
The Measures of Accuracy of Claim Frequency Credibility Predictor


Abstract
:1. Introduction
- The procedure in premium prediction taking into account some completely new risk factors (for which realizations of the response variable are not observed);
- Use of two accuracy measures applicable for any prediction problem based on the quantiles of absolute prediction errors;
- The parametric bootstrap estimators of the accuracy measures of the considered credibility predictor.
2. The Background of Bühlmann–Straub Model
3. Credibility Predictor of Claim Frequency
4. Bootstrap Estimators of Prediction Accuracy Measures for Claim Frequency
| Algorithm 1 The parametric bootstrap algorithm |
|
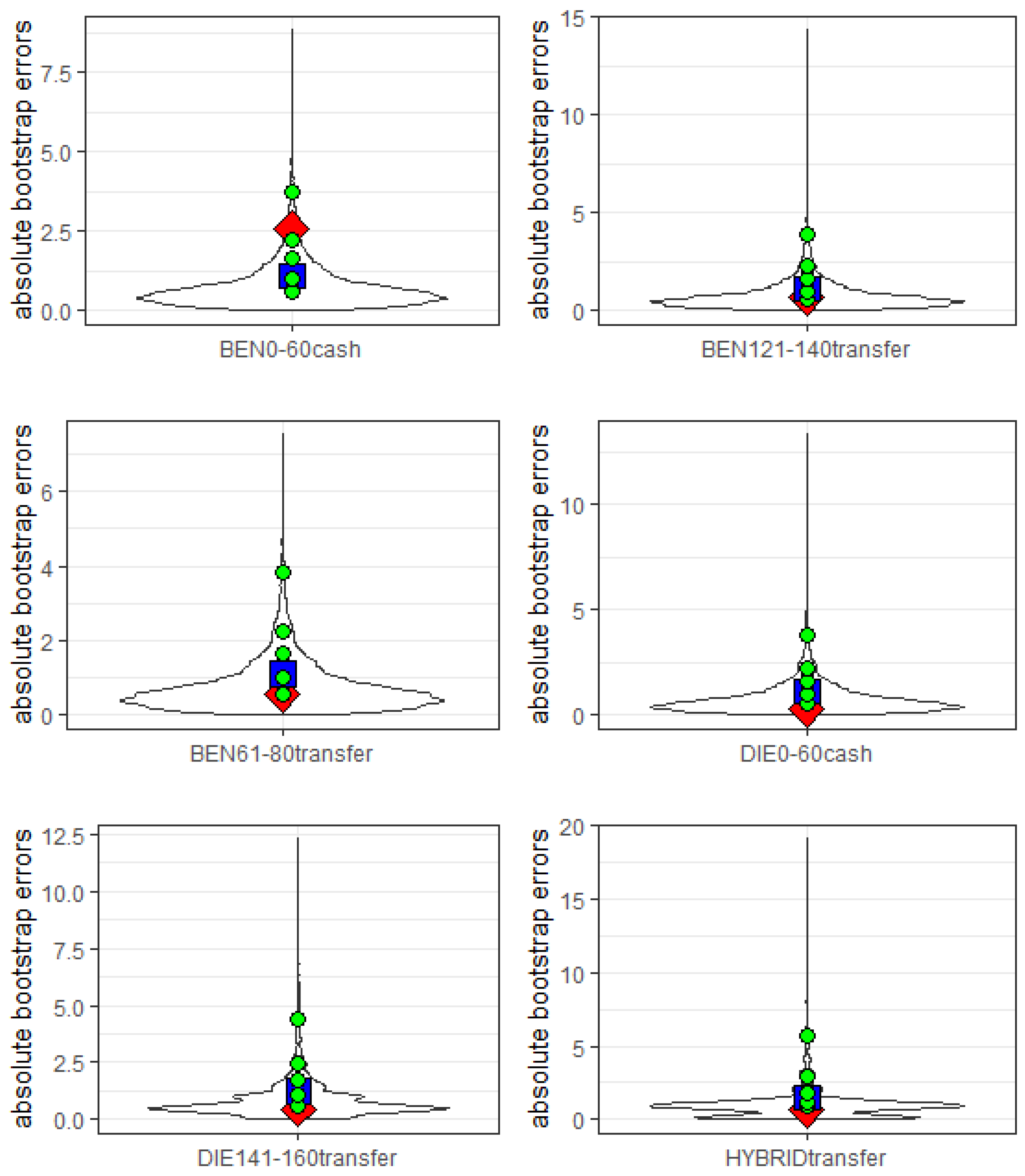
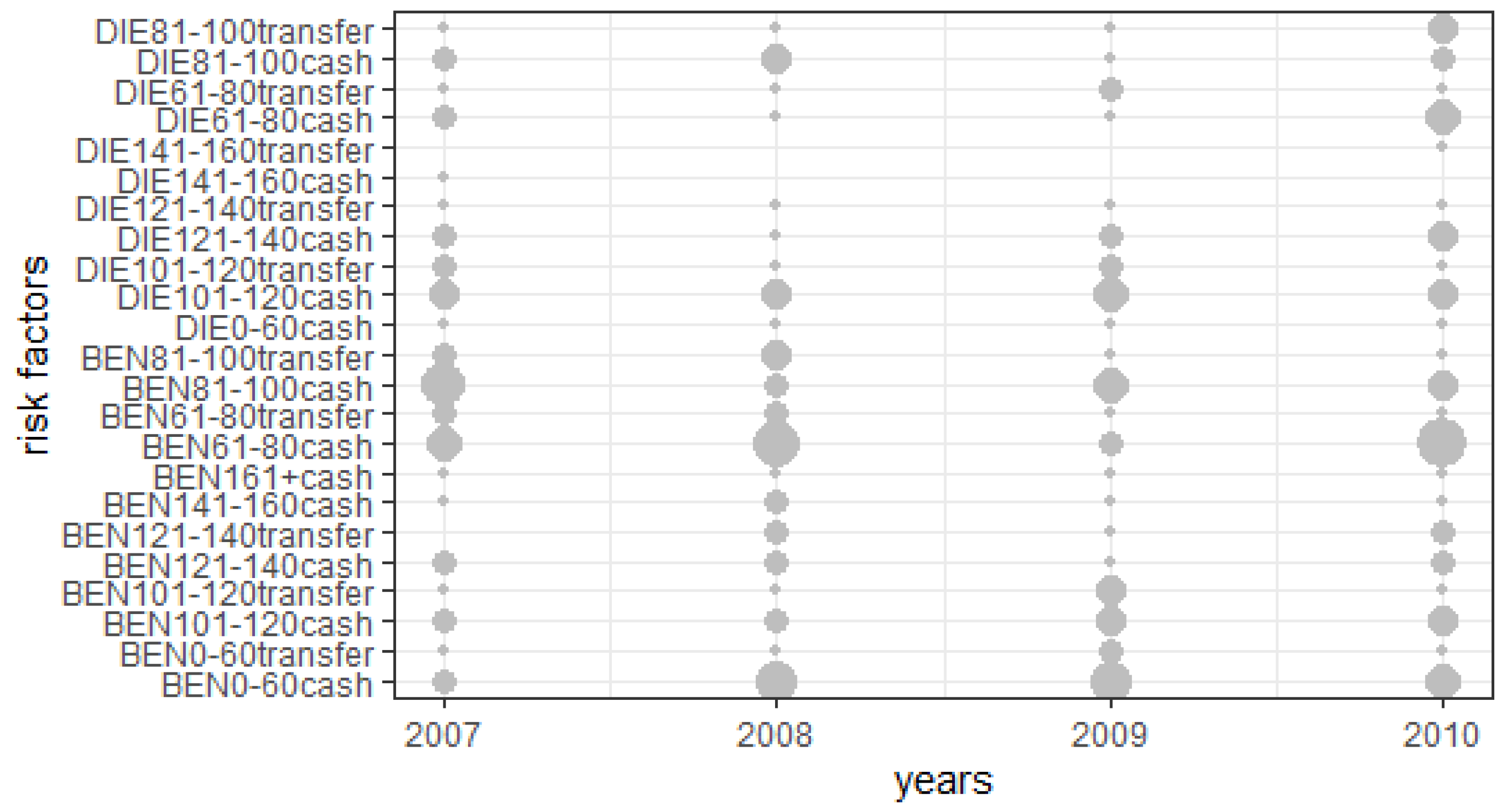
5. The Case Study Based on Longitudinal Portfolio
- The type of the engine—benzine (BEN), diesel (DIE), hybrid (HYBRID);
- The power range—0–60, 61–80, 81–100, 101–120, 121–140, 141–160, 160+;
- The type of payment—cash, transfer.
