Resilience of Process Plant: What, Why, and How Resilience Can Improve Safety and Sustainability


Abstract
:1. Introduction
1.1. What Is Meant with Resilience in This Paper?
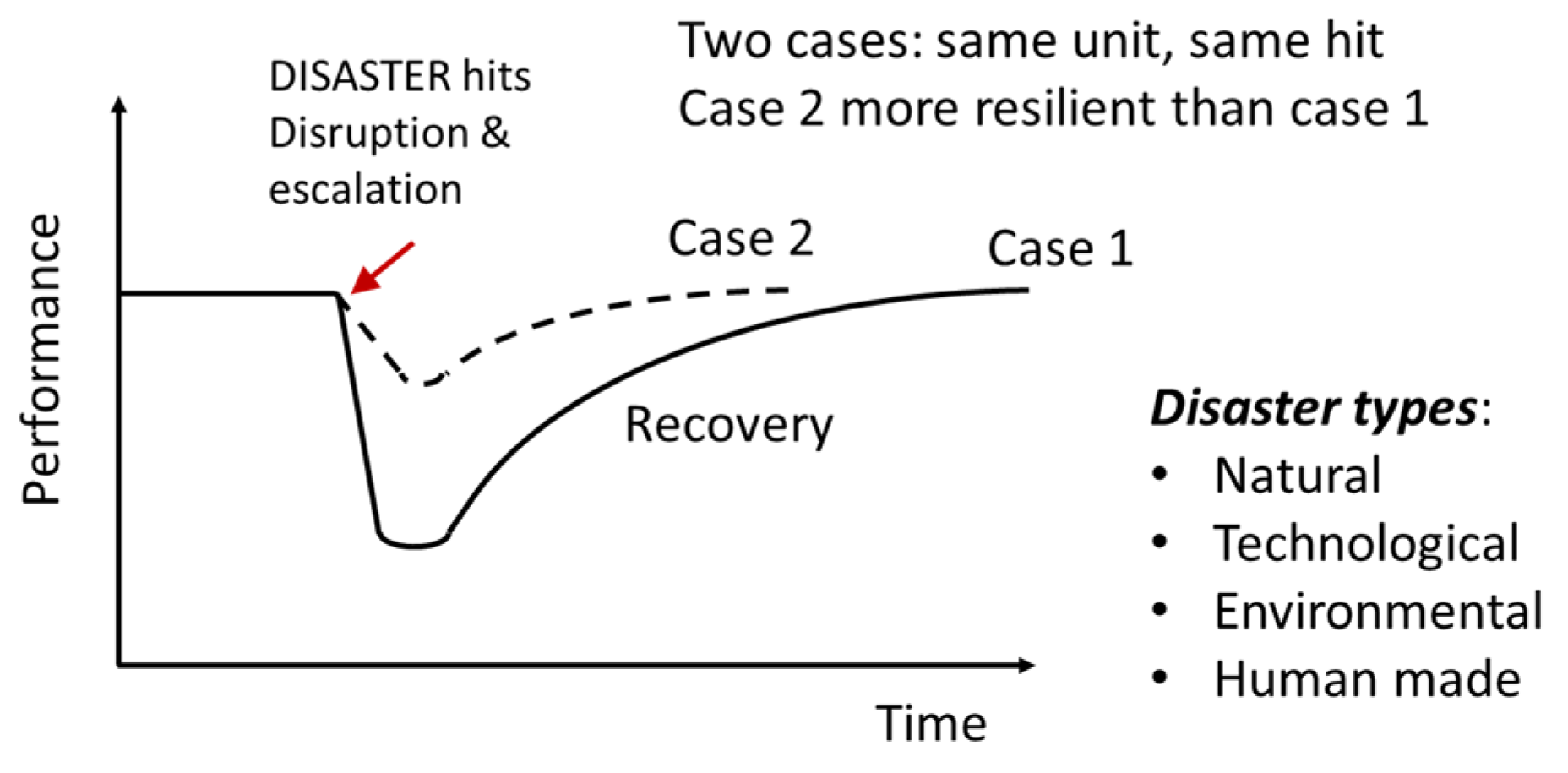
1.2. Why Is Considering Resilience Useful?
1.3. Previous Work and Objective of This Paper
2. Resilience Elements
2.1. System Approach: Sociotechnical System
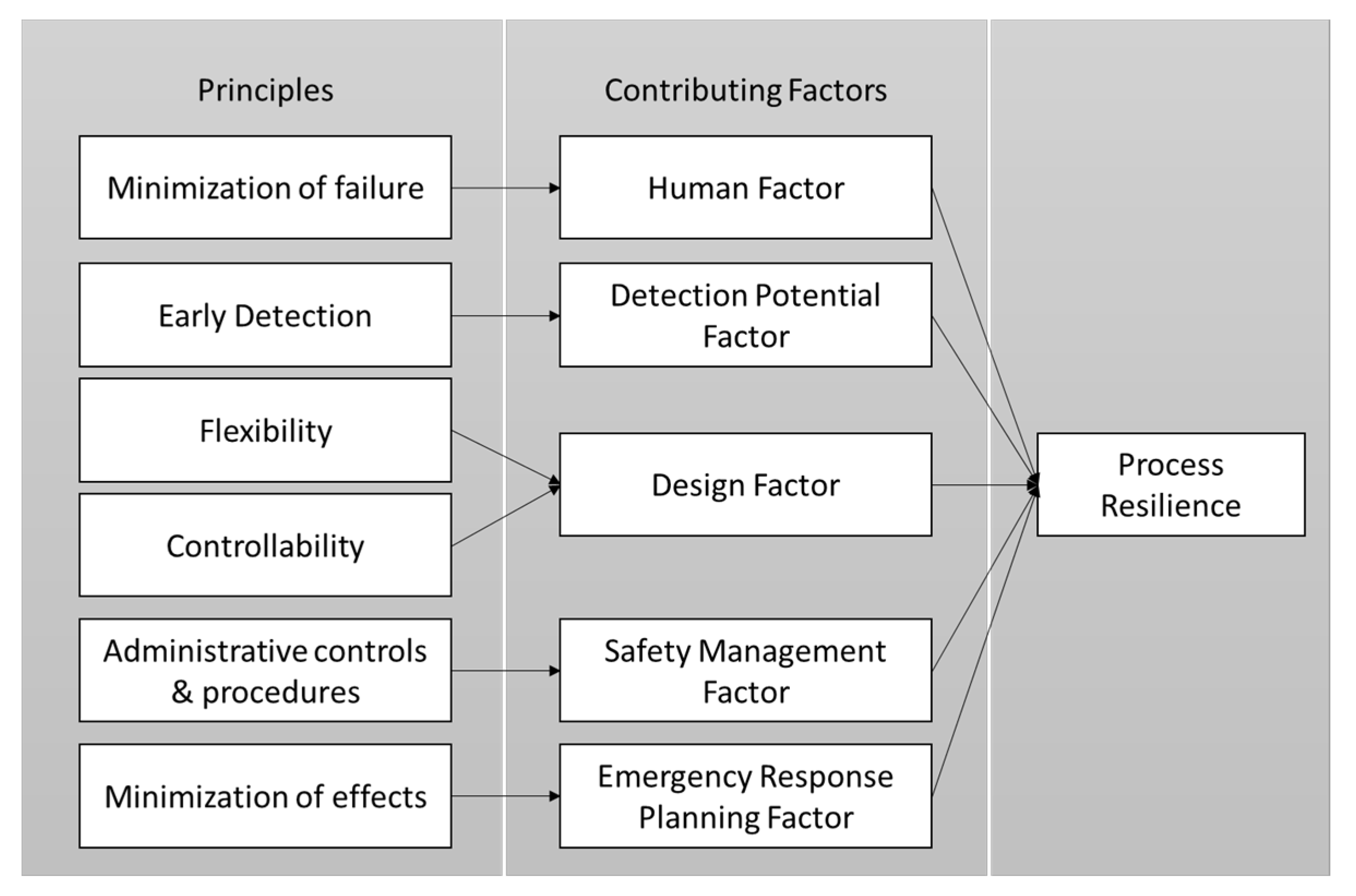
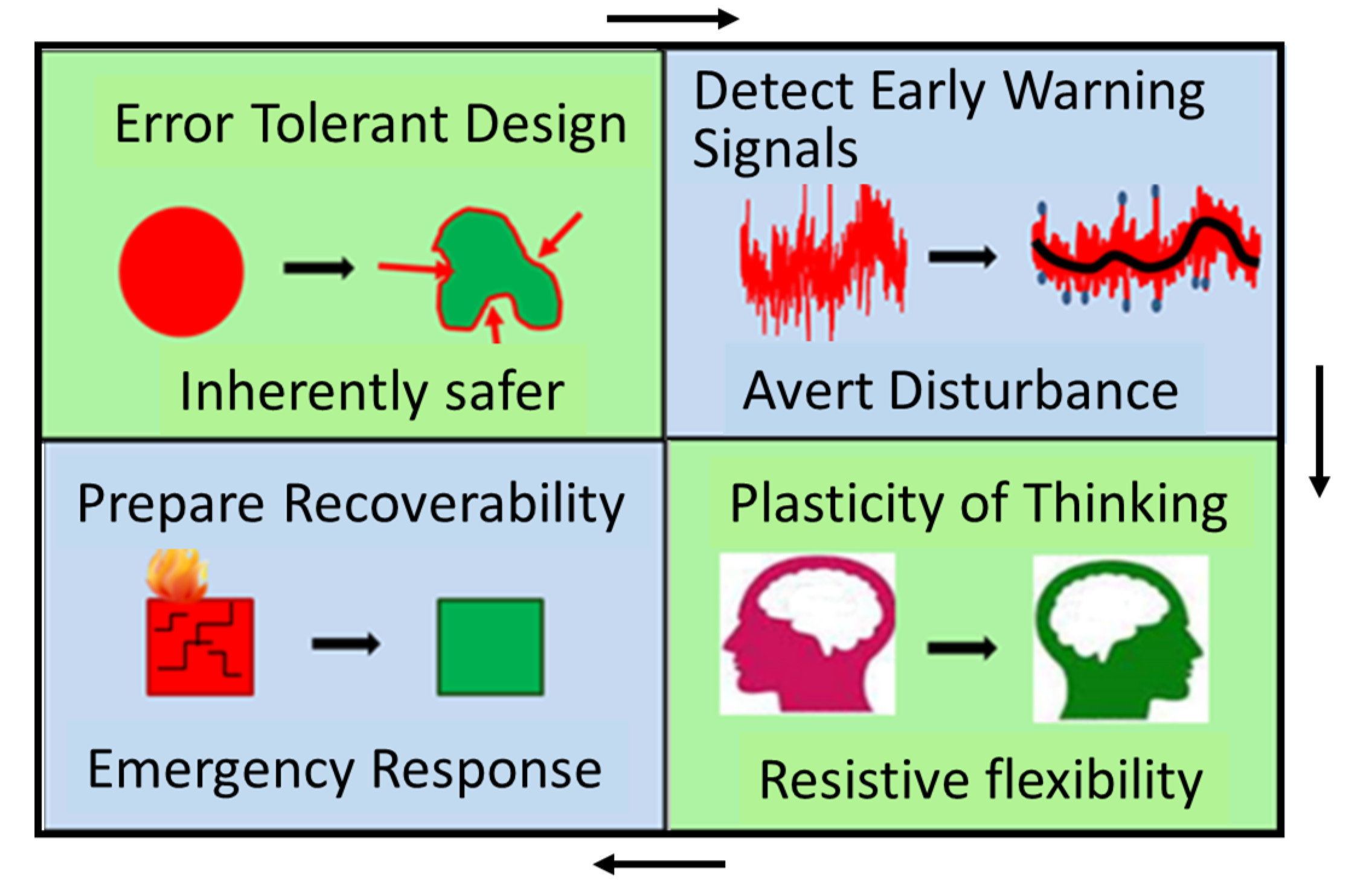
