5.1. Data Preparation and Training
Detection images of an underground pipe network in an old city in northwest China were collected, and 700 images taken by CCTV were selected as datasets. To simplify the analysis, only sediment, scum, corrosion, roots, mismatch, obstacles, and branch pipes were discriminated separately, as shown in
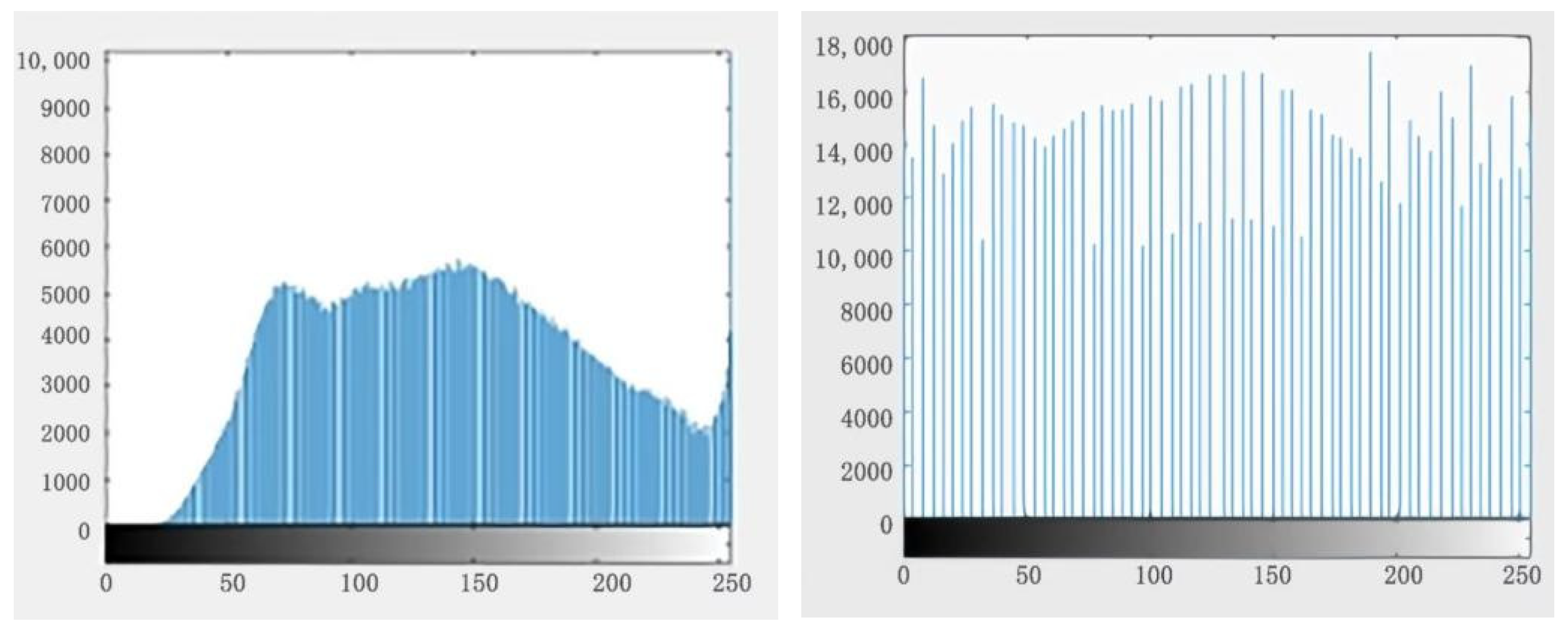
Figure 4. These seven types of defects are obvious characteristics with a high probability of occurrence and a significant impact. The dataset image was processed in advance to improve training outcomes. A histogram equalization procedure was applied to the image, and the outcome is displayed in
Figure 5. The primary purpose of histogram equalization was to average the histogram of the original image in order to increase the gray value range of the image, thereby enhancing the image contrast and optimizing the visual effect.
After histogram equalization processing, a labeled image of each defect was created, the information of which is shown in
Table 1. The above seven types of defects were marked by using Photoshop, and each picture was labeled with one major defect. To save training time and RAM, the original and labeled images were adjusted to a pixel size of 360 × 480.
Figure 6 shows an example of the labeled images.