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GLMM | Generalized Linear Mixed Model |
| LMM | Linear Mixed Model |
| MSE | Mean Squared Error |
| QAPE | Quantile of Absolute Prediction Errors |
| QMAPE | Quantile of Mixture of Absolute Prediction Errors |
| RMSE | Root Mean Squared Error |
References
- Gatzert, N.; Reichel, P.; Zitzmann, A. Sustainability risks & opportunities in the insurance industry. ZVersWiss 2020, 109, 311–331. [Google Scholar]
- Gómez-Déniz, E.; Calderín-Ojeda, E. A Priori Ratemaking Selection Using Multivariate Regression Models Allowing Different Coverages in Auto Insurance. Risks 2021, 9, 137. [Google Scholar] [CrossRef]
- Shiran, G.; Imaninasab, R.; Khayamim, R. Crash Severity Analysis of Highways Based on Multinomial Logistic Regression Model, Decision Tree Techniques, and Artificial Neural Network: A Modeling Comparison. Sustainability 2021, 13, 5670. [Google Scholar] [CrossRef]
- Huang, J.S.; Wang, K.C. Are Green Car Drivers Friendly Drivers? A Study Of Taiwan’S Automobile Insurance Market. J. Risk Insur. 2019, 86, 103–119. [Google Scholar]
- United Nations Environment Programme Finance Initiative. Principles for Sustainable Insurance; UNEP FI: Gland, Switzerland, 2012. [Google Scholar]
- Bühlmann, H. Experience rating and credibility. Astin Bull. J. IAA 1967, 4, 199–207. [Google Scholar] [CrossRef] [Green Version]
- Bühlmann, H.; Straub, E. Glaubwürdigkeit für schadensätze. Bull. Swiss Assoc. Actuar. 1967, 70, 111–133. [Google Scholar]
- Jewell, W.S. Credible means are exact Bayesian for exponential families. ASTIN Bull. J. IAA 1974, 8, 77–90. [Google Scholar] [CrossRef] [Green Version]
