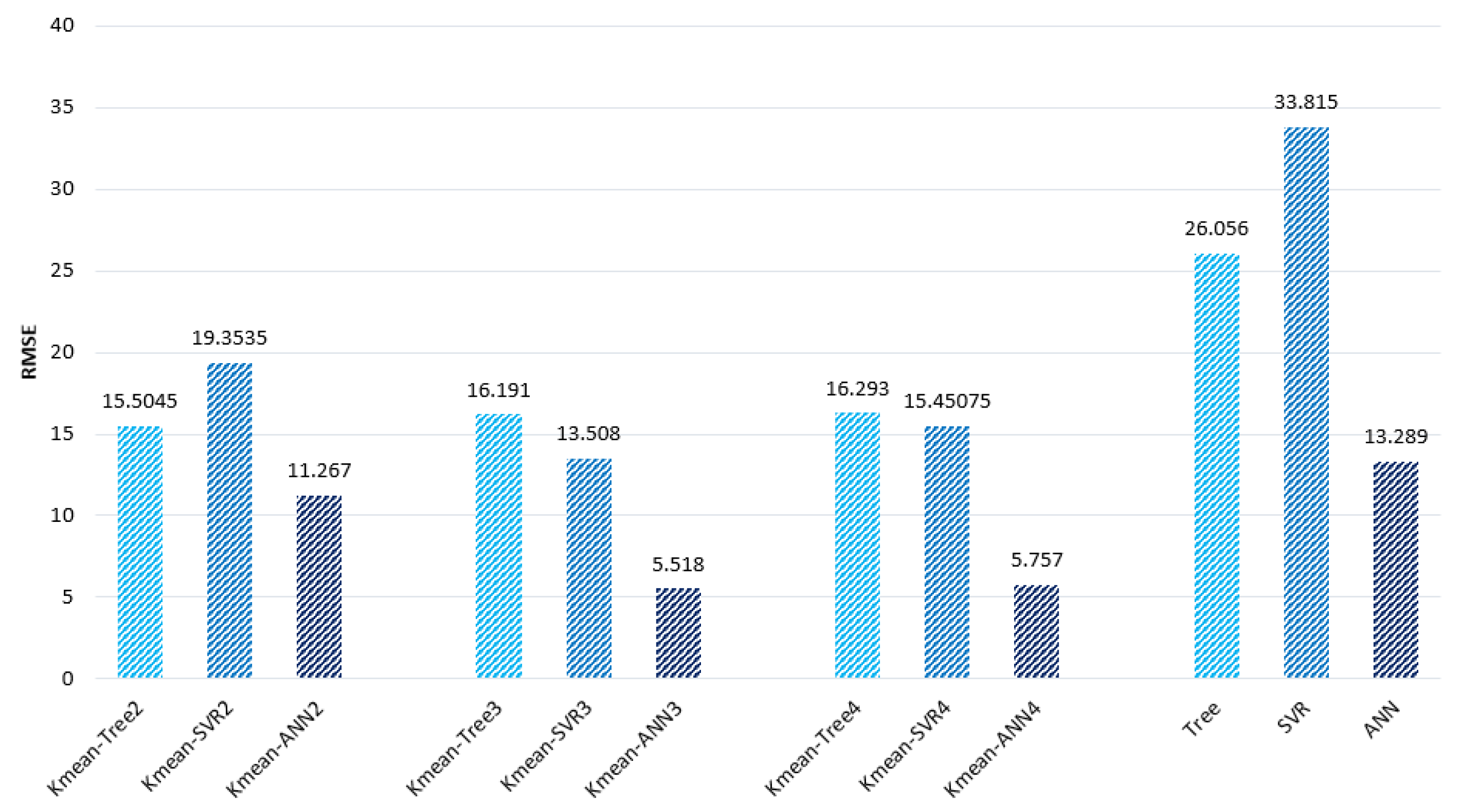
4.3. Comparison Step
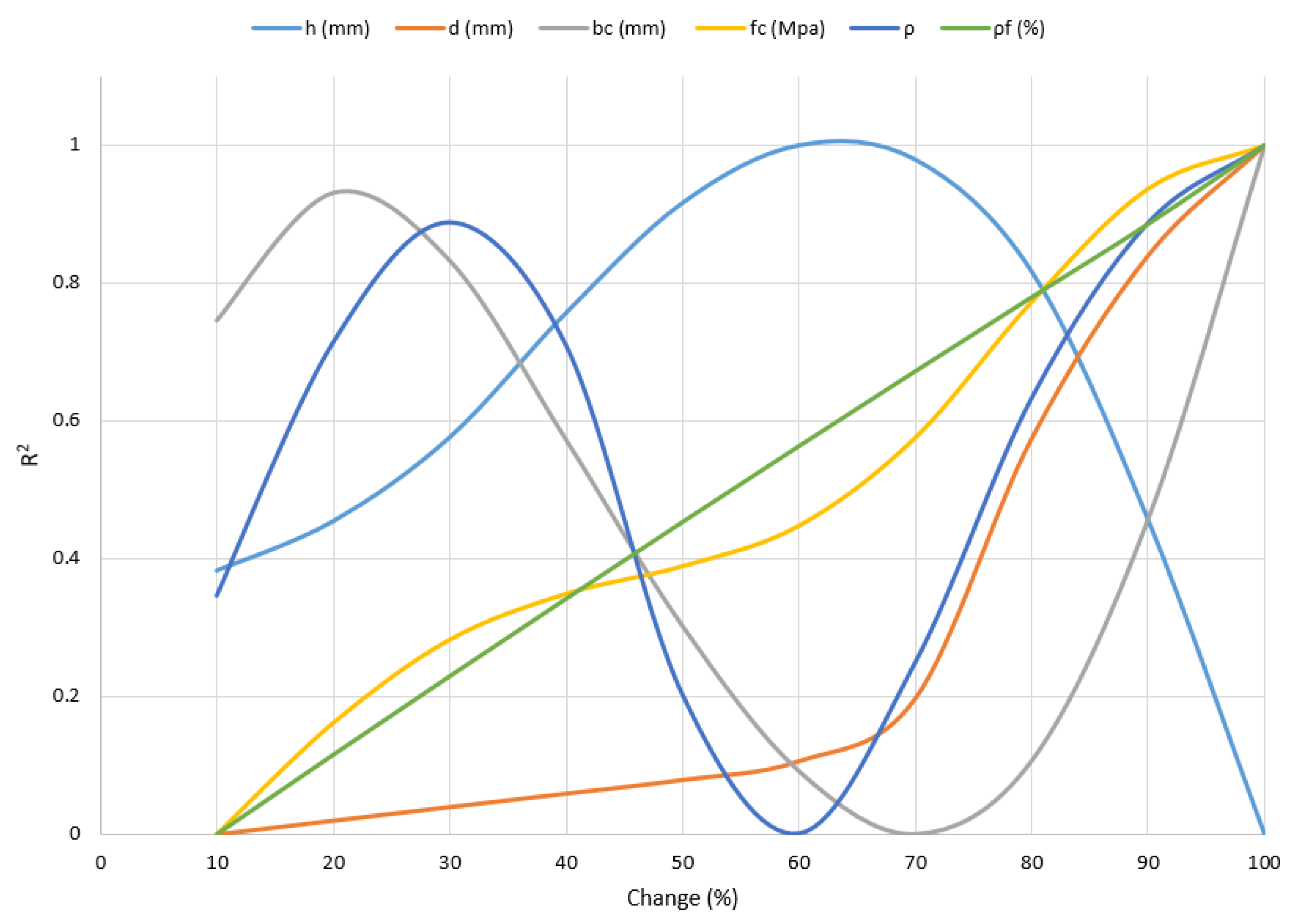
4.4. Optimization Step
5. Conclusions
- −
- The performance of all hybrid models implementing clusters 2, 3, and 4 were improved. Moreover, K-mean–ANN structures obtained accuracy up to R2 = 0.992 to predict SFRC flat slabs.