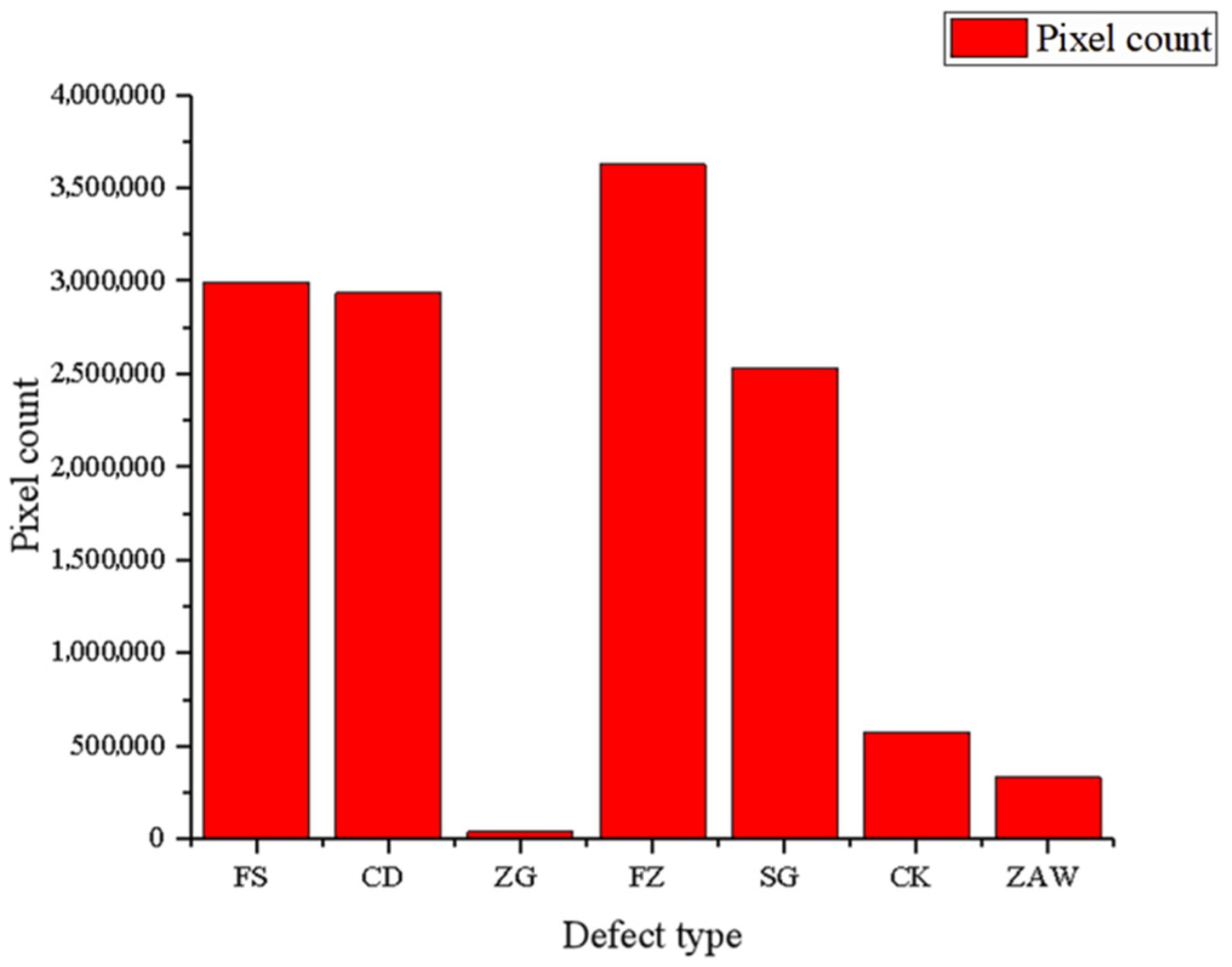
Pixel information from the labeled dataset is shown in
Table 2 and
Figure 7. It can be seen that the distribution of the various defect pixels is unbalanced. Because learning was oriented towards the dominant class, the imbalance may have had a negative impact on the learning process [
23,
24]. This problem was addressed by class weighting. The formula is shown in Equations (1) and (2), and the weights, after calculation, are shown in
Table 3.