- Hachemeister, C.A. Credibility for regression models with application to trend. In Proceedings of the Credibility, Theory and Applications, Berkeley Actuarial Research Conference on Credibility, Berkley, CA, USA, 19–21 September 1974; pp. 129–163. [Google Scholar]
- Nelder, J.A.; Verrall, R.J. Credibility theory and generalized linear models. ASTIN Bull. J. IAA 1997, 27, 71–82. [Google Scholar] [CrossRef] [Green Version]
- Ohlsson, E.; Johansson, B. Exact credibility and Tweedie models. ASTIN Bull. J. IAA 2006, 36, 121–133. [Google Scholar] [CrossRef] [Green Version]
- Ohlsson, E. Combining generalized linear models and credibility models in practice. Scand. Actuar. J. 2008, 2008, 301–314. [Google Scholar] [CrossRef]
- Rosenlund, S. Credibility pseudo-estimators. Scand. Actuar. J. 2019, 2018, 770–791. [Google Scholar] [CrossRef]
- Frees, E.W.; Young, V.R.; Luo, Y. A longitudinal data analysis interpretation of credibility models. Insur. Math. Econ. 1999, 24, 229–247. [Google Scholar] [CrossRef]
- Garrido, J.; Zhou, J. Full credibility with generalized linear and mixed models. ASTIN Bull. J. IAA 2009, 39, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.T.; Li, Z.X.; Parsa, R.A. Extension and application of credibility models in predicting claim frequency. Math. Probl. Eng. 2018, 2018, 6250686. [Google Scholar] [CrossRef]
- Pinquet, J. Poisson models with dynamic random effects and nonnegative credibilities per period. ASTIN Bull. J. IAA 2020, 50.2, 585–618. [Google Scholar] [CrossRef]
- Denuit, M.; Montserrat, G.; Trufin, J. Multivariate credibility modelling for usage-based motor insurance pricing with behavioural data. Ann. Actuar. Sci. 2019, 13, 378–399. [Google Scholar] [CrossRef] [Green Version]