- −
- The error of the models was significantly reduced compared to the base models, which confirms that the common data perform better with each other.
- −
- Finally, a diagram was presented showing the effect of input parameters on the K-mean–ANN3 structure that performed the best among all models. Using it, the effects of linearity and nonlinearity of the data on the structure of this selected model were determined.
- −
- This study presents a new methodology for a specific engineering problem. Different methods of clustering, classification, and basic predictive models including deep learning can be used to develop this methodology in future research.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fernández Ruiz, M.; Mirzaei, Y.; Muttoni, A. Post-punching behavior of flat slabs. ACI Struct. J. 2013, 110, 801–812. [Google Scholar]
- Habibi, F.; Redl, E.; Egberts, M.; Cook, W.D.; Mitchell, D. Assessment of CSA A23. 3 structural integrity requirements for two-way slabs. Can. J. Civ. Eng. 2012, 39, 351–361. [Google Scholar] [CrossRef]
- Maya, L.F.; Ruiz, M.F.; Muttoni, A.; Foster, S.J. Punching shear strength of steel fibre reinforced concrete slabs. Eng. Struct. 2012, 40, 83–94. [Google Scholar] [CrossRef] [Green Version]
- Genikomsou, A.S.; Polak, M.A. 3D finite element investigation of the compressive membrane action effect in reinforced concrete flat slabs. Eng. Struct. 2017, 136, 233–244. [Google Scholar] [CrossRef]
- Russell, J.M.; Owen, J.S.; Hajirasouliha, I. Nonlinear behaviour of reinforced concrete flat slabs after a column loss event. Adv. Struct. Eng. 2018, 21, 2169–2183. [Google Scholar] [CrossRef]
- Marí, A.; Cladera, A.; Oller, E.; Bairán, J.M. A punching shear mechanical model for reinforced concrete flat slabs with and without shear reinforcement. Eng. Struct. 2018, 166, 413–426. [Google Scholar] [CrossRef]
- Schousboe, I. Bailey’s crossroads collapse reviewed. J. Constr. Div. 1976, 102, 365–378. [Google Scholar] [CrossRef]
- King, S.; Delatte, N.J. Collapse of 2000 Commonwealth Avenue: Punching shear case study. J. Perform. Constr. Facil. 2004, 18, 54–61. [Google Scholar] [CrossRef] [Green Version]
- Shah, A.A.; Ribakov, Y. Recent trends in steel fibered high-strength concrete. Mater. Des. 2011, 32, 4122–4151. [Google Scholar] [CrossRef]
- Tian, Y.; Jirsa, J.O.; Bayrak, O. Strength evaluation of interior slab-column connections. ACI Struct. J. 2008, 105, 692. [Google Scholar]
- Tan, K.H.; Venkateshwaran, A. Punching Shear in Steel Fibre Reinforced Concrete Slabs Without Traditional Reinforcement. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Birmingham, UK, 13–15 October 2017; IOP Publishing: Bristol, UK, 2017; Volume 246, p. 12025. [Google Scholar]
- Cheng, M.-Y.; Parra-Montesinos, G.J. Evaluation of Steel Fiber Reinforcement for Punching Shear Resistance in Slab-Column Connections--Part I: Monotonically Increased Load. ACI Struct. J. 2010, 107, 101–109. [Google Scholar]
- Committee, A.C.I. Building Code Requirements for Structural Concrete (ACI 318-05) and Commentary (ACI 318R-05); American Concrete Institute: Indianapolis, IN, USA, 2005. [Google Scholar]
- Narayanan, R.; Darwish, I.Y.S. Punching shear tests on steel-fibre-reinforced micro-concrete slabs. Mag. Concr. Res. 1987, 39, 42–50. [Google Scholar] [CrossRef]