2.2. Key Elements or Aspects of Resilience
2.2.1. Error Tolerant Design
2.2.2. Early Warning
2.2.3. Plasticity
2.2.4. Recoverability
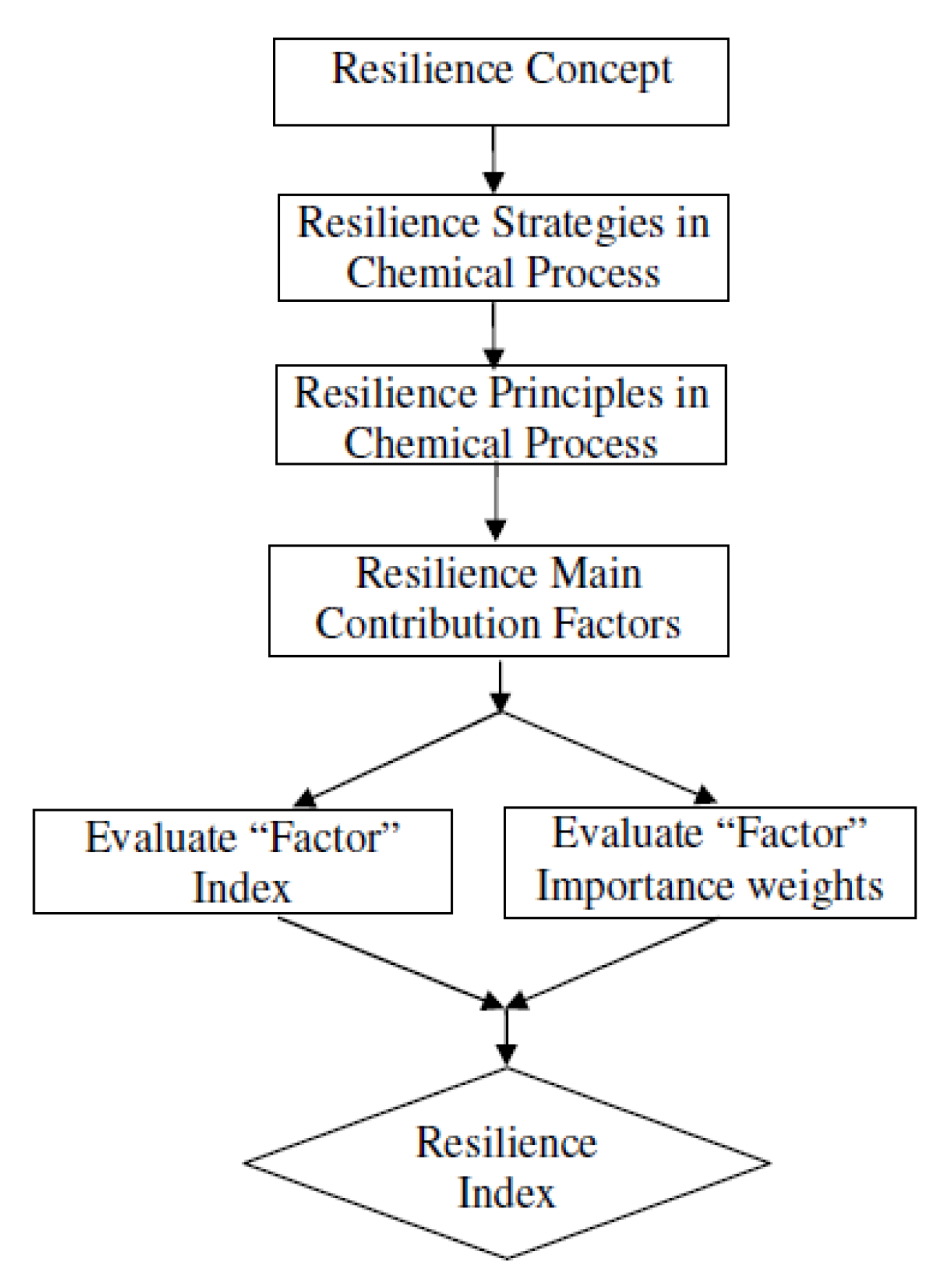
3. How Can Resilience Be Determined?
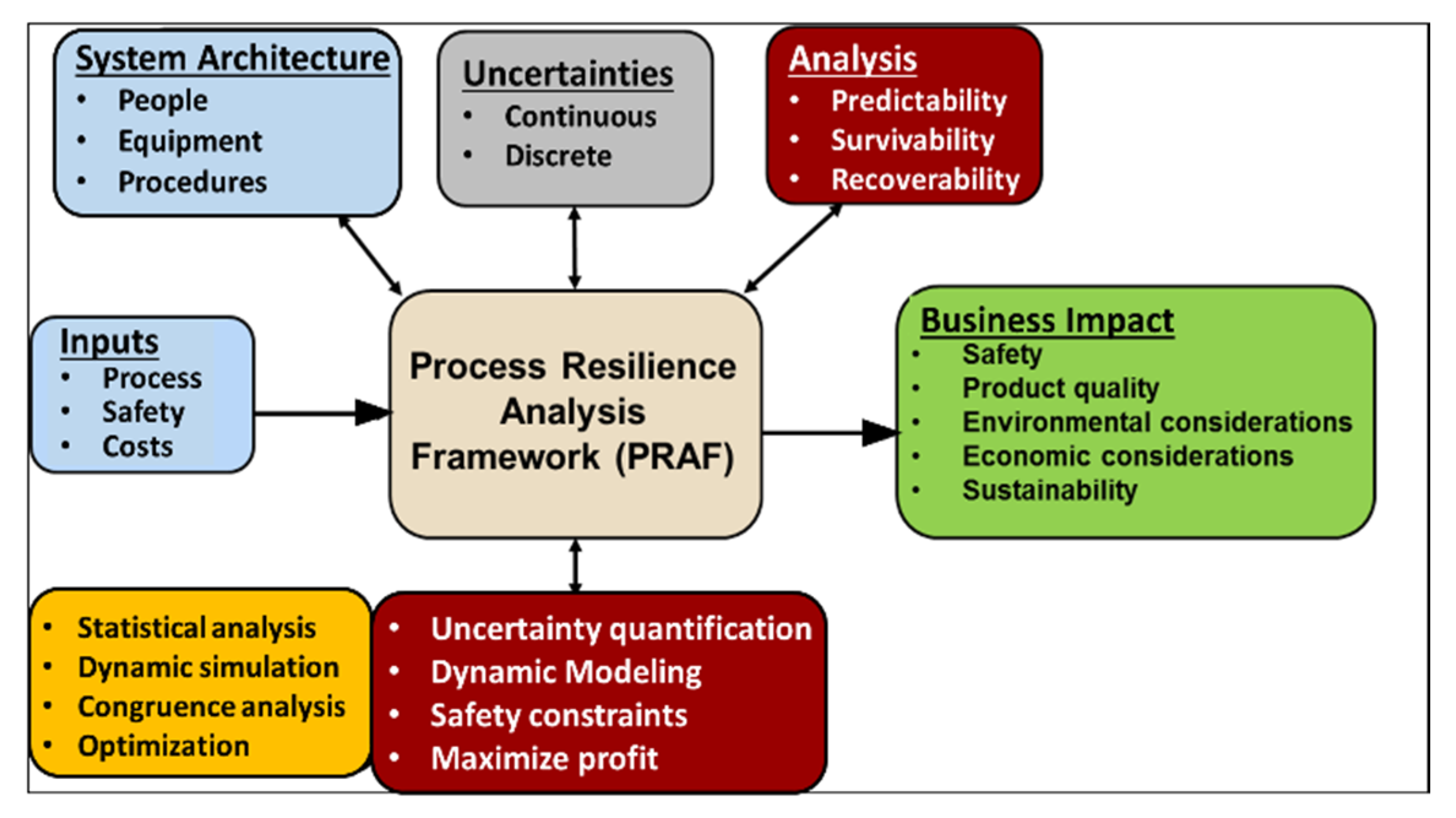
3.1. Resilience Determination Framework
3.2. Resilience Factors or Metrics
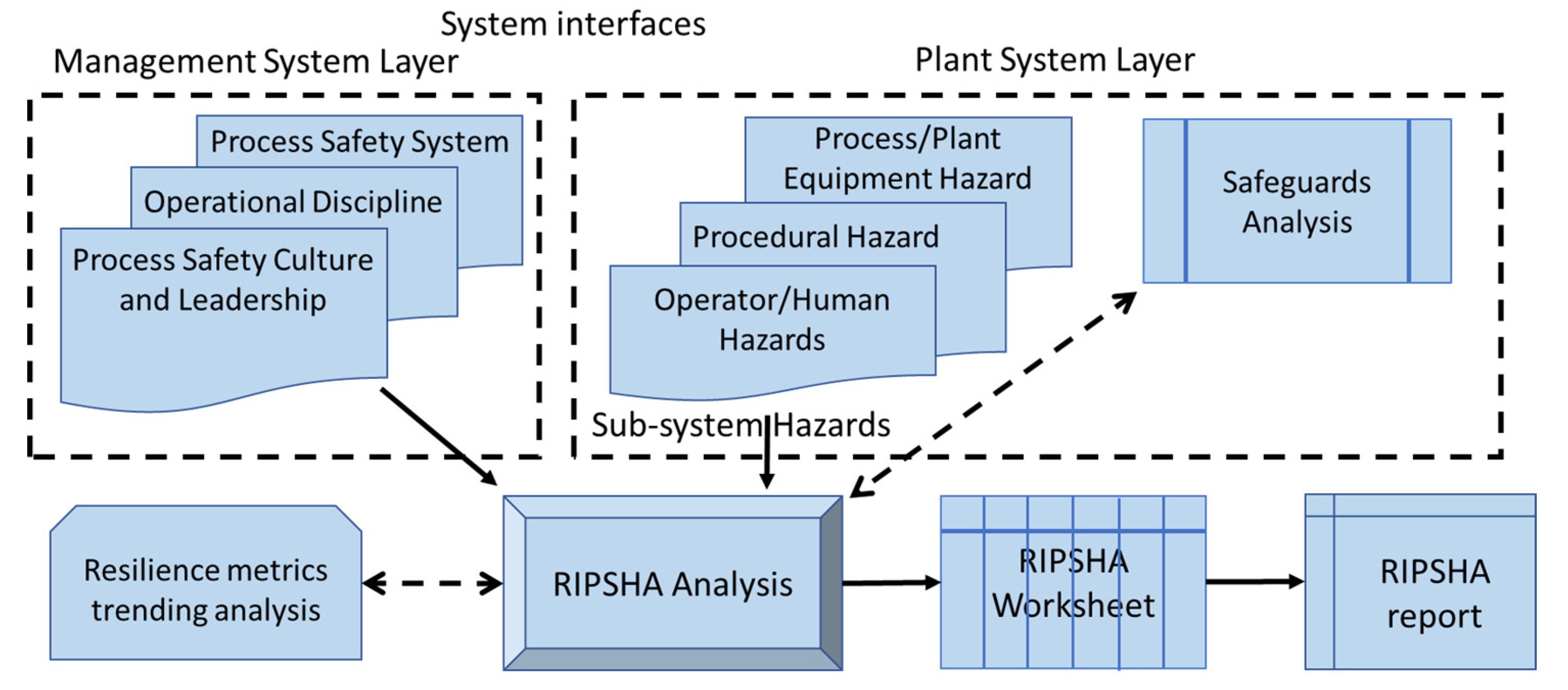
3.3. RIPSHA
3.4. RIPSHA I
- Team formation;
- Charter preparation;
- Data and documents collection;