After preprocessing was complete, the dataset was randomly divided into three subsets for training, verification, and testing. A total of 70% of the data was used for training, and the remaining 30% was divided into verification and test sets. To improve network accuracy and avoid overfitting, certain data augmentation methods, such as random left/right reflections and random left/right conversions, +/– 10 pixels, were used to provide more data. Six enhanced images were generated for each sample in the training set.
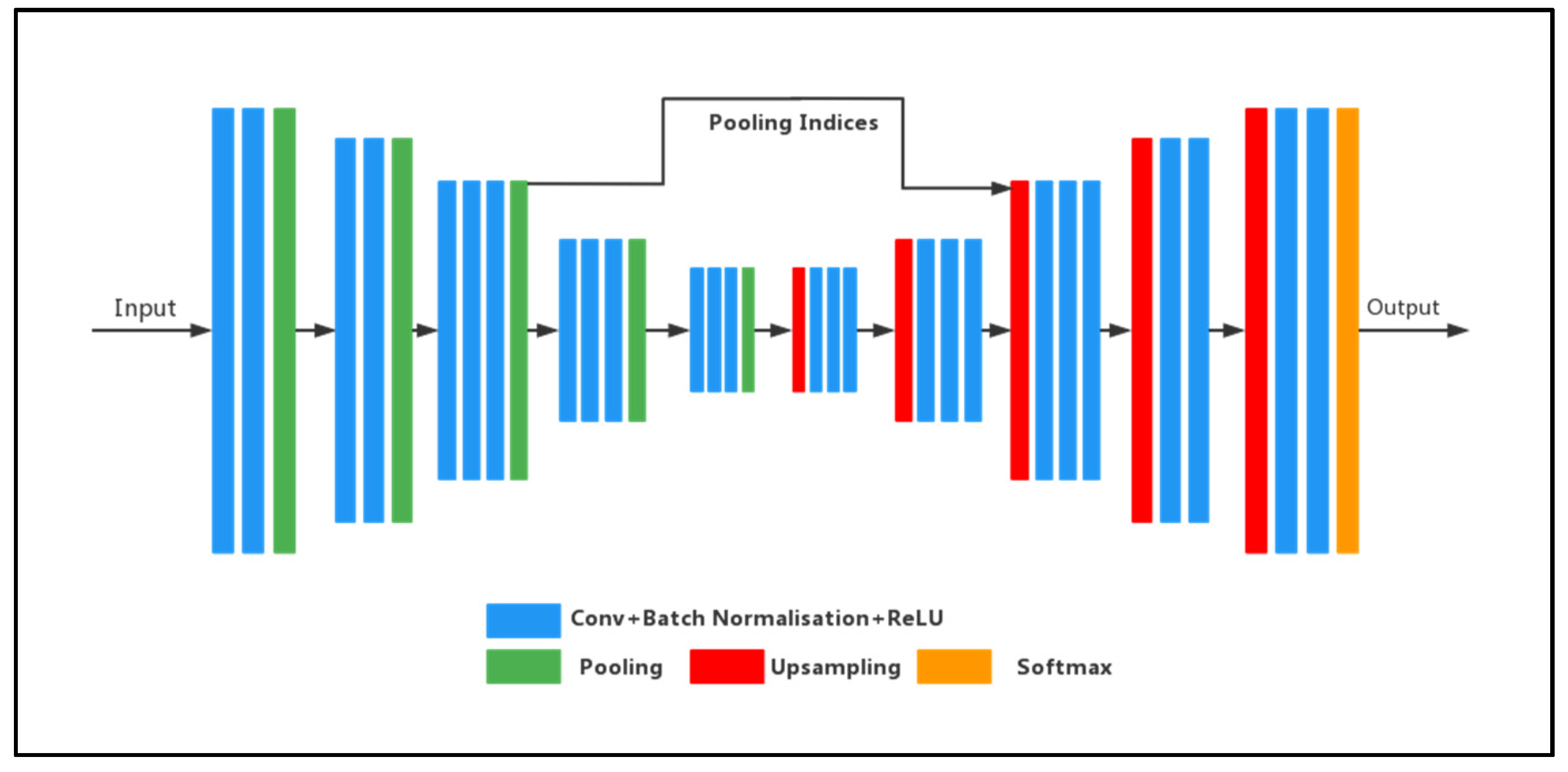
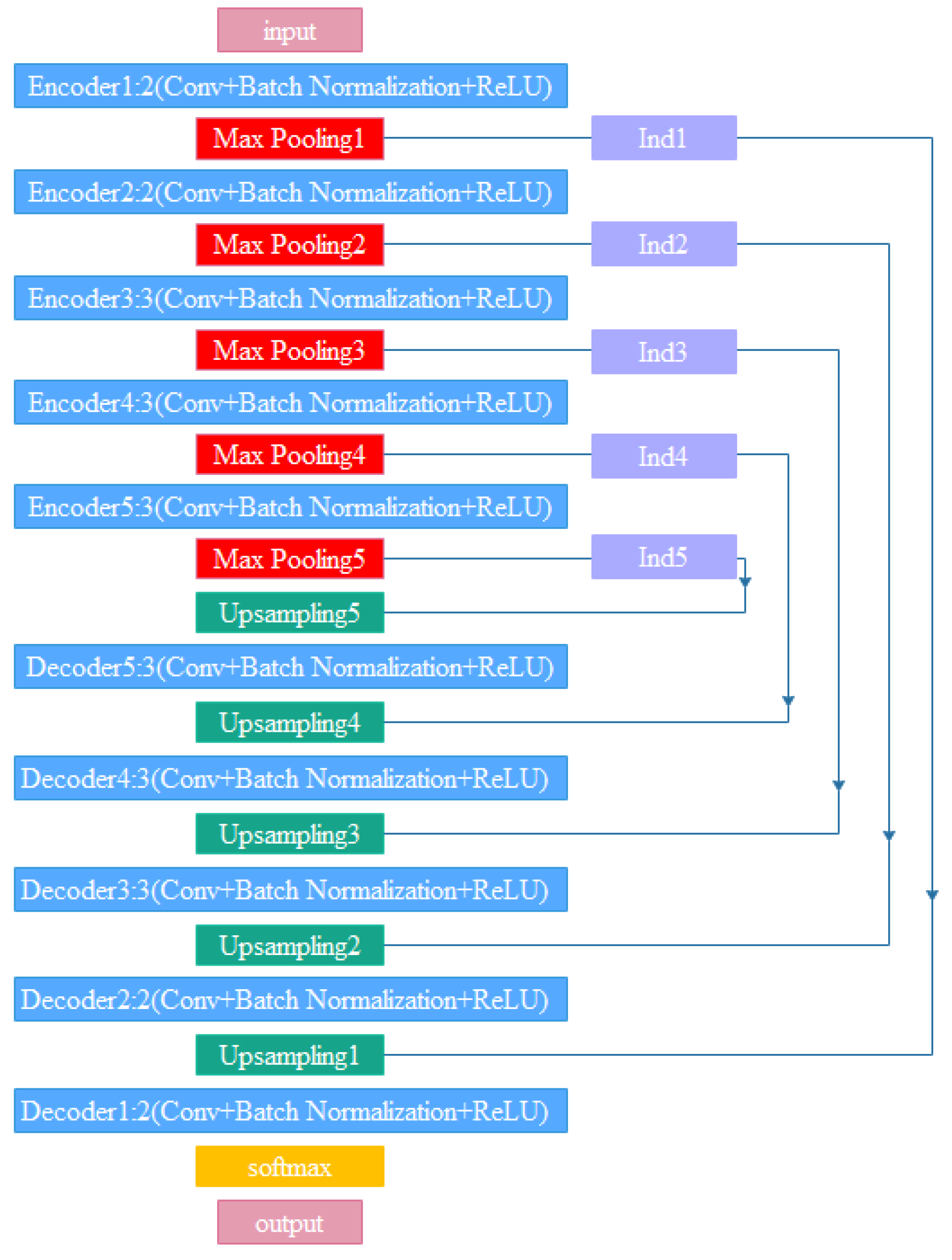
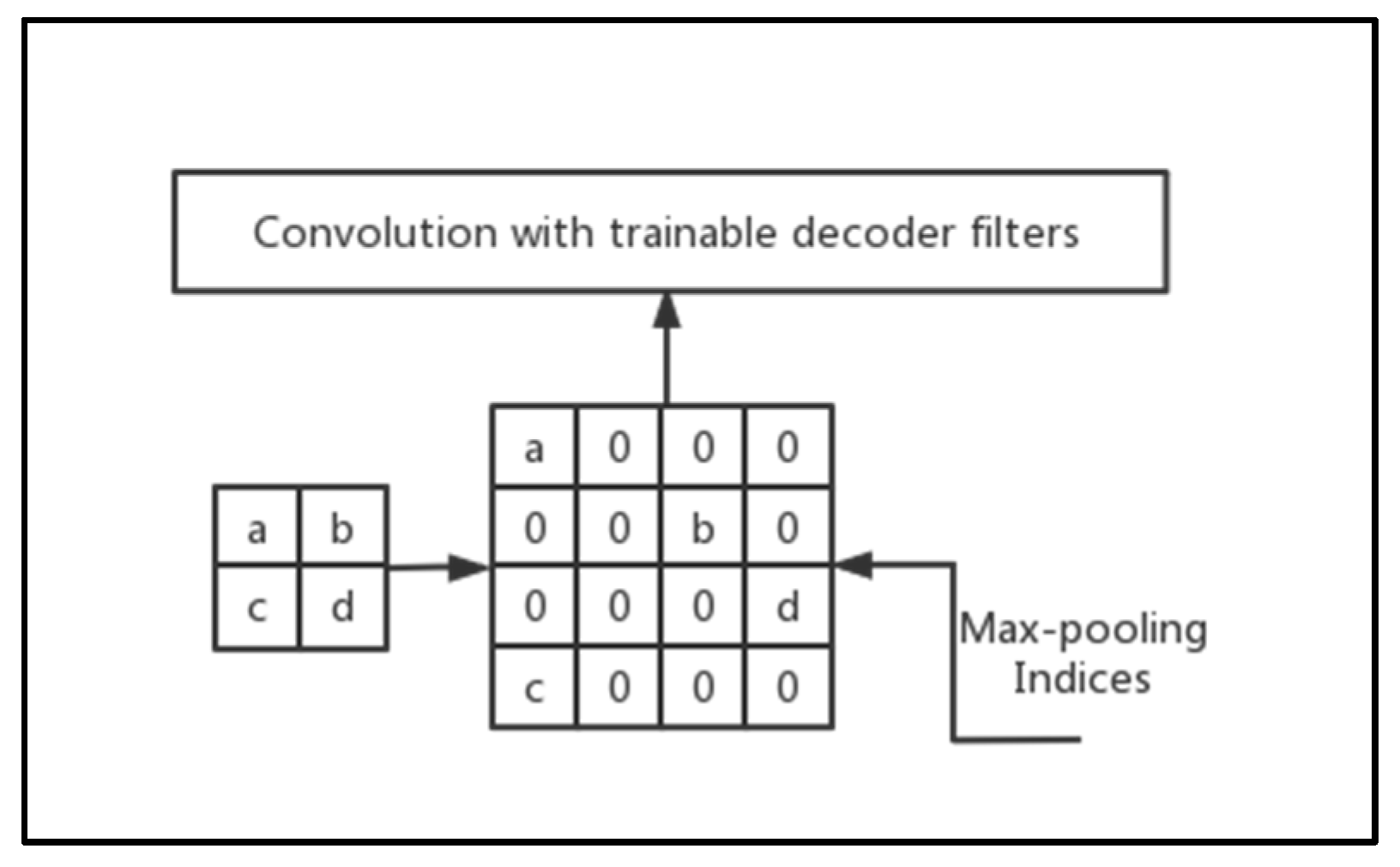
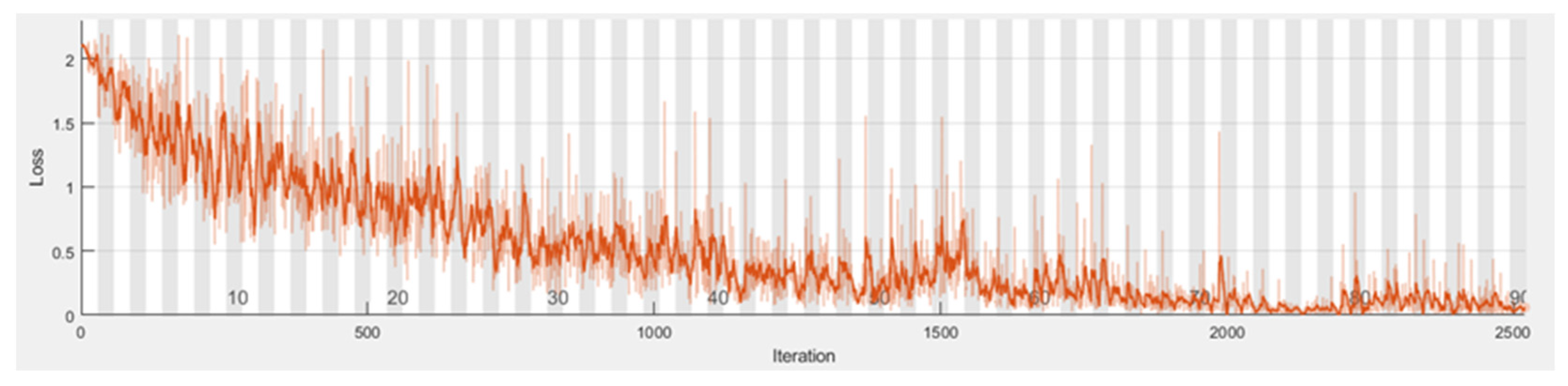
In the MATLAB platform, we used the vgg-16 network’s initialization weights to create the SegNet network. The sewage dataset was trained using the SegNet network pre-trained with the CamVid dataset, with the stochastic gradient descent with momentum (SGDM) optimizer as the