- Harajli, M.H.; Maalouf, D.; Khatib, H. Effect of fibers on the punching shear strength of slab-column connections. Cem. Concr. Compos. 1995, 17, 161–170. [Google Scholar] [CrossRef]
- Choi, K.-K.; Taha, M.M.R.; Park, H.-G.; Maji, A.K. Punching shear strength of interior concrete slab–column connections reinforced with steel fibers. Cem. Concr. Compos. 2007, 29, 409–420. [Google Scholar] [CrossRef]
- Gouveia, N.D.; Fernandes, N.A.G.; Faria, D.M.V.; Ramos, A.M.P.; Lúcio, V.J.G. SFRC flat slabs punching behaviour–Experimental research. Compos. Part B Eng. 2014, 63, 161–171. [Google Scholar] [CrossRef]
- Kueres, D.; Hegger, J. Two-parameter kinematic theory for punching shear in reinforced concrete slabs without shear reinforcement. Eng. Struct. 2018, 175, 201–216. [Google Scholar] [CrossRef]
- Einpaul, J.; Fernández Ruiz, M.; Muttoni, A. Measurements of internal cracking in punching test slabs without shear reinforcement. Mag. Concr. Res. 2018, 70, 798–810. [Google Scholar] [CrossRef]
- Simões, J.T.; Fernández Ruiz, M.; Muttoni, A. Validation of the Critical Shear Crack Theory for punching of slabs without transverse reinforcement by means of a refined mechanical model. Struct. Concr. 2018, 19, 191–216. [Google Scholar] [CrossRef] [Green Version]
- Vu, D.-T.; Hoang, N.-D. Punching shear capacity estimation of FRP-reinforced concrete slabs using a hybrid machine learning approach. Struct. Infrastruct Eng. 2016, 12, 1153–1161. [Google Scholar] [CrossRef]
- Xu, C.; Gordan, B.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M.; Zhang, X. Improving Performance of Retaining Walls Under Dynamic Conditions Developing an Optimized ANN Based on Ant Colony Optimization Technique. IEEE Access 2019, 7, 94692–94700. [Google Scholar] [CrossRef]
- Yang, H.; Koopialipoor, M.; Armaghani, D.J.; Gordan, B.; Khorami, M.; Tahir, M.M. Intelligent design of retaining wall structures under dynamic conditions. STEEL Compos. Struct. 2019, 31, 629–640. [Google Scholar]
- Koopialipoor, M.; Murlidhar, B.R.; Hedayat, A.; Armaghani, D.J.; Gordan, B.; Mohamad, E.T. The use of new intelligent techniques in designing retaining walls. Eng. Comput. 2019, 36, 283–294. [Google Scholar] [CrossRef]
- Sun, L.; Koopialipoor, M.; Armaghani, D.J.; Tarinejad, R.; Tahir, M.M. Applying a meta-heuristic algorithm to predict and optimize compressive strength of concrete samples. Eng. Comput. 2019, 37, 1133–1145. [Google Scholar] [CrossRef]
- Cai, M.; Koopialipoor, M.; Armaghani, D.J.; Thai Pham, B. Evaluating Slope Deformation of Earth Dams due to Earthquake Shaking using MARS and GMDH Techniques. Appl. Sci. 2020, 10, 1486. [Google Scholar] [CrossRef]
- Yang, H.; Liu, J.; Liu, B. Investigation on the cracking character of jointed rock mass beneath TBM disc cutter. Rock Mech. Rock Eng. 2018, 51, 1263–1277. [Google Scholar] [CrossRef]
- Yang, H.; Wang, Z.; Song, K. A new hybrid grey wolf optimizer-feature weighted-multiple kernel-support vector regression technique to predict TBM performance. Eng. Comput. 2020, 38, 2469–2485. [Google Scholar] [CrossRef]
- Yang, H.; Song, K.; Zhou, J. Automated Recognition Model of Geomechanical Information Based on Operational Data of Tunneling Boring Machines. Rock Mech. Rock Eng. 2022, 55, 1499–1516. [Google Scholar] [CrossRef]