- Sub-systems procedural review, including worksheet elucidation;
- Documentation of findings;
- Recommendations;
- Closure of recommendations and corrective actions.
3.5. RIPSHA II
4. How Can Resilience Be Maintained?
5. Summaries of Process System Resilience Analysis Example Cases
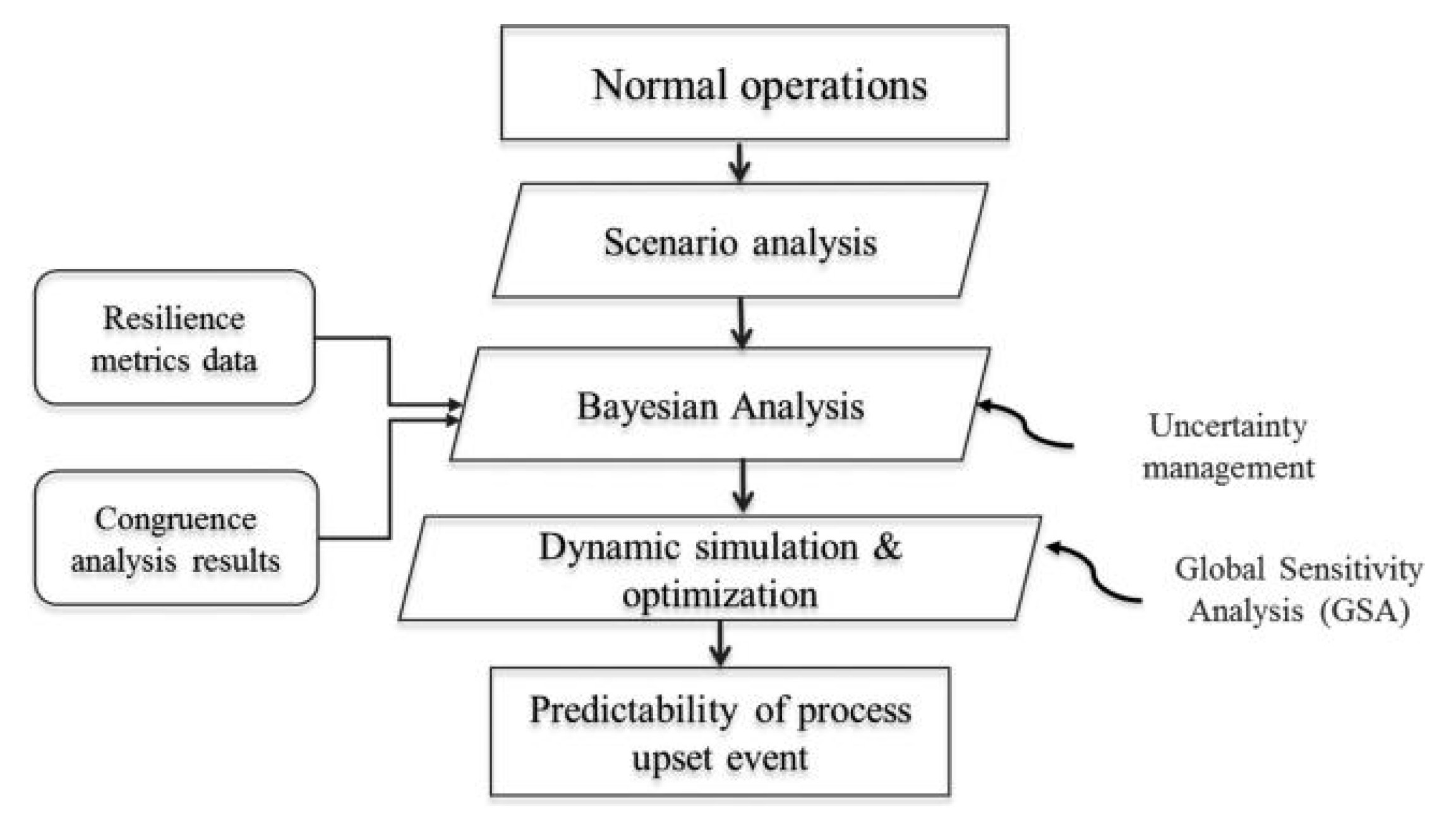
5.1. Batch Process Upset Event
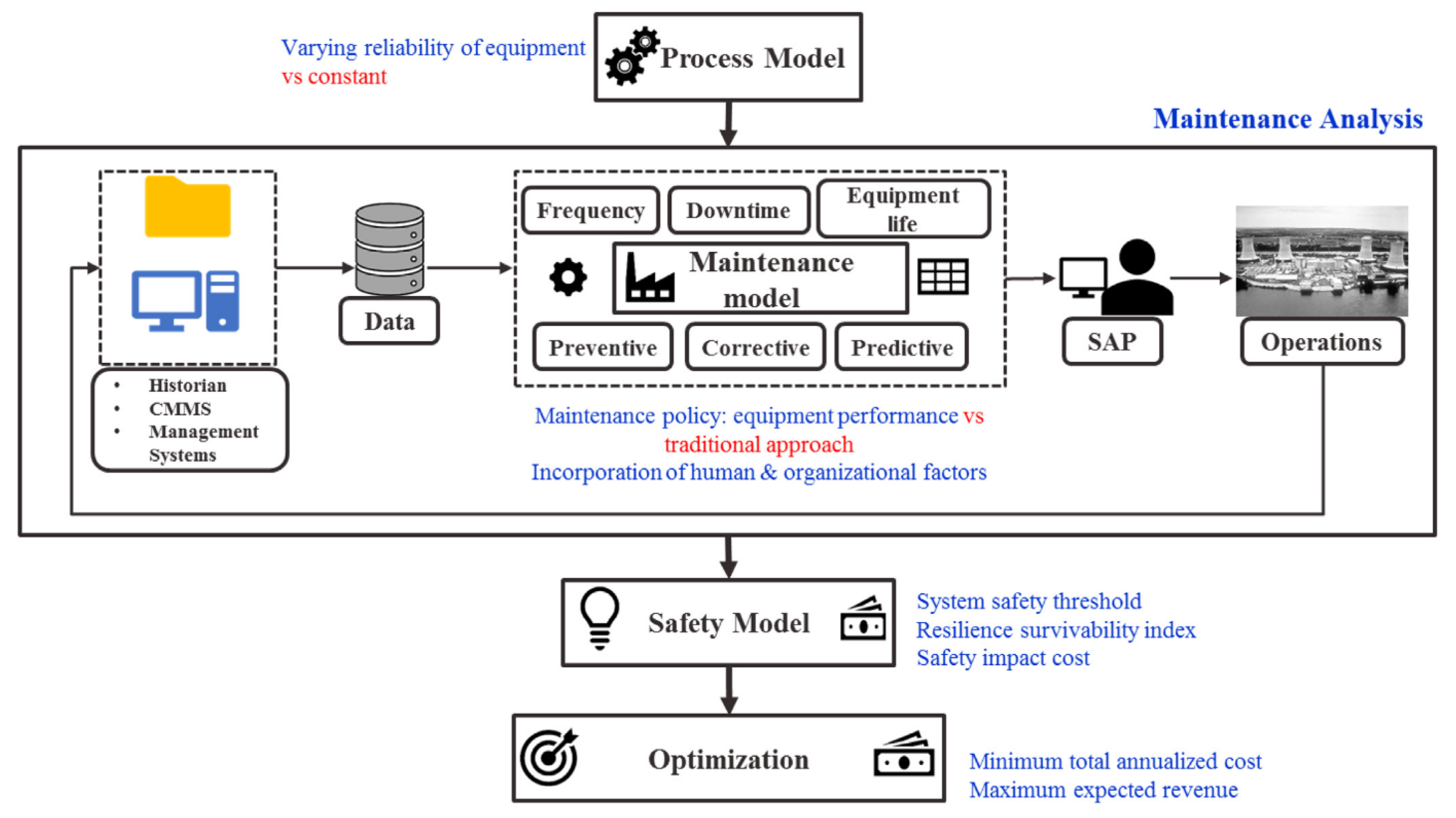
5.2. Data Driven Maintenance Optimization
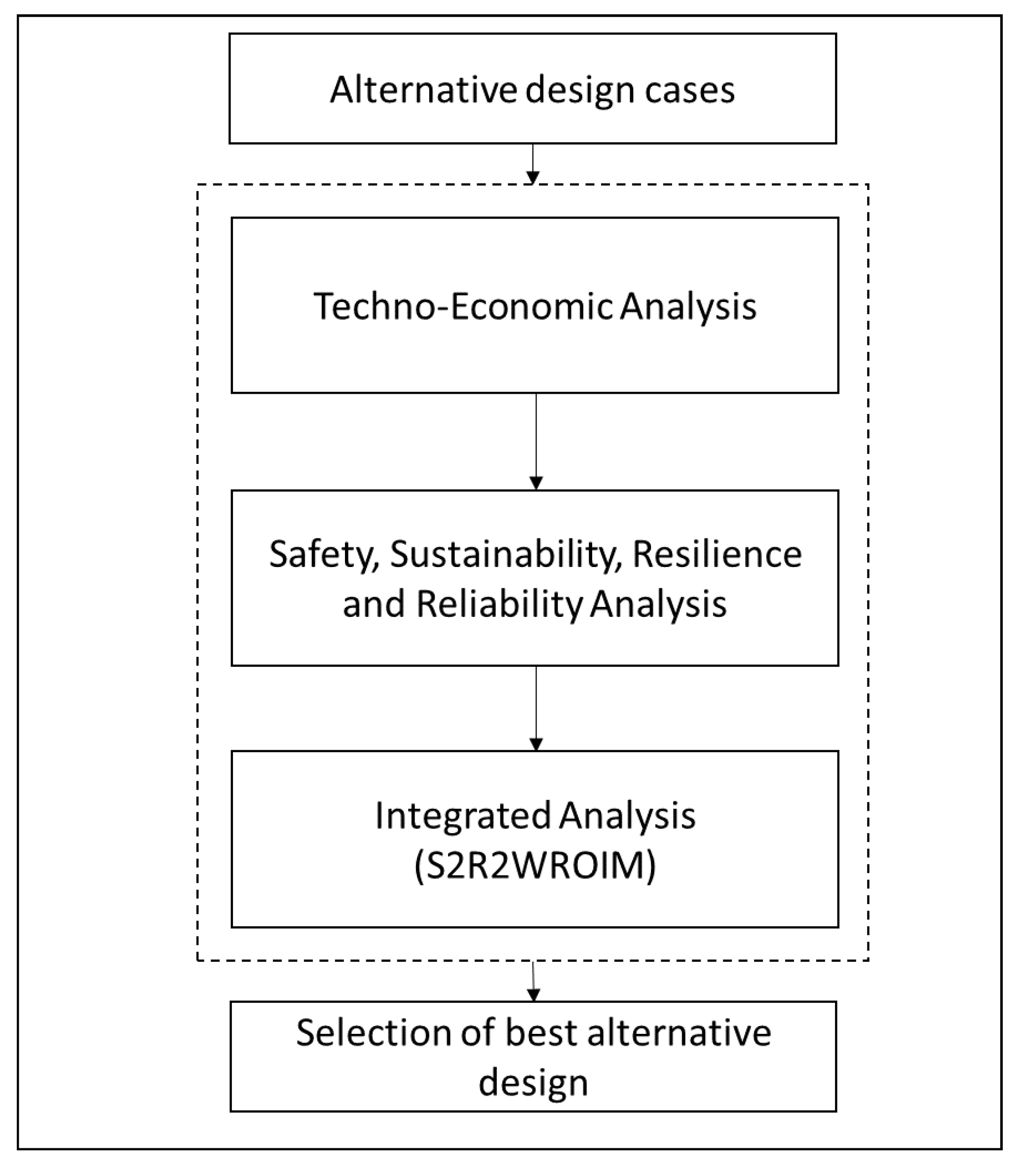
5.3. Resilience Integrated with Safety, Reliability, and Sustainability
5.4. Business Continuity and Sustainability
- Business resumption response time: This is the time required by an organization to continue with their business after an incident or failure scenario;
- Recovery time: This is the time required by an organization to restore to its original state after an incident or failure scenario;
- Recovery point objective (RPO): This is the acceptable limit for maximum data loss that an organization can withstand during an upset event;
- Return time objective (RTO): This is the target time for the resumption of product, service, or activity after an incident;
- Maximum tolerable period of disruption (MTPoD): This is the threshold period after which an organization’s operational capability will be irreversibly threatened because of the adverse impacts that would arise as a result of not providing a product, service, or perform an activity.