training technique. The specific parameter settings were as follows: momentum 0.9, initial learning rate 0.01, L2 regularization factor 0.0005, maximum number of epochs for training 90, and mini-batch size 4. As can be seen from
Figure 8, as the number of iterations increases, the training loss tends to flatten out, and the model tends to converge.
5.2. Results and Evaluation
After 90 iterations of training, test results were obtained, and a sample of these is shown in
Figure 9. Comparing the test results with the labeled image, it is apparent that the network correctly identified the defect of scum. Only the main defect in the picture was marked in the label, but the defects not marked in the label were also identified by the network after training.
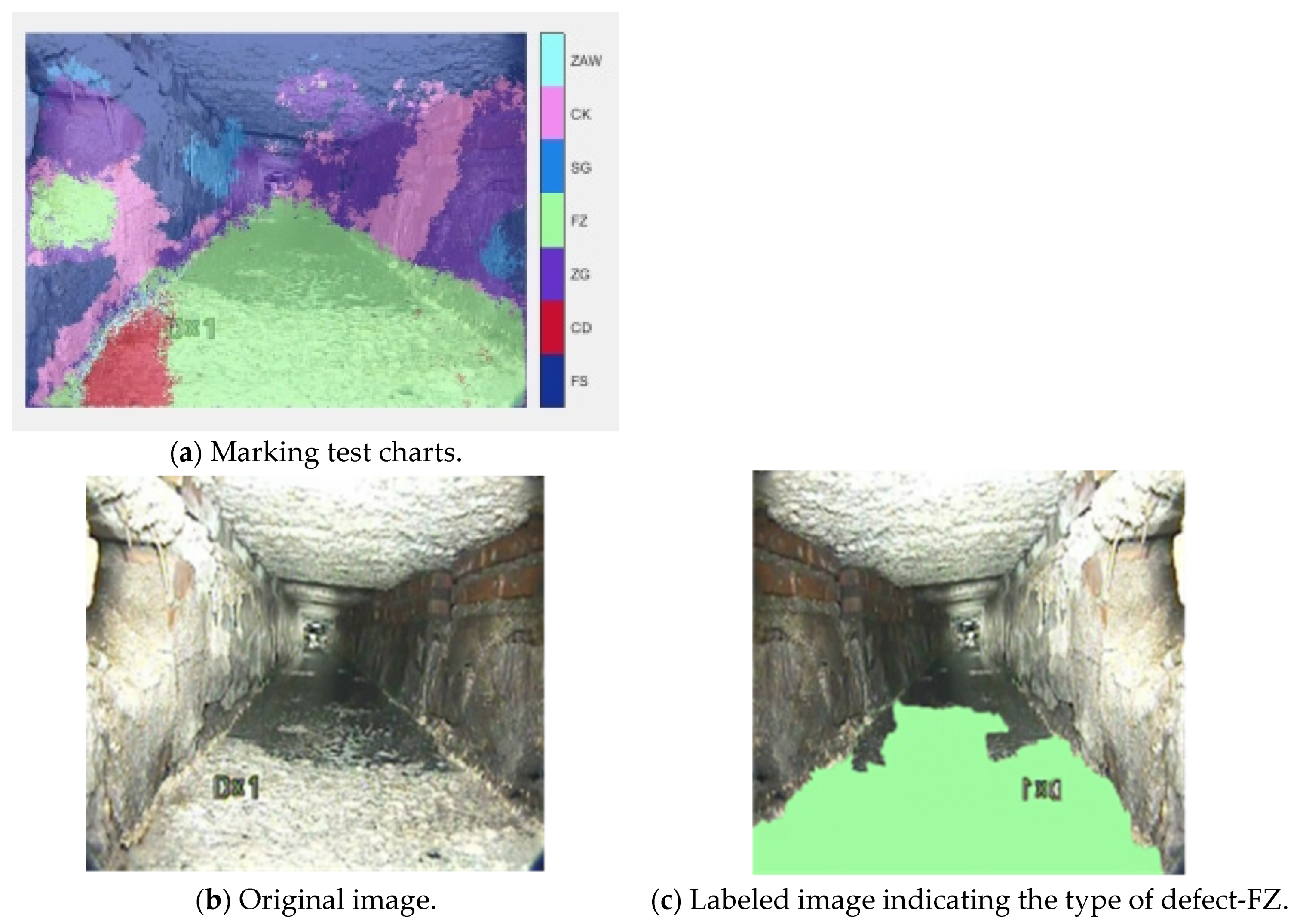
We further processed the image by processing the background to black, making it easier to identify the color of the segmented image in order to identify the type of defect in