- Gao, G.; Meng, S.; Wüthrich, M.V. Claims frequency modeling using telematics car driving data. Scand. Actuar. J. 2019, 2019, 143–162. [Google Scholar] [CrossRef]
- Gao, G.; Wüthrich, M.V.; Yang, H. Evaluation of driving risk at different speeds. Insur. Math. Econ. 2019, 88, 108–119. [Google Scholar] [CrossRef]
- Bühlmann, H.; Gisler, A. A Course in Credibility Theory and Its Applications; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Denuit, M.; Trufin, J. Generalization error for Tweedie models: Decomposition and error reduction with bagging. Eur. Actuar. J. 2021, 11, 325–331. [Google Scholar] [CrossRef]
- Antonio, K.; Beirlant, J. Actuarial statistics with generalized linear mixed models. Insur. Math. Econ. 2007, 40, 58–76. [Google Scholar] [CrossRef]
- Boucher, J.; Denuit, M. Fixed versus random effects in Poisson regression models for claim counts: A case study with motor insurance. Astin Bull. 2006, 36, 285–301. [Google Scholar] [CrossRef] [Green Version]
- Boucher, J.P.; Guillén, M. A survey on models for panel count data with applications to insurance. RACSAM-Rev. Real Acad. Cienc. Exactas Fis. Nat. Ser. Mat. 2009, 103, 277–294. [Google Scholar] [CrossRef]
- Boucher, J.P.; Inoussa, R. A posteriori ratemaking with panel data. ASTIN Bull. 2014, 44, 587–612. [Google Scholar] [CrossRef]
- Żądło, T. On asymmetry of prediction errors in small area estimation. Stat. Transit. New Ser. 2017, 18, 413–432. [Google Scholar] [CrossRef] [Green Version]