6. What Shall Be Done Further?
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fleming, J.; Ledogar, R.J. Resilience, an Evolving Concept: A Review of Literature Relevant to Aboriginal Research. Pimatisiwin 2008, 6, 7–23. Available online: http://www.pimatisiwin.com/online/?page_id=221 (accessed on 28 July 2020).
- Höfler, M. Psychological Resilience Building in Disaster Risk Reduction: Contributions from Adult Education. Int. J. Disaster Risk Sci. 2014, 5, 33–40. [Google Scholar]
- Weick, K.E.; Sutcliffe, K.M. Managing the Unexpected, Resilient Performance in an Age of Uncertainty, 2nd ed.; Jossey-Bass: San Francisco, CA, USA, 2007; ISBN 978-0-7879-9649-9. [Google Scholar]
- Hollnagel, E.; Woods, D.D.; Leveson, N. (Eds.) Resilience Engineering, Concepts and Precepts; Ashgate Publisher Ltd.: Aldershot, UK, 2006; ISBN 0-7546-4641-6. [Google Scholar]
- Haavik, T.K.; Antonsen, S.; Rosness, R.; Hale, A. HRO and RE: A pragmatic perspective. Saf. Sci. 2019, 117, 479–489. [Google Scholar] [CrossRef] [Green Version]
- Pasman, H.J.; Kirillov, I.A. (Eds.) Resilience of Cities against Terrorist and Other Threats: Learning from 9/11 and further Research Issues; NATO Workshop; Springer: Dordrecht, NL, USA, 2008; ISBN 978-1-4020-8488-1. [Google Scholar]
- UN, Disaster Risk and Resilience, UN System Task Team on the Post-2015 Development Agenda, 2012. Available online: https://www.un.org/millenniumgoals/pdf/Think%20Pieces/3_disaster_risk_resilience.pdf (accessed on 28 July 2020).
- Griffiths University. Business Continuity Management and Resilience Framework, 2018. Available online: http://policies.griffith.edu.au/pdf/BusinessContinuityManagementandResilienceFramework.pdf (accessed on 28 July 2020).
- Bergström, J.; Van Winsen, R.; Henriqson, E. On the rationale of resilience in the domain of safety: A Literature Review. Reliab. Eng. Syst. Saf. 2015, 141, 131–141. [Google Scholar] [CrossRef] [Green Version]
- Hosseini, S.; Barker, K.; Ramirez-Marquez, J.E. A review of definitions and measures of system resilience. Reliab. Eng. Syst. Saf. 2016, 145, 47–61. [Google Scholar] [CrossRef]
- Curt, C.; Tacnet, J.M. Resilience of Critical Infrastructures: Review and Analysis of Current Approaches. Risk Anal. 2018, 38, 2441–2458. [Google Scholar] [CrossRef]
- Patriarca, R.; Bergström, J.; Di Gravio, G.; Costantino, F. Resilience engineering: Current status of the research and future challenges. Saf. Sci. 2018, 102, 79–100. [Google Scholar] [CrossRef]
- Suokas, J.; Rouhiainen, V. Quality control in safety and risk analyses. J. Loss Prev. Process Ind. 1989, 2, 67–77. [Google Scholar] [CrossRef]
- Lauridsen, K.; Kozine, I.; Markert, F.; Amendola, A.; Christou, M.; Fiori, M. Assessment of Uncertainties in Risk Analysis of Chemical Establishments; The ASSURANCE Project. Final Summary Report; Risø National Laboratory: Roskilde, Denmark, 2002; Available online: https://backend.orbit.dtu.dk/ws/files/7712279/ris_r_1344.pdf (accessed on 28 July 2020).