- Zhou, J.; Qiu, Y.; Zhu, S.; Armaghani, D.J.; Khandelwal, M.; Mohamad, E.T. Estimation of the TBM advance rate under hard rock conditions using XGBoost and Bayesian optimization. Undergr. Sp. 2021, 6, 506–515. [Google Scholar] [CrossRef]
- Zhou, J.; Dai, Y.; Khandelwal, M.; Monjezi, M.; Yu, Z.; Qiu, Y. Performance of Hybrid SCA-RF and HHO-RF Models for Predicting Backbreak in Open-Pit Mine Blasting Operations. Nat. Resour. Res. 2021, 30, 4753–4771. [Google Scholar] [CrossRef]
- Zhou, J.; Qiu, Y.; Khandelwal, M.; Zhu, S.; Zhang, X. Developing a hybrid model of Jaya algorithm-based extreme gradient boosting machine to estimate blast-induced ground vibrations. Int. J. Rock Mech. Min. Sci. 2021, 145, 104856. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, C.; Wang, M.; Khandelwal, M. Proposing a novel comprehensive evaluation model for the coal burst liability in underground coal mines considering uncertainty factors. Int. J. Min. Sci. Technol. 2021, 31, 799–812. [Google Scholar] [CrossRef]
- Asteris, P.G.; Lourenço, P.B.; Roussis, P.C.; Adami, C.E.; Armaghani, D.J.; Cavaleri, L.; Chalioris, C.E.; Hajihassani, M.; Lemonis, M.E.; Mohammed, A.S. Revealing the nature of metakaolin-based concrete materials using artificial intelligence techniques. Constr. Build. Mater. 2022, 322, 126500. [Google Scholar] [CrossRef]
- Asteris, P.G.; Rizal, F.I.M.; Koopialipoor, M.; Roussis, P.C.; Ferentinou, M.; Armaghani, D.J.; Gordan, B. Slope Stability Classification under Seismic Conditions Using Several Tree-Based Intelligent Techniques. Appl. Sci. 2022, 12, 1753. [Google Scholar] [CrossRef]
- Mahmood, W.; Mohammed, A.S.; Asteris, P.G.; Kurda, R.; Armaghani, D.J. Modeling Flexural and Compressive Strengths Behaviour of Cement-Grouted Sands Modified with Water Reducer Polymer. Appl. Sci. 2022, 12, 1016. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Asteris, P.G.; Mohammed, A.S.; Alexakis, D.E.; Mamou, A.; Armaghani, D.J. Introducing stacking machine learning approaches for the prediction of rock deformation. Transp. Geotech. 2022, 34, 100756. [Google Scholar] [CrossRef]
- Barkhordari, M.; Armaghani, D.; Asteris, P. Structural Damage Identification Using Ensemble Deep Convolutional Neural Network Models. Comput. Model. Eng. Sci. 2022, 134, 835–855. [Google Scholar] [CrossRef]
- Shan, F.; He, X.; Armaghani, D.J.; Zhang, P.; Sheng, D. Success and challenges in predicting TBM penetration rate using recurrent neural networks. Tunn. Undergr. Sp. Technol. 2022, 130, 104728. [Google Scholar] [CrossRef]
- Li, C.; Zhou, J.; Tao, M.; Du, K.; Wang, S.; Armaghani, D.J.; Mohamad, E.T. Developing hybrid ELM-ALO, ELM-LSO and ELM-SOA models for predicting advance rate of TBM. Transp. Geotech. 2022, 36, 100819. [Google Scholar] [CrossRef]
- Asteris, P.G.; Mamou, A.; Ferentinou, M.; Tran, T.-T.; Zhou, J. Predicting Clay Compressibility Using a Novel Manta Ray Foraging Optimization-Based Extreme Learning Machine Model. Transp. Geotech. 2022, 37, 100861. [Google Scholar] [CrossRef]
- Mohamad, E.T.; Koopialipoor, M.; Murlidhar, B.R.; Rashiddel, A.; Hedayat, A.; Armaghani, D.J. A new hybrid method for predicting ripping production in different weathering zones through in-situ tests. Measurement 2019, 147, 106826. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Tootoonchi, H.; Jahed Armaghani, D.; Tonnizam Mohamad, E.; Hedayat, A. Application of deep neural networks in predicting the penetration rate of tunnel boring machines. Bull. Eng. Geol. Environ. 2019, 78, 6347–6360. [Google Scholar] [CrossRef]