- Wolny-Dominiak, A.; Żądło, T. On bootstrap estimators of some prediction accuracy measures of loss reserves in a non-life insurance company. Commun.-Stat.-Simul. Comput. 2020. [Google Scholar] [CrossRef]
- Flores-Agreda, D.; Cantoni, E. Bootstrap estimation of uncertainty in prediction for generalized linear mixed models. Comput. Stat. Data Anal. 2019, 130, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Żądło, T. On accuracy estimation using parametric bootstrap in small area prediction problems. J. Off. Stat. 2020, 36, 435–458. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Claims | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| number of policies | 41 | 23 | 11 | 5 | 2 | 1 | 1 | 1 |
| fraction of policies | 0.482 | 0.271 | 0.128 | 0.059 | 0.024 | 0.012 | 0.012 | 0.012 |
| Statistic | Value |
|---|---|
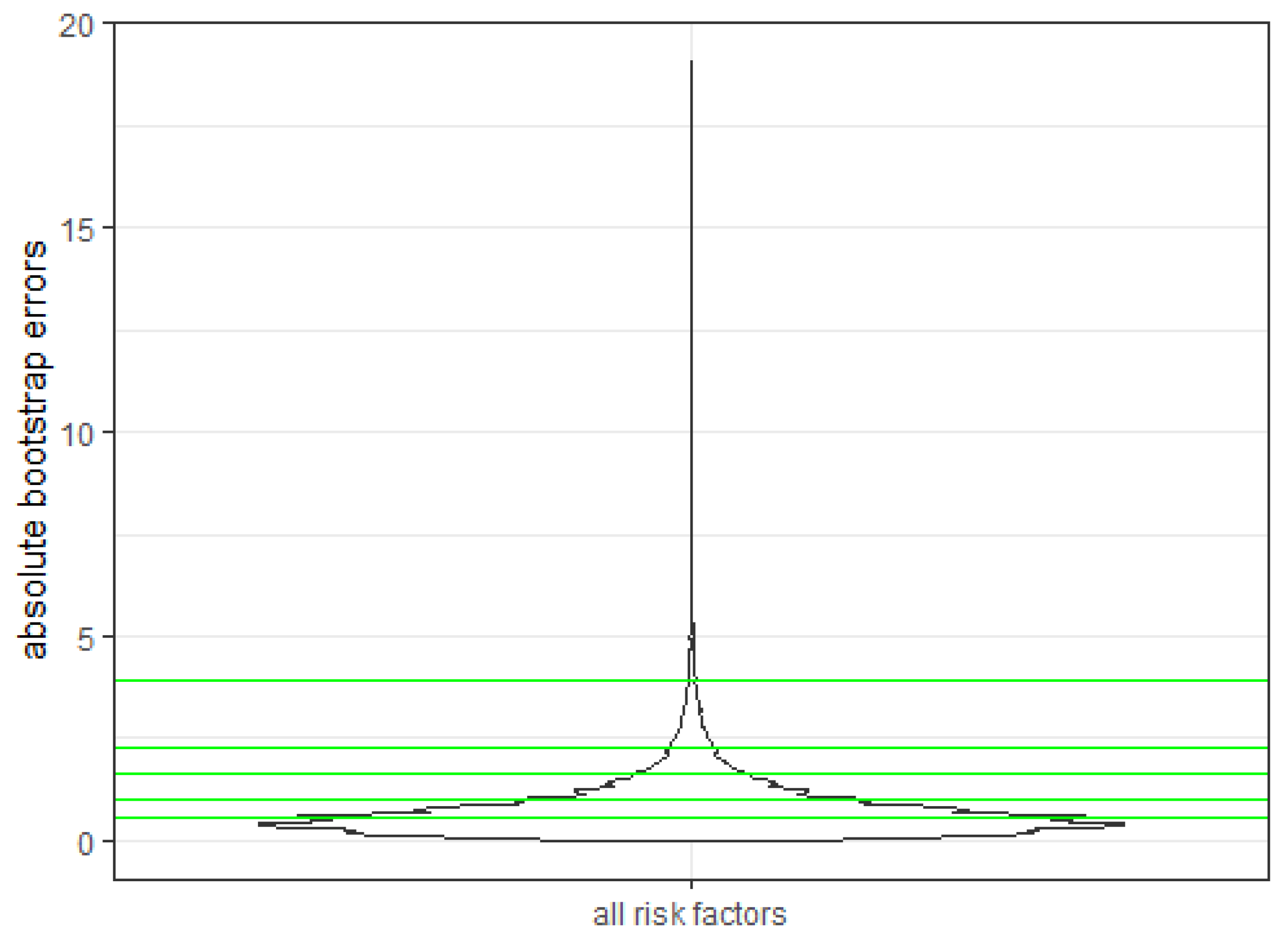
| 0.26–3.73 | |
| 1.06–1.50 | |
| 0.60 | |
| 1.01 | |
| 1.66 | |
| 2.27 | |
| 3.92 |
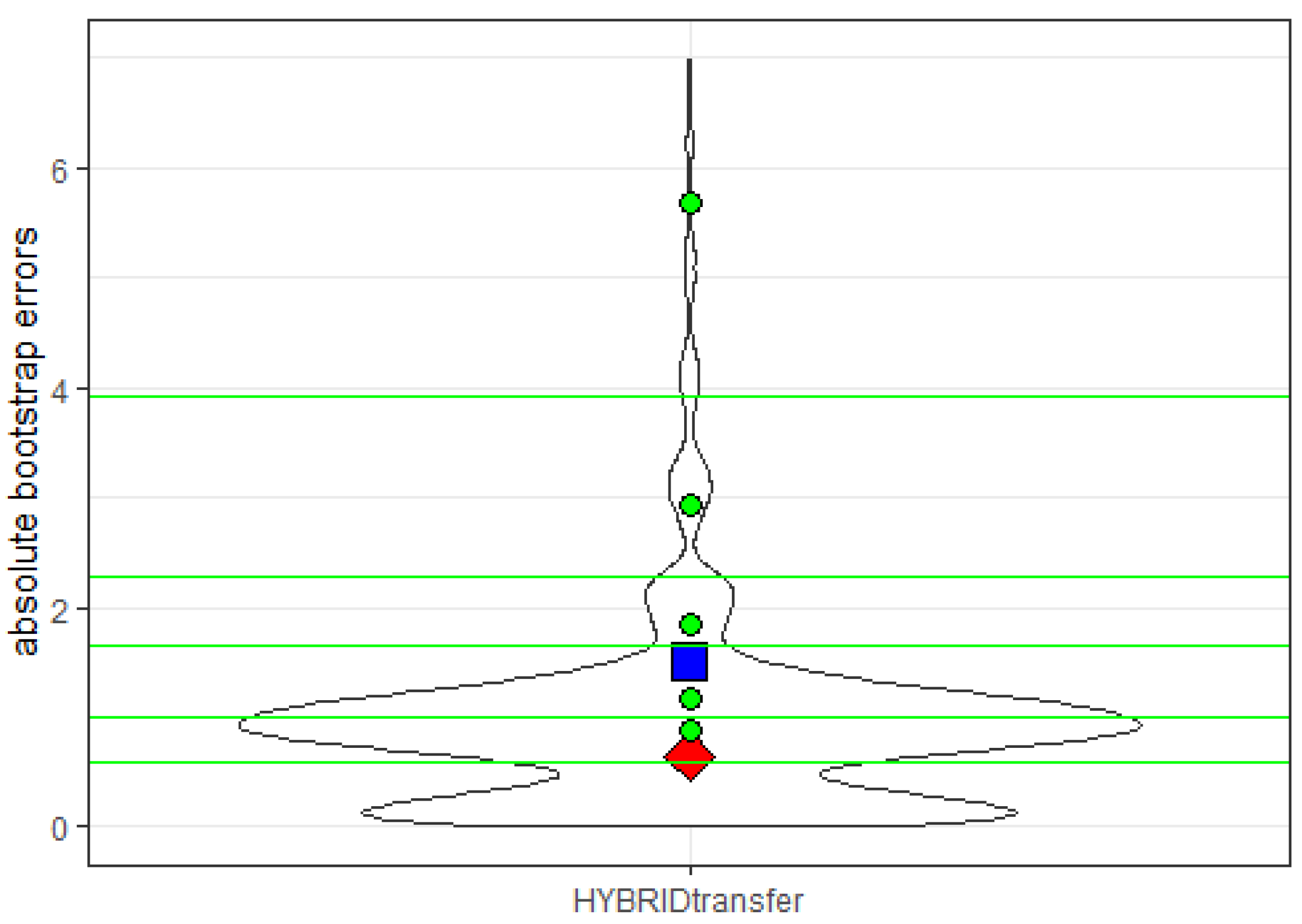
| Statistic | Value |
|---|---|
| 0.65 | |
| 1.50 | |
| 0.89 | |
| 1.18 | |
| 1.86 | |
| 2.92 | |
| 5.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wolny-Dominiak, A.; Żądło, T. The Measures of Accuracy of Claim Frequency Credibility Predictor. Sustainability 2021, 13, 11959. https://doi.org/10.3390/su132111959
Wolny-Dominiak A, Żądło T. The Measures of Accuracy of Claim Frequency Credibility Predictor. Sustainability. 2021; 13(21):11959. https://doi.org/10.3390/su132111959
Chicago/Turabian StyleWolny-Dominiak, Alicja, and Tomasz Żądło. 2021. "The Measures of Accuracy of Claim Frequency Credibility Predictor" Sustainability 13, no. 21: 11959. https://doi.org/10.3390/su132111959