Figure 10.
Figure 10 shows the original image and the segmented image, where the defects can be clearly seen.
For the segmented defect image, the accuracy, MIoU, and MeanBFscore were used as evaluation indicators.
Pixel accuracy (PA) is the ratio of the number of correctly segmented pixels to the total number of pixels, defined as in Equation (3). Mean pixel accuracy (MPA) is a simple improvement of PA. The proportion of correctly segmented pixels in each class is determined, and the average of all classes is calculated. The definition is shown in Equation (4):
where TP, TN, FP, and FN represent the numbers of true positives, true negatives, false positives, and false negatives, respectively, and k indicates the number of categories.
Table 4 presents the PAs and MPAs from the experiments performed in this study. The PAs were 82.77% and 79.59% on the validation and test sets, respectively, and the MPAs were 74.09% and 69.74% on the validation and test sets, respectively.
Table 5 shows the PAs of each class in the test set. Among them, five types of defect segmentation (FS, CD, ZG, FZ, and SG) achieved 80% or more precision, but the effectiveness of CK and ZAW segmentation needs to be improved.
MIoU is a commonly used evaluation index for semantic segmentation. Its definition is given in Equation (5), where
k indicates the number of categories. It calculates the intersection and union ratio of two sets. In semantic segmentation, these two sets are the labeled image and the predicted image, and the MIoU reflects the degree of coincidence between the two sets. The closer the MIoU is to 1, the higher the coincidence degree and the higher the quality of semantic segmentation. MIoU is presented in
Table 4, and the MIoU of each class in the test set is shown in
Table 5. The MIoUs were 0.61 and 0.55, respectively, on the validation and test sets, and the MIoU of each class in the test set is presented in
Table 5. The IoU of FS, CD, ZG, FZ, and SG was above 0.60, but the IoU of CK and ZAW was relatively low.
Another widely used metric for semantic segmentation is the Boundary F1 (BF) score [
25] (Equations (6)–(8)). The BF score is the contour matching score between the predicted segmentation and the true segmentation in the labeled set. The BFScores were 0.75 and 0.72, respectively, on the validation and test sets, and the BFScore of each class in the test set is presented in
Table 5.
The evaluation described above revealed that the FS, CD, ZG, FZ, and SG classes were easier to separate, but that it was difficult to separate CK and ZAW from the other classes. The reason for the poorer performance on ZAW was that there are many types of obstacles in the sewer and their division is usually based on object size, whereas the network used here is based on pixels.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