- Zhou, J.; Guo, H.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M. Investigating the effective parameters on the risk levels of rockburst phenomena by developing a hybrid heuristic algorithm. Eng. Comput. 2020, 37, 1679–1694. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Koopialipoor, M.; Bahri, M.; Hasanipanah, M.; Tahir, M.M. A SVR-GWO technique to minimize flyrock distance resulting from blasting. Bull. Eng. Geol. Environ. 2020, 79, 4369–4385. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Noorbakhsh, A.; Noroozi Ghaleini, E.; Jahed Armaghani, D.; Yagiz, S. A new approach for estimation of rock brittleness based on non-destructive tests. Nondestruct. Test. Eval. 2019, 34, 354–375. [Google Scholar] [CrossRef]
- Huang, L.; Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M. Invasive Weed Optimization Technique-Based ANN to the Prediction of Rock Tensile Strength. Appl. Sci. 2019, 9, 5372. [Google Scholar] [CrossRef] [Green Version]
- Asteris, P.G.; Kolovos, K.G. Self-compacting concrete strength prediction using surrogate models. Neural Comput. Appl. 2019, 31, 409–424. [Google Scholar] [CrossRef]
- Asteris, P.G.; Nikoo, M. Artificial bee colony-based neural network for the prediction of the fundamental period of infilled frame structures. Neural Comput. Appl. 2019, 31, 4837–4847. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 2020, 33, 4501–4532. [Google Scholar] [CrossRef]
- Muttoni, A. Punching shear strength of reinforced concrete slabs without transverse reinforcement. ACI Struct. J. 2008, 4, 440–450. [Google Scholar]
- Fernández Ruiz, M.; Muttoni, A. Applications of the critical shear crack theory to punching of R/C slabs with transverse reinforcement. ACI Struct. J. 2009, 106, 485–494. [Google Scholar]
- Voo, J.Y.L.; Foster, S.J. Tensile-fracture of fibre-reinforced concrete: Variable engagement model. In Proceedings of the 6th International RILEM Symposium on Fibre Reinforced Concretes, Varenna, Italy, 20–22 September 2004; RILEM Publications SARL: Paris, France, 2004; pp. 875–884. [Google Scholar]
- Muttoni, A.; Fernández Ruiz, M. MC2010: The critical shear crack theory as a mechanical model for punching shear design and its application to code provisions. FIB Bull. 2010, 57, 31–60. [Google Scholar]
- Hebb, D.O. The Organization of Behavior: A Neuropsychological Theory; J. Wiley: Hoboken, NJ, USA; Chapman & Hall: London, UK, 1949. [Google Scholar]
- Simpson, P.K. Artificial Neural Systems; Pergamon Press: New York, NY, USA, 1989; ISBN 0080378943. [Google Scholar]
- Zhou, J.; Koopialipoor, M.; Li, E.; Armaghani, D.J. Prediction of rockburst risk in underground projects developing a neuro-bee intelligent system. Bull. Eng. Geol. Environ. 2020, 79, 4265–4279. [Google Scholar] [CrossRef]
- Lu, S.; Koopialipoor, M.; Asteris, P.G.; Bahri, M.; Armaghani, D.J. A Novel Feature Selection Approach Based on Tree Models for Evaluating the Punching Shear Capacity of Steel Fiber-Reinforced Concrete Flat Slabs. Materials 2020, 13, 3902. [Google Scholar] [CrossRef] [PubMed]
- Erb, R.J. Introduction to backpropagation neural network computation. Pharm. Res. 1993, 10, 165–170. [Google Scholar] [CrossRef]