- Baybutt, P. A critique of the Hazard and Operability (HAZOP) study. J. Loss Prev. Process Ind. 2016, 33, 52–58. [Google Scholar] [CrossRef]
- Jarvis, R.; Goddard, A. An Analysis of Common Causes of Major Losses in the Onshore Oil, Gas and Petrochemical Industries: Implications for Insurance Risk Engineering Surveys; Version 1.0; Lloyd’s Market Association: London, UK, September 2016; (Search Web on the Title of the Report). [Google Scholar]
- Taylor, J.R. Can Process Plant QRA Reduce Risk?—Experience of ALARP from 92 QRA Studies over 36 Years. Chem. Eng. Trans. 2016, 48, 811–816. [Google Scholar]
- Casal, A.; Olsen, H. Operational Risks in QRAs. Chem. Eng. Trans. 2016, 48, 589–594. [Google Scholar]
- Dinh, L.T.T. Safety-oriented Resilience Evaluation in Chemical Processes. Ph.D. Thesis, Texas A&M University, College Station, TX, USA, 2011. [Google Scholar]
- Dinh, L.; Pasman, H.; Gao, X.; Mannan, M.S. Resilience engineering of industrial processes: Principles and contributing factors. J. Loss Prev. Process Ind. 2012, 25, 233–241. [Google Scholar] [CrossRef]
- Jain, P.; Pasman, H.J.; Waldram, S.P.; Rogers, W.J.; Mannan, M.S. Did we learn about risk control since Seveso? Yes, we surely did, but is it enough? An historical brief and problem analysis. J. Loss Prev. Process Ind. 2017, 49, 5–17. [Google Scholar] [CrossRef]
- Jain, P.; Pasman, H.J.; Waldram, S.; Pistikopoulos, E.; Mannan, M.S. Process Resilience Analysis Framework (PRAF): A systems approach for improved risk and safety management. J. Loss Prev. Process Ind. 2018, 5, 61–73. [Google Scholar] [CrossRef]
- Jain, P.; Rogers, W.J.; Pasman, H.J.; Mannan, M.S. A resilience-based integrated process systems hazard analysis (RIPSHA) approach: Part I Plant system layer. Process Saf. Environ. Prot. 2018, 116, 92–105. [Google Scholar] [CrossRef]
- Jain, P.; Rogers, W.J.; Pasman, H.J.; Mannan, M.S. A resilience-based integrated process systems hazard analysis (RIPSHA) approach: Part II management system layer. Process Saf. Environ. Prot. 2018, 118, 115–124. [Google Scholar] [CrossRef]
- Jain, P.; Mentzer, R.; Mannan, M.S. Resilience metrics for improved process-risk decision making: Survey, analysis and application. Saf. Sci. 2018, 108, 13–28. [Google Scholar] [CrossRef]
- Jain, P.; Chakraborty, A.; Pistikopoulos, E.N.; Mannan, M.S. Resilience-Based Process Upset Event Prediction Analysis for Uncertainty Management Using Bayesian Deep Learning: Application to a Polyvinyl Chloride Process System. Ind. Eng. Chem. Res. 2018, 57, 14822–14836. [Google Scholar] [CrossRef]
- Jain, P.; Diangelakis, N.A.; Pistikopoulos, E.N.; Mannan, M.S. Process resilience based upset events prediction analysis: Application to a batch reactor. J. Loss Prev. Process Ind. 2019, 62, 103957. [Google Scholar] [CrossRef]
- Jain, P.; Pistikopoulos, E.N.; Mannan, M.S. Process resilience analysis based data-driven maintenance optimization: Application to cooling tower operations. Comput. Chem. Eng. 2019, 121, 27–45. [Google Scholar] [CrossRef]
- Moreno-Sader, K.; Jain, P.; Tenorio, L.C.B.; Mannan, M.S.; El-Halwagi, M.M. Integrated Approach of Safety, Sustainability, Reliability, and Resilience Analysis via a Return on Investment Metric. ACS Sustain. Chem. Eng. 2019, 7, 19522–19536. [Google Scholar] [CrossRef]
- Jain, P.; Pasman, H.J.; Mannan, M.S. Process System Resilience: From Risk Management to Business Continuity and Sustainability. Int. J. Bus. Contin. Risk Manag. 2020, 10, 47–66. [Google Scholar] [CrossRef]
- Rasmussen, J. Risk management in a dynamic society: A modelling problem. Saf. Sci. 1997, 27, 183–213. [Google Scholar] [CrossRef]
- Trist, E.L.; Bamforth, K.W. Some Social and Psychological Consequences of the Longwall Method of Goal-getting. Hum. Relat. 1951, 4, 3–38. [Google Scholar] [CrossRef]
- Leveson, N. A new accident model for engineering safer systems. Saf. Sci. 2004, 42, 237–270. [Google Scholar] [CrossRef] [Green Version]
- Leveson, N.G. Engineering a Safer World, Systems Thinking Applied to Safety; The MIT Press: Cambridge, MA, USA, 2011; ISBN-10:0e262-01662-1, ISBN-13:978-0-262-01662-9. [Google Scholar]
- Taylor, J.R. Statistics of design error in the process industries. Saf. Sci. 2007, 45, 61–73. [Google Scholar] [CrossRef]
- Kidam, K.; Sahak, H.A.; Hassim, M.H.; Hashim, H.; Hurme, M. Method for identifying errors in chemical process development and design base on accidents knowledge. Process Saf. Environ. Prot. 2015, 97, 49–60. [Google Scholar] [CrossRef]
- Alauddin, M.; Khan, F.; Imtiaz, S.; Ahmed, S. A Bibliometric Review and Analysis of Data-Driven Fault Detection and Diagnosis Methods for Process Systems. Ind. Eng. Chem. Res. 2018, 57, 10719–10735. [Google Scholar] [CrossRef]
- CCPS, Center for Chemical Process Safety AIChE. Guidelines for Process Safety Metrics; Wiley: Hoboken, NJ, USA, 2010; ISBN 978-0-470-57212-2. [Google Scholar]
- Boring, R.L. 50 Years of THERP and Human Reliability Analysis, PSAM 11, 2012, INL/CON-12-25623 Preprint. Available online: https://inldigitallibrary.inl.gov/sites/sti/sti/5680968.pdf (accessed on 28 July 2020).
- Moura, R.; Beer, M.; Patelli, E.; Lewis, J.; Knoll, F. Learning from accidents: Interactions between human factors, technology and organisations as a central element to validate risk studies. Saf. Sci. 2017, 99, 196–214. [Google Scholar] [CrossRef] [Green Version]
- Williams, J.C. A data-based method for assessing and reducing human error to improve operational performance. In Proceedings of the IEEE Fourth Conference on Human Factors and Power Plants, Monterey, CA, USA, 5–9 June 1988; IEEE: New York, NY, USA, 1988; pp. 436–450. [Google Scholar] [CrossRef]
- Williams, J.C. Toward an improved evaluation analysis tool for users of HEART. In Proceedings of the International Conference on Hazard Identification and Risk Analysis, Human Factors and Human Reliability in Process Safety, AIChE/CCPS, Orlando, FL, USA, 15–17 January 1992. [Google Scholar]
- Taylor, J.R. Human Error in Process Plant Design and Operations: A Practitioner’s Guide; CRC Press: Boca Raton, FL, USA, 2015; ISBN 978-1-4987-3886-6. [Google Scholar]
- Peres, S.C.; Quddus, N.; Kannan, P.; Ahmed, L.; Ritchey, P.; Johnson, W.; Rahmani, S.; Mannan, M.S. Summary and synthesis of procedural regulations and standards - Informing a procedures writer’s guide. J. Loss Prev. Process Ind. 2016, 44, 726–734. [Google Scholar] [CrossRef]
- Mehta, R.K.; Peres, S.C.; Shortz, A.E.; Hoyle, W.; Lee, M.; Saini, G.; Chan, H.C.; Pryor, M.W. Operator situation awareness and physiological states during offshore well control scenarios. J. Loss Prev. Process Ind. 2018, 55, 332–337. [Google Scholar] [CrossRef]
- Guldenmund, F.W. The use of questionnaires in safety culture research–an evaluation. Saf. Sci. 2007, 45, 723–743. [Google Scholar] [CrossRef]
- O’Connor, P.; Buttrey, S.E.; O’Dea, A.; Kennedy, Q. Identifying and addressing the limitations of safety climate surveys. J. Saf. Res. 2011, 42, 259–265. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zohar, D.M.; Hofmann, D.A. Organizational Culture and Climate. In The Oxford Handbook of Organizational Psychology; Oxford Library of Psychology; Kozlowski, S.W.J., Ed.; Oxford University Press: London, UK, 2012; Volume 1, pp. 643–666, ISBN-13: 978-0199395453. [Google Scholar]
- Besnard, D.; Boissières, I.; Daniellou, F.; Villena, J. Safety Culture: From Understanding to Action, ICSI, Institut pour une culture de sécurité industrielle, Toulouse, France 2018. Available online: https://www.foncsi.org/en/publications/collections/industrial-safety-cahiers/safety-culture-from-understanding-to-action/view (accessed on 28 July 2020).