- Beale, R.; Jackson, T. Neural Computing–An Introduction; CRC Press: Boca Raton, FL, USA, 1990; ISBN 1420050435. [Google Scholar]
- Gurney, K. An Introduction to Neural Networks; CRC Press: Boca Raton, FL, USA, 1997; ISBN 1857285034. [Google Scholar]
- Breiman, L. Some properties of splitting criteria. Mach. Learn. 1996, 24, 41–47. [Google Scholar] [CrossRef] [Green Version]
- Pfahringer, B. Random Model Trees: An Effective and Scalable Regression Method; The University of Waikato: Hamilton, New Zealand, 2010. [Google Scholar]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Wen, L.; Cao, Y. Influencing factors analysis and forecasting of residential energy-related CO2 emissions utilizing optimized support vector machine. J. Clean. Prod. 2020, 250, 119492. [Google Scholar] [CrossRef]
- Peng, X. A spheres-based support vector machine for pattern classification. Neural Comput. Appl. 2019, 31, 379–396. [Google Scholar] [CrossRef]
- Wu, H.-C. The Karush–Kuhn–Tucker optimality conditions in an optimization problem with interval-valued objective function. Eur. J. Oper. Res. 2007, 176, 46–59. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Armaghani, D.J.; Hedayat, A.; Marto, A.; Gordan, B. Applying various hybrid intelligent systems to evaluate and predict slope stability under static and dynamic conditions. Soft Comput. 2018, 23, 5913–5929. [Google Scholar] [CrossRef]
- Tang, D.; Gordan, B.; Koopialipoor, M.; Jahed Armaghani, D.; Tarinejad, R.; Thai Pham, B.; Huynh, V. Van Seepage Analysis in Short Embankments Using Developing a Metaheuristic Method Based on Governing Equations. Appl. Sci. 2020, 10, 1761. [Google Scholar] [CrossRef] [Green Version]
- Mahdiyar, A.; Jahed Armaghani, D.; Koopialipoor, M.; Hedayat, A.; Abdullah, A.; Yahya, K. Practical Risk Assessment of Ground Vibrations Resulting from Blasting, Using Gene Expression Programming and Monte Carlo Simulation Techniques. Appl. Sci. 2020, 10, 472. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Li, C.; Koopialipoor, M.; Jahed Armaghani, D.; Thai Pham, B. Development of a new methodology for estimating the amount of PPV in surface mines based on prediction and probabilistic models (GEP-MC). Int. J. Min. Reclam. Environ. 2020, 35, 48–68. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Nikouei, S.S.; Marto, A.; Fahimifar, A.; Armaghani, D.J.; Mohamad, E.T. Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull. Eng. Geol. Environ. 2018, 78, 3799–3813. [Google Scholar] [CrossRef]
- Zhou, J.; Asteris, P.G.; Armaghani, D.J.; Pham, B.T. Prediction of ground vibration induced by blasting operations through the use of the Bayesian Network and random forest models. Soil Dyn. Earthq. Eng. 2020, 139, 106390. [Google Scholar] [CrossRef]
- Li, Z.; Yazdani Bejarbaneh, B.; Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M. A hybrid GEP and WOA approach to estimate the optimal penetration rate of TBM in granitic rock mass. Soft Comput. 2021, 25, 11877–11895. [Google Scholar] [CrossRef]
- Parsajoo, M.; Armaghani, D.J.; Asteris, P.G. A precise neuro-fuzzy model enhanced by artificial bee colony techniques for assessment of rock brittleness index. Neural Comput. Appl. 2021, 34, 3263–3281. [Google Scholar] [CrossRef]
- Liao, J.; Asteris, P.G.; Cavaleri, L.; Mohammed, A.S.; Lemonis, M.E.; Tsoukalas, M.Z.; Skentou, A.D.; Maraveas, C.; Koopialipoor, M.; Armaghani, D.J. Novel Fuzzy-Based Optimization Approaches for the Prediction of Ultimate Axial Load of Circular Concrete-Filled Steel Tubes. Buildings 2021, 11, 629. [Google Scholar] [CrossRef]
- Hoang, N.-D. Estimating punching shear capacity of steel fibre reinforced concrete slabs using sequential piecewise multiple linear regression and artificial neural network. Measurement 2019, 137, 58–70. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernel | Function | Parameter |
|---|---|---|
| Linear | X, Y | - |
| Polynomial | (gX.Y + c)d | g, c, d |
| Radius basis function (RBF) | exp(−g | g |
| Sigmoid | tanh(gX.Y + c) | g, c |
| Number of Class | Sub-Section | Models | R2 | MAE | RMSE |
|---|---|---|---|---|---|
| 2 | 1 | Tree | 0.959 | 14.836 | 18.638 |
| SVR | 0.916 | 18.61 | 26.584 | ||
| ANN | 0.973 | 9.327 | 15.118 | ||
| 2 | Tree | 0.979 | 9.156 | 12.371 | |
| SVR | 0.98 | 7.933 | 12.123 | ||
| ANN | 0.992 | 4.893 | 7.416 | ||
| 3 | 1 | Tree | 0.851 | 19.424 | 21.643 |
| SVR | 0.98 | 5.454 | 7.951 | ||
| ANN | 1 | 0.014 | 0.018 | ||
| 2 | Tree | 0.956 | 6.091 | 8.292 | |
| SVR | 0.977 | 3.779 | 5.989 | ||
| ANN | 0.999 | 0.689 | 1.418 | ||
| 3 | Tree | 0.959 | 14.836 | 18.638 | |
| SVR | 0.916 | 18.61 | 26.584 | ||
| ANN | 0.973 | 9.327 | 15.118 | ||
| 4 | 1 | Tree | 0.959 | 14.259 | 17.677 |
| SVR | 0.928 | 14.585 | 23.343 | ||
| ANN | 0.994 | 3.038 | 6.458 | ||
| 2 | Tree | 0.966 | 12.757 | 17.56 | |
| SVR | 0.934 | 14.665 | 24.52 | ||
| ANN | 0.975 | 10.321 | 15.134 | ||
| 3 | Tree | 0.851 | 19.424 | 21.643 | |
| SVR | 0.98 | 5.454 | 7.951 | ||
| ANN | 1 | 0.014 | 0.018 | ||
| 4 | Tree | 0.956 | 6.091 | 8.292 | |
| SVR | 0.977 | 3.779 | 5.989 | ||
| ANN | 0.999 | 0.689 | 1.418 |
| Class | Models | Average | ||
|---|---|---|---|---|
| R2 | MAE | RMSE | ||
| 2 | Tree | 0.969 | 11.996 | 15.505 |
| SVR | 0.948 | 13.272 | 19.354 | |
| ANN | 0.983 | 7.11 | 11.267 | |
| 3 | Tree | 0.922 | 13.450 | 16.191 |
| SVR | 0.958 | 9.281 | 13.508 | |
| ANN | 0.991 | 3.343 | 5.518 | |
| 4 | Tree | 0.933 | 13.133 | 16.293 |
| SVR | 0.955 | 9.621 | 15.451 | |
| ANN | 0.992 | 3.516 | 5.757 | |
| Optimum Parameters | Optimum Function | |||||
|---|---|---|---|---|---|---|
| h | d | bc | fc | |||
| 74.2078 | 130.7832 | 109.6579 | 50.2084 | 1.7756 | 1.6347 | 854.7517 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Hasanipanah, M.; He, B.; Rashid, A.S.A.; Ulrikh, D.V.; Fang, Q. An Optimized Clustering Approach to Investigate the Main Features in Predicting the Punching Shear Capacity of Steel Fiber-Reinforced Concrete. Sustainability 2022, 14, 12950. https://doi.org/10.3390/su141912950
Zhang S, Hasanipanah M, He B, Rashid ASA, Ulrikh DV, Fang Q. An Optimized Clustering Approach to Investigate the Main Features in Predicting the Punching Shear Capacity of Steel Fiber-Reinforced Concrete. Sustainability. 2022; 14(19):12950. https://doi.org/10.3390/su141912950
Chicago/Turabian StyleZhang, Shaojie, Mahdi Hasanipanah, Biao He, Ahmad Safuan A. Rashid, Dmitrii Vladimirovich Ulrikh, and Qiancheng Fang. 2022. "An Optimized Clustering Approach to Investigate the Main Features in Predicting the Punching Shear Capacity of Steel Fiber-Reinforced Concrete" Sustainability 14, no. 19: 12950. https://doi.org/10.3390/su141912950