- Pasman, H.J.; Rogers, W.J.; Mannan, M.S. Risk Control of Complex Systems: Can safety performance indicators be more informative? Hazards 2016, 26, 1–9. [Google Scholar]
- FACTS Data Bank. Accident #21667 2002 Czech Republic; #21266 2005 China; #25344 2011 France. Available online: www.factsonline.nl (accessed on 28 July 2020).
- Cataldo, M.; Herbsleb, J.D.; Carley, K.M. Socio-technical congruence: A framework for assessing the impact of technical and work dependencies on software development productivity. In Proceedings of the Second ACM-IEEE international symposium on Empirical software engineering and measurement, Kaiserslautern, Germany, 9–10 October 2008; ACM: New York, NY, USA, 2008; pp. 2–11. [Google Scholar]
- Freedman, D. Wald Lecture: On the Bernstein-Von Mises Theorem with Infinite-Dimensional Parameters. Ann. Stat. 1999, 27, 1119–1140. [Google Scholar] [CrossRef]
- El-Halwagi, M. Sustainable Design through Process Integration: Fundamentals and Applications to Industrial Pollution Prevention, Resource Conservation, and Profitability Enhancement; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- El-Halwagi, M.M. A return on investment metric for incorporating sustainability in process integration and improvement projects. Clean Technol. Environ. Policy 2017, 19, 611–617. [Google Scholar] [CrossRef]
- Guillen-Cuevas, K.; Ortiz-Espinoza, A.P.; Ozinan, E.; Jiménez-Gutiérrez, A.; Kazantzis, N.K.; El-Halwagi, M.M. Incorporation of Safety and Sustainability in Conceptual Design via a Return on Investment Metric. ACS Sustain. Chem. Eng. 2018, 6, 1411–1416. [Google Scholar] [CrossRef]
- CSB, US Chemical Safety and Hazards Investigation Board. Final Investigation Report Chevron Richmond Refinery Pipe Rupture and Fire; Report No. 2012-03-I-CA; CSB, US Chemical Safety and Hazards Investigation Board: Richmond, CA, USA, January 2015. [Google Scholar]
- ISO 22301:2012. Societal Securit—Business Continuity Management Systems—Requirements; The Standard Specifies Requirements to Plan, Establish, Implement, Operate, Monitor, Review, Maintain and Continually Improve a Documented Management System to Protect Against, Reduce the Likelihood of Occurrence, Prepare for, Respond to, and Recover from Disruptive Incidents When They Arise; International Standards Organisation: Geneva, Switzerland, 2012. [Google Scholar]
- ISO 22301:2019. Security and Resilience—Business Continuity Management Systems—REQUIREMENTS; ISO: Geneva, Switzerland, 2019. [Google Scholar]
- ISO 22313:2012. Societal Security—Business Continuity Management Systems—Guidance, in Accordance with the Requirements Set Out in ISO 22301:2012; ISO: Geneva, Switzerland, 2012. [Google Scholar]
- BS25999-2. Business Continuity Management-Part2: Specification Business Continuity Management; BSI: London, UK, July 2007; ISBN 860-2-47329-488-5. [Google Scholar]
- The Brundtland Commission, formally World Commission on Environment and Development (WCED), Main Report: Our Common Future. 1987. Available online: https://sustainabledevelopment.un.org/content/documents/5987our-common-future.pdf (accessed on 28 July 2020).
- Sikdar, S.K. Sustainable development and sustainability metrics. AIChE J. 2003, 49, 1928–1932. [Google Scholar] [CrossRef]
- Avalos, G. Chevron Restarts Crude Oil Unit at Richmond Refinery Damaged in August Fire. 2013. Available online: http://www.eastbaytimes.com/2013/04/26/chevron-restarts-crude-oil-unit-at-richmond-refinery-damaged-in-august-fire-2/ (accessed on 28 July 2020).
- Chemical Safety Board. Recommendations Statistics 2017. Available online: http://www.csb.gov/chevron-refinery-fire/ (accessed on 28 July 2020).
- Chevron. Corporate Sustainability Report Performance data 2016. Available online: https://www.chevron.com/-/media/shared-media/documents/corporate-responsibility-performance-data.pdf (accessed on 28 July 2020).
- Fortune 500. A Database of FORTUNE’s List of America’s Largest Corporations, November 2017. Available online: http://fortune.com/fortune500/2012/ (accessed on 28 July 2020).
- Pasman, H.J.; Rogers, W.J. How trustworthy are risk assessment results, and what can be done about the uncertainties they are plagued with? J. Loss Prev. Process Ind. 2018, 55, 162–177. [Google Scholar] [CrossRef]
- Pasman, H.J.; Rogers, W.J. How to treat expert judgment? With certainty it contains uncertainty! J. Loss Prev. Process Ind. 2020, 66, 104200. [Google Scholar] [CrossRef]
- Karunathilake, H.; Bakhtavar, E.; Chhipi-Shrestha, G.; Mian, H.R.; Hewage, K.; Sadiq, R. Decision Making for Risk Management: A Multi-Criteria. Perspective; Chapter 7 in Methods in Chemical Process Safety; Advanced Methods of Risk Assessment and Management; Khan, F.I., Amyotte, P.R., Eds.; AP Elsevier: Cambridge, MA, USA, 2020; Volume 4, pp. 239–287. [Google Scholar]
- Di Bona, G.; Silvestri, A.; Forcina, A.; Falcone, D. AHP-IFM Target: An Innovative Method to Define Reliability Target in an Aerospace Prototype Based on Analytic Hierarchy Process. Qual. Reliab. Eng. Int. 2017, 33, 1731–1751. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Reference | ||
|---|---|---|---|
| ROI | Return on Investment | ; | [54] |
| SWROIM | Sustainability weighted ROI metric | ; ; | [55] |
| SASWROIM | Safety and sustainability weighted ROI metric | ; ; | [56] |
| S2R2WROIM | Safety, sustainability, reliability, and resilience weighted ROI metric | ; | [29] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pasman, H.; Kottawar, K.; Jain, P. Resilience of Process Plant: What, Why, and How Resilience Can Improve Safety and Sustainability. Sustainability 2020, 12, 6152. https://doi.org/10.3390/su12156152
Pasman H, Kottawar K, Jain P. Resilience of Process Plant: What, Why, and How Resilience Can Improve Safety and Sustainability. Sustainability. 2020; 12(15):6152. https://doi.org/10.3390/su12156152
Chicago/Turabian StylePasman, Hans, Kedar Kottawar, and Prerna Jain. 2020. "Resilience of Process Plant: What, Why, and How Resilience Can Improve Safety and Sustainability" Sustainability 12, no. 15: 6152. https://doi.org/10.3390/su12156152